








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于三阶段生成网络的图像修复
[邵新茹1  , 叶海良
, 叶海良1 , 杨冰1 , 曹飞龙1 ]
, 叶海良, 杨冰, 曹飞龙]
|
|



作者简介:

邵新茹,硕士研究生,主要研究方向为深度学习、图像处理等.E-mail:17854337260@163.com.

叶海良,博士,讲师,主要研究方向为深度学习、图像处理.E-mail:yhl575@163.com.

杨 冰,博士,讲师,主要研究方向为深度学习、图像处理.E-mail:bingyang0517@163.com.
基于深度学习的图像修复研究重点之一是色彩、边缘和纹理的生成,然而,已有研究对色彩、边缘和纹理生成方法还可优化.因此,文中提出三阶段生成网络,每个阶段分别侧重于对色彩、边缘和纹理的合成.具体而言,在HSV色彩生成阶段,可在HSV色彩域中重建图像的全局色彩,为修复过程提供色彩指导.在边缘优化阶段,设计边缘学习框架,可获取更准确的边缘信息.在纹理合成阶段,构建特征双向融合解码器,增强图像的纹理细节.上述三个阶段依次衔接,每个阶段均可提升图像修复性能.大量实验表明文中网络性能较优.
About Author:
SHAO Xinru, master student. His research interests include deep learning and image processing.
YE Hailiang, Ph.D., lecturer. His research interests include deep learning and image processing.
YANG Bing, Ph.D., lecturer. His research interests include deep learning and image processing.
One of the research emphases of image inpainting based on deep learning is to generate color, edge and texture. However, generation methods of these three important properties need to be further improved. A three-stage generative network is proposed, and three stages tend to synthesize colors, edges and textures respectively. Specifically, the global color of the image is reconstructed in the HSV color space at the HSV color generation stage to provide color guidance for image inpainting. An edge learning framework is designed at the edge optimization stage to obtain more accurate edge information. At the texture synthesis stage, a decoder with feature bidirectional fusion is designed to enhance the details of the image. The three stages are successively connected, and each stage plays an important role in improving the performance of image inpainting. Extensive experiments demonstrate the superiority of the proposed method compared with the state-of-the-art methods.
图像修复[1, 2]是图像处理中的一个重要领域, 旨在使用视觉上合理的内容填补图像中的受损区域, 生成高质量的图像.目前, 图像修复已成为计算机视觉领域的研究热点之一, 并应用于目标移除[3]、图像编辑[4]、目标检测[5]和老照片修复[6]等诸多领域.
传统的图像修复方法分为基于扩散的方法[7]和基于块的方法[8].基于扩散的方法旨在将图像受损区域边缘的像素信息渗透传播到受损区域.基于块的方法是将图像分为若干小块, 根据小块之间相似度将最相关的小块填补到受损区域的相应位置.然而, 这些传统方法只是在图像水平上机械地运算, 没有学习能力, 无法捕获图像更深层的语义特征.
随着深度学习技术的发展, 学者们提出大量的基于深度学习的图像修复方法, 并成为当前的主流方法.Pathak等[9]将深度学习引入图像修复任务, 提出上下文编码器, 采用编码-解码的网络结构对图像进行语义修复.随后, 凭借卷积神经网络(Convo-lutional Neural Network, CNN)[10]强大的表示能力和生成对抗网络(Generative Adversarial Network, GAN)[11]强大的生成能力, 研究者在上下文编码器的基础上改进图像修复方法.Iizuka等[12]利用空洞卷积[13]捕获远距离的上下文信息, 用于填充受损区域, 并提出全局一致和局部一致的判别器, 保证生成的图像具有全局和局部的一致性.Wang等[14]使用三个不同大小的卷积核提取图像三个尺度的特征, 保证特征提取的全面性.Zeng等[15]提出PEN-Net(Pyramid-Context Encoder Network), 利用上下文注意力机制[16], 通过相似度学习的方式恢复多个尺度的特征.Liu等[17]针对图像修复任务的特点, 改进原始卷积, 提出部分卷积, 确保提取像素点的有效性.
此外, 两阶段网络架构也被用于图像修复任务.Yu等[16]设计两阶段修复网络, 第一阶段先对受损图像进行粗修复, 第二阶段对粗修复的图像进行精细化.进一步, Yu等又引入门控卷积[18]和Patch-GAN[19]的鉴别器改进先前工作, 获得更优性能.
然而, 上述方法往往缺少先验的指导, 导致生成的图像可能出现不合理的内容, 如颜色偏差、边缘不明确和纹理模糊等.
为此, 一些研究者引入不同的先验以指导图像修复.一方面, 为了获取图像全局的色彩结构信息, Ren等[20]引入平滑图像[21]作为先验, 设计两阶段网络, 第一阶段重建受损平滑图像, 获得图像的全局色彩结构, 以此作为先验指导第二阶段受损图像的修复.Qiu等[22]也采用同样的先验和网络架构.
在上述方法中, 第一阶段获取色彩结构先验的过程都是建立在RGB色彩域.然而, RGB色彩域对图像色彩的表征并不直观, 很难使用精确的数值表示色彩强度, 并且R、G、B三个颜色分量之间高度相关, 任意一个分量出现偏差, 会对图像色彩造成很大影响.因此, 为了使获取的先验具有较直观的色彩强度表征, 考虑在其它色彩域中进行色彩生成具有一定的研究意义.
另一方面, 为了使图像获得合理的边缘特征, Nazeri等[23]提出边缘指导[24]的两阶段网络框架, 第一阶段先恢复受损的边缘, 并将恢复好的边缘当作先验指导第二阶段图像的修复.Xu等[25]也提出E2I(Generative Inpainting from Edge to Image)这种类似方法.
然而, 上述方法的边缘学习框架存在如下问题.1)第一阶段中直接使用网络修复受损边缘, 效果通常不稳定, 很难获得合理的边缘, 影响后续的图像修复过程.2)第二阶段中输入图像仍是受损的, 仅依赖边缘指导对图像的受损区域进行填充往往是困难的.因此, 设计一种更有效的边缘学习方法至关重要.
此外, 图像纹理细节的合成质量往往也影响图像修复的性能.近来, 一些研究者[26, 27]致力于设计不同的网络模块合成图像纹理细节, 旨在生成更清晰和逼真的图像.
综上所述, 尽管上述对色彩、边缘和纹理的生成方法取得较优性能, 但其存在的问题仍需进一步改进.因此, 本文设计基于三阶段生成网络的图像修复, 每个阶段分别侧重于对图像的色彩、边缘及纹理的合成, 最终构建兼具色彩、边缘与纹理于一体的图像修复框架.具体而言, 第一阶段为HSV色彩生成阶段.将图像由RGB色彩域转至HSV色彩域, 以平滑HSV图像为输入, 设计色彩生成网络, 通过引入L1损失约束重建图像的全局色彩, 生成一个较合理的色彩先验.相比传统的RGB色彩域, 本文的三阶段生成网络色彩生成的过程建立在HSV色彩域中.HSV色彩域不仅能从色调、饱和度和亮度三方面直观表达色彩, 而且对色彩的感知更敏感, 这有利于进一步挖掘图像色彩信息[28, 29, 30].第二阶段是边缘优化阶段, 重点对图像的边缘进行细化.构建边缘优化网络, 以边缘损失为约束, 实现对图像边缘的优化, 再通过边缘提取算法[24]获得边缘.该方式的优势在于其获取的边缘更准确, 在边缘约束条件下通过修复受损图像并提取边缘, 缓解已有方法[23, 24, 25]直接使用网络进行边缘生成的不稳定问题, 同时为后续的修复过程提供更全面完整的信息.第三阶段是纹理合成阶段, 该阶段旨在对图像的纹理进行细化.设计特征双向融合解码器, 对图像的高级特征与低级特征进行自适应融合, 实现对图像细节的增强.同时, 引入PatchGAN判别器[19], 使生成图像的细节更逼真.上述三个阶段顺次连接, 每个阶段都将上一阶段的输出作为输入, 合成的内容通过损失约束各有侧重, 保证最终生成的图像具有较合理的色彩、清晰的边缘及纹理细节.
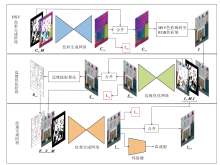
本文提出三阶段生成网络, 整体框架如图1所示.
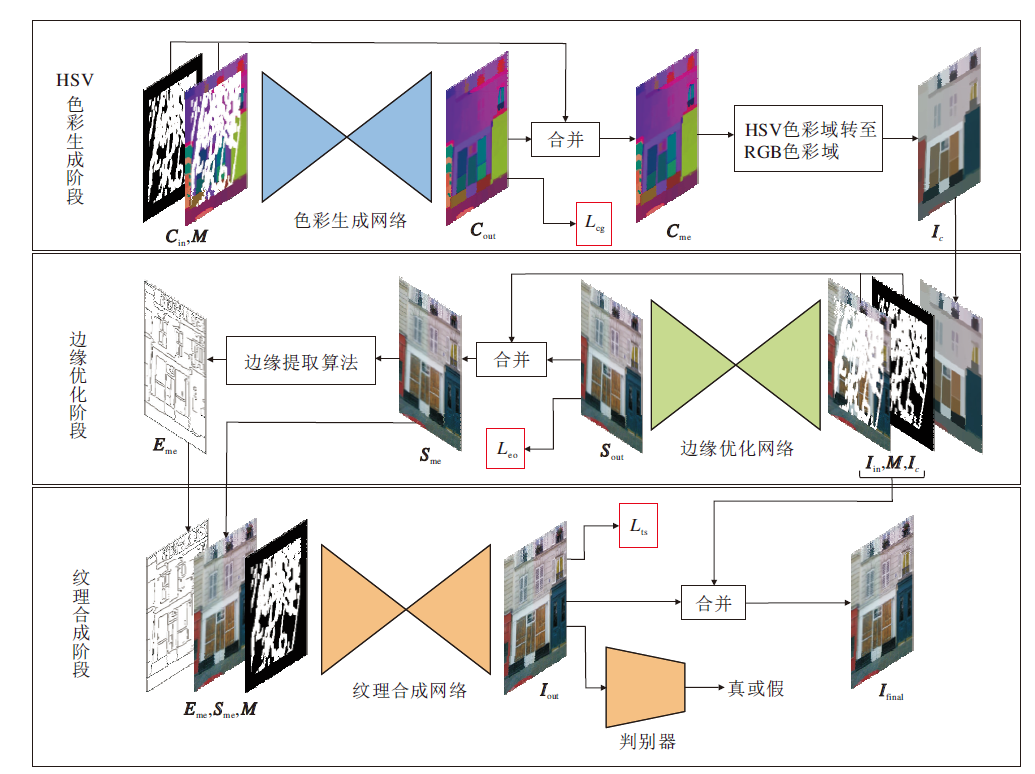 | 图1 本文网络整体框架图Fig.1 Overall architecture of the proposed network |
本文网络分为HSV色彩生成阶段、边缘优化阶段和纹理合成阶段, 三个阶段依次衔接, 旨在通过三个阶段的修复使生成图像具有合理的色彩、边缘和清晰的纹理.
HSV色彩生成阶段侧重于重建图像受损的全局色彩, 从而得到一个能代表图像全局色彩信息的先验.首先, 构造平滑HSV图像(如图2所示), 以此作为色彩生成的对象.构造方法如下:先将图像利用平滑结构算法[21]计算平滑图像, 再将平滑图像利用色彩转换算法[30]由RGB色彩域转至HSV色彩域.其中, 平滑结构算法可去除难以捕获的高频信息, 从而降低重建全局色彩结构的难度.
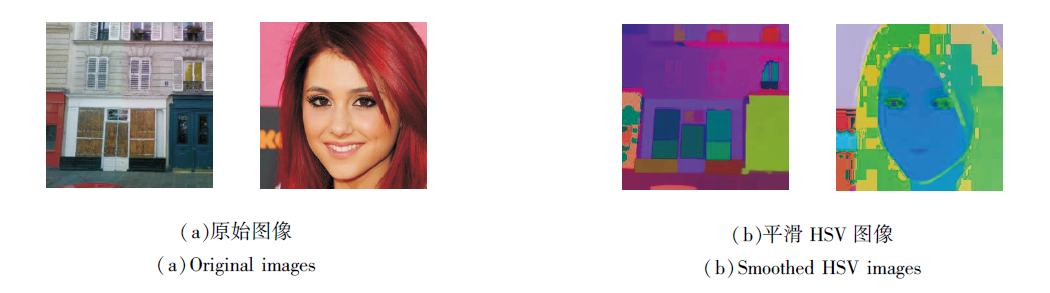 | 图2 原始图像及其对应的平滑HSV图像Fig.2 Original images and their corresponding smoothed HSV images |
与已有方法[20, 21, 22]不同的是, 本文色彩生成阶段通过色彩转换算法[30]将色彩生成过程由RGB色彩域转至HSV色彩域, 这主要取决于HSV色彩空间的如下优势[30]:HSV色彩空间可从色调、饱和度和亮度三方面对图像进行表征, 比RGB色彩空间具有更直观的色彩描述, 对色彩的感知更敏感, 这对图像色彩信息的捕获是更有利的.真实图像Igt可按照上述构造方法计算平滑HSV图像Cgt, 获得受损的平滑HSV图像:
Cin=Cgt☉(1-M),
其中, M表示二值掩码, 1表示受损区域, 0表示未受损区域, ☉表示逐元素相乘.
其次, 将Cin输入色彩生成网络(Color Genera- tion Network, CGNet)进行色彩重建, 可深度挖掘受损的平滑HSV图像的色彩信息, 并对其进行合理修复, 从而生成可信的色彩.生成的平滑HSV图像为:
Cout=CGNet(Cin‖M),
其中, ‖表示按通道维度拼接, CGNet(·)表示色彩生成网络.随后, 将Cout中生成的像素与Cin中已知的像素合并, 输出图像
Cme=Cout☉M⊕Cin☉(1-M),
其中⊕表示逐元素相加.
最后, 平滑HSV图像Cme由HSV色彩域转回RGB色彩域, 从而得到Ic.如图1所示, Ic具有图像全局的色彩结构信息, 这将被当作先验指导后续修复过程.
边缘优化阶段重点在于优化图像边缘, 并输出合理边缘.Nazeri等[23]先使用网络修复受损边缘, 再以此为先验指导修复受损图像.与文献[23]不同, 本文边缘优化阶段是在色彩先验的指导下先对图像而非边缘进行修复, 并在边缘损失函数[31]的约束下优化图像中的边缘信息, 进而提取边缘.在此阶段, 既能得到更合理的边缘, 又能获取具有合理边缘信息的图像, 相比文献[23]的工作, 这种方式能为后续的修复过程提供更准确完整的信息.
具体地, 将Ic当作色彩先验连同受损图像Iin一起输入边缘优化网络(Edge Optimization Network, EONet), 损毁图像:
Iin=Igt☉(1-M).
EONet可在边缘损失[31]的约束下调整图像的边缘结构.生成图像
Sout=EONet(Iin‖Ic‖M),
其中EONet(·)表示边缘优化网络.随后, 合并Sout中生成的内容与Iin中已知的内容, 得到输出图像:
Sme=Sout☉M⊕Iin☉(1-M).
因为色彩先验和边缘约束的介入, 此图像具有合理的色彩和边缘.
随后, 通过Canny边缘提取算法[24]提取Sme的边缘Eme.Sme和Eme紧接着传入下一阶段.
纹理合成阶段重点增强图像的纹理细节, 生成更精细的图像内容.具体地, 边缘Eme连同图像Sme一同输入纹理合成网络(Texture Synthesis Net- work, TSNet), 用于细化图像的纹理, 生成精细的图像:
Iout=TSNet(Sme‖Eme‖M),
其中TSNet(·)表示纹理合成网络.
在这一阶段, 边缘Eme的加入可有效指导图像纹理细节的合成.最后, 合并Iout中生成的内容与Iin中已知的内容, 得到最终输出图像:
Ifinal=Iout☉M⊕Iin☉(1-M).
上述三个阶段合成的内容各有侧重点, 采用串联网络结构的目的是在保留上一阶段特性的同时, 还可在下一阶段合成新的特性, 保证最终生成的图像同时具有较合理的色彩、边缘及清晰的纹理.
此外, 判别器的引入通常可使生成图像的细节更逼真清晰[3].如图1所示, 在网络末尾, 添加判别器, 对生成器生成图像的质量进行评判打分.由于PatchGAN[19]中的判别器被广泛应用于图像修复任务, 并获得较优性能, 本文沿用这种判别器.生成器和判别器在相互对抗的过程中使生成器的生成能力和判别器的评判能力均得到提升, 这也符合生成对抗网络[11]的结构.
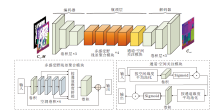
色彩生成网络(CGNet)框架如图3所示, 以受损平滑HSV图像为输入, 可在HSV色彩空间中挖掘图像色彩分布的同时, 对受损区域进行合理填充.CGNet包含编码器、瓶颈层和解码器三部分.编码器包含3层卷积层, 用于将受损图像映射到高级特征空间.瓶颈层由4个多感受野残差聚合模块和1个通道-空间关注模块组成, 可恢复高级特征.解码器包含3层卷积层, 用于将恢复好的高级特征映射到图像水平.
 | 图3 色彩生成网络框架图Fig.3 Framework of color generation network |
多感受野残差聚合模块结合空洞卷积[13]和ResNet[32]的优势, 具有强大的特征聚合功能.此模块以受损特征为输入, 可搜集特征中多个感受野的上下文信息, 并将这些信息聚合到受损区域, 从而实现特征恢复.
首先, 一层卷积层将输入特征X的通道数压缩为原来的1/4, 得到压缩特征X0.X0传入4层串联的空洞卷积层中, 每层空洞卷积都会搜集到具有不同感受野的特征, 这些搜集的信息会作为填补受损区域的原材料.这一过程表示为
Xr+1=ReLU(DCon
其中, r=0, 1, 2, 3, DCon
通过式(1), 可得到4个具有不同感受野的特征, 即X1~X4.这些特征按通道维度拼接, 并通过一层卷积层整合成一个综合的上下文特征Xc.这时, Xc与输入特征X的维度相同, 使用一个残差连接[32]使两者相加, 得到多感受野残差聚合模块的输出:
X'=X⊕Xc.
堆叠多个多感受野残差聚合模块, 上下文信息能反复聚合到受损区域, 有利于填补具有较大受损区域的图像.
通道-空间关注模块可对多感受野残差聚合模块搜集的上下文信息在通道维度和空间维度分别进行加权, 用于关注上下文信息中重要的内容.具体过程如下.由最后一个多感受野残差聚合模块输出的特征
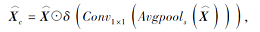
其中, δ(·)表示Sigmoid函数, Conv1×1(·)表示卷积核为1的卷积层, Avgpools(·)表示按空间维度的平均池化.其次, 对
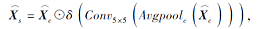
其中, Conv5×5(·)表示卷积核大小为5的卷积层, Avgpoolc(·)表示按通道维度的平均池化.
多感受野残差聚合模块和通道-空间关注模块的配合使用可聚合最相关的上下文信息到受损区域, 从而有效修复平滑HSV图像.
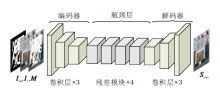
边缘优化网络(EONet)框架如图4所示, 以受损图像和色彩先验为输入, 重点优化图像边缘.由于存在色彩先验作为指导, 大幅降低修复受损图像的难度.同时, 在边缘损失函数[31]的约束下, 网络会朝着边缘最优的方向对图像进行恢复.EONet的网络结构很简洁, 由编码器、瓶颈层和解码器组成.编码器和解码器都包含3层卷积层, 瓶颈层包含4个文献[32]的残差模块.
 | 图4 边缘优化网络框架图Fig.4 Framework of edge optimization network |
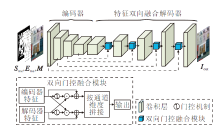
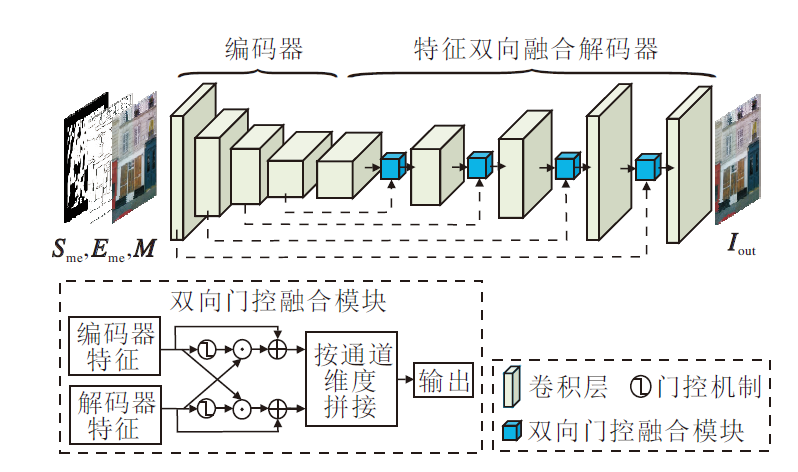
纹理合成网络(TSNet)框架如图5所示, 网络以边缘优化阶段输出的图像和相应的边缘作为输入, 侧重于增强图像的纹理细节.TSNet包含1个编码器和1个特征双向融合解码器.编码器包含4层卷积层, 特征双向融合解码器包含5层卷积层和4个双向门控融合模块.
 | 图5 纹理合成网络框架图Fig.5 Framework of texture synthesis network |
与传统的跳跃连接[34]采用的直接拼接方式不同, 双向门控融合模块可通过两个门控机制自适应地融合编码器的浅层特征和解码器的深层特征, 权衡浅层特征和深层特征.这样不仅可保留图像的原始特征, 也可挑选预测的新内容.具体过程如下.
编码器中的特征记为Yen, 解码器中的特征记为Yde, 这两个特征具有相同维度.双向门控融合模块以这两个特征为输入, 通过两个门控机制[18]学习两个门控权重:
gen=δ(Conv1×1(Yen)),
gde=δ(Conv1×1(Yde)).
然后, 两个门控权重被用于实现Yen和Yde之间的交互融合, 使Yen和Yde可相互获取对自身合成有利的信息, 即
Y'en=Yen(Yde☉gen),
Y'de=Yde(Yen☉gde).
接着, Y'en和Y'de按通道维度拼接, 得到双向门控融合模块的最终输出.
总之, TSNet以边缘为指导, 通过特征解码方式, 可使图像纹理细节变得更清晰.
大部分深度图像修复方法都使用L1损失、感知损失[17]、风格损失[17]、对抗损失, 本文网络沿用这些损失函数.此外, 也选择边缘损失作为本文的损失函数.
HSV色彩生成阶段损失函数如下.L1损失用于度量生成的平滑HSV图像Cout与真实平滑HSV图像Cgt之间的误差, 目标是在HSV色彩空间中重建图像的色彩, 损失
Lcg=‖Cout-Cgt‖1,
其中‖·‖1表示L1距离.
边缘优化阶段损失函数如下.采用L1损失和边缘损失[31]加权和的形式度量生成图像Sout和真实图像Igt之间内容和边缘的误差, 实现对图像边缘结构的优化, 损失
Leo=μ‖Sout-Igt‖1+ (1-μ)‖C(Sout)-C(Igt)‖1,
其中, C(·)表示Canny边缘提取算法[24], μ(0<μ<1)表示损失权重, 控制边缘约束的力度, 本文中μ=0.8.
纹理合成阶段损失函数如下.首先, L1损失用于保证生成图像Iout和真实图像Igt绝对距离相近, 损失
Lrec=‖Iout-Igt‖1.
其次, 感知损失[17]和风格损失[17]是借助预训练的VGG-16[35]计算的.这2个损失函数可在高级特征的水平上衡量生成图像Iout和真实图像Igt的差距.
感知损失
Lper=
其中, ϕ l(·)表示VGG-16[35]的第l层池化层, Hl、Wl表示第l层输出特征的高、宽, Cl表示第l层输出特征的通道数.
风格损失
Lsty=
最后, 对抗损失[11]的加入可使生成图像具有逼真的细节.对生成器来说, 它旨在使生成图像尽可能地逼近真实图像, 以至于判别器无法区分两者.那么生成器的对抗损失为:
其中, D表示判别器, z表示服从生成图像分布的样本, log(·)表示对数函数.
对判别器而言, 希望区分生成图像和真实图像, 判别器的对抗损失为:
其中x表示服从于真实图像分布的样本.
最终纹理合成阶段的总损失函数为:
Lts=Lrec+λperLper+λstyLsty+λadv
对于λper、λsty、λadv这些损失权重, 许多工作都继承文献[23]的设置, 本文也采用同样的参数设定, 即
λper=0.1, λsty=250, λadv=0.1.
综上所述, 本文网络总的损失函数为:
Lsum=Lcg+Leo+Lts.
本文采用Paris StreetView[9]、CelebA-HQ[36]图像数据集和二值掩码数据集[17]进行实验, 其中, 二值掩码数据集用于损毁图像.
Paris StreetView数据集包含15 000幅巴黎街景图像, 测试集包含100幅图像, 训练集包含14 900幅图像.CelebA-HQ数据集包含30 000幅人脸图像, 2 000幅用于测试, 28 000幅用于训练.
二值掩码数据集包含12 000幅二值掩码, 并根据受损率分为6类, 分别是1%~10%, 10%~20%, 20%~30%, 30%~40%, 40%~50%, 50%~60%.
CGNet、EONet和TSNet详细的网络设置如表1所示, Conv表示卷积层, TConv表示反卷积层.K表示卷积核尺寸, S/U表示滑动步长或上采样因子, P表示零填充数.
| 表1 CGNet、EONet和TSNet的网络设置 Table 1 Network settings of CGNet, EONet and TSNet |
本文所有的实验都在NVIDIA RTX 2080Ti GPU上进行, 并通过PyTorch框架实现.在训练过程中, 使用Adam(Adaptive Moment Estimation)优化器[37]作为整个网络的优化器, 内置参数β 1=0.5, β 2=0.9.生成器的学习率为1×10-4, 判别器的学习率为1×10-5.
与文献[17]的操作相同, 在模型收敛后学习率降低为原来的0.1进行参数微调.由于GPU内存的限制, 所有的图像及对应的二值掩码都统一调整为256×256, 批量大小设置为2.
同时, 本文使用峰值信噪比(Peak Signal to Noise Ratio, PSNR), 结构相似性(Structure Simila-rity, SSIM), 平均L1距离(Mean L1)和LPIPS(Learned Perceptual Image Patch Similarity)作为图像修复性能的评价指标.PSNR、SSIM值越大修复效果越优, Mean L1和LPIPS值越小修复效果越优.
为了证实本文网络具有优越的修复性能, 选择如下8种深度学习图像修复网络进行对比实验:PEN-Net[15]、GatedConv(Gated Convolution)[18]、E2I[25]、文献[26]网络、文献[27]网络、RFR(Recurrent Fea-ture Reasoning)[38]、文献[39]网络、SIFNet(Split-Inpaint-Fuse Network)[40].为了公平起见, 所有实验均在相同的环境和设置下进行.
各网络在Paris StreetView、CelebA-HQ数据集上的定量对比结果如表2和表3所示, 表中黑体数字表示最优值.由表可见, 本文网络的定量指标结果总体上优于其它网络.
| 表2 各网络在Paris StreetView数据集上的定量对比结果 Table 2 Quantitative result comparison of different networks on Paris StreetView dataset |
| 表3 各网络在CelebA-HQ数据集上的定量对比结果 Table 3 Quantitative result comparison of different networks on CelebA-HQ dataset |
具体来说, Paris StreetView数据集上包含大量复杂的场景图像, 修复这种图像极具挑战性.本文网络在4个指标上均有明显优势, 这说明本文网络对修复复杂场景的图像具有优越性.在CelebA-HQ数据集上, 由于人脸图像的语义结构都是相似的, 修复这种图像相对容易, 本文网络依旧可获得偏好的定量结果, 这说明本文网络对人脸图像的修复也具有优越性能.
各网络在Paris StreetView、CelebA-HQ数据集上的可视化效果如图6所示.
 | 图6 各网络在2个数据集上的视觉效果对比Fig.6 Visual effect comparison of different networks on 2 datasets |
具体地, Paris Street- View数据集上对比网络生成的场景图像存在模糊区域、伪影及结构扭曲等不良的视觉效果, 而本文网络生成的图像具有合理的边缘结构和清晰的细节, 如图像中的窗户框、管道和杆子.CelebA-HQ数据集上生成的人脸图像会存在错误的颜色和伪影, 而本文网络生成的人脸图像具有较好的视觉效果.
进一步, 通过放大的眼睛之间的对比可观察到, 本文网络色彩生成更准确, 如图中男士的人脸图像, 本文网络生成右眼与左眼颜色相同, 都是蓝色的, 而其它网络生成的眼睛是棕色的或黑色的, 而且本文网络生成的图像细节更逼真.
为了证实本文网络的3个阶段和提出模块的有效性, 在Paris StreetView数据集上进行消融实验.
本文网络包含HSV色彩生成阶段、边缘优化阶段和纹理合成阶段, 为了证实3个阶段各自的有效性, 设计如下3组消融实验:1)网络1.移除本文网络中的HSV色彩生成阶段.2)网络2.移除本文网络中的边缘优化阶段.3)网络3.移除本文网络中的纹理合成阶段.本文还设计3个模块, 即多感受野残差聚合模块、通道-空间关注模块和双向门控融合模块, 为了证实它们各自的积极作用, 也进行3组消融实验:4)网络4.将多感受野残差聚合模块替换为被大量工作广泛使用的空洞残差模块[20, 23, 27], 该模块只有一种空洞率r=2.5)网络5.移除通道-空间关注模块.6)网络6.将双向门控融合模块替换为传统的跳跃连接[34].
各网络的消融实验结果如表4所示, 表中黑体数字表示最优值.由表可观察到, 网络1~网络3的结果都与本文网络结果具有较大差距, 这反映HSV色彩生成阶段、边缘优化阶段和纹理合成阶段对提升修复性能的有效性.同时, 除了SSIM指标以外, 网络4~网络6结果均差于本文网络, 这说明多感受野残差聚合模块、通道-空间关注模块和双向门控融合模块的加入可提升网络的修复性能.
| 表4 在Paris StreetView数据集上的消融实验结果 Table 4 Results of ablation experiments on Paris StreetView dataset |
为了佐证上述结论, 消融实验的视觉对比结果如图7所示.一方面, 对比网络1~网络3的图像(见图7(c)~(e))与本文网络图像(见图7(i))可发现, 图像(i)具有更合理的色彩和边缘, 细节更清晰, 这定性说明三个阶段中的每个阶段都对提升图像的视觉效果具有积极作用.
 | 图7 在Paris StreetView数据集上消融实验的视觉效果Fig.7 Visual effect of ablation experiments on Paris StreetView dataset |
与此同时, 为了清楚展示边缘优化阶段对图像边缘生成的有效性, 对比网络2和本文网络的图像边缘(见图7(j)、(k)), 边缘优化阶段的加入使图像具有更合理的边缘信息.另一方面, 对比网络4~网络6的图像(见图7(f)~(h))和本文网络图像(见图7(i)), 可发现图像(i)具有更清晰的纹理细节, 这证实多感受野残差聚合模块、通道-空间关注模块和双向门控融合模块对提升图像质量具有一定作用.为了更加清楚地展示多感受野残差聚合模块和通道-空间关注模块对色彩生成的有效性, 可视化网络4、网络5和本文网络生成的平滑HSV图像(见图7(l)~(n)).对比可得, 图像(n)生成的色彩图像更全面合理, 这表明多感受野残差聚合模块和通道-空间关注模块可促进生成更合理的图像色彩.
本节进行实验, 证实在HSV色彩生成阶段中色彩生成方法的有效性和优越性.本文的色彩生成方法与已有方法的最大区别是色彩生成过程并不是在RGB色彩域中进行, 而是在HSV色彩域中进行.为了验证这一点的有效性, 设计如下消融实验.定义网络A, 即移除本文网络第一阶段中的色彩转换方法, 在RGB色彩域中进行色彩生成[30].
本文网络与网络A的有效性实验结果如表5所示, 表中黑体数字表示最优值.由表可知, 本文网络的指标值优于网络A.
| 表5 本文网络与网络A的指标值对比 Table 5 Index value comparison between the proposed network and network A |
与此同时, 网络A与本文网络的视觉对比如图8所示.由对比红框中生成的内容可知, 网络A生成色彩先验的全局色彩和结构并不合理, 颜色也有偏差, 导致最终生成图像的色彩和结构不合理.而本文网络生成色彩先验的结构合理, 颜色正确, 最终生成图像的视觉效果优于网络A.
 | 图8 色彩生成方法消融实验的视觉效果对比Fig.8 Visual effect comparison of ablation experiments of color generation methods |
上述实验结果说明在HSV色彩域进行色彩生成的效果优于在RGB色彩域进行色彩生成, 这证实本文的色彩生成方法的有效性.
此外, 为了验证本文网络在色彩生成方面的优越性, 选择如下相关网络:GatedConv[18]、Structure-Flow(Image Inpainting via Structure-Aware Appea-rance Flow)[20]、文献[27]网络.
对比各网络的生成图像结果, 具体如图9所示.由图可见, 对比网络生成图像的全局色彩并不合理, 如门、墙壁都存在色彩偏差, 图像的色彩结构也存在扭曲(如窗户).
 | 图9 各网络的生成图像对比Fig.9 Comparison of generated images of different networks |
而本文网络生成的图像不仅全局色彩结构正确, 而且图像的颜色自然, 细节清晰, 这表明本文网络在色彩生成方面的优势.
本节进行实验和分析, 验证本文的边缘学习方法的有效性.本文的边缘学习方法与已有边缘学习方法的最大区别在于本文方法并非使用网络直接对边缘进行学习, 而是在对图像进行修复的过程中通过边缘损失函数[31]的约束达到边缘优化的目的, 进而获取图像边缘.
为了验证这种方式的优越性, 设计如下消融实验.定义网络B, 即与文献[23]相同, 使用网络直接对边缘进行学习.
本文网络与网络B的有效性实验结果对比如表6所示.由表可见, 本文网络的指标值远优于网络B.
| 表6 本文网络与网络B的指标值对比 Table 6 Index value comparison between the proposed network and network B |
同时, 网络B和本文网络的视觉对比如图10所示.
 | 图10 边缘学习方法消融实验的视觉效果对比Fig.10 Visual effect comparison of ablation experiments of edge learning methods |
由图10可看出, 相比网络B, 本文网络生成的边缘更完整准确.由此得出结论, 本文的边缘学习方法比已有的边缘学习方法更有效.
此外, 为了验证本文网络生成边缘的准确性, 选择如下对比网络:EdgeConnect(Structure Guided Image Inpainting Using Edge Prediction)[23]、E2I[25]、文献[26]网络.下面重点对比生成图像的边缘, 证实本文网络在边缘学习方面的优势.各网络生成图像对比如图11所示.由图可知, 对比网络生成的图像并未获得准确的边缘, 如窗户框处的生成效果.而本文网络可生成更好的边缘特征.这表明本文边缘学习方法的优势.
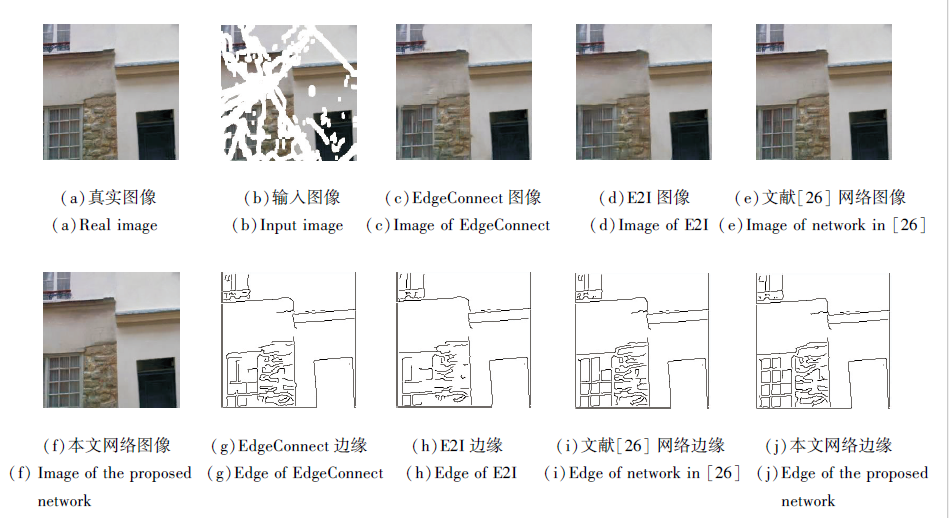 | 图11 各网络的生成图像及图像边缘对比Fig.11 Comparison of image edges and images generated by different networks |
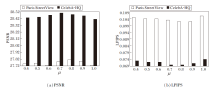
本节讨论边缘优化阶段涉及的损失函数权重μ的取值. μ可控制边缘约束的力度, μ值越大, 边缘约束力度越小, μ值越小, 边缘约束力度越大.为了探究μ值对网络性能的影响, 在Paris StreetView、CelebA-HQ数据集上利用受损率为30%~40%的二值掩码进行实验. μ不同对PSNR和LPIPS指标的影响如图12所示.由图可观察到, 在Paris Street-View数据集上, 当μ=0.8, 0.9时, 网络获得最优性能.在CelebA-HQ数据集上, 当μ=0.7, 0.8时, 网络获得最优性能.综合上述两点, 本文网络中当μ=0.8时, 可达到对图像边缘最适合的约束力度.
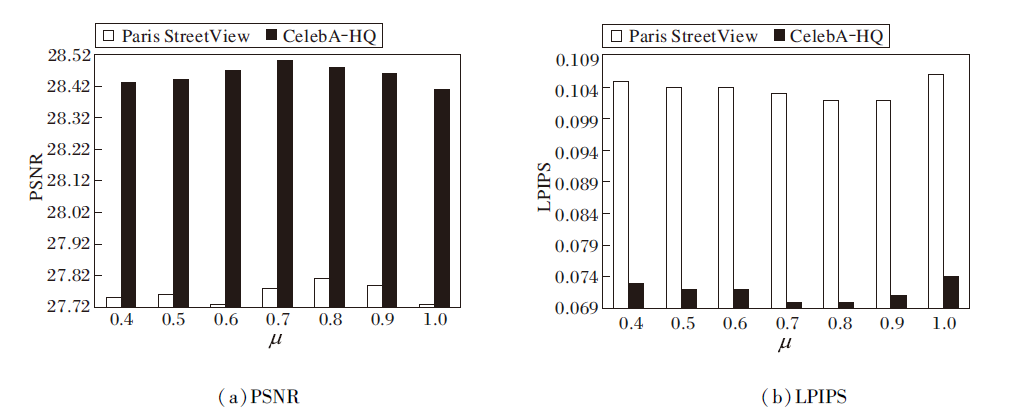 | 图12 μ值对网络性能的影响Fig.12 Influence of μ on network performance |
本文构造三阶段生成网络, 三个阶段分别侧重于图像色彩、边缘和纹理的合成.具体地, 在HSV色彩生成阶段, 图像的全局色彩能在HSV色彩空间中被合理重建, 为整个图像修复过程提供色彩指导.在边缘优化阶段, 提出边缘学习方法, 可获取更合理的边缘, 并为后续修复过程提供更准确完整的信息.此外, 提出特征双向融合解码器, 嵌入纹理合成阶段, 达到细化图像纹理细节的目的.大量的消融实验结果表明三阶段生成网络的有效性.同时, 通过与其它网络定量对比和可视化效果对比, 本文网络具有更好的图像修复性能.注意到本文网络采用串联的网络架构, 而有工作致力于设计并联的网络架构以获得性能提升[26].因此, 今后将致力于设计合理的并联网络进行图像修复.同时, 也可把本文的思路扩展到其它的计算机视觉任务中, 如超分辨率重建[13]、图像转换[19]等.
本文责任编委 黄 华
Recommended by Associate Editor HUANG Hua
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|