
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于多尺度特征融合的抗背景干扰人群计数网络
[余鹰1  , 李剑飞
, 李剑飞1 , 钱进1 , 蔡震1 , 朱志亮1 ]
, 李剑飞, 钱进, 蔡震, 朱志亮]
|
|



作者简介: 
李剑飞,硕士研究生,主要研究方向为计算机视觉、模式识别.E-mail:ljf_ecjtu@163.com. 
钱 进,博士,教授,主要研究方向为粒计算、大数据挖掘、机器学习.E-mail:qjqjlqyf@163.com. 
蔡 震,硕士研究生,主要研究方向为机器学习、粒计算、模式识别等.E-mail:caizhenup@163.com. 
朱志亮,博士,讲师,主要研究方向为图像处理、虚拟现实、人际交互.E-mail:rj_zzl@ecjtu.edu.cn.
随着计算机视觉和人工智能相关技术的快速发展,基于智能视频分析的人群计数算法取得长足进步,但在计数准确性和算法鲁棒性上还有很大的提升空间.针对复杂场景人群计数任务中存在的目标多尺度及背景干扰等问题,文中提出基于多尺度特征融合的抗背景干扰人群计数网络(Anti-Background Interference Crowd Counting Network Based on Multi-scale Feature Fusion, AntiNet-MFF).在U-Net网络架构基础上融入多层次特征分割提取模块,借助深度学习强大的表征能力提取人群多尺度特征.同时,为了提升计数模型对人群区域的关注度,减少背景噪声干扰,在解码阶段生成背景分割注意力图,作为注意力引导计数模型聚焦人头区域,提升人群分布密度图的质量.在多个典型人群计数数据集上的实验表明,AntiNet-MFF在准确性和鲁棒性上都取得良好效果.
About Author:
LI Jianfei, master student. His research interests include computer vision and pattern recognition.
Qian Jin, Ph.D., professor. His research interests include granular computing, big data mining and machine learning.
CAI Zhen, master student. His research interests include machine learning, granular computing and pattern recognition.
ZHU Zhiliang, Ph.D., lecturer. His research interests include image processing, virtual reality and human-computer interaction.
With the continuous development of computer vision and artificial intelligence, crowd counting algorithms based on intelligent video analysis have made considerable headway. However, the counting accuracy and robustness are far from satisfactory. Aiming at the problem of multi-scale feature and background interference in crowd counting task, an anti-background interference crowd counting network based on multi-scale feature fusion(AntiNet-MFF) is proposed. Based on the U-Net network architecture, a hierarchical feature split block is integrated into the AntiNet-MFF model, and multi-scale features of the crowd are also extracted with the help of the powerful representation capability of deep learning. To increase the attention of the counting model to the crowd area and reduce the interference of background noise, a background segmentation attention map(B-Seg Attention Map) is generated in the decoding stage. Then, B-Seg attention map is taken as the attention to guide counting model in focusing on the head area to improve the quality of the crowd distribution density map. Experiments on several typical crowd counting datasets show that AntiNet-MFF achieves promising results in terms of accuracy and robustness compared with the existing algorithms.
人群计数(Crowd Counting)属于目标计数(Ob- ject Counting)领域的研究范畴, 也是智能视频监控的重要研究内容之一[1], 可实时估计目标场景中人群的数量、密度或分布, 能对拥挤人群及时预警或辅助异常事件的检测, 在视频监控[2, 3]、公共安全管理[4, 5]、商业信息采集[6, 7, 8]等领域具有广泛的应用前景.同时, 人群计数算法可迁移到其它目标计数任务, 如细菌与细胞计数[9]、车辆计数[10]等, 拓展人群计数算法的应用范围.因此, 人群计数算法的研究具有重要的现实意义和应用价值.
随着计算机视觉和人工智能技术的快速发展, 基于视频图像的人群计数算法不断涌现.按照工作原理的不同, 可将现有的人群计数算法归为3类:基于检测的人群计数算法、基于区域回归的人群计数算法和基于密度估计的人群计数算法.基于检测的人群计数算法在遮挡严重的场景中应用时存在一定的局限性, 因此不适用于密集场景的人群计数.基于区域回归的人群计数算法虽然可用于大规模人群计数任务, 但只关注场景的目标总数, 无法提供人群的空间分布等细节信息.基于密度估计的人群计数算法适用于大规模群体目标数量统计, 在每个像素点上提取图像特征, 再训练回归模型, 直接学习从像素点特征到目标密度图的映射关系.生成的密度图既反映场景中的人群分布状况, 也可通过区域密度求和得到任意区域的人群数量, 是当前最普遍的也是最受关注的计数框架.
基于密度估计的人群计数算法又可划分为传统算法和基于深度学习的算法.传统算法大多依赖手工特征, 受手工特征表达能力不足的限制, 性能较差, 无法满足人群密集场景的计数需求.随着深度学习技术的蓬勃发展, 基于深度学习的人群计数算法逐渐占据主导地位.Zhang等[11]提出Crowd CNN(Convolutional Neural Networks) Model, 通过跨场景训练交替预估人群密度和数量.为了解决人群场景中大规模尺度变化问题, Zhang等[12]提出MCNN(Multi-column CNN), 每个分支采用不同大小卷积核, 提取图像中不同尺度特征, 但是, MCNN输出的人群密度图较模糊且计算量较大.为此, Sam等[13]提出Switch-CNN(Switching CNN), 在MCNN的基础上加入Switch开关, 并将图像进行平均划分, 然后自适应地选择合适的分支送入网络中进行训练.该方法虽然一定程度上缓解MCNN的密度图模糊问题, 但在Switch选择错误时, 会额外增加错误开销, 降低准确率.Sindagi等[14]针对MCNN生成的密度图模糊等问题, 提出CP-CNN(Contextual Pyramid CNN), 显式合并全局和局部上下文信息, 生成高质量的人群密度图.
多阵列网络结构虽然能提取多尺度特征, 但训练难度较大, 模型参数较多.近年来, Li等[15]提出CSRNet(Dilated CNN for Understanding the Highly Congested Scenes), 在通过空洞卷积[16]扩大模型的感受野的同时保留原图分辨率, 并以此避免空间信息丢失.Cao等[17]提出SANet(Scale Aggregation Net-work), 包含编码器和解码器两部分.编码器通过尺度聚合模块提取多尺度特征, 解码器通过使用转置卷积生成高分辨率密度图.
总之, 基于深度学习的人群计数算法依赖深度学习模型强大的特征自学习能力, 不仅可有效避免手工特征设计过于繁琐的问题, 而且能灵活获取图像中人群分布的细节信息, 提升密集场景人群计数的精度.
目前, 虽然人群计数问题的相关研究已取得长足进步, 但在人群密集、背景噪声干扰较大的场景中, 要实现准确的人群计数依然存在诸多困难和挑战.首先, 良好的特征表达是准确计数的基础, 然而目标尺度多样性减弱提取特征的表达能力, 如何获取多尺度信息, 增强特征判别力是提升计数算法性能的关键问题之一.其次, 复杂背景噪声会干扰计数, 因此如何去除背景噪声, 以便生成高质量人群分布密度图一直是实现准确计数的关键问题之一.针对尺度多样性, Zhang等[12]提出MCNN, 通过多阵列卷积结构提取多尺度特征, 但也有研究表明, 这种多阵列结构中不同分支学习的特征几乎相似[15].针对背景噪声, Hossain等[18]尝试通过注意力机制引导网络自动聚焦人群所在区域, 但模型参数量和计算复杂度均较高, 在高密度的场景中计数效果依旧不佳.
针对上述问题, 本文提出基于多尺度特征融合的抗背景干扰人群计数网络(Anti-Background Inter-ference Crowd Counting Network Based on Multi-scale Feature Fusion, AntiNet-MFF).以语义分割网络U-Net[19]为基础, 一方面通过串行跳层连接结构获取不同感受野, 然后在不同尺度上捕捉信息并融合.其中:浅层网络感受野较小, 提取的高分辨率细粒度表层信息包含大量空间几何细节, 适用于检测小目标; 深层网络感受野较大, 可关注到大目标, 提取的高级抽象语义信息包含与整体轮廓相关的信息, 有利于区分人群和背景区域.融合不同抽象层级的特征, 可在不采用多阵列卷积结构的条件下, 提升计数模型对目标尺度变化的适应性.为了进一步增强多尺度信息融合的效果, 在网络中添加多层次特征分割提取模块(Hierarchical Feature Spilt Block, HFS Block)和多尺度上下文特征聚合模块.另一方面, 为了提升计数模型对人群区域的关注度, 降低背景噪声对计数性能的影响, 在多尺度特征融合的基础上, 进行人群与背景区域的分割, 将生成的背景分割图作为注意力, 指导计数模型聚焦人群区域, 提升密度图的生成质量.
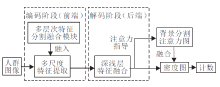
本文针对人群密集场景存在的目标多尺度及背景噪声干扰的问题, 基于U-Net网络, 提出基于多尺度特征融合的抗背景干扰人群计数网络(AntiNet-MFF).利用串行多分支结构提取人群图像多尺度特征, 然后借助跳层连接实现不同尺度特征的融合, 同时运用语义分割技术划分人群和背景区域, 生成注意力, 指导计数模型专注人群区域, 降低背景噪声干扰.AntiNet-MFF整体架构如图1所示, 包含编码器和解码器两部分.
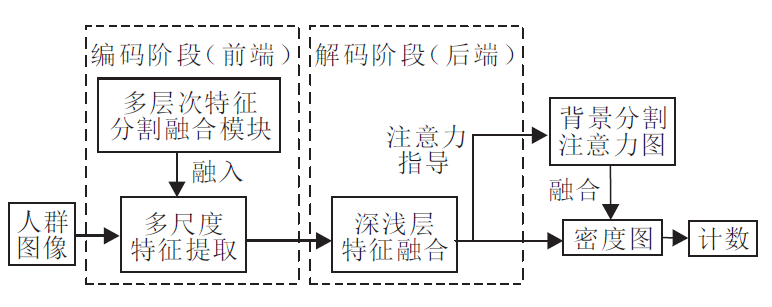 | 图1 AntiNet-MFF整体架构Fig.1 Framework of AntiNet-MFF |
前端编码器的主要任务是提取图像多尺度特征, 便于后续的注意力生成和人群计数.为了提取更丰富的多尺度特征, 将U-Net网络中3× 3卷积全部替换为多层次特征分割提取模块(HFS Block), 然后经过多次下采样后, 提取的多尺度特征送入后端解码器进行特征融合.在解码过程中, 这些多尺度特征会经历多次融合和上采样, 最终生成背景分割注意力图(Background-Segmentation Attention Map)和特征图(Feature Map).
为了获取高质量人群密度图(Density Map), 将两者对应位置元素相乘, 让注意力指导计数过程, 降低背景噪声和人群目标尺度多样化带来的干扰.
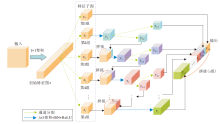
鉴于网络的输入为任意大小的图像, 因此整个网络采用全卷积结构, 确保输出的密度图与输入图像尺寸相同.AntiNet-MFF结构图如图2所示.
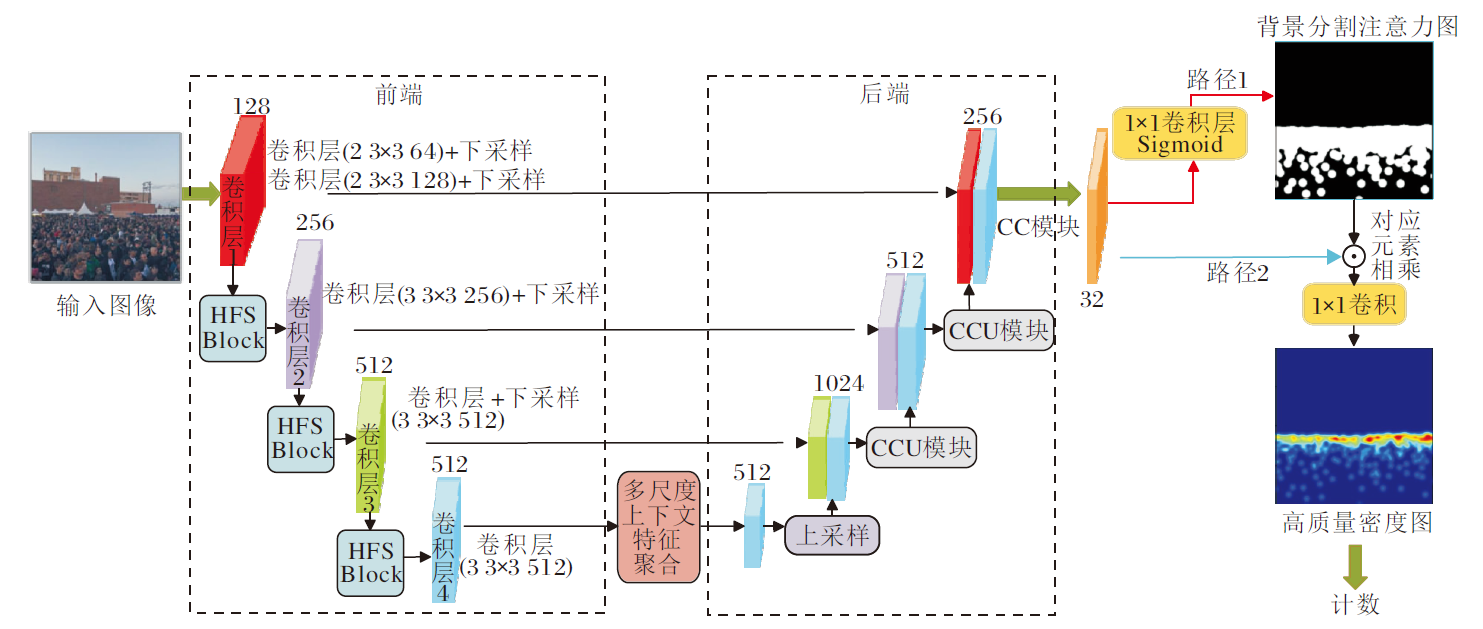 | 图2 AntiNet-MFF网络结构图Fig.2 Network structure of AntiNet-MFF |
在CNN中, 浅层特征图分辨率较高, 通常包含大量空间细节信息, 适用于目标定位.深层特征图保留较丰富的语义信息, 适用于目标分类.语义分割网络U-Net通过跳接结构直接融合不同层次的多尺度特征, 即将浅层详细的空间上下文信息逐步融合到更深层次的特征中, 增强特征的表达能力[20].
AntiNet-MFF网络架构参考U-Net的网络结构, 但在编码器部分使用多层次特征分割提取模块替换U-Net网络原有的3× 3卷积, 在具有与普通卷积相近参数量的前提下, 对卷积通道进行多层次分割提取, 旨在将浅层特征图中的细节信息进行多次分割复用后获得更清晰的特征表达.编码器最后一层连接多尺度上下文特征聚合模块, 进一步提取多尺度特征, 为解码阶段提供更清晰的语义指导.
1.1.1 基础网络
首先, 参照U-Net网络搭建编码器基础模型.编码器的骨干网络由13个卷积层和4个下采样层组成, 它们是多尺度特征提取的基础.具体结构如图2所示, 编码器共包含4个下采样层, 其中“ 卷积层(2 3× 3 64)+下采样” 表示2个通道数为64的卷积层连接一个下采样层, 卷积核大小为3× 3.编码器基础模型搭建好之后, 再将除第1个卷积层之外的所有3× 3卷积替换成HFS Block.这样经过多次卷积和下采样之后, 卷积层1~卷积层4这4层输出的特征图大小分别是原始图像的1/2、1/4、1/8和1/16.与多阵列计数网络偏好采用不同大小卷积核提取多尺度特征不同, AntiNet-MFF从单阵列网络的不同卷积层提取多尺度特征, 具有更灵活的训练过程和更少的计算量.
1.1.2 多层次特征分割提取模块
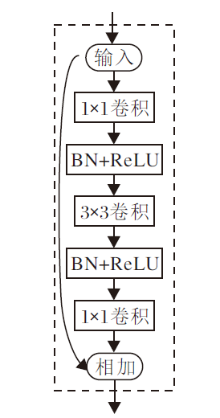
多层次特征分割提取模块(HFS Block)参照GhostNet网络[21]进行构建, 基本架构如图3所示, 通过替换普通卷积, 以分割融合的方式提取多尺度特征.
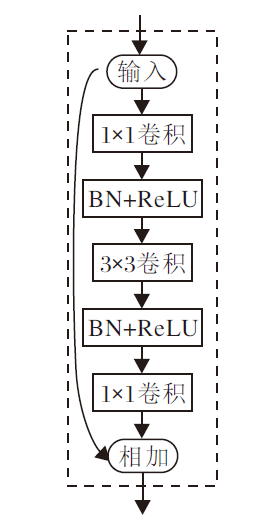 | 图3 HFS Block架构图Fig.3 Structure of HFS Block |
HFS Block的具体流程如图4所示.首先, 输入图像经过1× 1卷积获得初始特征图x.然后, x分割成s组特征子图xi(i=1, 2, …, s), 每组的通道数均为w.第1组特征子图x1直接作为本组的输出y1, 1, 拼接到最后的输出层.第2组特征子图x2经过3× 3卷积输出特征图y2, 等分为y2, 1和y2, 2, y2, 1作为本组的输出, y2, 2送入下一组.其余特征子图xi(i=3, 4, …, s)与前一组输入的yi-1, 2进行拼接, 然后经过3× 3卷积输出特征图yi(i=3, 4, …, s).yi(i=3, 4, …, s-1)被等分为yi, 1和yi, 2, yi, 1作为本组输出, yi, 2送入下一组.第s组特征图ys直接作为本组的输出ys, 1.此过程多次重复, 直到所有特征子图均处理完毕.最后, 拼接各组的输出yi, 1(i=1, 2, …, s), 使其和初始特征图的通道数保持一致, 其中各个yi, 1的通道数各不相同.拼接后的特征图会经过1× 1卷积进行重构.
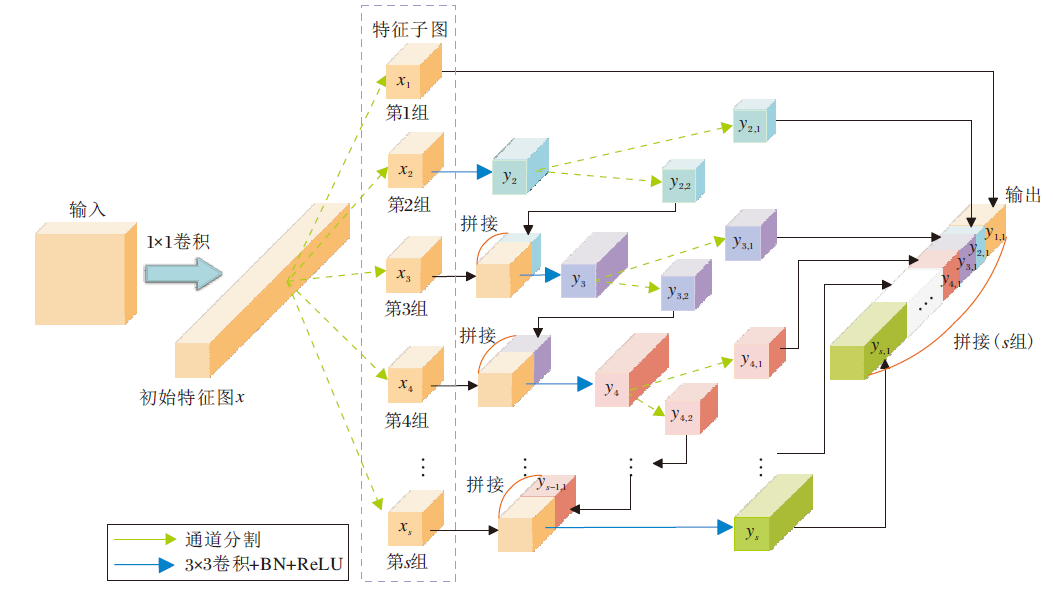 | 图4 HFS Block结构图Fig.4 Structure of HFS Block |
例如, 若输入的通道数为32, s=4, 经过1× 1的卷积后通道数变为64, 均分为4个通道数为16的组.第1组直接拼接到输出层, 第2组特征图经过3× 3卷积后, 在通道维度上均分为通道数为8的两个部分, 第1部分直接拼接到输出层, 第2部分与第3组特征子图进行拼接, 通道数为24.然后, 拼接后的第3组经过3× 3卷积后, 在通道维度上均分为通道数为12的两个部分, 第1部分直接拼接到输出层, 第2部分与第4组进行拼接, 通道为28.随后, 拼接后的第4组进行3× 3卷积, 直接拼接至输出层.最后, 4个通道数分别为16、8、12、28的特征进行拼接, 输出通道数为64的特征图.分组数量s取不同值对计数模型的性能具有一定影响.
多层次特征分割提取模块中yi的划分是实现多尺度感知的关键.yi被均分为yi, 1和yi, 2, yi, 1直接作为本组的输出, 更专注于图像细节信息的表达, yi, 2参与下一组的拼接.对于特征子图xi, 来自上一组的yi-1, 2感受野更大, 适合捕获更大的目标, 同时也包含丰富的抽象语义信息, 可对多尺度特征的提取进行指导.最后, 拼接每组输出的yi, 1, 复原成与原始输入具有相同通道数的特征图.yi的计算公式如下:
yi=
其中, Conv3× 3(· )表示3× 3卷积, xi表示经过1× 1卷积分割得到的第i组输入, 表示通道上的拼接(Concat)操作.相比像素间简单叠加的相加(Add)操作, 拼接能保留特征表示的空间相关性信息.
1.1.3 多尺度上下文特征聚合模块
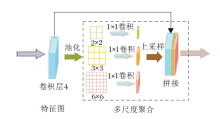
多尺度上下文特征聚合模块结构如图5所示, 用于获取不同感受野的上下文信息, 扩展多尺度表达的范围.
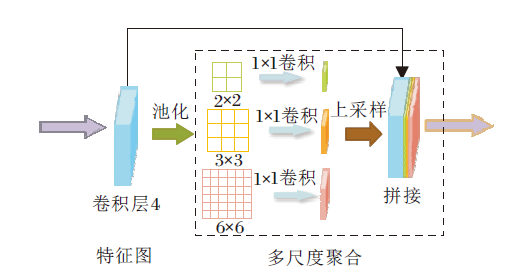 | 图5 多尺度上下文特征聚合模块结构图Fig.5 Structure of multi-scale context feature aggregation module |
多层次特征分割提取模块在编码阶段能提取不同层级特征, 在一定程度上丰富特征的尺度多样性, 但是连续的卷积和池化仅能在有限的尺度范围内提取多尺度信息.因此, 采用金字塔池化[22]将编码器最后一层卷积层4的特征图池化为3种不同的尺寸.然后, 利用1× 1卷积整合不同通道维度上的特征信息, 最后通过对低维的上下文信息特征图进行双线性插值上采样, 使其和输入特征图尺寸保持一致.
解码器的主要作用是通过跳接进一步对编码器提取的多尺度特征进行融合, 并生成背景分割注意力图, 然后在注意力的指导下, 生成更准确细致的人群密度图.
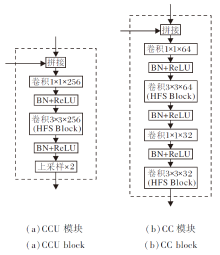
如图2所示, 编码器提取的特征图经过多尺度聚合输入解码器后, 首先会进行上采样, 得到的特征图与卷积层3输出的特征图进行拼接, 然后输入CCU (拼接+卷积层+上采样)模块进行聚合, CCU模块的结构如图6(a)所示.图2中的第2个CCU模块聚合卷积层2跳接后的特征.经过2个CCU 模块的卷积和上采样操作之后, 输出的特征图与卷积层1跳接后的特征图进行拼接, 然后输入CC(拼接+卷积层)模块, CC模块的结构如图6(b)所示.
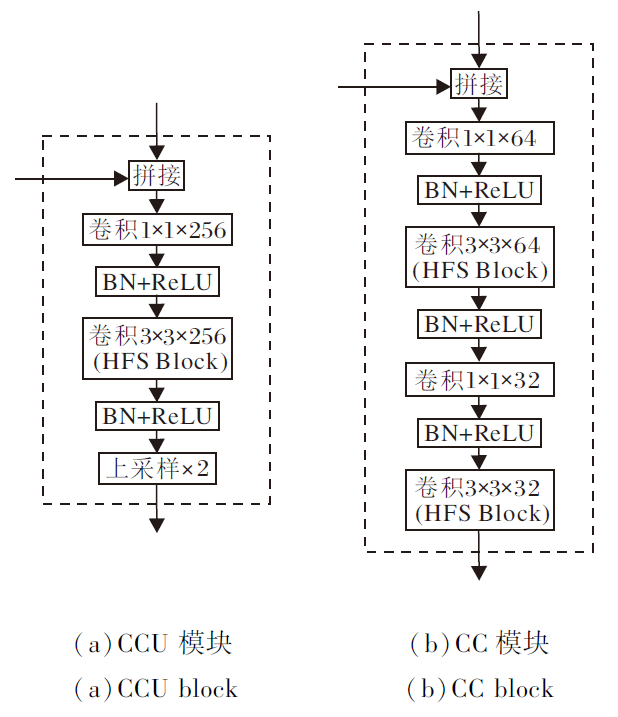 | 图6 2个模块结构图Fig.6 Structure of 2 modules |
CC模块和CCU模块均可聚合不同层次的多尺度特征, 但是相比CCU模块, CC模块在结构上缺少上采样层, 同时使用更平滑的卷积层实现特征转换.与编码器类似, 解码器中原有的3× 3卷积全部替换为HFS Block.
解码器包含两路输出, 如图2所示.路径1生成背景分割注意力图, 路径2融合注意力图和特征图, 生成高质量的密度图进行计数.
1.2.1 背景分割注意力图
背景分割注意力图可提供输入图像中人群的位置分布信息, 减少背景噪声对计数的干扰.设经过CC模块生成的密度特征图为fden, 则生成的背景分割注意力图为:
Mb-seg=Sigmoid(W⊗ fden+b),
其中, ⊗ 表示卷积操作, W和b分别表示卷积的权重和偏置, Sigmoid(· )表示激活函数, 可在网络层引入非线性, 该函数输出0~1之间的概率表示, 用于指示人群区域的概率.
1.2.2 注意力特征融合
背景分割注意力图生成后, 还需要和解码获得的密度特征图fden进行融合, 从而在准确定位人群空间位置的基础上生成高质量的密度图.首先, 背景分割注意力图Mb-seg通过和密度特征图fden对应位置元素相乘生成重新定义的密度特征图:
Fre=fden☉Mb-seg.
再通过1× 1卷积动态学习两者之间的关系, 从而生成高质量的密度图:
FH-qua=Conv1× 1(Fre).
其中☉表示对应位置元素相乘(Element-wise Mul-tiply).在进行操作之前, Mb-seg需要进行扩张, 使通道数和fden的通道数保持一致.
为了验证AntiNet-MFF的有效性, 在Shanghai-Tech[12]、UCF_CC_50[22]、UCF-QNRF[23]这3个经典的人群计数数据集上进行实验.数据集的详细信息如表1所示.
| 表1 实验数据集 Table 1 Experimental datasets |
ShanghaiTech数据集共包含1 198幅图像, 分为part_A和part_B两部分, 共标注330 165个头部坐标.人群分布较密集的Part A数据集包含300幅训练图像, 182幅测试图像, 图像分辨率是变化的.人群分布较稀疏的Part B数据集包含400幅训练图像, 316幅测试图像, 图像分辨率固定不变.总体上, 在ShanghaiTech数据集上进行精确计数是具有挑战性的, 因为该数据集无论是场景类型、透视角度, 或是人群密度都是变化多样的.
UCF_CC_50数据集内容涵盖音乐会、抗议活动、体育场和马拉松比赛等不同场景, 是第一个真正意义上具有挑战性的大规模人群计数数据集.包含50幅不同分辨率的图像, 共标注63 075个头部位置, 其中每幅图像包含的人数从94到4 543不等, 密度等级变化极大.
UCF-QNRF数据集具有场景丰富, 视角、密度及光照条件均变化多样的特点, 是一个具有挑战性的人群计数数据集, 包含1 535幅密集人群场景图像, 其中训练集1 201幅图像, 测试集334幅图像, 共标注1 251 642个目标.由于标注数量众多, 该数据集适合采用深度卷积神经网络进行训练.此外, 该数据集图像的分辨率很高, 因此在训练过程中可能出现内存不足的问题.
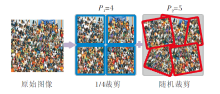
由于人群数据集标注困难, 特别是在密集场景中, 对人头进行标注的代价极大, 因此人群计数图像资源十分有限.为了获取更多的实验数据, 在训练之前对人群图像进行预处理.首先, 将ShanghaiTech数据集上所有图像的边长调整至400.同时, 针对UCF-QRNF、UCF_CC_50数据集图像分辨率过大导致计算量过高的问题, 统一将图像调整为1 024× 768的固定大小.然后, 借鉴CSRNet[15]的数据扩充方法对训练数据进行裁剪.如图7所示, 在原图上裁剪9个尺寸为原图1/4的图像子块, 其中前4个子块P1由原图均分为4份得到, 后5个子块P2由原图随机裁剪而成.后续将以0.5的概率对裁剪得到的图像进行随机水平翻转, 并以0.3的概率对其进行γ 对比度变换.对于ShanghaiTech 数据集上存在灰色图像的现象, 会以0.1的概率将彩色图像转换成灰色图像.同时, 为了匹配模型输出, ground truth密度图和背景分割注意力图均被调整为原图的1/2.
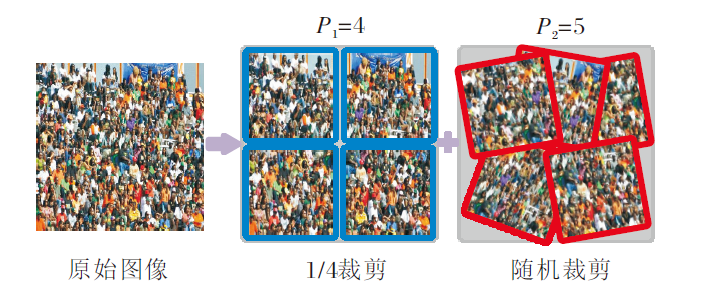 | 图7 数据增强裁剪示例图Fig.7 Sample of cropping for data enhancement |
在人群计数任务中, 数据集通常会标注人头的中心位置, 为了实现基于密度图的人群计数, 需要将这些人头标注信息转化为人群密度图.本文参照SFANet(Dual Path Multi-scale Fusion Network with Attention Mechanism)[24], 采用高斯核函数[25]对中心坐标进行处理, 生成人群密度图.具体步骤如下.
首先, 使用脉冲函数δ (x-xi)表示人群图像中N个人头坐标:
H(x)=
其中xi为第i个人头的中心位置.
然后, 将图像的人头坐标通过高斯核函数转化为连续的密度函数, 得到模糊化后的人群密度图, 即使用高斯核函数
FGT(x)=H(x)*
其中, μ 为高斯核的大小, σ 为高斯核的标准差.
在ShanghaiTech数据集上, 采用固定高斯核的方式生成人群密度图, μ =15, σ =4.在UCF-QRNF、UCF_CC_50数据集上, 采用自适应高斯核的方式生成人群密度图, 再将密度图尺寸统一规整为1 024× 768, μ 、σ 采用文献[26]的计算方法得到:
μ =1+15× 2int(
其中, int(· )为取整函数, w为图像宽度.
最终生成的密度图FGT(x)作为ground truth密度图参与训练.
根据已有的标注信息及密度图可进一步生成背景分割注意力图(B-Seg Attention Map).首先, 使用固定高斯核函数生成人群分布密度图FGT(x), 然后根据给定的阈值th, 如th=0.001, 对得到的FGT(x)进行二值化处理,
∀ pi∈ FGT(x), SGT(x)=
对于FGT(x)中所有像素点pi, 如果pi> th, 映射为背景分割注意力图上的像素值1; 否则映射为像素值0, 由此可得到人群背景分割注意力图SGT(x).
需要特别说明的是, 此处的背景分割注意力图不同于传统意义上的语义分割[27].后者需要详细拟合每位行人的准确轮廓, 而前者并不需要准确了解每人的详细轮廓, 主要是为了显示人头的大致位置和分布, 以便在模型的训练过程中对人头所在区域进行重点关注, 从而达到强化人群区域和弱化背景噪声的目的.实验结果也表明, 即使是这样简单的策略对计数性能的影响也是积极的.
本文选用预测人数与真实标注人数的绝对误差(Mean Absolute Error, MAE)及均方误差(Mean Square Error, MSE)度量网络性能, 其中, MAE主要评估网络精度, MSE评估网络鲁棒性.MAE和MSE值越小, 说明预测值误差越小, 性能越优, 泛化能力越强.具体计算公式如下:
MAE=
其中, N为测试图像总数量,
Ci=
为预测人数, F(l, w)为密度图在(l, w)处的像素值, L、W分别为预测密度图的长和宽.
为了生成人群分布密度图, 参考文献[12], 采用欧氏距离作为人群计数的损失函数, 用于度量预测密度图与真实密度图之间的差异:
Lden=
其中, Xi为输入图像,
除了密度图回归之外, 对于背景分割注意力模块, 还引入交叉熵作为损失函数:
Lb-seg=-
其中,
在整个网络的训练过程中, 将两种损失加权求和, 生成最终的损失函数:
Loss=Lden+λ Lb-seg,
其中, 超参数λ 可调节两种损失的比例, 本文设λ =0.1.
算法的实现基于Pytorch框架, 数据集遍历次数为500, 批量大小设为1, 采用Adam(Adaptive Moment Estimation)优化器, 初始学习率设为1× 10-7, 动量因子设为0.95, 权重衰减设为5× 10-4, 填充方式采用边界添加0(same)的方式.此外, 后期在损失趋于稳定时, 对学习率进行适当调整.
在训练之前, 对训练集样本进行归一化处理, 保证图像中每个像素点的值都位于(-1, 1)内, 避免出现训练内存溢出.
本文选择如下对比网络:Crowd CNN Model、MCNN[12]、Switch-CNN[13]、CP-CNN[14]、CSRNet[15]、SANet[17]、文献[23]网络、SFANet[26]、ic-CNN(Itera-tive Counting CNN)[28]、文献[29]网络.各对比网络在3个数据集上的实验数据均取自原文献.
各网络在ShanghaiTech数据集上的实验结果如表2所示, 其中ic-CNN采用双分支CNN结构以生成高质量密度图.由表可见, AntiNet-MFF在MAE和MSE指标上的表现均为最优.无论是采用多阵列结构的计数模型, 如MCNN, 还是采用空洞卷积的计数模型, 如CSRNet, 性能表现均差于AntiNet-MFF, 这说明AntiNet-MFF的多尺度特征表达能力更强.此外, 通过背景分割剔除背景噪声的干扰, 使网络更专注于人群区域, 也有助于计数性能的提升.
| 表2 各网络在ShanghaiTech数据集上的实验结果 Table 2 Experimental result comparison of different networks on ShanghaiTech dataset |
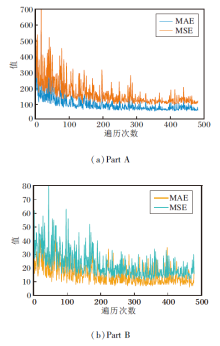
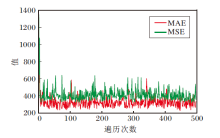
MAE和MSE的收敛趋势如图8所示.由图可知, 经过多次迭代, AntiNet-MFF的MAE、MSE可收敛到较稳定的值.
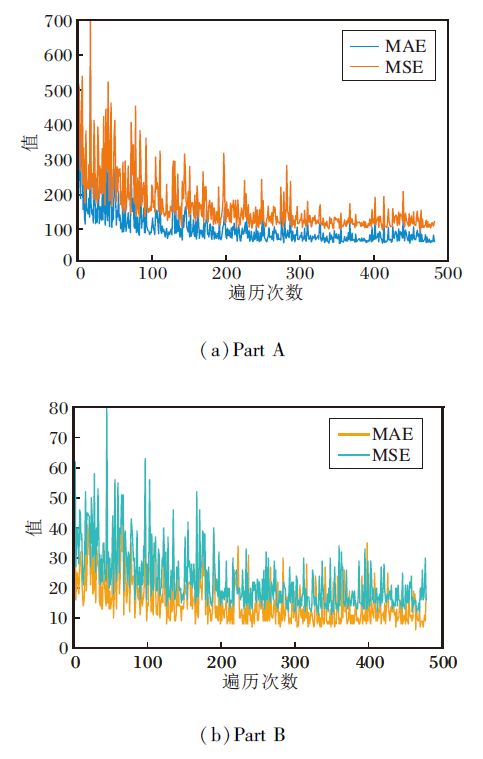 | 图8 AntiNet-MFF在ShanghaiTech数据集上的MAE和MSE曲线Fig.8 MAE and MSE curves of AntiNet-MFF on ShanghaiTech dataset |
各网络在UCF_CC_50数据集上的实验结果如表3所示.由表可见, AntiNet-MFF的准确率和鲁棒性优于大部分计数网络, 仅次于SFANet.SFANet也包含前端特征提取和后端特征融合两部分, 但后端由平行的两路网络构成, 一路生成注意力图, 另一路融合多尺度信息生成密度图, 而AntiNet-MFF的后端将注意力生成和信息融合在同一路网络中完成.相比SFANet, AntiNet的后端减少一半参数量.此外, 由于AntiNet-MFF的前后端都融入多层次特征分割提取模块, 能在保持性能不变的前提下, 进一步降低参数量, 因此, 虽然AntiNet-MFF的性能略次于SFANet, 但更简单, 计算复杂度更低.
| 表3 各网络在UCF_CC_50数据集上的实验结果 Table 3 Experimental result comparison of different networks on UCF_CC_50 dataset |
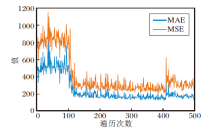
AntiNet-MFF在UCF_CC_50数据集上的MAE和MSE的收敛趋势如图9所示.由图可见, 经过多次迭代, MAE和MSE均可收敛到较稳定的值.此外, 需要特别说明的是, UCF_CC_50数据集的样本数据量太少, 验证效果可能偏弱.
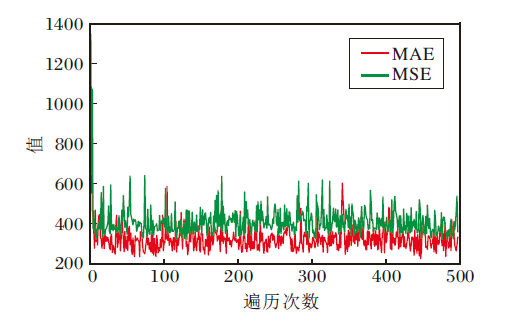 | 图9 AntiNet-MFF在UCF_CC_50数据集上的MAE和MSE曲线Fig.9 MAE and MSE curves of AntiNet-MFF on UCF_CC_50 dataset |
各网络在UCF-QNRF数据集上的实验结果如表4所示, 其中, 文献[29]网络是一个端到端级联CNN网络, 可同时完成人群数量分类和密度图估计两个关联的任务, 文献[23]网络可同时对计数、密度图估计和定位这3个任务进行训练和估计.由表可见, AntiNet-MFF在MAE和MSE指标上优于大部分计数网络, 其较好的准确性和鲁棒性进一步得到验证.
| 表4 各网络在UCF-QNRF数据集上的实验结果 Table 4 Experimental result comparison of different networks on UCF-QNRF dataset |
由于UCF-QNRF数据集包含数量极多的高分辨率图像, 人群密集, 场景种类繁多, 包括建筑物、道路、天空等野外真实的场景, 光照及目标尺度变化多样, 因此训练过程对实验的硬件条件要求较高.受已有实验条件的限制, AntiNet-MFF的训练过程未及时收敛.AntiNet-MFF的MAE和MSE指标在UCF-QNRF数据集上的收敛趋势如图10所示.由图可知, 随着遍历次数的增加, MAE和MSE并未及时收敛到某个稳定值, 这也是AntiNet-MFF未取得最优值的主要原因.
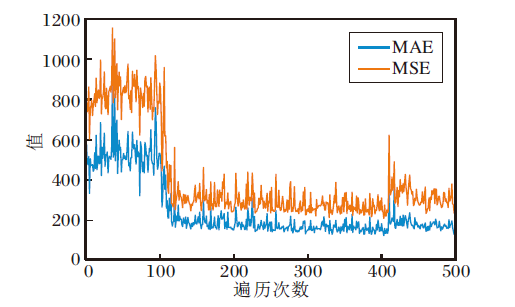 | 图10 AntiNet-MFF在UCF_QNRF数据集上的MAE和MSE曲线Fig.10 MAE and MSE curves of AntiNet-MFF on UCF_QNRF dataset |
在HFS Block中, 特征图经过1× 1卷积后被分割成s组输入, 本节讨论参数s的取值对AntiNet-MFF性能的影响.实验在ShanghaiTech Part A数据集上进行, s分别取4种不同的值, 结果如表5所示.由表可知, s取不同值对性能会产生一定影响.当s=8时, MAE和MSE达到最优.
| 表5 s不同时AntiNet-MFF的性能对比 Table 5 Performance comparison of AntiNet-MFF with different s |
为了验证添加多尺度特征融合和背景分割注意力的有效性, 移除编码器中的HFS Block和多尺度上下文特征聚合模块, 恢复成普通的3× 3卷积, 同时移除解码器中的背景分割注意力模块, 不考虑背景干扰, 从而得到基础模型BaseNet.然后, 将Base-Net和融入HFS Block的基础模型BaseNet_MFF在ShanghaiTech数据集上进行实验对比, 即从计数性能与模型参数量两方面分析网络优劣, 验证多尺度特征融合模块的有效性.
HFS Block的消融实验结果如表6所示.由表可见, BaseNet-MFF性能优于BaseNet, 同时参数量也远少于BaseNet.由此可知, 在BaseNet中融入HFS Block可提升多尺度特征的表达能力和计数性能, 同时有效减少参数量, 因此降低模型复杂度的思路是正确可行的.
| 表6 HFS Block的消融实验结果 Table 6 Ablation experiment results of HFS Block |
其次, 再将BaseNet和融入背景分割注意力模块的基础模型AntiBaseNet进行对比, 结果如表7所示.
| 表7 背景分割注意力模块的消融实验结果 Table 7 Ablation experiment results of B-Seg attention map |
由表7可见, 无论是在Part A数据集还是Part B数据集上, AntiBaseNet的MAE和MSE值都优于Base-Net.由此可知, 通过图像分割方法添加注意力, 指导生成更高质量的密度图、降低背景噪声干扰的思路是正确可行的.
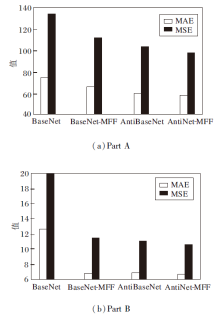
AntiNet-MFF相当是在BaseNet基础上, 同时添加HFS Block和背景分割注意力模块.BaseNet、BaseNet-MFF、AntiBaseNet、AntiNet-MFF的消融实验结果如图11所示.由图可知, 添加两个模块中的任意一个, 都会对性能产生积极影响, MAE和MSE值均会下降, 尤其是两个模块同时添加时, 性能达到最佳.
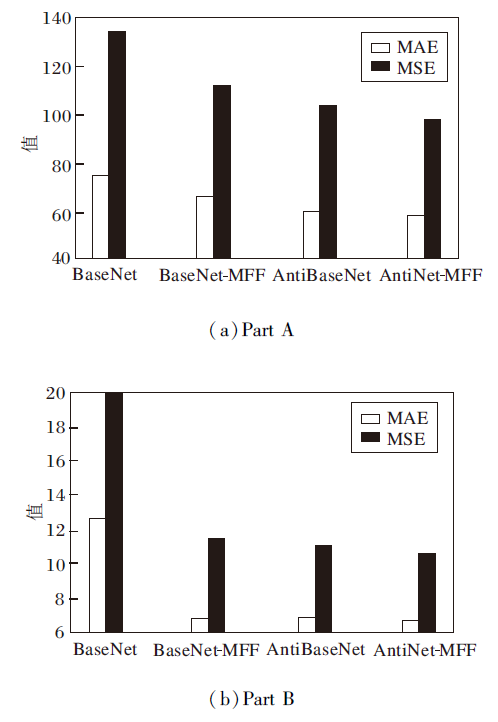 | 图11 各网络在ShanghaiTech数据集上的消融实验结果Fig.11 Ablation experiment results of different networks on ShanghaiTech dataset |
此外, 实验发现, 背景分割注意力模块的消融实验结果优于HFS Block, 说明抑制人群图像中的背景噪声至关重要.
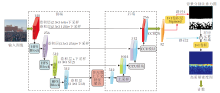
AntiNet-MFF的部分结果如图12所示.可视化图像全部选自ShanghaiTech数据集.由图可见, 背景分割注意力图可指示人群所在位置, 在它的指导下, 生成的密度图接近于真实密度图.
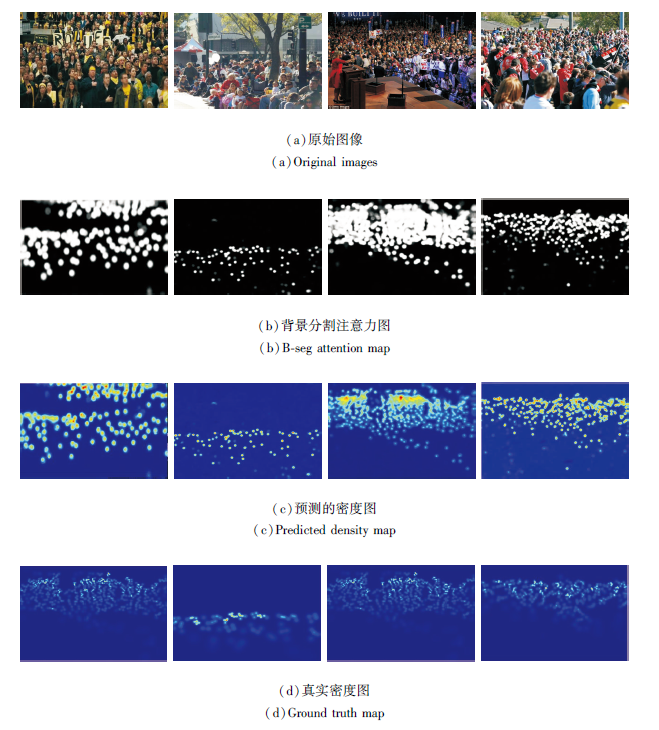 | 图12 AntiNet-MFF可视化结果Fig.12 Visualization results of AntiNet-MFF |
为了提高人群计数任务的准确性, 本文提出基于多尺度特征融合的抗背景干扰人群计数网络(AntiNet-MFF).首先, 在语义分割网络基础上, 在编码阶段融入多层次特征分割提取模块, 增强网络对多尺度特征的表达能力.其次, 在解码阶段, 在注意力的指导下生成背景分割注意力图, 起到对背景噪声的抑制作用.最后, 通过与特征图的融合, 生成更高质量的密度图.此外, 本文网络是一个端对端的网络, 可直接学习从原始图像到目标密度图的映射, 降低模型的复杂度和参数计算量.在典型的人群计数数据集上的实验表明, AntiNet-MFF可提高人群计数任务的准确性, 具有较好的鲁棒性和泛化能力.今后将考虑在人群高度密集、密度图严重重叠的情况下, 准确区分每个目标, 避免重复积分导致目标计数结果存在差异的问题, 从而进一步提升人群计数性能.
本文责任编委 叶东毅
Recommended by Associate Editor YE Dongyi
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|