


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于融合关系学习网络的行人重识别
[伍子强1 , 常虹1, 2 , 马丙鹏1  ]
]
]
|
|



作者简介:

伍子强,硕士研究生,主要研究方向为行人重识别、基于自然语言的行人检索.E-mail:wuziqiang19@mails.ucas.ac.cn.

常 虹,博士,教授,主要研究方向为机器学习与模式识别的方法、模型及在图像处理、计算机视觉、数据挖掘等方面的应用.E-mail:changhong@ict.ac.cn.
基于图卷积神经网络的行人重识别方法面临两个问题:1)在对特征映射构图时,图节点表达的语义信息不够显著;2)选择特征块构图时仅依赖特征块间的相对距离,忽略内容相似性.为了解决这两个问题,文中提出融合关系学习网络的行人重识别.利用注意力机制,使用最大注意力模型,使最重要的特征块更显著,赋予其语义信息.融合相似性度量,从距离和内容两方面对特征块进行相似性计算,度量方式更全面.该算法能够综合地选取近邻特征块,为图卷积神经网络提供更好的输入图结构,使图卷积神经网络提取更鲁棒的结构关系特征.在iLIDS-VID、MARS数据集上的实验验证文中网络的有效性.
About Author:
WU Ziqiang, master student. His research interests include person re-identification and natural language-based person search.
CHANG Hong, Ph.D., professor. Her research interests include algorithms and models in machine learning and pattern recognition, and their applications in image processing, computer vision and data mining.
There are two problems in person re-identification methods based on graph convolutional network(GCN). While graphs are built for feature maps, the semantic information represented by graph node is not salient. The process of selecting feature blocks to build graph just relies on the relative distance among feature blocks, and the content similarity is ignored. To settle these two problems, an algorithm of person re-identification based on fusion relationship learning network(FRLN) is proposed in this paper. By employing attention mechanism, the maximum attention model makes the most important feature block more salient and assigns semantic information to it. The affinities of feature blocks are evaluated by the fusion similarity metric in the aspect of distance and content, and thus the metric is more comprehensive. By the proposed algorithm, the neighbor feature blocks are selected comprehensively and better input graph structures are provided for GCN. Hence, more robust structure relationship features are extracted by GCN. Experiments on iLIDS-VID and MARS datasets verify the effectiveness of FRLN.
本文责任编委 叶东毅
Recommended by Associate Editor YE Dongyi
随着互联网的发展和终端设备数量的增加, 海量的图像、视频数据不断产生, 利用计算机对这些信息进行智能处理变得尤为重要.行人重识别是一项针对视角互不重叠摄像机网络下的目标行人查询任务, 可弥补固定摄像机视觉局限的问题, 在日常生活中被广泛应用.
行人重识别研究的思路大体可分为两种:从行人图像中抽取具有辨识度的特征[1, 2, 3, 4]和设计有效的距离度量方式[2, 5, 6].随着深度学习的发展, 学者们提出大量基于深度学习的行人重识别方法, 此方法也可大致分为两类:1)基于分类问题研究行人重识别[7, 8, 9], 主要思想为将行人图像作为神经网络的输入, 通过提取的特征获得行人所属类别的概率.2)基于度量问题研究行人重识别[10, 11, 12], 主要思想是将多幅行人图像作为孪生神经网络(Siamese Neural Network)的输入, 由网络学习图像之间的距离度量方式.
学者们还提出一些基于半监督或无监督训练方式的行人重识别算法[13, 14, 15, 16].这些半监督或无监督的行人重识别算法因其可扩展性和较高的实用价值, 吸引大量研究人员开展相关工作.针对行人重识别数据集的流形结构, Bai等[17]提出监督平滑流形算法(Supervised Smoothed Manifold, SSM), 最大程度地利用监督学习中的标签信息, 高效通用.针对行人重识别数据集中的遮挡问题, Wang等[18]提出基于高阶语义特征的行人重识别方法, 提取行人的语义特征, 对其进行建模和相似性度量.
在行人重识别研究中, 能否从不同摄像头拍摄的图像中找到具有辨识度的特征, 是决定方法性能的关键因素.随着算力的提升、深度学习算法的兴起及数据集的增加, 行人重识别中对目标行人的特征提取由手工设计方式逐渐转变成利用深度神经网络自动提取方式.尽管基于深度神经网络的行人重识别研究发展迅速, 但仍存在对图像信息, 尤其是图像像素之间的结构关系利用不充分的问题.
针对该问题, 学者们提出图卷积神经网络[19, 20, 21], 取得不错性能.图卷积神经网络是一种对图结构进行特征提取的网络, 将特征块视作节点进行构图, 可有效提取特征块之间的结构关系.近年来, 研究者们提出图卷积神经网络的相关研究[22, 23].Wang等[24]提出基于非局部(Non-local)神经网络的泛化图像处理方式, 为图卷积神经网络中的构图方式提供有效思路.
由于图卷积神经网络能对图像结构化信息进行提取和保留, 学者们提出一些基于图卷积神经网络的行人重识别方法.Hou等[23]提出交互-融合网络结构(Interaction-and-Aggregation, IA), 基于特征块的表征关系和位置关系, 增强网络提取特征的表达能力.Yan等[25]提出基于上下文信息的行人检索算法, 使用图卷积神经网络计算上下文信息对目标行人的影响.Bao等[22]提出结构关系学习方法(Struc-tural Relationship Learning, SRL), 基于特征块间相对距离挑选特征块并提取结构关系.
然而, 使用图卷积神经网络对特征块进行构图时, 特征块存在语义信息不显著的问题.具体地, 在图卷积神经网络进行特征提取时, 图中每个节点的贡献是相同的.然而在实际过程中, 节点因包含的语义信息不同, 在特征提取时的贡献也不同.某些节点因包含一定的语义信息, 对特征提取贡献较大; 某些节点因包含背景信息, 对特征提取贡献较小.囿于节点贡献的平均分配, 在构图时并不能体现包含较多语义信息节点的贡献程度, 导致这些节点中的语义信息被弱化.
另外, 在卷积神经网络的池化操作中, 存在图像结构信息丢失的问题.Bao等[22]提出利用图卷积神经网络进行结构特征提取的方法, 但在构图时仅依赖特征块在图像中的相对距离, 忽略特征块之间的内容相似性.在构图过程中, 为相关性较高的特征块建立边是图卷积神经网络中的关键步骤, 然而并不能简单地认为特征块之间的相似性仅与相对距离有关.已有的方法通常仅根据特征块的相对距离进行构图, 在构图时未考虑特征块的内容相似性, 导致对构图具有指示作用的内容相似性信息的浪费.
神经网络中的注意力机制借鉴人类脑部注意力机制原理并用于深度学习中, 高效地从大量数据中筛选有价值的信息, 注意力机制在计算机视觉任务[26, 27, 28, 29, 30]中逐渐成为一种提高方法性能的有效手段.Xu等[31]提出联合时空注意力池化网络(Attentive Spatial-Temporal Pooling Networks, ASTPN), 针对基于视频的行人重识别任务, 在空域和时域上同时使用注意力机制以提取更有效的信息.Li等[32]提出多约束的时空注意力算法(Diversity Regularized Spatiotemporal Attention, 简写为DRSA), 利用注意力机制, 在空间上从行人图像中提取多个且重叠部分较少的注意力区域, 对这些区域赋予较高权重以突出重要性.Woo等[33]提出卷积块注意模块(Convolu-tional Block Attention Module, CBAM), 从通道和空间两个维度对特征映射进行注意力提取.
针对上述问题, 本文提出基于融合关系学习网络(Fusion Relationship Learning Network, FRLN)的行人重识别方法.首先, 在融合关系学习网络中引入注意力机制, 解决图卷积神经网络中节点语义信息不显著的问题.然后, 针对图卷积神经网络构图时仅依赖于特征块间相对距离的局限性, 提出融合特征块相对距离和内容相似性的构图方式.在关注特征块相对距离的同时, 还考虑特征块内容间的相似性, 并融合两者.这种融合的相似性度量方式能从特征映射中筛选相似性较高的特征块进行构图, 从而使图卷积神经网络提取具有辨识度的结构关系特征.实验表明, 本文网络在iLIDS-VID[34]、MARS[35]数据集上性能有所提升.
融合关系学习网络的总体结构如图1所示.结构关系特征的提取分为三步:1)通过最大注意力模型(Maximum Attention Model)从中间特征映射中提取注意力系数映射, 生成注意力特征映射; 2)根据融合相似性度量(Fusion Similarity Metric), 将注意力特征映射转换成特征关系图; 3)通过图卷积神经网络对特征关系图进行结构关系特征提取.
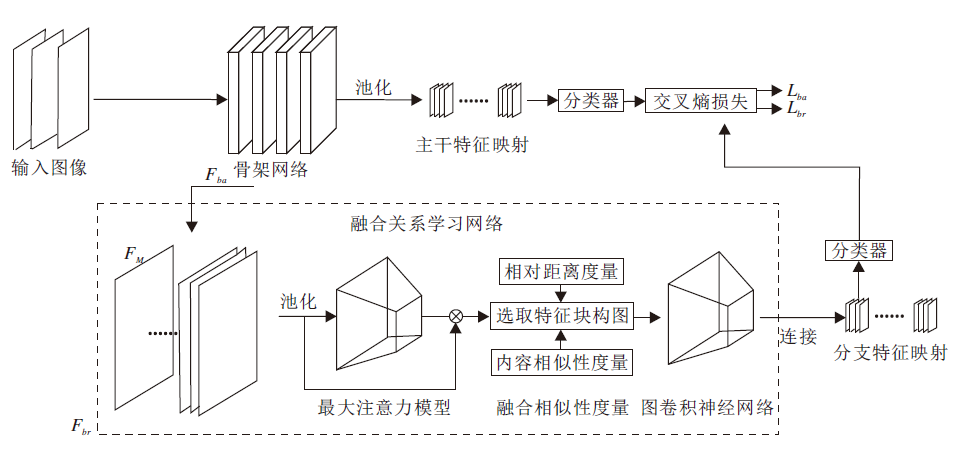 | 图1 本文网络的总体框图Fig.1 Framework of the proposed method |
具体地, 给定一批训练图像, 输入主干网络进行特征提取, 并进行池化和重塑操作, 生成该批图像的特征映射, 称为主干特征映射.融合关系学习网络, 以主干网络提取的中间特征映射作为输入, 从中提取结构关系特征映射.首先, 将中间特征映射输入到最大注意力模型, 生成注意力系数映射, 融合中间特征映射以生成注意力特征映射.然后, 利用融合相对距离和内容相似性的融合相似性度量方法, 对注意力特征映射中的特征块提取近邻点, 将注意力特征映射转换成特征关系图.特征关系图中节点与注意力特征映射中的特征相对应, 边表示特征块之间有关系.
通过图卷积操作对特征关系图进行结构关系特征提取.其中, 构图并进行图卷积操作的过程如图2所示.将融合关系学习网络提取的结构关系特征映射称为分支特征映射, 目的在于作为主干特征映射的补充对网络进行训练.
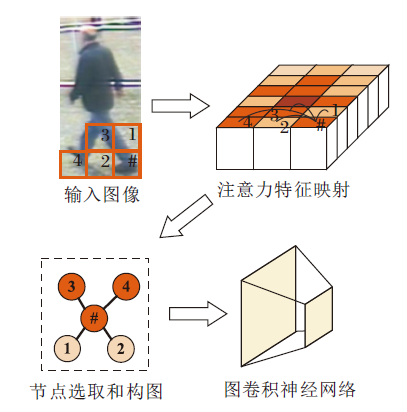 | 图2 基于特征映射构图并进行图卷积的流程图Fig.2 Flowchart of building graph based on feature map and conducting graph convolution |
训练阶段分别计算主干特征映射损失Lba和分支特征映射损失Lbr, 并且Lba和Lbr相加.设输入图像为xi, yi为对应的标签, 主干网络为Fba, 分支网络为Fbr, 交叉熵损失为CE, 则
Lba=CE(Fba(xi), yi),
Lbr=CE(Fbr(xi), yi),
L=Lba+Lbr.
总之, 本文网络能从图像中更好地提取特征之间的结构关系.在不增加网络训练数据的情况下, 将其作为额外特征以丰富网络提取特征的辨识度, 提高网络在行人重识别任务上的表现.
在行人重识别问题中, 采用注意力模型对中间特征映射进行注意力系数提取, 具有较高注意力系数的区域通常具有一定的语义信息, 注意力较低的区域通常包含背景信息.在对中间特征映射进行结构关系特征提取之前, 融合注意力系数映射与中间特征映射, 不仅能显著表示中间特征映射中的语义信息, 还能使特征块之间的联系更突出.
记网络抽取的中间特征FM∈ RD× H× W, 将FM输入最大注意力模型S中.S由J个不同的注意力模型组成, 每个注意力模型由两个全连接层堆叠而成.S中每个注意力模型生成的注意力系数映射记为Aj∈ RH× W, j=1, 2, …, J, 计算过程如下:
Aj(h, w)=
其中, Aj(h, w)∈ R表示Aj中第h行第w列的注意力系数, FM(h, w)∈ RD× 1表示FM中第h行第w列的特征,
为了标准化各注意力模型的系数, 使用Softmax函数对第j个注意力模型产生的注意力系数映射Aj进行归一化处理:
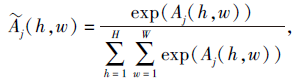
其中, $\widetilde{A}_{j}(h, w)$表示Aj经过Softmax函数处理后第h行第w列的注意力系数.最终, FM通过第j个注意力模型生成归一化注意力系数映射$\widetilde{A}_{j}$.
在对J个归一化注意力系数映射$\widetilde{A}_{j}$进行融合时, 注意到不同的注意力模型对中间特征映射FM的关注区域(即高注意力系数对应区域)有差异.添加正则化的约束条件, 可使不同注意力模型尽可能关注具有显著差异的特征区域[32].本文认为, 如果某区域被多个注意力模型关注, 说明此区域的重要性较大.如果强制使注意力模型关注多个区域, 可能使一些并不值得被关注的区域被强制关注.因此本文采用max(· )函数对J个注意力系数映射$\widetilde{A}_{j}$进行融合:

其中$\widetilde{A}$(h, w)表示最大注意力系数映射$\widetilde{A}$第h行第w列的注意力系数.
采用取最大值的融合方式的优点如下:1)如果多个注意力模型关注重叠较少的区域, 可使每类区域都得到关注; 2)如果不同注意力模型关注相似区域, 这类区域得到的注意力将更明显.通过将中间特征映射FM与注意力系数映射$\widetilde{A}$进行点对相乘, 得到注意力特征映射:
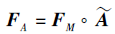
注意力特征映射是欧几里得数据结构, 除了相对距离以外并未直接包含特征块之间的关联信息, 因此在使用图卷积神经网络提取结构关系特征前, 需要寻找一种均衡且全面的度量方式计算特征块之间的相似性, 用于将注意力特征映射转换成特征关系图.
得到注意力特征映射后, 采用基于相对距离和内容相似性的融合相似性度量方式, 计算注意力系数映射中任意两个特征块之间的融合相似度, 对于某一特征块, 筛选与之融合相似性较大的点作为构图时的近邻点.融合相似性度量, 得到能反映特征块之间结构关系的特征关系图, 图节点表示特征块, 边表示两个特征块之间存在关联.将注意力特征映射FA转换成的特征关系图记为GF, FA中的特征块构成GF中的节点.
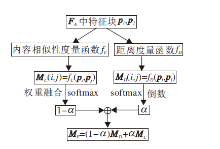
本文提出融合FA中特征块相对距离和内容相似性的度量算法, 用于选取FA中特征块进行构图.算法主要由三步组成:1)对FA中特征块之间的位置进行相对距离度量, 获得相对距离矩阵MD; 2)对FA中特征块之间的内容进行相似性度量, 获得内容相似性度量矩阵MC; 3)融合相对距离矩阵和内容相似性矩阵, 得出融合相似性矩阵MF, 通过MF构造特征关系图GF.具体算法框架如图3所示.
 | 图3 融合相似性度量算法框图Fig.3 Framework of similarity metric fusion algorithm |
特征块在特征映射中的相对距离反映特征块间的相似性, 基于特征块间的相对距离度量特征块间的相似性.径向基函数是一种取值仅依赖点pi、pj间距离的函数:
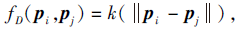
其中, fD(· , · )表示两点之间的相对距离, 采用二维高斯函数作为径向基函数的核函数k(· ), 度量不同特征块之间的相对距离.
相对距离度量在不同维度内是相同的, 所以仅考虑FA中的单个维度.设FA中2个特征块为pi、 pj, 位置分别表示为(hi, wi)、(hj, wj).pi、 pj之间的相对距离度量函数表示如下:

为了计算简便, 将fD(pi, pj)存储在相对距离映射MD中, 即MD(i, j)=fD(pi, pj).
使用径向基函数表示特征块之间的相对距离时, MD中两点之间距离度量值越大, 表示两点的距离越远.而在内容相似性度量中, 两点内容相似性越大, 表示两点越相似.因此, 将MD中的数值取倒数并进行归一化处理, 实现相对距离越近的点之间的度量值越小, 具体公式如下:
MD(i, j)=
内容相似性度量根据特征块内容之间的差异度量特征块之间的相似性.为了方便表述, 将注意力特征映射表示成FA∈ RH× W× D, 设N=H× W, 可转换为FA∈ RN× D.转换后FA包含N个特征块, 每个特征块的特征维度为D.将每维的贡献度视为相同, 因此计算D维特征属性之间的欧氏距离, 用于衡量特征块之间的内容相似性.设特征块pi∈ FA, pj∈ FA, pi的特征属性表示为{di, 1, di, 2, …, di, D}, pj的特征属性表示为{dj, 1, dj, 2, …, dj, D}.pi、 pj之间的内容相似性度量函数表示如下:
fC(pi, pj)=
为了方便计算, 将fC(pi, pj)存储在内容相似性映射MC中, 即MC(i, j)=fC(pi, pj).
在进行内容相似性度量时, 为了使内容相似性映射MC和相对距离映射MD处于同一范围内, 同样需要对内容相似性度量值进行归一化处理:
MC(i, j)=
相对距离映射MD和内容相似性映射MC分别表示注意力特征映射FA中特征块间的相对距离和内容相似性.在训练过程中, 采用加权融合的方式对MD和MC进行融合.设权重系数为α (0< α < 1), 融合MD和MC的过程如下:
MF=(1-α )MD+α MC, (1)
其中, MF表示特征块融合相似度映射, 1-α 表示相对距离映射MD在融合时的权重系数, α 表示内容相似性映射MC在融合时的权重系数.对于给定的特征块, 通过调整α 可获得不同的近邻点, 得到不同的构图结果.对比不同α 值下的算法精度, 不仅可确定较合理的α 取值范围, 还能启发式地探索特征块内容相似性和相对距离之间隐含的关系.
将特征块与其在融合相似度矩阵MF中相似性最高的Q个特征块构造连接边, 可从注意力特征映射FA中提取连接矩阵T∈ RN× N.通过注意力特征映射FA和连接矩阵T表示图GF, 对于FA中的特征块pi∈ RN× N, pj∈ RN× N,
T(i, j)=
为了能提取图GF中节点之间的结构关系特征, 采用图卷积神经网络中信息在层中的传递方式对图GF进行结构关系特征提取.在图卷积神经网络中, 特征映射在层与层中传递公式如下:
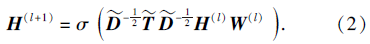
其中:$\widetilde{T}$=T+I, I为和T相同尺寸的单位矩阵; $\widetilde{D}$为$\widetilde{T}$的度矩阵, 因此$\widetilde{D}$中非对角线元素值为0, $\widetilde{D}$(i, i)=
本文的融合关系学习网络的损失计算伪代码如下所示.
算法 1 融合关系学习网络的损失计算(x, y, α , Q)
输入 行人图像x, 图像身份标签y, 度量融合系数α , 构图特征块数Q+1
输出 用于训练深度神经网络的损失值Loss
FR← x的主干特征映射
FM← x的中间特征映射
FG← x的分支特征映射
$\widetilde{A}$← 计算FM对应的注意力系数映射
FA← FM与$\widetilde{A}$点对相乘, FA形状为(B, H, W, D)
for idx遍历FA的B维时 do
FAidx← 取FA第idx条数据
FAidx← FAidx的形状视为(H× W, D)
for i遍历FAidx的H× W维度时 do
for j遍历FAidx的H× W维度时 do
MD(i, j)← 计算i、 j之间的相对距离
MC(i, j)← 计算i、 j之间的内容相似度
end for
end for
M← 使用α 融合MD和MC
edges← 特征块之间的连接关系
for ni遍历M的行时 do
[ni1, ni2, …, niQ]← ni行前Q大的值对应的点
edgesi← 构建ni和Q个选取点的边
end for
Fg← 将构建的edges输入图卷积神经网络, 得到分支特征映射
FG← 将Fg存储于FG中
end for
PR← 将FR输入分类器中, 得到类别概率分布
PG← 将FG输入分类器中, 得到类别概率分布
Loss← 计算PR、PG与标签y的交叉熵损失并相加
返回 Loss
本文选择在iLIDS-VID、MARS数据集上进行实验.iLIDS-VID数据集包含由2个视角不相交摄像头拍摄的42 495幅图像, 共有300个行人身份和600段图像序列, 每个行人包含由2个摄像头拍摄的2段图像序列.iLIDS-VID数据集上行人为手工标注, 行人图像有遮挡和姿态变化的情况.
MARS数据集是第1个基于视频的大规模行人重识别数据集, 为Market-1501数据集的扩展版本, 包含6个不同摄像头拍摄的1 261个行人身份, 共有1 191 003幅图像.MARS数据集为算法自动标注, 因此有一定的干扰项.
本文采用累计匹配曲线(Cumulative Match Cha-racteristic, CMC)[36]评估方法的命中率.在累计匹配曲线中, 将候选行人库中的图像按照与查询图像的相似度进行排序, 若前K个排序结果包含与查询图像同身份的图像, 此时Top-K值为1.对测试集数据进行Top-K查询, 可计算平均Top-K命中率.本文计算测试集的Top-1、Top-5、Top-10、Top-20, 测试方法的命中率.在实际应用场景中Top-1命中率通常更重要, 因此本文主要分析算法的Top-1命中率.
本文还采用平均精度均值(mean Average Preci-sion, mAP)[37]描述精度.mAP越大, 表示经相似度排序后候选行人库中与查询图像身份相同的图像排序越靠前.
本文网络以ResNet-50[38]为主要网络结构, 取其中Layer3提取的特征作为中间特征, 网络结构在Layer3之后划为2个分支:剩余的ResNet-50网络结构和融合关系学习网络.训练阶段通过计算两个分支的损失进行训练, 测试阶段以不同权重融合两个分支提取的特征映射, 从而寻找性能最优的查询结果.
在训练时, 网络首先经过ImageNet数据集[39]进行预训练, 输入图像大小限定为288× 144, 并且对图像进行正则化处理和随机剪裁, 每批送入随机选取的8幅图像对网络进行训练.使用随机梯度下降(Stochastic Gradient Descent, SGD)更新网络参数, ResNet-50网络和融合关系学习网络同时进行训练.根据实验测试, ResNet-50网络的学习率设为0.001, 融合关系学习网络的学习率设为0.01, 训练周期设为9, 每3个周期进行学习率衰减.
在融合时存在超参数α , α 表示在融合相似性度量模块中, 相对距离度量矩阵和内容相似性度量矩阵相加的权重系数.在实验时, α ∈ [0, 1], 遍历步长为0.25.为了公平起见, 本文方法和仅基于相对距离的方法[4]在构图时筛选的特征块个数Q均为4.
本文选取10种方法作为对比方法:SRL[22]、ASTPN[29]、DRSA[32]、顶部推离距离学习模型(Top-Push Distance Learning Model, TDL)[40]、质量意识网络(Quality Aware Network, QAN)[41]、联合空间和时间的循环神经网络(Joint Spatial and Temporal Recurrent Neural Networks, 简写为JSTRNN)[42]、基于范围的质量估计网络(Region-Based Quality Esti-mation Network, RQEN)[43]、姿态导向的时空对齐(Poseguided Spatiotemporal Alignment, PISA)[44]、掩膜图注意力网络(Masked Graph Attention Net-work, MGAT)[45]、自适应图表示学习(Adaptive Graph Representation Learning, AGRL)[46], 其中, MGAT、SRL、AGRL基于图卷积神经网络.
TDL提出顶部推离距离学习模型, 在这个模型中合并顶部推离约束, 用于匹配视频中的行人特征.QAN致力于学习两个数据集间的距离度量, 但样本质量无法得到保证, 因此提出质量敏感网络, 给不同样本的质量进行打分.JSTRNN设计空间注意力模型和时间循环模型, 同时处理空间信息和时间信息.ASTPN提出时空注意力池化网络, 使特征提取器对当前输入视频帧敏感, 匹配项之间的依赖性能直接影响其余特征计算.RQEN延续QAN对图像进行质量打分的思想, 将打分从单幅图像细化到对图像的每个区域分别打分, 并使用序列中质量较好的区域弥补质量较差的区域.DRSA利用注意力机制, 从行人图像中提取多个重叠部分较少的注意力区域.PISA使用以姿态为导向的时间-空间对齐方法, 对行人图像进行特征提取.MGAT使用掩码图注意网络, 关注样本集中丰富的全局互信息.SRL使用卷积神经网络和图卷积神经网络同时对图像进行特征提取.AGRL通过姿态对齐和特征相似度连接进行适应性构图, 并使用图卷积神经网络以利用局部特征之间的关系.
各方法在iLIDS-VID数据集上的实验结果如表1所示, 表中黑体数字表示最优结果.由表可看出, 相比未采用图卷积神经网络的方法DRSA, 本文网络在Top-1上提升3.8%.相比基于图卷积神经网络的方法SRL和AGRL, 本文网络在Top-1上分别提升1.3%和0.3%, 在mAP上, 本文网络也比SRL提高0.9%.其它基于图卷积神经网络的方法仅采用特征块之间相对距离作为度量方式, 而本文网络的性能提升主要来自于对中间特征映射强化语义信息的表达, 并且采用融合相似性度量方式, 这两个模块的融合能有效提高网络提取特征的表达能力.
| 表1 各方法在iLIDS-VID数据集上的实验结果 Table 1 Experimental results of different methods on iLIDS-VID dataset |
MARS数据集是一个对于行人重识别网络更具挑战性并且评价更客观和公平的数据集.各方法的实验结果如表2所示, 表中黑体数字表示最优结果.由表可看出, 本文网络在mAP、Top-1、Top-5指标上最优.相比DRSA, FRLN的mAP、Top-1值提高10.8%和1.8%.相比SRL, FRLN的mAP、Top-1值分别提高3.2%和2.1%.这一结果说明对于大规模行人数据集, 本文网络能有效学习特征映射的语义信息, 构建更合理的特征结构图, 获得更具辨识度的结构关系特征.
| 表2 各方法在MARS数据集上的实验结果 Table 2 Experimental results of different methods on MARS dataset |
为了验证本文网络中最大注意力模型和融合相似性度量的有效性, 采用消融实验测试不同模块的功能.实验中采用iLIDS-VID数据集, 控制其它因素不变, 对两个模块增删之后的mAP和Top-1值如表3所示, 表中黑体数字表示最优结果.当两种模块均不添加, 即不对特征映射语义信息进行显著表示, 只考虑特征块之间的相对距离时, 网络效果最差.当仅添加融合相似性度量时, 即对未进行语义信息显著表示的特征映射进行融合相似性度量, 效果高于两个模块均不添加.当仅添加最大注意力模型时, 即对特征映射进行语义信息提取, 但仅采用相对距离度量方式, 效果高于两个模块均未添加.当同时添加两个模块时, 网络的mAP和Top-1值最大.
| 表3 本文网络在iLIDS-VID数据集上的消融实验 Table 3 Ablation experiment of the proposed network on iLIDS-VID dataset |
由表3还能直观观察到, 当单独添加两个模块时, 实验结果中的mAP几乎相同, 但仅添加融合相似性度量时Top-1更高, 这说明采用融合相似性度量对网络性能的提升更大.消融实验验证融合关系学习网络中最大注意力模型能有效提取特征映射中的语义信息, 而融合相似性度量能更好地度量特征块之间的相似性, 这表明本文网络的有效性.
为了能更直观地展示本文网络带来的性能提升, 在iLIDS-VID数据集上对不同方法的检索结果进行可视化, 结果如图4所示.图4中左侧3幅图像表示3个不同查询ID, 右侧表示每个查询ID对应的检索结果.每种方法右侧的5个检索ID与左侧的查询ID相似度从左到右依次递减, 正确的检索ID使用红框标出.
 | 图4 各方法的检索结果Fig.4 Retrieved results of different methods |
由图4可知, 使用SRL时, 第1个查询ID的正确检索ID排在第4, 其它2个查询ID在测试范围内无法正确检索.使用融合关系学习网络时, 3个查询ID与正确ID的相似性均最高.第1个ID的行人图像腿部有部分遮挡, SRL检索的最相似行人图像在腿部也有部分遮挡, 因此腿部的遮挡也被考虑成行人特征.第2个ID的行人图像背景反光严重, SRL检索的最相似行人图像中背景反光也较严重, 背景的反光被考虑成行人的特征.第3个ID的行人图像整体偏暗, 但行李箱拉杆较亮, 在SRL的检索结果中大多存在一条较亮的栏杆, 拉杆被考虑成行人的特征, 而正确ID的行人图像中行李箱的拉杆并不明显.本文网络对这3个查询ID的正确检索结果均排在第1, 这是因为本文网络通过最大注意力模型, 使网络更多地关注图像中的语义信息, 降低背景、遮挡对特征提取的干扰, 在此基础上融合相似性度量对特征块构图并提取图像的结构关系特征, 使网络提取的特征更具辨识度.
在iLIDS-VID数据集上对网络中的一些重要参数进行测试分析.考虑到注意力系数映射对网络的作用, 分别测试最大注意力模型中注意力模型个数J和注意力系数映射尺寸Jsize.此外, 为了对比融合相似性度量中两种度量方式的作用, 设置式(1)中相对距离度量和内容相似性度量的融合权重为α , 式(2)中图卷积神经网络的层数为L, 观察不同层数对结构关系特征提取的影响.在对某个参数进行分析时, 其它参数均取最优值固定不变.
J和Jsize对FRLN的影响如表4所示, 表中黑体数字表示最优结果.Jsize表示中间特征映射的大小, 尺寸由ResNet-50网络的中间输出设定, 根据以往的经验设定.在2种不同的Jsize下, 实验结果均在J取较小值3时最好, 当Jsize较大时效果更优.本文认为当注意力模型个数过多时, 最大注意力模型提取的注意力系数映射反而会变平均, 使最大注意力模型的效果降低.而Jsize较大时, 对特征映射的划分更精细, 使最大注意力模型的效果提升.
| 表4 注意力模型个数J和特征映射尺寸Jsize对FRLN的影响 Table 4 Effect of the number of attention model J and the size of feature map Jsizeon FRLN |
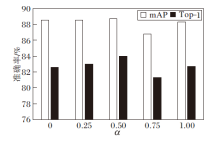
融合相似性度量中不同融合权重α 对FRLN的影响如图5所示.采用步长0.25对α 进行遍历实验, α =0表示仅采用相对距离度量, α =1表示仅采用内容相似性度量, 实验表明最佳的融合权重α =0.5.值得注意的是, FRLN在α =0.75时效果最差, 以包含垂直或水平边缘的行人边缘特征块为例进行说明.假设行人边缘特征块包含的背景特征多于行人特征, 当采用内容相似性度量权重更大的融合相似性度量时, FRLN会倾向于选择所有近邻的背景特征块, 这会导致包含边缘信息的特征块未被选择, 然而边缘特征块在提取结构关系特征时具有关键作用.当采用相对距离权重更大的融合相似性度量时, 因为对相对距离更敏感, FRLN更倾向于选择相对距离较近的特征块, 边缘信息更完整.在相对距离度量的基础上加入内容相似性度量, 可更好地优化网络对行人边缘特征的提取.因此, 本文认为α 的最优值在[0, 0.5]区间内.基于实验结果, 选择将2种相似性度量以相等的权重进行融合, 即α =0.5.
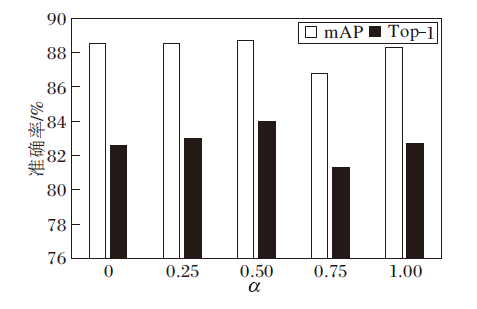 | 图5 融合权重α 对FRLN的影响Fig.5 Effect of fusion weight α on FRLN |
不同图卷积神经网络层数L对FRLN的影响如图6所示.当L=2时, 即图卷积神经网络只有输入层和输出层时, 效果最优; 当L=3时, 即输入层和输出层中间还含有一个隐含层时, 效果有所下降; 当L=4时, 即网络中有两个隐含层时, 发现网络并未收敛.根据实验结果, 本文认为当图卷积神经网络中隐含层过多时, 可能也存在类似于卷积神经网络中的梯度爆炸和梯度消失的问题, 因此取L=2.
 | 图6 图卷积神经网络层数L对FRLN的影响Fig.6 Effect of layers of graph convolution network L on FRLN |
针对基于图卷积神经网络的行人重识别中存在的特征块语义信息不显著和构图时仅依赖特征块相对距离的问题, 本文提出融合关系学习网络.采用最大注意力模型解决特征块语义信息不显著的问题, 采用融合相似性度量在构图时同时考虑特征块的相对距离和内容相似性.iLIDS-VID、MARS数据集上的实验验证本文网络的有效性.
由于本文仅采用欧氏距离度量特征块之间的内容相似性, 将特征块的所有特征维度分配平均权重, 因此, 本文认为通过采用马氏距离或其它不受量纲影响的内容相似性度量方法, 可进一步优化图卷积神经网络的构图方式.除此之外, 研究中并未考虑行人姿态, 行人姿态的结构化信息更明显, 特征块之间的关系更直观.在构图过程中加入对行人姿态的考虑, 提取更具辨识度的行人结构关系特征, 也是一个值得研究的方向.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|