



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于多任务对抗和抗噪对抗学习的人脸超分辨率算法
[陈泓佑1  , 陈帆
, 陈帆1 , 和红杰1 , 蒋桐雨1 ]
, 陈帆, 和红杰, 蒋桐雨]
|
|



作者简介: 
陈泓佑,博士,主要研究方向为机器学习、图像处理.E-mail:chy2019@foxmail.com. 
陈 帆,博士,副教授,主要研究方向为多媒体安全、计算机应用.E-mail:fchen@home.swjtu.edu.cn. 
蒋桐雨,硕士研究生,主要研究方向为人脸超分辨率.E-mail:jiangty971018@163.com.
高倍率单幅人脸图像超分辨率重建是一项具有实用价值但困难的任务.在人脸超分辨率任务中,端到端网络超分辨率图像较模糊,图像真实性和人眼视觉效果较差.针对上述问题,文中提出基于多任务对抗和抗噪对抗学习的人脸超分辨率算法.算法分为端到端网络学习阶段和网络参数微调阶段.为了提高端到端学习效果,设计深度多任务拉普拉斯金字塔网络,并结合多任务对抗学习.主任务为端到端学习,子任务为优化对抗学习惩罚项函数.为了改进通过对抗学习并微调主任务网络参数后的效果,在对抗学习的判别器优化过程中,融入抗噪对抗学习.实验表明,文中算法能使人脸超分辨率图像更具有图像真实性,更符合人眼视觉习惯.
About Author:
CHEN Hongyou, Ph.D. His research interests include machine learning and image processing.
CHEN Fan, Ph.D., associate professor. His research interests include multi-media security and computer applications.
JIANG Tongyu, master student. His research interests include face super-resolution.
The super-resolution(SR) of high magnification single face image is a hard but valuable task. In the face super-resolution(FSR) task, the end-to-end network SR image is fuzzy, and the photoreality and human visual effect are poor. Aiming at the problems, a FSR algorithm based on multi-task adversarial learning(MTAL) and antinoise adversarial learning(ANAL) is proposed. The algorithm is divided into end-to-end network learning and network parameters fine-tuning. To improve the end-to-end learning result, a deep multi-task Laplacian pyramid network(MTLapNet) is designed and integrated with MTAL. The main task is end-to-end learning, while the subtask is the optimization of adversarial learning penalty function. To improve the result of adversarial learning and parameters fine-tuning of the main task network, ANAL is integrated into the optimization process of discriminator of adversarial learning. The experiments show that the proposed algorithm can make the FSR image more photo-realistic and more consistent with human visual habits.
单幅图像超分辨率重建(Single Image Super-Resolution, SISR)是一个经典问题, 具有较大的应用价值.超分辨率算法可用于视频和照片的超分辨率任务, 也可拓展用于芯片图像中的芯片级特洛伊木马检测[1, 2].近年来, 基于深度学习的超分辨率技术发展迅速, 端到端学习模型是此领域的研究热点, 如SRCNN(Super-Resolution Convolutional Neural Net-works)[3]、VDSR(Super-Resolution Using Very Deep Convolutional Networks)[4]、LapSRN(Laplacian Pyra-mid Super-Resolution Networks)[5]、EDSR(Enhanced Deep Super-Resolution Networks)[6]、SRFBN(Image Super-Resolution Feedback Network)[7]、FC2N(Fully Channel-Concatenated Network)[8]、RFANet(Resi-dual Feature Aggregation Network)[9]、基于多残差网络的结构保持超分辨率模型[10]等.这些模型主要通过设计深度卷积神经网络和一些基本块(如残差块、通道连接块和注意力块等)以改进超分辨率图像的质量.也有一些模型利用非传统卷积神经网络和流体动力学原理设计超分辨率网络模型, 如SwinIR(Image Restoration Using Swin Transformer)[11]及文献[12]方法(Fluid Micelle Network for Image Super-Resolution Reconstruction).
由于生成式对抗网络(Generative Adversarial Network, GAN) 在图像生成上的成功应用, 其被迅速用于超分辨率任务中[13, 14].一般地, 在端到端模型融入对抗学习后, 能使超分辨率图像更具真实感.例如, SRGAN(Super-Resolution GAN)[15]、ESRGAN(Enhanced SRGAN)[16]、ESRGAN+(Further Impro-ving ESRGAN)[17]、DBPN(Deep Back-Projection Networks)[18]、PPON(Progressive Perception-Oriented Net- work)[19]等都能使超分辨率人眼视觉效果更优.
在人脸超分辨率任务中, 一些通用算法为其提供基础模型.目前的主流技术是端到端学习、基于GAN相关技术[20, 21].在一些端到端模型中, 先通过神经网络训练得到低分辨率(Low-Resolution, LR) 图像, 再将这些低分辨率图像用于端到端学习, 使人脸超分辨率网络更具泛化能力, 提高超分辨率图像质量[22, 23].在另一些模型中, 引入人脸图像的先验知识, 辅助网络训练, 提高超分辨率图像质量.例如:Chen等[24]提出FSRNet(Face Super-Resolution Net-work), 融合人脸关键点热图(Facial Landmark Heat-maps)和解析图(Parsing Maps).Ma等[25]提出DIC(Deep Face Super-Resolution with Iterative Collabora-tion), 利用人脸关键点循环训练策略(Facial Land-marks Cycle Training).Zhang等[26]提出MSFSR(Multi-stage Face Super-Resolution), 利用人脸边界线(Facial Boundaries)进行由粗到精的人脸超分辨率重建.蒋桐雨等[27]提出非对称U型金字塔重建人脸超分辨率网络(Asymmetric U-Pyramid Face Super-Resolution Network, AUP-FSRNet), 在构建非对称U型编解码网络的同时, 引入人脸关键点热图损失, 约束人脸结构重塑.
一般地, 基于GAN的人脸超分辨率模型能使超分辨率图像更真实、更符合人眼视觉习惯, 提高超分辨率图像的感知图像质量.FSRNet、DIC和AUP-FSRNet引入对抗学习后构成FSRGAN[24]、DIC-GAN[25]和AUP-FSRGAN[27], 这些模型能重建更清晰的纹理细节和面部轮廓信息.此外, Kim等[28]提出PFSR(Progressive Face SR Network), 融合面部注意力信息(Facial Attention Information)和对抗学习技术.Bulat等[29]提出Super-FAN, 融合人脸关键点距离(Facial Landmark Distance)和GAN.付利华等[30]提出融合参考图像的人脸超分辨率重构方法, 利用特征提取网络获得参考图像的多尺度特征, 再结合对抗学习, 利用逐级超分主网络对低分辨率人脸图像特征进行逐次填充.Dou等[31]提出PCA-SRGAN, 先通过主成分分析(Principal Component Analysis, PCA)投影矩阵, 将人脸超分辨率图像投影到特征空间中, 再将这些投影特征输入判别器中, 使超分辨率图像更规整, 减少畸变情况.Chen等[32]提出SPARNet(Spatial Attention Residual Network), 引入空间注意力到生成器(这个生成器是端到端网络), 改进超分辨率图像的视觉质量.
端到端学习的人脸超分辨率模型通常能更好地保持图像信息, 具有更高的结构相似指标数据, 但人脸图像细节信息(如头发纹理、牙齿边缘和瞳孔反光点等)相对较差[24, 25], 导致端到端学习的人脸超分辨率图像的真实感较差.基于GAN的人脸超分辨率模型常直接引入判别器进行对抗学习, 并未过多针对人脸超分辨率任务进行进一步优化.由于对抗学习生成图像的随机性, 超分辨率图像在诸如头发和面部轮廓等信息上容易扭曲变形[24, 28].
考虑到上述问题, 本文提出基于多任务对抗和抗噪对抗学习的人脸超分辨率算法(Face Super-Resolution Algorithm Based on Multi-task Adversarial and Antinoise Adversarial Learning, MTA-ANALFSR).整个算法分为端到端学习和端到端网络参数微调两个阶段.在端到端学习阶段中, 设计多任务拉普拉斯金字塔网络(Multi-task Laplacian Pyramid Network, MTLapNet), 完成多任务对抗学习.在端到端网络参数微调阶段, 利用预训练的二分类器, 完成端到端网络参数微调中判别器的优化函数抗噪学习.利用抗噪对抗学习提高对抗学习的稳定性, 改进最终的对抗学习参数微调效果.实验表明本文算法生成的人脸超分辨率图像具有更好的图像真实性, 更符合人眼视觉习惯.值得注意的是, 在整个网络训练过程中, 并未使用额外的诸如人脸特征点热图、解析图、人脸特征点距离和面部注意力信息等类似的图像特征信息.
1.1.1 多任务端到端学习网络
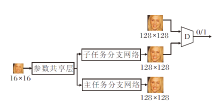
本文提出多任务对抗学习(Multi-task Adversa-rial Learning, MTAL)的端到端学习网络, 结构如图1所示.
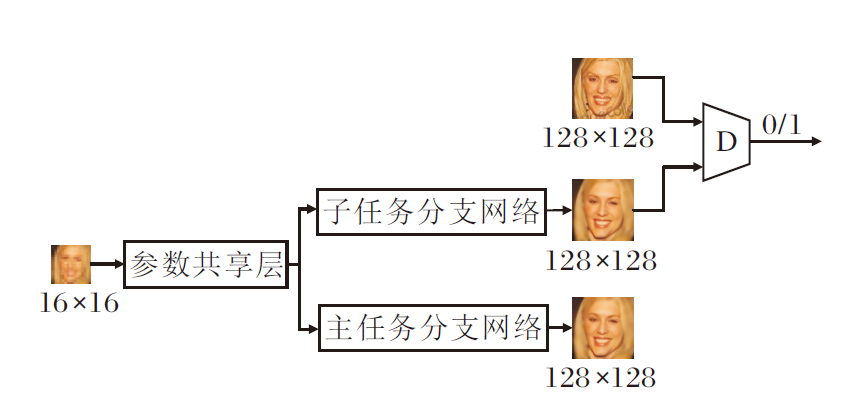 | 图1 多任务对抗学习的端到端学习网络结构图Fig.1 Structure of end-to-end network based on multi-task adversarial learning |
为了利用多任务对抗学习完成端到端网络学习, 将一般的端到端网络设计成多任务网络.主任务网络(参数共享层+主任务分支网络)进行端到端的人脸超分辨率学习, 子任务网络(参数共享层+子任务分支网络)进行含惩罚式对抗学习的人脸超分辨率学习.主任务网络和子任务网络之间采用部分参数共享的硬参数共享方式[33].
多任务对抗学习中的判别器使用一个VGG128网络[34].主任务网络利用L1优化函数, 完成从16× 16低分辨率图像到128× 128超分辨率图像的学习.子任务网络利用L1和对抗学习优化函数, 完成从16× 16低分辨率图像到128× 128超分辨率图像的学习.
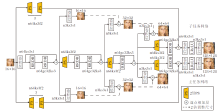
端到端学习对应的多任务拉普拉斯金字塔网络(MTLapNet)结构如图2所示.
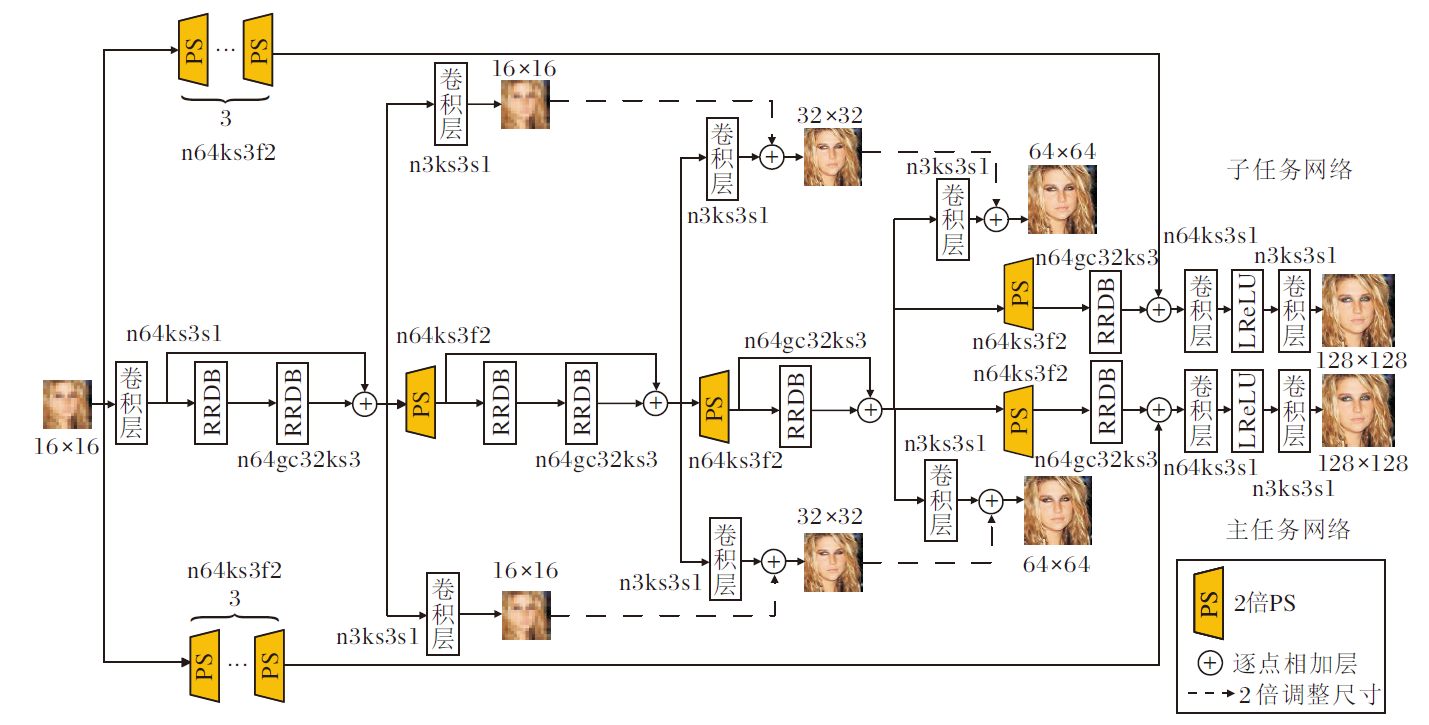 | 图2 多任务拉普拉斯金字塔网络结构Fig.2 Structure of multi-task Laplacian pyramid network |
在整个金字塔网络的搭建中, 应用残差密集连接网络块(Residual in Residual Dense Block, RRDB)[16, 17]作为基本块.RRDB参考残差网络(Re-sidual Network, ResNet)[35]和密集连接网络(Den-sely Connected Convolutional Networks, DenseNet)[36], 能有效预防神经网络梯度消失, 有效复用神经网络的浅层特征.
在图2中, RRDB由3组残差密集块(Residual Dense Block, RDB), 共15个卷积层组成.在参数共享层中, 为每两组串联或一组单独使用的RRDB块进行残差连接.如图2所示:卷积层中, “ n64ks3s1” 表示特征通道数为64、卷积核尺寸为3、卷积步长为1, 其它依次类推; 在RRDB块中, gc是指RRDB块内部中密集连接块(Dense Block) 的块内部卷积通道数; 亚像素卷积(Pixel Shuffle, PS)中, n64ks3f2表示亚像素卷积的特征通道数为64、卷积核尺寸为3、放大倍数为2; 2倍调整尺寸表示立方线性插值, 放大为原来的2倍.
在主任务网络中, 网络输出32× 32超分辨率图像过程如下:对应的主任务网络输出的16× 16图像立方线性插值放大2倍后, 与输出的32× 32图像按像素元素相加.相加后的32× 32图像再与32× 32高分辨率(High-Resolution, HR) 图像(128× 128高分辨率图像立方线性插值缩小4倍)进行L1优化函数学习.主任务网络输出的64× 64超分辨率图像过程与之类似.需要注意的是, 生成128× 128超分辨率图像的过程没有64× 64超分辨率图像直接参与, 是直接通过RRDB块和主任务网络末端卷积层等输出的.子任务网络与主任务网络对称, 32× 32图像、64× 64图像、128× 128超分辨率图像的输出与主任务网络一致, 但在训练过程中增加对抗学习优化函数.
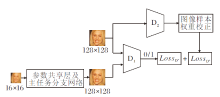
1.1.2 主任务网络参数微调
抗噪对抗学习网络(Antinoise Adversarial Lear-ning, ANAL)参数微调过程如图3所示.当图2中的MTLapNet完成学习后, 对其进行网络剪枝, 仅保留主任务网络(参数共享层+主任务分支网络).主任务网络与一个VGG128二分类网络D1构成对抗学习双方.抗噪对抗学习通过一个已完成预训练的VGG128二分类网络D2, 对D1网络的正样本优化函数Los
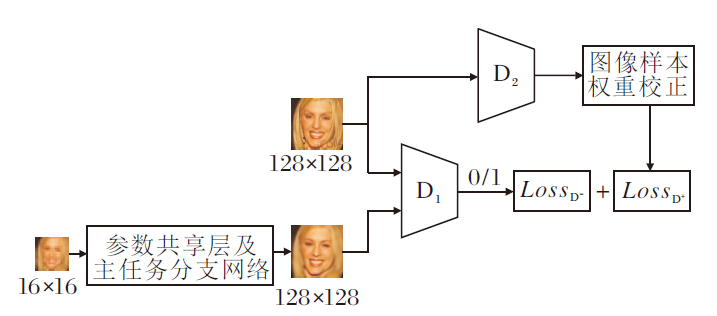 | 图3 抗噪对抗学习网络的参数微调过程Fig.3 Fine-tuning network parameters based on antinoise adversarial learning |
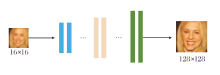
8倍率端到端学习的人脸超分辨率网络结构如图4所示, 图中不同色柱表示不同上采样结构块, 可以是卷积层堆叠, 也可以是类似于RRDB之类的结构.上采样结构块主要任务是完成小图像向更大尺寸图像(也可以是多幅更大尺寸的特征图)的采样.在8倍率端到端学习人脸超分辨率网络中, 16× 16低分辨率图像直接输入一个上采样深度神经网络, 然后输出128× 128超分辨率图像.
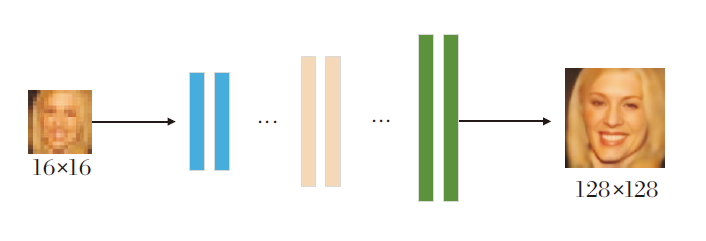 | 图4 端到端学习的人脸超分辨率网络结构图Fig.4 Network structure of end-to-end learning face super-resolution |
直接进行端到端学习得到的人脸超分辨率图像通常较模糊, 难以重建头发、瞳孔和牙齿边缘等细节[24, 25], 这是由于L1和L2型解码优化函数本身的限制所导致的, 它们更倾向于寻求批量图像平均一致.提高端到端学习阶段的视觉质量, 可在基于GAN进行端到端网络参数微调时, 设定更好的网络参数初始值.
在基于样本特征解码约束GAN中, 为了提高对抗学习生成图像质量, 引入样本特征解码约束条件[37].其核心思想是:在随机噪声通过生成器映射到随机图像的对抗学习任务中, 增加训练样本特征通过解码器映射到训练样本图像的解码约束条件.解码器和生成器结构相同, 网络参数共享, 样本特征与随机噪声维度相同.这种GAN能使生成器同时兼顾对抗学习和样本特征解码任务[37].类似地, 在端到端学习阶段设计兼顾低分辨率图像到高分辨率图像的解码任务, 以及低分辨率图像到高分辨率图像的对抗学习任务, 可提高人脸超分辨率图像质量.
多任务学习通常适合两个及两个以上的学习任务, 相比单任务学习, 通常具有性能上的优势, 便于提高主任务的学习效果[33].通常多任务学习包含硬参数共享和软参数共享两种方式[33].十字绣网络(Cross-Stitch Networks)是一种软参数共享方式多任务网络, 应用十字绣单元, 自动决定最佳共享层, 但带来诸如参数初始化、学习率设置等方面的问题[38].多任务学习中需要关注如何对各子任务的优化函数进行加权以取得较优的训练效果[39].在GAN中, 多任务学习依然有效, 利用多任务生成器配合多任务判别器, 优化多种散度的加权组合, 可改进对抗学习稳定性, 进而改进生成图像质量[40].
在端到端学习中, 由于需要完成低分辨率图像到超分辨率图像端到端学习(解码任务)和对抗学习两个任务, 故设计硬参数共享的多任务拉普拉斯金字塔网络(见图2).网络的主任务是完成低分辨率图像映射到高分辨率图像任务, 子任务是结合一个VGG128判别器完成对抗学习任务.在基于样本特征解码约束生成式对抗网络中, 优化JS(Jensen-Shannon)散度时融入训练图像样本特征解码约束, 提高生成图像质量[37].需要注意的是, 解码约束起辅助作用.在本文多任务对抗学习中, 低分辨率图像通过解码尽量拟合高分辨率图像是主任务, 对抗学习起辅助作用, 故对抗学习优化函数选用JS散度.在低分辨率图像的解码优化函数类型选择上, 参考ESRGAN和ESRGAN+[16, 17], 选用L1型.如图2所示, 拉普拉斯金子塔图像是网络输出的32× 32图像和64× 64图像(包括主任务网络和子任务网络), 优化方式和单任务端到端LapSRN[5]相近.结合图1和图2, 给出多任务对抗学习优化函数, 如下所示:
分类器优化函数
$\operatorname{loss}_{\mathrm{D}}=\frac{1}{m} \sum_{i=1}^{m}\left[\ln D\left(x_{i}^{\mathrm{HR}}\right)+\ln \left(1-D\left(x_{i}^{\mathrm{sub} S \mathrm{SR}}\right)\right)\right] ; $ (1)
生成器(子任务网络)优化函数
$\operatorname{loss}_{\mathrm{G}}=\lambda_{1} \frac{1}{m} \sum_{i=1}^{m} \ln \left(1-D\left(x_{i}^{\text {sub_SR }}\right)\right) \text {; }$(2)
子任务网络低分辨率图像解码优化函数
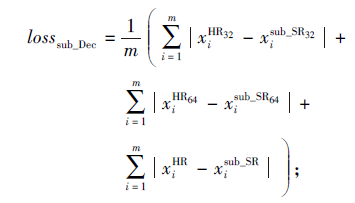 |
子任务网络最终含对抗学习的优化函数
losssub_SR=losssub_Dec+lossG; (4)
主任务网络低分辨率图像的解码优化函数
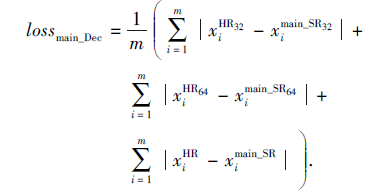 |
其中:
通过多任务对抗学习, 完成多任务拉普拉斯金字塔网络训练后, 进行网络参数剪枝, 仅保留图2中的主任务网络, 再通过对抗学习网络进行参数微调.当对抗学习进行网络参数微调时, 由于生成器(主任务网络)的梯度反传是通过判别器进行, 故判别器能直接影响生成器的人脸超分辨率图像效果.
在数据分类模型中, 训练样本需要与之对应的标签配对, 当前深度神经网络中的研究主要集中于噪声标签对分类效果产生的影响[41].噪声标签是一种难以避免的类型数据[41], 通常可使分类模型的判别值偏向随机值, 预测能力降低甚至产生错误.在深度神经网络中, 抗噪优化函数的设计是一种有效的标签噪声抗噪方法[42].例如:通过分析优化函数的数学性质, 设计风险最小化的抗标签噪声优化函数[42]; 通过公式化噪声察觉模型完成噪声标签的感知任务, 构建优化函数校正模型[43].在对抗学习中, 由于分类器正负样本的标签是设定值(0或1), 故在对抗学习中, 分类器的抗噪优化函数可针对训练样本.在抗噪学习和联盟博弈的GAN中, 分类器的抗噪学习能提升对抗学习的稳定性和生成图像质量[44].可利用生成图像和训练图像, 训练一个二分类卷积神经网络(依据输出的置信度进行噪声感知), 再将训练图像输入二分类网络, 得到分类置信度, 以此置信度校正对抗学习中判别器正样本优化函数样本权重[44].
如图3所示, 在抗噪对抗学习进行主任务网络参数微调中, D2为一个已完成预训练的VGG128二分类网络, 正负样本分别为训练集高分辨率图像和主任务网络输出的超分辨率图像.D1为另一个与D2完全相同的VGG128二分类网络.主任务网络和D1网络构成抗噪对抗学习的组件, 预训练网络D2对D1的正样本优化函数进行样本权重归一化校正.结合图3, 抗噪对抗学习的主任务网络优化函数如下所示.
分类器的正样本优化函数为:
los
$w_{i}=\frac{D_{2}\left(x_{i}^{\mathrm{HR}}\right)}{\sum_{j=1}^{m} D_{2}\left(x_{j}^{\mathrm{HR}}\right)} .$ (7)
分类器的负样本优化函数为:
$\operatorname{loss}_{\mathrm{D}_{1}^{-}}=\frac{1}{m} \sum_{i=1}^{m} \ln \left(1-D_{1}\left(x_{i}^{\text {main_SR }}\right)\right) \text {. }$(8)
生成器(主任务网络)优化函数为:
$\operatorname{loss}_{\mathrm{G}}=\lambda_{2} \frac{1}{m} \sum_{i=1}^{m} \ln \left(1-D_{1}\left(x_{i}^{\text {main_SR }}\right)\right) .$(9)
主任务网络低分辨率图像的解码优化函数为:
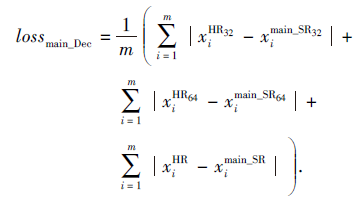 |
主任务网络最终含抗噪对抗学习的优化函数为:
lossmain_SR=lossmain_Dec+lossG.(11)
其中:
由1.1节~1.3节可知, 本文的人脸超分辨率算法(MTA-ANALFSR)分为多任务对抗学习端到端主任务网络和抗噪对抗学习主任务网络参数微调, 具体步骤如下, 优化器选用Adam(Adaptive Mo-ment Estimation).
算法1 多任务对抗学习主任务网络训练方法(主任务网络预训练)
输入 训练数据集X及对应的16× 16的LR图像,
学习率η , 优化器动量因子β ,
批尺寸大小m, 对抗学习权重参数λ 1
输出 多任务拉普拉斯金字塔网络
1.while 主任务网络未收敛 do
2. 采样一批128× 128的HR图像样本
3. 由式(1)更新D网络参数, Adam.
4. 由式(4)更新子任务网络参数, Adam.
5. 由式(5)更新主任务网络参数, Adam.
6.end while
在算法1中, step 3~step 4完成含对抗学习的子任务网络人脸超分辨率任务.step 5完成主任务网络(端到端学习)的人脸超分辨率任务.
算法2 抗噪对抗学习主任务网络参数微调训练方法
输入 训练数据集X及它的16× 16的LR图像,
学习率η , 优化器动量因子β ,
批尺寸大小m, 对抗学习权重参数λ 2,
已完成预训练的VGG128网络D2
输出 主任务拉普拉斯金字塔网络
1.while 主任务网络参数微调未结束 do
2. 采样一批128× 128的HR图像样本
3. 由式(7)计算128× 128的HR图像样本权重.
4. 由式(6)和式(8)更新D1网络参数, Adam.
5. 由式(11)更新主任务网络参数, Adam.
6.end while
在算法2中, step 3和step 4完成抗噪对抗学习的D1网络参数更新.step 5完成基于抗噪对抗学习的主任务网络参数微调.
本文实验中主要的软硬件环境为TensorFlow 1.13.1 GPU版本、CUDA SDK 10.0、cuDNN 7.6、OpenCV 3.4和Matlab 2016b.GPU包括NVIDIA GTX 1080和GTX 1080Ti.
实验选取训练数据集为HELEN、CELEBA数据集.HELEN数据集包含2 330幅人脸图像, 将其中心裁剪成128× 128大小, 其中2 005幅图像构成训练数据集, 50幅图像构成验证数据集, 测试数据集与验证数据集相同.CELEBA数据集包含202 599幅人物上半身图像, 将其中心裁剪成128× 128大小.经过筛选后选择其中168 854幅图像构成训练数据集, 100幅图像构成验证数据集, 1 000幅图像构成测试数据集[25].HELEN数据集由于样本量较少, 主要用于测试模型参数和验证模型有效性等.CELEBA数据集由于数据量较大, 可用于与其它人脸超分辨率算法的对比实验.利用MATLAB软件对高分辨率图像进行立方插值后制成16× 16的低分辨率图像.
为了对比分析人脸超分辨率图像质量, 选择如下评价指标:峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)[25], 平均结构相似度(Mean Struc-tural Similarity, MSSIM)[45], LPIPS(Learned Percep-tual Image Patch Similarity)[23], 人脸关键点的NRMSE(Normalized Root Mean Square Error)[25], FID(Fré -chet Inception Distance)[46].PSNR表征人脸超分辨率图像与高分辨率图像之间的信息损失.MSSIM计算超分辨率图像与高分辨率图像之间的结构信息相似程度.这两个指标值越高, 算法性能越优.LPIPS表征超分辨率图像与高分辨率图像之间的感知信息相似程度, NRMSE表征超分辨率图像与高分辨率图像人脸关键点的差异程度, FID计算超分辨率图像与高分辨率图像数据分布之间的差异程度.这3个指标值越低, 算法性能越优.
2.2.1 权重参数选取
为了测试式(2)中λ 1相对适合的参数值, 选取λ 1=1.0e-3, 5.0e-3, 1.0e-2, 分别进行测试.实验基本设定为Adam, 初始学习率η =0.000 1, 动量因子β =0.9, 批量样本数量m=16.最大迭代周期数为100, 每30个迭代周期学习率减半, 最小减到初始学习率的1/4.
λ 1不同时, 多任务对抗学习算法在HELEN数据集上的指标值对比如表1所示.由表可知, λ 1=5.0e-3时取得最高PSNR值和MSSIM值, 使超分辨率图像与高分辨率图像之间的信息损失和结构信息尽量最优.λ 1=5.0e-3, 1.0e-2时LPIPS相近, 但差于λ 1=1.0e-3时, 这表明λ 1=5.0e-3时能使感知图像块的相似度居中.λ 1=5.0e-3时对应的FID值也居中, 这表明在超分辨率图像与高分辨率图像的分布差异程度上居中.λ 1=5.0e-3时能取得低NR-MSE值, 表明能使超分辨率图像重建与高分辨率图像最相近人脸关键点.由于对抗学习具有稳定性较差的特点[40, 44], 所以训练效果对权重λ 1较敏感.
| 表1 λ 1不同时算法在HELEN数据集上的指标值对比 Table 1 Index value comparison of algorithms with different λ 1 on HELEN dataset |
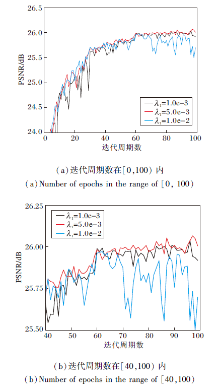
λ 1不同时, PSNR随迭代周期数的收敛曲线如图5所示.
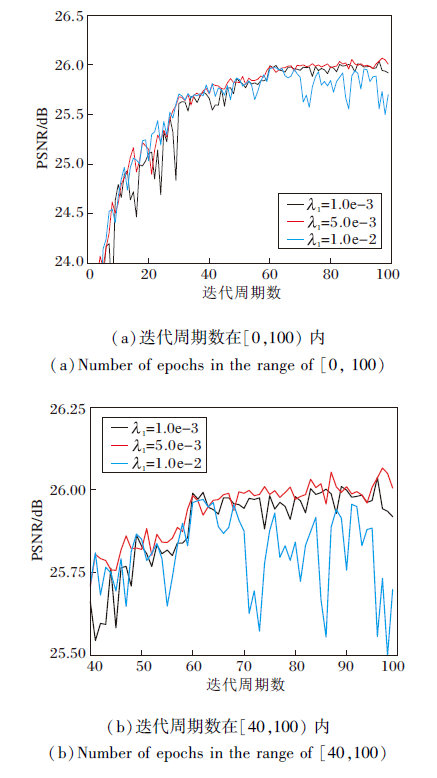 | 图5 λ 1不同时PSNR随迭代周期数变化的收敛曲线Fig.5 PSNR convergence curves with different numbers of epochs and different λ 1 |
由图5可知, λ 1=1.0e-3时, 前期PSNR曲线波动较大.λ 1=1.0e-2时, 后期PSNR曲线波动较大.λ 1=5.0e-3时, 有最好全局和局部的收敛效果.通过上述分析发现, 综合考虑评价指标和PSNR曲线收敛过程, 当选择λ 1=5.0e-3作为权重参数时, 惩罚式多任务对抗学习能使主任务跳出局部最优解[33, 40], 得到相对更好的局部最优解.
下面测试直接在主任务网络上添加VGG128二分类网络后(主任务网络未进行任何预训练), 执行对抗学习超分辨率任务的λ 2参数.相当于将对抗学习直接融入端到端网络, 执行人脸超分辨率任务, 无需再进行后继的主任务网络参数微调.
此时, 网络结构为图3中直接去掉D2参与的抗噪学习对应的网络结构.主任务网络优化函数为式(9)~式(11), D1网络的分类优化函数为标准的交叉熵优化函数, 与原始对抗学习相同[13].
为了测试相对合理的λ 2参数, 选择λ 2=1.0e-4, 1.5e-4, 2.0e-4, 分别进行测试.
实验基本设定为Adam, 初始学习率η =0.000 1, 动量因子β =0.9, 批量样本数量m=16.迭代周期数为100, 每30个迭代周期学习率减半, 最小减到初始学习率的1/4.
λ 2不同时, 直接对抗学习算法在HELEN数据集上的指标值对比如表2所示.
| 表2 λ 2不同时算法在HELEN数据集上的指标值对比 Table 2 Index value comparison of algorithms with different λ 2 on HELEN dataset |
由表2可知, 当λ 2=1.5e-4时, PSNR值和MSSIM值最高, 这表明它能使超分辨率图像与高分辨率图像丢失更小的信息损失和图像结构信息.λ 2=1.5e-4时LPIPS值最差, 但有最低FID值和NRMSE值.这表明虽然λ 2=1.5e-4时使超分辨率图像有较差的感知图像块的相似度, 但有最佳分布相似程度和人脸特征点重建效果.
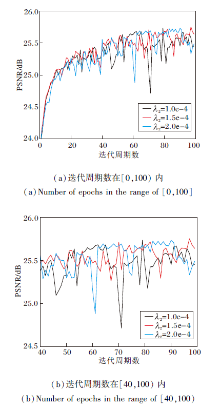
λ 2不同时PSNR随迭代次数变化的收敛曲线如图6所示.由图可知, λ 2=1.0e-4时, PSNR曲线波动情况最严重, λ 2=1.5e-4和2.0e-4时, PSNR曲线波动情况相近.通过上述分析, 综合考虑评价指标和收敛过程, 选择λ 2=1.5e-4.对抗学习稳定性较差, 导致训练效果对权重λ 2敏感.
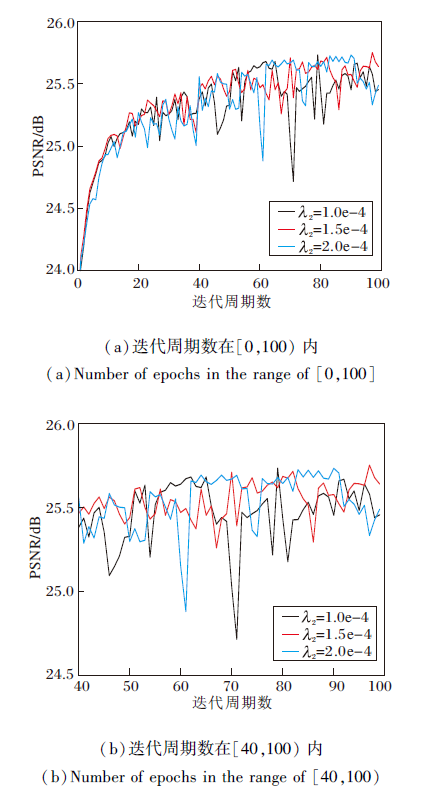 | 图6 λ 2不同时PSNR随迭代周期数变化的收敛曲线Fig.6 PSNR convergence curves with different numbers of epochs and different λ 2 |
2.2.2 对抗学习效果对比
本节测试直接利用主任务网络进行端到端学习, 由此产生的直接对抗学习效果(后继将不进行网络参数微调, 表2中后一组实验, 选最优效果对比)和含惩罚性质的多任务对抗学习的人脸超分辨率效果(后继还进行网络参数微调, 表1中选取最优效果对比).实验基本设定为Adam, 初始学习率η =0.000 1, 动量因子β =0.9, 批量样本数量m=16.迭代周期数为100, 每30个迭代周期学习率减半, 最小减到初始学习率的1/4.
不同人脸超分辨率算法在HELEN数据集上的指标值对比如表3所示.由表可见, 对比端到端学习和多任务对抗学习可知, 通过多任务对抗学习后, 主任务网络端到端学习能提升所有对比指标, 这表明多任务对抗学习的超分辨率图像质量得到全面提升, 减小高分辨率图像信息, 结构失真的条件下也能在一定程度上提升人眼视觉效果.对比端到端学习和直接对抗学习可知, 主任务网络直接进行对抗学习的PSNR值和MSSIM值有所下降, 信息损失和结构差异有所增加, 但LPIPS、FID、NRMSE这3个感知指标有所提升, 超分辨率图像更符合人眼视觉习惯.对比直接对抗学习和多任务对抗学习可知, 多任务对抗的PSNR值和MSSIM值有所提高, 超分辨率图像和高分辨率图像之间的信息损失和结构差异较少.在LIPIS、FID、NRMSE指标中仅FID指标更优, 其余两个指标较差.这表明相比直接对抗学习, 多任务对抗学习有利于超分辨率图像模拟高分辨率图像分布, 但特征感知相似度和人脸关键点重建效果较差, 需要下一阶段的主任务网络参数微调完成.
| 表3 不同人脸超分辨率方法在HELEN数据集上的指标值对比 Table 3 Index value comparison of different FSR methods on HELEN dataset |
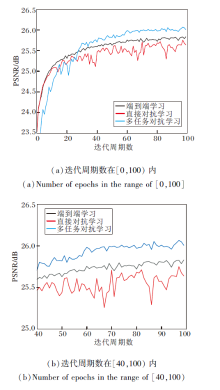
不同人脸超分辨率方法的PSNR收敛曲线如图7所示.由图可知, 端到端学习收敛曲线最稳定.多任务学习次之, 并且PSNR值在30个迭代周期后超过端到端学习.直接对抗学习PSNR值收敛稳定性和收敛效果最差.
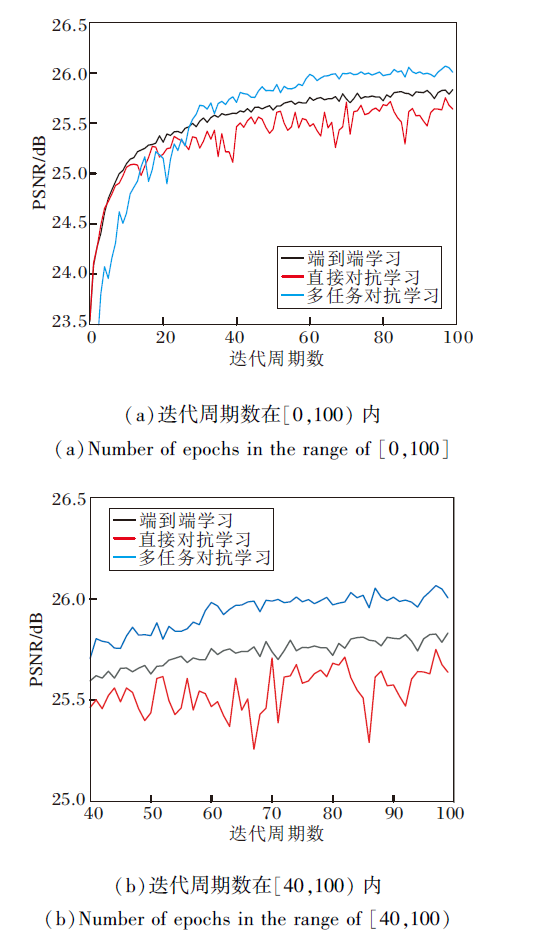 | 图7 不同人脸超分辨率方法的PSNR收敛曲线Fig.7 PSNR convergence curves of different FSR methods |
由于对抗学习中生成图像的随机性, 所以直接应用对抗学习进行超分辨率学习对收敛过程的稳定性影响较大, PSNR值和MSSIM值有所下降, 其余的感知指标性能有所提升.由于多任务学习对单任务学习具有性能优势, 故多任务对抗学习能提升训练效果.需要注意的是, 在多任务学习中, 由于子任务网络与主任务网络部分参数共享, 所以对抗学习带来的不稳定影响小于直接对抗学习.
上述数据分析表明, 综合考虑PSNR收敛稳定性和各指标数据效果, 在端到端学习阶段, 应用多任务对抗学习可提升主任务网络端到端学习效果.
几种不同超分辨率方法得到的超分辨率图像样本如图8所示.由图可看出, 在人脸纹理细节和轮廓重建上, 直接端到端学习所得的超分辨率图像均差于直接对抗学习和多任务对抗学习.直接对抗学习所得的超分辨率图像更符合人眼视觉习惯, 具有更清晰的面部特征信息, 但是图像扭曲相对严重, 这主要是由于对抗学习对填充图像内容具有随机性.多任务对抗学习人眼视觉效果在端到端学习和直接对抗学习之间, 需要注意的是, 通过抗噪对抗学习最终结果具有最好的视觉效果.
 | 图8 不同方法获得的人脸超分辨率图像Fig.8 Face super-resolution images obtained by different learning methods |
2.2.3 抗噪对抗学习效果
为了对比在主任务网络参数微调中, 抗噪对抗学习和非抗噪对抗学习的效果差异, 进行如下实验.在主任务网络参数微调阶段, 选用2.2.2节中通过多任务对抗学习完成训练的多任务拉普拉斯金字塔网络, 经过网络参数裁剪, 仅保留主任务网络作为网络参数微调的起始网络.实验基本设定为Adam, 初始学习率η =2.0e-5, 动量因子β =0.9, 批量样本数量m=16, 迭代周期数为40.结合生成式对抗网络对抗学习的超分辨率任务参数设置经验, 在大样本量数据集CELEBA上, λ 2通常控制在1.0e-3量级[16, 17, 24, 25, 28].在小样本量数据集HELEN上, 结合表2中直接对抗学习的对抗学习权重测试效果, 对抗学习权重λ 2=1.5e-4.
抗噪对抗学习和非抗噪对抗学习在HELEN数据集上的指标值对比如表4所示.
| 表4 抗噪对抗学习和非抗噪对抗学习在HELEN数据集上的指标值对比 Table 4 Index value comparison of antinoise adversarial learning and nonantinoise adversarial learning on HELEN dataset |
由表4可知, 2种方法的主任务网络参数微调都影响人脸超分辨率图像的PSNR值和MSSIM值, 这主要是由于对抗学习填充图像细节信息的随机性所致.但融入对抗学习的网络参数微调超分辨率图像的LPIPS、FID、NRMSE值均有所提升, 这表明主任务网络经过对抗学习参数微调后, 人脸超分辨率图像更符合人眼视觉习惯.对比抗噪对抗学习和非抗噪对抗学习可看出, 抗噪对抗学习效果在PSNR和MSSIM指标上稍弱, 但在LPIPS、FID和NRMSE感知指标上均有所提升, 即在人眼视觉习惯上优于非抗噪对抗学习效果.
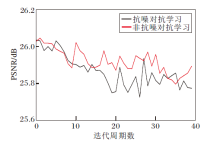
抗噪对抗学习和非抗噪对抗学习的PSNR收敛曲线对比如图9所示.由图可看出, 抗噪对抗学习在前20个迭代周期中, PSNR曲线比非抗噪对抗学习更光滑, 但在后20个迭代周期并不明显.这主要由于在主任务网络参数微调中, 对抗学习权重λ 2很小, 所以抗噪对抗学习的影响难以明显体现.由此可知, 抗噪对抗学习可在一定程度上改进收敛过程的稳定性, 得到更好的局部最优解, 超分辨率图像视觉效果更优.
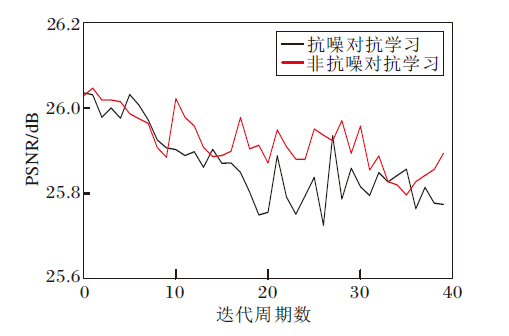 | 图9 抗噪对抗学习和非抗噪对抗学习的PSNR收敛曲线Fig.9 PSNR convergence curves of antinoise and nonantinoise adversarial learning |
2.2.4 最终的人脸超分辨率效果对比
由表3和表4可知, 相比端到端学习, 多任务对抗学习的所有指标都有一定程度的提升, 这表明在主任务网络参数训练阶段, 多任务对抗学习方式不仅能改进人脸超分辨率图像与高分辨率图像之间的图像信息损失和结构信息失真, 也能使超分辨率图像更符合人眼视觉习惯.在抗噪对抗学习网络参数微调阶段, 抗噪对抗学习能损失部分PSNR值和MSSIM值, 进一步提升LPIPS、FID和NRMSE感知指标值, 改进人眼视觉质量.对比图8可知, 端到端学习效果较模糊, 眼睛瞳孔和五官轮廓线条等面部信息丢失严重.多任务对抗学习超分辨率图像中的面部信息较丰富, 抗噪对抗学习进一步提升更细节的面部信息.
在CELEBA数据集上, 实验基本设定为Adam, 初始学习率η =0.000 1, 动量因子β =0.9, 批量样本数量m=16.在多任务对抗学习中, 迭代周期数为90, 每30个迭代周期学习率减半, 最小减到初始学习率的1/4.在抗噪对抗学习阶段, 迭代周期数为20, 学习率不变.
各方法在CELEBA数据集上的指标值对比如表5所示.由表可知, 相比端到端学习, 多任务对抗学习在PSNR、MSSIM、LPIPS、NRMSE指标上有一定提升, 在FID指标上少许下降.这表明多任务对抗学习对人脸超分辨率图像在图像信息损失、结构相似程度、特征感知相似程度及人脸关键点重建上均有改进, 但是对超分辨率图像模拟高分辨率图像分布的影响较小.多任务对抗学习整体上提高端到端学习的人眼视觉效果.抗噪对抗学习数据表明, 经过主任务网络参数微调后, 由于对抗学习填充图像内容的随机性, 在损失一定的PSNR值和MSSIM值的条件下, 可改进LPIPS、FID和NRMSE等指标, 进一步改进人眼视觉质量.
| 表5 不同方法在CELEBA数据集上的指标值对比 Table 5 Index value comparison of different methods on CELEBA dataset |
各方法在CELEBA数据集上的人脸超分辨率图像如图10所示.
 | 图10 不同方法在CELEBA数据集上的人脸超分辨率图像Fig.10 Face super-resolution image results obtained by different methods on dataset CELEBA |
由图10可知, 对比端到端学习和多任务对抗学习, 除了第3幅图像以外, 多任务对抗学习能填充更多的细节信息, 如牙齿轮廓线更清晰.对比多任务对抗学习和抗噪对抗学习, 抗噪对抗学习对主任务网络参数微调后, 具有更丰富的图像特征, 如更清晰的牙齿轮廓线、头发纹理和瞳孔反光点.最终人脸超分辨率图像人眼视觉质量更符合人眼视觉习惯.
实验中选取如下对比算法:FSRNet[24]、FSR-GAN[24]、PFSR[28]、DIC[25]、DICGAN[25]、AUP-FSRNet[27]、AUP-FSRGAN[27]、SPARNet[32].各对比算法的网络参数由原文献提供.只需将CELEBA数据集上的低分辨率图像输入对应网络后, 就能得到对应的人脸超分辨率图像.其中, FSRGAN、DICGAN、AUPFSR-GAN、PFSR、SPARNet均是融入对抗学习的人脸超分辨率算法.
各算法在CELEBA数据集上的指标值对比如表6所示, 在表中, MTAL表示本文多任务对抗学习的端到端学习后, 主任务网络的人脸超分辨率图像效果.MTAL-ANALFSR表示主任务网络参数微调后的结果, 黑体数字表示最优值.
| 表6 各算法在CELEBA数据集上的指标值对比 Table 6 Index value comparison of different methods on CELEBA dataset |
由表6可知, 对比FSRNet、DIC、AUP-FSRNet、MTAL这4个端到端学习算法, MTAL在PSNR、MSSIM、LPIPS和NRMSE指标上超过其它算法.这表明本文多任务对抗学习的端到端学习在图像信息损失、结构信息丢失、特征感知相似度和人脸特征点重建上具有更优性能.MTAL的FID值达到75.253, 差于DIC的70.289, 优于FSRNet和AUP-FSRNet.这表明MTAL模拟高分辨率图像分布效果居中, 但效果相近.对比Bicubic可知, 通过深度学习模型能使所有指标均有所提升.
对比FSRNet和FSRGAN、DIC和DICGAN、AUP-FSRNet和AUP-FSRGAN、MTAL和MTAL-ANA-LFSR这4组实验数据, 在端到端网络学习完成, 并通过对抗学习完成网络参数微调后, PSNR和MSSIM指标均有所变差, LPIPS和FID感知指标有所改进.FSRGAN和AUP-FSRGAN的NRMSE指标有所变差, DICGAN和MTA-ANALFSR的NRMSE指标均有所改进.由PSNR、MSSIM指标变化可知, 对抗学习对最终人脸超分辨率图像和高分辨率图像之间的图像信息和结构信息重建具有一定影响.由LPIPS、FID和NRMSE感知指标变化可知, 融入对抗学习, 通常可使感知指标数据变优, 超分辨率图像更具图像真实感.
各算法在CELEBA数据集上的人脸超分辨率图像如图11所示.由图可看出, 端到端学习效果相对更模糊, 结合对抗学习最终得到的超分辨率图像有明显的轮廓线和头发纹理等细节信息.由于对抗学习随机生成图像、训练困难、稳定性较差等原因[13, 14, 40, 44], 虽然能使最终超分辨率图像更符合人眼视觉习惯, 但也容易出现图像内容填充较差的情况.例如, 对比FSRNet和FSRGAN可发现, 虽然FSRGAN的图像轮廓线条比FSRNet更明显, 但是出现网格化.对比DIC、DICGAN、AUP-FSRNet和AUP-FSRGAN可发现, 第2幅、第3幅和第5幅图像填充的头发纹理较散乱.值得注意的是, 对比MTAL和MTA-ANALFSR, 再结合高分辨率图像可知, MTA-ANALFSR生成的头发纹理的线条方向更好, 更接近高分辨率图像的头发纹理方向, 相对而言更符合人眼视觉习惯.
 | 图11 各算法在CELEBA数据集上的人脸超分辨率图像Fig.11 Face super-resolution images of different algorithms on dataset CELEBA |
对比FSRGAN、DICGAN、PFSR、SPARNet、AUP-FSRGAN和MTA-ANALFSR可知, PFSR较低, 有最严重的图像信息损失和结构信息偏差.SPARNet的PSNR值为27.18 dB, MSSIM值为0.793 5, 表现最优.对比PSNR和MSSIM指标, MTA-ANALFSR与DIC-GAN相近, FSRGAN与PFSR相近, AUP-FSRGAN介于DICGAN和PFSR之间.对比LPIPS指标, MTA-ANALFSR、DICGAN和AUP-FSRGAN均在0.1000以下, 优于FSRGAN、PFSR和SPARNet, 有相对较好的特征感知相似度.对比FID指标, MTA-ANALFSR接近PFSR、DICGAN和AUP-FSRGAN, 在高分辨率图像分布模拟上表现较优.对比NRMSE指标, MTA-ANALFSR取得最好的人脸关键点重建效果, 稍优于SPARNet和DICGAN.通过上述数据对比可知, MTA-ANALFSR在各项指标的平衡性上与DCIGAN相近, 优于其它对比算法.
基于GAN的人脸超分辨率算法在CELEBA数据集上的超分辨率图像如图12所示.由图可知, FSRGAN填充的纹理出现网格式失真纹理并且较模糊.PFSR图像纹理填充丰富, 但图像扭曲失真等现象较严重.SPARNet人脸整体结构较协调, 五官轮廓线条保持较好, 但诸如头发和瞳孔等细节信息重建困难.DICGAN、AUP-FSRGAN和MTA-ANALFSR不但保持较好的人脸轮廓结构, 还具有较真实感的纹理填充信息.结合高分辨率图像, 相比DICGAN和AUP-FSRGAN, MTA-ANALFSR在细节信息重构上更优.MTA-ANALFSR生成的超分辨图像, 在瞳孔、头发纹理、嘴唇形态和牙齿轮廓等图像信息上, 更符合人眼视觉习惯.例如, MTA-ANA-LFSR生成的第1幅图像的眼镜镜面反光更鲜明, 第2幅和第5幅图像的头发纹理更细致, 第3幅图像的毛衣衣领纹理更丰富, 第4幅图像的五官轮廓线条更明显.
 | 图12 在CELEBA数据集上基于GAN的算法的超分辨率图像Fig.12 Super-resolution images of GAN-based algorithms on CELEBA dataset |
值得注意的是, 本文算法未使用人脸图像其它特征信息(如人脸关键点热图、解析图、人脸关键点距离和面部注意力信息等)进行辅助训练, 而其余算法均利用这些人脸图像的先验知识辅助人脸超分辨率任务.
上述实验表明, MTA-ANALFSR将多任务对抗学习融入端到端学习, 能改进端到端人脸超分辨率图像信息损失、结构信息失真和人眼视觉感知的习惯效果.将抗噪对抗学习融入主任务网络参数微调中, 虽然损失部分图像信息和结构信息重建效果, 但进一步改进超分辨率图像的人眼视觉感知效果, 生成的人脸超分辨率图像更具有图像真实感.
为了改进8倍率端到端学习人脸超分辨率图像的人眼视觉感知效果, 提高图像的真实感, 本文提出基于多任务对抗和抗噪对抗学习的人脸超分辨率算法(MTA-ANALFSR).在端到端学习阶段, 设计多任务拉普拉斯金字塔网络, 结合多任务对抗学习, 不仅改进主任务网络(端到端学习)的人脸超分辨率图像与高分辨率图像之间的图像信息损失和结构信息失真, 也使超分辨率图像更符合人眼视觉习惯.在主任务网络参数微调阶段, 融入抗噪对抗学习, 使超分辨率图像的人眼视觉效果优于非抗噪对抗学习效果.生成的超分辨率人脸图像, 包括头发纹理、牙齿轮廓线、瞳孔反光点等细节信息更清晰合理.通过对比其它基于对抗学习的人脸超分辨率模型, MTA-ANA-LFSR在未使用先验人脸图像特征信息(如人脸关键点热图、解析图、人脸关键点距离和面部注意力信息等)进行辅助训练的前提下, 和DICGAN一样, 保持PSNR、MSSIM和LPIPS、FID、NRMSE指标之间的平衡性, 人眼视觉质量也优于对比模型.本文算法中多任务对抗学习和抗噪对抗学习在训练上相对更繁复.今后可考虑结合人脸的一些先验特征信息, 简化训练繁复程度, 期望得到更简洁的算法, 以及更具有图像真实感的人脸超分辨率图像.
本文责任编委 杨健
Recommended by Associate Editor YANG Jian
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|