
{kind=link}
{kind=link}
网络决策形式背景下基于因果力的邻域推荐算法
[范敏1, 2  , 郭瑞欣
, 郭瑞欣1, 2 , 李金海1, 2 ]
, 郭瑞欣, 李金海]
|
|



作者简介:
范 敏,博士,副教授,主要研究方向为数据挖掘、粗糙集、粒计算、社会网络分析.E-mail:fmkmust@163.com.

郭瑞欣,硕士研究生, 主要研究方向为数据挖掘、社会网络分析.E-mail:1905248675@qq.com.
网络数据下的概念认知与知识发现是网络数据分析领域的热门研究方向,已应用于推荐系统领域,但是如何构建合理的弱概念集以提高邻域推荐效果仍是一个难题.为了解决该问题,文中提出变精度弱概念集,诱导出包含较多信息量的邻域,在此基础上提出基于因果力的邻域推荐算法.首先,定义相似性网络聚合中心度,确定专家节点,得到变精度弱概念集,进行邻域划分.然后,在每个邻域中利用变精度共有算子得到对象的条件属性弱概念和对象的决策属性弱概念,通过因果力代换原理和相关推论给出邻域推荐算法.在MovieLens、Filmtrust数据集上的对比实验表明,文中算法在精确度、召回率、 F1值和运行时间上均有明显提升.
About Author:
FAN Min, Ph.D., associate professor. Her research interests include data mining, rough set, granular computing and social network analysis.
GUO Ruixin, master student. Her research interests include data mining and social network analysis.
Concept cognition and knowledge discovery under network data are hot research directions in the field of network data analysis, and they are applied in the field of recommendation system. However, how to construct a reasonable set of weaken-concepts to improve the effectiveness of neighborhood recommendation is still a difficult problem. To solve this problem, a set of variable precision weaken-concepts is proposed to induce neighborhoods with more information, and then a neighborhood recommendation algorithm is developed based on causality force. Firstly, the aggregation centrality degree of similarity network is defined to determine expert nodes, and a set of variable precision weaken-concepts is obtained to divide neighborhoods. Secondly, the variable precision common operators are employed in each neighborhood to obtain the weaken-concepts of conditional attributes and decision attributes of objects. Finally, a neighborhood recommendation algorithm is given based on the principle of causality force and related properties. Experimental results on MovieLens and Filmtrust datasets show that the accuracy, recall, F1 and running time of the proposed algorithm are greatly improved.
早期形式概念分析(Formal Concept Analysis, FCA)[1]专注于研究概念及概念层次的数学化和形式化表达.随着FCA的快速发展, 与各领域的交叉研究日渐深入, 现已广泛应用于软件工程[2, 3]、数据挖掘[4, 5, 6]、推荐系统[7]等具有广阔应用前景的领域.
基于形式背景的概念认知是一个新兴的研究领域, 主要以形式概念分析、粗糙集及粒计算等理论为工具.在大数据环境下, 概念认知学习具有诸多认知优势, 学者们对其进行一系列的研究[8, 9, 10].在概念认知学习中, 基于各种算子的研究得到不同的概念[11].Dü ntsch等[12]给出近似算子— — 必要算子和可能算子, 研究面向属性概念格.Yao[13]研究面向对象概念格和面向属性概念格, 以及它们之间的关系.闫梦宇等[14]基于Wille概念格、面向对象概念格和面向属性概念格, 定义共有属性(对象)与独有属性(对象), 并研究它们的算子性质.将上述算子结合变精度思想可得到各种变精度算子, 进一步与实际应用结合, 有利于丰富概念认知理论与应用的研究.如何将概念认知学习方法与网络中的因果推断、规则提取结合, 是一个有意义的课题.
目前, 常见的推荐系统包括以下几种:Zaier等[15]提出的基于邻域的推荐系统, 主要是通过计算相似度找到相关邻域, 根据邻域信息进行推荐; Garcia等[16]提出的组推荐系统(Group Recommender System), 推荐对象为整个群组.基于邻域的推荐方法常见于协同过滤推荐系统中, 主要分为基于用户的协同过滤推荐[17]和基于项目的协同过滤推荐[18].前者是根据用户之间的相似度进行推荐, 后者是根据项目之间的相似度进行推荐.组推荐系统通过研究所有邻域成员偏好之间的关联性得到邻域偏好, 最后利用邻域偏好进行推荐[19].
由上述研究可知, 基于邻域的推荐算法需要解决两个问题:1)如何得到相关邻域, 并使这些邻域中能涌现足够多的规律; 2)如何根据每个邻域信息得到邻域偏好之间的关联性, 构建推荐算法.
Pearl[20]在《Causality》中指出:因果关系不应被视为单一关系, 而应被视为具有两个维度— — 充分性和必要性.该书结合概率论的相关知识, 给出充分性与必要性的定义, 为研究因果力奠定基础.之后Pearl又深入研究当代的因果分析方法, 将因果科学从一个模糊的概念变成一个可以量化的理论, 并广泛应用于数理统计[21]、人工智能[22, 23]、认知科学[24, 25]等领域.
之后, 学者们重新定义因果力的衡量标准[26], 并将PNS=suff(e|c)+nec(e|c)-1作为度量因果关系的新标准.Hoel等[27]提出使用一般的因果关系度量有效信息以衡量因果有效性, 并在文献[28]中列举十几种较通用的因果力测量方法.学者们结合各种因果力的研究与规则挖掘, 得到更有效的规则挖掘算法, 进一步应用于推荐系统[29, 30, 31].
当前, 基于概念格的推荐方法已取得如下研究成果:基于概念邻域的Top-N推荐[7]、启发式构造概念格进行推荐[32]、基于RSS(Really Simple Syndi-cation)的电子学习推荐[33]、模拟退火法构造概念集进行推荐[34]、PRS(Personalized Recommendation System)[35]、形式概念分析和协同过滤推荐结合[36].然而概念格构造效率太低, 几乎与形式背景的规模增长呈指数关系[37, 38, 39], 使基于经典概念集的社区划分在实际数据中难以实现.
为了解决在进行组推荐时应用概念格划分社区出现的高复杂度问题, 范敏等[40]提出基于弱概念相似度的组推荐算法(Group Recommendation Algori-thm Based on Weaken-Concept Similarity, GRAWS), 通过* 算子诱导的弱概念集划分论域形成社区, 并在划分社区时计算属性弱概念下限相似度, 以此进行组推荐, 降低划分社区的计算复杂度, 同时提高推荐效果.但是, * 算子的约束条件过于严格, 诱导的弱概念集频繁出现空集, 因此无法保证获得足够多的弱概念, 导致诱导的规则集应用于组推荐效果不佳.
针对上述问题, 本文将对象之间的完全包含关系弱化成部分包含关系, 在网络决策形式背景下定义
定义1[1] 三元组(U, A, I)称为形式背景, 其中, U={x1, x1, …, xn}为非空有限对象集, A={a1, a2, …, am}为非空有限属性集, I为笛卡尔积U× A上的二元关系.约定(x, a)∈ I表示对象x拥有属性a; (x, a)∉I表示对象x不拥有属性a.
为了从形式背景中诱导出概念, 给出如下算子的定义.对于∀ X∈ 2U, B∈ 2A, 有
1)xI={a∈ A|(x, a)∈ I},
2)Ia={x∈ U|(x, a)∈ I},
3)X* ={a∈ A|∀ x∈ X, (x, a)∈ I},
4)B* ={x∈ U|∀ a∈ B, (x, a)∈ I},
其中, xI表示对象x拥有的所有属性组成的集合, Ia表示拥有属性a的所有对象组成的集合, X* 表示X中所有对象共同拥有的属性, B* 表示拥有B中所有属性的对象.
定义2 五元组(U, M, C, D, I)称为网络决策形式背景, 其中:U={x1, x1, …, xn}为非空有限节点集; M={M1, M2, …, Mn}为网络邻接矩阵集, Ml=
例1 已知评分矩阵Q(见表1), 由定义2结合用户矩阵, 可得到网络决策形式背景(见表2).
| 表2 网络决策形式背景(U, M, C, D, I) Table 2 Network formal decision context(U, M, C, D, I) |
表1给出的评分矩阵Q描述用户xi对项目aj的评分情况.v(x1, a1)=4表示用户x1对项目a1的评分为4, v(x1, a2)=0表示用户x1没有对项目a2做出评分.表2描述用户之间的连接关系和用户对项目的拥有情况.
在表1中, 首先, 采用
WR(ak)=(
对项目评分进行修正(https://blog.csdn.net/Joenyye/article/details/80902717), 其中,
其次, 根据修正后的评分进行条件属性集C={c1, c2, …, cr}与决策属性集D={d1, d2, …, dt}的划分, 选取修正评分的中位数Md作为划分属性集的阈值, 评分大于等于Md的属性作为条件属性集C, 评分小于Md的属性作为决策属性集D.若v(xi, ci)> 0, 则在表2中IC(xi, ci)=1表示用户xi拥有项目ci.同理, 若v(xi, ct)=0, 则在表2中IC(xi, ct)=0表示用户xi不拥有项目ct.若v(xi, dj)> 0, 则在表2中ID(xi, dj)=1表示用户xi拥有项目dj.同理, 若v(xi, ds)=0, 则在表2中ID(xi, ds)=0表示用户xi不拥有项目ds.
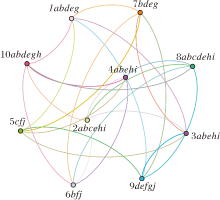
例2 已知一个电影推荐网络图(见图1), 根据该网络图可得到它对应的网络决策形式背景(见表3), 其中, U={x1, x1, …, x10}表示观看电影的10位对象, C={a, b, c, d, e, f}表示6部顶级热门电影, D={g, h, i, j}表示4部较热门电影.M1=
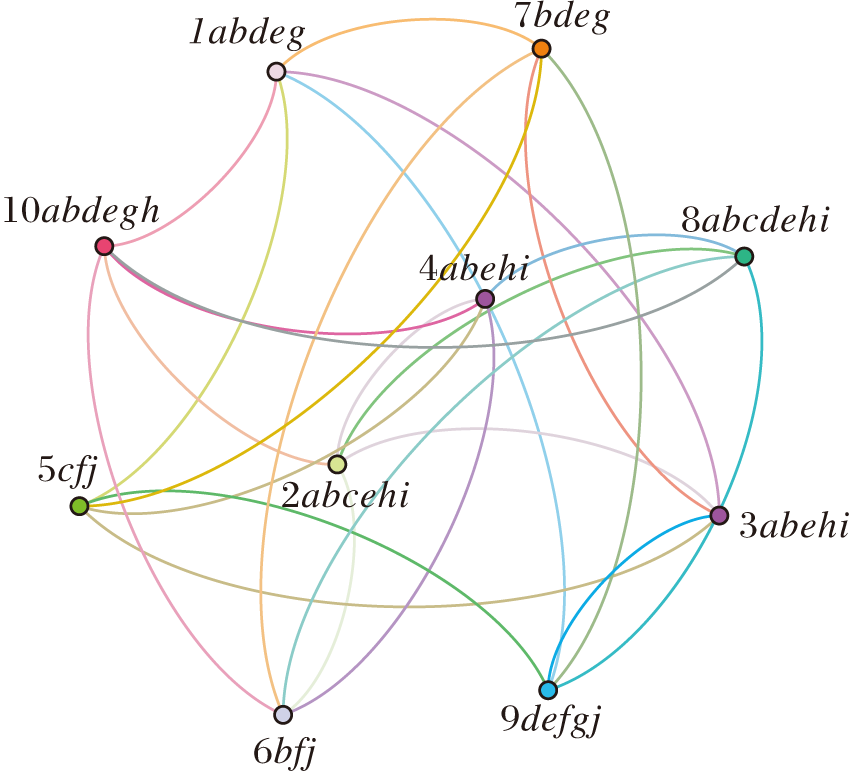 | 图1 电影推荐网络图Fig.1 Movie recommendation network |
| 表3 图1对应的网络决策形式背景(U, M, C, D, I) Table 3 Network formal decision context(U, M, C, D, I) of Fig.1 |
本文将主要解决如下两个问题:1)通过变精度弱概念划分论域, 构建社区; 2)利用因果力代换实现邻域推荐.
文献[40]通过构建弱概念集进行组推荐时, 需满足约束条件:1)得到的弱概念集要覆盖形式背景的所有对象, 即保证每个对象都至少属于一个弱概念; 2)挖掘的弱概念内涵的规模必须大于预设阈值.由于* 算子约束条件较严格, 诱导出的对象弱概念或属性弱概念组成的集合频繁出现空集, 因此, 按上述方式构建弱概念集可能出现无法找到足够多的弱概念满足上述约束条件的现象.
为了避免出现上述情况, 本文将对象之间的完全包含关系弱化成部分包含关系, 在网络决策形式背景下定义
定义3 对于评分矩阵Q,
Vi={v(xi, ap), ∀ ap∈ A}
为用户xi对项目集的评分,
Vj={v(xj, ap), ∀ ap∈ A}
为用户xj对项目集的评分, 则用户间的相似矩阵
S=(s(i, j))n× n,
其中
s(i, j)=
由定义2和定义3可将相似矩阵S转换为网络邻接矩阵M.
定义 4 给定网络决策形式背景(U, M, C, D, I), 则节点xi的相似性聚合中心度定义为
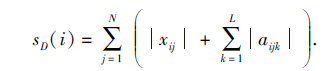
其中:当节点xj和节点xi一阶邻接时有|xij|=1, 此时,
定义5 给定一个网络决策形式背景(U, M, C, D, I), 对∀ X∈ 2U, C∈ 2C, D∈ 2D, 变精度共有算子定义如下:
1)
2)
3)
4)
例3 在例2的电影推荐网络中, C为顶级热门电影集, D为较热门电影集,
性质1 设(U, M, C, D, I)为一个网络决策形式背景, 对∀ X∈ 2U, C∈ 2C, D∈ 2D, 下述结论成立:
1)α 1> α 2⇒
2)β 1> β 2⇒
证明 先证1).对∀ X∈ 2U, 由定义5可得
对于∀ ci∈
故ci∈
再证2).对∀ C∈ 2C, 由定义5可得
对于∀ xi∈
故xi∈
定义6 给定网络决策形式背景(U, M, C, D, I), 称(X,
在上述定义1~定义6的基础上提出问题1, 描述如下.
问题1 通过变精度弱概念划分论域U
输入 网络决策形式背景(U, M, C, D, I)
输出 划分集CS
优化目标 min(|CS|)
约束条件1
约束条件2 ∀ (Xi,
|
其中
CS={(Xi,
优化目标表示最小化社区数量, 用于提高模型的拟合能力.约束条件1表示变精度弱概念集覆盖论域U中所有对象, 即每个对象至少划分在一个邻域(社区)中.约束条件2表示挖掘的变精度条件弱概念内涵规模不小于ω 1, 变精度决策弱概念内涵规模不小于ω 2, 即只有当用户拥有的项目足够多时, 形成的邻域(社区)才有意义.下面进一步研究邻域推荐算法.
本节首先给出推荐规则、规则置信度与规则因果力的概念.
定义7 推荐规则r(ci, dj)表示向拥有条件属性ci的对象推荐决策属性dj, 即r(ci, dj):ci→ dj.
定义8 对于规则r(ci, dj):ci→ dj, 称
μ ij=
为规则r(ci, dj)的置信度.
定义9 设规则r(dj, ci):dj→ ci为规则r(ci, dj):ci→ dj的反规则, 称
μ ji=
为反规则r(dj, ci)的置信度.
Pearl[20]在《Causality》中定义必要性概率:
nec(e|c)=P(~e|~c),
即反事实概率.也就是如果原因c没有发生, 结果e就不会发生的概率.定义充分性概率
suff(e|c)=P(e|c),
即原因c导致结果e发生的概率.并且, 给出衡量因果力的标准:
PNS=nec(e|c)+suff(e|c)-1.
Eells[29]从另外一个角度提出, c是e的原因需满足
p(e|c)> p(e|C-c),
其中C为原因集.并且可用这两个量之间的差衡量因果强度:
SCEells=p(e|c)-p(e|C-c)=suff(e|c)+nec(e|c)-1.
下面基于文献[20]、文献[29]和定义7~定义9, 研究因果关系充分性和必要性与定义8、定义9中规则置信度的关系, 并给出ci和dj之间因果力的定义.
定义10 对于规则r(ci, dj):ci→ dj, 充分性
suff(dj, ci)=
特别地, 若
P(dj|ci)=1,
表示ci的发生必然导致dj发生, 也可理解为规则r(ci, dj):dj→ ci的置信度为1.
定义11 对于规则r(ci, dj):ci→ dj, 必要性
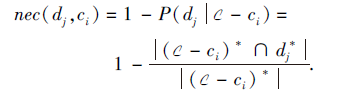
特别地, 若
1-P(dj|C-ci)=1,
则
P(dj|C-ci)=0,
即在C中删除ci之后, dj不发生, 表示ci的发生对dj的发生是必要的.
定理1 对于反向规则
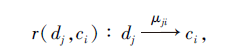
有如下结论成立:
μ ji=1⇔ P(dj|C-ci)=0.
证明 先证充分性.若
μ ji=P(ci|dj)=
即
从而有
即
故
P(dj|C-ci)=0.
必要性显然成立.
推论1 对于反向规则
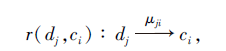
有如下结论成立:
μ ji=P(ci|dj)=1⇔ nec(dj, ci)=1.
由定理1和推论1可知, 若P(ci|dj)=1, 表示ci的发生对dj的发生是必要的.也可理解为规则r(dj, ci)的置信度μ ji=1, 反之亦然.
定理2 对于反向规则
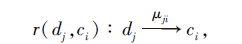
置信度μ ji与nec(dj, ci)呈正相关关系.
证明 假设
μ ji=P(ci|dj)=
从而
P(~ci|dj)=1-P(ci|dj)=1-β ,
进一步得
又因为
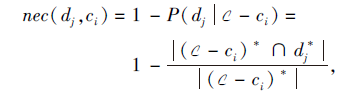
所以
nec(dj, ci)=1-
故置信度μ ji与nec(dj, ci)呈正相关关系.
根据上述研究并结合文献[20]中因果力的定义, 可得到如下因果力的定义.
定义12 对于规则
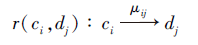
及其反规则
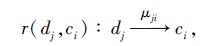
ci和dj之间的因果力定义为
CP=μ ij+μ ji-1.
显然CP∈ [-1, 1].
文献[39]指出, 当SCEells< 0时, 不能说明c是e的原因, 即:当CP< 0时, 不能说明ci是dj的原因; 反之, 当CP≥ 0时, 要么ci是dj的原因, 要么dj是ci的原因, 要么ci和dj互为因果.
下面讨论ci和dj互为因果的情形.假设当μ ij≥ ξ 时, ci是dj的原因, 即ci→ dj成立.同理, 当μ ji≥ ξ 时, dj是ci的原因, 即dj→ ci成立.同时满足μ ij+μ ji≥ 1, 于是有
从而2ξ ≥ 1, 进一步得到ξ ≥ 0.5.
因此, 根据上述研究可得到如下推论2.
推论2 若μ ij≥ 0.5, 有ci→ dj成立, 否则有ci→ ¬ dj成立.同理, 若μ ji≥ 0.5, 有dj→ ci成立, 否则有dj→ ¬ ci成立.
在问题1输出划分集CS的基础上结合上述定理和推论, 进一步可研究如下问题2.
问题2 基于因果力代换的邻域推荐
输入CS, 置信度阈值η 、δ
输出 推荐规则r(ci, dj)
优化目标 max(F1)
约束条件 对∀ ci∈
1)若μ ij≥ η , 则向拥有属性ci的对象推荐属性dj,
2)若μ ji≥ δ , 则向拥有属性dj的对象推荐属性ci.
其中, 优化目标是最大化综合评价指标F1, 用于提高模型的质量.约束条件表示在社区Xi中, 若μ ij≥ η , 则将属性dj推荐给社区Xi中拥有属性ci的节点; 若μ ji≥ δ , 则将属性ci推荐给社区Xi中拥有属性dj的节点.
特别地, 由推论2可知, 在提取推荐规则时, 置信度阈值η ≥ 0.5, δ ≥ 0.5.因此, 在后面实验部分设置置信度阈值分别为η =δ =0.5.
基于因果力的邻域推荐算法(NRACF)框图如图2所示.
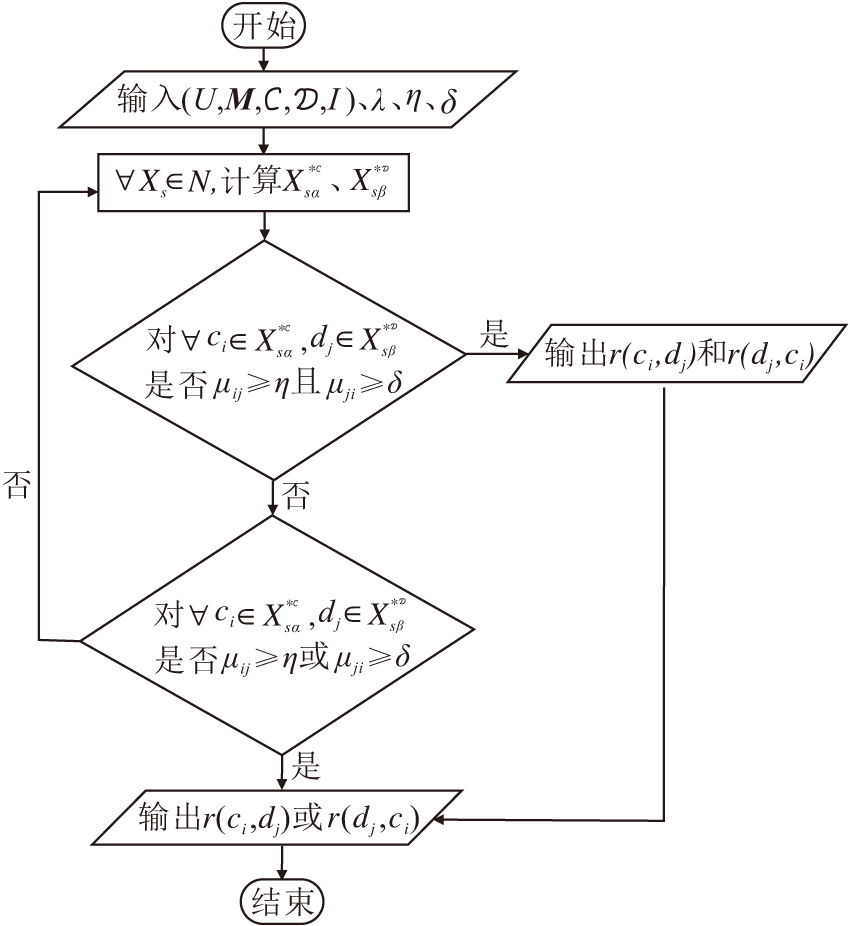 | 图2 NRACF框架图Fig.2 Flowchart of NRACF |
下面给出NRACF的具体步骤.
算法1 基于因果力的邻域推荐算法(NRACF)
输入 网络决策形式背景(U, M, C, D, I),
专家比例λ , 置信度阈值η 、δ
输出 推荐规则r(ci, dj), r(dj, ci)
step 1 计算网络中所有节点的聚合中心度:

将所有的聚合度中心度sD(i)按从大到小的顺序排列, 并依据λ 选取专家集, 记为E={e1, e2, …, eh}, 其中h=λ |U|.
step 2 依次选取E中的节点ei, 及其一阶邻接节点集构成社区N={X1, X2, …, Xh}.
step 3 依次选取N中的社区Xs, 计算每个条件属性ci在社区Xs中的密度
ρ c=
以及每个决策属性dj在社区Xs中的密度
ρ d=
在此基础上, 计算每个社区ρ c的均值μ 及标准差σ , 并对所有社区的μ -σ 求平均值, 记为条件属性密度α 的阈值, 同理得到决策属性密度β 的阈值.
step 4 依次选取N中的社区Xs, 计算
step 5 对于∀ ci∈
μ ij=
若μ ij≥ η , 输出推荐规则r(ci, dj); 若μ ji≥ δ , 输出推荐规则r(dj, ci); 若μ ij≥ η 且μ ji≥ δ , 输出推荐规则r(ci, dj)和r(dj, ci); 否则, 返回step 4.
step 6 利用获取的推荐规则对网络中的节点进行推荐预测, 算法结束.
假设网络决策形式背景中有n位用户和m个属性, 属性包括p个条件属性, q个决策属性, m=p+q, 则选取的专家个数为λ n, 通过专家节点划分社区的时间复杂度为O(λ n2).在划分的社区中, 计算条件弱概念内涵的时间复杂度为O(λ n2p), 计算决策弱概念内涵的时间复杂度为O(λ n2q), 对于w个条件弱概念内涵和v个决策弱概念内涵, 计算条件弱概念内涵与决策弱概念内涵间因果力的时间复杂度为O(wv).由于要遍历所有社区进行推荐, 所以算法1的时间复杂度为O(λ 2n3m+λ nwv).
注意到, 对象拥有的属性个数小于m, 因此, 构造弱概念集进行邻域划分的时间复杂度小于O(λ n2m).对比构造概念格进行邻域划分的时间复杂度O(n2m)[37]和文献[40]的时间复杂度O(λ n3m2), NRACF具有明显的计算优势.
本文实验选取电影评分MovieLens数据集(https://grouplens.org/datasets/movielens)上的ML-1m数据集与ML-100k数据集的5个抽样数据集和电影评分Filmtrust数据集(https://guoguibing.github.io/librec/datasets.html), 数据集信息如表4所示.
| 表4 实验数据集信息 Table 4 Information of experimental datasets |
在实验中, 首先将所用数据集进行预处理, 再随机选取80%的数据作为训练集, 剩余20%的数据作为测试集.然后在训练集上利用算法1得到推荐规则.进一步, 在测试集上进行推荐列表预测, 并计算该算法在数据集上的精确度、召回率和F1值.最后, 将算法1的结果与常见的6种推荐算法进行对比.
下面说明数据集的预处理步骤.
1)构造决策形式背景.首先, 由于部分电影评论人数较少, 可用性不强, 故选择评论人数前30%的电影作为属性集.然后, 将筛选的属性集按照例1中方法分为条件属性集C与决策属性集D.最后, 在电影评分矩阵Q中:若v(xi, ci)> 0, 则IC(xi, ci)=1, 否则, IC(xi, ci)=0; 若v(xi, dj)> 0, 则ID(xi, dj)=1, 否则, ID(xi, dj)=0, 得到决策形式背景.
2)构造网络邻接矩阵.对于电影评分矩阵Q, 根据定义3将对象间的相似性矩阵S转化为网络邻接矩阵M, 得到对象间的网络邻接矩阵.
本文采用如下推荐系统常用的评价指标.
1)精确度(Precision):
precision=
2)召回率(Recall):
recall=
3)F1-measure:
F1=
其中, R(x)为根据训练集得到的推荐预测列表, T(x)为用于验证结果的测试列表.
本节分析参数λ 对F1值的影响, 并讨论算法1中计算参数α 、 β 方法的合理性.
在算法1中, 选取λ =0.1、0.3、0.5、0.7、0.9, 依次计算F1值, 结果如表5所示, 表中黑体数字表示最大值.由表可知, 随着λ 的增大, 各数据集上F1值逐渐减小, 变化幅度较小, 但均在λ =0.1时取得最大值.这说明当专家比例达到0.1时, 算法1在各数据集上的指标值最优.
| 表5 参数λ 对F1值的影响 Table 5 Effect of λ on F1 |
在算法1中, 根据统计原理求得条件属性密度阈值α =0.2, 决策属性密度阈值β =0.1.
下面分别定义α =0.1, 0.2, …, 0.9, β =0.1, 0.2, …, 0.9, 根据算法1获取推荐规则集, 并在测试集上计算F1值, 结果如表6和表7所示, 表中黑体数字表示最大值.另外, 当α =0.5, 0.6, …, 0.9时, F1值都为0, 所以未显示在表6中.而当β =0.4, 0.5, …, 0.9时, F1值都为0, 所以也未显示在表7中.
| 表6 参数α 对F1值的影响 Table 6 Effect of α on F1 |
| 表7 参数β 对F1值的影响 Table 7 Effect of β on F1 |
由表6可知, 当α 从0.1增大到0.2时, 各数据集上的F1值逐渐增大, 并在α =0.2时取得最大值.而当α 继续增大时, 各数据集上的F1值逐渐减小直至为0.这是因为当α 达到一定值时, 若继续增大, 社区中满足条件的条件属性会减少, 获取的推荐规则也会减少, 最终导致F1值越来越小.所以, 在算法1中, 根据统计原理求得α 的方法是可行的.
由表7可知, 随着β 的增大, 各数据集上的F1值逐渐减小, 直至为0, 但均在β =0.1时取得最大值.这是因为当β 达到一定值时, 若继续增大, 社区中满足条件的决策属性就会减少, 获取的推荐规则也会减少, 最终导致F1值越来越小.所以, 在算法1中, 根据统计原理求得β 的方法也是可行的.
综上所述, 本文将算法1的参数设置为λ =0.1, η =δ =0.5, 并进行如下对比实验.
GRAWS[40]是基于弱概念相似度的组推荐算法, 主要通过* 算子诱导的网络弱概念进行社区划分, 并在划分的社区中根据属性弱概念下限相似度进行组推荐.对于n位用户和m个属性的网络决策形式背景, GRAWS的时间复杂度为O(λ n3m2).为了验证NRACF的有效性与运行效率, 将其与GRA-WS在不同的数据集上进行对比实验, 结果如表8所示, 表中黑体数字部分表示最优值.
| 表8 NRACF与GRAWS的推荐效果及运行时间对比 Table 8 Comparison of recommendation results and running time between NRACF and GRAWS |
由表8可知, 在7个数据集上, 相比GRAWS, NRACF的推荐效果有小幅提升, 但在运行效率上有明显提高.具体地, 在精确度上, NRACF均优于GRAWS.在召回率上, NRACF在ML-1m、ML-100k-u2、ML-100k-u5、Filmtrust数据集上优于GRAWS.在F1值方面, 除了ML-100k-u1、ML-100k-u4数据集, NRACF在其它数据集上都取得最优值.在运行时间上, NRACF的运行时间明显短于GRAWS, GRAWS的平均运行时间为6 407.21 s, 而NRACF的平均运行时间为1 708.43 s, 计算效率提升超过2倍.
为了进一步验证NRACF的有效性, 将其与如下5种常见的推荐算法进行对比.
1)User-Based CF(User-Based Collaborative Filtering)[17].基于用户的协同过滤推荐算法, 通过用户之间的相似性对目标用户进行预测评分.
2)Item-Based CF(Item-Based Collaborative Filtering)[18].基于项目的协同过滤推荐算法, 通过计算项目之间的相似度, 并根据评分信息预测目标项目.
3)GraphRec[41].基于图神经网络的社交推荐算法, 利用图神经网络对社交网络中的用户和项目的特征进行学习, 预测评分.
4)ETBRec(A Novel Recommendation Algorithm Combining the Double Influence of Trust Relationship and Expert Users)[42].结合用户信任关系和专家用户影响的协同过滤推荐算法, 通过用户之间的相似性构造信任关系矩阵, 并根据用户的信任度和积极态度计算各用户成为专家的可能, 结合信任关系矩阵和专家进行预测评分.
5)TF* Clarity(Term Frequency* Clarity)[43].结合标签相关性和用户社会关系的推荐算法, 构建标签相关矩阵和社交关系相似矩阵, 获取用户标签矩阵, 并进行预测评分.
各对比算法在各数据集上的精确度、召回率和F1值的对比结果如表9~表11所示, 表中黑体数字表示最优值.
| 表9 各算法在7个数据集上的精确度对比 Table 9 Accuracy comparison of different algorithms on 7 datasets |
由表9~表11可知:在精确度上, NRACF在所有数据集上都优于其它算法; 在召回率上, NRACF在ML-1m、ML-100k-u2、Filmtrust数据集上优于其它算法; 在F1值上, 除了ML-100k-u4数据集, NRACF在其它数据集上都得到最优值.
综上所述, 在选取的大部分数据集上, NRACF在精确度、召回率和F1值上均表现出明显优势.因此, 对于网络邻域推荐任务, 当数据集上的条件属性与决策属性之间存在较强的因果力时, 建议采用NRACF.
本文结合网络决策形式背景、变精度算子、Pearl因果力理论, 提出基于因果力的邻域推荐算法(NRACF), 并运用在MovieLens、Filmtrust数据集上.通过对比实验发现, NRACF整体上性能较优, 这有助于形式概念分析与因果推断的交叉融合研究.今后, 还可进一步结合因果涌现、因果推断与网络形式背景, 开展其它研究.
本文责任编委 梁吉业
Recommended by Associate Editor LIANG Jiye
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|