


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于多分支协作的行人重识别网络
[张磊1  , 吴晓富
, 吴晓富1 , 张索非2 , 尹梓睿1 ]
, 吴晓富, 张索非, 尹梓睿]
|
|



作者简介:

张 磊,硕士研究生,主要研究方向为行人重识别.E-mail:1019010621@njupt.edu.cn.

张索非,博士,讲师,主要研究方向为图像与视频信号处理、机器学习、物联网技术等.E-mail:zhangsuofei@njupt.edu.cn.

尹梓睿,硕士研究生,主要研究方向为机器学习等.E-mail:1343776717@qq.com.
设计多分支网络以提取分集特征已成为行人重识别领域的重要方向之一.由于单分支学习到的特征表达能力有限,所以文中提出基于多分支协作的行人重识别网络.在局部分支、全局分支、全局对比池化分支、关联分支这4个相互协作的分支上进行特征提取,获得强大的分集行人特征表达能力.文中网络可应用于不同的主干网络.实验中考虑OSNet、ResNet作为文中网络的主干网络进行验证.实验表明,文中网络在行人重识别数据集上均取得Start-of-the-art结果.
About Author:
ZHANG Lei, master student. His research interests include person re-identification.
ZHANG Suofei, Ph.D., lecturer. His research interests include image and video signal processing, machine learning and Internet of things.
YIN Zirui, master student. His research interests include machine learning.
Designing multi-branch networks to learn rich feature representation is one of the important directions in person re-identification (Re-ID). Aiming at the limited feature representation learned by a single branch, a multi-branch cooperative network for person Re-ID (BC-Net) is proposed. Powerful feature representation for person Re-ID is obtained by extracting features from four cooperative branches, local branch, global branch, relational branch and contrastive branch. The proposed network can be applied to different backbone networks. OSNet and ResNet are considered as the backbone of the proposed network for verification. Extensive experiments show that BC-Net achieves state-of-the-art performance on the popular Re-ID datasets.
本文责任编委 叶东毅
Recommended by Associate Editor YE Dongyi
飞速发展的深度学习目前已应用到计算机视觉的许多领域, 如图像分类、目标检测、语义分割、行人重识别等.一般地, 行人重识别有3种典型任务:行人检测、行人跟踪、行人检索.通常, 行人重识别的任务集中于人员检索, 即从多个摄像头捕获的大规模行人图像中训练具有行人辨别能力的特征模型.因为有视角、照明变化、姿势、遮挡和异质模式[1]等多种随机干扰因素影响, 摄像头拍摄的行人图像具有多种差异, 造成行人重识别任务的难度, 因此进一步提高检索精度仍是一个巨大的挑战.
行人重识别任务的关键是找到行人图像中丰富且具有分辨性的特征表示.卷积神经网络(Convo-lutional Neural Networks, CNN)因其独特的优势, 广泛应用于行人重识别任务中[2].朴素的CNN只能学习图像的全局特征, 由于无法使用全局特征较好地表示类内差异, 检索性能非常有限.一般来说, 全局特征有助于学习轮廓信息, 以便从更广阔的视野中检索图像.
但是, 局部特征可能包含更细粒度的信息.在Yi等[3]和Li等[4]中, 将输入的行人图像分为3个重叠部分, 分别学习这三部分的特征, 这种模式下行人图像不同的身体部分对结果的影响不一样, 躯干最稳定, 导致影响最大, 腿部结构变化最大, 导致影响最小.后来, 出现身体划分的不同方式.Su等[5]提出基于姿势的深度卷积(Pose-Driven Deep Convo-lutional, PDC), 考虑身体姿势对外观的影响, 使用姿势的关键点划分不同的身体区域和权重, 采用姿势估计算法预测姿势.这种方法依赖于外部人体姿态估计数据集和复杂的姿态估计, 但姿态估计和行人检索数据集之间的内在差距仍是一个问题.Zhao等[6]提出局部对齐表达(Part-Aligned Representa-tions, PAR), 放弃语义线索, 将人体划分成几个不相交的区域, 再连接每个区域的特征向量, 获得最终的特征向量表示, 将注意力机制嵌入网络中, 可自行决定关注点, 但会忽略各部分之间的一致性.Sun等[7]提出基于局部的卷积主干网络(Part-Based Con-volution Baseline, PCB), 局部特征表示方法(如头部、身体等)平均划分特征图以学习局部特征, 并提出改进的局部池化(Refined Part Pooling, RPP)以提高划分区域的内容一致性.PCB对每个划分的特征分别进行ID预测损失的计算, 可获得有用的局部特征以区分不同的人.但是, 许多局部特征含有的信息是有限的, 可能根本无法捕捉到不同人之间的区别信息.Wang等[8]提出多粒度网络(Multiple Granu-larities Network, MGN), 将图像均匀划分为多个条纹, 获得具有多个细粒度的局部特征表示.目前, 大量实验表明:不宜将图像划分过度, 反而会因为局部信息过少导致图像信息的损失, 降低检索精度.局部划分保证细粒度, 但信息有限; 全局信息充分, 但缺少局部考量.
关系型网络的基本思想是考虑所有局部特征并整合彼此的关系[9].全局特征和局部特征的级联有利于更丰富的行人特征表达.由于图像局部之间并非相互独立, 为了进一步提高特征的丰富性, 有必要级联图像局部之间的关联信息特征和背景与行人的对比信息特征.全局对比池化(Global Contrastive Pooling, GCP)[10]融合具有区分度的信息, 而关联模块[10]利用行人图像的局部和其余部分之间的关联性, 使网络更具有可区分性, 同时也保留紧凑的特征表示.
最大池化主要用于CNN的下采样, 平均池化主要用于取代全连接层以减小参数量.最大池化和平均池化的最佳适用场合还无理论指导.所以, 可使用通用均值(Generalized-Mean, GeM)[11]池化缩小最大池化和平均池化之间的差距.
因此, 本文提出基于多分支协作的行人重识别网络(Multi-Branch Cooperative Network for Person Re-identification, BC-Net).在局部分支、全局分支、全局对比池化分支、关联分支这4个相互协作的分支上进行特征提取, 获得强大的分集行人特征表达能力.文中网络可应用于不同的主干网.本文将ResNet[12]和轻量级网络OSNet[13]作为主干网构建BC-Net, 在多个行人重识别数据集上都取得Start-of-the-art性能..
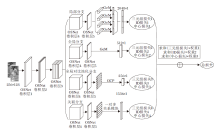
本文提出基于多分支协作的行人重识别网络(BC-Net), 将OSNet[13]作为主干网构建BC-Net, 简记为BC-OSNet.BC-OSNet整体网络架构如图1所示.输入图像大小为H× W× C , 其中, 高度H=3, 宽度W=3, 通道数C=3.BC-OSNet的共享网络采用OSNet的前5层, 包括3个卷积层和2个过渡层.再采用4个协作分支进行特征提取, 包括局部分支、全局分支、全局对比池化分支和关联分支.使用4个分支是为了学习丰富但具有区分度的特征.
 | 图1 BC-OSNet整体网络架构Fig.1 Overall network architecture of BC-OSNet |
与BC-OSNet网络结构相似, 将ResNet作为主干网构建BC-Net, 简记为BC-ResNet.在BC-ResNet网络结构中, ResNet(实验中使用的ResNet-101_ibn_a)的前四层作为共享网络, conv_1、conv2_x、conv3_x、conv4_x、conv5_x作为协作分支的一部分, 用于学习多样特征.
第一个分支是局部分支.在该分支中, 特征图划分为4个水平网格, 使用平均池化获得1× 1× C的局部特征.值得注意的是, 将4个局部特征串联到一个列向量中, 产生单个ID预测损失, 而每个局部特征通过PCB[7]的ID预测损失进行学习.最终级联特征为
f=[
其中f1、 f2、 f3、 f4表示水平划分特征图的4个列向量.
标记数据集合(xi, yi), i=1, 2, …, Ns.ID预测损失为
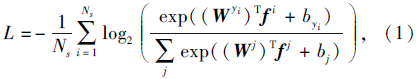
其中,
第二个分支是全局分支.对于BC-OSNet, 与局部分支的区别在于, 在卷积层4和卷积层5之后直接执行GeM池化.注意GeM的初始化参数设置pk=3.0, 获得512维向量:
GeM(fk=[f0, f1, …, fn])=
其中GeM运算符fk为单个特征图.当pk→ ¥ 时, GeM相当于最大池化, 当pk→ 1时, GeM相当于平均池化.
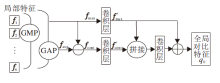
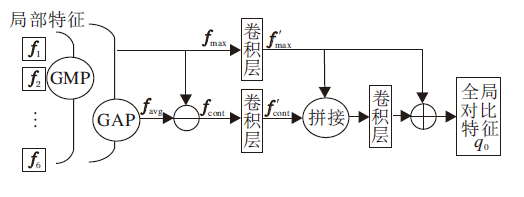
第三个分支是全局对比池化(GCP)分支, 框图如图2所示.GCP基于平均池化和最大池化获得局部对比特征.对于BC-OSNet, 卷积层5输出特征图后, 划分为6个水平网格, 并通过GCP获得256维特征向量.为了更好地理解GCP的内部结构, 使用favg和fmax分别表示通过平均池化和最大池化获得的特征图.
| 图2 全局对比池化分支框图Fig.2 Flow chart of global contrastive pooling branch |
平均池化是在每个局部特征(favg=
上操作的, 而最大池化是在卷积层5的输出的特征图上进行的.对比特征
fcont=
表示它们之间的差异信息.
为了降低维度, 瓶颈层(Bottleneck Layer)用于处理通道数为C的fcont和fmax, 相应的降维特征由通道数为c的f'cont和f'max表示.全局对比特征
q0=f'max+B(C(f'max, f'cont)),
其中, C表示f'cont和f'max的串联, 以形成通道数为2c的列向量, B表示瓶颈层操作, 通过该操作, 通道维数由2c减小为c.
第四个分支是一对多关联分支.局部特征包含各个区域的信息, 但不能反映它们之间的联系, 局部关联分支将图像区域与相应的剩余部分关联.与GCP类似, 通过局部关系模块计算6个水平网格特征, 分别为f1, f2, …, f6.
首先, 利用平均池化获得
ri=
然后, 瓶颈层处理 fi和ri, 将通道数从C减少到c, 生成f'i和r'i.使用关联网络, 计算局部关系特征
qi=f'i+B(C(f'i, r'i)), i=1, 2, …, 6,
在BC-OSNet上, qi为256维的向量.
计算局部关联特征的一对多模块, 框图如图3所示.
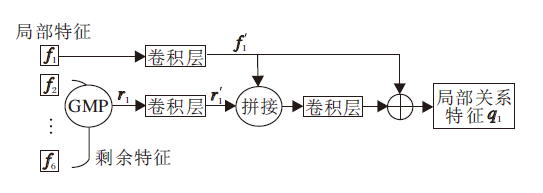 | 图3 一对多关联分支框图Fig.3 Flow chart of one-vs-rest relation module |
为了训练网络, 总损失函数是每个分支损失函数的总和, 包括ID损失(softmax损失)、软边界三元损失(Soft Margin Triplet Loss)[14]和中心损失[15]:
Lsum=λ 1Lid+λ 2Ltriplet+λ 3Lcenter,
其中λ 1、λ 2、λ 3为加权因子, 实验中分别设置λ 1=1, λ 2=1, λ 3=0.000 5.单个ID损失如式(1)所示.随机提取每个小批量的P个类别和K幅图像, 则软边界三元损失定义为

其中,
为了提高特征的判别能力, 中心损失定义为
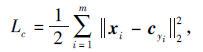
其中, xi∈ Rd表示第i个深度特征,
在3个行人重识别数据集Market1501、DukeMTMC-reID、CUHK03上进行实验.Market1501数据集由6台摄像机拍摄的32 668幅行人图像组成, 共1 501个类别(ID), 包含751个类别的12 936幅训练图像, 750个类别的3 368幅查询图像, 751个类别的1 5013幅数据库图像.
DukeMTMC-reID数据集由8个摄像头拍摄得到, 包括702个类别的16 522幅训练图像, 702个类别的2 228幅查询图像和1 110个身份的17 661幅数据库图像.
根据标注方法的不同, CUHK03数据集分为CUHK03-Labeled和CUHK03-Detected, 由2个摄像机拍摄得到, 分别有14 096幅图像和14 097幅图像.CUHK03-Labeled数据集包括7 368幅训练图像, 1 400幅查询图像, 5 332幅数据库图像.CUHK03-Detected数据集包括7 365幅训练图像, 1 400幅查询图像, 5 328幅数据库图像.
对于BC-OSNet, 输入图像大小为256× 128, 数据增强方法有随机翻转和随机擦除[16].对于BC-Res-Net, 输入图像大小为256× 192, 在数据增强中使用随机翻转、随机擦除和随机裁剪.2个主干网络使用不同的配置可获得各自最优精度.优化器是自适应矩估计(Adaptive Moment Estimation, Adam)[17], 动量设为0.9, 权重衰减设为5e-4.在训练过程中, 批尺寸大小设置为64, 迭代次数设为160.每个批次中包含16个ID, 每个ID有4幅图像.在训练期间使用预热策略, 初始学习率为3.5e-4, 在第60个批次后, 学习率更改为3.5e-5, 在第100个批次后, 学习率更改为3e-6.
所有网络都使用PyTorch进行端到端训练.对于BC-OSNet, 使用单独的NVIDIA Tesla P100 GPU 分别训练Market1501、DukeMTMC-reID、CUHK03数据集, 大约需要12 h、15 h、6 h.对于BC-ResNet, 分别需要25 h、31 h、12 h.
本文选择平均准确率均值(mean Average Preci-sion, mAP)和Rank-1作为评价指标.以OSNet为例, 增加分支后的训练时间对比如表1所示.
| 表1 各网络的训练时间对比 时 ∶ 分 ∶ 秒(英文的) Table 1 Training time comparison of different networks |
从单分支到全局分支和局部分支结合的二分支结构, 在Market1501、DukeMTMC-reID数据集上, 训练时间增加约两个小时, 在CUHK03数据集上增加近1个小时.增加到四分支网络时, 训练时间递增.时间的增加体现网络花费额外的时间去学习不同表达性的特征.
本节选择如下对比网络:PCB[7]、PCB+RPP[7]、MGN[8]、GCP[10]、OSNet[13]、协调注意力卷积神经网络(Harmonious Attention Convolutional Neural Net-work, HA-CNN)[18]、对齐的行人重识别(Aligned-ReID)[19]、水平金字塔匹配(Horizontal Pyramid Mat-ching, HPM)[20]、ABD(Attentive But Diverse)[21]、二阶非局部注意力(Second-Order Non-local Attention, SONA)[22]、关系感知的全局注意力(Relation-Aware Global Attention, RGA-SC)[23]、显著性引导级联抑制网络(Salience-Guided Cascaded Suppression Net-work, SCSN)[24]、一些技巧(Bag Of-Tricks)[25]、批丢弃块(Batch DropBlock, BDB)[26].
Aligned-ReID在动态匹配局部信息下结合全局特征和局部特征.HPM对特征图进行多尺度的水平切割, 相互协作.AlignedReID和HPM考虑全局信息与局部信息的重要性, 但忽略局部信息之间的关联与对比.
各方法在3个行人重识别数据集上的性能对比如表2所示.表中黑体数字表示最优结果.结果均未使用多查询融合(Multi-query Fusion)或Re-ranking[27]技术, BC-OSNet是融合GeM后的结果.
| 表2 各网络在3个数据集上的性能对比 Table 2 Performance comparison of different networks on 3 datasets % |
由表2可看出, 相比单分支OSNet:在CUHK-03-Detected数据集上, 多分支结构的mAP提升12.7%, Rank-1提升12.0%; 在Market1501数据集上, mAP提升4.6%, Rank-1提升0.8%; 在Duke-MTMC-reID数据集上, mAP提升7.7%, Rank-1提升2.8%.
表2中BC-ResNet是融合CutMix后的结果, 几乎在4个数据集上都达到最优性能.由此可看出, BC-Net可学到分集互补性较好的特征.
BC-Net中4个分支多样性的类激活映射图(Class Activation Map, CAM)如图4所示.由图可观察到, 这四个分支各自学到的特征在一定程度上有互补作用, 这意味着BC-Net网络架构可学习到多样性的特征, 这也是行人重识别任务中的关键.
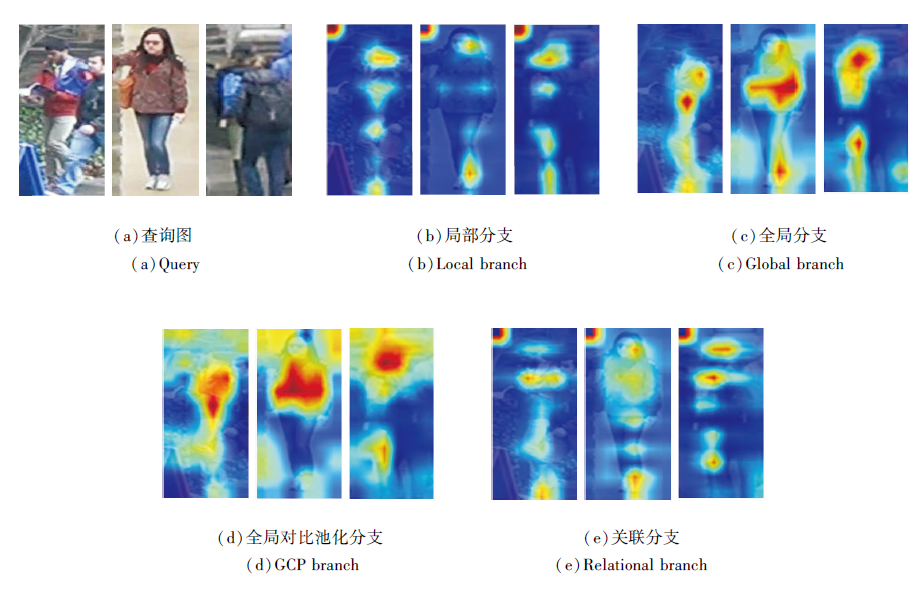 | 图4 BC-Net中4个分支的类激活映射图Fig.4 Class activation maps of 4 branches of BC-Net |
通过检索结果的可视化更直接地对比OSNet、ResNet、BC-OSNet和BC-ResNet.对于同个类别, 4个网络的检索结果如图5所示.由图可知, 单分支网络在top10检索结果上并不理想, 经过多分支学到的特征之间相互补充, 使同个类别行人图像top10检索准确率大幅提升.
 | 图5 不同网络在相同类别图像上的top10检索结果Fig.5 Top 10 retrieval results of different networks for images in same class |
BC-Net全面考虑这四个分支的协作性, 组合效果如表3所示, 表中黑体数字表示最优结果.在3个数据集上, 尤其是在CUHK03数据集上, 获得Start-of-the-art结果.由表可看出, 四个分支相互协作, 互为补充.在使用四分支协作网络结构时, 可获得稳定性能.
| 表3 不同分支组合的结果 Table 3 Results of various combinations of branches |
GeM视为全局平均池化(Global Average Pooling, GAP)和全局最大池化(Global Max Pooling, GMP)的通用版本.GeM中固有的可学习参数pk可学习GAP和GMP之间的更好版本.pk值不同时GeM会有不同表现.由文献[11]中得到具有较好性能的pk值.定义GeM(3, 3)是指将局部分支和全局分支中的平均池化(Average Pooling, AP)和GMP操作都替换为GeM池化, pk=3; GeM(1, 6.5)是指将局部分支中的AP操作替换为pk=1的GeM 池化, 将全局分支中的GMP替换为pk=6.5的GeM池化; GeM(3, 6.5)设置类似.
pk不同时各网络的性能对比如表4所示, 表中黑体数字表示最优结果.由表可看出, GeM池化略优于常规的最大池化和平均池化.实验中使用的pk值是固定的, 也可自适应学习pk值.
| 表4 pk不同时各网络的性能对比 Table 4 Performance comparison of different networks with different pk % |
文中虽然实验结果相差不大, 但是在局部分支和全局分支中, pk=3.0时能获得相对稳定的性能.使用其它参数性能会略有不足, 尤其是在pk值趋于0或无穷时.文献[11]中指出学习共享参数性能优于学习多个参数, 共享的学习参数性能优于共享的固定参数, 但这要基于不同的网络结构.在此次实验中, 相同的参数效果要略优一些.
本文考虑使用
| 表5 BC-OSNet中 |
本文提出基于多分支协作的行人重识别网络(BC-Net), 具有局部分支、全局分支、局部关联池化和对比分支的四分支体系结构, 获得更多样和更高分辨率的特征.以OSNet和ResNet作为BC-Net主干网络的实验证实四分支框架的有效性.另外, BC-Net也应用微结构和技巧, 包括GeM.消融实验表明四分支的协作可学习到互补的特征.BC-Net在3个行人重识别数据库上取得Start-of-the-art结果.BC-Net立足于多个行人重识别网络的融合创新, 通过实验证实多分支网络的优异性.缺陷是网络参数量和训练时间都有明显上升.目前, 多分支通过协作有效提高行人重识别性能还缺乏理论支撑, 有待进一步证明分析.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|