
{kind=link}
{kind=link}
{kind=link}
属性网络中基于变分图自编码器的异常节点检测方法
[李忠1, 2  , 靳小龙
, 靳小龙1, 2 , 王亚杰1, 2 , 孟令宾1, 2 , 庄传志1, 2 , 孙智1, 2 ]
, 靳小龙, 王亚杰, 孟令宾, 庄传志, 孙智]
|
|



作者简介:

靳小龙,博士,研究员,主要研究方向为知识图谱、社交网络计算.E-mail:jinxiaolong@ict.ac.cn. 
王亚杰,博士研究生,主要研究方向为信息抽取.E-mail:wangyajie18b@ict.ac.cn. 
孟令宾,博士研究生,主要研究方向为知识图谱.E-mail:menglingbin19b@ict.ac.cn. 
庄传志,博士研究生,主要研究方向为关系抽取、自然语言处理.E-mail:zhuangcz@ict.ac.cn. 
孙 智,博士研究生,主要研究方向为知识图谱、异常检测.E-mail:Sunzhi17b@ict.ac.cn.
图神经网络为属性网络数据挖掘提供融合利用结构信息和属性信息的方法,但是在现阶段基于图自动编码器进行无监督属性网络异常节点检测时,常将正常节点子属性插值形成的节点误识别为异常节点,导致方法的假负率较高.针对上述问题,文中提出基于变分图自编码器的异常节点检测方法.模型包含两个编码器和一个解码器,利用一个编码器和一个解码器构成的变分自编码器模型,重建原始输入数据,再利用解码器和第二个编码器,使模型学习到不包含异常节点数据的网络隐层表达.通过双变分自编码器学习正常节点子特征,并利用重建误差作为节点的异常度量,将由正常节点子特征构成的正常节点判别为正常节点.在真实网络数据集上的实验表明,文中方法能有效进行属性网络异常节点检测.
About Author:
JIN Xiaolong, Ph.D., professor. His research interests include knowledge graph and social network computing.
WANG Yajie, Ph.D. candidate. His research interests include information extraction.
MEMG Lingbin, Ph.D. candidate. His research interests include knowledge graph.
ZHUANG Chuanzhi, Ph.D. candidate. His research interests include relation extraction and natural language processing.
SUN Zhi, Ph.D. candidate. His research interests include knowledge graph and anomaly detection.
Graph neural network provides a method of combining structural information and attribute information for attribute network data mining. However, the current unsupervised attribute network anomaly node detection based on graph auto-encoder cannot capture the sub-features of normal nodes, and the false negative rate is high.Anomaly node detection method based on variational graph auto-encoders is proposed to detect abnormal nodes in attribute networks, containing two encoders and a decoder. A variational auto-encoder model consisting of an encoder and a decoder is designed to reconstruct the original input data. A decoder and the second encoder are utilized to learn the latent representation of the network without abnormal node data. The features of normal nodes are learned by the dual variational auto-encoder, and the reconstruction error is applied as the anomaly measure of nodes. Normal nodes composed of normal node features are identified as normal nodes by taking reconstruction error as the anomaly measurement of nodes. Experiments on real network datasets show that the proposed method is able to detect abnormal nodes in attribute networks effectively.
本文责任编委 郝志峰
Recommended by Associate Editor HAO Zhifeng
在大数据时代背景下, 属性网络的结构复杂度与属性信息维度都具有相当大的规模, 如何充分利用网络的结构信息和网络节点的属性信息进行网络数据挖掘获得学者们越来越多的注意力[1].属性网络中异常节点检测任务的目标是从属性网络中查找统计数据或分布规律和大多数正常节点不同的节点[2], 因此属性网络异常检测在网络分析与数据挖掘领域也受到学者们的关注[3].在现实的属性网络中, 根据具体应用场景的不同, 异常个体节点主要分为3类:结构异常[4, 5, 6]、属性上下文异常[7, 8, 9]、混合结构和属性信息异常.
近年来, 图神经网络由于能结合网络结构信息和节点特征信息进行隐层特征学习, 在很多图数据挖掘任务中表现出较优性能[10].但在实际的属性网络异常检测场景中, 通常绝大多数样本是正常样本, 异常样本数量占比极少, 并在很多场景中, 缺少真正可信的异常标注数据, 因此有监督的属性网络异常检测算法普适性较差.由于异常的原因和类型多种多样, 而正常节点的结构和属性特征具有一定的规律, 因此, 可利用无监督方法学习正常节点的特征规律, 结合重建误差以识别网络中的异常节点.
按照网络的节点是否包含属性信息, 可将网络异常检测分为无属性网络异常节点检测和属性网络异常节点检测.
无属性网络异常节点检测方法包括:1)基于节点结构的方法, 如权重图异常检测(Spotting Anoma-lies in Weighted Graphs)[11].2)基于社团的异常检测, 使用群体检测方法[12, 13, 14]查找异常节点, 此类算法可解释性较强, 但效果依赖于不同的群体检测方法, 只能检测固定类型的异常节点.3)基于图谱分析技术异常检测方法, 如EigenSpokes(Surprising Pa-tterns and Scalable Community Chipping in Large Graphs)[15], FRAUDAR(Bounding Graph Fraud in the Face of Camouflage)[16], M-Zoom(Fast Dense-Block Detection in Tensors with Quality Guarantees)[17], D-Cube(Dense-Block Detection in Terabyte-Scale Ten-sors)[18], 此类算法计算效率较高, 可扩展性较强, 但检测结果存在较高偏差, 异常数据中存在较多的正常数据.由于网络表示学习技术可将高维度的网络映射到一个低维的网络中, 使用网络表示学习技术进行个体节点嵌入及群体嵌入, 并结合分类技术, 可查找影响结构稳定的异常节点[19, 20].无属性网络异常节点检测方法通常只能利用网络的结构信息, 无法利用网络节点属性信息, 也无法利用网络隐层特征进行异常检测.
属性网络融合网络结构和节点属性信息, 属性的多样性及结构与属性融合也给属性网络异常节点检测带来极大挑战.传统的属性网络异常检测方法主要依赖特征选择方法, 如基于属性相似度云模型的网络异常检测方法[21].
为了充分利用网络结构和属性信息, 研究者利用残差矩阵进行检测.Li等[22]提出RADAR(Resi-dual Analysis for Anomaly Detection in Attributed Networks), 利用网络和属性信息结合的残差矩阵进行异常检测.Peng等[23]提出ANOMALOUS(Joint Mo-deling Approach for Anomaly Detection on Attributed Networks), 利用重建和残差矩阵分析进行异常检测.
随着卷积神经网络(Convolutional Neural Network, CNN)在计算机视觉方面的成功应用, 学者们考虑将CNN应用于网络数据挖掘.为了克服网络数据结构稀疏及网络结构为不规则的非欧氏空间的问题[10], 利用图卷积网络(Graph Convolution Network, GCN)进行节点分类检测异常的方法是有监督的机器学习方法, 而异常节点检测通常没有可信标注数据, 因此多使用无监督或半监督的方法.Ding等[24]提出DOMINANT(Deep Anomaly Detection on Attributed Net-works), 对原始训练数据依赖性较高, 检测结果存在较大偏差.
针对极少数现实世界中可以以较小的成本获得异常标注数据的异常检测问题, Pang等[25]提出弱监督异常检测算法, 在建模期间还可使用有限数量的标记异常数据, 使用标记的小规模异常数据进行学习, 有助于识别感兴趣的异常并解决无监督异常检测中高误报率问题.
针对使用图训练机制学习目标发现异常但无法扩展, 且无法连接到大型网络的问题, Liu等[26]提出CoLA(Contrastive Self-Supervised Learning Framework for Anomaly Detection on Attributed Networks), 可用于大型网络, 但算法结果对于节点对的选择具有一定的依赖性.
因此, 本文提出基于图变分自编码器的异常节点检测方法(Anomaly Node Detection Method Based on Variational Graph Auto-Encoders, VGAEE), 通过重建误差判断节点是否为异常节点.模型包含两个编码器和一个解码器, 利用一个编码器和一个解码器构成的变分自编码器模型重建原始输入数据, 再利用解码器和第二个编码器, 使模型学习到不包含异常节点数据的网络隐层表达.通过双变分自编码器学习正常节点子特征, 并利用重建误差作为节点的异常度量, 将由正常节点子特征构成的正常节点判别为正常节点.在真实网络数据集上的实验表明, 本文方法能有效进行属性网络异常节点检测.本文方法源代码开源在https://github.com/lizhong2613/VGAEE.
本文使用的标识符号和常用的网络定义符号相同, 具体如下.
定义 1 属性网络 定义一个属性网络ζ =(V, ε, X)由, 其中, V={v1, v2, …, vn}表示网络中所有节点的集合, 网络中节点个数为n, |V|=n.ε表示网络中所有节点连接边的集合, 其中|ε|=m.X为n×d矩阵, 表示网络中所有节点属性组成的集合.第i个节点的属性xi∈ Rd, i=1, 2, …, n.连接矩阵A∈ Rd×d, 表示网络节点和节点之间的连接关系, 如果节点i、 j之间存在连接, Ai, j=1, 否则Ai, j=0.对于一个有向连接网络, 连接矩阵A=max(A, AT), 将有向网络转为无向网络进行处理.
定义 2 属性网络异常节点检测 给定一个属性网络ζ =(V, ε, X), 从该网络中检测一个异常节点集合O={o1, o2, …, ok}, 其中oi, i=1, 2, …, k的结构和属性分布规律和其它大多数节点不同.
图神经网络类型开始主要为图卷积神经网络和图注意力网络, 后期其它神经网络迁移到图数据挖掘领域, 如图时空网络、图生成网络、图自编码器网络.图神经网络的本质是在图上对节点进行自动特征提取.
由于异常节点检测任务标注样本较少, 使得有监督的方法不适用于属性网络异常节点检测, 如利用图卷积神经网络和图注意力网络进行分类.
无监督的图神经网络异常节点检测可利用原始无标注样本数据, 学习属性网络的低维表达, 并利用重建数据与原始数据误差, 检测异常节点.自编码器是由多个编码函数和解码函数构成的可无监督学习的神经网络, 并在自然语言处理、计算机视觉及语音识别等领域存在广泛应用[27].图自编码器网络是将自编码器迁移至图数据上[28].目前图自编码器网络及其变种广泛应用于图节点表示, 图自编码器一般包含两部分:图自编码器和图解码器.图编码器将原始的网络数据表示为一个隐层表达, 图解码器根据隐层还原图的原始数据.根据采用降维的目标函数的不同, 可分为L2重建、拉普拉斯特征映射、递归重建、排序、生成对抗网络(Generative Adversarial Net-works, GAN)等, 其中部分方法可应用于属性网络[29].
变分图自编码器(Variational Graph Auto-Enco-ders, VGAE)的隐层表示不是通过一个函数获得, 而是先通过一个GCN, 确定一个多维高斯分布, 再计算均值向量和协方差矩阵, 即通过采样得到隐层表示:
μ=GCNμ(X, A), log2σ=GCNσ(X, A),
其中用到的2个卷积层权重矩阵是不同的.
区别于自编码器通过提取特征建立输入输出之间的映射, 应用VGAE的目标是让模型学习属性图的隐层特征, 通过训练数据, 可得到正常数据子特征的分布, 而通过学习训练数据的分布, 可生成与训练数据相似的数据, 生成数据与真实的正样本数据极为相似, 而异常数据会与生成数据存在较大不同, 因此, 可利用生成式模型进行异常检测.生成式模型GAN是一种学习范式, 并不特定于某种模型架构, 并且由于其存在2个模型互相博弈的特点, 理论的近似极限也无法确定.本文尝试将变分自编码器(Variational Auto-Encoders, VAE)应用于属性网络, 利用隐变量模型, 推断真实分布的近似值, 取得较优效果.
Ding等[24]提出DOMINANT, 依赖原始训练数据, 以整个属性图作为输入, 只能从一个原始的输入属性图G得到对应的重构属性图
本文提出基于变分图自编码器的异常节点检测方法(VGAEE), 框架采用图变分自编码器, 在编码过程中增加一些限制, 使生成的隐含向量能粗略遵循一个标准正态分布.
具体地, 在编码器中, 增加计算均值的网络和计算方差的网络.在计算均值的网络上施加高斯噪声, 使解码器对噪声具有鲁棒性, 增加一个KL散度损失函数, 目的是让均值为0, 方差为1.对应计算方差的网络用于动态调节噪声的强度.在解码器初始训练阶段, 重构误差远大于KL散度损失, 适当降低噪声, 使结果容易拟合.在训练后期, 重构误差小于KL散度损失, 增加噪声, 增加重构误差, 使用解码器提升它的生成能力.
利用均值网络和误差网络, 结合隐层向量概率分布, 使生成的结果包含由正常子特征构成的新样本, 避免由于输入网络中不存在而被自编码器为主的方法判断为异常情况.
在DOMINANT[24]中, 如果原始输入网络包含异常数据, 重构的属性网络也包含异常数据, 从而导致无法进行异常检测的问题.针对上述问题, 本文方法使用两层编码器结构, 使生成器可学习正常样本编码隐层特征.由于生成器和编码器都是为正常样本优化而设计, 异常样本无法最小化输入和生成样本之间的距离, 通过两层编码器, 可增加异常样本和正常样本之间的距离, 提高异常检测效果.
VGAEE框图如图1所示.整个模型的框架按顺序主要包含3个子网络:一个自编码器、一个解码器、一个自编码器.
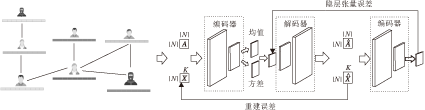 | 图1 本文方法框图Fig.1 Sketch map of the proposed method |
网络结构的自编码器和自解码器构成一个变分自动编码器结构, 通过自编码器实现将输入的网络结构矩阵和网络属性矩阵进行降维, 得到网络的隐层表示, 并通过解码器重建.
具体流程为:对于一个属性网络, 编码器首先读取网络的邻接矩阵A∈ Rn×k和属性矩阵X∈ Rn×n, 将数据前向传播至编码器网络GE.GE由两层GCN组成, 采用批量标准化(BatchNorm)加速神经网络训练过程, 使用线性整流函数(Rectified Linear Unit, ReLU)作为激活函数.通过GE进行特征提取, 将原始的输入数据压缩至一个隐层表示z∈ Rd, 其中d为z能保存网络特征的最小维度.然后隐层网络信息传输给解码器网络GD, 解码器网络针对网络结构和网络属性分别进行重建.X采用两层卷积网络进行重建, 使用ReLU作为激活函数.A采用一层卷积层进行解码, 再采用内积操作进行重建.通过解码器GD重建得到的邻接矩阵和属性矩阵与原始数据的维度相同.该过程可表示为
(
方法第2部分是一个编码器网络E, 使用不同的参数将重建得到的
VGAEE中添加一个额外的自编码器, 这是因为一个编码器和一个解码器可构成自编码器模型, 模型目标是为了重建原始输入数据, 而原始输入数据中包含异常数据.通过第一个解码器之后重建的网络数据是可能包含少量异常数据的结果数据集, 再次使用编码器网络, 得到的
给定一个属性网络数据G, 包含异常个体节点数据, 尽管GE尽量将所有的网络结构信息和网络属性信息包含在隐层表示z内, 但GD无法通过z对异常节点进行重建.这是因为在训练和调参的过程中, VGAEE只能捕获正常数据, 并根据正常数据获取数据的高维特征, 而异常数据因为数据量较少, 且不具备正常子特征, 因此在降维过程中, 对应信息不包含在隐层z中.
在通过变分自编码器得到的还原
重建损失函数和自编码器是相同的, 重建损失函数的目标是使通过解码器还原的数据和原始输入数据尽量接近.
通过重建损失函数, 本文方法能学习属性网络的上下文信息, 为了能尽量学习到正常的子特征, 忽略其它非重要及非正常的子特征, 重建损失函数采用L1正则化范式计算原始数据与重建数据之间的重建误差:
Lrec=α ‖X-
其中α 表示属性矩阵重建误差和邻接矩阵重建误差之间的加权值.
Lrec使解码器生成的数据尽量和原始数据接近, 可能会包含部分噪声数据.因此本文模型包含另外一个编码器E, 编码损失函数Lenc的目标是使通过编码器GE得到的中间变量z和重建变量经过编码器E之后的隐层表示尽量接近.Lenc定义如下:
Lenc=‖GE(A, X)-E(
其中, GE(A, X)表示通过编码器得到的中间隐层变量z, E(
整个方法的损失函数通过重建损失函数和编码损失函数加权求得:
L=β Lrec+(1-β )Lenc,
β 表示两部分的相对权重.
使用样本数据不断训练, 多次迭代, 通过梯度下降法不断优化权重矩阵, 变分自编码器使目标函数不断减小, 并最终收敛.利用最终的隐层进行数据重建, 对每个节点利用重建误差作为衡量节点异常的度量值.对网络中每个节点的异常度定义如下:
score(vi)=α (xi-
其中, xi表示原始节点i的属性向量,
节点的重建误差越大, 说明节点的异常度越高.因此可通过计算节点的异常重建误差, 按照节点的重建误差进行排序, 最后得到网络中异常节点的排序.按照给定的阈值, 最终得到满足阈值的前k个异常节点的集合O={o1, o2, …, ok}.
本节选择使用较多的BlogCatalog、ACM、Flickr数据集进行对比实验.
1)BlogCatalog数据集.从BlogCatalog社交博客网站上爬取的数据, 在该博客社交网络中, 用户可关注另外一位用户形成朋友关系, 每位用户都具有一些描述标签, 该标签整理之后形成节点的属性信息.
2)ACM数据集.ACM学术文章发表的一个引文网络, 网络中的每个节点都是一篇文章, 节点和节点之间的引用形成一条连接边, 每个节点的属性信息为该文章的摘要信息和关键词信息.
3)Flickr数据集.从Flickr网站爬取的社交网络数据.用户可在该网站上分享照片, 网络中每个节点对应一位用户, 节点的属性信息是用户的标签信息, 主要包括用户的兴趣爱好等.
以往的属性网络异常检测方法对上述三个数据集中插入一定数量的异常节点, 为了便于对比, 本文使用的数据集和以往的工作数据集相同, 3个数据集的具体信息如表1所示.
| 表1 实验数据集的详细情况 Table 1 Details of experimental datasets |
本文选择近年来具有代表性的属性网络异常检测方法作为基线方法进行对比.
1)LOF(Local Outlier Factor)[30].LOF基于距离的异常检测算法, 可直接对矩阵检测离群点.对于属性网络, 可直接将属性矩阵应用LOF, 或针对网络特征可结合节点属性矩阵直接进行拼接, 再应用LOF.本文采取第1种方法, 直接对属性矩阵采用LOF.
2)SCAN(Structural Clustering Algorithm for Networks)[6].该方法利用网络结构信息进行网络社团发现, 并将不属于任何社团的孤立节点作为异常节点, 时间复杂度较低, 可扩展性较强.本文直接利用SCAN, 输入网络邻接矩阵计算异常节点.
3)RADAR[22].该方法利用网络属性信息和网络结构信息的残差矩阵, 查找属性网络孤立异常节点.
3)ANOMALOUS[23].该方法是利用降维和残差矩阵分析的属性网络异常检测方法.
4)DOMINANT[10].该方法是基于自编码器的属性网络异常检测方法, 利用CNN进行特征提取, 利用重建误差进行异常节点检测.
5)AMEN(Anomaly Mining of Entity Neighbor-hoods)[7].该方法是基于自我网络结构特征的异常检测方法, 统计属性网络中自我网络的属性分布规律, 判断节点是否为异常节点.
6)CoLA[26].该方法是基于自编码器的属性网络异常检测方法, 利用CNN进行特征提取, 利用重建误差进行异常节点检测.
7)DGI(Deep Graph Infomax)[31].该方法是使用非监督方式学习节点嵌入表示的方法, 通过最大化局部特征与全局特征的互信息, 将属性网络的两者相关性用于分类任务, 进行正常节点与异常节点的分类.
异常检测问题可认为是从给定的样本中进行分类, 识别正负例, 本节使用分类问题中常用评价指标, 具体如下.
1)Recall@K.在前面Top K个查询结果中, 正确结果数量与所有正确结果数量的比率, 也叫查全率.
2)ROC-AUC.对于分类问题, 一般会设置一个阈值, 控制检索结果中正例和负例的不同权重.阈值越低, 较多的样本会被识别为正例, 虽然提高识别率, 但更多的负例会被识别为正例.根据不同的阈值设置, 横坐标由假正率, 纵坐标由真正率构成的分类结果的曲线成为受试者工作特征(Receiver Opera-ting Characteristic, ROC)曲线.ROC曲线下的面积(Area Under Curve, AUC)越大, 算法效果越优.
3)对于异常检测模型, 结果预测为正例或负例, 可使用二分类的评价指标说明模型的优劣.常用的二分类评价指标有真阳性(True Positive Rate, TPR)、真阴性(True Negative Rate, FPR)、假阳性(False Positive Rate, FPR)、假阴性(False Negative Rate, FNR).TPR为所有正例中被预测为正例的比率, 也叫召回率或查全率.FRP为所有反例中被预测为正例的比率.TNR为所有反例中被预测为反例的比率.FNR为所有正例中被预测为反例的比率.TPR越高, FRP越低, 说明模型性能越优.
由于自适应矩估计(Adaptive Moment Estimation, Adam)优化器可利用动量和自适应学习率, 替代梯度下降实现权重寻优, 因此在实验中使用Adam优化器加速神经网络收敛.设置迭代次数为200.实验中设置学习率为0.001, 隐层维度分别设置为8, 16, 32, 64, 128, 256, 512, 1 024, 采用网格搜索交叉验证(Grid Search Cross Validation, gridSearchCV), 确定最优参数.
在对比实验中, SCAN的邻居阈值ε设置为0.7, 邻居数量 μ设置为1.Radar中超参数α =0.1, β =0.01, γ =0.1, 在第17次迭代收敛, 因此设置迭代次数为20.LOF中设置邻居数量为20.DOMINANT中, 设置α =0.7, 迭代次数为300, 图自编码器隐层的维度设置为128.
各方法在3个数据集上的AUC值对比如表2所示, 对于CoLA[26]与DGI[33], 由于未找到可复现的代码, 本文直接使用文献[26]中AUC指标进行对比.
| 表2 各方法在3个数据集上的AUC值对比 Table 2 AUC value comparison of different methods on 3 datasets |
由表2可见, VGAEE的AUC值最高, LOF、RA-DAR、SCAN由于只能使用网络的结构或节点的属性信息, AUC值均低于0.5.
各方法在3个数据集上的Recall@K值对比如图2所示.
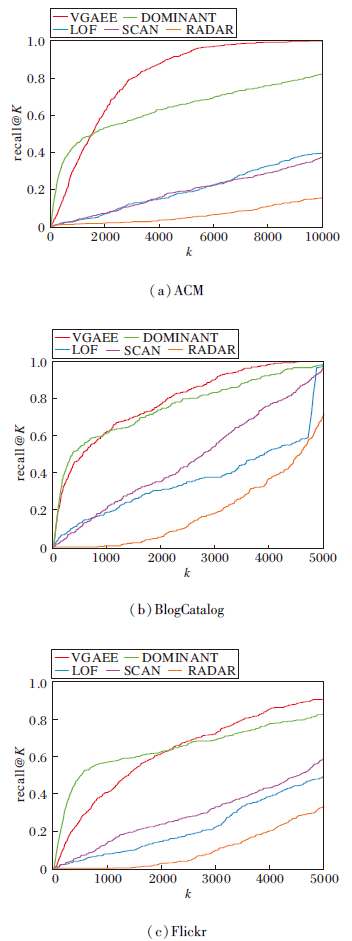 | 图2 各方法在3个数据集上的Recall@K值对比Fig.2 Recall@K value comparison of different methods on 3 datasets |
由图2可看到, 在3个数据集上, DOMINANT和VGAEE优于仅使用网络结构信息或仅使用节点属性的方法.DOMINANT能捕获异常程度较大的节点, 之后性能下降, 无法捕获异常节点的隐层子特征, 存在偏差, 会将正常节点判定为异常节点, 召回率随着K的增大, 无法识别更多的异常节点, 而VGAEE的召回率迅速增加, 识别更多的异常节点.
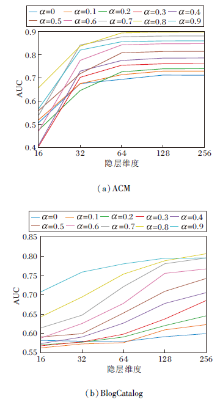
在ACM、BlogCatalog数据集上不同参数对实验结果的影响如图3所示.
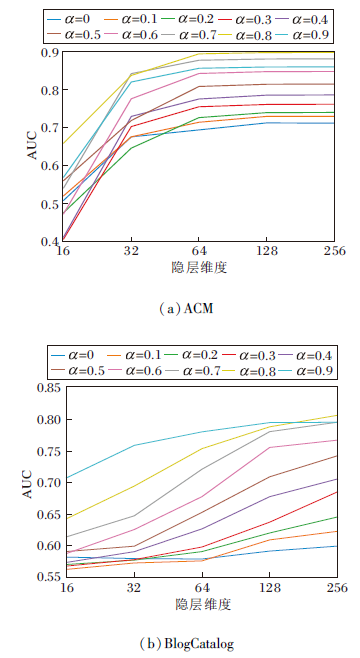 | 图3 α 对AUC值的影响Fig.3 Influence of different α on AUC values |
由图3(a)可看出, 当仅采用网络结构信息(α =1.0)时, AUC值最低, 说明仅采用单一因素进行异常检测效果不理想, 而当α =0.8时AUC值最优, 说明结构信息和节点的属性信息在异常检测上权重不同, 节点的属性信息占比更大.在ACM数据集上, 随着隐层维度的增大, 检测结果更优, 而在隐层维度达到128维之后, AUC值基本达到最优, 在维度达到256时, 无更好提升.
由图3(b)可知, 在BlogCatalog数据集上, α =0.9时AUC值最优, 隐层维度在256时达到最优.该结果说明不同数据集上, 节点的属性信息对于异常检测比网络结构更重要, 但不同的数据集节点属性对异常节点检测的重要性不同, 并且网络隐层维度在达到128或256时能更好地提取网络的深层特征.
本文提出基于变分图自编码器的异常节点检测方法, 可充分利用网络结构信息和节点属性信息进行异常节点检测.利用变分自编码器获取正常节点深度子特征, 并识别由正常子特征构成的节点为正常节点, 减少预测误差, 提升系统的召回率.通过两层编码器, 充分学习属性网络隐层特征, 并利用重建误差进行属性网络异常检测.实验表明, 本文方法优于仅利用网络结构信息或属性信息进行异常检测的方法, 并且优于使用自编码器的网络模型, 能有效地从属性网络中检测出异常节点.今后可考虑使用变分自编码器的改进算法, 如基于流模型的算法, 以提高检测效果, 也可在大规模网络上预训练模型并迁移至其它网络上进行异常检测, 降低时间成本, 提高检测效率.异常检测的可解释性也是今后的一个研究方向.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|