



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
面向夜间疲劳驾驶检测的改进Zero-DCE低光增强算法
[黄振宇1, 2  , 陈宇韬
, 陈宇韬1, 2, 3 , 林定慈1, 2 , 黄捷1, 2, 3 ]
, 陈宇韬, 林定慈, 黄捷]
|
|



作者简介: 
黄振宇,硕士研究生,主要研究方向为图像处理、模式识别.E-mail:1278378291@qq.com. 
陈宇韬,博士,副教授,主要研究方向为模型预测控制算法、混合增强智能、无人智能系统及应用.E-mail:yutao.chen@fzu.edu.cn. 
林定慈,硕士,高级工程师,主要研究方向为数字经济技术、自然语言语义理解、机器人控制、人机交互.E-mail:dencylin@163.com.
为了提高夜间疲劳驾驶检测的准确率,在现有低光增强算法Zero-DCE(Zero-Reference Deep Curve Estimation)的基础上,提出改进Zero-DCE的低光增强算法.首先,引入上下采样结构,减少噪声影响.同时,引入注意力门控机制,提高网络对图像中人脸区域的敏感性,有效提高网络的检测率.然后,针对噪声相关问题,提出改进的核选择模块.进一步,使用MobileNet的深度可分离卷积替换Zero-DCE的标准卷积,提高网络的检测速度.最后,通过人脸关键点检测网络和分类网络,判断驾驶员的疲劳状态.实验表明,在夜间环境下,相比现有的疲劳驾驶检测算法,文中算法在人脸检测的准确率和眼睛状态的识别率上都有所提升,取得较令人满意的检测效果.
About Author:
HUANG Zhenyu, master student. His research interests include image processing and pattern recognition.
CHEN Yutao, Ph.D., associate professor. His research interests include model predictive control algorithms, hybrid enhanced intelligence, unmanned intelligent systems and applications.
LIN Dingci, master, senior engineer. His research interests include digital economy technology, natural language semantic understanding, robot control and human-machine interaction.
Grounded on the existing low-light enhancement algorithm, zero-reference deep curve estimation(Zero-DCE), an improved Zero-DCE low-light enhancement algorithm is proposed to increase the accuracy of night fatigue driving detection. Firstly, the upper and lower sampling structure is introduced to reduce the influence of noise. Secondly, the attention gating mechanism is employed to improve the sensitivity of the network to the face region in the image, and thus the detection rate is increased effectively. Then, an improved kernel selecting module is proposed for the problems arising from noise. Furthermore, standard convolution of Zero-DCE is replaced by the depthwise separable convolution of MobileNet to accelerate the detection. Finally, the driver fatigue state can be judged by the face key point detection network and classification network. The experimental results show that the proposed algorithm improves the accuracies of face detection and eye state recognition rate in a night environment with satisfactory detection results compared with the existing fatigue driving detection algorithms.
疲劳驾驶是导致重大车祸的主要原因之一, 严重威胁交通安全.美国高速公路安全管理局(Na-tional Highway Traffic Safety Administration, NHTSA)估计, 美国每年因疲劳驾驶造成近10万起车祸, 1 500多人死亡和71 000人受伤[1].在中国, 据保守估计, 2015年因疲劳驾驶造成约1 271起交通事故, 677人死亡, 1 600人受伤[2].据美国国家安全委员会(National Security Council, NSC)报告, 每25名成年驾驶员中约有1名驾驶员表示在过去的30天内出现过开车时睡着的情况, 大多数驾驶员表示常在睡眠不足的状态下开车.虽然, 一些机构、部门已采取措施限制疲劳驾驶现象, 但是, 对于像长途汽车驾驶员之类的工作者, 由于工作原因, 经常需要连续行车, 更容易出现疲劳状况.在疲劳状态下, 由于人体生理机能的下降, 驾驶员往往会出现反应过早或过慢、修正时间不准等不安全操作, 对周围生命和环境造成严重威胁[3].因此, 十分必要对驾驶员进行疲劳检测.
现有的疲劳驾驶检测方法主要有基于车辆状态特征的方法[4]、基于驾驶员心理生理参数的方法[5]和基于驾驶员面部特征检测的方法[6].基于车辆状态特征的方法受限于特定的驾驶条件且实际使用时的检测结果不够稳定.基于驾驶员心理生理参数的方法要在驾驶员身上佩戴各种信号检测的设备, 造成驾驶体验不舒服, 且信号检测设备高昂.因此, 这两种方法难以有效推广.近年来, 随着深度学习技术的不断进步和深度学习硬件设备性能的逐步提升[7], 基于驾驶员面部特征检测的方法得到广泛使用.然而, 由于夜间环境光照强度较低, 上述检测算法难以有效提取人脸关键点位置信息, 导致降低检测效果.
传统的低光增强算法包括基于直方图均衡化的算法[8, 9]、基于Log变换的算法、基于伽玛变换的算法、基于拉普拉斯算子的算法和基于Retinex理论的算法[10].基于直方图均衡化的算法调整输入图像的直方图分布状况以增强图像亮度, 但是, 由于直方图均衡化是对整幅图像进行处理, 增强后的图像会存在局部过曝或过暗的问题.基于Log变换的算法和基于伽玛变换的算法虽然可提高低光图像的亮度, 降低图像的对比度, 但会造成图像的失真和噪声.基于拉普拉斯算子的算法可突出图像中的细节, 但同时也会带来更多噪声.基于Retinex理论的算法将输入图像看作入射图像和反射图像的乘积, 通过求解反射图像的方程对输入图像进行调整.
尽管传统的低光增强算法在某些情况下可产生令人较满意的结果, 但图像增强后的质量往往取决于人工的先验知识和正则化, 在一些复杂的情况下很难进行调优, 且基于Retinex理论的算法会导致增强后的图像色彩失真.此外, 由于传统低光增强算法复杂的优化过程, 推理时间一般较长, 不适合用于实时任务.
随着深度学习的发展, 低光图像增强领域出现许多优秀的算法.Guo等[11]提出LIME(Low-Light Image Enhancement via Illumination Map Estimation), 在图像的RGB三通道中找到最大值, 用于估计每个像素的照度, 再通过先验结构作用于像素上, 完善初始图像, 得到增强图像, 但是经LIME增强后的图像色彩不太理想.Lü 等[12]提出MBLLEN(Multi-branch Low-Light Enhancement Network), 解决低光图像中存在的亮度、噪声、对比度等问题, 但对图像的处理时间较长.近年来, 研究者们开始将Retinex理论与深度网络结合[13, 14].Zhang等[15]提出KinD(Kind-ling the Darkness), 针对仅提高黑暗区域的亮度会带来伪影的问题, 将原始图像空间分为两个较小的子空间, 通过不同曝光条件下的成对图像进行训练.欧嘉敏等[16]在Retinex-Net的基础上引入颜色损失函数, 保留图像的低频部分, 减少颜色失真的影响, 但是网络参数量较大, 难以实时处理图像.
同时, 一些研究者开始将GAN(Generative Ad-versarial Networks)技术应用于低光图像增强任务[17].基于GAN技术的算法利用非配对训练数据, 一定程度上解决低光增强领域没有真实配对训练数据的难题, 但这些非配对训练数据需要仔细选取以保证训练数据具有相同或相似的数据分布, 并且基于GAN技术的深度学习网络模型在训练过程中十分不稳定.Guo等[18]提出Zero-DCE(Zero-Reference Deep Curve Estimation), 通过深度曲线估计消除配对数据与非配对数据的需求, 将低光增强问题转换为图像特定曲线估计问题, 训练速度较快.但是, Zero-DCE在训练过程中需要始终保持图像大小不变, 使网络难以处理噪声, 给夜间疲劳驾驶检测任务带来挑战.
综上所述, 在夜间环境下进行疲劳驾驶检测, 不仅需要实时处理相机拍摄的图像, 还需要保证疲劳驾驶检测的准确性.因此本文在Zero-DCE的基础上, 提出改进Zero-DCE的轻量级低光增强算法(Improved Zero-DCE).首先, 使用上采样结构减少噪声影响.同时, 引入注意力门控机制[19], 使网络更关注图像中的人脸区域, 提高网络的检测率.然后, 针对噪声相关问题, 提出改进的核选择模块.进一步, 使用MobileNet[20]的深度可分离卷积操作替换Zero-DCE的标准卷积操作, 减少网络的计算量.最后结合人脸关键点检测网络和分类网络, 判断驾驶员的疲劳状态.
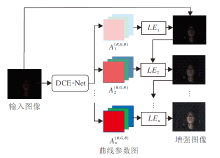
Zero-DCE将一幅低光照图像作为输入, 通过DCE-Net学习曲线参数图, 然后通过亮度增强曲线对输入图像进行像素级调整, 经过多次迭代获得增强后的图像.Zero-DCE框架如图1所示.
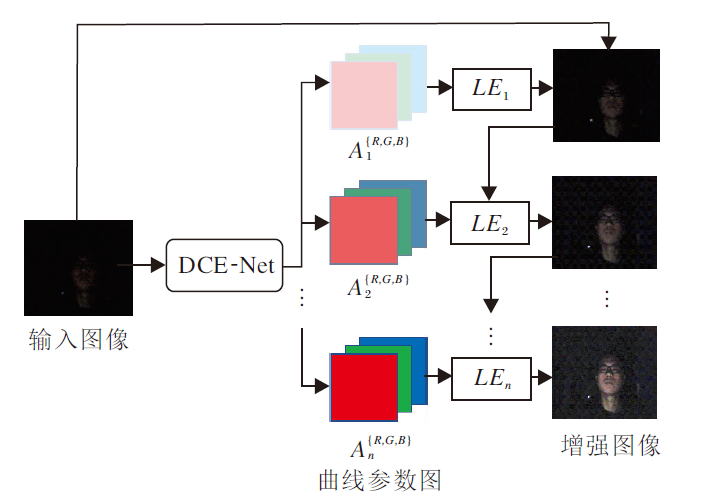 | 图1 Zero-DCE框架图Fig.1 Framework of Zero-DCE |
图像亮度增强后的结果为:
LEn(x)=LEn-1(x)+An(x)LEn-1(x)(1-LEn-1(x)),
其中, x表示图像像素坐标, n表示迭代次数, An表示曲线参数图, 大小与输入图像大小相等.通过上式, 输入图像的每个像素都被赋予一条最优化的高阶曲线, 使其能动态调整亮度.
为了得到合适的曲线参数图, 通过神经网络模型进行训练, DCE-Net结构如图2所示, 整个网络模型由7个卷积层和激活函数组成.在整个特征提取过程中, 图像的高度和宽度始终保持不变, 仅在通道维度上进行改变.
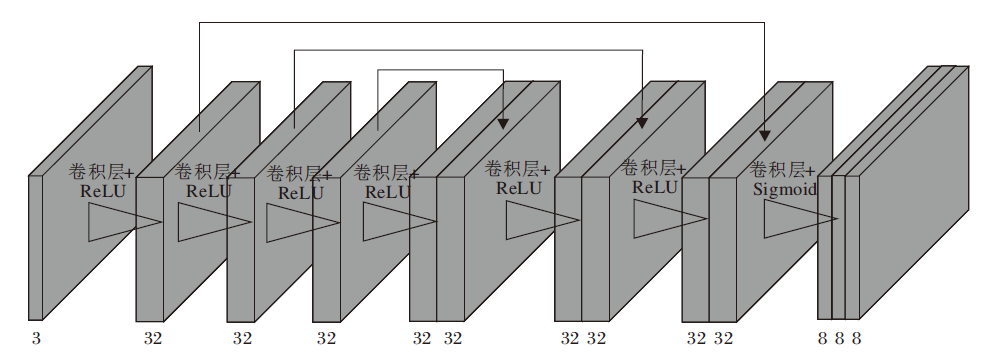 | 图2 DCE-Net结构图Fig.2 Architecture of DCE-Net |
首先, 输入1幅640× 640的图像, 通过第1个卷积操作, 将输入图像的通道数扩充到32维, 然后再通过3个卷积操作, 进一步提取特征.为了进一步加强特征提取, 在第5~7个卷积操作前, 先进行特征通道拼接操作, 使通道维数扩充到64维.最后, 使用卷积加激活函数操作将特征通道数压缩到24维, 包含RGB三通道各8个维度.
为了使网络在零参考信息的情况下完成训练, 本文采用一系列非参考损失函数, 包括空间一致性损失、曝光控制损失、彩色恒常损失和亮度平滑损失.下面简单介绍各个损失函数.
空间一致性损失函数是为了确保图像增强前后的局部区域与其周围像素的关系保持一致, 具体公式如下:
Lspa=
其中, K表示局部区域的数量, I表示图像增强前的局部区域平均值, Y表示图像增强后的局部区域平均值, Ω (i)表示以区域i为中心的上下左右四个邻近区域, 本文将每个区域i的大小定为4× 4.
曝光损失函数表示平均强度值与理想曝光值间的距离, 使图像增强后具有良好的曝光值.具体公式如下:
Lexp=
其中, Y表示图像增强后局部区域的平均强度值, E表示理想状态下RGB颜色空间的灰度级, 设置为0.6, M表示16× 16的不重叠区域的数量.曝光损失函数有效控制每个局部区域的平均强度值与理想曝光值E之间的距离.
彩色恒常损失函数利用灰度世界的原理[21], 修正增强图像中潜在的颜色偏差, 并在RGB三通道间建立调整关系, 保证图像在增强后, RGB三通道的平均值尽可能接近, 具体公式如下:
Lcol=
其中, Jp、Jq分别表示通道p、q的平均强度值, (p, q)表示属于ε 的一组通道.
亮度平滑损失函数主要是为了保持邻近像素点间的单调关系, 使相邻像素的曲线参数值尽可能接近, 平滑增强后的图像.具体公式如下:
LtvA=
其中, N表示迭代次数,
因此, 总损失函数可表示为
Ltotal=Lspa+Lexp+WcolLcol+WtvALtvA,
其中, 权重系数Wcol和WtvA用于平衡各损失函数间的比例.
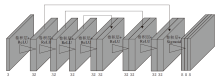
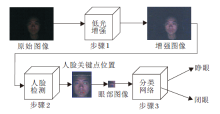
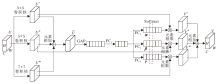
为了克服Zero-DCE在夜间环境下难以处理噪声, 导致疲劳检测器出现人脸误检和漏检的问题, 本文在DCE-Net的基础上进行改进, 提出改进Zero-DCE的轻量级低光增强算法.整体流程如图3 所示.整个过程分为3步.1)将低光照的人脸图像输入低光增强网络, 得到增强后的图像, 2)将增强后的图像通过RetinaFace[22]人脸关键点检测网络检测人脸区域, 并根据“ 三庭五眼” 的先验知识截取人眼区域图像, 3)将眼部图像输入分类网络中, 进行疲劳状态识别.考虑到RetinaFace与MobileNetV2检测人脸、人眼步骤的复杂性, 结合RetinaFace与MobileNetV2, 组成人脸检测网络.然后, 将低光增强网络放在人脸检测网络之前, 结合二者, 形成端到端的夜间疲劳驾驶检测模型.改进后的DCE-Net网络结构如图4所示.
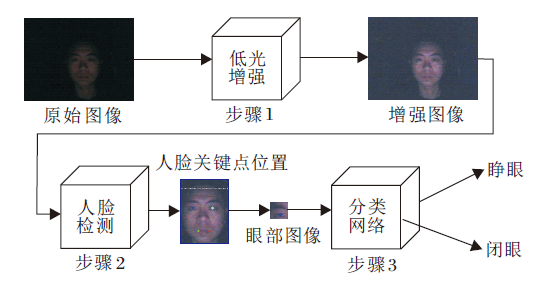 | 图3 本文算法流程图Fig.3 Flowchart of the proposed algorithm |
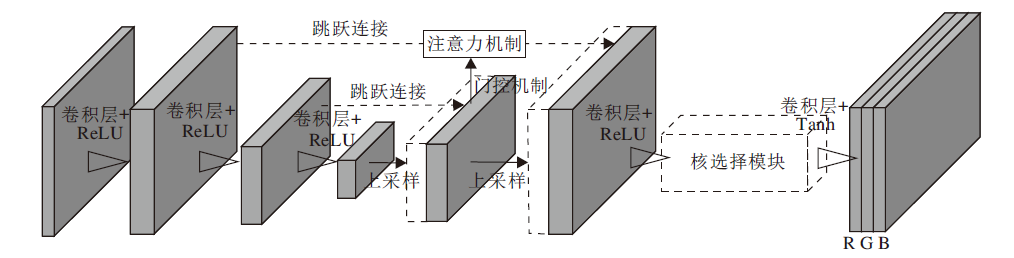 | 图4 改进的DCE-Net结构图Fig.4 Architecture of improved DCE-Net |
针对噪声相关问题, 当图像受到强噪声影响时, 会丢失噪声周围的局部信息, 此时, 噪声处的上下文信息将较有用.使用不同尺度的感受野可充分利用空间特征, 进行多尺度特征融合, 挖掘丰富的上下文信息.在多尺度特征融合方面, 现有的大多数方法都是基于特征金字塔结构, 以元素相加或串联的方式组合特征.虽然可结合不同尺度的特征图, 却忽略不同尺度特征的空间和通道特异性.因此, 基于特征金字塔结构的方法不能自适应地表达多尺度特征.受到SKNet(Selective Kernel Networks)[23]的启发, 在特征融合阶段, 提出改进的核选择模块(Kernel Selecting Module), 可自适应地调整感受野大小, 动态选择合适的路径, 特别是针对夜间场景下噪声图像中不断变化的噪声分布.改进的核选择模块结构如图5所示.
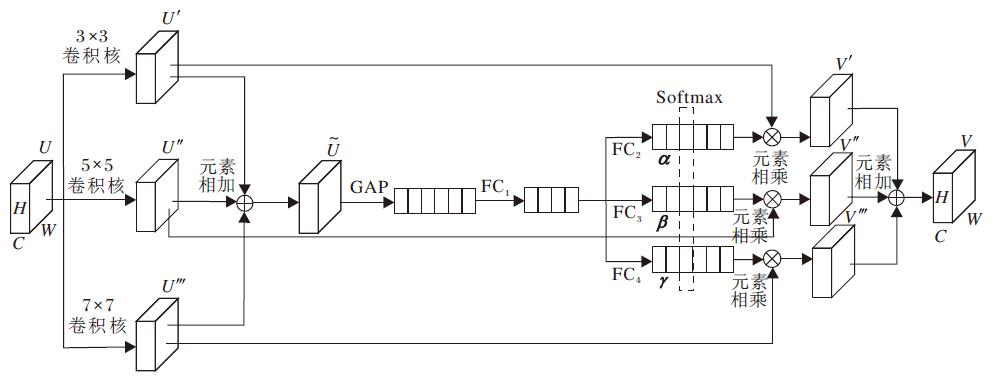 | 图5 核选择模块结构图Fig.5 Architecture of kernel selecting module |
针对输入特征图U, 选择3种不同大小的卷积核进行处理, 卷积核大小分别为3× 3, 5× 5和7× 7, 得到U', U″和U‴, 将三者相加得到
kc=
其中, α 、 β 、γ 分别表示特征图U'、U″、U‴的软注意力向量, α c表示α 的第c个元素, β c和γ c类似.
最后将不同大小卷积核处理的特征图与其相应的软注意力向量相乘, 得到最终的输出特征图:
Vc=α c· U'+β c· U″+γ c· U‴.
针对DCE-Net在特征提取过程中难以处理噪声而导致人脸检测的误检现象, 本文引入上采样结构模块, 降低噪声对输出结果的影响.网络结构如图4所示.首先, 输入一幅256× 256的RGB三通道原始图像, 通过第1个卷积操作, 将图像的通道数扩展到16维.为了减小噪声的影响, 使用两次卷积加激活函数操作, 将特征图的大小压缩至原图大小的1/16.之后, 通过两次上采样操作, 将特征图大小恢复成原图大小.同时, 为了弥补两次卷积加激活函数操作造成的信息丢失, 借鉴U-Net[24]的跳跃连接, 连接浅层网络和深层网络, 保留浅层网络的信息, 使深层网络的特征更丰富.
在上采样结构中引入跳跃连接, 将深层网络上采样后的特征图与上一层的特征图进行拼接, 虽然可避免浅层网络在下采样过程中丢失空间信息, 但是由于浅层网络有许多冗余的特征, 在特征提取过程中会引入噪声.为了使上述的特征提取网络能提取更关键的任务目标信息, 本文引入注意力门控机制模块, 结构如图4所示.门控机制用于激活图像空间信息的栅格信号, 使跳跃连接可融合不同比例的特征, 丰富语义信息.注意力机制通过学习的方式获取每个通道的特征权重, 再根据权重值加强关键特征的效果并抑制与人脸区域不相关的特征.
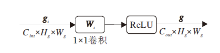
门控机制结构如图6所示.首先, 将特征图沿通道维度进行压缩, 特征图的宽高保持不变, 然后通过ReLU激活函数, 激活具有正值的神经元, 使神经网络更具稀疏性, 加快模型的计算效率.门控机制输出特征图:
g=δ (
其中, bi表示偏差项, δ (· )表示ReLU激活函数, gi表示输入特征图, Wi∈
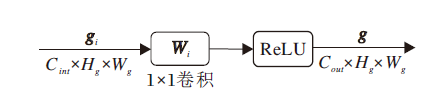 | 图6 门控机制结构图Fig.6 Architecture of gating mechanism |
注意力机制结构如图7所示.首先, 将通过门控机制得到的特征图与浅层特征图分别进行1× 1卷积操作, 转换为通道数为Cint的特征图, 将2个特征图进行加法操作.再将相加后的特征图通过ReLU激活函数, 舍弃全部负数的特征值, 通过1× 1卷积操作, 对特征图进行通道维度上的压缩, 使用Sig- moid激活函数, 将特征值控制在0~1范围内.进一步, 为了融合粗粒度特征图的上下文信息提取能力和细粒度特征图的纹理信息提取能力, 需要对注意力图进行上采样操作, 再将注意力图与浅层特征图进行乘法操作, 得到各像素点的注意力系数α , α 的大小在一定程度上反映二维特征在特征图上的重要程度.最后, 将α 与浅层特征图上的像素点进行乘法操作, 得到经过注意力机制的特征图.注意力机制的表达如下:
其中,
 | 图7 注意力机制结构图Fig.7 Architecture of attention mechanism |
注意力门控机制可添加在模型的跳跃连接上.本文在实验中发现, 在特征提取网络的浅层跳跃连接中引入注意力门控机制, 可使网络学习到各个通道的权重系数, 有效选取那些有利于低光增强任务的特征, 抑制周围环境的噪声特征, 降低后续夜间疲劳驾驶检测的难度.
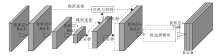
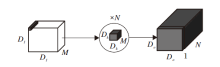
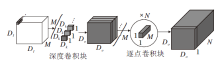
进一步, 为了使疲劳检测网络达到实时性的需求, 本文引入深度可分离卷积模块.深度可分离卷积模块分为深度卷积块(Depthwise)和逐点卷积块(Pointwise), 具体操作如图8和图9所示.
 | 图8 标准卷积操作Fig.8 Standard convolution operation |
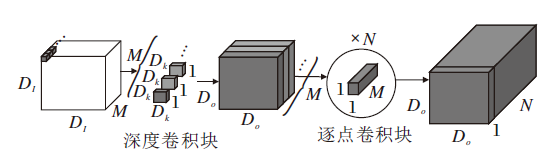 | 图9 深度可分离卷积操作Fig.9 Depthwise separable convolution operation |
深度卷积块先对每个通道单独进行卷积, 提取单通道的信息, 再通过1× 1的逐点卷积块对输入特征图的通道进行扩展或压缩, 得到预期大小的特征图.相比标准卷积核, 深度可分离卷积核在网络精度几乎不降的情况下, 大幅降低网络的参数量.
通常, 在网络模型中使用卷积核的大小为3× 3, 输出通道数远大于输入通道数, 因此, 深度可分离卷积在计算量上可近似为标准卷积的1/9, 大幅减少网络模型的参数量.
本次实验选择如下实验数据集:Zero-DCE网络数据集[18]、笔者使用RGB摄像头在不同低光照环境下拍摄的人脸图像、公开的DICM数据集[25]、NPE数据集[26].对于CNN分类网络的训练, 使用的数据包括CEW闭眼数据集[27]和对眼部区域裁剪后的LFPW室外标记的人脸面部数据集[28], 共收集1 919幅人眼图像, 其中睁眼图像852幅, 闭眼图像1 067幅.训练集和测试集的比例设为8:2.在训练、测试过程中, 为了增强数据的可靠性, 将图像大小统一缩放至256× 256.
本次实验的操作系统为Windows10, CPU为AMD Ryzen 7 4800 Hz, 显卡为NVIDIA GeForce RTX 2060, 深度学习框架为PyTorch.
在实验过程中, 根据测试阶段得到的增强图像, 通过图像客观评估指标和图像增强后的视觉表现, 利用控制变量法, 尝试不同的权重系数值.实验中发现, 不使用空间一致性损失函数会使增强图像出现局部对比度问题, 不使用曝光损失函数会导致增强图像过暗, 不使用彩色恒常损失函数会使增强图像出现色差, 不使用亮度平滑损失函数会导致增强图像出现伪影, 将图像的理想曝光值设置为0.5会导致欠曝现象, 设置为0.7会导致过曝现象.最终将低光增强算法的空间一致性损失函数的权重系数设为1, 曝光损失函数的权重系数设为1, 彩色恒常损失函数的权重系数设为5, 亮度平滑损失函数的权重系数设为1 600, 光照图像理想曝光值E设为0.6, 分类网络的批量化大小设为32, 学习率设为0.001, 训练轮次设为100.
为了验证本文算法的性能和优势, 设计多组消融实验与对比实验, 并采用如下图像客观评估指标:峰值信噪比(Peak Signal to Noise Ratio, PSNR)、结构相似性(Structural Similarity, SSIM)[29]、基于感知的图像质量评估(Perception-Based Image Quality Evaluator, PIQE)[30]和自然图像质量评估(Natural Image Quality Evaluator, NIQE)[31].
PSNR和SSIM值越高, 表明增强结果图像的质量越优.PIQE和NIQE值越低, 表明增强结果图像的质量越优.
首先, 以PSNR和SSIM为性能评价指标, 设计一组关于上下采样结构的消融实验, 结果如表1所示.表中Improved Zero-DCE使用上下采样结构的特征提取网络代替Zero-DCE中的特征提取网络.相比Zero-DCE, Improved Zero-DCE的PSNR和SSIM值都明显提高, 说明上下采样结构可有效抑制噪声, 减少外界环境的干扰.由此验证上下采样结构可有效弥补Zero-DCE难以处理噪声的缺点.
| 表1 上下采样结构的消融实验结果 Table 1 Ablation experiment results of upper and lower sampling structure |
此外, 通过消融实验进一步验证网络是否需要注意力门控机制及注意力门控机制插入位置的问题, 基础框架为Improved Zero-DCE.实验结果如表2所示, 表中黑体数字表示最优值.综合对比4种策略的PSNR和SSIM值, 发现在浅层跳跃连接上添加注意力门控机制取得最优值.
| 表2 注意力门控机制的消融实验结果 Table 2 Ablation experiment results of attention gating mechanism |
同时, 在实验中发现, 相比添加注意力门控机制的低光增强网络(简记为Attention Zero-DCE), 不添加注意力门控机制的低光增强网络得到的增强图像, 在步骤2人脸关键点检测过程中, 会出现在一幅人脸图像上检测2个人脸框的现象, 如图10所示, 这严重影响最终的疲劳状态识别结果.由此验证注意力门控机制能使模型抑制与人脸区域不相关的特征, 集中注意力激活人脸区域的特征.
 | 图10 人脸关键点位置检测结果Fig.10 Results of face key points detection |
最后, 针对核选择模块的有效性, 设计一组消融实验进行验证, 基础框架为Improved Zero-DCE.结果如表3所示.引入核选择模块后, PSNR和SSIM值都进一步提升.由此验证核选择模块的有效性, 通过自适应调整感受野大小, 进行多尺度特征融合, 降低噪声影响.
| 表3 核选择模块的消融实验结果 Table 3 Ablation experiment results of kernel selecting module |
本节通过多个对比实验, 验证本文算法的优势.为了体现本文算法的轻量性和实时性, 采用如下对比算法:LIME[11], MBLLEN[12], Retinex-Net[14], KinD[15], EnlightenGAN[17]和Zero-DCE[18].各算法的性能对比如表4所示, 表中黑体数字表示最优值.
| 表4 各算法的性能对比 Table 4 Performance comparison of different algorithms |
通过替换Zero-DCE的特征提取网络和引入深度可分离卷积, 在模型参数量和浮点运算数上, 本文算法都优于现有的低光增强算法.在推理时间上, 本文算法优于大部分低光增强算法.
为了验证本文算法对低光照图像的增强效果, 针对低光照数据集, 首先对图像进行灰度转换, 然后统计图像中每个像素的灰度值, 最后将所有像素的灰度值相加再取均值.低光图像整体的平均亮度值为8.83, 而增强图像整体的平均亮度值为28.02.引入低光增强算法后, 相比原图, 增强后图像的整体亮度值大幅提升, 有利于之后的人脸检测和人眼分类步骤.
进一步, 为了综合评估本文算法的性能, 选择DICM、NPE数据集作为测试对象, 并采用PIQE和NIQE作为图像客观评价指标.各算法的视觉效果对比如图11所示.由图可见, LIME和Retinex-Net增强的结果色彩不理想, MBLLEN和EnlightenGAN的增强结果偏暗, KinD的增强结果中物体边缘处产生伪影, Zero-DCE的增强结果易受到噪声影响.
 | 图11 各算法在典型低光照图像上的视觉效果对比Fig.11 Visual result comparison of different algorithms on typical low light images |
各算法在2个数据集上的NIQE、PIQE值对比如表5所示, 表中黑体数字表示最优值.由表可知, 本文算法在PIQE指标上取得最优结果, 在NIQE指标上, 优于大部分算法.综合图像客观评价指标和图像增强结果的可视化, 本文算法的低光增强性能最佳.
| 表5 各算法在公开数据集上的客观评价结果对比 Table 5 Objective evaluation results of different algorithms on public dataset |
在低光照数据集上, 采用RetinaFace直接检测人脸关键点位置, 漏检率达到6.56%, 而整体的平均准确率为88.70%.
使用Zero-DCE先对原始图像进行低光增强, 再通过RetinaFace检测人脸关键点位置, 平均准确率为98.55%, 虽有不小的提升, 但是漏检率升至7.14%, 漏检更多人脸, 部分原因是由于在低光增强过程中, Zero-DCE难以处理噪声, 导致增强后图像的人脸区域夹杂着环境信息, 使RetinaFace未检测人脸关键点位置.
而在低光增强过程中使用Improved Zero-DCE, 再通过RetinaFace检测人脸关键点位置, 漏检率为1.51%, 平均准确率为99.36%, 都有明显改善, 有利于后续对驾驶员疲劳状态的识别.
在原始图像上和使用低光增强算法后检测的人脸关键点位置如图12所示.由图可看出, 在原始图像上的人脸检测准确率较低, 人脸关键点位置都有些许偏差, 而引入低光增强算法之后, 人脸检测的准确率得到提高, 人脸关键点位置也更精确.
 | 图12 人脸关键点位置检测结果Fig.12 Results of face key points detection |
综上所述, 本文算法有助于提高夜间人脸关键点位置检测效果.
为了避免低质量数据影响实验结果, 经过人工筛选, 本次用于眼睛状态识别实验的数据集包含睁眼、闭眼图像共计572幅.直接使用RetinaFace+CNN, 识别率仅有74.13%, 正确识别图像424幅.在人脸关键点位置检测前先使用Zero-DCE, 再使用RetinaFace+CNN, 眼睛状态的识别率得到提升, 为85.31%, 正确识别图像为488幅.在人脸关键点位置检测前先使用本文算法得到增强图像, 再使用RetinaFace+CNN对眼睛状态进行识别, 可进一步提升识别率, 为93.53%, 同时正确识别图像升至535幅.
实验表明, 加入低光增强算法之后, 疲劳驾驶检测器的性能大幅提升, 主要是因为在夜间环境下, 未使用低光增强算法的图像曝光度较低, 人脸检测器难以准确检测人脸, 影响对眼睛状态的判别, 最终影响疲劳驾驶检测结果.
针对夜间疲劳驾驶检测这一任务, 本文提出改进Zero-DCE的低光增强算法, 在人脸检测任务之前引入低光增强算法, 然后通过人脸关键点检测网络得到眼睛区域, 最后使用CNN分类网络判断眼睛是睁开状态还是闭合状态.
本文算法在特征提取网络上使用上下采样结构取代DCE-Net的主干网络, 降低噪声影响.再引入注意力门控机制, 使网络有效激活图像中人脸区域的特征.然后, 针对噪声相关问题, 提出改进的核选择模块.进一步地, 为了使夜间疲劳驾驶检测达到实时性的目的, 使用MobileNet的深度可分离卷积核代替标准卷积核, 大幅减少网络的推理时间和计算量.最后, 通过多组消融实验和对比实验验证本文算法的性能.实验表明, 加入低光增强算法后, 相比现有的疲劳驾驶检测算法, 夜间疲劳驾驶检测的准确率和识别率都有不小提升.
今后的研究重心是研究在不同场景下的疲劳驾驶检测.同时, 将收集、制作更多不同场景下的疲劳驾驶图像, 使疲劳驾驶检测算法应用于更广泛的实际环境中.
本文责任编委 张军平
Recommended by Associate Editor ZHANG Junping
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|