
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于模拟退火法的概念集构造算法
[刘忠慧1  , 陈建宇
, 陈建宇1 , 宋国杰2, 3 , 闵帆1, 3 ]
, 陈建宇, 宋国杰, 闵帆]
|
|



作者简介:

刘忠慧,硕士,副教授,主要研究方向为机器学习、形式概念分析、粗糙集.E-mail:lz_hui@126.com.

陈建宇,硕士研究生,主要研究方向为形式概念分析、推荐系统.E-mail:chenjy_1996@163.com.

宋国杰,博士,教授,主要研究方向为深度学习、高性能计算.E-mail:cylsgj@126.com.
About Author:
LIU Zhonghui, master, associate profe-ssor. Her research interests include machine learning, formal concept analysis and rough set.
CHEN Jianyu, master student. His research interests include formal concept analysis and recommender system.
SONG Guojie, Ph.D., professor. His research interests include deep learning and high performance computing.
在形式概念分析中,构造概念格需要较高的时空复杂度,但仅部分格或概念集用于推荐应用.针对上述问题,文中提出基于模拟退火法的概念集构建算法.首先,提出候选概念生成技术,目标函数考虑概念外延相似度,解的更新采用Metropolis准则.再提出概念筛选技术,以外延相似度为评价指标,选择每位用户的强概念构成集合.最后,提出推荐技术,利用外延中邻居用户的偏好,向目标用户提供个性化推荐.在5个公开数据集上的实验表明,文中算法的推荐效果和效率较优.
In formal concept analysis, the construction of concept lattice produces high time and space complexity, but only partial lattices or concept sets are applied in recommendation. To solve this problem, a construction algorithm of concept set based on simulated annealing algorithm is proposed. The candidate concepts generation technique is presented based on the simulated annealing algorithm. The objective function takes the extension similarity of a concept into account. The Metropolis criterion is employed to update the solution. The concept filtering technique is designed based on all candidate concepts. Strong concepts of each user are selected with the extension similarity as the evaluation indicator, and the filtered strong concepts constitute a concept set. The recommendation technique is proposed based on the strong concept set. It provides personalized recommendations to the target user using the preferences of neighbor users in the same extension. Experimental results on 5 public datasets demonstrate that the recommendation performance and the efficiency of proposed algorithm are superior.
本文责任编委 苗夺谦
Recommended by Associate Editor MIAO Duoqian
形式概念分析(Formal Concept Analysis, FCA)[1]自提出后已得到充分发展.FCA的研究主要集中在概念格的构造、约简和应用等方面[2].概念格作为FCA的核心数据结构, 格的构造算法是数据分析的基础.传统的格构造算法根据构造过程的不同, 分为批处理算法[3, 4, 5]和渐进式算法[6].概念格的存储会涉及较高的空间复杂度, 概念格约简是为了在更高效地分析数据同时节省存储空间.根据约简的方式不同, 主要可分为对象约简[7, 8]、属性约简[9, 10]、概念约简[11, 12].在应用方面, 概念格广泛应用于机器学习[13, 14, 15]、知识发现[16]、软件工程[17, 18]、本体论[19, 20, 21]等领域.由于概念格结构模型能表示出形式背景中用户与项目之间的所有二元关系, 从而能描述用户的偏好, 因此FCA也可应用于推荐系统[22, 23, 24, 25].
FCA在推荐系统的应用主要基于概念格, 但经典的概念格构造算法[3, 4, 5, 6]的复杂度都会随形式背景规模的增加呈指数级增长.因此, 谢志鹏等[26]采用树结构对概念结点进行组织, 减少算法执行时间.李云等[27]和智慧来等[28]分解形式背景, 采用多概念格的联合算法构造格, 在一定程度上降低构造复杂度.Njiwoua等[29]和Fu等[30]利用并行计算的方式改进串行概念格构造算法, 降低概念格构造的计算代价.但是, 即使在对构造算法进行优化之后, 概念格构造的时间复杂度仍然非常高.加上推荐场景的数据规模往往较大, 导致FCA的推荐应用受到一定限制.
为了解决在推荐应用时概念格构造的高复杂度问题, 刘忠慧等[31]提出启发式概念构造的组推荐算法(Group Recommendation with Concept of Heuristic Construction, GRHC).在FCA的推荐应用中, 对目标用户的推荐包含该用户的形式概念.因此基于FCA的推荐应用的研究重点是生成高质量的形式概念.文献[31]采用启发式方法, 生成覆盖所有用户的强概念集合, 在降低算法复杂度的同时, 推荐效果与基于概念邻域的协同过滤推荐算法(Conceptual Neighborhood-Based Collaborative Filtering, CNCF)[25]相当.
但GRHC仅利用面积作为启发式信息以生成概念, 难以保证概念外延集合中用户之间的相似度.针对该问题, 本文在生成概念时考虑外延用户之间的相似度, 将模拟退火算法(Simulated Annealing, SA)[32, 33]引入概念集合的构造, 提出基于模拟退火法的概念集构造算法.首先, 利用SA, 设置目标函数为最大化外延相似度, 生成用户候选概念.然后, 从候选概念中筛选强概念, 构建概念集合.最后, 基于概念集合, 根据邻居用户的偏好实现个性化推荐.
定义1 形式背景[1] 形式背景是一个三元组K=(U, M, R), 其中, U为用户集合, M为项目集合, R为U和M之间的二元关系.∀ u∈ U, m∈ M, 如果有uRm, 则表示用户u拥有项目m, r(u, m)=1.
对于U的幂集和M的幂集之间可定义如下2个映射f和g:

表1所示的形式背景记录10位用户对于6个项目的拥有情况.其中:u1拥有m2, 则r(u1, m2)=1; u1未拥有m1, 则r(u1, m1)=0.
| 表1 形式背景 Table 1 Formal context |
定义2 评分形式背景[34] 评分形式背景是一个三元组F=(U, M, V), 其中, U为用户集合, M为项目集合, V为U和M之间的二元关系.∀ u∈ U, m∈ M, v∈ V, v(u, m)≥ 0.如果v(u, m)> 0, 表示用户u拥有项目m, 并且v(u, m)值越高, 表示用户u对项目m的喜爱程度越高; 否则, 表示用户u未拥有项目m.
评分形式背景与形式背景相似, 不同之处在于形式背景是一个二值表, 而评分形式背景的取值范围更广, 包含更多信息.表2是与表1对应的评分形式背景, 表中v(u1, m4)=3不仅表示u1拥有m4, 还表示u1对m4的喜爱程度.
| 表2 评分形式背景 Table 2 Rating formal context |
定义3 形式概念[1] 在形式背景K=(U, M, R)中, 如果存在二元组C=(E, I), 满足f(E)=I, g(I)=E, 其中, E⊆U, I⊆M, 则称C为形式背景K中的一个形式概念, 简称为概念.这里E表示概念的外延, I表示概念的内涵.
从表1中可得到概念C=({u3, u4, u10}, {m2, m3}), 其中E={u3, u4, u10}, I={m2, m3}.
定义4 偏序关系[1] 给定形式背景K中的2个概念C1=(E1, I1), C2=(E2, I2), 若满足E1⊆E2 (⇔ I1⊇I2), 则有C1≤ C2, 称≤ 为概念之间的偏序关系.
若2个概念满足C1≤ C2, 称C1为C2的子概念, C2为C1的父概念.
定义5 概念格[1] 将形式背景K中的所有概念按照定义4的偏序关系进行连接得到的格称为概念格, 记为L(U, M, R).
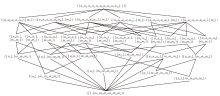
Hasse图是用来表示有限偏序集的一种数学图表.图1为表1对应的概念格Hasse图.该概念格中有2个概念
C1=({u10}, {m2, m3, m4}), C2=({u9, u10}, {m3, m4}),
C1≤ C2, 则C1为C2的子概念, C2为C1的父概念.
 | 图1 概念格Hasse图Fig.1 Concept lattice Hasse diagram |
本文主要解决2个问题:概念集合的构造问题和基于概念集合的推荐问题.具体如图2所示.
 | 图2 问题描述Fig.2 Problem description |
在描述概念集合构造之前, 首先给出相关定义.
定义7 用户相似度 给定形式背景F=(U, M, V), 用户ui∈ U, uj∈ U, 项目集A⊆M, 用户ui、uj基于项目集A的相似度表示如下:
SimA(ui, uj)=
其中, ak∈ A, |· |表示集合的基数, v(ui, ak)、v(uj, ak)分别表示用户ui、uj对项目ak的评分.特殊地, 如果i=j, SimA(ui, uj)=0.该相似度表示2位用户关于给定项目集合的曼哈顿距离.
定义8 外延相似度 给定概念C=(E, I), 基于概念C的外延相似度表示如下:
Sim(C)=
其中, uj∈ E, uk∈ E.该相似度表示外延集合中用户之间关于内涵I的曼哈顿距离的平均值.因此, 外延相似度越高, 外延中用户之间的平均距离越短, Sim(C)值越小.
本文中目标函数的设置基于外延相似度.前后概念分别对应流程图3中的C和C', C为当前概念, C'为添加一个项目后得到的新概念.前后概念之间的外延相似度之差记为Δ Sim.在此基础上, Metro-polis准则可调整为
P(Δ Sim)=
其中Δ Sim=Sim(C')-Sim(C).
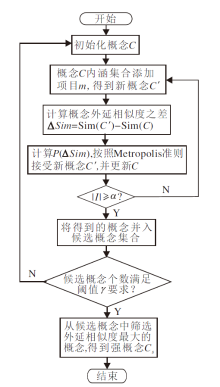
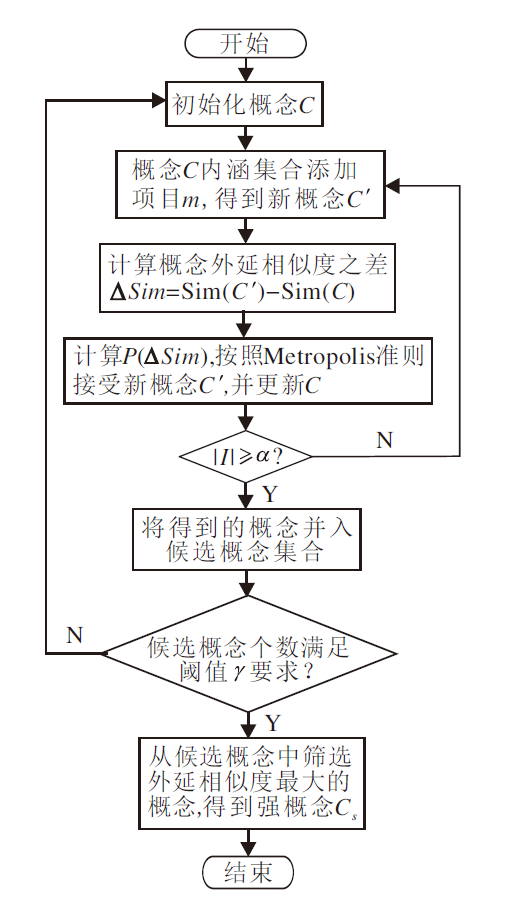 | 图3 强概念生成算法框图Fig.3 Flowchart of strongest concept generation algorithm |
调整后的准则表示:如果新概念的外延相似度更高, 有Sim(C')< Sim(C), 此时Δ Sim≤ 0, 直接接受新概念; 否则, 通过exp[
定义9 强概念 令C=(E, I)为基于用户u生成的一个候选概念, 若在用户u的其它候选概念中不存在C'=(E', I'), 使得Sim(C')< Sim(C), 则称C为用户u的强概念.
本文对文献[31]中的强概念进行重新定义, 使用概念外延相似度代替概念面积, 强概念为基于用户u的候选概念中外延相似度最高的概念.
问题1 模拟退火算法构造概念集合
输入 评分形式背景F=(U, M, V), 内涵阈值α
输出 概念集合S={Ci|i=1, 2, 3, …}
约束条件 ∀ (E, I)∈ S, |I|≥ α
优化目标 min(Sim(Ci)), Ci∈ S
输入中的阈值α 由经验值确定, 主要有2个作用:1)确保概念外延中的用户有足够多的共同项目, 2)调整外延集合中用户数量.一般而言:α 越大, 外延集合中用户数量越少, 但用户共同拥有的项目越多, 用户之间更相似; 否则, 外延集合中用户数量越多, 用户共同拥有的项目越少, 用户之间差异越大.输出中的概念集合S为每位用户的强概念构成的集合.约束条件表示强概念外延中用户共同拥有的项目数量至少为α .优化目标表示每个强概念外延内用户的平均距离尽可能短, 即用户之间的相似度尽可能高.
在描述推荐问题之前, 首先给出推荐置信度的定义.
定义10 推荐置信度 给定形式背景F=(U, M, V), 目标用户u参与生成的概念C=(E, I), 待推荐项目m∈ M, v(u, m)=0, 推荐置信度
RFC(u, m)=
其中, |· |表示集合的基数, v(u', m)表示用户u'对项目m的评分, RFC(u, m)表示在概念C中u的邻居用户拥有项目m的占比.
问题2 利用概念集合进行个性化推荐
输入 形式背景F=(U, M, V), 概念集合S,
推荐阈值β
输出 推荐矩阵L
约束条件 ∀ u∈ U, m∈ M, 如果v(u, m)=0且∃C∈ Su使RFC(u, m)> β , 则l(u, m)=1
优化目标 max(F1)
输入中的概念S为问题1中构造的概念集合.推荐阈值β ∈ [0, 1], 由经验值确定, 作用是控制推荐项目的数量.一般而言:推荐阈值越大, 推荐的项目数量越少; 否则, 推荐的项目数量就越多.输出是一个大小为|U|× |M|的二维布尔矩阵L, 记录每位用户的推荐结果, 矩阵的值初始时设置为0.约束条件中Su为S中包含有目标用户u的概念子集合.
约束条件表示:若同时满足1)用户u未拥有项目m, 2)基于概念C的推荐置信度大于推荐阈值, 则向用户u推荐项目m, 通过将L中对应位置的值改为1(l(u, m)=1), 记录推荐结果.
问题的优化目标是获得更高的F1值, 即更优的推荐效果.
概念集构造算法由强概念生成算法(Strongest Concept Generation Algorithm, SCGA)和基于模拟退火法的概念集构造算法(Concept Set Construction Based on Simulated Annealing, CSSA)共同完成, SCGA针对给定用户生成一个强概念, CSSA完成概念集合的构造.SCGA流程如图3所示.为了生成一个强概念, 首先会基于模拟退火算法生成γ 个候选概念, 再从候选概念中筛选得到外延相似度最大的概念, 即为给定用户的强概念.
算法1 SCGA
输入 评分形式背景F=(U, M, V), 内涵阈值α ,
给定用户u∈ U, 候选概念个数阈值γ
输出 强概念Cs
1.Cs← Ø ;
2.Sims← +¥ ;
3.while (γ --) do
4. E=g({m}), m∈ f({u});
5. I=f(E);
6. C=(E, I);
7. E'=E, I'=I, C'=(E', I');
8. Mu=f({u})-{m};
10. C″=C';
11. E'=g(I'∪ {m}), m∈ Mu;
12. I'=f(E');
13. C'=(E', I');
14. Mu=Mu-{m};
16. C'=C″;
19. Δ Sim=Sim(C')-Sim(C);
21. C=C';
25. Cs=C;
26. Sims=Sim(C);
28.end while
29.return Cs
算法1基于给定用户生成一个强概念.算法首先初始化强概念Cs及对应的外延相似度Sims, 见第1~2行.第4~6行为初始化候选概念, 随机选择一个项目添加到内涵中, 并通过映射确定概念.因为是第一个概念, 直接更新, 见第7行.概念的生成过程是不断尝试将项目添加到内涵集合中, 并通过f、g这2个映射来确保概念的完备性, 见第11~13行.如果添加某一项目后导致外延只包含给定用户, 则该概念无法用于推荐, 应当拒绝此次添加, 见第15~ 18行.第19行计算添加项目前后2个概念的外延相似度之差.第20~22行根据Metropolis准则判断是否接受添加项目后的新概念.整个过程将生成γ 个候选概念.第24~27行为概念筛选过程, 筛选候选概念中外延相似度最高的概念.输出为基于用户u的强概念Cs.
算法2 CSSA
输入 评分形式背景F=(U, M, V), 内涵阈值α ,
候选概念个数γ
输出 概念集合S
1.S← Ø ;
2.for (each u∈ U) do
3. C=SCGA(F, u, α , γ );
4. S=S∪ {C};
5.end for
6.return S
算法2构造概念集合.第3行调用SCGA, 生成一个包含用户u的强概念, 第4行将该概念并入概念集合中.输出为概念集合S.
本文利用概念集合对每位用户进行个性化推荐, 提出基于概念集的个性化推荐算法(Concept Set Based-Personalized Recommendation Algorithm, CSPR), 具体步骤如下.
算法3 CSPR
输入 评分形式背景F=(U, M, V), 概念集合S,
推荐阈值β
输出 推荐预测矩阵L
1.L|U|× |M|← 0;
2.for (each u∈ U) do
3. Su={C|u∈ E, C∈ S};
then
7. l(u, m)=1;
11.end for
12.return L
算法3基于包含用户u的概念集合, 对u未拥有的项目进行推荐.第6~8行为推荐过程, 如果用户u未拥有项目m, 且基于概念C的推荐置信度大于阈值β , 则向用户u推荐项目m, 并将结果记录到L中.
下面分析算法1~算法3的时间复杂度.假设评分形式背景中有n位用户和m个项目, 基于每位用户生成的候选概念个数γ =k.在生成候选概念时, 对于过程中出现的每个概念都需要计算外延相似度, 最坏的情况是一个概念包含所有用户与项目, 因此时间复杂度为O(n2m).在内涵添加过程中, 内涵阈值最大设置为α =m, 因此最坏情况需要添加m次.为了生成一个强概念, 需要生成k个候选概念, 因此算法1的时间复杂度为O(kn2m2).
为了构成概念集合, 需要基于每位用户生成一个强概念, 因此算法2的时间复杂度为O(kn3m2).
在推荐过程中, 需要遍历每位用户的每个项目, 遍历的时间复杂度为O(nm).对于每个项目, 最坏情况需要遍历所有概念才能得出最终推荐结果, 而概念个数和外延长度至多为n, 此过程的时间复杂度为O(n2).因此算法3的时间复杂度为O(n3m).
实际上, 在概念生成过程中, 项目添加的次数远小于m, 并且概念外延的长度远小于n, 内涵的长度远小于m, 因此算法2实际的执行时间远小于O(kn3m2).概念集合构造的复杂度远低于概念格构造的时间复杂度O(n2m)[6].在推荐过程中, 由于概念数量和内涵长度远小于n, 算法3的执行时间也远小于O(n3m).
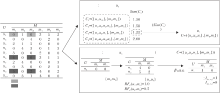
以表2所示的评分形式背景为例, 并结合图4所示的概念生成和推荐流程, 描述基于用户u1的强概念生成及针对其的推荐过程.设置内涵阈值α =2, 候选概念个数阈值γ =4, 推荐阈值β =0.6.
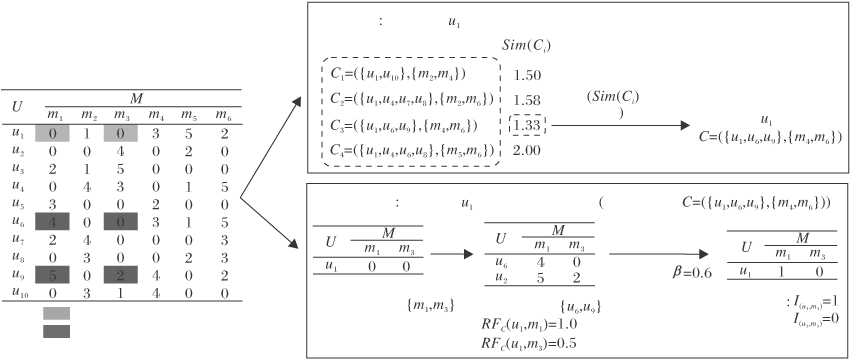 | 图4 运行实例流程图Fig.4 Flowchart of a running instance |
强概念生成过程见图4中概念生成部分.初始化概念C=C'=(U, Ø ).根据图4评分形式背景得到用户u1拥有的项目集合
C=({u1, u5, u6, u9, u10}, {m4}),
第1个概念直接更新C'=C.此时, 最高相似度
Sims=Sim(C')=1.00,
概念内涵长度为1, 小于内涵阈值α , 则继续随机选取项目m6加入内涵,
C=({u1, u6, u9}, {m4, m6}),
计算外延相似度之差
Δ Sim=Sim(C')-Sim(C)=-0.33,
计算接受概率
P(Δ Sim)=0.718,
这里假设P(Δ Sim)> ξ , 更新概念
C'=({u1, u6, u9}, {m4, m6}),
此时内涵长度为2, 满足阈值α , 结束添加内涵, 得到一个候选概念.重复上述过程, 生成4个候选概念C1、C2、C3、C4.再根据概念外延相似度进行筛选, 得到基于用户u1的强概念:
C=({u1, u6, u9}, {m4, m6}).
对于用户集合中的所有用户, 都按照上述过程生成一个强概念, 最终构成概念集合, 如表3所示.用户集上某些用户会生成相同的强概念, 因此集合中概念数量总是小于等于用户数量.
| 表3 概念集合 Table 3 Concept set |
强概念生成过程见图4中个性化推荐部分.以强概念C=({u1, u6, u9}, {m4, m6})为例, 描述针对用户u1的推荐过程.从形式背景中可得待推荐项目为{m1, m3}.用户u1基于该概念的邻居用户为{u6, u9}.2位邻居用户都拥有项目m1, 故推荐置信度RFC(u1, m1)=1, 大于推荐阈值β , 向用户u1推荐项目m1,
本文实验选用电影和笑话两类评分数据集, 以及基于它们随机抽样得到的6个抽样数据集, 其中ML-100k、ML-1m、ML-10m、Filmtrust数据集为电影评分数据集, Jester数据集为笑话评分数据集.数据集详细信息如表4所示.
| 表4 实验数据集 Table 4 Experimental datasets |
实验中使用的数据集均划分为两部分, 80%的数据作为训练集, 20%的数据作为测试集.文中数据集稀疏度定义为评分形式背景中有评分的数据占整个矩阵空间的比例.
对于推荐效果的评价主要采用推荐系统中常用的3个指标:精确度(Precision, P), 召回率(Recall, R)和F1.用户进行推荐得到的推荐预测矩阵记为L(U), 用于验证结果的测试矩阵记为T(U).
精确度为被正确推荐的项目个数与总推荐项目个数的比例:
precision=
召回率为被正确推荐的项目个数与测试集中项目个数的比例:
recall=
F1为综合考虑精确率和召回率, 对推荐结果进行全面评价:
F1=
为了验证CSPR的复杂度及推荐准确性, 在抽样数据集上与CNCF进行对比.CNCF为基于概念格的推荐算法, 概念格构造采用渐进式方法, 从空概念格开始, 将形式背景中的用户逐个加入到已构造好的格中, 再不断更新格, 最终完成格的构造.推荐时通过格间关系寻找包含目标用户概念的兄弟概念与子概念, 从而实现对目标用户的推荐.
实验所用的4个抽样数据集分别从ML-100k、ML-1m数据集上随机抽样得到, 大小均为200× 420.2种算法在不同数据集上的推荐效果和算法运行时间对比如表5所示, 表中黑体数字表示最优结果.
| 表5 CSPR和CNCF的推荐效果及运行时间对比 Table 5 Comparison of recommendation result and running time of CSPR and CNCF |
由表5可看出, 在4个抽样数据集上, CSPR和CNCF的推荐效果相当, 但运行时间有明显差异.在推荐效果方面, CSPR与CNCF在F1值上保持基本一致, CSPR的召回率均略高于CNCF.在运行时间方面, CSPR的平均运行时间为几百毫秒, 而CNCF运行时间却是前者的几百倍, 甚至是几万倍.与CNCF对数据集稀疏度敏感不同的是, CSPR在不同稀疏度的数据集上保持运行时间的稳定.相比CNCF的运行时间从3 min增至4 h, CSPR的增幅较小.
为了验证CSPR推荐的有效性, 选择基于项目的协同过滤算法(Item-Based Collaborative Filte-ring, IBCF)、GRHC、KNN对比推荐效果.
IBCF通过计算项目间的相似度, 向目标用户推荐与其喜爱项目相似度较高的其它项目.文中项目之间的相似度通过杰卡德相似度计算.
GRHC是基于FCA理论的推荐算法.以面积作为启发式信息, 同时利用内涵约束, 构造面积最大的强概念, 用于包含更多的邻居用户, 再根据邻居用户的偏好对目标用户进行推荐.
KNN计算用户之间的相似度, 寻找与目标用户最相似的前K位邻居用户, 再根据它们的偏好对目标用户进行推荐.文中用户之间的相似度通过余弦相似度计算.
实验中ML-10m-s、Jester-s数据集为抽样数据集, 大小分别为3 600× 1 000和2 000× 100.不同算法的推荐效果对比如表6所示, 表中黑体数字表示最优结果.
| 表6 各算法的推荐效果对比 Table 6 Recommendation result comparison of different algorithms |
由表6可看出, 各算法在不同数据集上的推荐效果有明显区别.在精确度方面, CSPR在Filmtrust数据集上有最高的精确度, 而在ML-1m数据集上明显低于IBCF和KNN.在召回率方面, CSPR在3个数据集上有最高的召回率, 在ML-10m-s数据集上有次高的召回率, 并且在所有数据集上的召回率都高于GRHC.在F1值方面, CSPR在3个数据集上有最高的F1值, 在ML-100k、ML-1m数据集上, CSPR的F1值均低于KNN和IBCF, 但在所有数据集上CSPR的F1值都高于GRHC.
实验结果表明, CSPR在较稠密的数据集上有更好的推荐效果.ML-10m-s、Jester-s比ML-100k、ML-1m稠密, CSPR在前两个数据集上的F1值更高.Filmtrust数据集虽然稀疏, 但数据在空间中分布较集中, CSPR在该数据集上的推荐效果也较优.
本文从实际应用出发, 提出基于模拟退火法的概念集构造算法, 并使用概念集代替概念格进行推荐.概念生成过程中引入SA和评分信息, 目标函数的设置采用外延相似度, 解的更新采用Metropolis准则.推荐过程中利用外延邻居用户的偏好对目标用户提供个性化推荐.实验结果表明, CSPR的推荐效果与CNCF、IBCF、GRHC、KNN等相当, 效率明显高于CNCF.今后将继续探讨新的概念集合构造方法和推荐方案:1)在设置目标函数时, 仅考虑外延相似度, 如何从项目等其它维度进行考虑是一个可研究的课题; 2)在多背景数据场景下, 研究如何构造概念集合具有现实意义; 3)在推荐时, 如何利用评分等其它信息提高推荐的准确性是一个重要课题.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|