{kind=link}
隐式知识图协同过滤模型
[薛峰1, 2  , 盛一城
, 盛一城3 , 刘康3 , 桑胜3 ]
, 盛一城, 刘康, 桑胜]
|
|



作者简介:

盛一城,硕士研究生,主要研究方向为推荐系统、数据挖掘.E-mail:yichengsheng@mail.hfut.edu.cn.

刘 康,博士研究生,主要研究方向为推荐系统、数据挖掘、多媒体分析.E-mail:kangliu1225@gmail.com.

桑 胜,博士研究生,主要研究方向为推荐系统、数据挖掘、多媒体分析.E-mail:ss.sang@qq.com.
目前,基于知识图谱的推荐方法利用图神经网络捕获用户偏好和知识实体之间的相关性,实现最优的推荐效果.但这种相关性建模方法依赖于节点(用户、物品或实体)之间的显式关系,具有一定的局限性.针对上述问题,文中提出隐式知识图协同过滤模型(Implicit Knowledge Graph Collaborative Filtering Model, IKGCF).首先,构建隐式协同知识图,一方面消除显式关系对推荐中隐式交互关系的干扰,另一方面解除显式关系对图谱中语义相关性的限制.然后,采用增强的图神经网络模块,执行邻居聚集和消息传播,更好地捕获隐式协同知识图上的高阶相关性.最后,采用层选择机制,得到最终的节点嵌入向量,并对模型进行预测和优化.在3个公开数据集上的实验表明,文中模型推荐效果较优.IKGCF的完整代码开源在
About Author:
SHENG Yicheng, master student. His research interests include recommendation system and data mining.
LIU Kang, Ph.D. candidate. His research interests include recommendation system, data mining and multimedia analysis.
SANG Sheng, Ph.D. candidate. His research interests include recommendation system, data mining and multimedia analysis.
In the existing recommendation methods based on knowledge graphs, graph neural networks are utilized to capture the correlation between user preferences and knowledge entities to achieve optimal recommendation results. However, certain limitations occur in this kind of relevance modeling methods due to its dependence on the explicit relationship between nodes(users, items or entities). To address these problems, an implicit knowledge graph collaborative filtering model(IKGCF) is proposed. Firstly, the implicit collaborative knowledge graph is constructed to eliminate the interference of explicit relationship on implicit interaction in recommendations and remove the limitation of explicit relationship on semantic relevance in the graph. Then, an enhanced graph neural network module is adopted to perform neighbor aggregation and message propagation to better capture the higher-order relevance on the implicit collaborative knowledge graph. Finally, a layer selection mechanism is employed to obtain the final node embedding vectors and predict and optimize the model. Experiments on three public datasets show that IKGCF achieves better performance. The full code of IKGCF is open-sourced at
近年来, 随着互联网技术的迅速发展, 推荐系统已广泛应用于各种在线服务中, 如电子商务、社交应用及新闻媒体等.推荐系统的主要目标是根据用户的历史行为推荐其可能感兴趣的物品.协同过滤[1, 2, 3]是使用最广泛的个性化推荐算法之一, 核心思想是:具有相似历史行为的用户会具有相似的兴趣和偏好, 因此在未来也会做出相似的选择.然而, 在真实的推荐场景中, 由于用户和物品的交互数据太少, 协同过滤算法常面临稀疏性问题.
为了缓解协同过滤算法面临的数据稀疏性问题, 一些研究工作[4, 5]将知识图谱作为附加信息, 融入推荐框架中, 丰富物品的特征表示.知识图谱是一种有向异构图, 由< 头实体-关系-尾实体> 三元组构成, 可用于描述真实世界中的实体与实体之间的关系.
基于知识图谱的推荐方法整体步骤可描述为:首先处理知识图谱, 得到其中每个节点的特征表示.再选择推荐框架, 将知识图谱提供的特征融入推荐框架.最后将交互数据输入融合后的推荐框架, 执行模型训练.不同方法的区别主要体现在知识图谱优化目标的选择、知识图谱特征表示和推荐框架的融合.
基于知识图谱的推荐方法可分为两类:基于正则化的方法[4, 6, 7, 8]和基于路径的方法[9, 10, 11, 12, 13].基于正则化的方法利用知识图谱中的三元组结构指导用户和物品的表示学习.具体地, 首先通过知识图嵌入技术[14], 为知识图谱中的节点生成语义向量表示, 然后将物品实体节点的语义向量融入推荐框架中, 将向量内积作为用户对目标物品的评分.尽管基于正则化的方法能实现较优的推荐效果, 但仅捕获知识图谱中一阶的实体关联, 方法对知识图谱的语义学习能力有限.
相比基于正则化的方法, 基于路径的方法可通过知识图谱中实体之间的路径捕获实体的高阶语义关联, 并融入用户的偏好建模中, 提升方法的推荐效果.然而, 在节点数量较多时, 路径的规模数量会很庞大, 导致模型复杂度过高, 知识图谱中的语义相关性难以得到有效传播.为了处理两个节点之间具有大量路径的问题, 一些研究工作会使用路径选择算法以选择最佳路径[10], 或定义元路径模式以约束路径[9].但是这种二阶段方法也存在如下问题:路径选择的第一阶段对最终性能影响较大, 并且没有针对推荐目标进行优化.此外, 定义有效的元路径需要领域知识, 对于具有不同类型关系和实体的复杂知识图谱而言, 相当耗费人力.
近来图神经网络[15, 16]被广泛应用于推荐算法研究中, 在图卷积神经网络(Graph Convolutional Net-works, GCN)中, 模型复杂度和路径长度呈线性关系[15], 因此, 利用GCN捕获知识图谱中高阶知识实体关系可有效解决上述两种方法存在的问题.受此启发, Wang等[17]提出KGAT(Knowledge Graph Atten-tion Network), 以线性时间复杂度捕获用户偏好和知识实体之间的高阶相关性, 并通过知识图表示学习建模节点(用户、物品或实体)之间的显式关系, 构建注意力机制, 区分邻居节点的重要性.尽管上述模型已取得较优的推荐效果, 但实体相关性建模依赖于节点之间的显式关系, 存在如下两点局限性.
1)在大部分推荐场景中, 用户和物品的交互是一种隐式反馈关系(如点击、查看), 它们在相关性建模中却被错误地等同于图谱中实体之间的显式关系, 这种做法会将用户向量和物品向量限制到只有一个特定显式关系的语义空间中, 实际上其语义空间应该是多种显式关系的总和, 这可能会降低用户偏好建模的质量.然而使用隐式关系对于用户向量和物品向量对应的语义空间限制更小, 可提升其嵌入向量学习的泛化能力.
2)图谱中确定的两个实体之间存在多种多样的关系, 但由于现有的数据集无法提供多样的关系, 只能提供实体之间单一的关系, 按照特定显式关系进行相关性建模时可能会将实体间的关系限制在一个具体的类别, 弱化学习的关系嵌入向量的表达泛化性, 降低实体之间的高阶语义相关性.
为了解决上述不足, 本文提出结合隐式知识图谱与图神经网络的推荐模型— — 隐式知识图协同过滤模型(Implicit Knowledge Graph Collaborative Filte-ring Model, IKGCF), 将带有显式关系的知识图谱转换成隐式的知识图谱, 并融入用户-物品二元图中, 得到隐式协同知识图.IKGCF不需要学习节点之间特定的显式关系, 一方面可消除显式关系对推荐中隐式关系的干扰, 另一方面可突破显式关系对图谱中语义相关性的限制, 使模型充分捕捉协同信号.同时, 使用增强的图神经网络模块[18, 19], 执行邻居聚集和消息传播, 更好地捕获在隐式协同知识图上的高阶相关性.最后, IKGCF采用层选择机制[20], 得到最终的节点嵌入向量, 并对模型进行预测和优化.在3个公开数据集上的实验验证IKGCF性能较优.
本文提出隐式知识图协同过滤模型(IKGCF), 具体流程如下.1)结合用户-物品二元图和隐式物品-实体知识图谱, 构建隐式协同知识图, 并根据用户、物品和实体的ID信息生成对应的嵌入向量, 输入模型; 2)在隐式协同知识图中采用增强的图神经网络, 分别聚合用户节点、物品节点和实体节点的邻居节点信息和它们自身节点信息, 使隐式协同知识图中各节点可捕获其高阶邻居信息, 建立节点之间的高阶连通性; 3)将输出的第3层和第4层图卷积过程输出的嵌入向量作为用户节点和物品节点的最终嵌入向量, 采用层选择机制同时预测用户和物品交互的可能性大小.
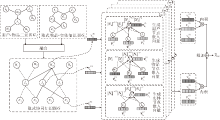
图1为IKGCF框架图, 在图中, uk表示用户节点, ik表示物品节点, ek表示实体节点.IKGCF包含3个主要部分.1)嵌入层.基于隐式协同知识图中的用户节点、物品节点、实体节点的ID信息生成对应的嵌入向量.2)基于隐式关系的嵌入传播层.IKGCF采用增强的图神经网络模块执行邻居聚集和消息传播.3)模型预测层.输出用户对物品的预测得分.
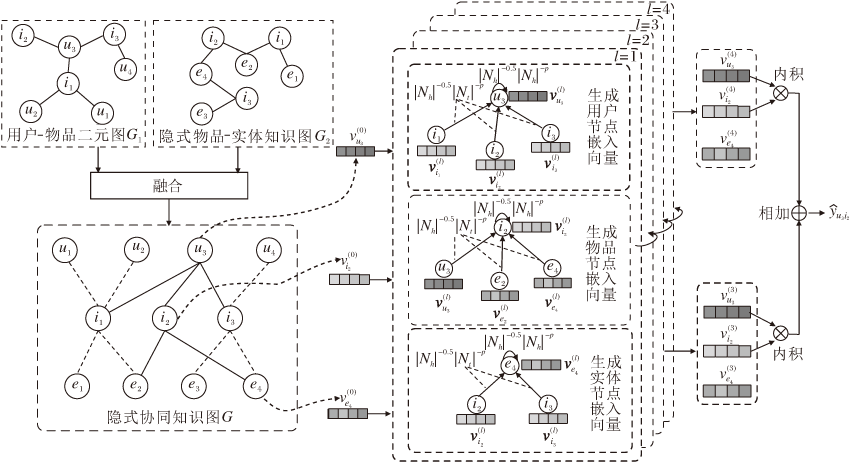 | 图1 IKGCF结构图Fig.1 Structure of IKGCF |
根据隐式的用户-物品历史交互数据可构建用户-物品二元图:
其中:
其中:
其中,
隐式协同知识图谱可用于整合用户-物品二元图G1 和物品-实体隐式图谱G2, 因此将物品-实体对作为一种辅助信息融入用户-物品二元图中, 得到隐式协同知识图:
其中, 头实体和尾实体可以是用户节点、物品节点或实体节点, 同样地, rui=1仅表示头实体h与尾实体t之间有关系, 否则rht=0.
首先随机初始化所有用户、物品和实体的嵌入向量, 由于本文正在处理的协同过滤场景输入数据只有用户ID、物品ID和实体ID, 不包含任何其它信息, 因此嵌入向量的初始化只能通过简单的ID映射实现, 具体过程描述如下:
其中,
隐式协同知识图中存在一系列三元组, IKGCF采用增强的图神经网络模块聚合头实体h及邻居节点(尾实体t)的信息, 然后不断循环这个过程, 更新头实体h的嵌入向量, 捕获隐式协同知识图中节点之间的高阶相关性.
1.3.1 节点消息传播
用户-物品二元图中包含大量的三元组, 物品-实体隐式知识图谱中也包含大量的三元组, 物品节点作为其中的桥梁连接两组三元组, 并在构成的隐式协同知识图中传播信息.在一阶传播过程中, 汇聚头实体h的邻居节点信息, 得到嵌入向量:
其中, Nh表示头实体h邻居节点的集合, Nt表示尾实体t邻居节点的集合, |Nh|表示头实体h邻居节点的数量, |Nt|表示尾实体t邻居节点的数量, p表示控制流行度的系数, et表示尾实体t的嵌入向量.
1.3.2 节点信息聚合
对于每个头节点h, 不仅要从它邻居节点的角度考虑其嵌入向量的更新, 还要从节点自身的角度及其本身的特性考虑嵌入向量的更新.在一阶传播过程中, 头实体h聚集节点自身信息得到的嵌入向量:
eh← h=|Nh|-0.5|Nh|-peh,
其中, eh表示头实体h的嵌入向量,
通过上述过程可得到头实体h的邻居节点信息eh← t 和包含节点自身信息的eh← h, IKGCF采用轻量级的图卷积聚合方式编码eh← t和eh← h之间的特征交互.轻量级的图卷积方法去除非线性激活函数与权重转换矩阵, 减少在节点的嵌入传播过程中引入过多的冗余信息, 最终生成头实体h的嵌入向量:
总之, 上述嵌入传播过程有效利用隐式协同知识图中的一阶连通性信息, 使用户节点、物品节点和实体节点都包含自身和邻居节点的信息.
1.3.3 高阶传播
下面探寻如何叠加更多的嵌入传播层以捕获隐式协同知识图中的高阶相关性, 即如何将头实体h的高阶邻居节点信息也聚集到头实体h中.在第l层嵌入传播过程中, 头实体h的嵌入向量为:
在图卷积的第l-1层中, 包含头实体h的邻居节点信息的嵌入向量
其中,
至此通过上述多层嵌入传播的过程, IKGCF可捕获隐式协同知识图上的高阶相关性, 将基于属性的协同信号引入隐式推荐模型之中, 提升推荐效果.
对于给定的用户-物品对, IKGCF经过L层的高阶传播后, 会获取用户u的每层向量的输出表示:
同理也可获取物品i的每层向量的输出表示:
不同层数输出的向量强调不同层次的语义连通信息.IKGCF使用
其中f(· )表示内积函数.
IKGCF采用层选择机制, 即同时利用最后两层输出的用户嵌入向量和物品嵌入向量预测用户和物品交互的概率, 预测函数如下:
本文采用联合学习的目标函数优化IKGCF, 即
LIKGCF=LCF+LKG+λ ‖ θ
其中:LCF和LKG采用推荐领域中常用的BPR loss
(Bayesian Personalized Ranking Loss), 这是一个成对损失函数, 旨在最大化观察到的样本与未观察到的样本的得分之差, 通过小批量梯度下降的方法交替优化LKG和LCF; θ 表示所有可学习的参数, λ 表示正则化系数.LCF、LKG具体定义如下:
LCF=
其中,
Y={(u, i, j)|(u, i)∈ Y+, (u, j)∈ Y-},
表示用户-物品交互数据的训练集, Y+表示正样本, 即用户u和物品i之间是有交互的样本, Y-表示负样本, 即用户u和物品j之间无交互的样本, σ (· )表示sigmoid激活函数.
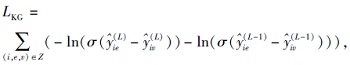
其中,
Z={(i, e, v)|(i, e)∈ Z+, (i, v)∈ Z-},
表示物品-实体隐式知识图谱的训练集, Z+表示正样本, 即物品i和实体e之间是有交互的样本, Z-表示负样本, 即物品i和实体v之间无交互的样本.
本文选取Amazon-book, Last-FM、Yelp2018数据集进行实验, 这3个数据集都可公开获取.Amazon-book数据集为广泛应用在商品推荐上的数据集, 为了保证数据集的质量, 本文采用10-core策略, 即保留用户和物品之间至少有10次交互记录.Last-FM数据集为音乐数据集, 数据来源于在线音乐系统Last.FM, 本文同样也使用10-core策略, 确保在数据集上用户和物品之间至少有10次交互记录.Yelp-2018数据集为一家大型点评网站数据集, 同样地, 本文也在该数据集上采用10-core策略.
这3个数据集除了包含用户-物品交互数据以外, 还包含文献[21]中整理并公开的物品知识图谱, 以三元组的形式表示一对实体及它们之间的关联.表1详细给出3个数据集的统计结果.
| 表1 实验数据集 Table 1 Experimental datasets |
在每个数据集上, 本文随机选择每位用户80%交互历史以构建训练集, 剩余的20%交互历史作为测试集, 另外从训练集中随机选择10%的交互作为验证集以调整超参数, 在Last-FM、Yelp2018数据集上, 学习率调整为0.001, L2正则化系数调整为10-4, 流行度偏置系数调整为0.4, 此时实验效果最佳.在Amazon-book数据集上, 学习率调整为0.000 1, L2正则化系数调整为10-5, 流行度偏置系数调整为0.3, 此时实验效果最佳.由于本文是基于BPR loss训练模型, 针对训练集上每位用户, 都为其随机采样与交互历史数量相同的负样本.
为了评估IKGCF的推荐效果, 采用推荐系统中常用的2个评价指标:召回率(Recall)和归一化折损累计增益(Normalized Discounted Cumulative Gain, NDCG).Recall@K表示测试集上所有正样本被正确预测的比例(推荐列表取前K个, 记为Recall@K, 其它位置同理, 本文默认设置K=20).NDCG@K额外考虑正样本在推荐列表中的位置, 为正样本排序靠前的结果给予更高的分数.两种指标的值越高, 表示推荐模型的效果越优, 理论上最佳结果均为1.
为了验证IKGCF的有效性, 选择如下对比模型.
1)监督学习模型:FM(Factorization Machines)[21]、NFM(Neural MF)[22].
2)基于正则化的方法:CKE(Explainable Colla-borative Knowledge Base Embedding)[4]、ECFKG(Colla-borative Filtering over Knowledge Graphs)[5].
3)图神经网络方法:KGAT[17].
具体模型介绍如下.
1)FM.因式分解模型, 将用户和物品及与物品关联的实体ID信息视为输入特征, 考虑输入特征之间的二阶特征交互.
2)NFM.因式分解模型, 结合FM与神经网络.
3)CKE.典型的借助图嵌入技术的知识图谱推荐模型, 从结构、文本、视觉三个层面获得包含知识的初始嵌入向量, 用于增强传统矩阵分解模型随机初始化的物品隐向量.
4)ECFKG.将知识图表示学习技术应用在包含用户、物品、实体和关系的统一图上, 将推荐任务转换为(u, Interact, i)三元组的预测任务, 其中Interact表示用户与物品的交互.
5)KGAT.基于图卷积的模型, 以端到端的方式建模知识图谱中的高阶连接, 循环传播来自节点邻居的嵌入向量, 细化目标节点的嵌入向量, 并采用一种注意力机制区分邻居节点的重要性.
本文使用Tensorflow实现IKGCF, 所有模型的输入向量长度固定为64, 使用Adam(Adaptive Mo-ment Estimation)优化器优化所有模型, 其中批处理大小(Batchsize)固定为1 024.本文使用默认的Xavier初始化器用于初始化模型参数, 在超参数的设置上采用网格搜索:学习率在{0.01, 0.001, 0.000 1}之间调整, L2标准化系数在{10-5, 10-4}之间调整, 流行度偏置系数在{0.3, 0.4, 0.5}之间调整.在模型的预测阶段, 均采用层选择机制, 同时选取最后两层输出向量对模型进行预测和优化.
各模型在3个数据集上的性能对比如表2所示, 其中, Improve表示本文模型相比KGAT的增长比例, P-value表示本文模型相比KGAT通过显著性检验方法得到的值, 显著性水平为0.05, 黑体数字表示最优值.
| 表2 各模型在3个数据集上的性能对比 Table 2 Performance comparison of different models on 3 datasets |
由表2可观察到, 两个不使用知识图谱的模型(FM和NFM)在大多数情况下表现优于使用知识图谱的模型(ECFKG和CKE), 这是因为FM和NFM的交叉特性实际上充当用户和物品之间的二阶连通性, 因此在某种程度上可捕获更充分的协同信号.而基于正则化的方法(ECFKG和CKE)仅捕获知识图谱中一阶的实体关联, 对知识图谱的语义学习能力有限.此外, 知识图表示学习方法通常适用于知识图谱的补全任务, 而不适用于推荐任务.
在这3个数据集上KGAT的表现优于FM和NFM, 这是因为:KGAT不仅利用知识图谱丰富物品节点的向量表示, 同时挖掘协同知识图中的高阶连通信息, 用于丰富用户和物品节点的向量表示, 从而提高模型的推荐效果.
IKGCF在所有的数据集上均取得最优值, 并且所有指标都显著高于KGAT(P-value值小于0.05).尤其在Yelp2018数据集上模型性能差异显著(P-value值小于0.01), 相比KGAT, IKGCF性能提升明显, 在NDCG指标上的提升高达15.67%, 在Recall指标上的提升高达13.79%, 这是因为IKGCF通过构建隐式协同知识图谱, 消除显式关系对推荐中隐式交互关系的干扰, 解除显式关系对图谱中语义相关性的限制, 取得更优的推荐效果.在Amazon-Book数据集上, IKGCF提升幅度过小, Recall指标只提升1.07%, NDCG指标提升1.43%, 这主要与Amazon-Book数据集本身有关, 其知识图谱中实体间的关系较单一, 对显式关系进行相关性建模并不会将实体之间的关系限制在一个类别内, 导致性能提升较小.
为了验证IKGCF中层选择机制、流行度偏置及隐式协同知识图谱的有效性, 本节将IKGCF与5个变体模型进行对比.具体变体模型定义如下:IKGCF w/o PN表示移除IKGCF中的流行度偏置; IKGCF w/o LS表示移除IKGCF中的层选择机制, 仅采用第4层的输出向量对模型进行预测和优化; IKGCF w/o LS* 表示移除IKGCF中的层选择机制, 采用层平均机制对模型进行预测和优化; IKGCF w/o PN& LS表示同时移除IKGCF中的流行度偏置和层选择机制; IKGCF w/o BS表示移除联合的损失函数, 仅在用户-物品交互图上为用户和物品节点设置对应的BPR loss, 去除在隐式知识图上为物品和知识实体设置对应的BPR loss.
各模型的消融实验结果如表3所示, 其中黑体数字表示最优值.由表3可知, IKGCF w/o LS的性能在大部分情况下都优于IKGCF w/o LS* , 这是因为在轻量级图卷积模块中, 图卷积的第4层输出向量已包含前3层输出向量的全部语义信息, 即更高层输出的嵌入向量具有更大的交互空间, 低层的嵌入向量不需要参与生成节点的最终向量表示.
| 表3 各模型的消融实验结果 Table 3 Ablation experiment results of different models |
IKGCF的性能在3个数据集上都优于IKGCF w/o PN、IKGCF w/o LS、IKGCF w/o LS* 和IKGCF w/o BS, 这是因为:1)层选择机制的使用增强模型的表现力, 即最优的图卷积层需要充分捕获两层语义信息(分别表示目标节点的同构节点和异构节点的语义信息), 这两层语义信息包含不同的交互空间大小, 因此选择最优的奇数层和偶数层可确保这两种语义信息的交互空间是足够的.2)流行度偏置也会提升模型的性能, 增强推荐效果.3)联合的BPR loss有助于提升模型性能, 联合学习这两个不同的优化目标可保证IKGCF更充分地建模用户-物品-实体之间的隐式相关性.
在更多的推荐场景下, 知识图谱中实体之间的关系总是复杂多样的(如Yelp2018、Last-FM数据集), 而IKGCF w/o PN& LS在这些场景下的推荐性能总是显著优于KGAT, 因此隐式关系建模比显式关系建模更有效且具备更强的适用性.
值得注意的是, IKGCF w/o PN& LS在Amazon-Book数据集上的表现略弱于KGAT, 这可能是因为相比Last-FM、Yelp2018数据集, Amazon-Book数据集上知识图谱实体间的关系更单一, 这意味着传统方法(如KGAT)采用的显式关系建模不会过度限制其多样性, 即实体之间的关系不会限制在一个类别中.
本节改变IKGCF的图卷积层数, 研究使用多层嵌入对推荐效果的影响.实验中控制流行度偏置系数, 将p值统一设为0.4, 在3个数据集上进行实验.不同卷积层数对IKGCF性能的影响如表4所示, 表中IKGCF-(1, 2)表示模型拥有两层卷积层, 并且同时使用第1层和第2层的输出向量进行预测, 其它的符号与其同理, 黑体数字表示最优值.
| 表4 不同卷积层数对IKGCF性能的影响 Table 4 Effect of different number of convolution layers on IKGCF performance |
由表4可见, IKGCF-(2, 3)和IKGCF-(3, 4)的推荐效果在3个数据集上都远优于IKGCF-(1, 2), 这表明增加模型的卷积层数可提升模型性能, 这种效果的提升可归结为多层嵌入传播为模型注入更多的高阶连通性信息.
相比IKGCF-(2, 3), IKGCF-(3, 4)的提升幅度变小, 这表明考虑到实体之间的四阶关系就已足够捕捉隐式协同知识图中的协同信号, 过多的图卷积层数并不能有效提升推荐效果.
除了图卷积的层数以外, 还有一些超参数会对模型性能产生影响.下面研究模型的流行度偏置PN, 定义PN=0.3, 0.4, 0.5, 并测试不同PN对IKGCF性能的影响.结果如表5所示, 表中黑体数字表示最优值, 模型使用第3层和第4层的输出向量同时预测得分.
| 表5 不同流行度偏置系数对IKGCF性能的影响 Table 5 Effect of different popularity bias factors on IKGCF performance |
由表5可见, 引入流行度偏置系数后, IKGCF性能具有显著提升, 并且在不同的数据集上, 最佳性能对应的流行度偏置不同.这表明流行特征在建模用户偏好中起到重要作用, 并证实用户偏好在流行特征中表现差异.此外, 结合流行特性可显著提高IKGCF在Yelp2018、Amazon Book数据集上的性能, 这可能是因为这两种场景中的用户对流行特性更敏感.
本文提出隐式知识图协同过滤模型(IKGCF), 构建隐式协同知识图, 一方面消除显式关系对推荐中隐式交互关系的干扰, 另一方面解除显式关系对图谱中语义相关性的限制.此外, 采用增强的图神经网络模块, 更好地捕获在隐式协同知识图上的高阶相关性.在3个公开数据集上的实验结果表明IKGCF具有出色的性能.在推荐系统任务中, 隐式协同知识图谱还有更大的利用价值, 节点之间存在丰富、隐含的关系.今后将着力研究如何进一步挖掘节点之间隐含的关系, 提高节点之间的语义相关性, 提升推荐效果.
本文责任编委 林鸿飞
Recommended by Associate Editor LIN Hongfei
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|