





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于深度强化学习的遥感图像可解释目标检测方法
[赵佳琦1, 2, 3  , 张迪
, 张迪1, 2 , 周勇1, 2 , 陈思霖1, 2 , 唐嘉澜1, 2 , 姚睿1, 2 ]
, 张迪, 周勇, 陈思霖, 唐嘉澜, 姚睿]
|
|



作者简介:

赵佳琦,博士,副教授,主要研究方向为深度学习、计算机视觉、多目标优化.E-mail:jiaqizhao@cumt.edu.cn.

张 迪,博士研究生,主要研究方向为深度学习、遥感图像处理.E-mail:zhang_di@cumt.edu.cn.

陈思霖,硕士研究生,主要研究方向为计算机视觉、遥感图像目标检测.E-mail:silin.chen@cumt.edu.cn.

唐嘉澜,学士.E-mail:jialanT@stu.xjtu.edu.cn.

姚 睿,博士,副教授,主要研究方向为计算机视觉、机器学习.E-mail:ruiyao@cumt.edu.cn.
随着遥感技术的飞速发展,遥感图像目标检测在资源勘探、城市规划、自然灾害评估等方面得到广泛应用.遥感影像背景复杂、目标尺度较小,难以检测.针对此问题,文中提出基于深度强化学习的遥感图像可解释目标检测方法.首先,将深度强化学习应用于超快速区域神经网络中的候选区域生成网络,修改激励函数,提高对遥感图像的检测精度.然后,将原有参数量较大的主干网络轻量化,提高方法的检测速度和可移植性.最后,利用网络解剖方法对隐层表征的可解释性进行量化,赋予方法人类理解的可解释性概念.实验表明,文中方法在3个公开的遥感数据集上的性能有所提升.通过改进的网络解剖方法进一步验证方法的有效性.
About Author:
ZHAO Jiaqi, Ph.D., associate professor. His research interests include deep learning, computer vision and multi objective optimization.
ZHANG Di, Ph.D. candidate. His research interests include deep learning and remote sensing image processing.
CHEN Silin, master student. His research interests include computer vision and remote sensing image target detection.
TANG Jialan, bachelor.
YAO Rui, Ph.D., associate professor. His research interests include computer vision and machine learning.
With the rapid development of remote sensing technology, object detection for remote sensing image is widely applied in many fields ,such as resource exploration, urban planning and natural disaster assessment. Aiming at the complex background and the small target scale of remote sensing images, an interpretable object detection method for remote sensing image based on deep reinforcement learning is proposed. Firstly, deep reinforcement learning is applied to the region proposal network in faster region-convolutional neural network to improve the detection accuracy of remote sensing images by modifying the excitation function. Secondly, the detection speed and portability of the model are improved by lightening the original backbone network with a large number of parameters. Finally, the interpretability of the hidden layer representation in the model is quantified using the network anatomy method to endow the model with an interpretable concept of human understanding. Experiments on three public remote sensing datasets show that the performance of the proposed method is improved and the effectiveness of the proposed method is verified by the improved network anatomy method.
责任编委 徐勇
Recommended by Associate Editor XU Yong
由于遥感图像的目标检测不受时间、地域限制, 可获得大范围、多角度数据等优势, 现已成功应用在地物分类、环境管理和矿物填图[1]等方面.随着人工智能技术的兴起, 以数据为驱动的智能化遥感图像目标检测方法成为遥感图像解译领域的重要手段.
遥感图像场景较大, 背景复杂, 图像中目标尺度较小, 容易受到树木、建筑物等异物的遮挡, 在人流量较大、目标密集的区域或多个目标之间容易产生重叠和遮挡.此外, 由于遥感技术应用领域的重要性和特殊性, 需保证目标检测结果的可信度, 但当前大部分目标检测算法缺乏对检测结果的可解释性分析.因此遥感图像目标检测的检测性能及应用仍面临严峻的挑战.
目标检测是从图像中检测不同尺度、类别的物体, 给出不同类别物体的预测位置[2].在目标检测方法中, 特征提取阶段通常采用人工选择的方式, 如尺度不变特征转换和方向梯度直方图等.特征提取方法的性能在很大程度上依赖于特征设计, 而设计特征需要从业者具备大量先验知识, 因此该类方法的设计成本较高、特征鲁棒性较差、泛化能力较弱.相比人工设计特征的方法, 基于深度学习的目标检测使用卷积神经网络(Convolutional Neural Network, CNN)提取图像特征, 具有自动、强大的特征提取能力, 以及更好的鲁棒性和更高的检测精度, 因此传统目标检测方法已逐步被基于深度学习的目标检测方法取代.
基于深度学习的目标检测算法大致可分为:基于锚点(Anchor-Based)的算法和非基于锚点(Anchor-Free)的算法, 两者区别在于是否使用锚点提取候选框.
基于锚点的算法包括两阶段检测模型区域卷积神经网络(Region CNN, R-CNN)[3, 4, 5]系列、一阶段检测模型YOLOv2(You Only Look Once Version 2, YOLOv2)[6]、SSD(Single Shot MultiBox Detector)[7]等.R-CNN首先生成候选框, 进行特征提取, 再在这些区域内放入分类器, 修正和提取目标.超快速区域神经网络(Faster R-CNN)使用候选区域生成网络(Region Proposal Network, RPN), 完成检测任务的深度化.SSD对于给定的一幅图像, 使用回归的方式输出这个目标的边框和类别.
非基于锚点的算法抛弃锚点, 通过其它方式获取框的描述, 如YOLOv1(You Only Look Once Version 1)[8]、角点网络(Corner Network, CornerNet)[9]、极值点网络(Extreme Points Network, ExtrmeNet)[10]、一阶段全卷积网络(Fully Convolutional One Stage, FCOS)[11]等.YOLOv1对于特征图的每个像素点进行目标位置和类别的回归.CornerNet、ExtremeNet利用关键点回归检测框.CornerNet将回归框定位问题转化为对左上和右下两个点的检测与匹配问题.ExtremeNet将关键点定义为极值点, 根据几何结构对关键点进行分组.FCOS使用密集预测方式预测检测框, 检测器直接将像素点作为训练样本, 因此不需要锚点限制特征的选择.
深度强化学习结合深度学习和强化学习, 集成深度学习在视觉等感知问题上强大的理解能力和强化学习的决策能力, 实现端到端学习.深度学习强大的函数逼近能力成为替代人工指定特征的最佳手段, 并为性能更优的端到端学习提供可能[12]. 近年来, 基于价值函数的深度Q学习网络(Deep Q-Learning Network, DQN)[13]性能逐步提升, 学者们提出许多基于DQN的优化算法, 如基于优先级采样的DQN[14]、基于竞争架构的DQN[15]等, 这些都将深度强化学习推向一个研究热潮.
目前深度学习是一个黑盒模型, 缺乏对模型预测行为的解释信息, 导致缺乏预测结果的可信度.Zhang等[16]在预训练的卷积神经网络上增加语义图模块, 获取分类的语义信息, 增强可解释性.Baehrens等[17]提出利用梯度归因的方法, 使用输入模型中每个像素的梯度理解输入与预测结果之间的关联.另外, 还有一些可视化方法[18, 19], 如可视化卷积核激活值较大的区域, 分析模型在图像中获取的信息.这些可解释性方法一般利用人类的主观判断, 缺乏深入分析.
本文在通用的目标检测框架Faster R-CNN的基础上, 针对遥感图像目标尺度较小、数量较多的特点, 提出基于深度强化学习的遥感图像可解释性目标检测方法(Interpretable Object Detection Method for Remote Sensing Image Based on Deep Reinforcement Learning and Faster R-CNN, IFDRL-Fr).将深度强化学习应用于Faster R-CNN中的RPN, 修改强化学习的激励函数和模型结构, 提高检测精度.针对遥感图像目标检测缺乏可解释性的问题, 改进网络解剖算法, 获取模型可解释性语义, 提高模型的可解释性.实验表明, 本文方法可有效提升遥感图像目标检测的准确率和可解释性, 具有模型轻量、检测速度较快的优势.
Faster R-CNN是两阶段目标检测方法, 整合特征提取、候选区域生成、边界框回归, 提出候选区域生成网络, 用于寻找可能为目标的感兴趣区域(Region of Interest, RoI).主干网络负责将输入图像通过卷积神经网络进行特征提取, 提取的特征图用于后续的目标定位和分类.候选区域生成网络通过softmax分类器判断锚点对应区域是正样本还是负样本.根据训练数据集计算针对每个锚点的边界框回归的偏移量, 再通过边界框和目标真实标签修正生成的锚点, 由于结果更精确和更接近目标区域, 进而获得精确的候选框.感兴趣区域池化(RoI Pooling)对大小不同的候选框统一尺度, 方便后续的分类和回归任务.
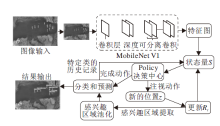
基于Faster R-CNN框架, 本文提出性能更有效的基于深度强化学习的遥感图像可解释目标检测方法.采用强化学习方法优化RPN, 改进强化学习的奖励函数, 提升区域提案生成的效果, 使用轻量级网络MobileNet进行特征提取, 减少方法复杂度.本文方法总体框架如图1所示.
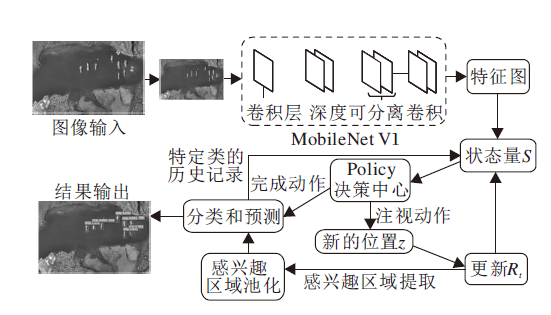 | 图1 IFDRL-Fr框架图Fig.1 Framework of IFDRL-Fr |
受文献[20]~文献[22]的启发, 本文将深度强化学习应用于RPN网络中, 提出基于改进深度强化学习的Faster R-CNN(Improved Deep Reinforcement Learning-Faster R-CNN, IDRL-Fr), 根据遥感图像的特性改进奖励函数, 获得更精确的区域提案.
在每个时间步长内, 深度强化学习的RPN的智能体(Agent)会根据策略计算是否终止搜索, 该策略由注视动作(Fixate Action)和完成动作(Done Action)的概率决定.智能体表示本文设计的强化学习模型.注视动作表示在特征提取得到大量兴趣区域后, 对这些区域进行筛选, 若选择某个区域计算奖励, 为注视该区域.只要搜索还未结束, 便发出注视动作, 访问新的位置.感兴趣区域观测量在以这个新的位置为中心的领域中进行更新, 若要表明已选择这个兴趣区域, 将此领域内的所有条目都设置为1.所有兴趣区域都将发送到RoI池化模块, 进行分类和特定类的边界框偏移量预测.将类的非极大值抑制(Non-maximum Suppression, NMS)应用于已分类的RoI, 获得最显著的信息.由于尚存的兴趣区域具有最终的边界框预测, 因此将它们映射到迄今为止观察到的特定类别的历史记录的某些空间位置.将特定类别的概率向量插入到与基本状态量
算法 1 基于深度强化学习的RPN
输入特征图谱, 形成初始状态量
在每个时间步长t内, 代理根据一个策略决定下一步动作
IF 注视动作
THEN
访问新的位置
将
特定类别的概率向量插入到与
ELSE IF 完成动作
THEN 跳出循环, 结束搜索, 计算完成奖励
检测和分类, 输出结果
强化学习的Agent首先应平衡2个选择RoI的标准.1)应产生较高的对象实例重叠; 2)RoI的数量应尽可能少, 以减少误报数量并保持可管理的处理时间.在此基础上, 设置2个动作奖励评估代理发出的动作:注视动作奖励和完成动作奖励.
考虑到遥感图像具有图像尺寸较大、目标实例较小的特点, 对于遥感图像NWPU VHR-10数据集[23], 原本的深度强化学习奖励函数内容简单、数据量较少, 因此在该数据集上表现较优, 但在DOTA[24]、VisDrone2018数据集[25]上效果并不明显.在深度强化学习的RPN中探查以上3个数据集, 根据奖励函数得到的注视奖励和完成奖励, 发现在NWPU VHR-10数据集上搜索一幅图像, 获得的注视奖励较密集, 完成奖励一般在-20~-1之间.而在DOTA、VisDrone2018数据集上搜索一幅图像获得的注视奖励非常稀疏, 多为0, 完成奖励在-50~-20之间.在DOTA、VisDrone2018数据集上获取到实例的输出检测框较少, 目标较小, 所以在训练中容易被舍去, 无法在图像中获得更多的注视奖励和完成奖励, 难以收敛.
对于每个对象实例, 注视动作奖励为每项注视动作先给出一个小的负奖励, 但代理也会因为与当前图像的任何真值实例产生增加的交并比(Intersection over Union, IoU)而获得正奖励.在每个时间步长t上计算实例与真值的IoU和该实例在整个时间步长中的最大IoU值(即
其中i表示第i个对象实例.完成动作奖励根据每个实例和真值的IoU计算, 被覆盖面积越大, 奖励越接近0, 否则将变得越来越负.终止后, 代理会收到反映搜索轨迹质量的完成动作奖励:
奖励函数的伪代码如算法2所示.改进奖励函数后基于深度强化学习的Faster R-CNN网络称为IDRL-Fr.
算法 2 奖励函数
IF 注视动作
THEN 计算每个对象实例与真值的最大交并比, 记为
在每个时间步长t内, 计算ROI与对象实例的最大交并比, 记为
IF
THEN 累积注视奖励
跳转至注视动作
ELSE IF 完成动作
THEN 计算
IDRL-Fr是基于VGG-16(Visual Geometry Group 16)网络[26]结构进行设计的, VGG16一共包含13个卷积层、3个全连接层、5个池化层和1个softmax层.虽然VGG-16总体结构并不复杂, 在同类型网络中精确度也较高, 但参数量非常大, 共有1.38亿个参数, 导致VGG16占用的空间较多、训练时间较长.
如图2所示, 轻量级卷积神经网络Mobile-Net V1[27]一共由28层构成, 除第一层采用标准卷积核外, 其余的卷积层都使用深度可分离卷积(Xception[28]变体结构).MobileNet V1有95%的计算量和74.59%的参数集中在1× 1的卷积层上, 另外的参数也几乎在全连接层上.
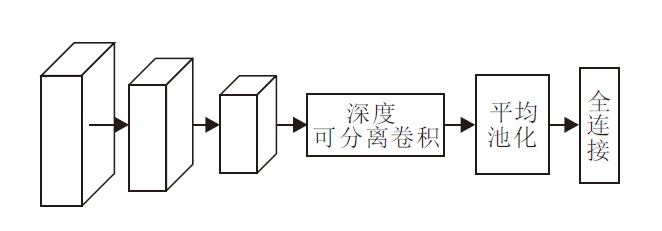 | 图2 MobileNet V1的网络结构Fig.2 Network structure of MobileNet V1 |
在1.1节的基础上, 本文提出基于深度强化学习的遥感图像可解释目标检测方法(IFDRL-Fr), 将VGG16网络替换为MobileNet V1进行遥感图像的训练和测试, 在保持准确率基本不变的基础上, 调节轻量级卷积神经网络的参数, 减少训练时间和参数数量, 获得性能更高的训练模型.
具体地, 以计算主干网络VGG16最后一层conv3-512的可解释性为例, 若输入图像为
其中, H、W表示第i个特征图f(X)的高、宽,
为了计算特征图与标注的语义掩膜的相似度, 首先对特征图进行二值化处理, 将强语义特征与弱语义特征差异化, 得到二值语义图
其中, C表示不同的语义,
通过上述方法可获取卷积核的可解释性语义评分.为了进一步获取卷积层的可解释性语义, 统计该层所有卷积核的可解释性评分, 利用均值作为阈值, 统计高级语义概念与低级语义概念的卷积核个数, 通过对比大小获取该卷积层最终的语义概念.
本文改进网络解剖方法, 预设一组人类容易理解的语义概念作为参照, 并利用包含这些语义概念的Broden数据集获取模型的特征图, 通过计算特征图与数据集语义标签的相似程度, 量化模型的可解释性, 具体如图3所示.
 | 图3 可解释性算法框图Fig.3 Illustration of the proposed interpretable algorithm |
首先将算法中划分的语义概念{场景、目标、部件、材料、纹理、颜色}按照符合人类认知的形式进行再划分, 将{场景、目标、部件}视为高级语义信息, 其余视为低级语义信息, 这种划分更有利于区分卷积神经网络不同层次特征.再将本文方法在Broden数据集上的特征提取结果用于计算可解释性.
实验采用tensorflow框架和python语言搭建目标检测环境, 平台配置包括16 GB的GPU(Tesla P100)、14核CPU(Intel(R) Xeon(R) Gold 5117 CPU@2.00 GHz), 使用GPU和CPU联合训练.
实验选用3个常见的遥感数据集:NWPU VHR-10、DOTA、VisDrone2018.NWPU VHR-10数据集包含10个地理空间对象类, 650幅带标注的遥感图像, 空间分辨率为0.08 m.DOTA数据集包含15个不同的对象类别, 2 806幅带标注的遥感图像, 其中188 282个目标实例由一个面向对象的包围框标记.VisDrone2018数据集采用无人机进行拍摄, 包含12个地理空间对象类, 提供由不同高度的10 209幅静态图像(6 471幅用于训练, 548幅用于验证, 3 190幅用于测试), 是2018年公开的最大无人机地面实况数据集.
可解释性实验数据集Broden采集自ADE[29]、OpenSurfaces[30]、Pascal-Context[31]、Pascal-Part[32]、Describable Textures Dataset(DTD)[33]数据集.数据集具体情况如表1所示.
| 表1 Broden数据集数据分布情况 Table 1 Data distribution of Broden dataset |
实验使用的评价指标为平均准确率(Average Precision, AP)、推断单幅图像耗时和参数大小.AP是小目标检测的一个常用评价指标, 用于计算平均检测精度和衡量检测器在每个类别上的性能; 而各类别AP的平均值(Mean Average Precision, mAP)可衡量检测器在所有类别上的性能好坏.AP和mAP的计算公式如下:
其中, Q表示类别数量,
可解释性实验通过对比不同任务下同一网络的可解释性实现, 用于分析目标检测任务中深度学习模型关注的语义概念, 实验的评估指标为卷积核的个数.
FasterR-CNN、DRL-Fr、IDRL-Fr在3个数据集上进行目标检测训练, 结果如表2所示. 实验选取的基础卷积神经网络为VGG16和MobileNetV1, 迭代次数为110000次, 批尺寸大小为256, 学习率为0.00025, 每隔80000次自动调整学习率, 下降0.1倍.图像输入的最小边为600, 最长边为1000.未调整前IoU阈值设为0.5, 调整后设置为0.45.根据文献[34]和文献[35], 调整正样本和负样本采样的阈值, 提高小目标匹配度.
| 表2 各方法在3个数据集上的mAP值对比 Table 2 mAP value comparison of different methods on 3 datasets |
由表2可看出, 加入深度强化学习和奖励函数调整后, 在NWPU VHR-10、DOTA、VisDrone2018数据集上, mAP都有小幅提升.在NWPU VHR-10数据集上提升1.4%~1.7%, 在DOTA数据集上提升0.2%~0.7%, 在VisDrone2018数据集上提升0.3%.实验结果表明加入深度强化学习后可有效选择遥感图像中大量密集目标, 驱动后续的分类与更好的回归.
将VGG16替换为MobileNet V1, 代入Faster R-CNN和DRL-Fr, 分别称为MF-Fr和MFDRL-Fr, 使用3个遥感数据集分别进行目标检测训练.实验环境和参数设置与2.2节相同.3个数据集的轻量化网络分别在VGG16和MobileNet V1上对比推断时间及参数量.推断时间对比如表3所示.
| 表3 各方法在3个数据集上的推断时间对比 Table 3 Comparison of inference time of different methods on 3 datasets s |
各方法参数量如下:Faster R-CNN为1 126 M, MF-Fr为97.3 M, IDRL-Fr为1 348 M, IFDRL-Fr为132.6 M.
从实验结果可看出, 与2.2节相比, MobileNet V1确实可保持精确度基本持平, 同时大幅减少推断时间, 节约训练成本, 明显减少参数量.
IFDRL-Fr在3个数据集上得到的结果都优于原始的网络模型, 表明其在精确度基本持平的状态下, 小幅提高训练结果, 降低训练时间.
本节从检测精度、参数数量、推断时间上说明深度强化学习的有效性, 结果如表4所示.表中FR表示Faster R-CNN, FR-withDL表示Faster R-CNN中引入深度强化学习.
| 表4 各方法在3个数据集上的消融实验结果 Table 4 Ablation experiments of different methods on 3 datasets |
由表4可见, 引入深度强化学习后, 在可接受的范围内损失一定计算效率(参数量增大, 推断时间增加), 但有效增长检测精度.
在3个数据集上选取相同的图像, 绘制的可视化结果如图4~图6所示.
 | 图4 各方法在NWPU VHR-10数据集上的可视化结果Fig.4 Visualization result comparison of different methods on NWPU VHR-10 dataset |
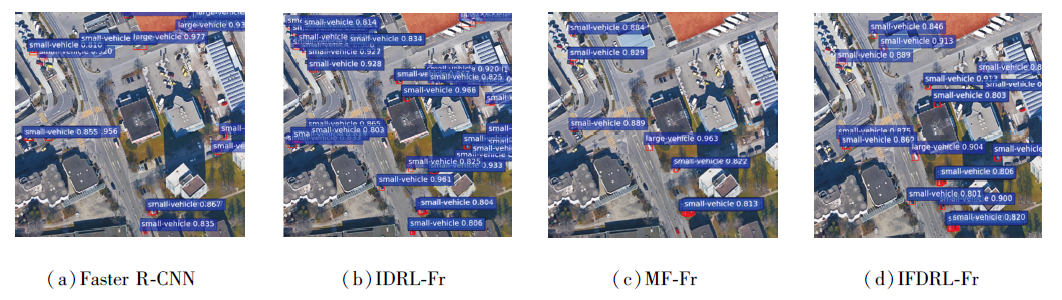 | 图5 各方法在DOTA数据集上的可视化结果Fig.5 Visualization result comparison of different methods on DOTA dataset |
 | 图6 各方法在VisDrone2018数据集上的可视化结果Fig.6 Visualization result comparison of different methods on VisDrone2018 dataset |
NWPU VHR-10数据集由于数据较少且图像内容简单、实例单一, 加入深度强化学习后效果明显, 相比Faster R-CNN, 实例分类概率有所提升, 预测框也更精确.
DOTA数据集上图像尺寸更大, 同幅图中标注的实例目标更小、更多, 调整后, IFDRL-Fr识别的物体更多, 分类也更准确.
VisDrone2018数据集比DOTA数据量更大, 无人机拍摄的角度和光线问题会阻碍网络对目标实例进行特征提取, 造成训练结果精确度不高.由图6可见, IFDRL-Fr获得较优结果.
本节分别对VGG16网络在分类任务上训练的模型与目标检测任务上训练的模型进行可解释性实验, 对比相同网络在不同任务下关注语义信息的异同.实验选取VGG16的最后一层conv3-512, 分类任务训练集为ImageNet[36], 检测任务训练集为NWPU VHR-10.结果如表5所示.
| 表5 可解释性结果 Table 5 Interpretability analysis results |
通过可解释性实验, 分类任务的模型在该层更关注场景、目标、部件等高级语义信息, 检测任务的模型关注场景和纹理, 因此检测任务的最高层卷积既关注高级语义又关注低级特征, 这与任务类型相关.由于分类任务通过特征提取网络获取语义信息进行分类, 因此最高层卷积需要包含丰富语义特征, 而检测任务既需要丰富语义分类, 也需要低层特征进行定位, 因此在最高层卷积网络特征中既包含高级语义信息也包含低层特征信息.
不同卷积核可解释性实验的可视化结果如图7所示.图中随机展示conv3-512层中4个卷积核量化可解释性的可视化结果, 从数据集上随机选取带语义标签的图像, 通过IFDRL-Fr计算得到强语义激活区域与标签的IoU, 图中高亮部分为IoU激活区域, 表示该卷积核着重关注的区域.
 | 图7 不同卷积核可解释性实验的可视化结果Fig.7 Visualization of interpretability experiments for different convolution kernels |
由图7可看出:当输入较低级的纹理图像时, 该层的卷积核可激活大部分区域; 当输入较高级的图像时, 也可激活部分场景区域.因此, 该层既可获取低级的语义信息, 也可获取高级的场景语义信息.
本文提出基于深度强化学习的遥感图像可解释性目标检测方法, 针对遥感图像目标实例小且多的特点, 应用深度强化学习的RPN, 改进奖励函数, 减小锚框的大小和IoU阈值, 适当增加搜索获得的奖励, 鼓励代理继续搜索.针对训练时间较长和空间不足的问题, 应用轻量级的卷积神经网络MobileNet V1, 减少训练时间和参数量, 获得性能更高的训练模型.为了解决模型可解释性问题, 利用网络解剖算法, 通过对可视化特征图的量化, 获取模型内部隐藏层的行为语义, 使模型更利于理解.本文方法为遥感图像目标检测提供新的思路, 为方法提供可解释性.今后将继续研究如何提升复杂场景下遥感图像微小目标检测方法的精度和鲁棒性.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|