


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于语义传播与前/背景感知的图像语义分割网络
[刘漳辉1, 2  , 占小路
, 占小路1, 2 , 陈羽中1, 2 ]
, 占小路, 陈羽中]
|
|



作者简介:

刘漳辉,硕士,副教授,主要研究方向为数据挖掘.E-mail:lzh@fzu.edu.cn. 
占小路,硕士研究生,主要研究方向为计算机视觉、人工智能.E-mail:458919267@qq.com.
虽然图像语义分割因其有助于更好地分析和理解图像而被广泛应用于多个领域,但是基于全卷积神经网络的模型在语义分割方面依然存在分辨率重构及如何利用上下文信息的问题.因此,文中提出基于语义传播与前/背景感知的图像语义分割网络.首先,提出联合语义传播上采样模块,提取高层特征的全局语义信息与局部语义信息,用于得到语义权重,将高层特征语义传播到低层特征,缩小两者之间的语义差距,再通过逐层上采样实现分辨率重构.此外,还提出金字塔前/背景感知模块,通过两个并行分支提取不同尺度前景特征与背景特征,建立前景与背景间的依赖关系,捕获多尺度的前/背景感知特征,增强前景特征的上下文表示.语义分割基准数据集上的实验表明,文中网络性能较优.
About Author:
LIU Zhanghui, master, associate professor. His research interests include data mi-ning.
ZHAN Xiaolu, master student. His research interests include computer vision and artificial intelligence.
Although image segmentation is widely applied in many fields owing to the assistance of better analysis and understanding of images, the models based on fully convolutional neural networks still engender the problems of resolution reconstruction and contextual information usage in semantic segmentation. Aiming at the problems, a semantic propagation and fore-background aware network for image semantic segmentation is proposed. A joint semantic propagation up-sampling module(JSPU) is proposed to obtain semantic weights by extracting the global and local semantic information from high-level features. Then the semantic information is propagated from high-level features to low-level features for alleviating the semantic gap between them. The resolution reconstruction is achieved through a hierarchical up-sampling structure. In addition, a pyramid fore-background aware module is proposed to extract foreground and background features of different scales through two parallel branches. Multi-scale fore-background aware features are captured by establishing the dependency relationships between the foreground and background features, thereby the contextual representation of foreground features is enhanced. Experiments on semantic segmentation benchmark datasets show that SPAFBA is superior in performance.
本文责任编委 兰旭光
Recommended by Associate Editor LAN Xuguang
图像语义分割或场景解析是计算机视觉中长期存在且充满挑战的基础任务.它的基本目标是对给定图像中每个像素都分配一个对应语义类别的标签, 最后得到对应类别的分割图, 因此图像分割也可看作是像素级的分类任务, 是细粒度最小的图像语义理解任务.精准高效的图像语义分割算法能帮助人们更好地分析和理解图像, 广泛应用于自动驾驶、医疗诊断、图像生成、图像编辑、增强现实等诸多领域.
随着深度神经网络的发展, 学者们提出一些基于卷积神经网络(Convolutional Neural Network, CNN)的图像语义分割算法.全卷积神经网络(Fully CNN, FCN)[1]将完全卷积用于语义分割, 将分类网络的全连接层替换成卷积层, 有效地进行端到端训练, 输入图像大小不受限制, 产生对应大小的密集预测, 实现像素级别的分类预测.此后, 研究者们提出一系列基于FCN的改进算法, 在图像语义分割任务上取得一定进展.但是, 由于FCN通过堆叠卷积与池化操作提取特征, 图像分辨率不断下降, 出现位置信息的损失.此外, 受到感受野的限制, 容易出现错误的上下文信息聚合, 难以适应包括存在多类别的场景在内的一些复杂场景.因此, 图像语义分割研究的重点在于上下文关系建模及解决分辨率重建问题.
针对上下文关系建模, 早期的研究工作主要通过概率图模型描述像素之间的关系, 如条件随机场[2]和马尔科夫随机场[3].针对前端-后端结构, 前端采用深度神经网络(Deep CNN, DCNN)进行特征提取, 后端使用概率图模型提取像素间的依赖关系.但是, 由于模型多在离散的标签空间中进行建模, 计算代价高昂.还有一些方法在骨干网络后通过金字塔聚合或注意力机制捕获上下文关系.基于金字塔聚合的方法主要通过池化操作或空洞卷积操作获得更大范围的上下文信息, 进而融合多尺度特征的上下文信息, 得到更有鉴别力的特征.Zhao等[4]提出PSPNet(Pyramid Scene Parsing Network), 使用空间金字塔池化模块(Spatial Pyramid Pooling, SPP), 通过不同网格大小的池化操作捕获多尺度的上下文信息.Chen等[5]提出DeeplabV3, 使用空洞空间金字塔池化模块(Atrous SPP, ASPP), 通过并行多个不同空洞率的空洞卷积获得多尺度特征图.Yang等[6]提出DenseASPP(Densely Connected ASPP), 使用密集连接的带孔金字塔池化模块, 结合DenseNet(Dense Convolutional Network)[7]与ASPP模块, 有效增大特征的感受野, 获得更大范围的上下文信息.
虽然特征金字塔能收集丰富的上下文信息, 但未对上下文信息的重要性进行有效区分, 忽略前景与背景上下文之间的依赖关系, 影响构建特征的类别区分能力.此外, 人类在观察前景目标时不仅依赖局部信息辨别前景目标的准确类别, 还会与背景进行对比, 以突出前景目标.近年来, 基于注意力机制的方法广泛应用于包括图像语义分割在内的各种计算机视觉任务中.该机制的主要思想是通过一个注意力图对特征进行有选择的增强, 即将注意力更多地放在感兴趣的区域内.受SENet(Squeeze and Excitation Networks)[8]的启发, Zhang等[9]提出EncNet(Context Encoding Network), 使用上下文编码模块, 从编码的语义中生成一个加权向量, 有选择地突出与类别相关的特征.Wang等[10]提出Non_local(Non-local Neural Networks), 利用自注意力机制建模每个像素间的依赖关系, 突破感受野的限制, 捕获长距离的依赖关系.Fu等[11]提出DANet(Dual Attention Network), 从空间与通道两个角度构建两个注意力模块, 并行建模像素间的语义相互依赖关系, 融合两个注意力模块的输出, 进一步增强特征的表示能力.
自注意力机制存在计算复杂度较高且有大量冗余计算的问题.一些优化方法, 如CCNet(Criss-Cross Network)[12]、EMANet(Expectation-Maximization Atten-tion Networks)[13]、ANNet(Asymmetric Non-local Neural Networks)[14], 降低计算复杂度, 其核心思想是优化采样点, 避免在整个图像上建立注意力图.此外, 一些方法聚焦于提取各类上下文关系, 如ACFNet(Attentional and Class Feature Network)[15]、OCRNet(Object-Contextual Representations-Network)[16]等, 引入像素和类别之间的依赖关系, 丰富上下文信息.
随着图神经网络的发展, 研究者们采用图卷积捕获更广泛的上下文信息.Chen等[17]提出GloRe-Net(Graph-Based Global Reasoning Networks), 将坐标空间的像素级特征聚合到交互空间, 再进行有效的关系推理, 最后在反投影回原始坐标空间, 以图卷积的方式有效建模远区域之间的关系.Wu等[18]提出GINet(Graph Interaction Network), 利用图交互单元, 以类别的文本形式提取语义概念, 通过视觉图和语义图的交互更新每个像素特征的信息.
针对分辨率重建问题, 大多数研究者采用空洞卷积[19]或编解码结构.基于空洞卷积的模型主要在骨干网络中以空洞卷积替代原有的卷积操作, 从而维持图像的分辨率.此类方法未引入额外参数, 但高分辨率的特征图显著增加内存消耗与计算复杂度, 限制模型的应用范围.基于编解码结构的模型通过聚合编码器的多层次特征逐步恢复分辨率, 在恢复过程中不断进行上采样及特征融合操作.Ronne-berger等[20]提出U-Net, 每次进行2倍上采样直至恢复原分辨率.Noh等[21]提出DeconvNet(Learning Deconvolution Network), 通过堆叠反卷积层, 逐步恢复原图大小.但是, 上述模型引入大量参数, 增大训练难度.Wu等[22]提出FastFCN, 使用联合金字塔上采样方法, 通过多并行空洞卷积生成高分辨率的特征图.Tian等[23]提出DUsampling, 使用数据依赖上采样方法, 学习重构矩阵以最小化真实标签与压缩标签的误差, 再使用重构矩阵对特征进行上采样.特征融合操作多采用普通的加法或拼接操作.由于高层特征包含丰富的语义信息, 缺少空间的细节信息, 低层特征则相反, 因此, 对高层特征与低层特征进行简单的相加与拼接操作无法得到高质量的特征.
针对上述问题, 本文提出基于语义传播与前/背景感知的图像语义分割网络(Image Segmantic Seg-metation Network Based on Semantic Propagation and Fore-Background Aware, SPAFBA).首先, 提出联合语义传播上采样模块(Joint Semantic Propagation Up-Sampling Module, JSPU), 提取高层特征的全局语义信息与局部语义信息, 得到语义权重, 将高层特征语义传播到低层特征, 缩小两者之间的语义差距, 再通过逐层上采样实现分辨率重构.此外, 还提出金字塔前/背景感知模块(Pyramid Fore-Background Aware Module, PFBA), 通过两个并行分支提取不同尺度的前景特征与背景特征, 建立前景与背景间的依赖关系, 捕获多尺度的前/背景感知特征, 增强前景特征的上下文表示.语义分割基准数据集上的实验表明, SPAFBA性能较优.
本文提出基于语义传播与前/背景感知的图像语义分割网络(SPAFBA), 整体框图如图1所示.
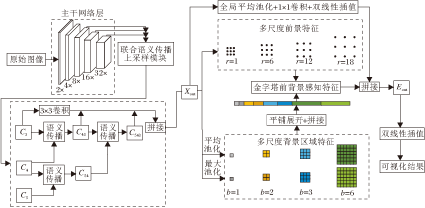 | 图1 SPAFBA整体框图Fig.1 Overall framework of SPAFBA |
SPAFBA主要由深度卷积神经网络模块(DCNN)、联合语义传播上采样模块(JSPU)、金字塔前/背景感知模块(PFBA)及预测层4个模块组成.DCNN是整个模型的入口, 遵循典型的神经网络设计, 也称为主干网络.DCNN输出一个低分辨率、携带丰富语义信息的特征图.JSPU旨在获取具有高分辨率和丰富语义信息的特征, 输出3个具有相同大小的特征图, 分别包含不同级别的语义特征.PFBA以JSPU输出的3个特征图的连接作为模块的输入, 捕获前景特征和背景特征之间的依赖关系, 并增强前景特征的上下文表示, 得到像素鉴别能力更强的特征图.预测层通过Softmax激活函数生成类标签上的概率分布, 预测目标类别.
深度卷积神经网络通过不断堆叠卷积与池化操作, 并使用残差连接加深网络的深度, 提取丰富的特征表示.SPAFBA使用ResNet101作为骨干网络.ResNet101分为5层, 每层对应于1个输出, 分辨率逐层减小为1/2倍, 最后一层输出原图缩小32倍的特征图.另外, 为了减少参数和计算量, 使用3个3×3卷积替换骨干网络第1层中的7×7卷积.
语义分割模型通常采用分类模型作为骨干网络, 如ResNet系列、EfficientNet系列.分类网络对于分辨率的要求并不高, 作为骨干网络时, 最后输出尺寸通常为原图的1/32.但是, 语义分割任务是密集的逐像素预测任务, 最终输出需恢复为原图大小, 因此输出的分辨率大小严重影响模型性能.目前, 大多数模型采用空洞卷积的方法维持特征的分辨率, 虽然能维持特征的分辨率, 但需要更大的内存消耗及计算资源.因此, SPAFBA提出联合语义传播模块, 不采用空洞卷积的方法, 而是从骨干网络后三层的输出中逐步恢复空间信息.
另外, 高层特征分辨率较低, 通常含有丰富的语义信息, 对类别预测更具有区分性, 但缺乏空间位置信息.低层特征则分辨率较高, 含有更多细粒度结构的信息, 但缺乏语义表征能力.充分结合这两种特征的优势是实现精准语义分割的基础.
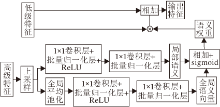
SPAFBA在恢复空间信息时还抽取高层特征的语义信息, 用于增强低层特征的语义表示.首先, 高层特征通过上采样操作实现空间信息的补充, 再利用2个分支分别捕获全局语义权重及局部语义权重.全局语义分支先通过1个全局平均池化操作, 得到C×1×1(C为通道个数)的全局语义向量, 通过2个1×1卷积进行权重学习, 前一个卷积进行通道缩减以减少计算, 后一个卷积恢复成原有通道大小.局部语义分支通过2个简单的1×1卷积学习局部语义权重.与全局语义分支相同, 前一个卷积进行通道缩减以减少计算.将全局语义分支与局部语义分支学习的全局语义及局部语义权重相加, 经过Sigmoid函数激活后, 得到高层特征的语义表示.之后, 通过与低层特征进行逐像素乘法, 将语义信息传入低层, 增强低层特征的语义表示.为了利用残差结构的优势, 模块通过连接的方式融合增强后的低层特征与原低层特征, 得到具有鲁棒性的输出特征:
t=T(l, h)=l+l·sigmoid(F(pooling(h); θ, μ)+F(h; φ, ω)), (1)
其中, T(·)为语义传播函数, l为低层特征输入, 具有相同维度, h为高层特征输入, pooling(·)为最大池化操作, F(·)为分支结构, θ、μ、φ、ω为卷积操作.
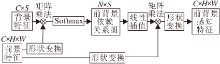
联合语义传播上采样模块的逐级传播结构如图1左下角所示, 最左侧3个特征为骨干网络最后三层的输出, 分别记为C3、C4、C5.不同于经典的以Top-Down方式逐步恢复分辨率的U-Net或FPN(Fea-ture Pyramid Network), JSPU模块的上采样结构类似三角形, 同一阶段考虑每两个相邻特征, 并逐渐上升到顶部.
在第一阶段中, C5与C4进行一次语义传播, 得到输出特征:
C54=C5⊕T(C4, C5),
其中, T(·)如式(1)函数, ⊕为逐像素加法.同时C4与C3进行一次语义传播, 得到特征:
C43=C3⊕T(C3, C4).
此时C43包含C4的语义信息, 减少与C54之间的语义差异.相比而言, Top-Down结构得到C54后直接与C3进行传播, 两者语义差距较大, 并且可能随着不断传递造成语义丢失问题.但是, JSPU模块提出的上采样结构通过每两个邻近特征传递语义信息, 较好地解决语义丢失问题.在第二阶段中, C54与C43再进行一次传播, 得
C543=C54⊕T(C43, C54).
此时C543分辨率为原图的1/8, 并且结合三层特征的语义.最后将C3、C43、C543按通道维度拼接, 得到JSPU模块最后的输出特征:
Xout=concat(ω(C3), C43, C543),
其中, ω为3×3卷积操作, concat表示按通道拼接.Xout空间维度与C3相同, 通道维度为C3通道数的3倍.注意到C3经过3×3卷积层提取更细粒度的特征表示.另外, C4作为整个传播的中间特征, 语义表示能力会影响整个模型性能.因此, SPAFBA在C4处增加一个辅助监督以确保其表征能力.
JSPU模块结构如图2所示.
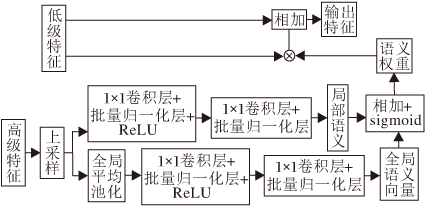 | 图2 JSPU模块结构图Fig.2 Structure of JSPU |
研究表明, 上下文信息有利于模型性能的提升, SPAFBA模仿人类观察辨别事物的方式, 建立前景与背景之间的上下文依赖关系, 更好地识别前景信息, 增强前景特征的类别识别能力.由于图像中相邻像素可能属于不同类别, 空间区分对于前景环境至关重要.SPAFBA使用空洞卷积捕捉前景的上下文, 空洞卷积可提供更大的感受野以捕获空间上更远的上下文信息.对于背景, 由于背景通常是由一些像素作为一整个区域的代表, 无需进行空间区分, 故采用池化方法捕捉背景的上下文信息.
PFBA通过4个不同空洞率的空洞卷积得到4个不同尺度的前景特征:
fi=atrous(Xout; ri ), i=1, 2, 3, 4,
其中, 空洞率r1=1, r2=6, r3=12, r4=18, Xout为上一模块的输出, atrous为空洞卷积操作.由此得到前进特征集合:
F={f1, f2, f3, f4 }.
背景特征由最大池化分支及平均池化分支获得, 注意在每次池化操作后都经过一个堆叠的由1×1卷积、批量归一化层(Batch Normalization, BN)及ReLU激活函数构成的卷积层.经过2个分支可得到2组不同含义的背景特征:
AB={Flat(ab1), Flat(ab2), Flat(ab3), Flat(ab4)},
MB={Flat(mb1), Flat(mb2), Flat(mb3), Flat(mb4)},
其中,
mbi=ρ i (Mpool(Xout; bi )), i=1, 2, 3, 4, abj=τ j(Apool(Xout; bj)), j=1, 2, 3, 4,
Flat为按空间平铺展开操作, Apool为平均池化操作, Mpool为最大池化操作, ρ i、τ j 为1×1卷积操作, 背景划分区域b1=1, b2=2, b3=3, b4=6.最大池化分支重视全局背景特征, 平均池化侧重局部背景特征, 再将其按空间平铺展开并拼接, 得到最后的背景特征:
B=concat(AB, MB),
其中concat为拼接操作.
基于前景特征与背景特征, PFBA提出前/背景感知特征(Fore-Background Aware Feature)的概念, 用于表示经过前景-背景关系图增强后的前/景特征.前/背景感知特征中的每个像素能自适应获得不同背景上下文依赖关系.首先对于背景特征B'按空间维度展开为C×S矩阵, 其中S为背景区域个数.前景特征经过一个空洞卷积之后获得三维特征D∈ RC×H×W.为了获得前/背景的关系图, 将前景特征D维度转换为C×N, 其中N=H×W, 将其转置后与背景特征进行矩阵乘法, 并通过softmax函数激活, 得到前/背景依赖关系图M∈ RN×S, 前景特征第i个位置与第j个背景区域之间的依赖关系表示如下:
Mij=
其中, ·为点积运算, 通过指数映射放大关系差异.
PFBA对关系图M进行线性插值, 将S个背景区域扩成N个, 即由原来的N×S对关系增加到N×N对关系, 以扩充前景特征的视野, 得到更丰富的上下文对比信息.最后的前/背景依赖关系图为
M=Ñ (D, B')=Interpolation(softmax(DT×B')),
其中, Ñ 为获取前/背景依赖关系图函数, Interpola-tion为线性插值操作.
最后, 为了捕获多尺度的前/背景感知特征, 4个前景特征共享同一个背景特征, 将前景特征集合F中的每个前景特征依次与背景特征B通过Ñ (·)函数建立依赖关系, 再通过矩阵乘法对前景特征加权, 并将结果重塑, 得到由4个前/背景感知组成的集合:
A={A1, A2, A3, A4}=f+α (f·Ñ (f, B)),
其中, f∈ F, α 初始值置为0, 通过模型学习得到一个分配权重.
此外, PFBA包括一个全局池化分支, 由全局平均池操作、1×1卷积和双线性插值组成, 用于捕获全局上下文信息.PFBA将4个前/背景感知特征与全局特征按通道维度进行拼接, 并使用1×1卷积缩减通道, 同时加入失活层保证模型的泛化能力.通过融合全局特征与多尺度前/背景感知特征, 获得鉴别能力较强的语义特征图, 即PFBA模块最后的输出特征:
Eout=concat(A, glo_pool(Xout)),
其中glo_pool为全局池化分支操作.
PFBA模块结构图如图3所示.
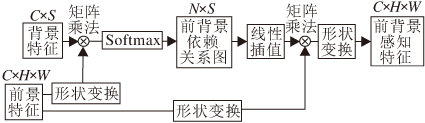 | 图3 PFBA模块结构图Fig.3 Structure of PFBA |
预测层以金字塔前/背景特征感知模块的输出作为输入, 通过一个卷积层将通道输出缩减至总的分类个数, 再通过双线性插值上采样两倍恢复成原图大小, 得到最终的分割预测图.采用像素交叉熵损失应用于最终的分割预测, 通过最小化模型的损失值训练模型.另外, 除了最终的预测损失, SPAFBA对骨干网络第4层的输出进行监督.最终损失为
Ltotal=Lmain+α Laux,
其中, Lmain为最终预测损失, Laux为辅助监督损失, α 为辅助损失的加权参数.
本文在PASCAL_VOC2012、PASCAL-Context、ADE20K数据集上进行实验.PASCAL_VOC2012数据集是一个广泛使用的语义分割基准数据集, 包含20个前景目标类别和1个背景类, 分为3个子集, 训练集包括1 464幅图像, 验证集包括1 449幅图像, 测试集包括1 456幅有精细分割标注的图像.本文使用由SBD数据集提供的额外数据扩充数据集, 得到包含10 582幅图像的训练集, 即train_aug.PASCAL-Context数据集是一个复杂且具有挑战性的场景解析数据集, 包含59个前景目标类和1个背景类, 训练集包括4 998幅图像, 验证集包括5 105幅图像.ADE20K数据集是一个庞大的场景解析数据集, 包含150个类别, 训练集包含25 000幅图像, 验证集包含2 000幅图像, 测试集包含3 000幅图像.
SPAFBA使用标准的ResNet101作为骨干网络, 包含5层网络结构.为了实现全分辨率的预测, 在骨干网络后增加1个上采样层.此外, 使用3个3×3卷积取代第1层的7×7卷积.模型基于PyTorch框架实现, 使用ImageNet上预训练的模型初始化主干网络的权重.学习率采用poly衰减策略, 在训练期间每次迭代后基础学习率根据
lr=base_lr(1-
逐渐下降至0.采用随机梯度下降法(Stochastic Gra-dient Descent, SGD)作为训练优化器, 并设置动量为0.9, 权重衰减为0.000 1.另外, 模型还使用异步批处理归一化(Synchronized Batch Normalization, SyncBN)进行训练, 衰减系数设置为0.000 1.
在数据增强方面, SPAFBA在训练期间对输入图像进行随机水平翻转, 在0.5~2.0范围内对图像进行随机缩放和随机裁剪.
对于不同的基准数据集, 采用不同的训练设置.针对PASCAL_VOC2012数据集, 在验证集和测试集上, 首先将初始学习率设置为 0.001, 裁剪大小为 512×512, 批处理大小为16, 在 train_aug训练集上训练80个迭代周期.然后, 在原始PASCAL_VOC2012训练集上进行微调, 迭代周期设置为50, 设置较小的初始学习率为0.000 1.针对PASCAL_Context数据集, 初始学习率设置为0.001, 裁剪大小设置为520×520, 训练120个迭代周期, 批处理大小设置为16.针对ADE20K数据集, 初始学习率设置为0.004, 裁剪大小设置为576×576, 训练180个迭代周期, 批处理大小设置为16.
采用广泛使用的平均交并比(Mean Intersection-over Union, mIoU)和像素精度(Pixel Accuracy, pixAcc)作为主要评估指标.在测试期间, 模型增加多尺度和翻转的策略进行评估.输入图像按原始尺度的{0.5, 0.75, 1.0, 1.25, 1.5, 1.75, 2.0}进行缩放并随机翻转, 得到多个输入图像, 最后生成最终的预测结果.
实验中采用的对比方法如下.1)语义分割方法:FCN[1]、PSPNet[4]、EncNet[9].2)注意力机制方法:DANet[11]、CCNet[12]、ANNet[14]、CFNet(Cooccur-rent Feature Network)[24]、DMNet(Dynamic Multi-scale Network)[25]、SANet(Squeeze-and-Attention Net-works)[26]、APCNet(Adaptive Pyramid Context Net-work)[27].3)图卷积方法:GINet[18]、CDGCNet(Class-Wise Dynamic Graph Convolution Network)[28].4)其它方法:OCRNet[16]、RecoNet(Low-Rank-to-High-Rank Context Reconstruction Framework)[29]、EfficientFCN[30].
各方法在3个数据集上的mIoU值对比如表1所示.对比方法的实验结果数据均引自对应文献.为了公平对比, 所有对比方法都未采用额外的数据进行预训练.
| 表1 各方法在3个数据集上的mIoU值对比 Table 1 mIoU value comparison of different methods on 3 datasets % |
由表1可知, 相比FCN、PSPNet、EncNet, SPAF-BA的mIoU值有显著提升.相比DANet、CFNet、DMNet、SANet、CCNet和ANNet, SPAFBA的mIoU值在PASCAL_VOC2012、PASCAL_Context数据集上至少提升1.1%~1.6%, 在ADE20k数据集上也取得微弱的性能优势.相比CDGCNet和GINet, SPAFBA的mIoU值在Pascal_VOC2012数据集上提升1.1%, 在PASCAL_Context数据集上提升0.6%.相比RecoNet, SPAFBA的mIoU值在PASCAL_VOC-2012数据集上略有下降, 但在PASCAL_Context数据集上提升0.7%.在ADE20K数据集上, SPAFBA的mIoU值略优于OCRNet、EfficientFCN, 但略差于RecoNet.从3个数据集的整体性能表现可分析出, SPAFBA在类别数适中的复杂任务中更能体现优势, 相比采用注意力机制或图卷积方式构建上下文依赖关系的方法, SPAFBA由于考虑背景区域对不同尺度前景特征的激励与约束, PFBA模块建立的前/背景依赖关系在复杂场景下依然能提供上下文区分关系, 增强前景特征的表示, 从而提升方法性能.
在本节实验中, SPAFBA的基线模型仅包括标准的ResNet101骨干网络, 并直接通过双线性插值恢复原图分辨率大小, 通过逐模块增加的方式进行消融实验, 评估不同模块对模型总体性能的影响.模型在train_aug数据集上进行训练, 在PASCAL_VOC2012验证集上进行评估.为了公平起见, 训练及测试设置均相同.
不同模块对SPAFBA的mIoU值对比如表2所示.
| 表2 不同模块对SPAFBA的mIoU值的影响 Table 2 Influence of different modules on mIoU of SPAFBA |
由表2可看出, 仅包括ResNet101骨干网络的基线模型的mIoU值为71.68%, 添加JSPU模块后, mIoU值提升7.66%, 表明相比基线模型, JSPU模块使用的双线性插值上采样具有明显优势.原因在于 JSPU模块使用高层特征的语义信息作为低层特征的语义指导, 同时考虑全局语义及局部语义, 更好地利用低层特征恢复分辨率.双线性插值仅考虑局部信息, 容易受局部错误像素干扰, 恢复分辨率能力较弱.仅在ResNet101中添加PFBA模块, mIoU值比基线模型提升4.95%, 相比仅加入JSPU模块降低2.71%.其主要原因在于ResNet101具有较低的输出步幅, 丢失过多的细节特征.PFBA难以捕获具有较好特征表示的前景特征及背景特征, 建立的前/背景依赖关系对前景特征的增强效果有限.在添加JSPU模块后继续加入PFBA模块, mIoU值提升至80.34%.上述性能提升表明建模前景与背景之间的依赖关系能增强特征的上下文表示, 从而提高模型性能.在添加JSPU模块与PFBA模块后, 根据文献[9], 进一步在骨干网络第四层添加辅助损失, SPAFBA的mIoU值又提升0.21%.这表明辅助损失确保中间层特征的语义表示能力, 加强模型的表征能力.进一步在测试过程中采用多尺度和翻转策略, 相比只添加辅助损失, mIoU值提升0.13%.最后, 使用原始PASCAL_VOC2012数据集的训练集微调模型, mIoU达到81.67%.上述实验表明, SPAFBA中的模块能显著提高网络性能.
下面进一步对比分析采用不同骨干网络时, JSPU模块对骨干网络的性能影响, 结果如表3所示, 表中Dilated_表示在相应骨干网络中增加空洞卷积操作, +JSPU表示在相应骨干网络中添加JSPU模块.
| 表3 采用不同骨干网络时JSPU模块在PASCAL_VOC2012验证集上的性能表现 Table 3 Performance of JSPU module with different backbone networks on PASCAL_VOC2012 val set |
由表3可看出, 添加JSPU模块后的效果明显优于添加空洞卷积操作.相比空洞卷积维持高分辨率的方法, JSPU模块能获得同样输出步幅的结果, 此外, JSPU模块内存占用更少, 在训练模型时也具有优势.
最后, 分析JSPU模块与不同的上下文信息提取方法及PFBA模块结合的性能表现, 进一步验证JSPU模块与PFBA模块的有效性.采用的上下文信息提取方法包括EncNet中的 Context Encoding Mo-dule方法(简记为Encoding), DeeplabV3中的ASPP, PSPNet中的PPM(Pyramid Pooling Module).
各方法在PASCAL_VOC2012验证集上的有效性结果如表4所示:Encoding、ASPP、PPM的上采样方法不做插值时, 表示原始论文的网络结构; ASPP、PPM的上采样方法为JSPU时, 表示加入JSPU模块进行上采样恢复分辨率; Encoding中上采样方法为双线性插值时, 表示首先从EncNet的骨干网络中移除空洞卷积, 输出步幅调整为32, 再使用双线性插值对输出特征图进行4倍上采样, 将输出步幅恢复到与原始模型一致, 并将特征图送入Context Encoding Module上下文提取模块.
| 表4 各方法的有效性实验结果 Table 4 Vadility of different methods in experiment |
由表4可见, Encoding中上采样方法从不采用插值改为双线性插值.mIoU值有所下降, 表明替换骨干网络中空洞卷积获得高分辨率的图像是困难的, 不恰当的上采样方法可能导致性能损失.但采用JSPU模块替换空洞卷积时, mIoU值有所提升, 优于不采用插值的方式, 进一步验证JSPU模块在上下文信息提取方面的优势.同时, 将JSPU模块应用到ASPP和PPM中, mIoU值也有所提升.JSPU模块与PFBA模块结合, mIoU值达到最优, 说明PFBA模块捕获的前/背景依赖能对前景特征提供背景区域上下文依赖, 实现对每个像素特征的激励与约束, 增强特征的语义表示能力.
ResNet101和SPAFBA在PASCAL_VOC2012验证集上的可视化结果如图4所示.
 | 图4 各方法在PASCAL_VOC2012 验证集上的可视结果展示Fig.4 Visual results of different methods on PASCAL_VOC2012 val set |
由图4可见, SPAFBA的分割质量明显优于ResNet101.在第1幅飞机图像中, ResNet101基本丢失飞机两翼及尾部形状, 而SPAFBA清晰捕获其形状.类似地, 对于第4幅和第5幅图像, SPAFBA都能较好地分割对象形状.在第2幅和第3幅这种多对象距离很近或重叠的场景中, ResNet101容易将对象边界错分或难以区分, SPAFBA则大幅改善边界划分效果, 边界信息和细节处理更精确.
SPAFBA在PASCAL_VOC2012测试集的可视化结果如图5所示.由图可见, 预测结果中每个像素的分类结果与原始图像基本一致, 在边缘及边界上效果较优, 说明SPAFBA具有较高的语义分割精度.
 | 图5 SPAFBA在PASCAL_VOC2012测试集上的可视化结果Fig.5 Visualization results of SPAFBA on PASCAL_VOC2012 test set |
本文提出基于语义传播与前/背景感知的图像语义分割网络(SPAFBA).SPAFBA中包含联合语义传播模块和金字塔前/背景感知模块.联合语义传播模块提取高级特征的语义信息, 增强低层特征的语义, 缓解两者之间的语义差距, 较好地利用低层特征进行融合, 恢复分辨率, 解决图像语义分割的分辨率重建问题.金字塔前/背景感知模块建立前景与背景之间的上下文依赖关系, 较好地增强特征的表示能力.两个公共数据集上的实验表明SPAFBA性能较优.今后将考虑如何改善边缘细节信息的处理, 以及如何构建一个更轻、更有效的模型.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|