
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于多视角知识图谱嵌入的量刑预测
[王治政1  , 王雷
, 王雷2 , 李帅驰1 , 孙媛媛1 , 陈彦光1 , 许策1 , 王刚1 , 林鸿飞1 ]
, 王雷, 李帅驰, 孙媛媛, 陈彦光, 许策, 王刚, 林鸿飞]
|
|



作者简介:

王治政,博士研究生,主要研究方向为表示学习、知识图谱推理.E-mail:wzz_dllg@mail.dlut.edu.cn.

王 雷,博士,主要研究方向为刑事司法.E-mail:18804002266@163.com.

李帅驰,硕士研究生,主要研究方向为知识图谱问答系统.E-mail:shuaichi@mail.dlut.edu.cn.

陈彦光,硕士研究生,主要研究方向为文本挖掘、知识图谱构建.E-mail:cygariel@mail.dlut.edu.cn.

许 策,硕士研究生,主要研究方向为文本自动摘要、法律人工智能.E-mail:xuce0915@mail.dlut.edu.cn.

王 刚,硕士研究生,主要研究方向为文本摘要.E-mail:31909181_wg@mail.dlut.edu.cn.

林鸿飞,博士,教授、主要研究方向为情感分析与观点挖掘、信息检索与推荐、知识挖掘等.E-mail:hflin@dlut.edu.cn.
量刑预测是智慧司法建设的重要组成部分.为了解决量刑预测的可解释性问题,文中将量刑预测任务重新定义为基于知识图谱的链路预测任务,提出多视角的知识图谱嵌入方法,预测案件量刑.首先,文中设计知识图谱本体模式,用于指导案情描述中关键要素的提取.然后,使用图嵌入技术,从案件要素构成的辅助图中学习要素的初始表示.最后,融合知识图谱的结构化特征,对案件要素进行增强表示.以贩卖毒品类案件为研究对象,文中方法在基于知识图谱的量刑预测任务中性能较优,量刑结果有较好的可解释性.
, WANG Lei, LI Shuaichi, SUN Yuanyuan, CHEN Yanguang, XU Ce, WANG Gang, LIN Hongfei
About Author:
WANG Zhizheng, Ph.D.candidate. His research interests include representation lear-ning and knowledge graph reasoning.
WANG Lei, Ph.D. His research interests include criminal judicature.
LI Shuaichi, master student. His research interests include knowledge graph based question answering.
CHEN Yanguang, master student. Her research interests include text mining and know-ledge graph construction.
XU Ce, master student. His research inte-rests include text automatic summarization and legal artificial intelligence.
WANG Gang, master student. His research interests include text summarization.
LIN Hongfei, Ph.D., professor. His research interests include sentiment analysis and opinion mining, information retrieval and re-commendation, and knowledge mining.
Sentencing prediction is a crucial component of smart judicial construction. To make sentencing results more interpretable, the sentencing prediction task is defined as a link prediction task based on a knowledge graph. In this paper, a multi-view knowledge graph embedding method is proposed to predict the sentencing of a case. Firstly, a knowledge graph ontology pattern is designed to guide the extraction of essential elements in the case description. Next, an auxiliary graph is constructed by the extracted elements and the graph embedding method is applied to learn the initial representations of elements from this auxiliary graph. Finally, the representation of elements is enhanced by fusing the structural features of the knowledge graph. Taking drug trafficking cases as the research data, the proposed method generates better performance in sentencing prediction task based on knowledge graph, and the interpretability of sentencing results is improved.
本文责任编委 欧阳丹彤
Recommended by Associate Editor OUYANG Dantong
随着“ 智慧司法” 建设的不断推进, 人工智能技术逐渐应用于司法量刑中, 成为辅助法律实务工作者进行定罪量刑的关键技术[1].人工智能技术下的量刑预测是从海量司法案件中学习判决模式, 根据案件事实的文本描述推理刑罚裁量.在司法活动中, 量刑是司法审判的关键环节之一, 量刑结果是诸多因素综合作用的产物[2].
目前, 很多深度学习算法都致力于使用端到端的方式学习案件事实的多源特征, 为模型提供预测参数.这些参数通常以数据流的形式随模型预测过程的递进而不断更新, 所以在程序语言的理解和计算中十分方便.基于CAIL2018数据集, 谭红叶等[3]提出多模型投票的量刑预测方法, 划分案件量刑区间, 引入卷积神经网络(Convolutional Neural Net-work, CNN)、长短期记忆网络(Long Short-Term Me-mory, LSTM)等多个深度学习框架, 预测输入的案例文本, 由模型投票选择最优的模型, 获得较优的预测结果.Zhong等[4]提出拓扑学习方法, 结合法条预测、罪名预测、罚金及刑期预测, 借助子任务之间的关联性, 提升模型对刑期预测的性能.Xu等[5]针对混淆度较大的案件事实, 提出基于图神经网络的多任务学习框架, 同时预测罪名、法条和刑期.
相比完全依靠领域专家设计规则的方式进行刑罚裁量, 深度学习模型可大幅减少人工成本, 但是端到端模型需要海量的案例数据进行训练, 以此获得案件事实的语义表示.与可见规则不同, 案例事实的语义特征是由模型自主学习的一种隐层状态, 对办案人员并不可见, 同时语义特征并不是一种稳定状态, 由模型通过挖掘数据与标签间的关联特性而不断被优化.所以, 尽管深度学习模型在预测效率和精度上效果提升明显, 但缺少必要的先验规则, 对案件中的核心要素刻画不足, 导致在量刑规则的可解释性上较弱.
近年来, 研究者们构建许多司法知识图谱, 用于描述案件要素、要素属性及案件要素间的关系, 为量刑规则的可解释性提供重要支持.洪文兴等[6]提出司法案件的案情知识图谱自动构建模型, 依托命名实体识别和关系抽取技术, 面向司法案件的案情, 自动构建数十万法律文书的知识图谱.陈彦光等[7]提出刑事案件的知识图谱构建方法, 针对刑事案件中的简单案例和复杂案例有的放矢, 设计信息抽取模型, 实现涉毒类案件的知识图谱构建.
相比通用领域的中文知识图谱, 司法领域的知识图谱针对性更强, 知识结构更聚焦, 可更好地契合司法办案的业务需求.司法知识图谱以三元组的方式刻画案件事实的核心要素及要素间的关系, 概括案件事实的骨架结构, 为案件的刑罚裁量提供先验规则.利用司法知识图谱实现量刑预测不仅可显式地引入规则, 提升模型的可解释性, 还可保证规则的不变性扩展, 即已有规则不发生改变但是可进行扩增.
现阶段知识图谱嵌入技术逐渐成熟, 为基于知识图谱的量刑预测提供技术保障.Bordes等[8]提出TransE, 以平移嵌入的方式将知识图谱中的实体和关系表示成向量, 提出基于知识图谱的链路预测任务.学者们不断改进TransE, 提出TransH(Transla-tion on Hyperplanes)[9]、TransG[10]、TransA[11]等众多“ Trans” 系列算法, 解决知识图谱中多类型关系的表示问题, 进一步提高链路预测的准确性.同时, DistMult[12]、ComplEx(Complex Embedding)[13]等非线性转换算法也被提出并用于知识图谱嵌入的研究中.近年来, 知识图谱表示研究越来越多地融合语言模型, 如K-BERT(Knowledge-Enabled Bidirectional Encoder Representation from Transformers)[14]和KG-BERT(Knowledge Graph Bidirectional Encoder Representations from Transformer)[15]等将预训练模型用于表示知识图谱中实体和关系的文本描述, 增强实体和关系的语义表达.
本文依托知识图谱嵌入技术, 以贩卖毒品案为研究对象, 将量刑预测任务重定义为基于知识图谱的链路预测任务, 提出多视角的知识图谱嵌入方法, 获得实体和关系向量.首先, 在贩卖毒品罪的案情图谱构建中, 采用远程监督的方式, 根据领域专家定义的知识图谱本体规则抽取案件事实中的核心要素及要素间的关系.再构建所有案件要素的辅助图, 使用图嵌入技术学习案件要素的结构信息, 提供实体和关系的预训练向量.然后, 基于ComplEx设计多视角图谱嵌入方法, 将案件要素的初始向量映射到知识图谱中, 融合图谱结构, 对案件要素向量再表示, 得到知识图谱中实体和关系的向量表示.最后, 根据实体和关系向量完成针对目标实体的量刑预测.
传统的量刑预测模型多使用端到端的分类模型, 以文本分类模型为主要技术手段[16].这些分类模型的输入端为案件事实的自然文本, 输出端为案件事实对应的量刑区间.给定案件事实文本的集合
T={t1, t2, …, tn}
和量刑标签集合
Y={y1, y2, …, yk},
n为案件个数, k为标签个数.分类模型旨在通过卷积操作学习文本特征f(T).该特征经softmax后可得到案件ti的量刑yi的概率.
本文根据分类模型的预测模式将量刑预测任务重定义为知识图谱的链路预测任务.输入端是从案件事实中提取的所有三元组集合
Tr={tri1, tri2, …, trim},
输出端是三元组trii的量刑尾实体.给定量刑三元组tri(headtarget, relation, tailterm), 遮盖量刑实体tailterm, 得到测试三元组tripred(headtarget, relation, ?).知识图谱量刑模型通过对头实体向量和关系向量进行二元操作, 计算当前的量刑实体属于目标实体headtarget的概率.
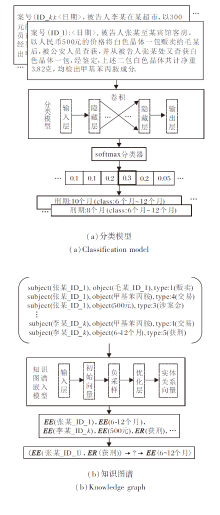
图1是两种方式的量刑预测的实例展示.图中EE(· )表示实体向量, ER(· )表示关系向量.
 | 图1 两种方式的量刑预测实例Fig.1 Examples of 2 kinds of sentencing prediction |
由图1可看出:
1)两者都是以量刑区间代替具体的量刑结果, 这主要是为了平衡数据的分布, 降低数据质量问题对模型产生的噪声.
2)在输入端, 知识图谱的量刑预测是分类模型的延展.它从案件事实的文本描述中抽取结构化的三元组, 把案件的量刑结果作为尾实体参与训练.两者区别在于模型对文本特征的表示方式不同, 即知识图谱的量刑预测采用文本中实体及关系的结构化特征, 分类模型的量刑预测使用案件文本的语义特征.
3)在输出端, 两者都采用概率容错的方式预测量刑标签(或实体).知识图谱的量刑预测通过实体向量和关系向量的二元操作预测量刑实体, 分类模型的量刑预测通过softmax计算每个类别的概率, 选择量刑标签.
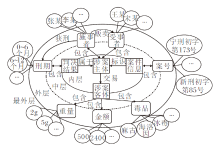
知识图谱量刑的输入端是依靠远程监督和本体设计从案件事实中抽取的三元组Tr.本节以贩卖毒品案为例, 介绍知识图谱本体的设计规则, 如图2所示.图中自内向外依次为一阶关系(属于、交易和标识)、二阶关系(包含)和三阶关系(获刑和贩卖).
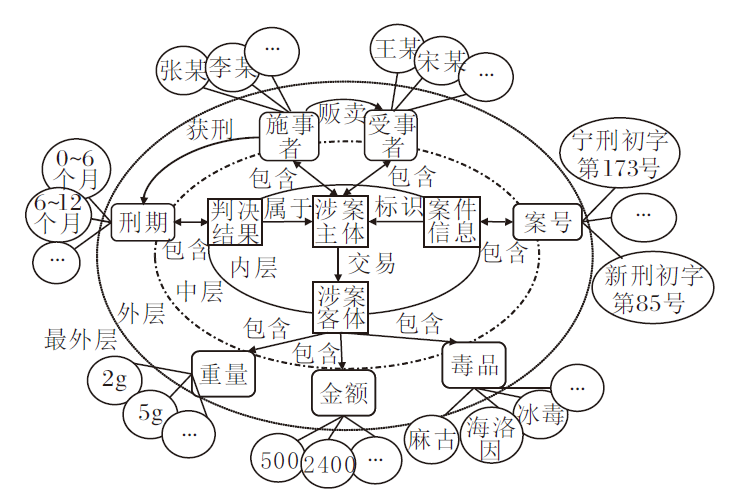 | 图2 贩卖毒品案的知识图谱本体设计图Fig.2 Ontology pattern of knowledge graph for drug trafficking cases |
从图2可看到, 本文的本体设计分为3个层次.内层的一阶关系为单向元关系类型, 主要定义顶层概念之间的依存关系.中层的二阶关系为双向过渡关系类型, 主要定义底层概念与顶层概念之间的扩展关系.外层的三阶关系为单向实体关系, 主要定义底层概念之间的具体关系.最外层的实体为具体案例中的案件要素.
本文在领域专家指导下并结合任务需求, 针对案件事实描述完成顶层概念及联系的设计, 主要包括4类:涉案主体、涉案客体、判决结果、案件信息.涉案主体是指案件事实描述中出现的犯罪嫌疑人以及与其存在贩卖关系的人员等.涉案客体是指案件事实中对犯罪对象的描述.案件信息是指案件的物理属性, 主要用于标识案件要素.判决结果是指对犯罪嫌疑人的刑罚裁量.在保证图谱可训的前提条件下, 基于4类顶层概念选择如下7种底层概念:施事者、受事者、毒品、金额、重量、案号、刑期.基于选定的底层概念, 就底层概念间的关系设计规则, 具体如表1所示.
| 表1 知识图谱本体中关系的设计规则 Table 1 Design rules of relations in knowledge graph ontology |
由表1的规则设定可看出, 规则1的目的是保证部分实体的归一表示.在贩卖毒品案中, 如“ 冰毒” 等实体在整体语料中是统一的, 并不区分属于某一案件, 故使用该规则对此类实体进行归一表示.同时, 规定元关系可根据具体的底层概念进行分解, 得到单向实体关系.规则2是为了简化图谱结构, 防止在底层概念中出现冗余的关系.该规则也指明在知识三元组中头实体与尾实体的主被动关系, 即确保关系的非对称性.规则3主要保证案件要素与顶层概念的路径可达, 避免出现实体孤岛.规则4是为了明确底层概念与顶层概念的附属关系, 消除关系的混淆.例如在图2中, “ 刑期” 应该是针对涉案主体中的“ 施事者” 进行的判决结果, 而不是针对“ 受事者” , 故在底层概念之间明确定义单向实体关系, 表明这种具体的从属.
基于上述的实体选择和规则设计, 本文将贩卖毒品案的案情描述使用若干三元组表示, 将案件事实的自然文本转换成结构化的图谱表示.
本文的多视角的知识图谱嵌入方法表示结构化的案情图谱, 获得实体和关系的向量表示, 方法框架如图3所示, 主要包括三部分.
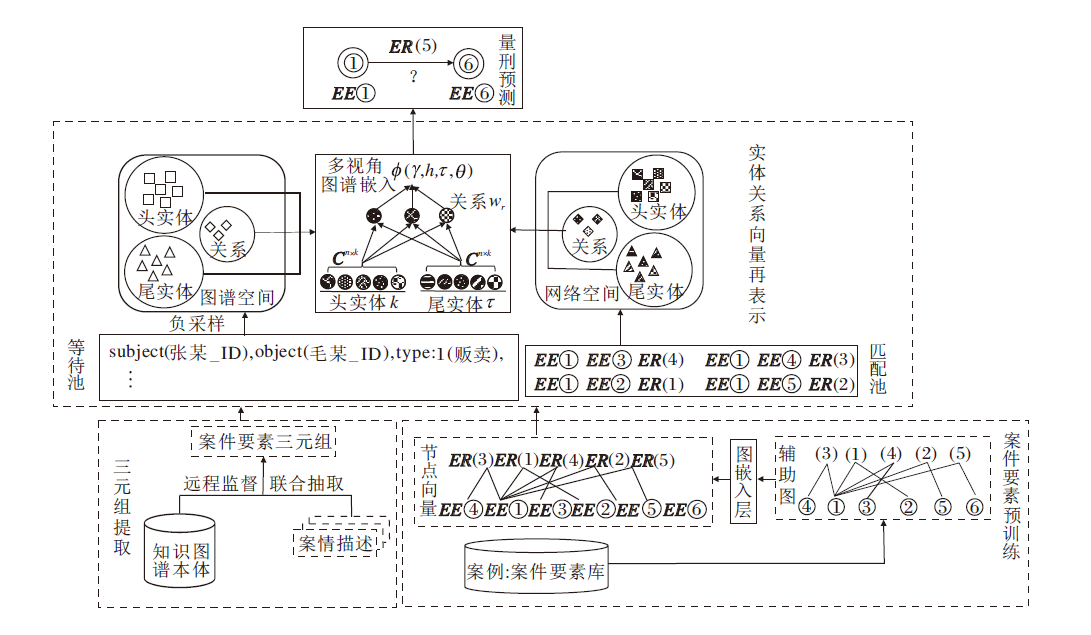 | 图3 多视角的知识图谱嵌入方法框图Fig.3 Framework of multi-view knowledge graph embedding |
1)结合远程监督, 并根据知识图谱本体实现三元组提取, 为模型提供结构化的数据输入.
2)构建所有案件要素(实体和关系)的辅助图, 学习案件要素的初始表示.该辅助图为案件要素的表示提供全局信息, 以图结构的形式突出案件要素间的依存关系.
3)根据ComplEx设计多视角的案件要素再表示方法, 使用“ 等待池” 接收来自知识图谱的结构化知识, 使用“ 匹配池” 融合案件要素的网络特征, 获得知识图谱中实体和关系的最终表示.
Mintz等[17]将远程监督用于关系抽取中, 认为:对于知识图谱中的某个三元组, 如果外部语料包含该三元组中实体对的句子, 那么这些句子都可反映该三元组中的关系.但是这种假设太过宽泛, 会导致很多错误关系的产生, 无法保证三元组的准确性.
本文将这种假设限制在知识图谱本体中, 认为在外部语料中, 只有那些包含本体概念的句子才可能反映概念间的具体关系类型.从语料中筛选句子后, 使用联合抽取的方式提取案件要素, 以此构建模型的输入三元组.对于实体间的关系, 本文明确其关系, 具体分类如表2所示.
| 表2 实体间关系分类 Table 2 Relation classification of entities |
“ 施事者” 和“ 受事者” 在不同案件中可能存在相同的描述(如不同案件中均有施事者“ 张某某” ), 从而导致实体的指代混淆.为了区分不同案件中的“ 施事者” 和“ 受事者” , 本文将知识图谱本体中的“ 案号” 信息拼接在这两类实体的标签中.
三元组是案件要素间的一种关系型结构表示, 反映案件要素在知识图谱中的局部信息.为了提供案件要素的全局依存关系, 本文将案件要素组织成辅助二部图G=(V, E), 其中, V为案件要素的集合, E为案件要素之间的连边.在辅助二部图中, 三元组的头实体和尾实体之间不产生直接连边, 而是通过关系要素建立联系, 关系之间也不产生直接连边.
基于辅助二部图G, 本文使用node2vec[18]学习G中的节点嵌入, 作为案件要素的初始向量.相比采用随机初始化的实体向量和关系向量, 使用图嵌入方式学习实体和关系的初始向量能更准确地表征案件要素在全局空间中的特征分布, 从而为基于知识图谱的案件要素再表示提供具有拓扑结构信息的预训练向量.
node2vec是网络的拓扑表示方法, 目标是学习映射函数f, 将案件要素从网络空间映射到向量空间.它通过对案件要素采样, 构建当前案件要素u的邻域信息Ns(u), 并最大化Ns(u)与u产生连边的条件概率, 实现对u的向量表示:
其中s表示一种采样策略.
在node2vec算法中, 案件要素u的邻域信息Ns(u)由采样策略s从其直接邻域和结构相似的案件要素中获得.根据条件独立假设
Pr(Ns(u)|f(u))=
和特征空间的对称性假设

通过目标函数, node2vec将辅助图中的案件要素V表示成低维稠密的向量RV× d, d表示向量的维度.需要强调的是, 在案件要素的向量空间中并不区分实体和关系, 因为node2vec是一个无差别的节点嵌入算法.因此, 本文方法对案件要素进行再表示, 获得案情图谱中实体和关系向量的最终表示.
多视角图谱嵌入设计一个“ 匹配池” , 用于划分案件要素中的实体向量和关系向量.在“ 匹配池” 中, 实体编码从零开始, 关系编码从实体编码的结束位置开始.使用“ 等待池” 为知识图谱中的三元组设置候选队列, 并接收三元组的采样负例.
“ 匹配池” 的尺寸为V× d, 包含V个d维向量的案件要素, V由实体和关系组成.在“ 匹配池” 中, 使用案件要素的ID对实体和关系进行初步区分, 向量表示分别为EE(
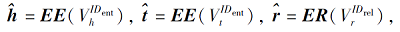
其中,
具体映射方式如下.首先, 按照ID的顺序将所有案件要素的预训练向量存储在“ 匹配池” 中, 形成一张向量表, 反映案件要素在网络空间中的相似性.然后“ 等待池” 中的正例三元组和负例三元组体现案件要素在图谱空间中的依存特性.最后, 为了融合图谱空间中的三元组结构和网络空间中的相似性度量, 根据图谱空间中的实体ID或关系ID在向量表中查找对应的案件要素向量, 得到用于实体关系再表示的初始向量.
由表2可看到, 输入三元组中的关系类型均为非对称关系.所以本文使用ComplEx从图谱结构和网络依存关系两个视角对实体和关系的初始向量进行再表示.ComplEx是一种双线性模型, 将实体和关系的向量表示扩展到复数空间, 通过引入复数的共轭计算解决知识图谱中非对称关系类型的实体表示.本文将实体和关系向量映射到复数空间:
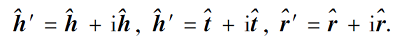
采用与ComplEx一致的得分函数:
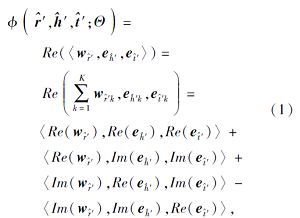
其中, Re(· )表示向量的实部, Im(· )表示向量的虚部,
该得分函数将案件要素的预训练向量融入知识图谱的三元组结构中, 为三元组中实体和关系的特征表示提供全局视角, 增强实体和关系向量的表达能力.
本文方法是一种流水线式的算法结构, 伪代码如下所示.
算法 多视角的知识图谱嵌入方法
子步骤 1 构造辅助二部图G
输入 通过远程监督和联合学习, 根据本体规则提取
获得的知识图谱KG
输出 辅助二部图G
初始化G为空
FOR (e1, r, e2) in KG:
G = {(e1, r), (r, e2)}
RETURN G
子步骤 2 案件要素预训练
输入 辅助二部图G=(V, E), 维度d, 训练轮数r,
采样长度l, 上下文尺寸k, 返回参数p,
输入参数q
输出 案件要素预训练向量PreE
node2vecWalk(G'= (V, E, π ), Start node u, Length l)
初始化walk为[u]
FOR walk_iter=1 to l DO
curr = walk [-1]
Vcurr = GetNeighbors(curr, G')
s = AliasSample(Vcurr, π )
Append s to walk
RETURN walk
π = PreprocessModifiedWeights(G, p, q)
G'= (V, E, π )
初始化walks为空
FOR iter=1 to r DO
FOR all nodes u∈ V DO
walk = node2vecWalk(G', u, l)
Append walk to walks
PreE = StochasticGradientDescent(k, d, walks)
RETURN PreE
子步骤 3 量刑预测
输入 知识图谱KG, 案件要素预训练向量PreE
输出 量刑实体tailterm
FOR (h, r, t) in KG:
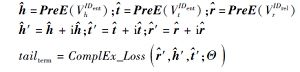
RETURN tailterm
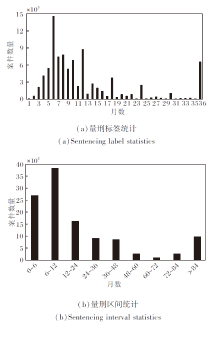
案件事实数据来自裁判文书网(http://wenshu.court.gov.cn)的186 912份涉毒类刑事案件判决书.经过罪名筛选和数据清洗, 将案件事实的文本长度限制在200500, 共获得10 913份符合要求的贩卖毒品类案件.统计这些数据的量刑标签, 将量刑结果进行区间划分, 分为9个类别, 如图4所示.
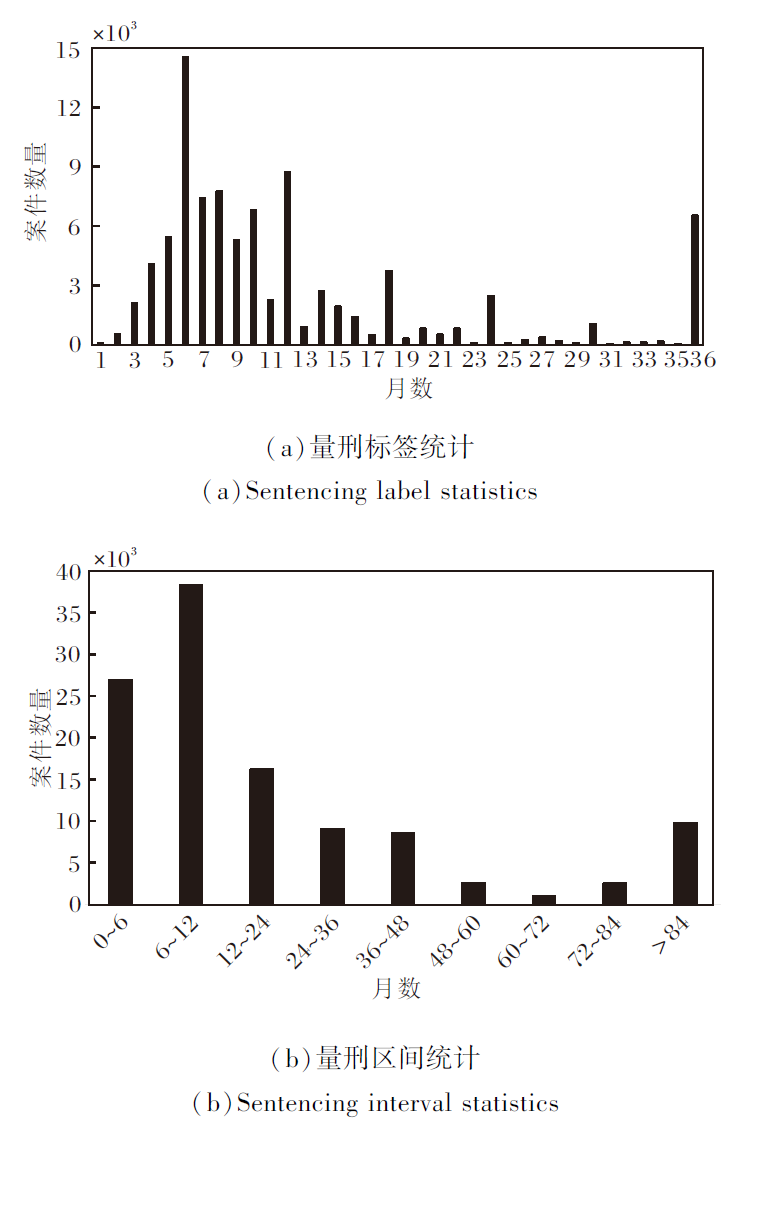 | 图4 贩卖毒品案量刑标签统计和量刑区间统计Fig.4 Statistics of sentencing labels and sentencing intervals for drug trafficking cases |
图4(a)为刑期136个月的案件数量统计.由图可看到, 案件量刑标签的分布极不平衡, 而在划分到固定区间范围后, 数据的类别分布基本达到平衡.因此在基于分类模型的量刑预测和本文方法中均采用对量刑区间的类别预测, 减小数据分布的不平衡产生的噪声.
与分类模型的输入数据不同, 基于知识图谱的量刑预测模型得到描述案件事实的知识图谱.本文根据知识图谱本体从10 913份贩卖毒品罪的案件事实中抽取50 684个三元组.每个案件均包括三四个用于描述案件事实的三元组和一个指明量刑结果的三元组.量刑预测的目的是根据案件事实的三元组获得目标实体的量刑结果, 本文从所有指明量刑结果的三元组中随机抽取2 000个构成测试集, 再抽取2 000个作为验证集, 其余的46 684个三元组为训练集.
案件要素预训练的主要参数如下, 其余参数为node2vec中提供的默认参数.
1)向量维度d1.在使用node2vec获得案件要素初始表示时, 向量维度d1=200.
2)采样长度L.构造案件要素的邻域信息Ns(u)的长度L=100, 即为案件要素u采样100个节点作为其上下文信息.
3)训练轮数epoch1.node2vec使用语言模型对采样的案件要素序列进行训练, epoch1=10.
本文中实体和关系向量再表示的主要参数如下, 其余参数为ComplEx中提供的默认参数.
1)实体和关系向量维度d2.式(1)表明, 实体和关系的最终向量表示由计算结果的实部组成, 维度d2=d1=200.
2)计算批次batch.每个计算批次的大小与模型的“ 等待池” 尺寸一致, 为100× 50, 其中, 100为正例三元组的个数, 50为每个三元组的负采样个数.
3)训练轮数epoch2=2 000.
实验中使用如下指标:测试集中正确实体排名小于等于1的比例(Hit@1), 测试集中正确实体排名小于等于3的比例(Hit@3), 平均倒数排名(Mean Reciprocal Rank, MRR), 准确率(Accuracy, Acc), 宏F值(Macro F1-Value, macro-F).
Hit@1、Hit@3和MRR用于评估基于知识图谱的量刑预测.Acc和macro-F用于文本分类的量刑预测.Acc与Hit@1基本一致, 评价分类结果中最大概率为正确标签的比例.macro-F用于评价模型在所有标签中的分类性能, 是一个宏观评价指标.
为了验证本文方法在基于司法知识图谱的量刑预测任务中的有效性, 设计如下2组实验.
实验1主要为了验证在基于知识图谱的量刑预测任务中, 相比其它知识图谱嵌入方法, 本文方法可能学习到更丰富的实体和关系特征.将本文方法与传统的知识图谱嵌入方法在量刑预测任务上进行对比.对比方法主要包括:TransE[8]、TransH[9]、TransR[19]、TransD[20]、DistMult[12]、SimplE(Simple Embedding)[21]、全息表示模型(Holographic Embeddings, HolE)[22]和ComplEx[13].Random是一种随机选择量刑实体的对比方法.各方法的实验结果如表3所示, 在表中, 本文方法(money)为本文方法去除“ 交易金” 关系, 黑体数字为最优结果, 斜体数字为次优结果.
| 表3 各方法的实验结果对比 Table 3 Experimental result comparison of different methods |
由表3可见, 本文方法取得最优结果.相比ComplEx, 本文方法的Hit@1指标提升1.6%, Hit@3指标提升2.5%.这说明本文方法在预测精度上更优.相比ComplEx, 本文方法的MRR指标提升1%.这说明本文方法对正确实体的预测位置更靠前, 可改进性更强.
由表3还可见, 相比本文方法, 去掉“ 交易金” 后的方法又分别提升1.9%、3.7%和2%.这主要是因为:1)买卖双方的金额交易存在较大的不确定性因素, 它是由时间、地域、毒品交易量和涉案人员主观动机等多种因素决定.同时在《中华人民共和国刑法(2017年修正)》第347条中明确规定贩卖毒品的重量和种类, 对涉案金额并未做出规定, 因此交易金额在量刑中属于一种弱特征.2)案件事实描述中对于交易金额的提及并不全面, 抽取的金额只是涉案总金额的一部分, 因此对模型预测带来噪声.实验表明, 基于知识图谱的量刑预测有更好的规则解释性, 不仅可通过增减特定规则获得更优的预测结果, 而且能更好地契合相关法律法规的内容.
实验2将案件要素预训练模块迁移至TransE中, 验证其对提升方法性能的有效性.实验结果如表4所示, 表中TransE+Graph embedding 表示使用图嵌入方式学习案件要素的预训练表示, 然后使用TransE在知识图谱中进行量刑预测.由表可见, 案件要素的预训练向量提升TransE的预测性能, Hit@1指标提高0.9%, Hit@3指标提高1.3%.这表明在知识图谱嵌入中融合网络结构信息可提高模型的预测精度, 提升量刑预测任务的性能.
| 表4 知识图谱量刑预测的模块实验结果 Table 4 Module experiment results of sentencing prediction based on knowledge graphs |
基于知识图谱的量刑预测任务是根据端到端文本分类任务而重新设计的.本次实验在图谱量刑预测的基础上, 开展分类量刑预测的实验, 主要目的是验证基于知识图谱开展量刑预测任务的可行性, 同时为该任务的进一步研究提供改进方案和思路.
对比的中文文本分类方法包括:基于CNN的文本分类(CNN for Text Classification, TextCNN)、基于循环神经网络的文本分类(Recurrent Neural Networks for Text Classification, TextRNN)、基于带注意力机制的循环神经网络的文本分类(Recurrent Neural Networks with Attention for Text Classification, Text-RNN_Attention)、基于循环卷积神经网络的文本分类(Recurrent CNN for Text Classification, TextRCNN)、深度金字塔卷积神经网络(Deep Pyramid CNN, DPCNN)、FastText、基于预训练语言模型的文本分类(Bidirectional Encoder Representation from Trans-formers, Bert-Transformer).
在深度学习模型中, 数据输入为案情描述的自然文本及提取的量刑标签.将10 913份涉毒类案件划分为训练集、验证集和测试集.验证集和测试集分别来自根据知识图谱量刑中的验证三元组和测试三元组检索的2 000个案情文本及其量刑标签, 其余的6 913个案情文本和量刑标签构成训练集.Bert_Transformer采用原文本和默认参数进行实验.预训练模型选择Bert_Chinese_base, 词向量维度设为768.其它方法对输入的案情文本进行分词和去停用词处理, 使用最优的模型参数.词向量维度均设为200维.具体实验结果如表5所示, 表中黑体数字为最优结果, 斜体数字为次优结果.
| 表5 各方法的量刑预测实验结果 Table 5 Sentencing prediction results of different methods |
在表5中, 除Bert_Transformer以外的其它文本分类方法都是基于搜狗实验室发布的中文词向量(https://github.com/649453932/Chinese-Text-Classification-Pytorch)进行的.在文本多分类问题中, Acc衡量方法对所有类别的预测精度, 而macro-F衡量方法对单个类别的预测精度.实验结果表明, 本文方法与使用词向量的文本分类方法性能相当, 而与Bert_Transformer差距较大.这主要是因为:1)Bert模型利用大量的参数和更深的网络层数学习文本语义的更高阶表示, 训练所得的词向量具有更多的语义信息, 因此在文本分类的准确率中获得更优结果.2)Transformer在编码文本时使用注意力机制捕获文本的长距离依赖, 这种文本特征结合Bert学习的词向量可挖掘文本更深层次的语义特征, 具有更优的分类优势.
为了提高量刑预测的可解释性, 本文提出多视角的知识图谱嵌入方法.与端到端的文本分类模型不同, 本文方法通过人工参与知识图谱的本体设计, 以结构化的三元组刻画案件事实的核心要素, 同时使用多视角图谱嵌入方法获得案件要素的向量表示, 完成量刑预测.知识图谱本体为模型学习案件的量刑特征提供先验规则, 保证办案人员能理解模型的预测依据.多视角图谱嵌入融合案件要素在图谱空间的依存结构和网络空间的相似关系, 相比基准知识图谱嵌入方法, 在量刑预测结果上有明显提高.今后将增强知识图谱中的实体和关系与案件的文本描述之间的关联, 获得实体和关系在案情文本中的语义信息, 并结合预训练方法提高基于知识图谱的量刑预测性能.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|