
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于异构邻域聚合的协同过滤推荐算法
[夏鸿斌1, 2  , 陆炜
, 陆炜1 , 刘渊1, 2 ]
, 陆炜, 刘渊]
|
|



作者简介:

陆 炜,硕士研究生,主要研究方向为深度学习、推荐系统.E-mail:1051183356@qq.com.

刘 渊,硕士,教授,主要研究方向为网络安全、社交网络.E-mail:lyuan1800@sina.com.
About Author:
LU Wei, master student. His research interests include deep learning and recommendation system.
LIU Yuan, master, professor. His research interests include network security and social network.
传统的协同过滤算法使用one-hot编码生成的特征向量信息量稀少,对异构行为数据仅挖掘不同行为间的联系而忽略用户间行为的联系.针对上述问题,文中提出基于异构邻域聚合的协同过滤推荐算法.首先,使用图对用户和项目的异构交互进行建模,并利用图的连通特性构建邻域.然后,使用轻量级图卷积方法整合邻域信息,融入目标用户和目标项目的特征向量.最后,将融合邻域信息的用户与项目的特征向量输入多任务异构网络进行训练,通过丰富特征向量信息的方法缓解数据稀疏问题.在数据集上的实验证实文中算法的性能较优.
In traditional collaborative filtering models, the feature vector generated by one-hot encoding is sparsely informative. Heterogeneous behavior data is only employed to describe the relationship between different behaviors and the relationship between behaviors of different users is ignored.Aiming at these problems, an algorithm of collaborative filtering with heterogeneous neighborhood aggregation is proposed. Firstly, the heterogeneous interaction between users and items is modeled by the graph, and neighborhoods are built through the connectivity of graph. Then, the neighborhood information integrated by the lightweight graph convolution method is merged into the feature vectors of the target users and items. Finally, the feature vectors of users and items integrating with neighborhood information are input into a multi-task heterogeneous network for training. The problem of data sparseness is alleviated by enriching the hidden information of feature vectors. Experiments on the datasets prove that the performance of the proposed model is better.
本文责任编委 马少平
Recommended by Associate Editor MA Shaoping
推荐系统作为一种高效的信息过滤工具, 在每天产出海量信息的当下已成为生活的必需品.为用户推荐符合用户需求、心意的项目是推荐系统的最终目标, 所以个性化推荐的核心是如何精准获取用户的兴趣, 从而预测用户对于项目的偏好.
目前, 主流的推荐算法主要分为三类:基于内容的推荐算法、协同过滤推荐算法和混合推荐算法[1].最经典是协同过滤推荐算法[2], 它通过用户的历史行为分析用户偏好, 建模用户特征, 为用户推荐感兴趣的项目.根据不同的交互数据利用方式, 协同过滤又可分为基于用户的协同过滤、基于项目的协同过滤、基于模型的协同过滤[3].由于协同过滤需要使用用户的历史行为数据, 而这类数据相对于项目数量往往很少, 因此协同过滤容易受制于数据稀疏问题.
在基于模型的协同过滤中, 用户和项目特征向量中包含的信息量是决定效率的重要因素.早期, 基于模型的协同过滤主要使用的模型为矩阵分解(Matrix Factorization, MF)[4], 通过将用户和项目的ID升维以得到特征向量, 并通过内积表示用户和项目的交互.近年来, 由于机器学习及深度学习技术的快速发展, 推荐领域也逐渐开始使用神经网络挖掘用户与项目间的隐含关联, 如融合多层感知器(Multilayer Perception, MLP)的神经协同过滤模型(Neural Collaborative Filtering, NCF)[5]和协同记忆网络模型(Collaborative Memory Network, CMN)[6], 但仍采取与矩阵分解相同的方式生成特征向量, 这种方式将用户-项目对视为独立的个体, 忽略用户和项目间的关联.基于项目相似度的因子分解模型(Factored Item Similarity Models, FISM)[7]、基于注意力的协同过滤模型(Attentive Collaborative Fil-tering, ACF)[8]、基于记忆增强图网络的序列推荐模型(Memory Augmented Graph Neural Networks, MA-GNN)[9]将用户的历史交互记录视为用户特征, 通过基于注意力的方法将其融入用户特征向量.
近来, 由于用户-项目交互数据对二分图结构(Binary Graph)天然的适应性及计算力的提升, 基于图神经网络的推荐模型越来越受到关注.Qu等[10]提出邻域交互的概念, 将用户项目交互通过图扩展为邻域与邻域的交互.Wang等[11]提出神经图协同过滤模型(Neural Graph Collaborative Filtering, NGCF), 将图卷积的方法应用在推荐中, 通过图网络结点连通的特性, 获取高阶的协同信息, 并融入目标用户/项目的特征向量中.He等[12]提出轻量化图卷积模型(Simplifying and Powering Graph Convolu-tion Network for Recommendation, LightGCN), 针对推荐任务特征较少的特点, 对NGCF进行精简优化, 提升训练效率.但是, 基于网络的模型容易受采样策略的影响, 根据训练过程中抽样的不同, 得出的实验结果往往会有波动.
另一方面, 一些学者引入辅助信息, 缓解数据稀疏问题, 如用户评论、项目简介等文本信息[13]或隐式交互信息[14].Zhao等[15]提出基于联合行为的矩阵分解模型(Combined Behavior Matrix Factorization, CBMF), 分别为每类用户行为构建交互矩阵, 通过矩阵分解方法训练并优化用户与项目的隐向量, 最终融合各行为交互矩阵中得到的隐向量, 得到用户与项目的特征.Gao等[16]提出基于多行为数据的神经多任务推荐模型(Neural Multi-task Recommenda-tion, NMTR), 融合网络模型与多任务学习, 应用于用户异构行为.Chen等[17]认为用户的异构行为具有关联性, 通过构建异构行为的关联预测提升推荐精度, 通过全采样改善推荐稳定性, 但对于异构行为数据只挖掘行为间的联系而忽略用户间行为的联系.
为了充分利用用户的异构行为信息缓解数据稀疏带来的推荐性能问题, 在高效异构协同过滤模型(Efficient Heterogeneous Collaborative Filtering, EHCF)的基础上, 结合图神经网络(Graph Neural Network, GNN)连通结点的特性, 本文提出基于异构邻域聚合的协同过滤推荐算法(Collaborative Filtering with Heterogeneous Neighborhood Aggregation, HNACF).首先通过用户-项目二分图构建邻域, 对每个结点的用户/项目的ID进行升维, 生成包含ID信息的特征向量.再通过图卷积网络(Graph Convolutional Network, GCN)聚合邻域, 将目标结点高阶邻域中结点的异构行为信息融入目标向量, 丰富特征空间中所含信息.然后, 将融合邻域信息的用户/项目特征向量输入行为关联层, 提取用户行为的内在联系.最后, 将行为关联层的输出输入多任务学习模块, 对每个行为进行单独训练, 为每个行为的权重进行分配, 得到最终的训练结果.
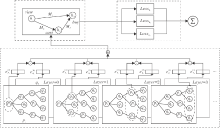
本文提出基于异构邻域聚合的协同过滤推荐算法(HNACF), 结构如图1所示.算法分为基于图网络的异构邻域聚合、基于异构数据的协同过滤和多任务学习三部分.
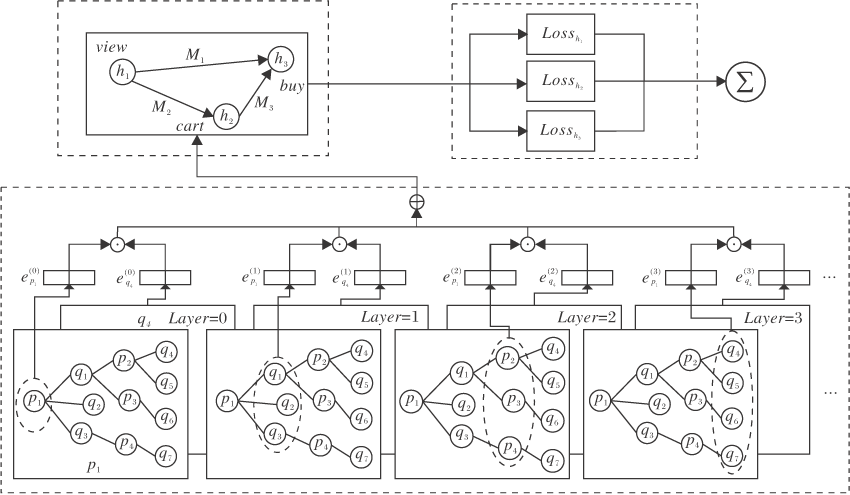 | 图1 HNACF框图Fig.1 Framework of HNACF |
1.1.1 用户-项目的二分图构建
在图G=(V, E)中, 将G中的顶点V划分为2个不相交的集合A, B, 若G中的每条边E的其中一个顶点属于A, 另一个顶点属于B, 这样的图称为二分图.
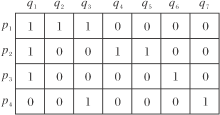
给定Np个用户构成的用户集U, Nq个项目构成项目集I, 用户和项目的交互矩阵[18]为
R(pi, qj)=
对应交互矩阵如图2所示.
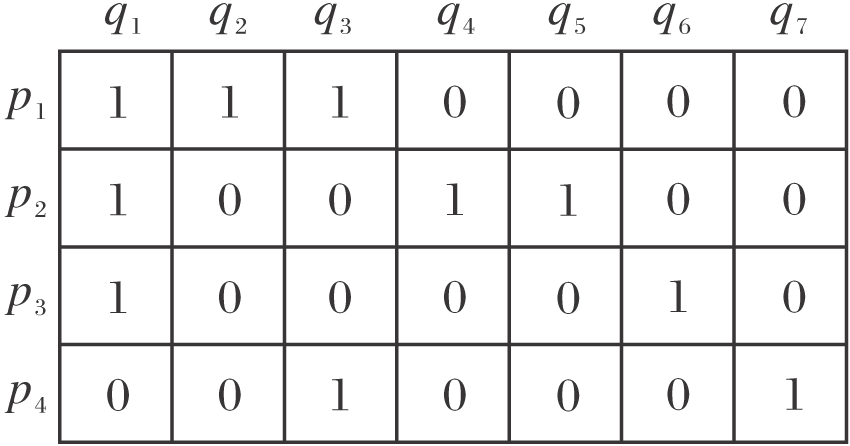 | 图2 用户-项目的交互矩阵Fig.2 Matrix of user-item interaction |
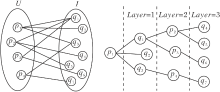
对于每对交互R(pi, qj)=1, 均有pi∈ U, qj∈ I, 因此以用户与项目作为节点, 用户项目交互作为边的图是天然的二分图G[19], 根据图2构建的用户-项目二分图如图3左图所示.
 | 图3 用户-项目的二分图Fig.3 Binary graph of user-item |
1.1.2 基于图的邻域构建
在用户和项目交互构成的二分图G中, 对于目标用户pi∈ U, 所有与其存在交互的项目q构成的集合称为pi的一阶邻域:
类似地, 对于目标项目qj∈ I, 所有与其存在交互的用户p构成的集合称为qj的一阶邻域:
由一阶邻域扩展得到高阶邻域.以用户的二阶邻域为例:对于
1.1.3 神经图协同过滤的协同信号传播
在传统的协同过滤算法中, 一般采用one-hot编码[5, 6]或矩阵分解[4]的方式对用户和项目进行特征提取.两种方式只利用目标用户和目标项目本身的信息及它们之间的交互, 而且这些信息在用户项目交互矩阵高稀疏度的背景下, 发挥的效果有限.
对于目标用户p及其一阶邻域中的项目q, (p, q)这一用户项目对中的信息表达为
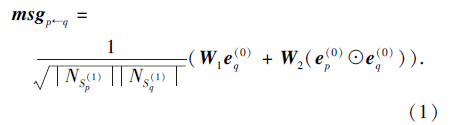
其中:
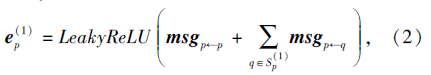
其中
根据已构建的邻域, 对其中的任意用户或项目都可进行一阶邻域聚合.以项目q∈
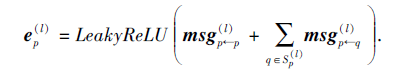
其中, 用户-项目对信息的表达如下:

其中,
项目部分的邻域聚合仅需将用户与项目向量进行互换即可得到, 因此不作赘述.
最终将各阶邻域的特征向量进行拼接得到目标用户/项目的特征向量;
e=e(0)‖ e(1)‖ …‖ e(l),
其中‖ 为拼接符号.
1.1.4 轻量级图卷积模型的邻域聚合
本文参考He等[12]提出的LightGCN, 对用户的异构行为数据进行邻域信息聚合.LightGCN是对NGCF的优化, 根据推荐任务特征较少、特征维度较低的特点, 删除GCN[20]中的特征转换与非线性激活的步骤, 获得更快的训练速度和更少的资源消耗.
GCN或者说神经网络的一大特点就是可通过权值W和偏执b将数据的原有特征转换为新的特征, 即将原向量映射到新的向量空间, 以此挖掘数据在原向量空间中无法发现的关联.
GCN的另一大特点是非线性激活.通过激活函数(如NGCF使用sigmoid函数), 原来的线性特征转换为非线性特征, 提高模型的特征表达能力.
在半监督或无监督的训练任务中[21], 结点一般存在丰富的语义信息.然而在协同过滤中, 结点的输入只有ID及其交互, 不包含任何具体的语义信息.GCN的特征转换与非线性激活操作对协同过滤的效果产生阻碍, 于是对NGCF结构进行优化.
首先, 对于目标用户p的一阶邻域聚合式(1), 去除其中的特征转换操作:
msgp← q=
将上式代入式(2)并去除非线性激活函数, 得到LightGCN的一阶邻域聚合算法:
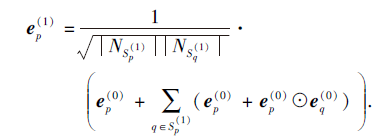
如果使
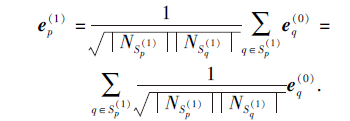
通过上式将一阶邻域扩展到高阶邻域, 对于高阶的信息聚合式(3), 同样采取去除特征转换和去除目标结点本身信息的方法, 得到简化后的高阶邻域聚合算法:
最终得到LightGCN的邻域聚合向量:
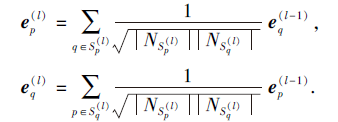
由于LightGCN删除NGCF的邻域卷积中的自结点聚合, 在生成最终的结点特征向量时, 采用加和的方式融合目标结点信息与邻域结点信息:
e=e(0)+e(1)+…+e(l)=
最终邻域聚合层的输出仍采用用户与项目特征向量的哈达玛积的形式:
epq=ep☉eq.
1.1.5 异构邻域聚合
用户除了主行为数据之外, 通常还有大量的辅助行为数据.例如在电商系统中, 用户的主行为体现为购买, 辅助行为体现为浏览与加入购物车.购买是决定推荐的主要因素, 但是浏览与加入购物车同样也表现出用户对商品的兴趣.
对用户的异构行为数据分别进行邻域聚合, 得到用户关于不同行为的特征向量:
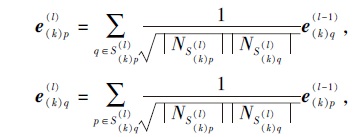
其中,
本文参考Chen等[17]的方法, 通过行为关联预测、全采样、多任务学习优化模型参数.
1.2.1 异构用户行为的关联预测
在异构数据的训练任务中, 通常将用户的不同行为单独进行训练[22], 但在现实生活中用户的不同行为中存在隐含的关联关系.为了捕获行为之间的关联, Chen等[17]在预测层中加入特征变换步骤:
其中, Wtk∈ Rd× d表示将行为t的向量空间映射到行为k的空间向量的变换矩阵, d表示特征维度, bt∈ Rd表示用户行为t的预测层权值, rtk∈ Rd表示偏执.关于行为k的预测层权值由所有行为与行为k的关联组成:
bk=
最终的关于行为k的预测层输出为
M(k)pq=
1.2.2 基于异构数据的全采样高效优化方法
在协同过滤中, 交互数据稀疏是导致算法鲁棒性较差的重要原因之一.许多算法采用随机抽取未观察到的用户-项目交互作为负样本对算法进行训练[5, 10, 23], 这直接导致实验结果剧烈波动.Chen等[17]提出基于全采样的损失函数, 并改进损失函数提升训练效率.关于用户行为k的损失函数表示如下:
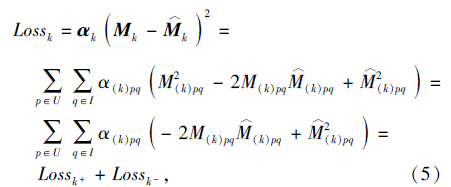
其中, Mk表示用户行为k的交互矩阵, α k表示使用Mk的权值矩阵, Los
如1.1.2节所述, 不可见的用户-项目交互一般使用0(Mpq=0)表示, 所以负样本的损失函数可简化为
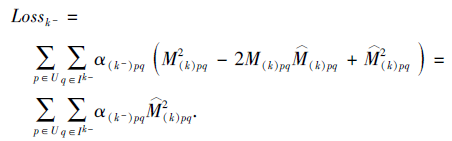
将上式代入式(5), 变换后得到损失函数的变形:
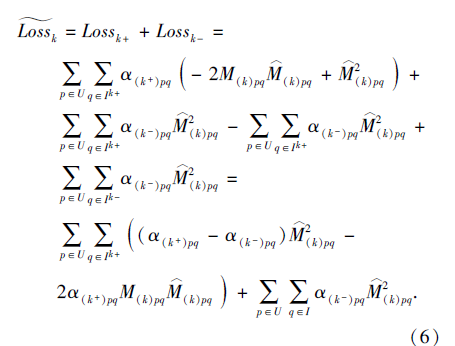
此时的损失函数为两部分加和, 时间复杂度的优化瓶颈转移到后半部分.由于此处的预测交互矩阵M仅是在聚合层输出式(4)的基础上乘上一个异构行为权值, 所以对于式(6)中
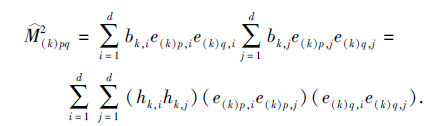
又因为负样本的权值

此时, 损失函数的时间复杂度为
O((|U|+|I|)d2).
多任务学习可优化不同的用户行为, 损失函数如下所示:
L(Θ )=
其中, K表示用户异构行为的种类数,
为了验证HNACF的性能, 采用Tensorflow框架, 在Windows 10 64位操作系统, PyCharm 2019, Intel(R) Core(TM) i5-8300H CPU @2.30 GHz, 32 GB内存, RTX 2060 GPU, Python 3.7的环境下进行对比实验.
本文使用MovieLens-1m[25]、Taobao[26]、Beibei[27]数据集作为实验数据集.MovieLens-1m数据集仅有单行为的数据, Taobao、Beibei数据集包含多行为异构数据(包括浏览、加入购物车、购买).3个数据集的基本信息如表1所示.
| 表1 数据集基本信息 Table 1 Basic information of datasets |
本文采用推荐系统模型中常用的衡量top-k任务的命中率(Hit Ratio, HR)和归一化折损累计增益(Normalized Discounted Cumulative Gain, NDCG)两个评价指标进行性能评价.HR强调推荐的准确性, 定义如下:

其中, N表示用户数量, R(i)@K表示有K个推荐项的推荐列表, T(i)表示用户真实感兴趣的项目列表.
NDCG强调推荐列表中的项目顺序, 定义如下:
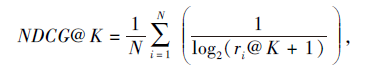
其中ri@K表示第i个用户的真实交互项目在K项推荐列表中的位置.
由于实验数据集分为单一行为数据与异构行为数据两类, 为了验证HNACF的性能, 也选用两类算法进行对比.对单一行为建模的对比算法如下.
1)基于贝叶斯的个性化推荐(Bayesian Persona-lized Ranking, BPR)[4].基于正负样本对的残差优化参数的经典推荐算法, 通过抽样方法得到正负样本对.
2)基于用户曝光的矩阵分解模型(Exposure Matrix Factorization, ExpoMF)[24].基于矩阵分解的全采样方法, 将所有未观察到的用户项目对作为负样本进行采样.
3)NCF[5].融合神经网络和矩阵分解的经典协同过滤推荐算法, 通过神经网络挖掘用户和项目间的非线性关联, 提升算法性能.
4)基于单一数据的高效异构协同过滤推荐(EHCF-Single, EHCF-s)[17].基于单一数据的全采样协同过滤推荐算法, 优化全采样的损失函数, 提升训练效率.
5)基于单一数据的本文算法(Collaborative Fil-tering with Neighborhood Aggregation, NACF).本文提出的基于单一数据的融合邻域的方法.
对异构行为建模的对比算法如下.
1)CBMF[15].为每类用户行为构建一个交互矩阵, 通过矩阵分解方法训练并优化用户与项目的隐向量, 最终融合各行为的隐向量, 得到用户与项目的特征.
2)基于多反馈的贝叶斯个性化排序算法(Multi- feedback BPR, MF- BPR)[27].将BPR通过正负样本对的残差训练模型参数的思想应用于异构数据, 并将所有观察到的交互作为负样本进行采样.
3)NMTR[16].将融合神经网络与矩阵分解的NCF应用于异构数据, 并通过多任务学习优化各行为的权重.
4)EHCF[17].基于异构数据的全采样多任务学习的协同过滤推荐算法, 通过行为特征转换模块探究用户不同行为间的关联, 以此优化用户建模, 并优化全采样损失函数, 提升训练效率.
5)HNACF.
在本文所有实验中, 特征向量维度设置为64, 批尺寸大小设置为512, 学习率设置为0.05.对于MovieLens-lm数据集, 失活率为0.8, 对于Beibei、Taobao数据集, 失活率为0.5.对于涉及负采样的方法, 将负采样比例设置为4.对于评价指标HR与NDCG, 设置top-N中N=5, 10, 50, 100, 200.
下文评价各算法在相同环境下的性能.在3个数据集上分别进行5次实验, 取其平均值作为实验结果, 如表2~表4所示, 表中黑体数字表示最优结果.
| 表2 各算法在MovieLens-1m数据集上的实验结果 Table 2 Experimental results of different algorithms on MovieLens-1m dataset |
| 表3 各算法在Beibei数据集上的实验结果 Table 3 Experimental results of different algorithms on Beibei dataset |
| 表4 各算法在Taobao数据集上的实验结果 Table 4 Experimental results of different algorithms on Taobao dataset |
在3个数据集上, 对于单一行为数据, 对比基线中性能最佳的EHCF-s, NACF的HR值平均提升0.41%、0.78%、15.9%, NDCG值平均提升0.52%、0.44%、16.7%.
ExpoMF、EHCF-s、NACF性能优于BPR, 说明全采样算法的性能优于随机抽样算法.NCF、NACF性能优于BPR, 说明结合网络的算法性能优于基于矩阵分解的算法.NACF性能优于EHCF-s, 说明融合邻域信息的特征向量比仅用multi-hot编码方式生成的特征向量包含更多信息, 并且更准确地表达用户/项目特征.根据表1又可得出结论, 交互矩阵稀疏度越高, 邻域聚合对算法的提升越大.
在单一行为数据的实验中, 对比EHCF-s, NACF在Taobao数据集上的HR值和NDCG值平均提升16.3%.在MovieLens-1m、Beibei数据集上, NACF提升较小, 仅为0.47%、0.61%, 可能是数据集组成结构对算法性能造成影响.
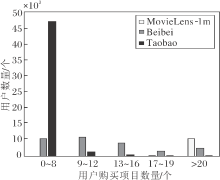
下面研究3个数据集结构.如图4所示, Taobao数据集上约96%的用户交互物品数量是0~8个, 对于MovieLens-1m、Beibei数据集, 这一区间的用户仅分别占总用户数的0%和27.9%.由此提出假设, 对于交互少量项目的用户更容易发现其喜好, 而对于交互较多项目的用户, 邻域聚合对其特征的提升有限, 这也符合个性化推荐的需求和趋势.
 | 图4 根据购买数量对用户进行分类Fig.4 User classification according to purchase quantity |
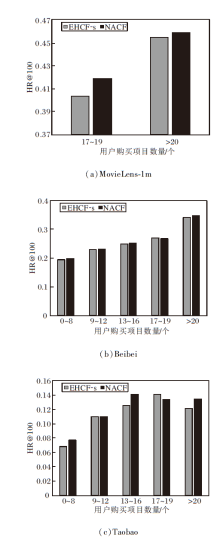
针对用户交互物品数量对算法产生的影响进行深入研究, 分别在3个数据集上根据用户购买的商品数量进行用户分类, 针对HR@100指标, 以EHCF-s为基线模型进行实验, 结果如图5所示.
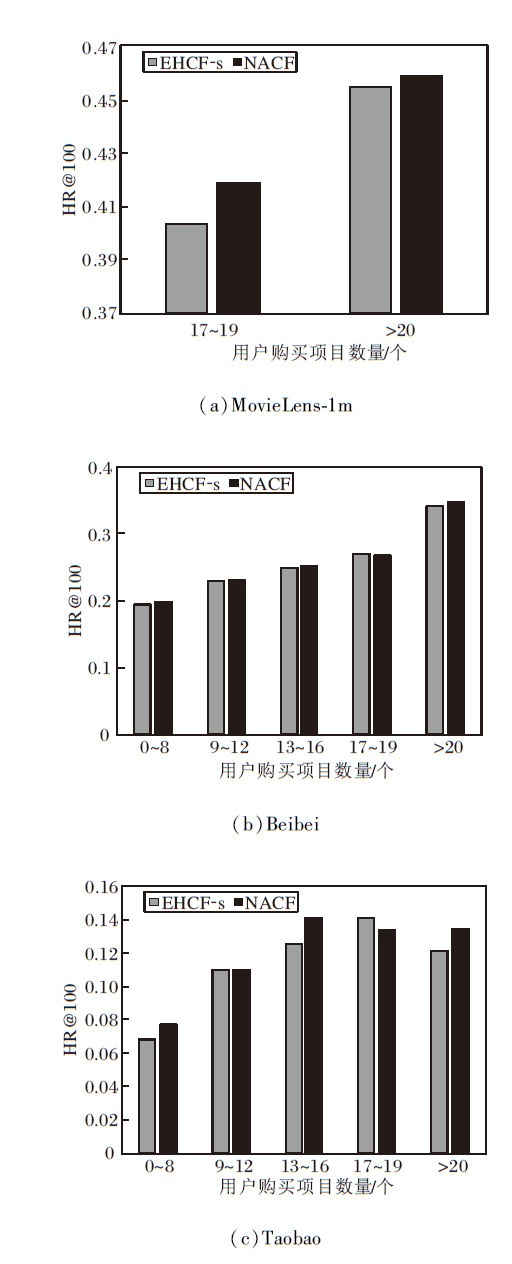 | 图5 用户购买项目数量不同时EHCF-s和NACF的性能对比Fig.5 Performance comparison of EHCF-s and NACF with different purchase quantities |
在MovieLens-1m数据集上, 由于所有用户的交互项目都大于17个, 因此只有两类数据.在用户交互项目数量为17~19个时, NACF比EHCF-s提升3.8%, 而在用户交互项目数量超过20个时, 提升为0.9%.
在Beibei、Taobao数据集上, 根据交互项目数量不同, 用户分为5类, 分别是0~8, 9~12, 13~16, 17~19, > 20.在Beibei数据集上, 相比EHCF-s, NACF这5类用户的性能指标分别提升2.8%, 1.1%, 0.68%, -1.0%, 1.8%.在Taobao数据集上, 相比EHCF-s, NACF这五类用户的性能指标分别提升13.9%, 0.001%, 11.9%, -5.5%, 11.1%.
由此可见, 用户交互项目数量为0~8或超过20时, 邻域聚合的效果较明显.用户交互项目数量较少时, 这些项目可精确表现用户的兴趣和需求, 此类用户有交互项目重合则强化特征, 让推荐更具目的性.而当用户交互项目数量超过一定数量(本文实验中为20)后, 邻域会通过大规模聚合特征的方式, 为目标用户带来更多样的推荐, 吸引这类用户.
如表2和表3中的异构行为数据指标, 在Bei-bei、Taobao数据集上, 对比性能最佳的EHCF, HNACF的HR平均提升为4.6%, 6.3%, NDCG平均提升6.8%, 6.9%.
CBMF与MF-BPR的性能接近且互有优劣, 这表明对于异构数据, 将未观察到的交互作为负样本, 在一定程度上能提升算法性能, 但是结果不稳定, 波动较大.NMTR、HNACF性能优于CBMF和MF-BPR, 再次说明融合网络模型的优越性.EHCF、HNACF性能优于CBMF和MF-BPR, 体现出全采样性能优于抽样方法, 也更稳定.HNACF性能优于EHCF, 表明邻域聚合在异构数据上的有效性.
EHCF通过对异构数据进行特征关联预测以获得不同行为内在关联, 为推荐任务进行指导.而HNACF将异构数据进行邻域聚合, 不仅能将行为关联更好地融入特征向量, 也深入挖掘用户间异构行为的关系, 同时也表明不仅购买行为, 浏览与加入购物车行为也能体现用户的喜好.而数据集上远大于购买行为数据的其它行为的数据为建模用户兴趣起到很大的帮助.
在所有异构行为数据上, 算法的性能均高于仅使用单一行为数据的算法, 说明辅助行为数据可对用户/项目建模起到积极作用, 提升算法性能.
下面验证本文算法缓解数据稀疏性的能力.由图6可看出, 即使在交互较稀疏(即购买记录较少, 实验中购买项目数量在0~8个之间)的用户中, 对比EHCF, HNACF在Beibei、Taobao数据集上, HR@100仍分别提升1.4%和6.7%, 这表明在用户与项目的特征向量中融合邻域信息可有效缓解数据稀疏的问题.
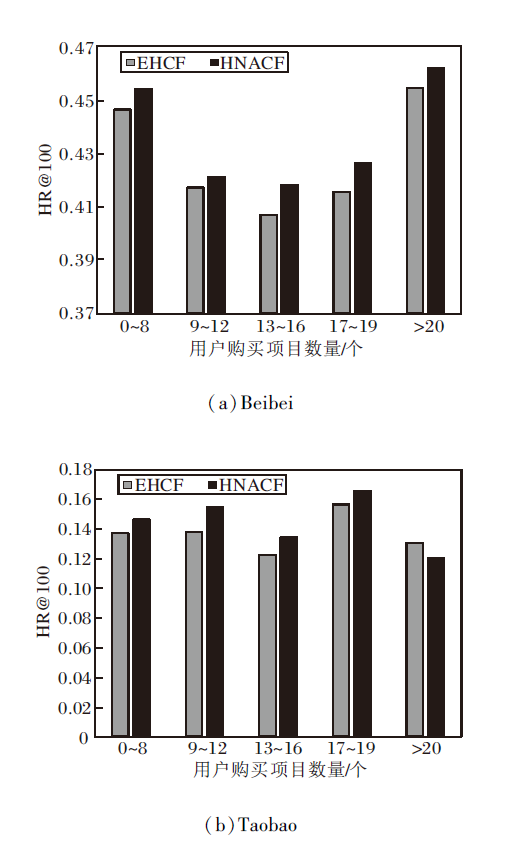 | 图6 用户购买项目数量不同时EHCF和HNACF的性能对比Fig.6 Performance comparison of EHCF and HNACF with different purchase quantities |
为了验证异构邻域聚合的有效性, 本文设计如下消融实验, 验证算法如下.
1)NACF.仅使用主行为数据, 对交互矩阵进行邻域聚合.
2)NACF-h.使用异构数据与异构邻域聚合, 但不使用特征转换模块, 将异构邻域聚合的结果直接输入多任务学习模块.
3)EHCF.使用异构数据, 但不使用邻域聚合模块, 仅使用异构特征转换.
4)HNACF-s.使用异构数据, 但仅对主行为数据进行邻域聚合, 并使用行为关联预测.
5)HNACF.使用异构邻域聚合与行为关联预测.
消融实验结果如表5所示, 表中黑体数字表示最优结果.由表可知, NACF-h与EHCF的性能均优于NACF, 这表明异构行为数据作为辅助信息加入算法能有效缓解数据稀疏问题, 提升性能, 而行为关联预测的性能优于异构邻域聚合.但是两者的侧重点并不相同, 异构邻域聚合目的是挖掘不同用户间行为的关联, 而行为关联预测是为了探索同一用户不同行为之间的关联.HNACF-s的性能优于EHCF, 这表明异构邻域聚合与行为关联预测并不冲突, 它们的融合对算法起到优化作用.HNACF的性能优于HNACF-s, 再次证实异构行为数据能使用户特征更明确, 也再次证实邻域聚合的有效性.
| 表5 各算法的消融实验结果 Table 5 Results of ablation experiment of different algorithms |
在Beibei、Taobao数据集上, 分别测试邻域层数为1, 2, 3, 4时HNACF的性能, 结果如表6所示, 表中黑体数字表示最优结果.由表可见, 邻域层数为3时, HR和NDCG同时达到最高值.而在邻域层数为2、4时, 算法性能相对较差, 猜测可能是由于聚合路径的起始结点与终止结点类型相同, 造成信息冗余.
| 表6 邻域层数对HNACF性能的影响 Table 5 Influence of number of neighborhood layers on HNACF |
传统的异构协同过滤算法仅使用one-hot编码生成特征向量, 而异构数据也仅用于描述行为之间的关系, 忽略用户间行为的联系.本文提出基于异构邻域聚合的协同过滤推荐(HNACF), 将目标用户/项目邻域的信息融入目标的特征向量, 以此缓解数据稀疏, 提高推荐性能.在基于异构数据的推荐算法中, 还将异构数据同时进行邻域聚合, 将非主行为数据作为辅助信息加入用户/项目特征向量, 将行为关联传递到特征映射层, 优化异构行为转换的向量空间.HNACF在MovieLens-1m、Beibei、Taobao数据集上均体现出异构邻域聚合的优势.
算法性能受数据集内部结构影响较大.今后会考虑优化异构邻域聚合对于不同类型用户的算法流程, 使其具有更强的适应性.也会将商品信息和用户评论作为辅助信息加入算法, 进一步缓解数据稀疏问题, 改善推荐性能.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|