{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于双并行残差网络的遥感图像超分辨率重建
[刘丛1  , 王亚新
, 王亚新1 ]
, 王亚新]
|
|



作者简介:

王亚新,硕士研究生,主要研究方向为图像超分辨率重建.E-mail:1225729214@qq.com.
About Author:
WANG Yaxin, master student. Her research interests include image super resolution reconstruction.
当面对目标地物尺寸差异性较大、复杂性较高的遥感图像时,图像超分辨率重建算法的重建效果较差.因此,文中提出双并行轻量级残差注意力网络,提高遥感图像重建效果.首先,提出多尺度浅层特征提取块,融合不同感受野的特征信息,解决遥感图像目标地物尺寸差异较大的问题.再设计基于非对称卷积和注意力机制的轻量级残差注意力块,既降低参数规模,又获取更多高频信息.然后,设计含有不同卷积核的并行网络框架,用于融合不同尺度的感受野.此外,多个残差块中使用跳跃连接融合不同阶段特征,增加信息复用性.最后,通过对比实验验证文中网络在遥感图像上具有较优的重建效果.
The image super-resolution reconstruction algorithm generates a poor effect for the remote sensing images due to different sizes of ground objects and high complexity in the images. Aiming at this problem, a dual-parallel lightweight residual attention network is proposed to increase the reconstruction result. Firstly, a multi-scale shallow feature extraction block(MFEB) is put forward to gain the feature information of different receptive field sizes. The problem of the ground objects with different sizes can be solved by MFEB. Secondly, a lightweight residual attention block(LRAB) is designed with asymmetric convolution and attention mechanism. And thus, the model parameters are reduced and more high-frequency information is captured. Then, the parallel network with different convolution kernels is designed to fuse different receptive fields. Besides, lots of skip connections are employed in residual blocks to increase the reusability of information. Finally, experiments show that the proposed model produces superior performance.
本文责任编委 黄华
Recommended by Associate Editor HUANG Hua
随着遥感技术的高速发展, 海量的遥感图像被卫星摄像机或机载摄像机采集并存储, 供研究者后续识别与解译.该类图像在诸如智能交通、地质灾难检测、城市规划等众多领域都起着越来越重要的作用.然而, 该类图像在拍摄过程中通常会受到运动、大气、超距离成像、通道传输能力等一系列因素的影响, 导致获取的遥感图像存在分辨率较低等问题.通常来说, 设计更精确的遥感摄像机可提高遥感图像的分辨率, 但不可避免地需要高昂的发射和维护成本, 耗时过长.因此, 研究者们需要考虑采用图像处理技术提高分辨率.
图像超分辨率重建旨在通过一幅低分辨率图像获得其对应的高分辨率图像.Dong等[1]提出超分辨率重建卷积神经网络(Super-Resolution Convolutional Neural Network, SRCNN), 使用3个卷积层学习低分辨率图像和高分辨率图像端对端之间的映射关系.借鉴SRCNN的思想, Liebel等[2]在遥感数据集上使用卷积神经网络, 将SRCNN整合到高光谱遥感图像超分辨率重建中.
众所周知, 网络层数越深, 网络的表达能力越优.He等[3]提出残差网络(Residual Network, ResNet), 堆叠大量的残差单元, 获取很深的网络, 保证网络的顺利收敛.Lim等[4]提出EDSR(Enhanced Deep Super-Resolution Network), 利用多个残差块获取更深的网络结构, 捕获高频信息.残差学习也被广泛应用在遥感图像超分辨率重建中.Lei等[5]提出局部-全局连接网络(Local-Global Combined Point-Based Network, LGCNet), Pan等[6]提出残差密集反投影网络, 均在全局和局部都加入残差学习.随着网络层数的不断加深, 研究者们发现网络重建效果逐渐达到饱和, 于是开始寻求新的方向以获得更优的重建效果.
近年来, 研究者们发现大多数重建算法都是平等对待通道特征, 没有捕捉重要的通道.Hu等[7]提出压缩-激励网络(Squeeze-and-Excitation Network, SeNet), 通过压缩-激励(Squeeze-and-Excitation, SE)模块获取不同通道之间的权重, 将通道注意力用于图像处理中.受SeNet启发, Woo等将通道注意力和空间注意力通过不同的方式融合, 提出卷积注意力模块(Convolutional Block Attention Module, CBAM)[8]和瓶颈注意力模块(Bottleneck Attention Module, BAM)[9]两种注意力机制模块.Zhang等[10]提出残差通道注意力网络(Residual Channel Atten-tion Network, RCAN), 将通道注意力融入残差块中, 取得较好的重建效果.
遥感图像具有高度的空间分布, 地面物体具有不同的大小和形状.因此, 遥感图像超分辨率重建更注重高频信息的提取.Gu等[11]和Dong等[12]在网络中设计宽注意力块(Wide Feature Attention Block, WAB), 将通道注意力融入残差块中, 更好地提取高频信息.Haut等[13]整合残差网络中的视觉注意力机制, 并采用多级跳跃连接获得低频信息, 显著提高网络训练过程中的目标获取.Dong等[14]在梯度辅助特征对齐的模型中加入残差注意力模块(Residual Attention Module, RAM), 利用参考图像中丰富的纹理信息重建低分辨率图像中的细节信息.
与此同时, 复杂的网络模型也含有巨大的参数量, 从而影响网络梯度优化, 甚至会在网络训练中出现过拟合现象.Szegedy等[15]提出Inception V1网络, 将全连接层换成稀疏连接, 减少网络参数.随后, Szegedy等[16]对Inception网络不断优化, 在Incep-tion V3网络中, 采用拆分卷积层和非对称卷积层的方式减少参数, 取得较优效果.Xception网络[17]和MobileNet网络[18]使用深度可分离卷积, 减少网络参数量.上述轻量级模型均使用大量的1× 1卷积, 会在网络中耗费大量的计算资源.因此在ShuffleNet网络[19, 20]中, 摒弃大量的1× 1卷积, 在分组卷积之后增加通道重洗(Channel Shuffle)操作, 解决采用分组卷积产生的通道之间独立性过大的特点.轻量级模型有效解决网络深度过深而导致参数量过多的问题.
现有网络在超分辨率重建中取得较优效果, 然而, 已有的大多数网络均采用单一尺度的卷积层提取浅层特征.但是, 由于遥感图像目标地物尺寸差异性较大, 因此, 采用单一卷积层提取的信息有限, 获取信息往往不够准确.
为了解决上述问题, 本文提出双并行轻量级残差注意力网络(Dual-Parallel Lightweight Residual Atten-tion Network, DPLRAN), 提高遥感图像的重建效果.首先, 采用多尺度浅层特征提取块提取浅层信息.然后, 设计轻量级残差注意力块(Lightweight Residual Attention Block, LRAB), 主要融合非对称卷积和注意力机制.LRAB既减少网络的参数量, 又可捕获更多的高频信息.最后, 受多感知网络(Multi-perception Attention Networks, MPSR)[21]的启发, 整个网络框架采用并行框架, 增加网络的鲁棒性, 使网络更贴合遥感图像特征.
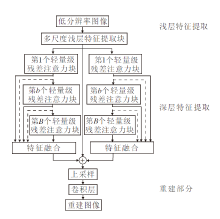
双并行轻量级残差注意力网络(DPLRAN)的整体框架如图1所示.网络主要包括浅层特征提取、深层特征提取、图像重建三部分.本文深度特征提取的两个并行分支均采用B个轻量级残差注意力块.
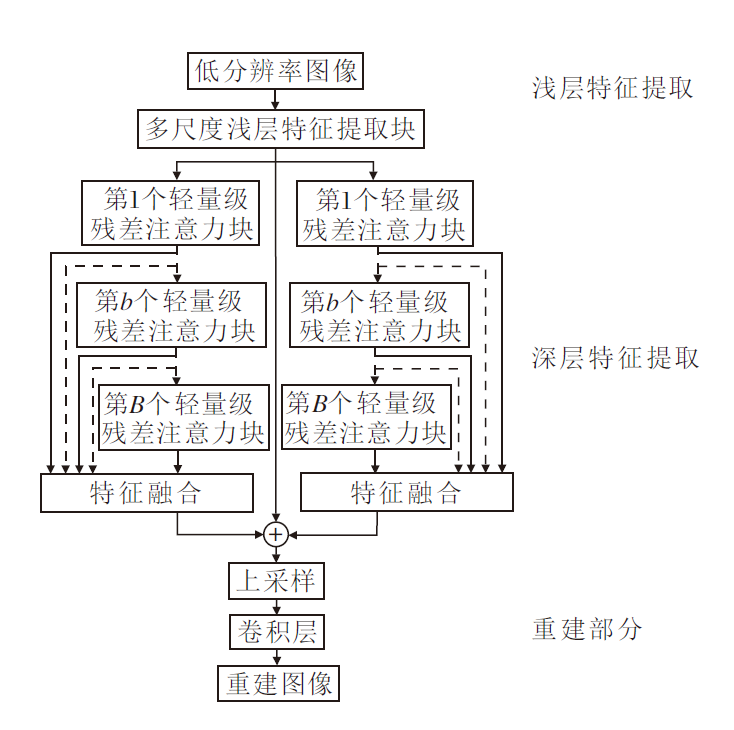 | 图1 DPLRAN框图Fig.1 Architecture of DPLRAN |
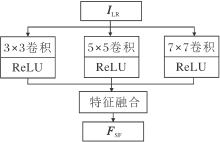
传统的重建网络往往采用单一的卷积层提取图像的浅层特征.针对大多数图像, 通过单一卷积层提取浅层特征可满足人们的需求.然而, 遥感图像内部包含的目标地物尺寸差异较大.当面对含有目标地物尺寸差异较大的遥感图像时, 单一的卷积层略显不足.较小的卷积核使网络的局部感受野较小, 不利于高频信息的提取.较大的卷积核会导致重建目标需要的像素过少, 重建效果变差.所以面对遥感图像时, 目标地物尺寸差异性较大的特点使单一卷积层提取浅层特征并不是一个较好的选择.因此, 本文提出多尺度浅层特征提取块(Multi-scale Shallow Fea-ture Extraction Block, MFEB)解决此问题.MFEB框图如图2所示.
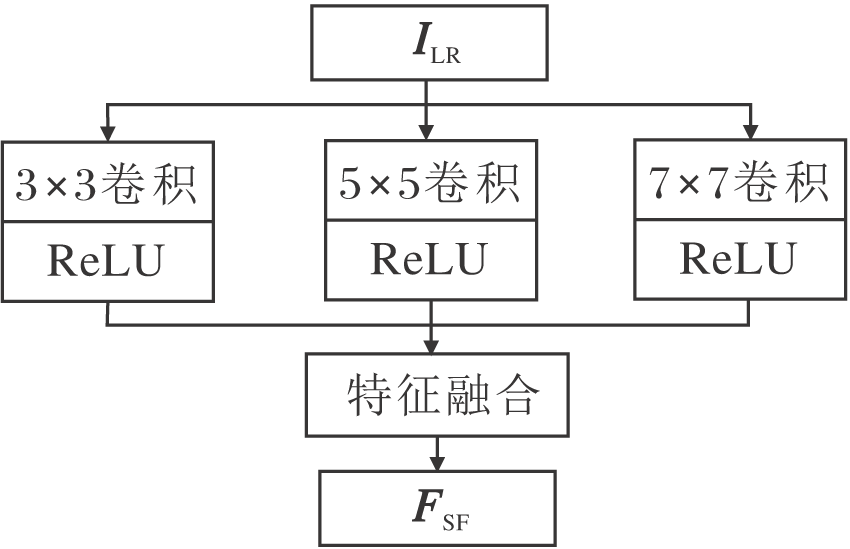 | 图2 多尺度浅层特征提取块框图Fig.2 Architecture of MFEB |
对于给定的低分辨率图像ILR, 使用不同大小的卷积核提取多种特征, 并将获取的多种特征进行特征融合, 具体如下所示:
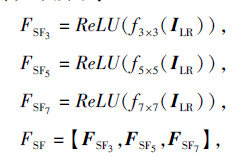
其中, fi× i(· )表示卷积操作, i表示卷积核大小, 【· 】表示特征融合操作.本文中使用的卷积操作均含有补零(Padding)操作, 因此经卷积操作前后输入输出特征的特征尺寸大小一样.将获取的不同尺度的特征图沿通道方向堆叠, 再采用1× 1的卷积, 使通道数降为目标通道数.
现有的重建网络通常提取不同层次的特征图, 融合并捕捉特征图的多尺度信息.MPSR网络指出, 相比融合不同层次的特征信息, 并行多个不同尺度的卷积层可捕获更多的特征信息.因此, 本文提出并行网络结构, 提取深层特征以捕捉特征图中不同尺度信息, 如图1所示.并行结构包括3个分支, 分别为2个轻量级残差注意力块(LRAB)级联分支和1个残差学习分支.前两个分支结构相似, 区别在于两者使用不同尺寸的卷积核, 以便获取特征图中不同尺寸的感受野.残差分支目的在于学习全局残差, 增加网络的鲁棒性, 并使网络获取更准确的高频信息.
1.2.1 并行网络结构
以第1个分支为例.该分支由B个轻量级残差注意力块(LRAB)级联组成, 可描述为
FDF1, B=LRABB(LRABB-1(…LRAB1(FSF))),
其中FDF1, B(· )表示该分支中经过B个轻量级残差注意力块后获得的特征图.再融合不同深度的轻量级残差注意力块获取的特征图, 更好地利用多尺度特征.由此获得第1个分支的最终特征图:
FDF1=【FDF1, 1, FDF1, 2, …, FDF1, B】.
与第1个分支相似, 第2个分支的最终特征图表示为FDF2.将3条分支对位相加, 获得该模块的特征图:
FDF=FDF1+FDF2+FSF.
1.2.2 轻量级残差注意力块
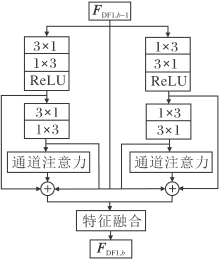
轻量级残差注意力块是本文提出的模块, 模块在设计时考虑4方面因素.1)残差结构可缓解深层网络收敛速度较慢和梯度消失爆炸问题.2)注意力机制可使网络更注重高频信息的提取.3)轻量级结构可减少网络参数.4)并行结构可增加网络的鲁棒性, 提取更多的特征信息.
如图3所示, 受Inception V3启发, 为了降低参数量, 轻量级残差注意力块中的卷积层使用非对称卷积.为了增加网络的鲁棒性, 获取更多的高频信息, 本文的轻量级残差注意力块采用并行分支.2个并行分支仅在1× n卷积和n× 1卷积的执行顺序上不同, 其余结构均相同.最后采用局部残差学习将输入信息与提取的特征图进行特征融合, 得到输出信息.
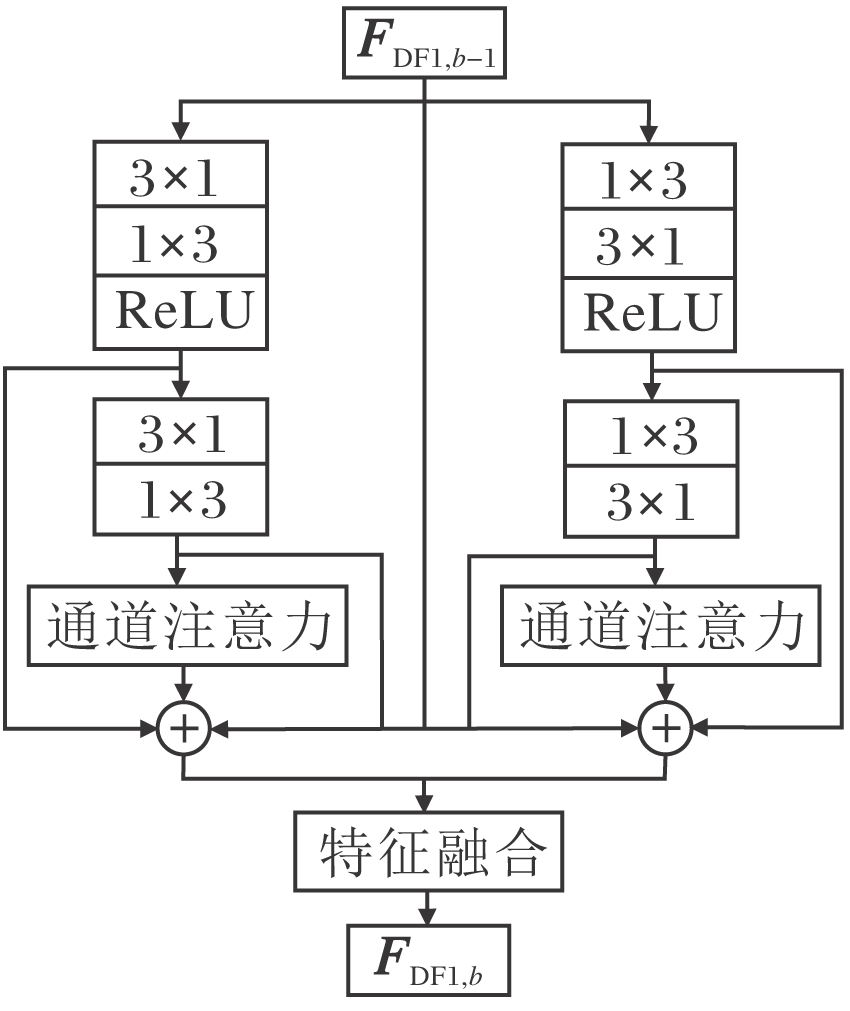 | 图3 轻量级残差注意力块框图Fig.3 Framework of LRAB |
继续以第1个分支为例.对于第b个LRABb块, 输入和输出分别为FDF1, b-1和FDF1, b, 如图3所示.此处含有并行2个分支和1个残差分支.对于右分支, 使用2个非对称卷积、1个注意力机制和若干跳连接组成.首先使用一组非对称卷积提取特征, 再加入激活函数以增加非线性映射, 该操作可描述为
F1-1=ReLU(f3× 1(f1× 3(FDF1, b-1))),
其中F1-1表示右分支提取的第1个层次特征信息.其次使用第2组非对称卷积对F1-1进行操作:
F1-2=f3× 1(f1× 3(F1-1)).
其中F1-2表示右分支提取的第2个层次特征信息.接下来对不同通道执行注意力机制, 以区分不同通道重要性, 即
F1-ca=fca(F1-2),
其中fca(· )表示通道注意力机制, 同RCAN[3]通道注意力一致.最终使用多个跳跃连接, 融合不同层次特征:
F1=F1-1+F1-2+F1-ca.
图3中左分支与右分支结构相似, 在此不再介绍.通过左分支, 可获得最终特征图F2.再融合2个分支特征和残差分支, 获得最终输出特征:
FDF1, b=【F1, FDF1, b-1, F2】.
在重建网络中, 常用的上采样模型有2种:前上采样和后上采样.前上采样通常在网络前部使用插值扩充特征图, 该操作会导致网络在学习过程中需要非常大的计算复杂度.因此, 本文使用后上采样, 在网络结构后部扩充特征图.如何选择合适的后上采样算子也非常重要.转置卷积可通过“ 补零” 加卷积操作对特征图进行上采样, 但容易在每维上产生“ 不均匀重叠” , 获得的特征图往往伴有严重的棋盘效应.亚像素卷积网络(Efficient Sub-Pixel Convolu-tional Neural Network, ESPCN)[22]中采用亚像素卷积对特征图进行上采样, 可获得更好的效果.因此, 本文也采用亚像素卷积获得上采样后的特征图.经过上采样操作后的高分辨率特征映射为
Fup=Hup(FDF)∈ RC× H'× W',
其中, Hup(· )为上采样操作, 由1个卷积层、Conv(3, C× u2)和1个亚像素卷积层组成, u表示上采样因子, 本文实验中u=2, 3, 4.
最后, 对上采样后获得的特征图Fup进行3× 3的卷积操作, 得到重建后的高分辨率图像:
ISR=f3× 3(Fup)∈ R3× H'× W'.
本文使用L1损失函数.通过不断优化真实的高分辨率图像与重建的高分辨率图像之间的差值优化网络.给定训练数据{I
L1(θ )=
其中θ 为本文网络中的参数.采用自适应矩估计(Adaptive Moment Estimation, Adam)优化器优化损失函数.
本文使用UCMerced-LandUse、NWPU-RESISC45遥感数据集作为实验数据集.UCMerced-LandUse数据集来自美国地质调查局全国地图城市区域图像集, 共包含21类, 每类包含100幅图像.每幅图像的分辨率为256× 256.本文取飞机类的100幅图像作为测试集, 命名为UCMTest.NWPU-RESISC45数据集是由西北工业大学创建的用于遥感图像场景分类的公开数据集, 包含45类, 每类共有700幅图像.同样选择飞机类的700幅图像用于实验, 从前600幅图像中随机选取500幅作为训练集, 剩余100幅作为验证集.第601~700幅之间的图像作为另一个测试集, 命名为NWPUTest.为了更好地使用训练集, 采取随机水平翻转和随机旋转90° 、180° 、270° 的方式, 用于增强训练集.
在实验过程中, 采用峰值信噪比(Peak Signal to Noise Ratio, PSNR)和结构相似性(Structural Simi-larity, SSIM)作为评估指标.PSNR和SSIM值越大, 重建效果越好.
在网络训练过程中, 低分辨率图像被随机裁剪成48× 48的图像块, 采用Adam优化器对网络进行优化, 参数设置为β 1=0.9, β 2=0.999, ∈=10-8.初始的学习率为10-4, 每训练200代学习率减少
网络越深, 重建效果越好, 但也会导致网络参数量的迅速增加.本文的轻量级残差注意力块使用非对称卷积代替传统卷积, 可有效减少网络的参数量.
本节进行参数量对比实验.对比方法包括EDSR[4]和宽通道注意力网络(Wider Channel Atten-tion Network, WCAN)[11].在放大因子r=2时, 各网络在不同残差块时的网络参数对比如表1所示.
| 表1 残差块个数不同时各网络的参数量对比 Table 1 Comparison of number of parameters among different methods with different number of residual blocks |
由表1可看出, 当网络中的残差块较少时, 3种网络的参数量相近, 随着残差块的增加, 3种网络参数量之间的差距越来越大.对于EDSR和WCAN, 残差块每增加5个, 参数量增加约400 000.在DPL-RAN中, 残差块每增加5个, 参数量增加约20 000.这同时也说明在参数量相同时, DPLRAN拥有更深层的结构, 更大的感受野.在相同的残差块结构中, DPLRAN拥有更少的参数量.
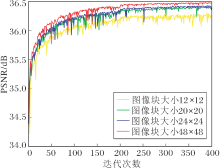
如何设置输入图像块的尺寸也较重要.Incep-tion网络[16]建议, 当使用非对称卷积, 参数设置为12~20时, 获得的重建效果最优.本节分析该参数, 寻找DPLRAN中最佳设置.实验使用L1损失函数的收敛性和PSNR值.在放大因子r=2时, 设置不同的图像块大小获得的PSNR曲线如图4所示.由图可看到, PSNR曲线随迭代次数的增加而趋于稳定.在本次实验中, 将图像块的大小设置在12~20之间, 不能取得较优结果, 然而图像块过大也会增加网络的参数量.因此综合上述两点, 本文将图像块的大小设置为48× 48.
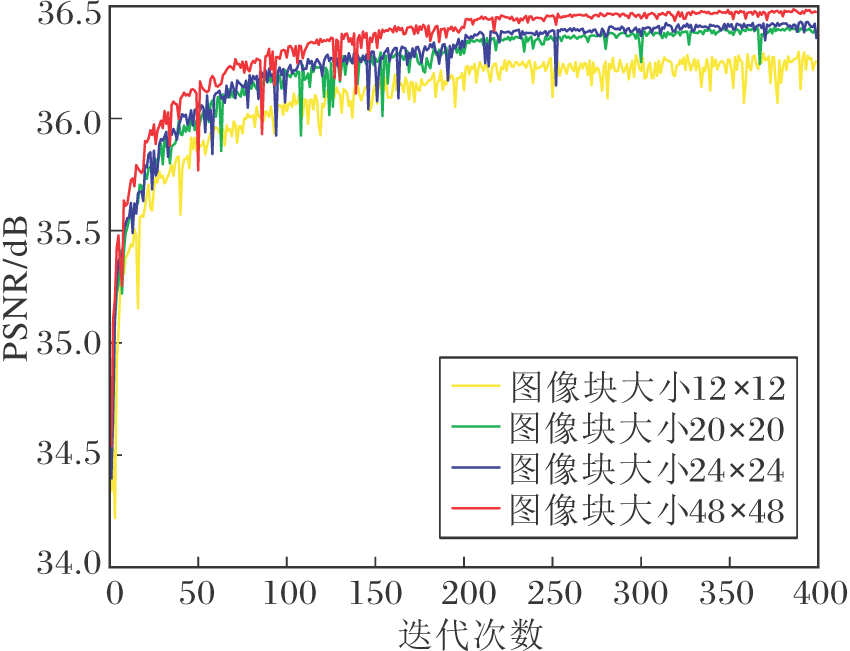 | 图4 图像块大小不同时DPLRAN的PSNR曲线Fig.4 PSNR curves of DPLRAN with different patch sizes |
本节使用消融实验分析并行结构、多尺度浅层特征提取模块(MFEB)和通道注意力机制模块(CA)的性能及其对重建结果的影响.并行结构用在2个位置:网络框架的并行结构(简称为MP模块)和轻量级残差注意力块(LRAB)中的并行结构(简称为BP模块).对于MP模块、BP模块、MFEB模块、CA模块的不同组合, 在2个测试集上进行实验.组合模型如表2第1列所示.M1没有包含4个模块, 使用3× 3的卷积代替MFEB模块提取浅层特征.M2在M1的基础上增加MFEB模块.M3在M2的基础上增加CA模块.M4在M3的基础上增加BP模块.M5包含所有模块, 即本文的DPLRAN网络.
| 表2 不同模块组合在2个测试集上的PSNR值 Table 2 PSNR values of different module combinations on 2 testsets dB |
实验结果如表2所示, 在2个测试集上, 相比M1, M2重建得到的图像在PSNR值上分别提高0.01 dB和0.02 dB.因此, MFEB模块比采用单一的卷积层提取的浅层信息更丰富.在2个测试集上, M3获取的PSNR值比M2分别提高0.03 dB和0.04 dB, 说明注意力机制使网络捕获更多的高频信息.对比M3和M4可发现, 在2个测试集上M4的PSNR值比M3分别提高0.19 dB和0.24 dB, 这说明BP模块起了重要的作用.最后对比M5和M4, M5的PSNR值比M4提高0.05 dB和0.03 dB.因此, 并行网络可增加网络的鲁棒性, 使重建效果更优.
2.4.1 客观指标评价
为了评估DPLRAN网络的有效性, 选取7个具有代表意义的重建网络作为对比算法, 具体如下:SRCNN网络[1]、LGCNet网络[5]、RCAN网络[10]、MPSR网络[21]、IDN网络(Information Distillation Net-work)[23]、IRN网络(Improved Residual Network)[24]和DSSR网络(Dense-Sampling Super-Resolution Network)[12].
在本次实验中, 采用10个残差块训练网络.同时为了公平对比, 对含有残差块结构的网络进行压缩, 参数量是DPLRAN参数量的2倍.表3和表4分别给出放大因子r=2, 3, 4时各方法的PSNR值和SSIM值, 表中黑体数字表示最佳结果.
| 表3 放大因子不同时各网络的PSNR值对比 Table 2 Comparison of PSNR values obtained by different methods with different magnification factors dB |
| 表4 放大因子不同时各网络的SSIM值对比 Table 4 Comparison of SSIM values obtained by different methods with different magnification factors |
相比精简后DSSR, DPLRAN的参数量为DSSR的一半, 但重建效果总体优于DSSR.在UCMTest测试集上, r=4时, DPLRAN稍逊于DSSR, 在r=2, 3时, DPLRAN均优于DSSR.在NWPUTest测试集上, r=2时, DPLRAN的PSNR和SSIM值分别比DSSR提高0.07 dB和0.000 5, r=3时, DPLRAN的PSNR和SSIM值分别比DSSR提高0.04 dB和0.001 1, r=4时, DPLRAN的PSNR和SSIM值分别比DSSR提高0.05 dB和0.000 6.
2.4.2 可视化分析
除了运用客观指标评估以外, 同时采用视觉效果评估DPLRAN网络.不同的重建算法对3幅图像在不同放大因子下的局部放大图如表5所示.由表看出, DPLRAN的重建图像更接近真实的高分辨率图像, 本文算法取得更优的重建效果.
| 表5 各网络对3幅图像在不同放大因子下的局部放大图 Table 5 Local enlarged images of different networks for 3 images with different magnification factors |
本文提出双并行轻量级残差注意力网络, 用于解决遥感图像目标地物尺寸差异性较大及分辨率较低的问题.首先, 提出多尺度卷积层, 提取图像的浅层信息, 捕捉遥感图像中不同尺寸的地物目标.再提出轻量级残差注意力块, 将传统残差块中的卷积层换成非对称卷积层, 提取高频信息, 通过堆叠残差块提取更准确的信息, 同时也尽可能地降低参数量.并且在该模块中加入注意力机制, 对特征进行学习和增强, 使网络可学习到更多的高频信息.最后, 设计双并行网络, 使网络学习不同尺度下的信息, 增大网络的感受野, 使网络更具有鲁棒性.
由于本文提出的残差块是基于低分辨率图像设计的, 因此, 在放大因子较小时, 重建效果较优.随着放大因子的增加, 重建效果逐渐削弱.本文使用大量的特征融合操作, 导致许多层次特征信息都无法销毁.在网络准确率增加的同时, 内存占有率也在增加.下一步研究将主要针对上述两个问题, 不断完善实验结果.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|