

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
非对称内核卷积结合语义置信嵌入的模糊人脸图像重建
[胡正平1, 2  , 潘佩云
, 潘佩云1 , 郑赛月1 , 赵梦瑶1 , 毕帅1 , 刘洋3 ]
, 潘佩云, 郑赛月, 赵梦瑶, 毕帅, 刘洋]
|
|



作者简介:

潘佩云,硕士研究生,主要研究方向为模糊图像、低分辨率识别图像重建.E-mail:ppy_1203@163.com.

郑赛月,硕士研究生,主要研究方向为模式识别.E-mail:saiyue1120@163.com.

赵梦瑶,博士研究生,主要研究方向为视频异常检测.E-mail:zhaomengyao0826@126.com.

毕 帅,博士研究生,主要研究方向为视频图像处理.E-mail:921553925@qq.com.

刘 洋,硕士研究生,高级工程师.主要研究方向为模式识别、知识图谱应用.E-mail:46259252@qq.com.
受异构卷积原理的启发,在深度学习框架下提出非对称内核卷积结合语义置信嵌入的模糊人脸图像重建网络.针对对称方形卷积内核在进行特征提取时对重要特征表达的不足,使用非对称内核替代,增强方形卷积内核特征的表达能力.在重建阶段,结合非对称内核卷积与语义置信网络,进一步提取每类语义信息在重建中最利于重建效果的特征,结合置信度引导网络向更利于重建的方向训练.在CelebA、Helen数据集上的实验证实文中网络重建效果较优.
About Author:
PAN Peiyun, master student. Her research interests include blurry image and low resolution recognition image reconstruction.
ZHENG Saiyue, master student. Her research interests include pattern recognition.
ZHAO Mengyao, Ph.D.candidate. Her research interests include video anomaly detection.
BI Shuai, Ph.D.candidate. His research interests include video picture processing.
LIU Yang, master student,senior engineer. His research interests include pattern recognition and knowledge graph application.
Inspired by the principle of heterogeneous convolution, a blurry face image reconstruction algorithm based on asymmetric kernel convolution combined with semantic confidence embedding is proposed under the framework of deep learning. Aiming at the deficiency of symmetrical square convolution kernel in expressing important features during feature extraction,asymmetric kernel is employed to replace the symmetric square convolution kernel to enhance the feature expression ability of the square convolution kernel. In the reconstruction stage, the asymmetric kernel convolution is combined with the semantic confidence network to further extract the most benificial features of each type of semantic information for the results in the reconstruction. The confidence is combined to guide the network to train in a more suitable direction for reconstruction. Experimental results on CelebA and Helen datasets show that the proposed algorithm produces better reconstruction results.
本文责任编委 封举富
Recommended by Associate Editor FENG Jufu
在图像采集过程中, 受拍摄参数设置、图像采集装置抖动、拍摄目标不固定等因素影响, 采集图像可能会出现模糊现象.这不仅影响图像视觉质量, 还影响图像信息传达, 不利于研究者对图像进行处理.为了利用这些模糊图像, 需要进行去模糊处理, 即从模糊图像中恢复清晰图像和相应模糊核.去模糊重建可理解为利用模糊核进行反向卷积操作.在重建去模糊图像研究中, 根据模糊核是否已知, 重建工作可分为非盲图像去模糊和盲图像去模糊[1].而现实中模糊核大多由随机运动产生, 所以盲去模糊工作更具有挑战性.
由于盲图像去模糊是不适定问题, 需要一定的假设或先验知识以约束解空间[2], 并根据最大后验概率估计获得去模糊图像.在传统方法中, Xu等[3]提出L0稀疏表示方法, 寻求合适的梯度先验, 利用先验完成去模糊工作.Ren等[4]利用增强低秩先验, 进一步提升低阶图像的去模糊效果.此外, 去模糊研究中有部分研究者将彩色图像通道信息作为先验项, Pan等[5]利用暗通道先验信息解决图像去模糊问题.Yan等[6]在文献[5]启发下提出亮通道优先思想, 并与暗通道先验结合, 形成联合先验, 进一步提升图像去模糊性能.虽然这些先验表现良好, 但不能用于捕捉特定的图像属性, 如复杂人脸图像, 尤其对于没有太多纹理信息的模糊人脸图像.Pan等[7]开发人脸结构, 解决人脸图像去模糊问题, 将通过脸部边缘估计得到的脸部图像作为全局图像使用, 进而完成模糊核估计工作.
上述方法在图像去模糊工作上都依赖于估计模糊核是否准确, 可实际场景中由于环境噪声等多种复杂原因, 在去噪[8]过程中可能丢失模糊信息, 导致模糊核估计不准确.为了解决此问题, Zhong等[9]提出在盲图像反卷积中处理噪声, 在输入图像上应用定向低通滤波, 达到在降低噪声影响的同时保留模糊信息, 提升模糊核的质量.然而该方法不能避免模糊核估计问题, 使去模糊工作仍受限于模糊核估计的精确度.
近年来, 深度学习在图像超分辨率重建[10]、图像去模糊[11]等领域被广泛应用.深度学习在解决盲图像去模糊上表现较优, 端到端思想为盲去模糊提供新思路.Tao等[12]在编码-解码结构基础上设计尺度循环卷积网络, 不同尺度子网络间参数共享, 达到端到端由粗到精的去模糊效果.Lu等[13]提出基于解纠缠表示的无监督方法, 内容编码器和模糊编码器在模糊图像中拆分内容和模糊特征, 实现解纠缠, 利用循环一致性损失约束去模糊结果.Shen等[14]通过卷积神经网络(Convolutional Neural Net-work, CNN), 根据面部语义图引入内容损失, 改善面部眼睛、鼻子和嘴巴区域的质量, 完成图像去模糊工作.Shen等[15]在文献[14]的基础上添加粗去模糊网络, 利用粗去模糊的结果再进行语义解析, 将得到的语义图输入去模糊操作网络中, 完成去模糊工作.Yasarla等[16]受文献[14]启发, 提出多流网络, 针对不同类别面部语义图对人脸进行分类去模糊, 并融合不同类别去模糊结果, 得到最终去模糊图像.
文献[12]文献[16]均是在卷积网络为网络底层架构前提下改进模型.文献[12]使用网络参数共享机制减少训练参数, 文献[16]利用平均池化层(步幅为2)达到下采样效果, 降低模型复杂度.因此如何在不增加网络复杂度且不引入大量计算条件下提升网路性能, 已成为网络改进方向.Ding等[17]提出非对称卷积网络模型(Asymmetric Convolutional Network, ACNet), 使用3个并行通道代替常见方形卷积核, 几个不同但大小兼容(小卷积核可嵌入大卷积核)的二维卷积核在相同输入、相同操作、相同分辨率输出情况下进行输出求和, 可等效为将这些卷积核在相应位置进行相加, 得到一个能产生相同输出的等效卷积核, 即二维卷积具有可加性.Ding等[17]提出的网络将3个具有方形、水平、垂直核的卷积分支的输出求和, 不仅增强卷积核表达能力, 还避免引入大量参数计算.Li等[18]在文献[17]基础上提出增强非对称卷积网络(Enhanced Asymmetric Convolution Network, EAC-Net), 设计一对增强卷积模块, 由深度非对称卷积和扩张卷积构造, 用于提取短距离特征和长距离特征, 进一步提升网络性能.
受上述已有研究的启发, 本文提出非对称内核卷积结合语义置信嵌入的模糊人脸图像重建网络.使用非对称卷积块替代卷积网络原有方形卷积, 增强方形卷积内核的表达能力, 在训练时提取增强特征信息, 进而使模型能根据置信网络计算每类语义先验信息置信度, 将网络引导至更利于去模糊重建方向.最终网络在不断迭代优化过程中重建清晰人脸图像, 并且也使重建人脸保留原有清晰图像特征信息.在提高网络性能的同时, 非对称卷积块的嵌入没有以增加网络复杂度及引入大量计算为代价.
在盲去模糊重建研究中, 更准确的先验知识为去模糊工作指明方向.不同于其它风景图片, 人脸图像不仅要考虑人物重建, 还要考虑背景及图像整体结构完整度的重建, 且人脸面部的眼睛、鼻子、嘴巴等部位携带大量细节信息和身份特征.如何在去模糊过程中对重点部位进行有针对性的操作, 对保留图像原有细节和身份信息至关重要.而面部语义可提供眼睛、嘴巴、背景等不同部位的信息, 以此作为去模糊网络输入中的语义先验指导.
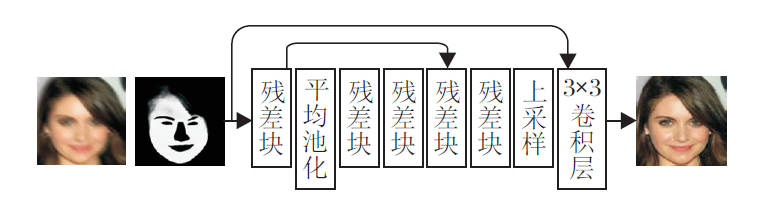
非对称内核卷积结合语义置信嵌入的模糊人脸图像重建网络框架如图1所示.网络由语义网络、残差网络(Residual Network, ResNet)[19]、置信网络(Con-fidence Network, CN)等部分组成.语义网络和置信网络均是在残差网络基本框架结构上进行构造, 并采用密集连接方式.置信网络主要由非对称卷积块(Asymmetric Convolution Block, ACBlock)、卷积模块构成.
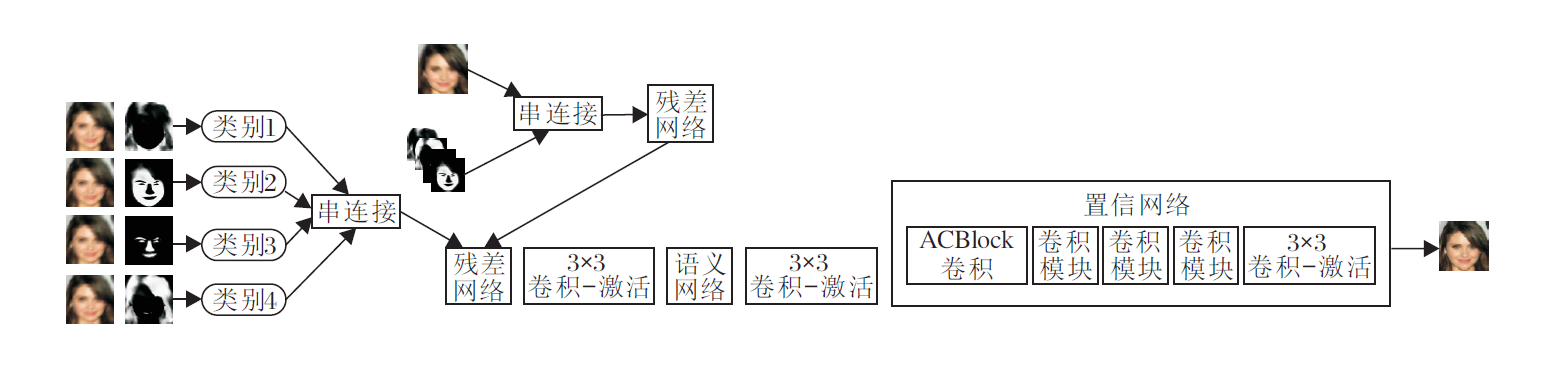 | 图1 本文网络框图Fig.1 Network Framework of the proposed method |
在实验中, 将11个语义脸部标签分为4类, 分别为
m1={背景}, m2={脸部皮肤}, m3={左眉, 右眉, 左眼, 右眼, 鼻子, 上唇, 下唇, 牙齿}, m4={头发}.
根据文献[16]提供的语义分割预训练模型得到网络训练所需语义图.为了利用这4类不同语义图携带的先验信息, 实验中采用语义网络, 结构如图2所示.在残差块基础上采用密集连接, 以此确保训练过程中信息的完整性, 密集连接结构也可起到正则化效果, 当训练数据集较少时能防止过拟合现象发生.
 | 图2 语义网络结构图Fig.2 Sketch map of semantic network structure |
残差网络中使用残差块结构可解决当神经网络较深时, 在反向传播过程中出现梯度爆炸、梯度消失的问题.常见残差块可表示为
xi+1=xi+F(xi, wi),
其中, xi表示输入, xi+1表示输出, F(xi, wi)表示残差映射, 该操作一般由二三个卷积层构成.在实际操作中, xi、xi+1特征图数量有可能不一致, 这时残差块可表示为
xi+1=h(xi)+F(xi, wi), h(xi)=Wi· xi,
其中Wi表示对输入进行1× 1卷积操作.在实验中, 本文采用的残差结构是加入1× 1卷积操作的残差块.
语义网络的引入可利用语义图携带的不同语义先验, 完成在不同条件下的初步去模糊工作.实验中可得到4个针对不同类的重建人脸, 在语义网络的后端将这4类输出进行拼接, 得到尺寸大小为64× 64的图像, 作为下级网络输入.
实验中为了度量不同类语义图对去模糊重建工作的贡献度, 根据贡献度对不同类别分配不同权重, 进而实现利于网络训练且去模糊效果较好的目标, 在网络中使用置信网络.同时为了保证置信网络在网络训练中能采集到更有效的特征信息, 利用非对称卷积可增强方形卷积内核特征表达能力, 将其与非对称卷积结合形成非对称卷积的置信网络.
1.2.1 非对称内核的卷积神经网络
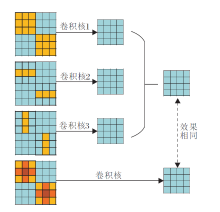
为了增强标准方形内核层表示能力, 将非对称卷积融入方形内核中, Ding等[17]利用卷积可加性提出非对称卷积网络, 主要构成是非对称卷积块(ACBlock), 结构如图3所示.ACBlock包括3个分别为d× d、1× d、d× 1大小的卷积内核, 最终输出结果为3个并行层叠加.如图3所示, 该结果与3个不同卷积核分别卷积再相加的效果相同.
 | 图3 非对称卷积块结构图Fig.3 Asymmetric convolution block structure |
ACBlock定义如下.对于以C通道特征图作为输入, 卷积核尺寸为H× W, 滤波器个数为N的卷积层, 使用F∈ RH× W× C表示滤波器的卷积核, M∈ RU× V× C表示尺寸为U× V、通道为C的特征图输入, O∈ RR× T× N表示通道为N的输出特征图.该层第i个滤波器对应的输出特征映射通道为
O:, :, i=
其中, * 表示二维卷积算子, M:, :, k表示M的第k个通道尺寸为U× V的特征图,
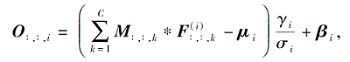
其中, μ i表示批标准化通道平均值, σ i表示标准差, γ i表示缩放系数, β i表示偏移量.
1.2.2 非对称卷积的置信网络
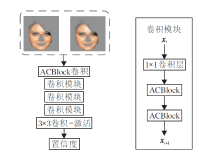
非对称卷积的置信网络结构如图4(a)所示.网络由ACBlock、基于ACBlock的卷积模块及3× 3卷积-激活层组成.图4左图2个人脸分别为清晰图像与语义先验结合得到的人脸图和同样先验条件下进行去模糊重建后的人脸, 网络作用类似于注意力机制[20], 计算不同类语义先验在重建中的贡献度, 对利于网络训练的信息分配相对较高的权重.
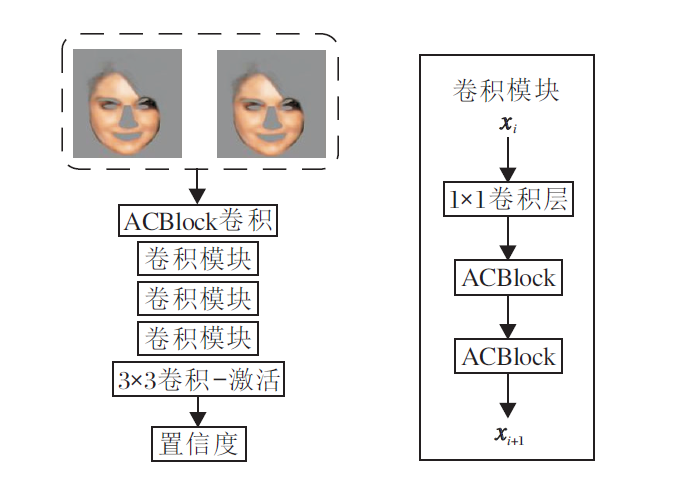 | 图4 非对称卷积的置信网络结构图Fig.4 Confidence network structure of asymmetric convolution |
本文网络通过最小化损失L训练优化网络参数Θ , 损失
Ψ =
其中, fΘ (· )表示非对称内核卷积结合语义置信嵌入的模糊人脸图像重建网络, xdb表示去模糊重建图像, m表示根据语义网络提取语义图, y表示网络输入图像, L表示xdb与x之间L1-范数,
L=
一个人脸图像可表达成人脸图与对应语义图间映射总和:
x=
其中, ☉表示元素间乘法, M表示语义映射数量.由于掩模间相互独立, 式(2)可改写为
Ψ =
换句话说, 为每个类别分别计算损失并求和, 以便获得总损失
L(xdb, x)=
此外, 针对每个类别引入置信度度量, 并使用它加权每个类别损失对总损失的贡献.如果网络因学习不到某个特定类而降低重视程度, 那么置信网络(CN)将为这些类估算低置信度值和较高梯度, 从而帮助网络模型学习这些类的特定特征.此外, 通过重新加权来自每个类别损失的贡献, 可抵消来自不同类别误差估计中的不平衡项.置信损失函数可写为
LC(xdb, x)=
其中, Ci∈ [0, 1].为了防止置信度Ci值归零, ln Ci用于执行正则化操作, α 表示常数, mi☉xdb、mi☉x表示置信网络输入.
模型在训练时还引入感知损失LP.通过VGG-Face预训练模型[21]提取relu1_2、relu2_2、relu5_3层特征, 并计算特征间L1-范数, 以此表示感知损失:
LP=
网络整体损失
Ltotal=LC+β LP,
其中β 表示常数项.使用基于自适应矩估计(Adaptive Moment Estimation, Adam)的优化算法进行迭代训练, 网络在不断学习更新基础上可完成人脸图像去模糊重建工作.
本文实验选择Helen、CelebA数据集.对于CelebA数据集, 首先根据模糊属性筛选192 287幅清晰图像, 作为CelebA的数据子集.Helen数据集包含具有2 000幅图像的训练集和具有330幅图像的测试集.实验分别在CelebA数据子集上随机选取12 500幅图像, 在Helen训练集上随机选取1 000幅图像, 由这两部分数据组成实验训练集.实验过程中将其与利用3D相机轨迹生成、大小由13× 13到29× 29组成的25 000个模糊核进行卷积, 并将σ =0.03的高斯噪声添加到模糊图像中, 以此作为网络最终训练图像.根据文献[14]提供的测试集, 在Helen、CelebA测试数据集上进行测试.测试集共包含图像16 000幅, 是由80个随机模糊核(由文献[14]作者合成, 与训练使用模糊核不同)分别与Helen、CelebA数据测试集上抽取100幅清晰人脸图像卷积而成, 其中Helen、CelebA数据集各8 000幅.
实验选用如下对比网络:文献[3]网络、文献[7]网络、文献[9]网络、文献[13]网络、文献[14]网络、文献[16]网络.为了对比不同网络去模糊能力强弱, 各网络去模糊主观视觉效果对比如图5所示.
 | 图5 不同网络在2个数据集上的去模糊效果图Fig.5 Deblurring results of different networks on 2 datasets |
由图5可发现, 文献[13]网络的去模糊效果不理想, 文献[14]网络得到的图像趋于平滑, 文献[16]网络的去模糊效果接近真实清晰图像, 但仍存在部分细节表达不清晰的缺陷, 而本文网络的去模糊效果在细节表达及整体表现上都更接近清晰图像.
从客观效果上看, 实验采用峰值信噪比(Peak Singal to Noise Ratio, PSNR)、结构相似度(Structural Similarity, SSIM)进行判断, 各网络在Helen、CelebA数据集上的结果如表1所示, 其中文献[14]的结果来自项目官网上公布的测试结果.由表1可知, 在Helen数据集上, 本文网络结果略高于其它网络.相比同样采取语义先验信息去模糊的文献[16]网络, 本文网络清晰度和相似度分别提升0.2%和0.8%.在CelebA数据集上, 本文网络的PSNR值为26.01 dB, SSIM值为0.780, 相比文献[16]网络, 分别提升0.3%和0.8%.综合结果表明本文方法在重建上取得较优效果.
| 表1 各网络在2个数据集上PSNR和SSIM值对比 Table 1 Comparison of PSNR and SSIM of different networks on 2 datasets |
此外, 为了验证本文网络没有以牺牲大量计算时间、引入大量参数运算为代价来达到提升网络性能的目的, 计算所有训练时间, 得到本文网络的训练时间约为3 137.88 min, 文献[13]网络约为4 712.43 min, 文献[16]网络约为3 024.29 min, 文献[14]网络约为7 200 min.文献[16]网络用时最短, 本文网络增加3.7%.
针对模型参数数量, 文献[13]网络为636.3 M, 文献[14]网络为42.3 M, 文献[16]网络为32.1 M, 本文网络为37.6 M.对比文献[13]网络, 本文网络训练参数量大量减少, 但比文献[16]网络提高17.1%.
综上所述, 实验中参数量及训练时间都略有增加, 文献[17]也表明, 因为训练过程是动态的, 内核权重会随机初始化, 训练中梯度会由它们参与的不同计算流得出, 因此ACBlock模块的引入不会和原有卷积层在训练时间及参数上有完全等价的效果.所以本文网络的训练时间和参数量并未做到与使用方形卷积的文献[16]完全等价, 但本文网络实现在同数量级上提升性能的目标.
为了验证去模糊操作重建人脸图像特征信息的保留程度, 利用视觉集合群网络(Visual Geometry Group Network, VGGNet)中包含16个权重层的VGG16网络[22]pool5层输出, 计算重建人脸图像与原始清晰图像特征间L2-范数, 实验中使用DVGG表示上述L2-范数, 数值越小表示去模糊重建图像特征信息保留程度越高.为了方便观察, 将每个数据均扩大10倍表示, 各网络实验结果如表2所示.
| 表2 各网络在2个数据集上的DVGG值对比 Table 2 DVGGcomparison of different networks on 2 datasets |
由表2可知, 在Helen数据集上, 本文网络重建人脸计算得到的DVGG为5.91, 比文献[16]网络减少2.0%, 比文献[14]网络减少21.0%.在CelebA数据集上, 本文网络得到的DVGG为6.43, 比文献[16]网络减少1.2%, 比文献[14]网络减少20.2%.DVGG值越小越表明特征信息保留效果越优.因为非对称卷积的加入可增强卷积核特征表达能力, 所以在训练过程中能提取更重要的特征信息, 理论上本文网络在特征信息保留上应有较好优势.结合表2数据表明, 本文网络确实在人脸身份特征信息保留上具有更优效果.
因每类语义图携带的先验信息不同, 因此在训练时每类语义图是否参与训练会对训练结果产生不同的影响.为了了解每类语义信息参与训练时对结果的影响, 在本文网络结构的基础上, 设置7组训练, 分别为:类别1、类别2、类别3、类别4、类别1+2、类别1+2+3、类别1+2+3+4.实验在CelebA、Helen数据集上进行, PSNR、SSIM值如表3所示.
| 表3 各网络在2个数据集上的消融实验结果 Table 3 Results of ablation experiments of different networks on 2 datasets |
类别1至类别4分别表现出背景信息、面部信息、五官信息、面部边缘信息(面部与头发的边缘).由表3可知, 不同语义图单独参与训练时, 会得到不一样的训练结果.观察PSNR值发现:在Helen数据集上, 仅类别4参与训练时有更优的清晰度; 在CelebA数据集上, 类别2、类别4的清晰度相当.观察SSIM值发现, 2个数据集均是在类别4参与训练时结构相似度更高.当不同语义图联合训练时, 在2个数据集上, 均是在全部类别参与训练时, PSNR、SSIM值均达到最优.综上所述, 语义图对网络训练具有引导作用, 随着语义图的加入, 网络测试结果呈现上升趋势.
针对现有人脸去模糊算法中因常用的对称卷积核在特征提取时对特征表达不足的问题, 本文提出非对称内核卷积结合语义置信嵌入的模糊人脸图像重建网络, 使用非对称卷积内核, 对图像进行特征提取, 增强卷积内核特征表达能力, 传递利于重建的特征信息, 达到较优的重建效果.同时, 结合非对称内核卷积与置信网络, 使网络能根据置信网络为每类语义人脸分配不同权重, 进行针对性训练.相比目前较常见的人脸去模糊网络, 本文网络具有更优的重建效果, 并且没有以花费大量计算时间、引入较多参数运算量为代价.为了进一步提高网络的重建性能, 今后可从原有人脸携带的3D先验信息和更高效的语义提取主干网络等方面展开深入研究.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|