
{kind=link}
{kind=link}
{kind=link}
基于序列对抗域适应的智能裁剪算法
[王皓文1  , 桑农
, 桑农1 ]
, 桑农]
|
|



作者简介:

王皓文,硕士研究生,主要研究方向为计算机视觉、图像处理、模式识别.E-mail:whw95@hust.edu.cn.
About Author:
WANG Haowen, master student. His research interests include computer vision, image processing and pattern recognition.
智能裁剪任务一直受到缺乏训练数据的困扰,目前还局限于公开数据集中.因为实际应用场景与训练场景之间存在域迁移,文中提出基于序列对抗域适应的智能裁剪算法.首先,通过实验证实裁剪数据集GAICD和CPC之间存在域迁移问题.然后,构造由美学评分模块和对抗域适应模块组成的算法.美学评分模块用于预测图像的美学评分,并辅助提取面向裁剪任务的不变特征.对抗域适应模块实现基于对抗的域适应学习.不同裁剪数据集之间的域迁移实验及室内/室外场景之间的域迁移实验均验证文中算法的有效性.
Image cropping is short of training data for its high threshold for annotation. Current research on image cropping is confined on public datasets. Grounded on domain shift between training domain and practical application scene, a listwise adversarial domain adaption algorithm for image cropping is proposed in this paper. Firstly, the domain shift between two image cropping datasets, GAICD and CPC, is proved. Then, an image cropping model composed of an aesthetic evaluation module and an adversarial domain adaptation module is constructed. Aesthetic evaluation module is employed to predict the aesthetic score of current image and assist the model to extract the invariant features for cropping task. Adversarial domain adaptation module is exploited to realize adversarial based domain adaptation learning. Domain migration experiments between different cropping datasets and between different scene domains verify the effectiveness of proposed algorithm.
本文责任编委 吴飞
Recommended by Associate Editor WU Fei
图像裁剪任务按照美学标准裁剪图像, 将裁剪后的图像作为生成图像, 使生成图像具有更高的美学质量.图像裁剪操作简便, 只涉及空间操作, 却显著提升图像的美学质量, 被广泛应用于图像编辑领域.然而人工裁剪存在效率较低、门槛较高的问题, 裁剪者需要花费大量时间学习摄影知识并逐一裁剪图像.因此, 研究利用智能算法自动裁剪图像是一件有价值的工作.相比人工裁剪, 智能裁剪算法不需要用户掌握摄影知识, 任何人都能在短时间内得到大批图像的优质裁剪结果.
在智能裁剪从理论走向实用的过程中, 有两个问题需要解决:构建有监督情况下的智能裁剪算法和提升智能裁剪算法在无标签域上的泛化能力.具体来说, 研究者首先要构建合适的裁剪算法, 用于模拟人类美学鉴赏的过程, 描述当前裁剪图像的美学质量, 筛选较好的裁剪方式, 使用美学标签加以约束, 增强裁剪算法在特定数据集上的裁剪效果.然后, 裁剪算法需要具有一定的泛化能力, 适应于不同数据集和不同场景.
智能裁剪任务从算法上分为3类:美学驱动算法、注意力驱动算法、数据驱动算法.数据驱动算法又包含全监督算法和弱监督算法.
美学驱动的智能裁剪算法按照传统美学规则裁剪图像, 会根据构图规则设计手工特征, 提取图像的美学信息并筛选裁剪方式[1, 2, 3, 4].虽然美学驱动算法具有可解释性, 但遵循固定构图规则, 不能适应其它构图模式.并且该类算法采用的原始数据来源于AVA[5]、AADB[6]等美学数据集, 缺乏针对裁剪任务的标注.
注意力驱动的智能裁剪算法从图像中的显著性区域生成裁剪图像.从经验可知, 人物、动物、建筑等关注度更高的区域显然包含原始图像中的主要信息, 通常应被保留.因此, 注意力驱动算法考虑到显著目标对裁剪图像的影响, 取得较优效果[4, 7, 8, 9, 10, 11, 12, 13].Lu等[7]先通过显著性检测网络得到显著性最高的区域, 再基于该区域生成合适的裁剪区域.Tu等[8]和Lu等[14]把显著性检测结果用于监督生成的裁剪结果.注意力驱动算法往往会将最显著的区域放在裁剪图正中心, 更适用于提取缩略图而不是智能裁剪.
近年来数据驱动的智能裁剪算法得到快速发展.AVA数据集[5]在早期被作为训练数据, 用于训练裁剪算法.但AVA数据集只包含原图的美学标注, 难以满足裁剪任务的要求.所以, 学者们提出ICDB[1]、FLMS[2]、FCDB[15]数据集, 将原图裁剪成更好的区域, 并保留裁剪数据作为标签.学者们进而提出CPC[16]、XPView[16]、GAICD[17]数据集, 每幅图像都包含大量相似的图像对.在这些数据集的支撑下, 数据驱动算法也取得较优效果.按照标签的类型, 现有数据驱动的智能裁剪算法可分为全监督算法和弱监督算法.
全监督数据驱动算法在训练时使用训练集标签, 通常包含裁剪标签(裁剪方式的坐标)和美学标签(裁剪方式对应的美学分数标签).Wang等[11]、Wei等[16]和Deng等[18]使用AVA、AADB等传统美学数据集, 训练得到美学分类器, 并生成裁剪区域.Zeng等[17]摒弃传统的美学分类+裁剪两阶段方法, 定义预选裁剪框, 将预选图像区域序列排序.Tu等[8]将原图划分成若干块, 预测不同块的像素评分, 再按照设定的构图模式得到裁剪图.虽然上述方法已取得较好效果, 但未考虑训练样本分布和实际测试样本分布之间的差异, 在实际使用中会因为域偏移问题导致性能下降.
弱监督数据驱动算法在训练时只会使用部分标签, 如训练数据中只包含当前原始图像的质量, 而不包含完整的美学标签[14, 19].而Li等[20]将Chen等[19]的美学分类器作为软标签, 通过强化学习的方法找到最优裁剪模式.
研究者们利用有标签的训练集样本训练模型, 再将训练好的模型用于推理其它缺少标签的测试样本.在这个过程中, 训练集样本分布与测试样本分布之间往往存在差异, 这个差异称为域偏移.域适应就是为了解决域偏移问题.在域适应问题的研究中, 有标签的用于训练的数据域称为源域, 缺少标签的数据域称为目标域, 其中, 目标域中只有图像而没有任何标签的情况称为无监督域适应.无监督域适应算法旨在对齐源域和目标域的特征, 在目标域无标签的情况下, 将从源域学到的模型应用于目标域.
无监督域适应算法已大量应用于跨域分类、检测、分割任务.有些方法[21, 22, 23, 24, 25]引入损失函数, 衡量源域和目标域分布的差异, 并加以约束.有些方法[26, 27, 28, 29]采用基于对抗的域适应策略, 将特征提取器作为生成器, 混淆对齐两个域的特征.还有些方法[30, 31]采用梯度反转层[31]对齐不同域, 在生成器和域判别器之间添加梯度反转层, 使生成器和域判别器按照相反的方向优化.
现有的智能裁剪算法未考虑无监督域迁移的问题, 有些算法训练样本和测试样本均来自同一数据集GAICD, 不涉及域迁移的问题[8, 17, 32].还有些算法的训练集和测试集虽然完全不同, 但默认算法能从单一训练集学到足够的泛化能力, 不需要采用域迁移策略[7, 15, 16, 33].Lu等[14]和Chen等[19]的方法尽管实现从源域到目标域的迁移, 但需要大量目标域高质量图像作为先验信息, 不属于无监督域适应.用户也很难在实际使用中获得大量目标域高质量图像用于训练算法.
因此, 本文提出基于序列对抗域适应的智能裁剪算法(Listwise Adversarial Domain Adaption Algori-thm for Image Cropping, LDAIC), 提升裁剪算法对于不同场景的适应能力.在训练时, 本文算法依赖的美学标签只来自源域样本, 针对于不同的目标域, 选择对应的无标签图像作为目标域样本, 用于训练网络的域适应能力.具体来说, 针对域迁移问题, 设计基于对抗损失的域适应算法, 用于对齐源域数据和目标域数据.当输入样本来自源域/目标域时, 域判别器分辨当前样本的所属域, 而特征提取器会尽量混淆两个域的数据, 对齐目标域样本特征与源域样本特征.进一步, 本文设计2个不同的美学分类器, 用于评价当前区域的美学质量, 通过约束预测值的相似度和权重参数的差异度, 辅助算法提取到与裁剪任务相关的不变特征.通过这种策略, 提升裁剪算法在跨域和跨数据集时的泛化能力, 能在完全不依赖目标域美学标注的情况下提升裁剪算法在目标域上的裁剪性能.
首先, 本文使用2个实验证实裁剪任务中存在域迁移问题.
实验选用CPC[16]、GAICD[17]数据集.CPC数据集包含10 800幅图像, 每幅图像有24种裁剪方式, 每种裁剪方式包含6位不同标注者的美学评价.实验中将6位标注者美学评价的平均值作为当前区域的美学评分.本文将CPC数据集也分为包含7 559幅图像的训练集和3 238幅图像的测试集.GAICD数据集包含1 236幅原始图像, 每幅原始图像平均包含86种不同的裁剪方式, 共106 860种.每种裁剪方式都具有对应的美学标签, 标签分数取值范围为1~5, 分数值连续分布.数据集上1 036幅图像作为训练集, 200幅图像用于测试和验证.GAICD数据集上预选裁剪区域的相对位置按照固定网格(Grid Anchor)规则[17]确定, 因此预选框的相对位置是研究者已知的先验信息.
将CPC数据集和GAICD数据集分成的训练集和测试集交替作为源域和目标域, 训练裁剪算法并测试其在训练域和域迁移情况下的性能.
为了衡量裁剪算法的性能, 本文采用如下评价指标:斯皮尔曼等级相关系数(Spearman's Corre-lation Coefficient for Ranked Data, SRCC), 预测结果中前k种裁剪方式属于美学标签中前N种裁剪方式的准确率(AccK/N).SRCC反映2组变量之间关系的密切程度.一幅原始图像的裁剪子图构成一个图像序列, 对应一个美学标签序列和一个美学预测序列, 美学标签评分序列与美学预测序列相似度越高, SRCC值越大.按照文献[17] , AccK/N中取Acc5和Acc10作为对比项:
$Ac{c_5} = \mathop {\mathop \sum \limits_{n = 1} }\limits^4 Ac{c_{n/}}_5, Ac{c_{10}} = \mathop {\mathop \sum \limits_{n = 1} }\limits^4 Ac{c_{n/}}_{10}.$
在实际应用中, 用户只关心高质量裁剪结果, 不在意裁剪算法对低质量裁剪结果预测的精确度.虽然SRCC考虑到这一点, 赋予高质量裁剪区域更大的判别权重, 但仍会受到低质量裁剪区域的影响.AccK/N只包含前N个高质量裁剪区域, 是本文首选的评估指标.
实验1旨在验证使用源域样本训练好的裁剪算法, 在迁移到目标域后, 性能会显著下降.实验2旨在验证CPC数据集和GAICD数据集之间的数据分布存在差异, 本文构造域判别器, 赋予2个域数据各自的域标签进行训练, 最后测试域判别器的二分类准确率.
实验1 跨数据集模型性能验证
实验1共包含4组对照实验, 分别将CPC/GAICD作为源域和目标域.这里约定表达方式:CPC→ GAICD表示训练样本来自源域CPC, 测试样本来自目标域GAICD时, 算法从CPC迁移到GAICD上的实验结果.而CPC→ CPC表示训练样本和测试样本均来自CPC, 不存在域迁移时的实验结果.
不同源域数据在不同目标域上的结果如表1所示.当源域样本和目标域样本来自一个数据集时, 即CPC→ CPC和GAICD→ GAICD, 裁剪算法能生成较优结果.而当CPC→ GAICD和GAICD→ CPC时, 算法性能会受到严重影响.在固定训练集的情况下, 算法在同分布的测试样本上表现更优.在固定测试集时, 使用同分布的样本训练的算法会取得更优效果.
| 表1 不同源域数据在不同目标域上的结果 Table 1 Results of different source domains data on different target domains |
实验1说明, 在裁剪任务中进行数据集迁移会影响实验效果.为了进一步证实这种性能下降是由CPC、GAICD数据集上数据分布不同引起的, 设置实验2.
实验2 GAICD和CPC的可分性实验
实验2共包含3组对照实验, 目的是测试域判别器能否学习到判别源域图像和目标域图像的能力.
实验模型包含一个计算机视觉组(Visual Geo- metry Group, VGG)结构的特征提取器、一个由全连接层和softmax组成的判别器, 输入为两个域的图像, 输出为当前图像隶属于两个域的置信度.
第1组实验.从KAIST数据集[34]上随机选取1 200幅白天图像和1 200幅黑夜图像.从白天数据和黑夜数据中各选取1 000幅图像作为训练集, 200幅图像作为测试集, 以0.5作为置信度的阈值, 算法收敛以后的二分类准确率为93.4%.
第2组实验.从GAICD数据集和CPC数据集上各选取1 000幅图像作为训练集, 200幅图像作为测试集, 阈值为0.5时的二分类准确率为74.3%.
第3组实验.从GAICD、CPC数据集上选取图像, 随机从中各抽取600幅并两两组合, 形成混合A数据集和混合B数据集.将混合A、混合B数据集各自分成1 000幅训练集和200幅测试集, 阈值为0.5时的二分类准确率为48%~52%.
在第1组实验中, 源域样本和目标域样本在光照强度上有显著差异, 二分类准确率在90%以上, 域判别器可轻松分辨两个类别的图像, 说明实验中的域判别器是有效的.第3组实验中GAICD、CPC数据集上的数据被完全打乱分到两个数据集, 域判别器无法区分当前样本来自混合A数据集还是混合B数据集.在第2组实验中, 域判别器能取得75%左右的准确率, 与第3组实验中的50%准确率相比有明显增长, 说明GAICD数据集和CPC数据集之间的数据分布存在显著差异, 并且体现在图像而不是标签上, 这也解释了实验1进行数据集迁移之后的模型性能下降原因.
上述2个实验说明GAICD数据集和CPC数据集之间的数据分布存在差异, 即域偏移, 并且这种域偏移会导致算法在域迁移的过程中性能下降.
为了解决裁剪域偏移问题, 本文提出基于序列对抗域适应的智能裁剪算法(LDAIC).
将有标签的A数据集作为源域(Source), 无标签的B数据集作为目标域(Target).一幅原始图像对应若干种裁剪方式, 因此将按照规定方式裁剪后的图像作为基本样本单位, 命名为裁剪子图.设源域原始图像集合
Is={Is(0), Is(1), …, Is(k)},
每幅原始图像对应若干个裁剪子图, 裁剪子图集合
Bs={Bs(0), Bs(1), …, Bs(n)},
源域裁剪子图对应的美学标签集合
as={as(0), as(1), …, as(n)}.
设目标域原图集合
It={It(0), It(1), …, It(k)},
裁剪子图集合
Bt={Bt(0), Bt(1), …, Bt(n)},
目标域裁剪子图对应的美学标签集合
at={at(0), at(1), …, at(n)}.
在本任务中, 研究者设计算法预测目标域子图的美学分数, 并从中筛选更优的裁剪方式.问题在于:目标域标签at是缺失的, 只能利用源域裁剪子图Bs、源域美学标注as和目标域裁剪子图Bt训练算法, 再通过算法预测 Pt作为目标域子图的美学预测.另外, 设Ps作为源域子图的美学预测.
本任务的目的是减小算法在目标域上的预测误差, 即减小
${E_t}({B_t}, {a_t}) = \mathop {\mathop \sum \limits_{i = 1} }\limits^N D({P_t}(i), {a_t}(i)).$
由于目标域标签at缺失, 无法直接约束Et(Bt, at)最小, 但可使用Es(Bs, as)和dis(Is, It)衡量Et(Bt, at).Es(Bs, as)表示裁剪算法在源域上的预测误差, dis(Is, It)表示源域和目标域数据分布的差异, 即域偏移量.为了减小Et(Bt, at), 从减小Es(Bs, as)和dis(Is, It)入手, 构建LDAIC.
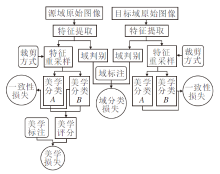
本文算法网络结构如图1所示, 主要包含特征提取器、域判别器、2个美学分类器.本文采用VGG作为特征提取器, 用于从原始图像I∈ RH× W× 3中提取全局特征F1∈
 | 图1 本文算法网络结构图Fig.1 Network structure of the proposed algorithm |
2个美学分类器构成本文算法美学评分模块, 用于预测裁剪子图的美学评分并辅助算法提取不变特征.自适应梯度反转层和域判别器构成对抗域适应模块.对抗域适应模块通过对抗域适应方法对齐源域和目标域样本的分布.
为了使算法具备裁剪任务相关的美学鉴赏能力, 减小在源域的预测误差Es(Is, as), 本文构建美学评分模块.2个不同参数的美学分类器A1、A2组成美学评分模块.本文首先根据Grid Anchor规则[17]生成预选裁剪方式并对全局特征进行重采样, 将原始图像中的裁剪区域作为前景重采样, 将原始图像中被裁剪的区域作为背景重采样.
F1和N种裁剪方式输入ROIAlign[35], 得到前景特征Ff∈ R(N× 8× 8× D1).对于背景部分, 将待裁剪区域置0并输入ROIAlign中, 得到背景特征Fb∈ R(N× 8× 8× D1).将前景特征和背景特征从通道维度叠加, 得到重采样特征F2∈ R(N× 8× 8× 2D1), F2被分别送入A1和A2.A1主要由3个卷积层和1个失活层组成.F2首先送入kernel_size=(8, 8)的卷积层, 得到F3∈ R(N× 1× 1× D2), 本文中D2=1 024.F4经过kernel_size=(1, 1)卷积层和1个失活层, 最后被送入输出维度为1, kernel_size=(1, 1)的卷积层, 得到预测结果P∈ RN× 1× 1× 1.P中第1个维度表示N种裁剪方式, 对应每种裁剪方式的预测结果.A2与A1结构相同, 此处不赘述.
将A1和A2预测结果的均值作为每种裁剪方式的美学预测分数, 并选择分数最高的前K个裁剪子图作为算法输出.本文采用源域数据集上的裁剪方式和美学标签作为监督训练模型的美学鉴赏能力.对于A1和A2, 约束其预测结果趋于一致, 并保持它们参数的独立性, 辅助提取与美学相关的不变信息.
原始图像Is(i)对应1组共N种裁剪方式, 裁剪后生成的新图像
B(i)={B1(i), B2(i), …, BN(i)},
每个裁剪区域的美学分数标签
Sc(i)={Sc1(i), Sc2(i), …, ScN(i)}.
根据图1, 输入原始图像提取特征并使用ROIAlign对预设裁剪区域进行重采样, 得到每个裁剪子图的区域特征
Fsi (i)=G(Isi (i)), j=1, 2, …, N,
其中, Isi (i)表示图Is(i)对应裁剪区域为Bj时的裁剪子图, Fsi (i)表示对应的区域特征, G表示特征提取器.
得到区域特征后, 输入A1、A2, 用于预测当前裁剪子图的美学分数, 将美学分数的平均值作为裁剪子图的美学质量预测结果, 即
ps(i)={p1(i), p2(i), …, pN(i)}.
GAIC(Grid Anchor Based Cropping)[17]采用SmoothL1作为美学损失LA, 用于约束ps(i)和Sc(i)趋于一致, SmoothL1如下所示:
${L_{smoothL1}} = \left\{ {\begin{array}{* {20}{l}}{\frac{1}{2}e{{\left( i \right)}^2}, }& {\left| {e\left( i \right)} \right| \le \delta } \\ {\delta \left| {e\left( i \right)} \right| - \frac{1}{2}{\delta ^2}, }& {\left| {e\left( i \right)} \right| > \delta }\end{array}} \right.$
其中, e(i)=ps(i)-sc(i)表示预测值与美学标签之间的误差, δ =0.5.
但在SmoothL1的计算过程里, 所有裁剪子图都具有相同权重, 这与任务目标不符.在智能裁剪任务中, 用户只需要得到高质量的裁剪结果, 不关心算法对低质量裁剪结果预测的精确度.因此, Listwise-Loss[36]通过非线性归一化的策略放大高质量裁剪子图的权重.
ListwiseLoss计算如下:
$\begin{aligned} & S c^{\prime}(j)=\prod_{j=1}^{n} \frac{\Phi\left(s c_{j}\right)}{\sum_{k=1}^{n} \Phi\left(s c_{k}\right)}, \Phi(x)=e^{x} ; \\ & P^{\prime}(j)=\prod_{j=1}^{n} \frac{\Phi\left(f\left(I^{j}\right)\right)}{\sum_{k=1}^{n} \Phi\left(f\left(I^{k}\right)\right)}, \Phi(x)=e^{x} ; \\ & L_{\text {listwise }}=-\sum_{i=1}^{m} \sum_{j=1}^{n} S c^{\prime}(j) \ln \left(P^{\prime}(j)\right) . \end{aligned}$ (1)
其中, Sc表示原始标签, Sc'表示归一化后的标签, f表示预测函数, P'表示归一化后的预测值.
本文结合SmoothL1和ListwiseLoss, 作为美学损失函数, 命名为ScalingSmoothL1.该损失按照式(1)中的归一化方法处理标签Sc和预测值P, 将归一化后的Sc'和P'分别作为标签和预测值代入SmoothL1中计算损失, 即
${L_A} = \left\{ {\begin{array}{* {20}{l}}{\frac{1}{2}{{({X_{{\rm{dis}}}})}^2}, }& {\left| {{X_{{\rm{dis}}}}} \right| \le 1} \\ {\left| {{X_{{\rm{dis}}}}} \right| - \frac{1}{2}, }& {\left| {{X_{{\rm{dis}}}}} \right| > 1}\end{array}} \right.$
其中
${X_{dis}} = \frac{{{e^{Sc\left( i \right)}}}}{{\mathop {\mathop \sum \limits_{j = 1} }\limits^n {e^{Sc\left( i \right)}}}} - \frac{{{e^{p\left( i \right)}}}}{{\mathop {\mathop \sum \limits_{j = 1} }\limits^n {e^{p\left( i \right)}}}}, $
表示归一化后的预测值与美学标签之间的误差.
通过上述方法, 可让p(i)趋近真实值Sc(i), 使算法学习到美学鉴赏能力.而通过上述的非线性映射方法, 也可将网络的关注点向高质量裁剪子图倾斜, 避免算法耗费过多资源拟合低质量裁剪子图.在测试阶段, 裁剪算法根据p(i)筛选裁剪子图, 并输出裁剪结果.
除此之外, 本文算法采用2个结构相同参数不同的美学分类器构建美学评分模块.相比单美学分类器的方法, 2个参数不同的美学分类器有利于算法提取美学不变特征.参数不同的美学分类器是从不同角度分析当前子图, 如果预测结果趋于一致并与美学标签吻合, 说明算法提取到的特征含有更多的美学信息, 不易受到分类器的影响.这种不受分类器限制、被输入到不同美学分类器都能得到正确且相似预测结果的特征, 称为美学不变特征.美学不变特征更关注图像的美学内容, 提高算法的美学鉴赏能力, 增强算法的鲁棒性.
为了制造2个有差异的美学分类器, 本文通过权重损失约束分类器参数, 降低2个美学分类器参数的相似度.首先将每个分类器的参数都编码为一个参数矩阵, 再最大化分类器参数之间的余弦距离, 避免分类器在训练过程中趋同, 称为权重损失Lw.设2个分类器A1、A2, W1为A1参数矩阵, W2为A2参数矩阵, 权重损失
$\begin{array}{r} L_{w}\left(\boldsymbol{W}_{1}, \boldsymbol{W}_{2}\right)=-\left(1-\cos \left\langle\boldsymbol{W}_{1}, \boldsymbol{W}_{2}\right\rangle\right)= \\ \frac{\sum_{i=1}^{n} W_{1 i} W_{2 i}}{\sqrt{\sum_{i=1}^{n} W_{1 i}^{2}} \sqrt{\sum_{i=1}^{n} W_{2 i}^{2}}}-1 \end{array}$.(2)
当A1、A2分类面相近时, Lw(W1, W2)偏大, 最小化Lw(W1, W2)可使W1与W2相似度减小.由于A1、A2只是具体参数不一样, 结构和参数规模都是相同的, 因此可直接代入式(2)计算.
同时, 本文约束A1、A2对相同数据预测相同的结果.输入一幅图像I(i)和k个预设的裁剪方式
B(i)={B1(i), B2(i), …, Bk(i)},
A1预测结果向量P1(i)∈ Rk× 1, A2同样预测结果向量P2(i)∈ Rk× 1, 采用一致性损失Lc优化算法, 使2个分类器预测结果趋于一致, 即
$L_{c}=\frac{1}{n} \sum_{i=1}^{n}\left|\boldsymbol{P}_{1}(i)-\boldsymbol{P}_{2}(i)\right|$.
为了减少源域和目标域之间的数据分布差异dis(Is, It), 本文设计对抗域适应模块, 用于解决这一问题.对抗域适应模块包含一个自适应梯度反转层和一个域判别器.全局特征F1作为该模块的输入被送入自适应梯度反转层, 在正向传播中, 自适应梯度反转层为恒等变换, 输出F1并作为域判别器的输入.域判别器首先通过一个全图ROIAlign对F1进行重采样, 得到F4∈ R(8× 8× D1).F4经过一个kernel_size=(8, 8)的卷积层、1个全连接层和1个softmax, 得到域判别器预测结果Pdomian∈ R1× 2, Pdomian表示当前图像隶属于某个域的置信度.
在反向传播的过程中, 自适应梯度反转层会将目标域样本的梯度反转, 域判别器会判别当前样本隶属的域.当输入样本来自目标域时, 自适应梯度反转层会将梯度反转, 导致域判别器与特征提取器接收到相反方向的梯度.因此, 在域判别器学习判别能力的同时, 特征提取器也在强化混淆两个域特征的能力, 两者形成对抗, 让目标域样本的特征分布与源域样本的特征分布对齐.
2个不同分布之间的差异可采用散度衡量.这里使用F表示当前图像提取的特征向量, Fs表示源域特征, Ft表示目标域特征.Ddomain表示域判别器.设源域样本标签为0, 目标域样本标签为1, 设H表示所有可行的Ddomain参数构成的集合, 源域和目标域之间分布的差异表示如下:
${d_H} = 2(1 - \mathop {{\rm{min}}}\limits_{{D_{{\rm{domain}}}} \in H} (err({D_{domain}}({F_s})) + err(D{d_{omain(}}F{t_)})))$
其中, err(Ddomain(Fs)))表示源域样本的误分率, err(Ddomain(Ft)))表示目标域样本的误分率, dH表示两个域分布的差异.随着样本误分率的提高, dH变小, 因为域判别器更难区分这两个域, 说明它们之间的特征相似度更高.
本文将全局特征F1=G(I)输入域判别器中, 约束dH, 使两个分布之间的差异dH最小, 即
$\mathop {{\rm{min}}}\limits_G {d_H} \leftrightarrow \mathop {{\rm{max}}}\limits_G \mathop {{\rm{min}}}\limits_{{D_{{\rm{domain}}}} \in H} (err({D_{domain}}({F_s})) + err(D{d_{omain(}}F{t_)})).$
具体到算法结构, 本文用自适应梯度反转层优化上式.自适应梯度反转层是梯度反转层(Gradient Reversal Layer, GRL)[31]的变形, 梯度反转层会在算法反向传播梯度时, 将梯度反转, 前向传播和反向传播
Rλ (x)=x,
$\frac{{\partial {R_\lambda }}}{{\partial x}} = - \lambda \frac{{\partial {L_d}}}{{\partial x}}, $
其中, Rλ (x)表示输入为x时正向传播的结果, $\frac{{\partial {L_d}}}{{\partial x}}$表示反向传播计算出的梯度.GRL在正向传播时为恒等变换, 反向传播时, GRL将计算的梯度乘-λ 后传回上一层网络, 本文设置λ =0.3.
本文采用二分类交叉熵作为判别器损失:
Ld=-[y'ln(Ddomain(F))+(1-y')ln(1-(Ddomain(F)))].
其中:y'表示输入图像I对应的域标签, 当I来自源域时y'=0, 当I来自目标域时y'=1; Ddomain(F)表示域判别器的输出结果, 在经过softmax归一化后数值介于0和1之间.
采用GRL可初步对齐源域和目标域样本特征, 但GRL会同时反转源域样本和目标域样本的梯度, 导致特征提取器实际按照
Ddomain(Fs)=1, Ddomain(Ft)=0
的方向优化, 这与本文算法混淆源域和目标域样本特征的策略不符.而本文采用自适应梯度反转层只反转目标域样本的梯度, 不改变源域样本的梯度, 反向传播公式如下:
$\frac{{\partial {R_s}}}{{\partial x}}=\frac{{\partial {L_s}}}{{\partial x}}, \frac{{\partial {R_t}}}{{\partial x}} = - \lambda \frac{{\partial {L_t}}}{{\partial x}}.$
当输入样本来自目标域时, 特征提取器G和域判别器Ddomain会按照相反的方向优化, 在域判别器学习判别能力的同时, 特征提取器会生成混淆2个域数据的样本特征, 特征提取器和域判别器形成对抗.当输入样本来自源域时, 特征提取器G和域判别器Ddomain会按照相同的方向优化, 特征提取器与域判别器不会产生对抗.按照这种方式, 域判别器的优化方向为
Ddomain(Fs)=0, Ddomain(Ft)=1,
而特征提取器的优化方向为
Ddomain(Fs)=0, Ddomain(Ft)=0,
此时特征提取器将两个域的样本视为相同类别进行优化, 与域判别器形成对抗, 克服GRL的缺陷, 对齐两个域的特征分布.
综合上述内容, 本文算法是一个端到端模型, 并采用多任务损失综合优化.在训练阶段, 一组源域-目标域图像对, 包含一幅源域原始图像和一幅目标域原始图像, 作为单次迭代的样本送入算法.源域样本对应的美学标签和域标签会同时计算美学损失LA(采用ScalingSmoothL1)、一致性损失Lc、权重损失Lw和判别器损失Ld.而目标域样本只有域标签, LA=0, 计算Ld、Lc、Lw.计算一组源域-目标域图像对的总损失:
L=LA+λ 1Ld+λ 2(Lc+μ Lw), (11)
其中, λ 1、λ 2、 μ 均为折衷参数, 用于平衡4种损失.本文设定λ 1=0.2, λ 2=0.5, μ =0.2.在训练阶段, 特征提取器、美学评分及域判别器都会参与训练.而在推理阶段, 输入图像经过特征提取和美学评分, 预测当前裁剪区域的美学分数, 而后根据分数筛选裁剪结果.
本文采用在ImageNet上预训练过的参数来初始化算法.整个算法通过自适应矩估计(Adaptive Moment Estimation, Adam)优化器学习参数.在最初的30个迭代周期里, 采用L=LA优化网络, 使网络具有基本的美学鉴赏能力.在之后的10个迭代周期里, 固定域判别器之外的所有参数, 使用L=λ 1Ld训练域判别器参数, 使域判别器能判别源域和目标域样本.之后解除所有参数的固定, 使用
L=LA+λ 1Ld+λ 2(Lc+μ Lw)
优化整个网络, 整个过程包括60个迭代周期, 学习率为10-4, 输入原图的批尺寸大小设为1.
最后得到本文算法流程图如图2所示.
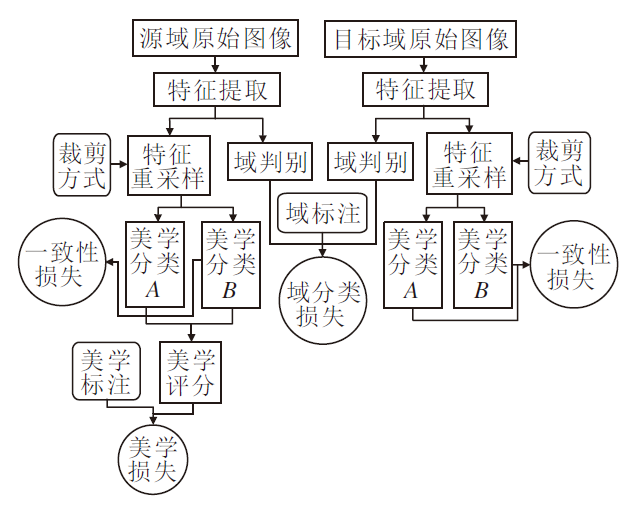 | 图2 本文算法流程图Fig.2 Flow chart of the proposed algorithm |
本文在实验过程中需要变换源域和目标域, 训练集和测试集也会随之变化, 涉及到的数据集主要有CPC[16]、GAICD[17]、INDOOR、OUTDOOR.
CPC、GAICD数据集具体信息见第2节.INDOOR和OUTDOOR是本文在GAICD、CPC数据集基础上建立的跨域数据集.INDOOR包含4 867幅室内场景图, OUTDOOR包含7 172幅室外场景图, INDOOR、OUTDOOR数据集上的12 039幅图像和美学标注均来自GAICD、CPC数据集.INDOOR、OUTDOOR数据集按照原始图像的场景域分类, 本文通过文献[37]的场景识别方法将其分为室内/室外两类, 分别归纳到INDOOR、OUTDOOR数据集.INDOOR训练集包含3 936幅图像, 测试集包含931幅图像.OUTDOOR训练集包含5 703幅图像, 测试集包含1 469幅图像, 比例约为4∶ 1.
评估指标仍采用SRCC和Acc5、Acc10, 具体见第2节.
为了验证算法的跨域自动裁剪能力, 实验包含源域、目标域两类数据集.源域训练集的样本既包含原始图像也包含美学标注, 而目标域训练集只包含原始图像不包含美学标注.测试集同时具有原始图像和美学标注.因此, 本文主要设计4个实验, 分别是:基准方案选取实验、CPC↔ GAICD域迁移实验、INDOOR↔ OUTDOOR域迁移实验、消融实验.最后给出可视化结果.
首先确定基准方案.将CPC→ GAICD的裁剪性能作为基准方案的筛选条件.这里将源域为CPC、目标域为GAICD的域迁移实验简写为CPC→ GAICD, 后文沿用该表达方式.针对算法的特征提取器结构和损失函数, 设置如下两组实验, 对特征提取器结构和美学损失函数进行优选.
实验3 特征提取器结构优选
本文按照文献[17]将GAICD数据集上1 036幅图像作为训练集, 200幅图像作为测试集.CPC数据集上随机选取7 559幅图像作为训练集, 剩下的3 238幅图像作为测试集.
实验中需要使用CPC训练集和GAICD测试集.对比4种现有智能裁剪算法用到的特征提取器结构:VGG、ResNet50(Residual Network 50)、Mobile-Net、shuffleNet.结果如表2所示.由表可见, VGG的效果略优于ResNet50.其实学者们已验证VGG在同域有监督的智能裁剪任务中是效果较优的特征提取器结构[8, 17, 32].实验3进一步验证在CPC→ GAICD域迁移的过程中VGG也能取得较优效果.VGG能在智能裁剪任务中取得较优效果可能得益于较少的数据量.相比ResNet这种深层网络, VGG的层数较少, 裁剪任务的训练集, 如GAICD数据集, 只包含约千幅原始图像, 深层网络极易过拟合于训练集, 影响裁剪算法在其它数据域上的泛化能力.因此, 本文算法在后续实验中采用VGG作为特征提取器的结构.
| 表2 不同特征提取器对CPC→ GAICD的影响 Table 2 Effect of different feature extractors on CPC→ GAICD |
实验4 美学损失函数优选
在美学损失函数方面, 对比文献[17]采用的smoothL1、文献[36]采用的Listwise Loss和本文采用的ScalingSmoothL1, 结果如表3所示.
| 表3 不同损失函数对CPC→ GAICD的影响 Table 3 Effect of different loss functions on CPC→ GAICD |
由表3可见, ScalingSmoothL1在SRCC指标上具有显著优势, 通过非线性函数适当放大高质量区域之间的评分差异, 压缩低质量区域之间的评分差异, 这有助于提升算法的裁剪能力.
在本次实验中, 对比CPC→ GAICD和GAICD→ CPC时LDAIC、基准方案及其它现有跨域裁剪算法的性能.
实验5 CPC↔ GAICD域迁移实验
按照3.1节的数据集划分, 在CPC→ GAICD域迁移实验中, 涉及的数据包括:有标签的CPC训练集样本、无标签的GAICD训练集样本和有标签的GAICD测试集样本.在训练LDAIC时, 批尺寸大小为1, 一个迭代周期包括1 036次迭代.按照设置, 一个迭代周期只包含1 036个源域/目标域图像对, 但实验中设置shuffle=True, 随着迭代的进行, CPC训练集上7 559幅图像样本都会参与训练.
按照3.1节的数据集划分, GAICD→ CPC域迁移实验中涉及的数据包括:有标签的GAICD训练集样本、无标签的CPC训练集样本和有标签的CPC测试集样本.同样设置shuffle=True, 一个迭代周期迭代1 036次.
选择本文能复现结果或能找到跨域情况下测试结果的现有智能裁剪算法:GAIC[17]、VFN(View Finding Network)[19]、A2-RL(Aesthetics Aware Rein-forcement Learning)[20], 结果如表4所示, 表中黑体数字表示最优结果.
| 表4 各方法在GAICD↔ CPC上的结果 Table 4 Results of different methods on GAICD↔ CPC |
由表4可见, 本文算法在Acc5和Acc10上有显著优势.VFN在SRCC指标上表现更优, 但相对Acc指标而言, SRCC指标考虑低质量区域之间的关系, 对裁剪结果的影响较小.这说明本文算法在跨域情况下更容易找到高质量的裁剪区域.另外, 由于A2-RL只会生成一个最好的裁剪子图, 只能计算Acc1/5和Acc1/10, 而
Acc1/5> Acc5, Acc1/10> Acc10,
本文将Acc1/5和Acc1/10作为Acc5和Acc10的上界.
为了进一步探究GAICD、CPC数据集之间分布的差异, 采用文献[37]的场景识别方法对GAICD、CPC数据集进行分析, 将所有数据分为室内/室外两类.实验结果显示:GAICD数据集上图像室外场景占89%, 室内场景占11%; CPC数据集图像室外场景占53%, 室内场景占47%.这或许能从图像层面上解释2个数据集之间存在的图像分布差异.于是本文将室内场景(INDOOR)和室外场景(OUTDOOR)交替作为源域和目标域, 验证算法性能.
实验6 INDOOR↔ OUTDOOR域迁移实验
按照3.1节描述, 本文将GAICD、CPC数据集上的数据分成室内/室外两类, 分别命名为INDOOR、OUTDOOR数据集, 并在其上进行基准方案和本文算法的对比实验.参照CPC→ GAICD的实验设置, 每个批次的迭代次数由2个数据集上训练集较小的那个决定, 本次实验设置为3 936次.为了避免随机误差造成的影响, 选取随机种子{0, 10, 100, 1000, 10000}进行实验, 并取平均值作为实验结果, 具体如表5所示.由表可见, 相比基准方案, 本文算法在各指标上均有小幅提升, Acc指标提升较显著.
| 表5 各方法在INDOOR↔ OUTDOOR上的结果 Table 5 Results of different methods on INDOOR↔ OUTDOOR |
为了验证本文算法中两个域适应策略的有效性, 实验设置CPC→ GAICD作为迁移域, 在固定算法结构的情况下, 针对损失函数设计一组消融实验.
本次实验旨在验证两个域适应策略的有效性, 包括4种方案.4种方案均采用2.2节中的结构.方案1为本文基准方案, 将美学损失LA作为损失函数优化算法, 不采用任何域适应策略约束模型, 是实验的对照组.方案2将LA+λ 1Ld作为损失函数优化算法, 利用域判别器, 验证对抗域适应策略的有效性.方案3将LA+λ 2(Lc+μ Lw)作为损失函数优化算法, 验证本文美学不变特征的有效性.方案4将L3作为损失函数, 为本文算法.
各方案的消融实验结果如表6所示.由表可知, 相比方案1, 方案2性能有一定提升, 对抗域适应策略即使被单独添加到算法中也能提升裁剪算法在目标域的泛化能力, 而方案3的美学不变特征策略在单独作用的情况下对算法性能提升较小.但方案4(本文算法)将对抗域适应策略和美学不变特征策略结合后, 性能得到显著提升, 这验证域适应策略的有效性.
| 表6 不同方案的消融实验结果 Table 6 Results of different ablation experiment schemes |
对于方案3, 本文认为源域和目标域的图像数据差异过大, 仅设置2个参数不同的美学分类器很难约束算法提取到适用于目标域样本的美学不变特征, 算法可能被源域数据过拟合.但结合对抗域适应策略后, 2个域样本特征的边缘分布被对齐, 2个参数不同的美学分类器能更好地利用无标签的目标域图像, 提取美学不变特征.此时的特征提取器一边学习混淆域判别器的能力, 一边从源域向目标域传递其学到的美学鉴赏能力, 最终在跨域的智能裁剪任务上达到更优效果.
为了更直观地体现本文算法效果, 展示本文算法的裁剪结果和特征分布, 各对比算法的裁剪结果由图3给出.
 | 图3 各算法的裁剪结果对比Fig.3 Comparison of cropping results of different algorithms |
由图3可看出, 本文算法能有效适应各种不同场合, 裁剪后的图像包含原始图像的显著区域, 并且显著目标处在裁剪图约三分之一处, 满足摄像构图中的三分法原理.而其它算法的裁剪结果虽然也能将原图显著区域包含在内, 但显著目标所在的位置会导致裁剪图不够美观.
本文提出基于序列对抗域适应的智能裁剪算法.在不需要目标域美学标签的情况下, 仅依靠源域数据和部分无标注的目标域图像实现跨域的智能裁剪学习.建立一个端到端的卷积神经网络模型, 主要包含美学评分模块和对抗域适应模块.最后通过实验验证本文算法在跨数据集、跨场景域时的有效性.值得关注的是, 本文结果依然与有监督情况下的智能裁剪结果有较大差距, 今后将考虑进一步挖掘与图像裁剪相关的不变特征, 提升无监督情况下的智能裁剪算法的性能.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|