
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于去冗余特征和语义关系约束的零样本属性识别
[张桂梅1  , 龙邦耀
, 龙邦耀1 , 曾接贤1 , 黄军阳1 ]
, 龙邦耀|
|



作者简介:

龙邦耀,硕士研究生,主要研究方向为计算机视觉、图像处理、模式识别.E-mail:609527215@qq.com. 
曾接贤,硕士,教授,主要研究方向为计算机视觉、图像处理、模式识别.E-mail:zengjx58@163.com. 
黄军阳,硕士研究生,主要研究方向为计算机视觉、图像处理、模式识别.E-mail:mike1160554026@163.com.
基于生成式的零样本识别方法在生成特征时受冗余信息和域偏移的影响,识别精度不佳.针对此问题,文中提出基于去冗余特征和语义关系约束的零样本属性识别方法.首先,将视觉特征映射到一个新的特征空间,通过互相关信息对视觉特征进行去冗余处理,在去除冗余视觉特征的同时保留类别的相关性,由于在识别过程中减少冗余信息的干扰,从而提高零样本识别的精度.然后,利用可见类和不可见类之间的语义关系建立知识迁移模型,并引入语义关系约束损失,约束知识迁移的过程,使生成器生成的视觉特征更能反映可见类和不可见类之间语义关系,缓解两者之间的域偏移问题.最后,引入循环一致性结构,使生成的伪特征更接近真实特征.在数据集上的实验证实文中方法提高零样本识别任务的精度,并具有较优的泛化性能.
About Author:
LONG Bangyao, master student. His research interests include computer vision, image processing and pattern recognition.
ZENG Jiexian, master, professor. His research interests include computer vision, image processing and pattern recognition.
HUANG Junyang, master student. His research interests include computer vision, image processing and pattern recognition.
The generative zero shot recognition method is affected by redundant information and domain shifting while generating features, and thus its recognition accuracy is poor. To deal with the problem, a zero shot attribute recognition method based on de-redundant features and semantic relationship constraint is proposed. Firstly, the visual features are mapped to a new feature space, and the visual features are de-redundant via cross-correlation information. The redundant visual features are removed with the correlation of the categories preserved. The accuracy of zero shot recognition is improved due to the reduction of redundant information interference in the recognition process. Then, a knowledge transfer model is established using the semantic relationship between the seen and unseen classes, and the loss of semantic relationship is introduced to constrain the process of knowledge transfer. Consequently, the semantic relationship between the seen and unseen classes is reflected better by the visual features generated by the generator ,and the problem of domain shifting between them is alleviated as well. Finally, the cycle consistency structure is introduced to make the generated pseudo-features closer to the real features. Experiments on datasets show that the proposed method improves the accuracy of zero shot recognition tasks with better generalization performance.
本文责任编委 吴 飞
Recommended by Associate Editor WU Fei
近年来, 随着深度卷积神经网络的发展, 目标识别的精度得到提升[1].目前, 基于卷积神经网络(Convolution Neural Networks, CNN)方法最大的缺点是需要大量有标签的训练数据集, 而训练数据集标签的收集和标注费时费力.为了缓解该问题, Larochelle等[2]提出零样本学习(Zero-Shot Learning, ZSL)的概念.零样本学习是迁移学习的一种特殊形式, 关键思想是通过学习训练样本和测试样本之间的知识迁移, 使计算机视觉系统逐渐摆脱对大量有标签训练数据的依赖.
零样本学习通过对可见类样本的学习, 根据可见类与不可见类高层特征间的相关性, 达到对不可见类样本进行识别的目的.可见类表示带标签的类别, 不可见类表示未带标签的类别, 可见类和不可见类是互斥的.零样本学习广泛应用于计算机视觉的各个领域, 如指纹识别、交通场景识别、自然语言处理等.
早期的零样本学习是找到一个可见类和不可见类的公共语义空间, 弥补可见类与不可见类之间的语义鸿沟.零样本学习常用的语义空间包含文本描述和属性两种.文本描述通常容易从维基百科中获取, 成本较小.近年来学者们对于基于文本的语义空间[3, 4, 5, 6, 7]研究较深入.属性是语义特征的集合, 连接训练样本和测试样本, 在ZSL中具有重要的作用.Lampert等[8]提出直接属性预测(Direct Attribute Pre-diction, DAP), 先估计输入图像的属性, 再根据属性相似度值确定类别标签, 但分类的正确类别较少.针对该问题, Frome等[9]提出深度视觉语义嵌入(Deep Visual-Semantic Embedding, DeViSE), 引入双线性兼容函数, 度量图像和标签之间的兼容性, 提升分类的正确率.Romera-Paredes等[10]提出ESZSL(Embarra-ssingly Simple Approach to Zero-Shot Learning), 将特征、属性和类别之间的关系建模为两个线性层网络, 解决可见类和不可见类之间的分类偏差.Change-pinyo等[11]提出用于零样本学习的合成分类器(Synthesized Classifiers for Zero-Shot Learning, SY-NC), 对齐语义特征空间与视觉特征空间, 解决可见类与不可见类之间相关性较低导致分类精度低下的问题.
不同于上述方法以语义空间作为嵌入空间, Zhang等[12]提出DEM(Deep Embedding Model), 从语义到视觉空间的反向映射, 将视觉空间作为嵌入空间, 在视觉空间中使用最近邻分类, 缓解分类中心差异较大的问题.吴凡等[13]提出基于属性平衡正则化的端到端零样本学习框架, 解决不可见类在训练过程中缺少足够正样本的问题.张鲁宁等[14]总结基于属性的方法, 指出基于属性的零样本学习在识别分类研究中需要解决的问题及未来的发展方向.
针对知识迁移过程中产生严重的域偏移问题, Yao等[15]提出基于引导的属性偏移消除模块, 首先消除视觉上的差异, 再提出注意力图的属性嵌入算法, 利用图网络获取类别之间的语义关系, 减少视觉上的差异, 进一步缓解域偏移问题.
早期的零样本学习方法主要是建立视觉和语义特征空间之间的跨模态映射函数.但是, 由于视觉和语义之间存在较大的模态鸿沟, 容易造成语义信息丢失的问题, 故早期的零样本识别方法对不可见类进行识别时精度不够理想.
由于生成对抗网络(Generative Adversarial Net-work, GAN)[16]在图像生成、图像编辑和表示学习方面的良好效果, 因此针对早期零样本识别精度较低的问题, 学者们提出基于GAN的零样本识别方法.Xian等[17]提出特征生成对抗网络(Feature GAN, FGAN), 结合WGAN(Wasserstein GAN)[18]与分类器, 生成具有足够类别信息的特征, 并使用该特征训练softmax分类器.Verma等[19]提出通过合成样本的广义零样本学习(Generalized ZAL via Syn-thesized Examples, SE-GZSL), 基于变分自编码器的框架, 从给定的可见类属性和不可见类属性中生成新的样本, 缓解零样本识别中存在的域偏移问题.
但是上述方法仅采用生成对抗网络, 并不能保证生成的伪视觉特征和真实视觉特征更接近.针对该问题, Felix等[20]提出cycle-CLSWGAN(cycle-Con-sistent WGAN), 重建网络, 将生成的伪视觉特征重建为语义特征, 并使用重建损失对生成器进行正则化约束, 确保生成的伪视觉特征更接近真实视觉特征.Saeiyildiz等[21]提出梯度匹配生成网络(Gradient Matching Generative Networks, GMN), 仅根据不可见类的类嵌入生成对应的训练样本, 并使用梯度匹配损失度量生成样本, 可将零样本识别问题简化为一个有监督的分类任务.Li等[22]提出利用边缘信息的生成式零样本学习(Leveraging the Invariant Side of Generative ZSL, LisGAN), 引入灵魂样本(Soul Sam-ples), 对每个类别样本最具语义意义的部分进行可视化, 并使用两个以级联的方式进行设置的分类器, 达到由粗到细的识别过程.
基于双向映射的生成模型性能较优, 但是现有方法只能访问可见类别的底层数据, 无法访问不可见类的底层数据.针对该问题, Shermin等[23]提出利用可见类和不可见类的类语义, 通过视觉-语义耦合学习双域联合分布, 在合成的图像中保留独特信息, 减少对可见类的偏移, 使生成特征更接近真实特征, 从而缓解域偏移问题.生成特征的质量取决于模型获取底层数据的能力.因此, Chandhok等[24]提出两级联合的最大化思想, 在训练中使用一个推理网络, 用于增强生成网络, 有助于模型更好地获取底层数据.
由于域偏移问题的存在, 特征在知识迁移的过程中会存在一定程度的语义丢失, 针对该问题, Xiang等[25]提出ZSL生成方法, 使用多知识的语义特征作为输入, 自适应融合不同知识域的视觉特征, 训练更相关的语义特征进行语义到视觉的嵌入, 可使语义信息更丰富, 改善识别性能.生成式的零样本识别方法可较高地提升零样本学习任务的性能, 但由于不可见类的特征缺乏多样性, 训练的分类器性能不够理想, 存在严重的泛化问题.针对该问题, Li等[26]提出多样化特征合成模型.与以往只利用语义知识的方法不同, 多样化特征合成统一视觉知识和语义知识, 得到特定类的多特征样本, 并在测试阶段利用鲁棒的分类器识别可见类和不可见类.多样化特征合成在对齐的空间中表示视觉和语义知识, 能以低复杂度的方式产生较好的特征样本.
生成模型是解决零样本识别问题的常用方法, 近年来取得较大进展, 但是零样本识别的生成模型仍存在一些局限性.首先, 受零样本识别中的域偏移问题影响, 生成的不可见类伪视觉特征与真实视觉特征之间存在较大偏差, 分类器往往容易将不可见类错误归类为可见类, 导致零样本识别的精度下降.其次, 现有的生成式零样本识别方法通常是在细粒度数据集上进行识别, 因为细粒度的类别在语义上是相关的, 不同细粒度类别的图像在外观上较相似, 但是细微的差异都影响零样本识别的精度.这是因为在对这些数据集上的类别进行识别时, 其中的细粒度图像往往包含一些非判别性的冗余信息.此外, 现有的生成式零样本识别方法均使用可见类样本进行训练, 使用不可见类样本进行测试, 因此, 不能保证生成的伪视觉特征与输入的真实视觉特征的分布更接近.
针对上述问题, 本文提出基于去冗余特征和语义关系约束的零样本属性识别方法(Zero-Shot Attri-bute Recognition Based on De-redundancy Features and Semantic Relationship Constraint, RS-ZSAR).首先, 提出基于可见类和不可见类间语义关系的生成方法, 使用语义关系约束损失将可见类的信息迁移到不可见类生成的视觉特征中, 在一定程度上缓解ZSL中的域偏移问题.再将生成的伪视觉特征映射到新的特征空间, 基于映射后的视觉特征和原视觉特征之间的相关性约束, 减少视觉特征中的冗余信息, 保留原视觉特征中的类别信息, 提高零样本识别效果.最后, 引用循环一致性损失[27], 使生成的伪特征与输入的真实特征更接近, 进一步缓解域偏移问题, 提高识别精度.在AWA、CUB、SUN、APY标准数据集上的实验表明, 本文方法精度较高.此外, 在图像检索和基于文本的识别任务上进行泛化性能验证, 实验结果进一步表明本文方法具有较好的泛化能力, 容易拓展到其它应用中.
本文涉及的符号表示如表1所示.
| 表1 本文的符号表示 Table 1 Description of symbols |
在零样本学习中, 已知可见类样本集S和不可见类样本集U, S和U不相交, 即S∩ U=Ø , 训练集的类标签与测试集的类标签也互不相交.一方面, 定义一个由可见类样本的视觉特征、语义特征和标签组成的训练集{(xi,
本文工作是在文献[22]的基础上展开的, 该文献采用WGAN作为主干网络.由于CTGAN(Consistency Term WGAN)[28]在WGAN-GP(WGAN-Gradient Penalty)[29]的基础上增加一致性项(Consistency Term), 能有效约束真实样本附近的梯度, 加强数据样本附近的Lipschitz连续性, 并继承WGAN可抑制模式崩溃的特性, 故本文采用CTGAN代替WGAN作为主干网络.
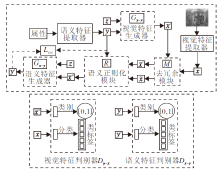
本文方法包括视觉特征生成网络和语义特征生成网络.一方面, 将属性生成的视觉特征映射到一个新的去冗余特征空间, 去除冗余的视觉特征, 保留类别相关性, 保证在去除视觉特征冗余信息的同时不丢失类别信息, 减少冗余信息的干扰, 提高零样本识别的精度.另一方面, 利用可见类和不可见类之间的语义关系建立知识迁移模型, 引入语义关系约束损失进行知识迁移, 使生成器生成可反映可见类和不可见类之间语义关系的视觉特征, 在一定程度上缓解生成模型的域偏移.此外, 引入循环一致性结构, 进一步使生成的特征更接近真实特征.本文方法网络结构如图1所示.
 | 图1 本文方法网络结构Fig.1 Network structure of the proposed method |
由图1可见, 将属性输入语义特征提取器, 提取对应的语义特征y, 作为真实语义特征.将图像输入到视觉特征提取器提取图像的视觉特征x, 作为真实视觉特征.将真实语义特征y和随机噪声z同时输入视觉特征生成器Gy-x中, 得到相应的伪视觉特征x'.再将伪视觉特征x'和真实视觉特征x输入去冗余模块中进行去冗余处理, 得到相应去冗余后的视觉特征$\widetilde{x}'$和$\widetilde{x}$.然后, 将去冗余后的视觉特征输入语义关系约束模块中, 利用语义关系约束损失对知识迁移过程进行监督, 使可见类的知识更有效地迁移到不可见类中, 并得到语义关系约束后的伪视觉特征$\widetilde{x}″$. 最后, 为了使生成的伪特征更接近真实特征, 将伪视觉特征$\widetilde{x}″$和随机噪声z同时输入到语义特征生成器中, 得到伪语义特征y', 使用循环一致性损失函数约束真实语义特征y和伪语义特征y'.
使用视觉特征判别器Dy-x对真实视觉特征x和伪视觉特征$\widetilde{x}″$进行判断和分类.使用语义特征判别器Dx-y对真实语义特征y和伪语义特征y'进行判断和分类.
视觉特征生成网络主要包含语义特征提取器、视觉特征生成器和视觉特征判别器.
语义特征提取器的作用是对输入属性进行预处理, 并提取该属性的语义特征.本文使用一个全连接(Full Connection, FC)层作为属性特征提取器.该全连接层是语义特征编码器, 将输入的属性进行特征编码, 得到该属性对应的语义特征, 作为真实语义特征.
视觉特征生成器的作用是将语义特征生成相应的伪视觉特征.该生成器由简单的编码器组成, 包括两组卷积模块、两组全连接模块和一个Tanh激活函数.卷积模块由一个卷积层、一个最大池化层和一个归一化层组成.全连接模块由一个全连接层和一个Leaky ReLU组成.将语义特征提取器提取的语义特征和随机噪声同时输入视觉特征生成器, 得到伪视觉特征.
视觉特征判别器的作用是对生成的伪视觉特征与真实视觉进行判断和分类.该判别器包含两个分支:一个分支用于0/1的真假判断, 另一个分支用于对输入视觉特征的类别进行分类.第一个分支的网络结构包含一组全连接模块和一个二路的全连接层.另一个分支的网络结构包含一组全连接模块和一个n路的全连接层.
语义特征生成网络主要包含视觉特征提取器、语义特征生成器和语义特征判别器.
视觉特征提取器的作用是对输入图像进行预处理, 提取视觉特征.本文使用ResNet-101作为视觉特征提取器, 提取2 048维的视觉特征, 并作为真实视觉特征.
语义特征生成器的作用是将视觉特征生成相应的伪语义特征.该生成器包括两组全连接模块和一个全连接层.全连接模块由一个全连接层、一个Leaky ReLU组成.将视觉特征和随机噪声同时输入语义特征生成器, 得到对应的伪语义特征.
语义特征判别器作用是对生成的伪语义特征与真实语义特征进行判断和分类.该判别器与视觉特征判别器的网络结构相同, 也包括两个分支:一个分支用于0/1的真假判断, 另一个分支用于对输入语义特征的类别进行分类.
1.3.1 视觉特征生成损失
本文的视觉特征生成网络框架是带辅助信息的条件CTGAN, 损失函数包含视觉特征生成器损失和视觉特征判别器损失.
将可见类的属性输入语义特征编码器φ 中, 使用一个全连接层作为语义特征编码器, 并提取对应的语义特征φ (α ), 用y表示.将其与噪声z同时输入到视觉特征生成器Gy→ x中, 生成相应的伪视觉特征, 即x'=Gy→ x(y, z), x'表示生成的伪视觉特征.视觉特征生成器将不可见类的语义特征生成相应的伪视觉特征, 但生成的伪视觉特征包含大量的冗余信息.为了减少冗余信息对识别精度的影响, 本文提出去冗余特征模块, 去除视觉特征中的冗余信息.去冗余的目标是对去冗余后的视觉特征$\widetilde{x}'$和伪视觉特征x'之间的相关性进行约束, 实现对x'中冗余信息的去除.
本文采用Alemi等[30]的互相关信息(Mutual Information, MI)衡量视觉特征间的相关性.使用I($\widetilde{X}’$; X')表示2个随机变量之间的互相关信息, 以约束$\widetilde{X}’$和X'之间信息的传递, 提取x'中去冗余后的信息.去冗余信息

其中
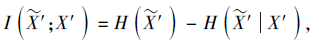
X'表示生成的伪视觉特征x'的集合, $\widetilde{X}’$表示去冗余后的视觉特征$\widetilde{X}’$的集合, H(· )表示求信息熵.等式右边表示信息约束函数, DKL表示Kullback-Leibler (KL)散度, pM($\widetilde{X}’$|x')表示去冗余特征$\widetilde{X}’$的条件分布, r($\widetilde{X}’$)表示去冗余特征$\widetilde{x}'$的边缘分布.
式(1)确定x'有多少信息传送到$\widetilde{X}’$.但是, 仅去除冗余信息并不能保证获得较好的零样本识别结果, 去冗余面临的主要问题是如何在去除冗余特征的同时保留类别信息.
为了消除去冗余后的视觉特征和语义特征之间的语义鸿沟, 将语义空间作为去冗余特征空间, 然后将去冗余后的伪视觉特征映射到该语义空间.通过使用映射函数M将视觉特征映射到该语义空间中, 类似于传统的语义嵌入方法.因此, 本文去冗余后的视觉特征映射到语义空间中, 即

其中, y表示x'对应的语义特征, y'表示除y以外随机选择的其它类的语义特征, Δ 表示使映射函数M更鲁棒的临界值, $\widetilde{X}’$表示去冗余后的视觉特征.
不同于传统语义嵌入方法, 本文设置上界阈值b, 通过对$\widetilde{X}’$限制一个上界, 在去除冗余视觉特征的同时使式(1)中的信息约束函数低于该阈值, 保留原始特征中的类别信息.有界互相关信息约束
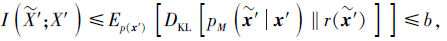
其中, b表示上界阈值, 经多次实验取值为0.1.
为了验证通过映射函数M获得的去冗余特征的类别信息具有识别性, 利用可见类的视觉特征对映射函数M进行约束, 使可见类数据的类别关系也可较好地保留在去冗余后的视觉特征空间中.本文使用文献[31]的中心损失对映射函数M进行约束, 约束损失
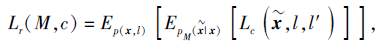
其中, c表示类别的聚类中心, l表示x对应的类标签, l'表示除x以外随机选择的其它类的类标签, $\widetilde{X}$表示可见类数据的去冗余特征.

表示使用文献[31]方法计算得到的中心损失.
现有的生成式零样本学习方法在预测分类概率时, 由于存在域偏移, 容易将不可见类的类别分类为可见类的类别.因此, 本文提出语义关系约束损失, 用于解决该问题, 即利用一个新的正则化损失对可见类和不可见类之间的语义关系进行约束, 从而在语义中正确迁移可见类的信息, 用于指导方法生成不可见类的视觉特征.
视觉空间和语义空间共享同一个公共的潜在空间, 用于生成视觉特征和语义特征.本文提出利用视觉空间和语义空间的这种关系, 将知识从语义空间迁移到视觉空间, 生成不可见类的图像特征.使用余弦距离计算类别的相似度, 对于类别ci和cj, 使用φ sim(
对于语义相似度, 由于每个类别只有一个语义, 因此未计算类c中语义特征的均值.由于相同的两个类别间的语义特征相似度往往大于视觉特征相似度, 本文使用
η sim(
对去冗余的视觉特征进行语义关系的约束, 其中, α ij表示用于加强类i和类j的特征之间相似度的临界值, 经过多次实验, α ij=0.15.
本文应用文献[32]的惩罚方法对类特征间的相关性进行约束.文献[32]的惩罚方法如下:
其中惩罚参数
对于可见类, 约束函数

其中, i表示可见类的取值, j表示与可见类相似性最高的集合中的取值,
对于不可见类, 约束函数
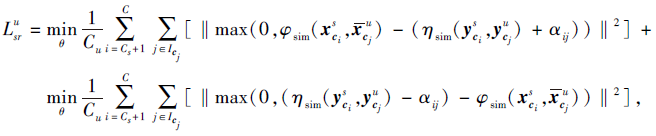
其中,
视觉特征生成器损失表示如下:
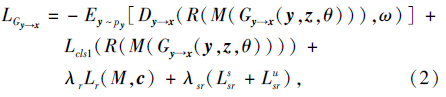
其中, py表示真实语义特征的特征分布, px表示真实视觉特征的特征分布, θ 表示生成器Gy→ x的超参数, ω 表示判别器Dy→ x的超参数, λ r表示去冗余约束损失的超参数, λ sr表示语义关系约束损失的超参数.
式(2)右边第1项表示语义关系约束后的去冗余伪视觉特征的Wasserstein距离, 第2项表示该视觉特征的分类损失, 第3项表示去冗余的约束损失, 第4项表示语义关系约束损失.
将语义关系约束后的去冗余伪视觉特征与从可见类提取的真实视觉特征输入到判别器中进行判断和分类, 视觉特征判别器的损失函数表示如下:
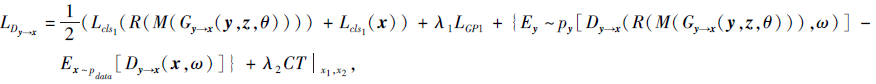
其中, λ 1表示梯度惩罚系数, λ 2表示一致性项的超参数,
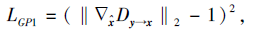
$\hat{x}$表示伪视觉特征$\widetilde{x}″$和真实视觉特征x之间的线性插值,
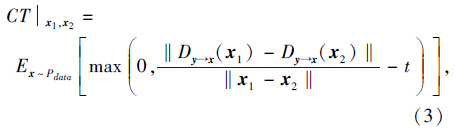
x1、x2表示真实样本附近的扰动数据, t表示一个固定常数.
CTGAN在WGAN-GP的基础上增加一致性项, 目的是约束真实分布样本的梯度, 加强数据样本分布附近的Lipschitz连续性, 并继承WGAN抑制模式崩溃的特性.
式(3)右边第1项表示视觉特征的分类损失, 第2项表示Lipschitz梯度惩罚项, 第3项表示语义关系约束后的去冗余伪视觉特征$\widetilde{x}″$和真实视觉特征x之间的Wasserstein距离, 第4项表示CTGAN损失函数中的一致性项.
1.3.2 语义特征生成损失
与视觉特征生成网络类似, 语义特征生成损失由语义特征生成器损失和语义特征判别器损失组成.
语义特征生成器的目标是生成更接近于真实语义特征的伪语义特征.将经过语义关系约束的去冗余伪视觉特征$\widetilde{x}″$和高斯随机噪声z同时输入到语义特征生成器中, 得到相应的伪语义特征.语义特征生成器Gx→ y的损失函数表示为

其中, pz表示服从高斯分布的随机噪声分布, δ 表示Gx→ y的超参数, ζ 表示Dx→ y的超参数.
式(4)右边第1项表示伪语义特征的Wasserstein距离, 第2项表示伪语义特征的分类损失.
将语义特征生成器生成的伪语义特征和真实语义特征输入判别器中进行判断和分类, 语义特征判别器的损失函数表示为
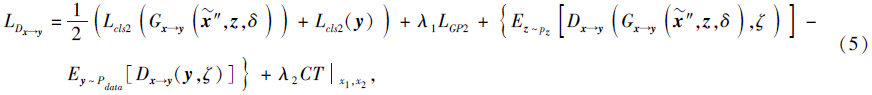
其中, λ 1表示梯度惩罚系数, λ 2表示一致性项的超参数.
式(5)右边第1项表示语义特征分类损失, 可有效保留语义信息.第2项中LGP2表示以与视觉特征判别器相同的方式计算的梯度惩罚, 第3项表示生成的伪语义特征和真实语义特征的Wasserstein距离, 第4项表示CTGAN损失函数中的一致性项.
1.3.3 循环一致性损失
为了使生成的伪视觉特征与输入的真实视觉特征更接近, 本文引入循环一致性损失以正则化视觉特征生成器, 循环一致性损失表示为
Lcyc=λ
其中, λ 表示循环一致性损失的权重超参数, B表示批尺寸大小的值, 通过多次实验取512, y表示真实语义特征, x表示真实视觉特征, θ 表示视觉特征生成器的超参数, δ 表示语义特征生成器的超参数.
1.3.4 总损失
本文利用可见类和不可见类之间的语义关系对去冗余后的视觉特征进行约束, 即约束视觉特征生成器
L=
本文方法的最终目标是最小化总损失函数, 提高不可见类语义属性的识别精度.
输入不可见类的属性, 通过语义特征编码器提取语义特征
由于本文方法可基于语义特征生成相应的伪视觉特征, 故容易拓展到其它应用中, 如零样本图像检索、基于文本的零样本识别和图像语义分割[33]等领域.
本文实验的硬件环境为Intel i7-9700K CPU、RTX 2080Ti GPU; 软件环境为Ubuntu 18.04 LTS操作系统、cuda 9.2.0、cudnn 7.5.0.深度学习算法框架为PyTorch 1.4.0, 识别模型的训练和测试均在PyTorch环境下完成.
在训练过程中, 选用LisGAN[22]作为Baseline与本文方法进行对比.参照文献[22], 将批尺寸大小设置为512, 学习率设置为0.000 1, 分类损失权重参数设置为0.2, 学习衰减率设置为0.95, 中心损失的权重参数设置为0.1, 梯度惩罚超参数λ 1=10, 一致性项的超参数λ 2=2.使用Adam(Adaptive Moment Estimation)优化器优化各部分网络参数.
在Animal with Attributes(AWA)、Caltech-UC-SD-Birds(CUB)、Scene Understanding(SUN)、A Pascal-a Yahoo(APY)这4个基于属性的数据集上进行实验.
AWA数据集是一个中等规模的细粒度动物数据集, 拥有50个动物类别, 每类有 85维属性注释, 样本总数为30 475.随机选取40类作为有标签的训练集, 其余10类作为无标签的测试集.对于语义特征, 使用语义编码器提取的语义特征维数为85.对于视觉特征, 利用ResNet-101作为视觉特征提取器, 提取2 048维的视觉特征作为真实视觉特征.
CUB数据集是一个中等规模的细粒度鸟类数据集, 拥有200个鸟类, 每类有312维注释属性, 样本总数为11 788.随机选取150类作为有标签的训练集, 其余50类作为无标签的测试集.对于语义特征, 使用语义编码器提取的语义特征维数为312.对于视觉特征, 利用ResNet-101作为视觉特征提取器, 提取1 024维的视觉特征作为真实视觉特征.
SUN数据集是一个中等规模的场景类型数据集, 拥有717个场景类别, 每类有102维注释属性, 样本总数为14 340.随机选取645类作为有标签的训练集, 其余72类作为无标签的测试集.对于语义特征, 使用语义编码器提取的语义特征维数为102.对于视觉特征, 利用ResNet-101作为视觉特征提取器, 提取2 048维的视觉特征作为真实视觉特征.
APY数据集包含来自于PASCAL VOC 2008和Yahoo图像搜索库中的32个类别, 每类有64维注释属性, 其中20类来自PASCAL、12类来自Yahoo图像库, 样本总数为15 339.将PASCAL VOC 2008中的20类设置为有标签的训练集, Yahoo图像库中的12类设置为无标签的测试集.使用语义编码器提取的语义特征维数为64; 利用ResNet-101作为视觉特征提取器, 提取1 024维的视觉特征作为真实视觉特征.
为了测试语义关系约束损失、去冗余的约束损失和循环一致性损失对本文方法性能的影响, 在AWA、CUB、SUN、APY数据集上进行消融实验.除了与LisGAN对比以外, SR表示为仅采用语义关系约束损失, REF表示为去冗余的约束损失, CYC表示为循环一致性损失, SR+CYC表示联合使用语义关系约束和循环一致性结构, REF+CYC表示联合使用去冗余约束和循环一致性结构, SR+CYC+REF表示联合使用语义关系约束、循环一致性结构和去冗余约束, 即为本文方法(RS-ZSAR).实验结果如表2所示, 表中黑体数字表示最优结果.
| 表2 在4个数据集上的消融实验结果 Table 2 Results of ablation experiments on 4 datasets % |
由表2可知, 每种策略对本文方法的识别精度均有一定的提升, 但是去冗余的约束损失对精度提升贡献最大.在AWA数据集上, 仅增加去冗余的约束损失得到的识别精度比LisGAN提高1.1%.由于知识从可见类到不可见类的迁移容易受到主观因素的限制, 导致语义关系约束的效果不够理想.通过多次组合实验可知, 本文方法将循环一致性损失、语义关系约束损失和去冗余的约束损失同时引入LisGAN中, 所以识别精度更高.
为了验证本文方法的有效性, 在AWA、CUB、SUN、APY数据集上进行实验.选择如下对比方法法:GAZSL(A Generative Adversarial Approach for Zero-Shot Learning from Noisy Texts)[5]、DAP[8]、DeViSE[9]、ESZSL[10]、SYNC[11]、DEM[12]、F-GAN[17]、cycle-CLSWGAN[20]、LisGAN[22].各方法的零样本属性识别精度如表3所示, 表中黑体数字表示最优结果.
| 表3 各方法在4个数据集上的零样本属性识别精度 Table 3 Accuracy of zero-shot attribute recognition of different methods on 4 datasets % |
由表3可见, DAP、DeViSE、ESZSL、DEM、SYNC由于是传统的零样本识别方法, 识别精度低下.GAZSL、cycle-CLAWGAN、F-GAN、LisGAN为基于GAN的方法, 识别精度有一定的提升, 表明GAN对零样本识别方法的性能有较大的促进作用.
GAZSL直接使用GAN对属性进行识别, 相比传统的零样本识别方法, 精度又有所提高.cycle-CLSWGAN在GAZSL的基础上增加循环一致性结构, 对不可见类的识别精度高于GAZSL.
LisGAN在F-GAN的基础上增加边缘信息和灵魂样本的学习, 识别精度高于F-GAN.RS-ZSAR在LisGAN基础上结合循环一致性结构和CTGAN, 约束生成的视觉特征, 去除冗余信息, 并利用可见类和不可见类之间的语义关系对无冗余的视觉特征进行学习, 使生成器生成的伪视觉特征更接近于真实视觉特征, 所以识别精度高于LisGAN.相比LisGAN, 在AWA、CUB、SUN、APY数据集上, RS-ZSAR的识别精度分别提高1.6%、1.5%、1.1%、2.5%.
传统零样本学习方法通常将测试样本限制在不可见类中, 即测试样本与训练样本无交集.传统零样本学习的测试阶段设置的条件过于严格, 不能真实反映目标识别的情景.因为在实际场景中, 测试样本通常会包括可见类样本和不可见类样本, 因此将这种任务称为广义零样本学习任务[34].广义零样本学习(Generalized ZSL, GZSL)主要思想是对测试样本的来源进行更宽松的假设, 即测试样本可来源于任意的目标类别.
一个行之有效的零样本学习应既能识别可见类样本, 也能识别不可见类样本.在广义零样本识别任务中, 测试阶段同时使用可见类样本和不可见类样本对方法进行测试.实验目的是为了验证本文方法在广义零样本识别任务上的有效性.
在AWA、CUB、SUN、APY数据集上进行实验.对比方法如下:GAZ-SL[5]、DAP[8]、DeViSE[9]、ESZ- SL[10]、DEM[12]、 F-GAN[17]、 SE-GZSL[19]、GMN[21]、LisGAN[22].各方法的广义零样本属性识别精度如表4所示, 表中黑体数字表示最优结果.
| 表4 各方法在4个数据集上广义零样本属性识别精度 Table 4 Accuracy of generalized zero-shot attribute recognition of different methods on 4 datasets % |
基于属性的广义零样本识别精度通常使用调和平均值H进行评估:
H=
其中, U表示不可见类, S表示可见类.由表4可看出, RS-ZSAR在广义零样本识别任务中的精度高于LisGAN.相比LisGAN, 在AWA、CUB、SUN、APY数据集上, RS-ZSAR的识别精度分别提高4.0%、3.6%、2.8%、1.9%.故RS-ZSAR不仅适合于零样本识别任务, 也适合于广义零样本识别任务.
2.5.1 超参数的选择
为了得到最佳超参数, 在AWA、CUB、SUN、APY数据集上对基于零样本识别任务的不同超参数值进行评估.
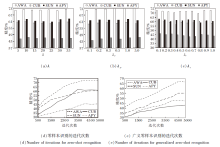
首先, 在4个数据集上对比式(6)中的循环一致性损失系数λ , λ 不同时SR-ZSAR精度变化如图2(a)所示.当λ < 10时, 随着λ 的增加, 精度呈现上升趋势; 当λ > 10时, 曲线呈下降趋势, 即当λ =10时, 精度达到最高.故本文选择λ =10.
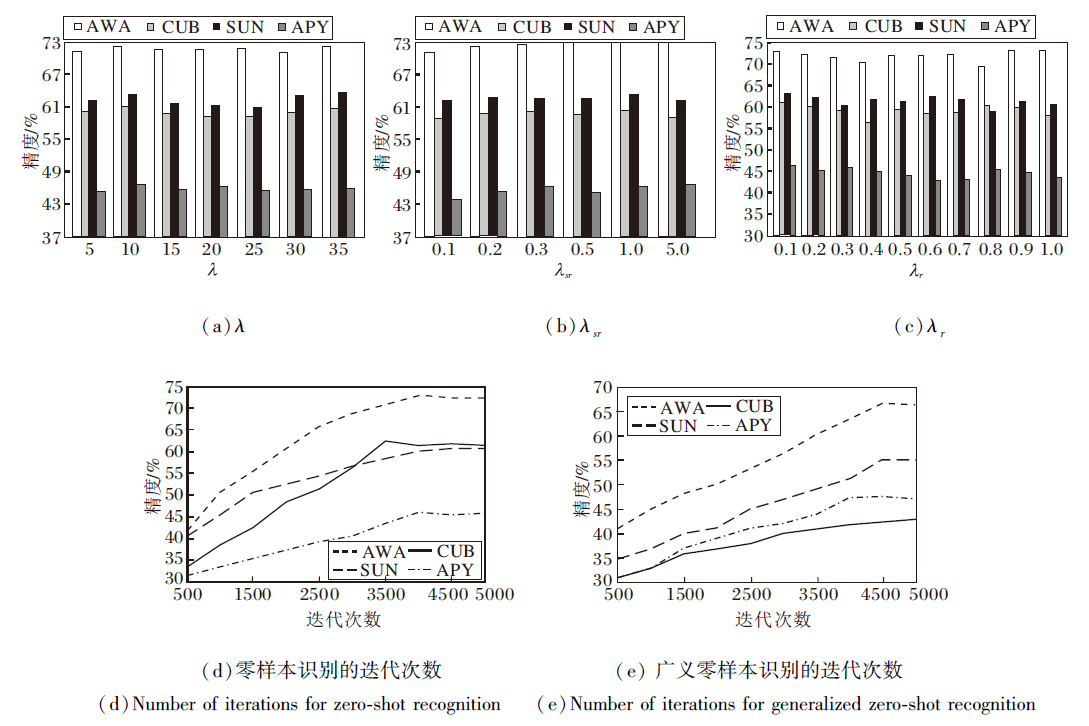 | 图2 超参数值不同时RS-ZSAR在4个数据集上的精度Fig.2 Accuracy of RS-ZSAR with different hyperparameter values on 4 datasets |
然后, 统计式(2)中的语义关系约束损失系数λ sr, λ sr不同时SR-ZSAR的精度变化如图2(b)所示.由图可知, 在λ sr取不同值时, SR-ZSAR的精度无明显波动, 即对λ sr不是很敏感, 当λ sr=0.25时, 精度相对较高.故本文选择λ sr=0.25.
再分析式(2)中的去冗余约束损失系数λ r, λ r不同时SR-ZSAR的精度变化如图2(c)所示.由图可知, 精度整体呈下降趋势, 即λ r取值越大, 精度越低, 而λ r=0.1时, 识别精度最高.故本文选择λ r=0.1.
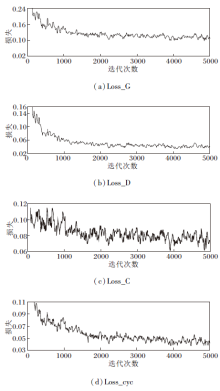
最后, 在4个数据集上统计RS-ZSAR的收敛迭代次数.采用多次实验求平均值的方式, 结果如图2(d)、(e)所示.由于本文方法的网络结构较简单, 在训练过程中梯度收敛速度较快, 当迭代次数达到4 000时, 本文方法趋于收敛.而对于广义零样本识别, 迭代次数在4 500~5 000时, 性能保持稳定, 故选择迭代次数为5 000次.
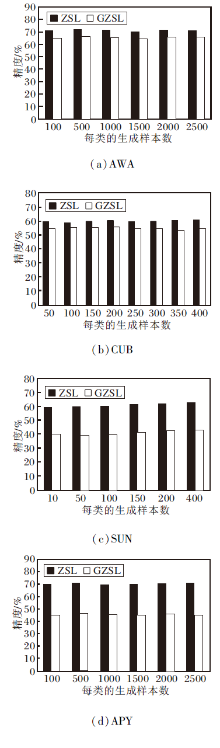
2.5.2 生成样本的数量
为了验证不可见类生成样本的数量对SR-ZSAR识别性能的影响, 在AWA、CUB、SUN、APY数据集上对每个类别不同的生成样本数进行评估, 如图3所示.
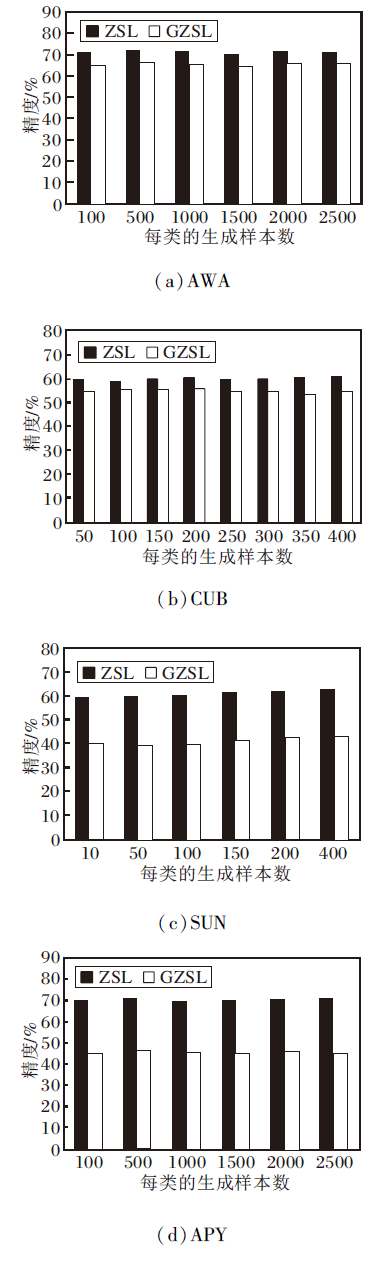 | 图3 每类的生成样本数不同时SR-ZSAR的精度对比Fig.3 Accuracy comparison of SR-ZSAR with different number of generated samples of each class |
如图3(a)所示, 在AWA数据集上, 当生成样本的数量为500时, ZSL和GZSL的识别精度均达到最高值, 随着生成样本数量的增加, ZSL和GZSL的识别精度整体出现下降.故在AWA数据集上, 每个类别生成样本的数量选择500个.同理得出在CUB数据集上, ZSL的生成样本数量最佳为400个, GZSL的生成样本数量最佳为150个.在SUN数据集上, 每个类别生成样本的最佳数量为400个.在APY数据集上, 每个类别生成样本的数量为500个.
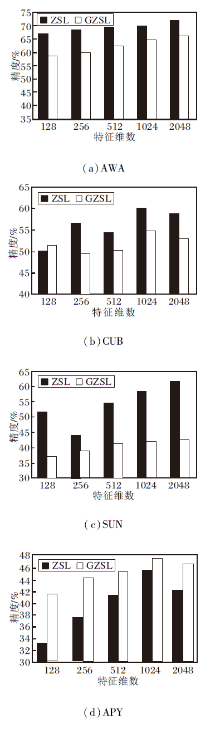
2.5.3 去冗余后的特征维数
为了验证不可见类生成样本的去冗余后特征维数对RS-ZSAR性能的影响, 在AWA、CUB、SUN、APY数据集上对去冗余后的特征维数进行评估, 如图4所示.
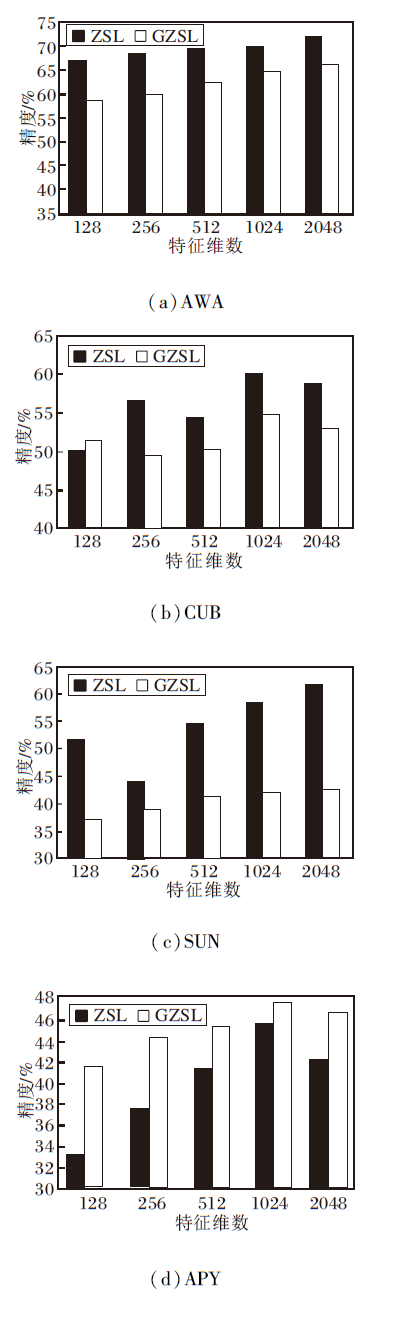 | 图4 特征维度不同时RS-ZSAR的精度对比Fig.4 Accuracy comparison of RS-ZSAR with different feature dimensions |
在AWA数据集上, 随着去冗余后特征维数的增加, ZSL和GZSL的识别精度整体呈上升趋势, 当特征维数增加到2 048时, 两者识别精度达到最高值.故在AWA数据集上去冗余特征维度选择2 048, 如图4(a)所示.同理得出在CUB数据集上, 去冗余特征维度为1 024.在SUN数据集上, 去冗余特征维度为2 048.在APY数据集上, 去冗余特征维度为1 024.
综上所述, 当去冗余后特征维数较小时, RS-ZSAR在CUB、SUN、APY数据集上的精度较低.随着维数的增加, 性能越来越好.由图4可知, 当无冗余特征的维数为1 024时, 在4个数据集上取得较高精度.
2.5.4 收敛性分析
本文在GAN的基础上加入去冗余模块、语义关系约束模块和循环一致性损失.为了验证RS-ZSAR的收敛性, 分析4个主要损失函数的收敛性.由于本文重点是视觉特征的生成过程, 因此, 生成器损失和判别器损失的收敛性分析主要针对视觉特征.4个主要的损失函数分别是:视觉特征生成器损失Loss_G、视觉特征判别器损失Loss_D、分类器损失Loss_C、循环一致性损失Loss_cyc.各损失函数的收敛性分析如图5所示.
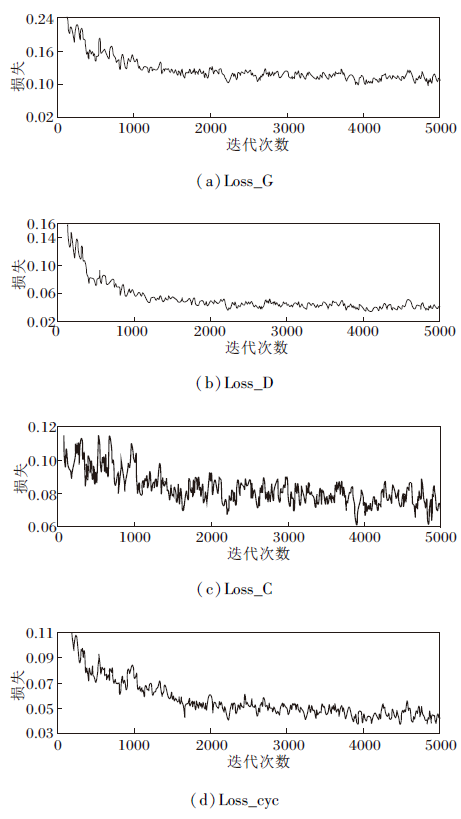 | 图5 各损失函数的收敛性分析Fig.5 Convergence analysis of different loss functions |
RS-ZSAR设置的迭代次数为5 000次.如图5所示, RS-ZSAR在5 000次迭代内, 视觉特征生成器损失Loss_G、视觉特征判别器损失Loss_D、分类器损失Loss_C和循环一致性损失Loss_cyc均可达到收敛.
为了验证RS-ZSAR的泛化性能, 将RS-ZSAR用到零样本图像检索任务中, 即用图像代替属性作为测试阶段的输入进行检索实验.在AWA数据集上对比RS-ZSAR和LisGAN对零样本图像的检索结果.RS-ZSAR在去冗余的特征空间中为每类生成10个视觉特征, 再计算10个视觉特征的均值, 检索映射到去冗余特征空间的top5图像.LisGAN执行相同操作, 但检索的生成图像映射到原视觉特征空间.
图6为5个动物样本的top5检索结果, 正确检索图像使用绿色方框表示, 错误检索图像使用红色方框表示, 每列为一个类别, 类别名称标注在图像上方.
 | 图6 各方法在AWA数据集上top5的零样本图像检索结果Fig.6 Top5 zero-shot image retrieval results of different methods on AWA dataset |
在其它3个数据集重复此实验, 得出的结果类似.实验结果表明RS-ZSAR的检索结果比LisGAN更准确, 因为RS-ZSAR对视觉特征进行去冗余处理, 减少冗余信息的干扰, 同时引入语义关系约束损失和循环一致性损失, 使生成的视觉特征更接近真实视觉特征, 提高检索精度.
为了进一步验证RS-ZSAR的泛化性能, 将RS-ZSAR应用到基于文本的零样本识别任务中, 使用文本代替属性作为测试阶段的输入, 对训练好的方法进行测试, 并在视觉特征生成器中添加抑制文本噪声的全连接层.在CUB、NAB数据集上进行实验, 根据文献[4]方法对数据进行分割, 分成Super-Category-Shared(SCS)和Super-Category-Exclusive (S-CE)[4].在SCS上, 可见类和不可见类属于同类, 相关性较高.在SCE中, 可见类和不可见类属于不同类, 相关性较低.
对比方法如下:WAC(Write a Classifier:Zero-Shot Learning Using Purely Textual Descriptions)[4]、GAZSL[5]、CIZSL(Creativity Inspired Zero-Shot Lear-ning)[6]、CANZSL(Cycle-Consistent Adversarial Net-works for Zero-Shot Learning from Natural Language)[7]、ESZSL[10]、SYNC[11].各方法基于文本的零样本识别精度对比如表5所示, 表中黑体数字为最优结果.
| 表5 各方法在2个数据集上基于文本的零样本识别精度 |
由表5可见, WAC、ESZSL、SYNC为传统零样本文本识别方法, 精度较低.GAZSL使用基于GAN的框架, 精度具有一定提升, 表明GAN能在一定程度上提升零样本识别精度.CIZSL在GAZSL的基础上增加创造性引导的文本, 对方法进行训练, 相比GAZSL, 在CUB、NAB数据集上分别提升0.9%和1.0%.CANZSL在GAZSL的基础上增加循环一致性结构, 相比GAZSL, 在CUB、NAB数据集上精度分别提升2.1%和2.5%.RS-ZSAR引入循环一致性结构, 对视觉特征进行去冗余信息的处理, 并利用可见类和不可见类之间的语义关系对去冗余后的特征进行学习, 使生成器生成的伪视觉特征更接近于真实视觉特征, 所以RS-ZSAR在文本识别任务上精度最高.
因此RS-ZSAR不仅在属性识别任务上, 而且在噪声文本识别任务上均较优, 具有较好的泛化性.此外, RS-ZSAR基于文本的零样本识别精度低于属性识别的精度, 这是因为文本中含有过多的噪声, 这些噪声会对方法有一定的干扰, 降低方法的识别性能.
本文以CTGAN为基本网络框架, 提出基于去冗余特征和语义关系约束的零样本属性识别方法(RS-ZSAR).一方面, 对视觉特征进行去冗余处理, 在保留类别相关性的前提下减少冗余信息的干扰, 提高零样本识别的精度.另一方面, 利用可见类和不可见类之间的语义关系建立知识迁移模型, 引入语义关系约束损失, 使生成器生成的视觉特征更能反映可见类和不可见类之间的语义关系, 有效缓解可见类和不可见类之间的域偏移问题.此外, 引入循环一致性结构, 使生成的伪特征更接近真实特征, 进一步提高识别精度.在4个标准数据集上对零样本识别和广义零样本识别任务进行验证, 并在图像检索和基于文本的零样本识别任务上进行泛化性能验证.实验表明, RS-ZSAR性能较优, 容易拓展到其它应用中, 如图像检索、零样本文本识别、图像分割等任务.本文主要研究基于属性的零样本识别方法, 由于属性是人工进行标注的, 不同的专家会得到不同的标注.近年来, 随着自然语言处理技术的发展, 学者们逐渐使用文本描述代替属性作为零样本识别的中间嵌入空间.文本描述通常容易在线获取, 成本较低, 准确性相对较高.后期将会进一步研究基于文本的零样本识别方法.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|