



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于显著性背景引导的弱监督语义分割网络
[白雪飞1  , 李文静
, 李文静1 , 王文剑1, 2 ]
, 李文静, 王文剑]
|
|



作者简介:

白雪飞,博士,副教授,主要研究方向为图像处理、机器学习.E-mail:baixuefei@sxu.edu.cn.

李文静,硕士研究生,主要研究方向为图像处理、机器学习.E-mail:804159841@qq.com.
目前基于图像级标注的弱监督语义分割方法大多依赖类激活初始响应以定位分割对象区域.然而,类激活响应图通常只集中在对象最具辨别性的区域,存在目标区域范围较小、边界模糊等缺点,导致最终分割区域不完整.针对此问题,文中提出基于显著性背景引导的弱监督语义分割网络.首先通过图像显著性映射和背景迭代产生背景种子区域.然后将其与分类网络生成的类激活映射图融合,获取有效的伪像素标签,用于训练语义分割模型.分割过程不再完全依赖最具判别性的类激活区域,而是通过图像显著性背景特征与类激活响应信息相互补充,这样可提供更精确的像素标签,提升分割网络的性能.在PASCAL VOC 2012数据集上的实验验证文中方法的有效性,同时分割性能较优.
About Author:
BAI Xuefei, Ph.D., associate professor. Her research interests include image proce-ssing and machine learning.
LI Wenjing, master student. Her research interests include image processing and machine learning.
Weakly-supervised semantic segmentation methods based on image-level annotation mostly rely on the initial response of class activation map to locate the segmented object region. However, the class activation map only focuses on the most discriminative area of the object, and the shortcomings exit, including small target area and blurred boundary. Therefore, the final segmentation result is incomplete. To overcome this problem, a saliency background guided network for weakly-supervised semantic segmentation is proposed. Firstly, the background seed region is generated through image saliency mapping and background iteration, and then it is fused with the class activation map generated by the classification network. Thus, effective pseudo pixel labels for training the semantic segmentation model are obtained. The segmentation process does not entirely depend on the most discriminative object. The information complementation is implemented through image saliency background features and class activation response map. Consequently, pixel labels are more accurate, and the performance of the segmentation network is improved. Experiments on PASCAL VOC 2012 dataset verify the effectiveness of the proposed method. Moreover, the proposed method makes a significant improvement in segmentation performance.
本文责任编委 桑 农
Recommended by Associate Editor SANG Nong
图像语义分割是计算机视觉和图像处理中重要的研究内容, 语义分割提供的像素级类别语义信息有助于智能机器快速掌握物体的位置区域.图像语义分割已广泛应用于许多视觉任务中, 如车辆自动驾驶[1]、行人检测、缺陷检测、治疗规划、计算机辅助诊断[2]等.
近年来, 深度卷积神经网络[3, 4, 5]成功应用于图像语义分割, 取得显著进展.然而, 此方法需要专业人员对训练数据集样本进行精准的像素级标注, 使图像语义分割成为一项昂贵且繁琐的任务.为了降低神经网络的训练成本, 研究人员提出基于弱监督学习的语义分割方法, 使用一些低成本的训练数据, 让神经网络达到相对精准的分割效果, 如包围框标签[6, 7]、基于点的标签[8, 9]、涂鸦标签[10, 11]、图像级标签[12, 13].图像级标签是弱监督学习中成本最低的一种标注形式, 只提供图像中存在的类别, 却未明确给出对象的位置和形状等信息.
目前学者们提出很多基于图像级标签的弱监督语义分割方法, 其中一类是基于多示例学习的方法[12, 13, 14], 即利用交叉熵函数, 对全局类感知向量建立多类多示例学习损失, 在PASCAL VOC 2012数据集[15]上实现弱监督语义分割.另一类是使用类激活映射(Class Activation Map, CAM)获取类别响应图[16], 作为初始种子预测, 再对种子进行一定约束的扩张, 最终分割不同类别的目标区域.Kolesnikov等[17]提出种子定位、边界约束原则(Seed, Expand and Constrain, SEC), 定义3个损失函数, 约束种子生长范围.Huang等[18]首先利用深度网络学习像素间的相似性, 再根据区域生长策略[19, 20]扩充初始种子.Shimoda等[21]采用对消[22]的方法, 首先使用CAM对目标种子进行定位, 将目标类的注意力图逐个减去其它前若干类注意力图, 再使用完全连接的条件随机场, 排除不相联系的像素块, 得到语义分割效果图.尽管上述方法都利用图像级标签实现语义分割, 但分割准确率仍远低于完全监督的分割方法.
在基于图像级标签的语义分割问题中, 如何根据图像类别标签生成准确有效的像素级类别标签是提高语义分割网络模型泛化能力的关键因素之一.图像显著性检测生成类别未知的显著图, 从背景中突显图像的前景目标, 可为语义分割提供可靠的目标物体空间线索, 因此有一些研究者[23, 24, 25, 26]利用图像显著性信息生成伪像素类别标签, 从而解决弱监督语义分割任务.Wang等[23]提出自底向上、自顶向下的迭代框架, 首先利用初始种子自底向上挖掘共同对象特征(Mining Common Object Features, MCOF), 扩展对象区域.同时, 在贝叶斯框架下, 利用显著图的显著性引导实现自顶向下的边界细化, 最后将迭代后的对象区域作为监督以训练分割网络, 预测分割图.但是, 此方法耗时太久, 过程过于繁琐, 不利于推广和训练.Oh等[24]首先从图像级标签中随机抽取一个类别, 再计算图像显著性信息, 如果该类别的种子与显著区域有交集, 将这些显著区域赋予该类别标签.Sun等[25]通过图像显著值加权像素之间的相似度, 从而控制初始种子的生长.但Oh等[24]和Sun等[25]的方法很大程度上依赖于显著性检测方法的精度, 如果显著区域中一些不正确的像素点也被划分到同一类, 可能产生次优的分割结果.
由于显著性检测主要用于区分前景和背景, 显著图中的前景对象类别不可知, 但背景类别明确, 为了提高伪像素类别标签的准确性, 本文提出基于显著性背景引导的弱监督语义分割网络(Saliency Back-ground Guided Network, SBGN).首先利用显著性背景引导模块生成背景种子区域, 再与类响应区域进行融合, 生成高质量的伪像素类别标签以训练语义分割网络.融合显著性背景种子区域和类激活响应图, 生成高质量的伪像素类别标签.两类信息相互补充, 不仅有效解决类激活映射区域过小和显著性融合信息不准确的问题, 还可获取较完整的对象轮廓.同时, 网络还具有可扩展性, 可采用不同的类响应映射方案和语义分割网络结构, 很大程度上融合语义分割网络的多尺度特征, 有利于得到更高的语义分割准确率.在PASCAL VOC 2012数据集上的实验验证本文网络的有效性.显著性背景特征和类激活响应图的信息相互补充, 可有效挖掘对象的完整轮廓, 获得更优的语义分割效果.
本文提出显著性背景引导的弱监督伪标签生成算法, 主要包括三个步骤:1)利用显著性背景引导策略生成较准确的背景种子区域; 2)利用分类网络生成类别注意力线索; 3)融合背景种子区域与类别注意力线索, 产生高质量的伪像素类别标签.
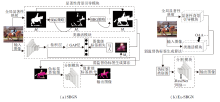
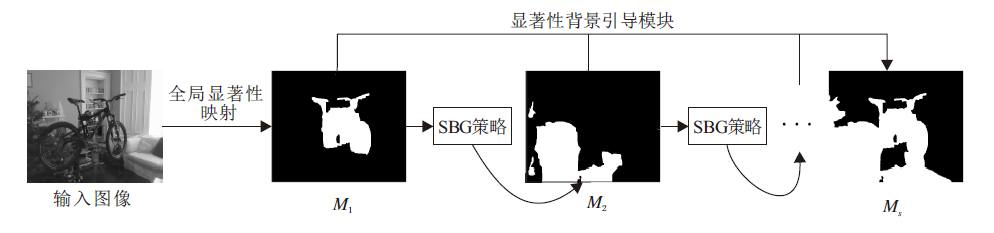
显著图可分开输入图像的前景与背景, 但相比背景信息, 前景通常包含不确定数量和类别不可知的目标, 一些利用显著性前景信息与类激活种子区域进行融合的方法往往不能得到令人满意的分割结果.因此, 本文提出显著性背景引导策略(Saliency Background Guided, SBG).首先利用迭代的方式生成多个显著图, 再结合多个显著图背景信息获得背景种子区域.具体来说, 对于给定的图像X, 首先进行全局显著性映射(Saliency Mapping), 生成第一个显著图M1, 再按SBG策略, 依次生成第i个显著图:
Mi=S(Avg(Mi-1)), i=2, 3, …, t,
其中, S(· )表示显著性映射, Avg(· )表示将Mi-1中的显著像素值替换为该图像所有像素的平均值, 依次挖掘图中显著性对比度较小的区域.
SBG具体过程如图1中所示, 输入图像在显著性映射下得到第1个显著图M1, 将M1中显著部分平均弱化后, 再通过显著性映射, 得到其它显著部位, 生成第2个显著性图M2, 以此类推.
 | 图1 显著性背景引导策略流程图Fig.1 Flowchart of saliency background guided strategy |
显著性背景引导模块不断重复上述过程, 在第t个时间点, 利用SBG生成t-1个显著性映射图, 即M2, M3, …, Mt.最后, 采用一个逐像素点显著值覆盖策略生成显著背景图Ms, 即Ms在位置(i, j)处的像素值
利用上述过程, 可有效累积显著背景区域信息, 为生成语义分割网络的伪像素类别标签提供可靠的背景种子, 如图1中Ms所示.
本文借鉴Zhou等[16]的方法, 在类激活模块中构建CAM网络, 为生成伪标签[27]提供类别注意力线索.在此网络中, 包含5个模块, 每个模块均由池化层与卷积层组成.为了获取图像中的类映射图, 在分类网络最后的卷积层后再加一个卷积层, 卷积核尺寸为1× 1× |C|, 在PASCAL VOC 2012数据集上|C|=21, 使用平均池化层(Global Average Pooling, GAP)代替分类网络的全连接层, 效果等同于在模型上增加正则项, 并且相比全连接层, 平均池化层能更好地保存图像语义信息.最后, 为了获得图像的类别得分, 连接GAP层与softmax层, 利用这样的网络结构, 可使卷积神经网络(Convolutional Neural Net-work, CNN)具有精确的目标定位[16].除此之外, 图像经过GAP层后与softmax层连接, 可达到全连接的效果, 并且不含偏置项.
具体来说, 对于图像中的任一像素点(x, y), 设定经过最后一个卷积层第k(k∈ |C|)个通道后得到的输出为fk(x, y), 则该点经过平均池化层后的输出为
Cmax=arg
其中,
Cmax=arg
其中,
利用上述值对经过最后一层卷积层后得到的特征图加权, 再将特征图放大到与输入图像X相同大小进行叠加, 可获得类别注意力线索MC.
本文算法重点关注类激活映射图中能将区域判定为目标类别具有积极影响的特征, 需要过滤消极影响的部分, 因此选取ReLU激活函数作为前向激活图的加权组合.
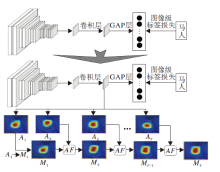
通过1.1节提取到较准确的背景种子区域信息、1.2节提取到类别注意力线索后, 本文提出弱监督伪标签生成算法(Weakly-Supervised Pseudo-label Generation Algorithm, WPGA), 将类激活映射不同类别的MC特征图与背景种子融合, 生成用于分割网络训练的伪像素类别标签.具体过程如算法1所示.通过设置显著背景图和类激活图的阈值, 提取对比度明显的部位, 再对背景图和类激活图设置一定大小的置信度, 减少错误划分的可能性.
算法 1 弱监督伪标签生成算法
输入 原始图像集合X={Xx}, ∀ x∈ X,
显著背景图集S={Sx}, 显著背景阈值Tsg,
类激活图集合CA={CAx}, 类激活图阈值Tca,
图像置信度cf, 置信度阈值Tcf
输出 伪标签图集T={Tx}
step 1 初始化伪标签图集T=zeros(W× H)
/* W、H为图像x的宽度和高度* /.
step 2 将CAx中图像x的每个类激活像素p赋予一定权重:
CAx(p)=
若像素超过阈值Tca, 置黑, 并对类激活区域赋予图像置信度cf.
step 3 对于Sx中图像x的每个背景像素p, 若超过阈值Tsg, 置黑, 并对背景区域赋予图像置信度cf.
step 4 将Tx中图像x的每个像素p进行显著背景区域与阈值内类激活区域合并:
Tx(p)=max(Sx(p), (CAx(p)< Tca)× 255),
若出现区域重叠, 优先将重叠区域分给类别对象.
step 5 对Tx中图像x的每个小于置信度阈值Tcf的像素p置白.
WPGA过程如图2所示, 输入图像经过SBG策略获得较可靠的背景区域Ms, 同时经过CAM网络获得类激活映射图MC, 然后将背景种子Ms与类激活映射图MC进行WPGA并融合, 将生成图中不确定的部分设置为白色, 从而获得伪标签类别图, 用于训练弱监督分割网络.
 | 图2 弱监督伪标签生成算法流程图Fig.2 Flowchart of weakly-supervised pseudo-label generation algorithm |
通过显著背景图和CAM类激活图融合生成弱监督伪标签后, 本文首先构建显著性背景引导的弱监督语义分割网络(SBGN), 然后在SBGN基础上构建扩展网络Ex-SBGN.
SBGN网络由3部分组成:1)利用SBG策略生成较准确的背景种子区域; 2)将提取到的背景种子区域与分类网络生成的类激活映射图进行WPGA融合; 3)利用伪标签图训练语义分割模型.
显著性背景图和类激活图融合后的种子可作为语义分割网络的标签, 用于训练语义分割模型.本文提出混合损失函数, 综合考虑分类网络图像级标签损失和分割网络像素级标签损失两方面因素, 避免单一损失函数的片面性, 提高分割准确率.
由图像级标签监督的CAM网络的全局平均池化层得到预测向量v, v大小为1× 1× ρ , ρ =
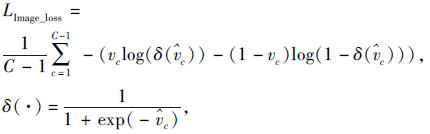
其中, $\hat{v_{c}}$为真值图像级标签, 对于图像中的所有像素, δ (· )取值为1表示目标存在, 否则为0.
对于分割网络来说, 将大小为m× n的标签图像X中的每个像素Xij输入分割网络, 设置对应的类标签为Yij, 则网络输出函数可表示为Q(X; Θ ), Θ 为训练网络中待优化的参数.因此, 分割网络的损失函数定义为
LSeed_loss=
其中, Z=m× n为图像X的大小, E(· , · )为像素级交叉损失函数, δ (· )∈ {0, 1}.
综上所述, SBGN的损失函数定义为
L=LImage_loss+LSeed_loss.
本文选择Chen等[28]提出的DeepLab网络模型作为弱监督语义分割网络, 并且为了与其它弱监督语义分割进行对比, 分别以16层深的视觉几何群网络(Visual Geometry Group Network-16 Layers Deep, VGG-16)[29]和101层深的深度残差网络(Deep Resi-dual Network-101 Layers Deep, ResNet-101)[30]为骨干网络进行训练.不同于增加卷积核膨胀率的做法[31], 本文使用1.3节WPGA融合的伪标签作为语义分割网络的标签进行训练.为了减小弱监督语义分割网络对目标类别的错误判断, 本文将CAM网络中的图像标签线索作为语义分割网络的辅助监督.具体来说, 分割网络是CAM分类网络的一个分支, 输入图像在经过卷积层后生成多幅特征图, 作为分割网络的输入, 再结合伪标签的监督, 提高分割准确度.具体SBGN流程图如图3(a)所示.
 | 图3 SBGN和Ex-SBGN流程图Fig.3 Flowchart of SBGN and Ex-SBGN |
Ex-SBGN流程图如图3(b)所示.图像分类器产生的CAM网络往往集中在最有区分度的目标部分, 研究发现分类网络产生的注意力图在迭代的训练中能关注不同的目标区域.为了积累已发现的不同目标区域, 有研究者提出在线注意力积累策略(Online Attention Accumulation, OAA)[32], 通过对图像中包含的每个目标类别生成一个累积注意力图, 最终生成分割图.本文的SBGN网络中类激活模块很容易与在线注意力累积策略进行结合, 过程如图4所示, 利用如上结构, 可进一步提高分割准确率.
 | 图4 SBGN网络与OAA结合的流程图Fig.4 Flowchart of combination of SBGN network and OAA method |
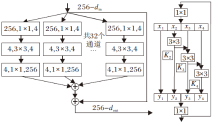
语义分割任务要求CNN对目标物体的上下文语境信息具有较强的多尺度提取能力.因此, 为了使CNN获得多尺度信息表达能力, 通常会堆叠卷积层, 使用大范围的感受野获得不同尺度的上下文信息等.Gao等[33]提出的Res2Net架构是可嵌入Res-Net、VGG、聚合残差变换的深度神经网络(Aggrega-ted Residual Transformations for Deep Neural Net-works, ResNeXt)等任意骨干网络的模块, 用于语义分割网络中, 可进一步增强网络的多尺度表达能力.相比ResNet, 基于Res2Net模块集成的类激活映射更能倾向于覆盖整个目标物体.
本文将Res2Net与显著性背景引导网络中的分割模块进行融合, 过程如图5所示, 将分割模块中的1× 1卷积层进行结构转化.输入的图像X经过卷积层生成k个子特征图, 若此时输入图像的通道数为h, 则每个子特征图的通道都为h/k.使用xi表示子特征图, i=1, 2, …, k.除了x1, x2~xk后都连接一个3× 3的卷积层, 用Ki(· )表示, 定义Ki(· )的输出为yi, 子特征图xi和Ki-1(· )相加后, 送入Ki(· )进行处理, 输出结果
yi=
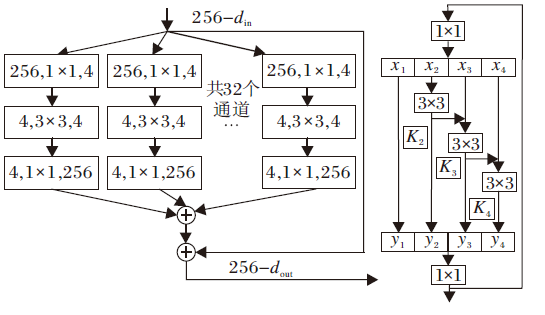 | 图5 SBGN网络与Res2Net结构转换图Fig.5 Conversion between SBGN and Res2Net |
为了验证本文提出的显著性背景引导的弱监督语义分割网络的有效性, 在PASCAL VOC 2012数据集上进行一系列的对比实验.
PASCAL VOC 2012数据集作为基准数据集之一, 在图像分割网络对比实验与模型效果评估中被广泛使用.它标注21个类别(包含1个背景类别和20个对象类别), 每幅图像包含一个或多个对象.遵循之前的弱监督语义分割方法, 本文使用增强的10 528幅训练图像以及它们的图像级标签训练网络.在验证集和测试集设置方面, 本文分别采用1 449幅和1 456幅图像数据与其它经典方法进行对比, 所有图像均来自PASCAL VOC官方网站.
为了评估和对比不同网络得到的图像语义分割结果, 使用如下定义的平均交并比(Mean Intersection over Union, mIoU)[34]作为评价指标:
mIoU=
其中, N表示图像像素的类别数量, Ti表示第i类的像素总数, xii表示实际类型为i、预测类型为i的像素总数, xji表示实际类型为i、预测类型为j的像素总数.mIoU值越大, 表示分割效果越优.
在本文实验中, 在与其它基于图像级标签的弱监督方法进行分割性能对比的同时, 也和一些利用显著性信息的弱监督工作进行分割效果对比.SBGN网络中的显著性背景引导模块采用以全局对比度为基准的显著性检测算法[35], SGB策略的迭代次数可根据显著性背景的效果图进行用户自定义, 实验中最好的效果值为5次.除此之外, 用户还可自定义背景图和类激活图的置信度, 工作中经验值为0.9.
本文将分类网络的输入统一设置为321× 321, 批尺寸大小为5, 动量为0.9, 衰减权重为e× 10-4, 初始学习率为0.001, 对网络进行100次迭代训练, 每10次迭代, 学习率降低1/10.分割网络设置批尺寸大小为15, 动量为0.9, 衰减权重为0.000 1, 初始学习率为0.01, 对网络进行10 000次迭代训练, 每1 000次迭代, 学习率降低0.5倍进行实验.
本文所有实验均使用PyTorch, 在一个8 GB内存的NVIDIA TITAN Xp GPU上实现.
实验选择如下对比方法:多示例学习加平滑先验(Multiple Instance Learning+SP-seg, MIL+seg)[14]、SEC[17]、文献[19]方法、文献[20]方法、像素语义关联网络(AffinityNet)[22]、挖掘共同对象特征(Mining Common Object Features, MCOF)[23]、文献[25]方法、文献[26]方法、随机推理网络(FickleNet)[31]、OAA[32].
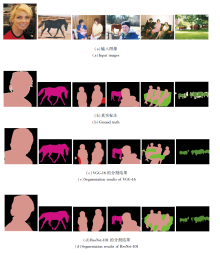
在PASCALVOC 2012数据集上, SBGN网络分别利用VGG-16和ResNet-101的部分分割效果如图6所示.由图可看出, VGG-16在单个目标场景下与ResNet-101的分割效果相似, 但在一些复杂环境下, 会稍显逊色.
 | 图6 SBGN网络分别利用VGG-16和ResNet-101在PASCAL VOC 2012数据集上的分割结果对比Fig.6 Segmentation result comparison of SBGN using VGG-16 and ResNet-101 on PASCAL VOC 2012 dataset |
各方法在PASCAL VOC 2012验证集和测试集上的mIoU值如表1所示.
| 表1 各方法在PASCAL VOC 2012验证集和测试集上的mIoU值对比 Table 1 mIoU comparison of different methods on PASCAL VOC 2012 val and test datasets % |
由表1可看出, 当分别采用VGG-16和ResNet-101作为语义分割网络基准时, SBGN和Ex-SBGN在PASCALVOC 2012测试集上分别获得62.9%和66.5%的mIoU值, VGG-16上的分割结果都有所提升, ResNet-100上的分割结果相对于大部分方法都有所提升, 但仍有不足.
图7列出SBGN和Ex-SBGN在PASCAL VOC 2012验证集上的一些分割结果.图7第1列和第2列包含鸟的图像, 一般具备背景和前景目标颜色、轮廓较分明的特征, 因此在分割结果中可获得较清晰、准确的轮廓.而对于一些包含过渡色的图像, 如图7第7列, SGB策略不能较好地检测到准确的背景信息, 不能获得十分清晰的背景轮廓.最后一列图像中人的头发与背景色区分度不明显, 造成最终的分割误差.
 | 图7 SBGN和Ex-SBGN网络在PASCAL VOC 2012验证集上的分割结果对比Fig.7 Segmentation result comparison of SBGN and Ex-SBGN network on PASCAL VOC 2012 val set |
表2详细列出各方法在PASCAL VOC 2012验证集的21个类别上的mIoU值对比, 表中黑体数字表示最优结果.由表可知, SBCN和Ex-SBGN在12个类别上性能都有所突破, 在bkg类别上取得90.2%的mIoU值, 相比其它方法, 获得更高的分割准确度, 说明显著性背景引导模块的有效性.除此之外, air-plane、bird、person类别的图像通常场景较简单, 轮廓单一, 与背景区分度较明显, 因此分割效果较优.而chair、bike类别的图像通常背景较复杂, 区域轮廓不明显, 因此不容易被分割.
| 表2 各方法在PASCAL VOC 2012验证集的21个类别上的mIoU值对比 Table 2 mIoU comparison of different methods on PASCAL VOC 2012 val set % |
此外, 将本文网络与Wang等[23]提出的MCOF网络和文献[25]方法在PASCA-LVOC 2012验证集进行分割结果对比, 具体实验结果如图8所示.观察图8不难发现, 因为本文网络利用SBG策略, 相比其它方法, 在最终的分割结果中拥有更完整的目标轮廓.
 | 图8 各方法在PASCAL VOC 2012验证集的分割结果对比Fig.8 Comparison of segmentation results of different methods on PASCAL VOC 2012 val set |
为了验证本文网络各模块的有效性, 对SBGN网络的不同部分进行消融实验.不利用伪标签生成算法, 只采用CAM网络生成语义分割结果图时, mIoU值为32.05%, 效果很差.将CAM网络得到的结果放入语义分割网络进行训练, mIoU值为39.22%, 有所上升.而SBG策略和伪标签生成算法加入后, mIoU值为66.50%, 大幅提高弱监督语义分割网络的性能, 表明SBGN网络各个组成部分的有效性和重要性.
在表1中, 当扩展后的Ex-SBGN网络以ResNet-101为语义分割网络基准时, 在PASCALVOC 2012验证集和测试集上分别获得66.8%和68.9%的mIoU值, 充分体现显著性背景引导网络经过扩展后大幅提升分割能力.在图7中, 对比最后一列分割结果, 不难发现引入网络多尺度信息, 可更好地让网络学习到上下文信息, 减少类别错误划分的可能性.一系列实验数据表明, 本文网络具有可扩展性, 并且可更换不同类响应映射方案和语义分割网络结构, 进一步提升网络分割性能.
本文提出基于显著性背景引导的弱监督语义分割网络.引入显著性背景引导模块, 利用图像级标签实现语义分割功能.具体来说, 首先设计显著性背景引导模块生成背景种子, 再将该种子与分类网络生成的类激活映射图融合, 获取伪标签, 训练分割网络.在PASCAL VOC 2012数据集上的实验表明, 本文网络在分割准确度上有所提升.
基于图像级标签的弱监督语义分割是近年来研究较多且具有挑战性的研究课题.今后将对本文网络在利用CAM网络获得类别信息和语义分割网络结构方面进行进一步改进, 大幅缩小伪标签与真值标签的差距, 提高分割准确度, 并尝试应用于医学图像分割等领域.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|