


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于双通道深度CNN的烟雾浓度测量方法
[莫鸿飞1 , 谢振平1, 2  ]
]
]
|
|



作者简介:

莫鸿飞,硕士研究生, 主要研究方向为计算机视觉.E-mail:1640657648@qq.com.
现有基于视频图像测量烟雾浓度的方法主要通过人工提取特征,需要已知环境的大气光、背景等外界条件.为了提高烟雾浓度测量方法的直接性和实用性,文中通过烟雾化方程,建立烟雾图像与其浓度数值的对应关系,进而提出基于双通道深度卷积神经网络(DCCNN)的烟雾浓度测量方法,实现端到端的烟雾浓度直接测量.DCCNN中采用1×1卷积进行通道数据融合,引入跳跃连接解决网络层数较深时梯度消失问题,加快训练过程.同时引入自注意力机制,自动学习隐含特征的重要程度,再合并两个通道提取的特征,获得综合测量结果.实验表明,DCCNN测量烟雾浓度的平均绝对误差较低,综合性能较优.
About Author:
MO Hongfei, master student. His research interests include computer vision.
In the existing methods for measuring smoke density based on video images, features are mainly extracted manually, and the external conditions, such as ambient light and background, are required as known conditions. To improve the directness and practicability of the smoke density measurement method, the corresponding relationship between smoke images and their density values is established through the Aerosolization equation. The smoke density dataset is established as well. A smoke density measurement method based on dual-channel deep convolution neural network(DCCNN) is proposed to realize the end-to-end direct measurement of smoke density. In DCCNN, 1×1 convolution is used for channel data fusion, and jump connection is introduced to make the neural network training faster. The self-attention mechanism is also introduced to learn the importance of hidden features automatically. Finally, the features extracted from two channels are combined to obtain comprehensive measurement results. Experiments show that DCCNN gains lower mean absolute error and higher comprehensive performance.
本文责任编委 汪增幅
Recommended by Associate Editor WANG Zengfu
火灾中烟雾总是先于火焰出现, 并且往往是火灾致死的主要原因[1], 因此烟雾检测对社会公共安全具有重要意义.烟雾浓度是烟雾的本质特征之一, 是衡量火灾严重程度和火灾检测的重要标准[2].相比烟雾检测, 烟雾浓度为火灾模拟、人员疏散等提供更丰富和准确的信息, 但烟雾浓度测量也比单纯的烟雾检测需要更多的数据信息, 烟雾浓度测量可归结到密集回归问题.这项任务不仅要求标注图像是否为烟雾, 还要标注每块的烟雾浓度.目前常用的烟雾浓度测量方法通常采用光学法, 如光透射法[3].光学法具有较高的检测精度, 适用于浓度较高的烟雾, 但对于硬件有很高的精度要求, 成本相对较高, 不适合应用于较大的空间环境, 不能实时用于火灾现场[4].
为了克服光学法测量烟雾浓度的局限性, 学者们开始研究基于视频图像的测量方法.基于视频图像的烟雾检测方法可分为传统方法和深度学习方法[5].烟雾检测传统方法主要利用烟雾的运动、颜色和纹理等信息提取特征[6, 7].Gubbi等[8]通过小波变化在烟雾图像中提取算术均值、偏差等, 结合支持向量机(Support Vector Machine, SVM)进行视频烟雾检测.学者们也提出很多基于深度学习的烟雾检测方法[9].Yin等[10]将批归一化(Batch Normalization, BN)融入卷积神经网络(Convolutional Neural Net-work, CNN), 提出基于BN层的深度神经网络(Deep Normalization CNN, DNCNN), 并建立烟雾数据集, 为烟雾检测提供公开、全面的数据集.Yuan等[11]提出基于多尺度的CNN(Deep Multi-scale CNN, DMCNN), 引入Inception结构, 利用不同尺度提取特征并融合, 用于烟雾检测.Gu等[12]将双通道神经网络(Dual-Channel Neural Network, DCNN)用于烟雾检测, 一个通道提取烟雾浅层整体特征, 一个通道提取烟雾深层纹理, 最后将提取的特征融合用于烟雾检测.
进而学者们提出基于视频图像的烟雾浓度测量方法, 此方法也可分为传统方法和深度学习方法.基于视频图像的烟雾浓度测量传统方法主要对烟雾图像的灰度、结构相似度等进行研究[13].He等[14]计算烟雾化方程, 使用暗通道法完成图像去雾, 为通过图像灰度计算烟雾浓度提供理论依据.王新玲[15]通过激光测试烟雾穿透实验, 得出烟雾浓度与图像灰度存在一定关系, 为通过图像灰度计算烟雾浓度提供证明.袁飞阁[16]根据烟雾化方程, 实现根据视频图像测量烟雾浓度的目标, 并用于火灾检测中.Miao等[17]通过暗通道法观察图像灰度, 得出烟雾浓度与暗通道强度值的关系.马天颖[4]通过对图像结构相似度的分析, 建立烟雾浓度与图像结构相似度变化的关系.吴昊[18]确定图像灰度和烟雾透过率之间的关系, 建立图像相似度与烟雾透过率的描述关系, 为研究瞬态烟雾浓度提供新思路.深度学习的方法使用人工合成的烟雾图像进行烟雾分割, 估算烟雾浓度.Yuan等[19]使用粒子散射和发射模型的3D可视化技术, 模拟烟雾行为, 并使用RGBA通道生成大量半透明的纯烟雾图像, 使用全卷积网络(Fully Convolutional Network, FCN)完成端到端烟雾浓度估计.
基于视频图像烟雾浓度测量的传统方法主要根据有烟和无烟的情况下图像相似度或图像灰度的变化进行检测[4], 需要已知大气光和背景图像.而在真实环境中, 视频图像的背景和大气光会经常发生变化, 因此上述方法并不适合于实际环境下的测量.并且仅根据图像数据直接测量烟雾浓度时, 烟雾会模糊图像并降低图像对比度, 并且烟雾并无具体的外观形状, 边界非常模糊, 烟雾本身的半透明特性也会使烟雾纹理与背景混合[5], 使基于视频图像的烟雾浓度直接测量成为一个难题.基于深度学习的烟雾分割中训练数据主要为合成数据, 和真实烟雾情况有一定区别.并且现有测量烟雾浓度的算法大多基于人工提取特征的模型, 容易遇到瓶颈且缺少泛化性, 因为人工提取的图像特征并不足以表示烟雾图像中的复杂变化.
因此, 本文提出基于双通道深度卷积神经网络(Dual-Channel Deep CNN, DCCNN)的烟雾浓度测量方法, 通过CNN、注意力机制[20]及跳连结构[21]建立网络模型, 进行烟雾浓度测量.为了避免手动标注烟雾浓度的困难, 通过烟雾化方程[14], 得出视频烟雾图像与其浓度对应关系的物理模型, 解决手动标注烟雾浓度的难题.以该物理模型作为监督信号, 通过深度卷积神经网络从数据集中学习性能更好、鲁棒性更强的模型, 并且不再受大气光和背景图像等因素影响.
网络结构对深度卷积神经网络的性能起到决定性作用, 在众多经典神经网络的基础上, 本文提出基于双通道深度卷积神经网络(DCCNN)的烟雾浓度测量方法.DCCNN由子通道1和子通道2组成.
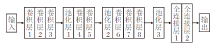
参考DNCNN和VGG网络[22], 子通道1结构如图1所示, 由8层卷积层和3层池化层组成.
 | 图1 子通道1的结构示意图Fig.1 Sketch map of sub-channel 1 |
网络整体结构采用金字塔结构, 可更好在特征提取和减少冗余信息之间取得平衡.卷积层由一组3× 3的卷积核组成, 卷积核可视为二维数字矩阵, 有助于找到烟雾特定的局部图像特征.图像相邻区域的像素倾向一定的相似性, 因此由卷积层输出的相邻区域参数也有一定的相似性, 这说明卷积层输出的信息会有大量的冗余.因此池化层选择最大池化, 激活局部最大响应以学习最显著的特征.激活函数选择整流线性单元(Rectified Linear Unit, ReLu), ReLu具有单侧抑制性, 更像生物学神经元的特征, 使神经网络中的神经元也具备稀疏激活性.ReLu函数定义如下:
y=max(wx+b, 0),
其中, x为激活函数的输入, y为激活函数的输出, w
为共享权重, b为偏差.如果输入小于0, 输出y也为0; 如果输入大于0, 输出y等于输入.
深度神经网络在训练时, 网络中权重参数的变化会引起内部神经元结点数据分布发生变化, 导致网络需要不断对权重参数进行调整以适应输入数据分布的变化, 神经网络的学习速度会下降, 还容易导致网络训练过程中陷入梯度饱和.因此本文选择使用BN层解决这些问题.BN层在非线性激活之前通过缩放和移位步长变换内部输入, 消除内部协方差移位, 可使网络中各层数据的分布相对稳定, 网络学习速度得到提升, 学习过程更稳定, 并且具备一定的正则化效果, 缓解梯度消失.BN函数定义如下:
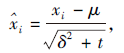
其中, μ 为小批量均值, δ 2为小批量方差, t为一个稳定的数值.
最后选择性地添加BN层, 该选择源于文献[23], 此研究表明BN使提取的特征受到自由约束.因此为了保护提取特征, 第一层不添加BN层.
在上述结构的基础上, 在最后一个池化层后面添加3个全连接层.由于全连接层中参数占可学习参数的很大一部分, 容易导致过拟合现象, 因此本文中使用随机失活方法, 让全连接层在前向传播中神经元的激活值以概率p的几率中止工作, 这样可使网络模型不会过于依赖某些局部特征, 具备更强的泛化性.最后一层全连接层的激活函数选择Linear, 即
y=b+
Linear函数输出图像对应的烟雾浓度数值, 范围在0和1之间.
子通道1的详细参数设置如表1所示.
| 表1 子通道1的参数设置 Table1 Parameters setting of sub-channel 1 |
在神经网络的训练过程中, 为了重点关注需要的特征信息, 提高检测效率, 引入自注意力机制, 自动学习网络模型中提取特征的重要程度, 提升对检测有利的特征, 抑制对检测无用的特征[7].Woo等[24]提出自注意力机制(Convolutional Block Atten-tion Module, CBAM).CBAM是一种基于卷积模块的注意力机制模块, 合理结合空间注意力机制和通道注意力机制, 在增加的计算开销可忽略不记的同时提高模型的准确率.本文将其扩展到烟雾浓度的回归问题上, 提高烟雾浓度测量的准确率.CBAM结构如下.
1)通道注意力模块.神经网络中的通道信息一般表示图像不同的特征信息, 因此对通道进行选择就是在关注什么样的特征是有意义的.为了对通道进行选择, 分别计算特征图的全局平均池化和全局最大池化信息.通道注意力模块
MC(F)=σ (MLP(AvgPool(F))+MLP(MaxPool(F)))=σ (W1(W0(
其中, F∈ RC× H× W为输入的特征图, W0∈ RC/r× C, W1∈ RC× C/r, σ 为sigmoid函数.
对输入的特征图进行空间的全局平均池化和全局最大池化, 得到2个1× 1× C的通道.分别将其送入两层的共享神经网络, 第1层有C/r个神经元, 采用ReLu激活函数, 第2层有C个神经元.将最后得到的特征参数相加, 通过σ 得到最后的MC.
2)空间注意力模块

与通道注意力类似, 对输入的特征图进行空间的全局平均池化和全局最大池化, 得到2个H× W× 1的通道, 拼接之后通过1个卷积核为7× 7的卷积层, 激活函数为sigmoid, 得到最后的MS.
通道注意力模块和空间注意力模块可以以并行或顺序的方式组合.通过实验发现顺序组合并且将通道注意力放在前面可取得更优效果.最终输出为
F″=MS(F')ⓧF',
其中F'=MC(F)ⓧF.
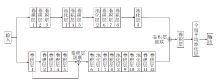
在子通道1和DCNN的基础上, 子通道2的结构如图2所示.子通道2连接12层卷积层、3层最大池化层、10层BN层、1层全局平局池化层和1层全连接层, 用于提取烟雾图像特征.
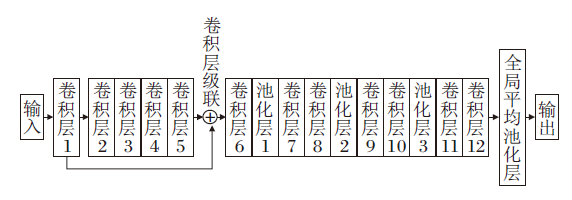 | 图2 子通道2的结构示意图Fig.2 Architecture of sub-channel 2 |
为了更好地提取特征, 类似于子通道1, 前两层卷积层并未添加BN层.为了不使网路层数更深导致梯度消失, 并且提取更丰富的图像特征, 第1层卷积层的卷积核大小设为7, 效果优于使用3层3× 3卷积核的神经网络.在子通道2的第1层卷积层提取得到的特征, 跳连到第5层, 通过级联操作连接, 即
其中, [
不同于子通道1, 子通道2使用全局平均池化层(Global Average Pooling, GAP)代替全连接层.在文献[9]中采用GAP替代全连接层, 实现直接降维, 大幅减少模型中的参数(CNN中全连接层的参数占总参数的很大部分).通过网格寻优的方式确定注意力机制添加的最佳位置, 在Conv6、Conv8、Conv10处添加CBAM层.
为了防止神经网络过拟合, 选择在神经网络中添加l2正则化项.l2正则化项是在原来损失函数的基础上加上权重参数的平方:
L'=L+λ
其中, λ 为可选择的正则化参数, L为未包含正则化项的损失函数误差.
子通道2的详细参数设置如表2所示.
| 表2 子通道2的参数设置 Table2 Parameters setting of sub-channel 2 |
通过训练可发现, 神经网络的两个通道在单独训练中都取得较好结果:层数较少、结构较简单的子通道1更适合提取烟雾图像的浅层特征和全局信息; 层数较深、结构较复杂的子通道2更适合提取烟雾的深层特征和局部纹理; 联合二者一起训练也会取得更优效果.
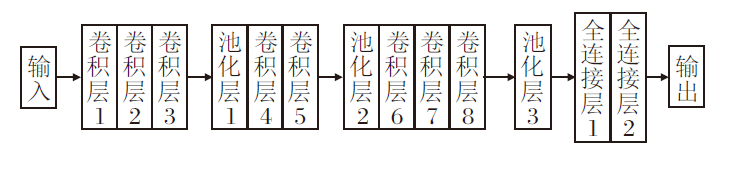
联合操作如下.首先去除子通道1的3层全连接层, 将剩余的模型命名为子通道1_1, 用于提取特征, 并通过网格寻优的方式确定注意力机制添加的最佳位置, 具体在Conv3、Conv5、Conv7处添加CBAM层.类似地, 去掉子通道2的全局平均池化层, 命名为子通道2_1.再合并, 通过级联运算2个通道提取的特征:F12=r(w[
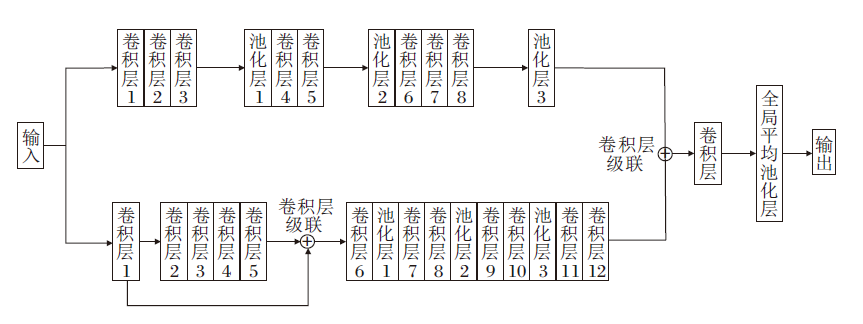 | 图3 DCCNN结构示意图Fig.3 Architecture of DCCNN |
本文使用Tensorflow和Keras深度学习框架构建和训练DCCNN, 并与其它网络进行对比研究.所有实验均在Ubuntu16.04操作系统上进行, 服务器配置为i9-10900X CPU和2块Nvidia GTX 2080ti GPU.
烟雾图像直观可视的特点为烟雾浓度测量、烟雾的相关纹理特征获得等研究提供丰富的信息, 因此使用烟雾图像进行烟雾浓度测量是烟雾浓度测量领域发展的方向.根据视频图像灰度测量烟雾浓度的方法可参考烟雾化方程[14, 16]:
I=J×
其中, I为当前图像的灰度, J为背景图像的灰度, m为减光系数, A为大气光, D为摄像头与背景图像之间的距离.为了计算方便, 这里定义烟雾的穿透率作为衡量烟雾浓度大小的数值:
t=
则烟雾化方程可使用穿透率表示为
I=J· t+A(1-t),
当前图像的灰度I、背景图像的灰度J均可从视频图像中得出.一个像素点的烟雾灰度和整幅图像烟雾区域的平均灰度都可根据上述公式得到对应的烟雾透过率.
大气光A最直接、准确的获得方式就是通过视频图像中天空部分的像素灰度平均值进行估计.如果视频中拍摄到天空, 可直接选择这种方式计算得到A值.视频中没有天空部分时, 可通过如下方法进行计算[17].在一幅图像的固定范围内背景灰度发生剧烈变化, 而烟雾图像相邻区域间的烟雾浓度 m 近似相同, 该范围内的烟雾浓度可认为基本没有变化.据此可建立方程:
其中, Ib为亮处当前图像的灰度, tb为亮处烟雾的穿透率, Jb为亮处背景的灰度, Ik为暗处当前图像的灰度, tk为暗处烟雾的穿透率, Jk 为暗处背景的灰度.由于亮处和暗处的烟雾穿透率近似相等, 即tk=tb, 而式(1)中I和J都是已知的, 只有A和t未知, 因此由2个方程可求出A和t.
烟雾浓度γ =1-t, γ 的取值范围为0~1, 0表示此区域无烟雾, 1表示此区域烟雾浓度达到最大值, 本文将γ 在0~0.2的区域定义为无烟雾区域, 0.2~0.5的区域定义为低浓度烟雾区域, 0.5~0.8的区域定义为高浓度烟雾区域, 0.8~1的区域定义为特高浓度烟雾区域, 出现情况较少.
因为无公开统一的烟雾图像浓度数据集, 因此采用网上公开发布的烟雾视频[25, 26], 计算烟雾浓度.如图4所示, 对图中部分区域进行标注.根据公开的20段视频中, 计算得到约11万幅40× 40的烟雾浓度图像, 其中70%的图像作为训练集, 30%的图像作为测试集.为了避免过拟合, 还使用数据增强技术, 如水平翻转、垂直翻转和旋转等, 以产生更多的烟雾浓度图像.
 | 图4 烟雾视频图像示例Fig.4 Examples of smoke video image |
为了定量分析各网络, 选择平均绝对误差(Mean Absolute Error, MAE)作为评价指标:
MAE=
其中, xi为预测值, yi为真实值.MAE是用于回归模型的一种损失函数, 表示预测值与真实值之差的绝对值之和的平均值.衡量方式不考虑反向, 主要衡量预测值与真实值之前误差的平均模长.相比均方误差, MAE在面对异常点时具有更好的鲁棒性.
为了更好地衡量图像烟雾浓度测量的准确性, 将检测结果二值化, 作为衡量烟雾浓度测量准确率的指标.计算图像预测烟雾浓度与实际烟雾浓度之间的差值以进行二值化, 将差值的阈值K分别定为0.1, 0.15, 0.2, 低于阈值的差值标为检测正确, 高于阈值的差值标为检测错误.准确率定义为低于阈值的烟雾图像占总测量图像的百分比.本文的主要目标是实现低MAE的同时, 在二值化之后的结果中获得较高的检测准确率, 其中阈值为0.1时的测量准确率最重要, 接下来默认烟雾浓度测量准确率即指阈值为0.1时的测量准确率.
本次训练采用自己制作的烟雾图像浓度数据集Set1和Set2, Set1数据集包含78 679幅各种浓度的烟雾图像, Set2数据集包含32 215幅各种浓度的烟雾图像, Set1、Set2数据集上图像都来源于公开烟雾视频, 每个数据集都包含浓烟、淡烟和类似烟雾的非烟雾图像, 与烟雾纹理、颜色类似的非烟雾图像是影响烟雾浓度测量准确率的重要因素.在较大的Set1数据集上进行训练, 在较小的Set2数据集上进行验证.
实验中, 首先分别训练2个子通道, 再合并训练.以DCCNN为例, 采用RMSprop(Root Mean Square Prop)优化器训练深度神经网络模型, 初始学习率设置为0.01, 学习率衰减系数设置为0.001, 采用Kaiming初始化方法[21]对网络参数权重进行初始化, 批大小设置为256, 数据集共迭代200次.
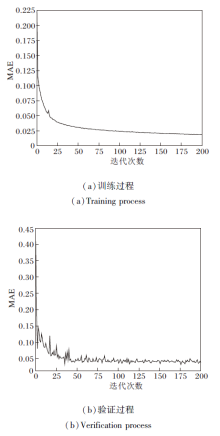
在DCCNN的训练和测试过程中, 随着迭代次数的增加, MAE的变化情况如图5所示.由图可知, 在迭代约100次后, MAE值趋于稳定.
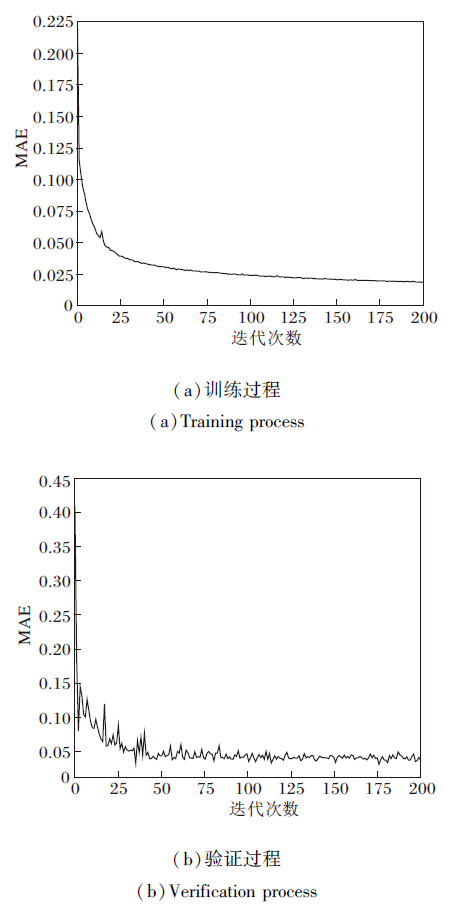 | 图5 DCCNN训练和验证过程的MAE变化曲线Fig.5 MAE curves of DCCNN training and verification |
为了验证DCCNN的优越性, 选择如下对比网络:AlexNet、VGG16、ResNet、DNCNN、DCNN, 得到的实验结果如表3所示.由表可知, DCCNN获得最优性能.MAE指标体现网络对烟雾浓度测量整体的精准程度, 相比专门用于烟雾检测的DCNN, DCCNN的MAE值降低约0.003, 准确率提高约2%.从不同阈值下准确率的对比中也可看出, DCCNN检测稳定性更优.相比VGG16, DCCNN的MAE值降低约0.011, 准确率提高约4%, 整体性能有所提升.
| 表3 各网络的实验结果对比 Table 3 Comparison of smoke density measurement results of different methods |
为了验证双通道深度神经网络的作用, 将DCCNN与其组成部分子通道1和子通道2进行对比, 结果如表4所示.由表可知, 子通道2效果明显优于子通道1, 这可能是跳连机制防止梯度消失和注意力机制自动学习特征重要程度的作用.DCCNN最优, 说明双通道网络可相互融合补充, 达到更优性能.
| 表4 DCCNN与子通道的实验结果对比 Table 4 Comparison of smoke density measurement results between DCCNN and sub-channels |
对DCCNN进行消融实验.去除DCCNN中的全部BN层, 命名为DCCNN_1; 去除DCCNN中的跳连结构, 命名为DCCNN_2; 去除DCCNN中的注意力机制, 命名为DCCNN_3; 去除DCCNN中的1× 1卷积部分, 命名为DCCNN_4.采用与DCCNN相同的方法训练DCCNN-1、DCCNN-2、DCCNN-3、DCCNN-4, 所得消融实验结果如表5所示.由表可知, DCCNN_1效果很差, 说明没有BN层的作用, 神经网络会产生严重的过拟合.之外DCCNN_3性能最差, 说明BN层和注意力机制对网络性能影响最大, 因此最重要.
| 表5 消融实验结果对比 Table 5 Comparison of ablation experiment results |
对根据烟雾化方程推出的物理模型与各网络进行对比, 结果为各网络对训练集的检测准确率, 如表6所示.由于在训练时考虑到过拟合的情况, 因此DCCNN网络计算得到的烟雾浓度与物理模型计算的烟雾浓度稍有差别, 但控制在合理范围内.
| 表6 各网络与物理模型的实验结果对比 Table 6 Result comparison of different networks and physical models |
考虑到测量的实时性, 对比各网络烟雾浓度测量速度, AlexNet为55.56帧/ 秒, VGG16为27.78帧/秒, ResNet为25.32帧/秒, DNCNN为33.33帧/秒, DCNN为23.80帧/秒, DCCNN为16.75帧/秒.为了得到较高的测量精准度, DCCNN使用双通道神经网络并添加CBAM注意力机制, 因此测量速度相对较慢, 但平均检测速率仍可达16.75帧/秒, 基本可满足实时检测要求, 若考虑到硬件性能的发展, DCCNN完全具备实时可用性.
将DCCNN用于公开视频的烟雾浓度测量, 测量结果如图6所示, 对图中无烟雾区域、低浓度烟雾区域和高浓度烟雾区域都进行结果展示, 无烟雾区域包括人和车辆等容易误判的物体.实验表明DCCNN在多个测试视频中都取得较优效果, 对于不同浓度的烟雾可进行较好地测量, 对于车辆、人等容易误判的物体也有较好的鲁棒性.
 | 图6 DCCNN烟雾浓度检测结果Fig.6 Smoke density detection results of DCCNN |
为了解决烟雾浓度测量这一难题, 首先, 根据烟雾化方程, 推出烟雾图像与浓度的物理模型, 计算烟雾图像对应的浓度, 避免手动标注烟雾浓度的难题.然后, 将深度学习和CNN应用在烟雾浓度测量领域, 提出双通道深度卷积神经网络(DCCNN)的烟雾浓度测量方法.实验表明, 在阈值为0.1时, DCCNN性能较优, 并且测量速度基本满足实时检测要求.实验也证实双通道和注意力机制有助于提高烟雾浓度测量准确率.
目前网络上公开发布的烟雾视频数据库数量较少, 虽然本文通过数据增强等方法进一步丰富数据集, 但数据集上的场景类型仍不够丰富.今后将继续扩大数据集, 并考虑将合成数据和真实数据一起学习, 同时进一步设计新型网络结构, 提升方法的准确率和鲁棒性.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|