{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于知识图谱与关键词注意机制的中文医疗问答匹配方法
[乔凯1  , 陈可佳
, 陈可佳1, 2 , 陈景强1, 2 ]
, 陈可佳, 陈景强]
|
|



作者简介:

乔 凯,硕士研究生,主要研究方向为知识图谱、自然语言处理、数据挖掘.E-mail:997843576@qq.com.

陈景强,博士,副教授,主要研究方向为摘要、语义链接网络、自然语言处理.E-mail:cjq@njupt.edu.cn.
About Author:
QIAO Kai, master student. His research interests include knowledge graph, natural language processing and data mining.
CHEN Jingqiang, Ph.D., associate profe-ssor. His research interests include summarization, semantic link network and natural language processing.
针对当前中文医疗领域高质量问答数据缺乏的问题,提出基于知识图谱与关键词注意机制的中文医疗问答匹配方法.首先,引入医学知识图谱,得到知识增强的句子特征.然后,加入关键词注意力机制,强调问题和答案句子之间的相互影响.在2个公开的中文医疗问答数据集cMedQA与webMedQA上的实验表明,当样本数据量较小时,文中方法的优势明显.消融实验也验证每个新增模块对文中方法的性能均有一定程度的提升.
Due to the lack of high-quality question and answer data in Chinese medical field, a Chinese medical question answering matching method combining knowledge graph and keyword attention mechanism is proposed. Firstly, the medical knowledge graph is introduced into the bidirectional encoder representation from transformers(BERT) model to obtain knowledge-enhanced sentence features, and a keyword attention mechanism is employed to emphasize the interaction between question and answer sentences. The experimental results on two open Chinese medical question-answer datasets, cMedQA and webMedQA , show that the proposed model is obviously better , especially for the small amount of samples. The ablation experiment also verifies that each of the new modules improve the performance of BERT to a certain extent.
本文责任编委 陈松灿
Recommended by Associate Editor CHEN Songcan
随着智能信息技术的发展, 越来越多的人在面对健康问题时会在互联网中的问答社区(如百度知道、拇指医生、寻医问药网等)上寻求帮助.为了减少用户的等待时间, 自动问答系统应运而生.这些系统基于社区中已有的医疗问答记录, 将与用户问题相关的最佳回复返回给用户.然而, 一个问题通常会有多个回复, 质量也参差不齐.因此, 如何从众多回复中自动选择与用户问题匹配的最佳答复是一个值得研究的问题.
通常问答匹配被认为是一种分类或排序任务.早期的问答匹配研究主要关注基于规则、特征工程或语言工具的方法.Barró n-Cede
深度学习可实现端到端的学习, 具有强大的表征能力, 近年来逐渐成为自然语言处理的主流方法.Severyn等[6]提出相似度矩阵, 替代传统的文本相似度计算方法, 将句子对之间的相似度作为文本的一个特征, 一同送入卷积神经网络(Convolutional Neu-ral Network, CNN).Yin等[7]构建基于注意力机制的CNN(Attention-Based CNN, ABCNN), 实现问答匹配, 在答案选择(Answer Selection)、释义识别(Paraphrase Identification)和文本蕴含(Textual Entail-ment)3个任务上进行实验.Mueller等[8]提出SiaGRU(Siamese Gate Recurrent Unit), 使用2个共享权重的长短期记忆网络(Long Short-Term Memory, LSTM), 2个句子编码为相同长度的向量, 以此计算2个句子的相似性.上述两种方法通过共享权重的神经网络得到输入句子对的向量再进行匹配.
虽然共享参数的方式可有效减少模型的学习参数, 但未较好利用2个句子元素之间的匹配信息.Chen等[9]与Wang等[10]提出BIMPM(Bilateral Multi-perspective Matching Model), 首先匹配2个句子之间的词向量序列, 将匹配结果通过神经网络转化为向量, 再对向量进行匹配, 捕捉2个句子之间的交互特征.Chen等[9]提出改进的LSTM(Enhanced LSTM for Natural Language Inference, ESIM), 预测句子对之间的关系.Wang等[10]提出基于匹配聚合(Matching Aggregation)的语义匹配模型, 先利用双向LSTM提取文本特征, 再采用4种匹配方式并聚合匹配结果, 输出最终结果.Yang等[11]构建RE2, 保留3种序列间对齐的关键特性:原始点对齐特性、先前对齐特性和上下文特性, 同时简化剩余组件以提高文本匹配性能.Miao等[12]将基于关键词的注意力机制引入问答匹配模型, 学习问答对之间的交互关系, 进一步提高模型性能.
词向量预训练模型(Bidirectional Encoder Representation from Transformers, BERT)自提出以来, 在NLP领域展现强大的学习能力, 在文本匹配任务也取得较优结果[13].BERT依靠 Transformer[14] 强大的文本特征提取能力、遮蔽语言模型和句子预测任务增强模型的语义表示能力.随后, 出现一系列融入知识的改进模型.Liu等[15]提出K-BERT(Knowledge-Enabled BERT), 将知识图谱引入BERT中, 为模型增添额外知识, 并使用可视化矩阵代替句子间的注意力, 解决知识噪声的问题.Zhang等[16]在BERT的编码模块中增加一个K-Encoder模块, 融入知识图谱的实体嵌入.
本文关注中文医疗领域的问答匹配, 相比开放领域下的英文问答匹配[17], 该任务具有更多挑战性.首先, 疾病类别分布极不平衡.医疗领域中疾病类别众多, 而问答社区中患者的提问大多集中于常见的疾病类别(如流行性感冒、慢性胃炎等), 对于不常见的疾病类别(如肾周脓肿、静脉曲张综合征等)则难以获取充足而高质量的问答数据, 疾病类别的不平衡降低问答匹配模型的泛化能力.其次, 医学术语描述形式多样, 同一疾病的不同称谓会对匹配模型的性能产生干扰.例如, 对于“ 胃食管反流” 疾病, 患者提问时可能会使用简称“ 胃反流” 或俗称“ 胃食道反流” 等.最后, 存在动词干扰匹配结果的现象.例如, 对于问答对“ 发烧吃什么药?” , “ 可以吃鸡蛋, 喝粥” , 由于问句与答句中均出现“ 吃” 这一动词, 问答匹配模型可能就此认为该问答对具有较高的匹配程度, 从而做出错误的判断.
为了克服上述问题, 本文提出基于知识图谱与关键词注意机制的BERT方法(BERT Based on Knowledge Graph and Keyword Attention Mechanism, KK-BERT), 用于中文问答匹配任务.方法中加入医疗领域图谱中的知识, 解决部分疾病的训练样本量不足的问题.利用百度百科的重定向功能构建医疗同义词库, 减少医疗术语描述多样性的影响.将对问答序列句意具有重要影响的名词标记为关键词, 采用预训练模型BERT[13]加微调的方式处理字级的表示, 并在BERT基础上增加关键词注意力机制, 更好地学习“ 问题-回答” 句子对之间的关系[18].
在医疗问答匹配中, 对任意一个问题
Q={q1, q2, …, qn},
有候选答案池
P={A1, A2, …, As},
其中, n为问题Q的长度, s为问题Q的候选答案个数, 答案池中的候选答案可分为与问题Q匹配或不匹配两种.将问题Q和其任一候选答案
A={a1, a2, …, am}
组成问答对
text={q1, q2, …, qn, a1, a2, …, am},
其中m为候选答案A的长度.问答匹配旨在学习一个分类函数F(· ), 使
F(text)=p,
其中, p表示text被分类为匹配的概率, p∈ R且p∈ [0, 1],
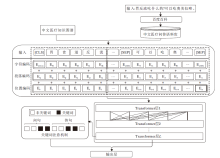
本文提出基于知识图谱与关键词注意机制的BERT方法(KK-BERT), 整体框架如图1所示.KK-BERT主要包括:基于医学领域图谱与医学同义词表的知识增强模块、基于关键词的问答对注意力模块、BERT.首先, 在知识增强模块中, 将知识图谱中的相关知识(三元组)添加到问答对中, 并使用BERT预训练加微调的方式学习问答对的向量表示.然后, 在关键词注意力模块中, 学习问答对之间的关键词交互, 并拼接该向量与BERT的输出向量, 作为问答对的最终向量表示.最后, 将问答对的最终向量表示输入到全连接神经网络, 判断该问答对是否匹配.
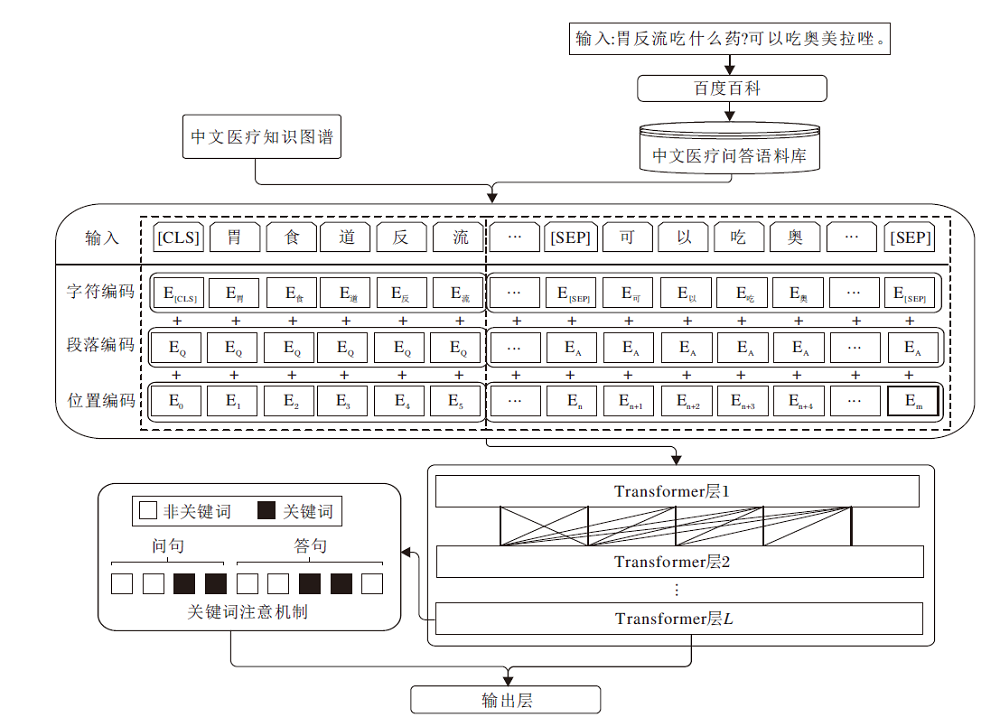 | 图1 KK-BERT的整体框架Fig.1 Overall framework of KK-BERT model |
为了增强方法在样本数量有限情况下的语义表示能力, 本文引入医学领域知识图谱, 提供外部知识.知识图谱的基本组成单位是三元组(h, r, t), 其中h为头实体(Head Entity), t为尾实体(Tail En-tity), r为头、尾实体之间的关系.相比K-BERT[16], 本文在加入外部知识的同时构建同义词表, 用于解决医学术语称谓多样性的问题, 并对候选三元组进行筛选.具体步骤如下.
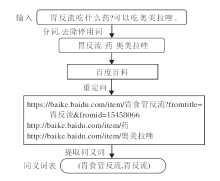
1)建立医学同义词表, 将问答对中的疾病转化为统一术语.如图2所示, 首先使用中文分词工具pkuseg[19]对问答对序列text进行分词并筛除中文停用词, 得到包含医学术语的序列sent={s1, s2, …, sk}.再利用百度百科的重定向功能搜索sent中的词, 构建一张包含医学疾病名称的同义词表.
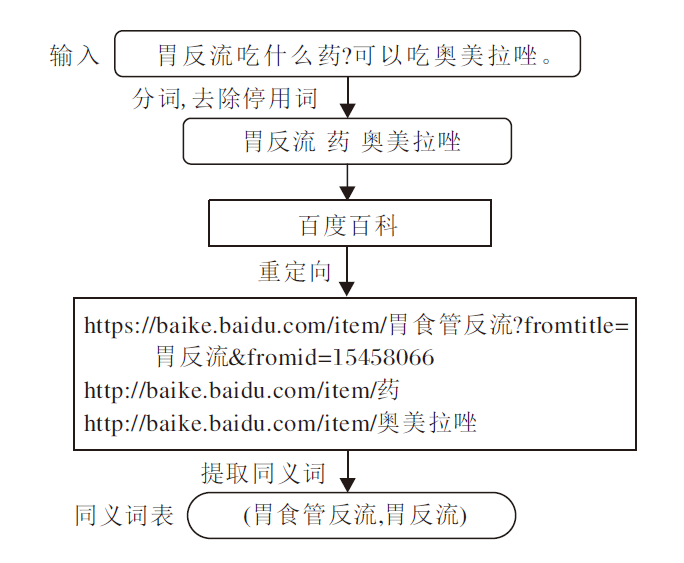 | 图2 医学同义词表构建流程Fig.2 Process of constructing medical thesaurus |
2)引入外部知识.遍历sent序列, 若序列中某个词或其同义词在医学知识图谱的头实体集head=(e1, e2, …, en)中出现, 则将该头实体对应的三元组添至候选三元组.为了避免引入与文本无关的噪声信息, 本文对候选三元组进行筛选后加入序列, 筛选标准为:对于一对问答序列, 若候选三元组中的头实体在序列对中出现, 将该三元组的尾实体连接到序列中, 获得最终的问句序列Q2、答句序列A2与问答对序列text2.
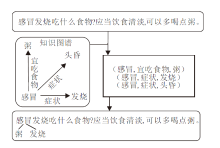
例如, 图3中对于序列对< “ 感冒发烧吃什么食物?” , “ 应当饮食清淡, 可以多喝点粥.” > , 感冒为知识图谱实体集head中的实体, 因此作为头实体的三元组均被列为候选三元组.
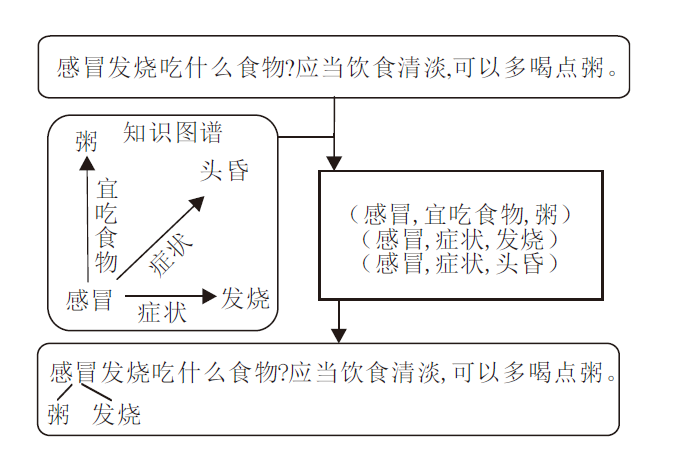 | 图3 外部知识加入问答模型Fig.3 Process of adding external knowledge into Q& A model |
若候选三元组中存在尾实体在序列对中出现, 则将其连接到序列对中的相应实体后, 最终得到序列:
Q2=“ 感冒粥发烧发烧吃什么食物?” ,
A2=“ 应当饮食清淡, 可以多喝点粥.” ,
text2=“ 感冒粥发烧发烧吃什么食物?应当饮食清
淡, 可以多喝点粥.”
3)采用预训练模型BERT加微调的方式提取增广序列的特征, 增强方法的语义表示能力.
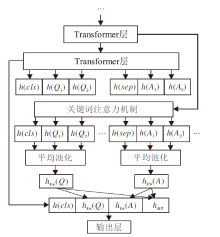
目前主流的问答匹配方法都基于深度学习模型, 将问答对之间的语义匹配问题视为二分类任务.然而, 当问答对中出现相同词句时, 会影响深度学习模型的性能.例如:对于问句“ 发烧吃什么药?” , 答句“ 可以吃鸡蛋, 喝粥.” 两句话中都出现“ 吃” 这一谓语, 可能会干扰已有方法而将该问答对误判为匹配.受Miao等[12]的启发, 本文将问答对中的关键词引入方法, 在BERT的基础上增添一个关键词注意力机制, 用于解决上述问题.在上例中, 如果对问答对中的关键词“ 药” 给予更高的关注, 会提高匹配的准确度.关键词注意力机制的流程如图4所示, 具体步骤如下.
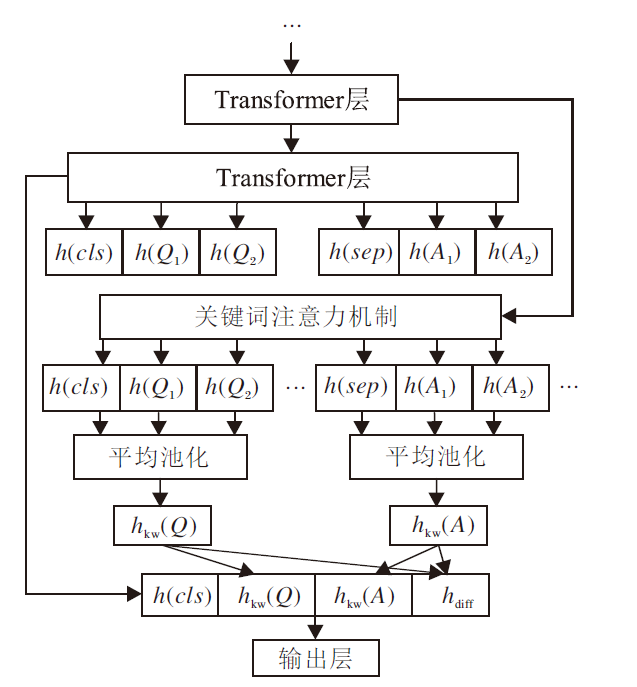 | 图4 关键词注意力机制流程图Fig.4 Keyword attention mechanism |
1)使用中文关键词提取工具CKPE(https://github.com/dongrixinyu/chinese_keyphrase_extra
ctor)提取序列
text={q1, q2, …, qn, a1, a2, …, am}
中的关键词.CKPE借鉴Teneva等[20]的方法, 使用隐含狄利克雷分布(Latent Dirichlet Allocation, LDA)推断主题分布, 提取文档中的名词短语并排序, 实现关键词的抽取.算法具体过程如下:首先, 使用pkuseg进行分词和词性标注, 计算文本中每个词的TF-IDF(Term Frequency-Inverse Document Fre-quency)权重.然后, 将权重较高的相邻词合并为关键碎片词(Key Fragment Words), 将相邻的关键碎片词融合并重新计算权重, 得到候选的关键短语(Key Phrases).最后, 使用预训练好的LDA计算文本与每个候选关键短语的主题概率分布并作为其权重, 最终筛选原文本的关键词.
2)由于外部知识三元组实体本身可视为关键信息, 因此将筛选的实体也标记为关键词, 与1)中筛选的关键词一起加入注意力机制进行学习.
3)在BERT最上层引入一个关键词注意力层, 并接受BERT下层学习得到的参数.为关键词生成关键词注意力掩码序列:
MQ=(t1, t2, …, tn, 0, 0, …, 0), MA=(0, 0, …, 0, t1, t2, …, tm), M=(t1, t2, …, tn+m),
其中, n为问句序列长度, m为答句序列长度, ti∈ {0, 1}.MQ、MA、M与问答对序列text2等长, text2中标注为关键词的位置在关键词注意力掩码序列中对应为1, 其余位置对应为0.
例如, 对于序列“ 胃反流吃什么药?可以吃奥美拉唑.” 抽取的关键词为奥美拉唑、胃、药, 则
MQ=(1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0),
MA=(0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0),
M=(1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0).
使用M对自注意力机制的计算结果进行掩藏.训练模型得到包含问答对关键词信息的表示向量Okw.
4)计算问句关键词和答句关键词之间互信息:
hdiff=(hkw(Q)-hkw(A))⊕(hkw(A)-hkw(Q)),
其中, 表示连接运算符, hkw(· )表示Okw与M· 进行Hadamard积,
hkw(Q)=Okw☉MQ, hkw(A)=Okw☉MA.
5)将问答对的不同表示进行拼接, 用于分类:
hkw=h(CLS)⊕hkw(Q)⊕hkw(A)⊕hdiff,
其中h(CLS)为BERT的学习结果.
实验使用2个公开的中文医疗问答数据集:cMedQA数据集[21]和webMedQA数据集[22].
cMedQA数据集的数据来自寻医问药网, 问题通常由用户提出, 回复来自专业医生.通常一个问题会得到多个回复.数据集划分为3个子集:训练集、开发集、测试集, 共有54 000个问题句子与101 743个答案句子.问题句子的平均字数为119, 答案句子的平均字数为212.
webMedQA数据集的数据来源于专业健康咨询网站(如百度医生、120Ask等).用户先填写个人信息, 然后描述健康问题及问题类别.这些问题对所有注册的临床医生和用户开放, 直到问题提出者选择最满意的答案并关闭问题为止.数据集同样划分为3个子集:训练集、开发集、测试集, 共有63 284个问题句子与306 620个答案句子.问题句子的平均字数为86, 答案句子的平均字数为147.
由于cMedQA数据集上存在大量的负样本, 为了在训练中平衡正负样本的比例及测试模型在不同样本数量下的性能, 本文按照webMedQA数据集的正负样本比例1∶ 5分别从2个数据集上顺序抽取样本量为9 000与54 000的样本, 构造新的实验数据集.统计信息如表1和表2所示.
| 表1 cMedQA-9000与cMedQA-54000数据集的统计信息 Table 1 Statistical information of cMedQA-9000 and cMedQA-54000 datasets |
| 表2 webMedQA-9000与webMedQA-54000数据集的统计信息 Table 2 Statistical information of web MedQA-9000 and webMedQA-54000 datasets |
本文使用深度学习框架 Tensorflow1.14在Ubuntu 18.04上训练和测试各方法.使用分词工具pkuseg并加载工具自带的医学辞典进行分词, 使用CKPE工具包实现关键词提取.采用BERT加微调的方式提取文本特征.BERT的参数设置如下:隐藏层数为12, 隐藏尺寸为768, 自注意力头数为12, 训练批次设置为10, 问题和答案的最大序列长度均为128字符.
本文共进行4个对比实验.每个对比实验各进行3次, 最终结果取其平均值.
本文选择如下对比方法.
1)ABCNN[7].使用基于注意力的CNN, 并采用相似矩阵计算文本对的相似度.
2)SiaGRU[8].使用2个共享权重的 LSTM对2个句子编码生成长度相同的向量, 对比2个句子的相似性.
3)ESIM[9].使用改进的LSTM预测句子对之间的关系.
4)BIMPM[10].利用双向LSTM提取文本特征后结合4种匹配方式进行匹配.
5)RE2[11].快速的文本匹配模型, 保留3个用于序列间对齐的关键特性并简化剩余组件.
6)BERT[13].
7)K-BERT[15].将知识图谱的三元组引入BERT, 提出软位置编码与可视矩阵, 解决知识噪声问题.
问答匹配本质上是一个分类问题, 本文采用准确率(Accuracy, Acc)与F1值作为评价指标.
各方法在2个数据集上不同样本量下的实验结果如表3和表4所示, 表中黑体数字表示最优结果, 斜体数字表示次优结果.
| 表3 各方法在cMedQA数据集上不同样本量下的实验结果 Table 3 Results of different models with different sample sizes on cMedQA dataset % |
| 表4 各方法在webMedQA数据集上不同样本量下的实验结果 Table 4 Results of different models with different sample sizes on webMed dataset % |
由表3和表4可见, BERT及基于BERT的变体模型在问答匹配任务上效果明显优于基于CNN和LSTM的传统深度学习模型.这说明预训练词向量模型在中文自然语言处理任务上同样具有强大的学习能力.在所有模型中, KK-BERT取得最优结果.在cMedQA-9000、webMedQA-9000数据集上, 相比BERT, KK-BERT的准确率分别提升1.1%与2.0%.这验证外部知识与关键词注意力机制的引入有助于提高方法的判别精度.在同一数据集中, 在样本数量较少时, 从BERT到KK-BERT的性能提升更明显.这说明KK-BERT可有效弥补样本数量不足的情况.
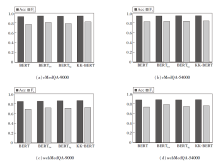
KK-BERT的不同部件对方法性能的影响如图5所示.在图中, BERTkw表示仅加入关键词注意力的BERT, BERTkg表示仅加入外部知识的BERT.由图可看出, 分别引入外部知识和关键词注意机制后, 性能得到提升, 但没有明显的证据表明哪个模块的提升效果更大.在绝大部分数据集上, KK-BERT取得最优结果.KK-BERT的性能普遍高于BERTkg, 这说明关键词注意力机制的加入可让方法更鲁棒, 降低知识噪声的干扰.
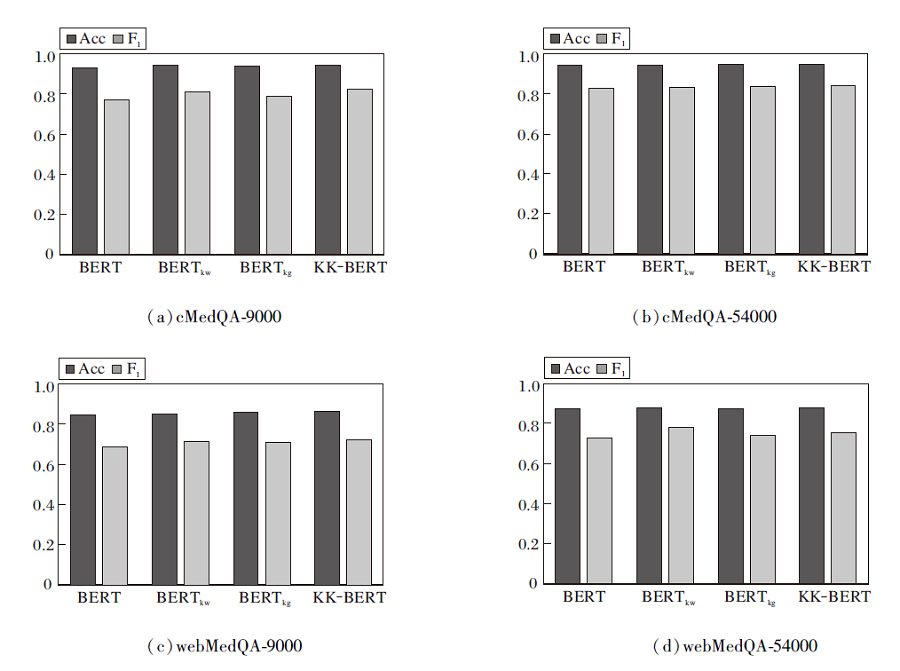 | 图5 KK-BERT的不同部件对性能的影响Fig.5 Effect of different components of KK-BERT on performance |
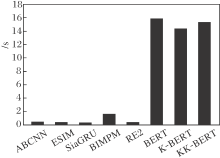
为了对比各方法的匹配效率, 记录它们在cMedQA-9000数据集上每1 000个样本的匹配时间, 结果如图6所示.
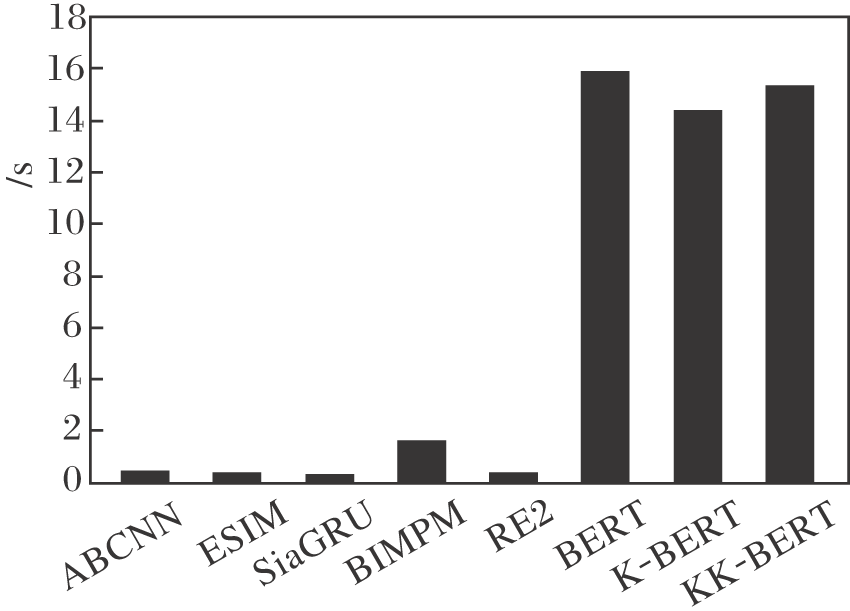 | 图6 各方法的匹配时间对比Fig.6 Matching time comparison of different methods |
由图6可看到, 基于BERT的问答匹配方法的匹配效率要远低于基于非预训练的深度学习方法.主要原因是前者具有更深的层数与更大的参数量.不过, 对于单个样本而言, KK-BERT的响应速度约为0.015 s, 基本满足现实使用的需求.
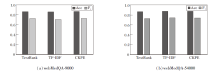
为了进一步探究不同关键词提取方法对模型性能的影响, 选取如下关键词提取方法:CKPE、TF-IDF、TextRank[23].在webMedQA-9000、webMedQA-54000数据集上对比使用不同关键词提取方法的KK-BERT, 如图7所示.由图可知, 使用CKPE的KK-BERT在2个数据集上的性能均优于使用TextRank和TF-IDF的KK-BERT.一个可能的原因是, CKPE对关键词权重的多次重新计算有利于提取更高质量的关键词, 从而增强方法与外部知识的交互.
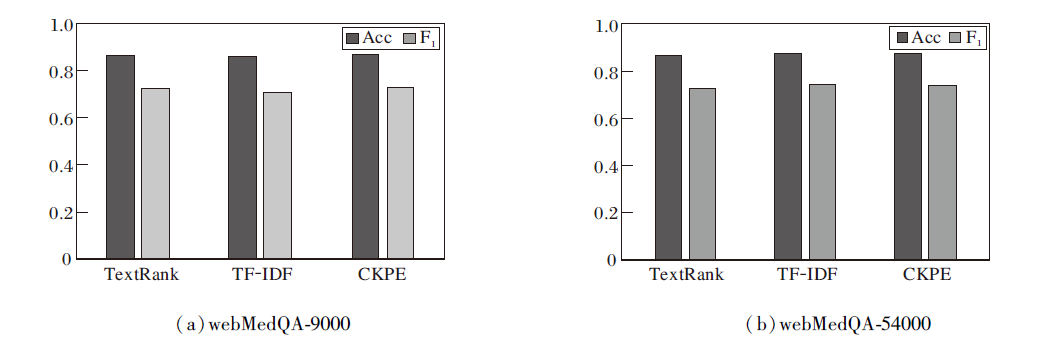 | 图7 不同关键词提取算法对KK-BERT的影响Fig.7 Effect of different keyword extraction algorithms on KK-BERT |
本文提出基于知识图谱与关键词注意力机制的BERT方法, 用于解决中文医疗领域的问答匹配问题.方法基于BERT抽取文本特征, 引入知识图谱学习额外知识, 并利用关键词注意力机制学习问答对之间的交互信息, 结合文本特征和问答对之间的交互信息进行问答匹配.实验表明, 当可训练的样本数量较少时, 外部知识与关键词注意力机制均能有效提升方法性能.因此KK-BERT更适用于难以获取大量高质量样本的领域(如医学领域).今后考虑进一步解决知识噪声对方法性能的影响; 优化方法结构, 进一步提升匹配效率; 研究本文方法在其它序列到序列任务中的性能.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|