




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
模态不变性特征学习和一致性细粒度信息挖掘的跨模态行人重识别
[石林波1  , 李华锋
, 李华锋1 , 张亚飞1 , 谢明鸿1 ]
, 李华锋, 张亚飞, 谢明鸿]
|
|



作者简介:

石林波,硕士研究生,主要研究方向为计算机视觉、行人重识别.E-mail:1527467911@qq.com.

李华锋,博士,教授,主要研究方向为图像处理、计算机视觉.E-mail:hfchina99@163.com.

谢明鸿,博士,高级工程师,主要研究方向为计算机视觉.E-mail:minghongxie@163.com.
跨模态行人重识别方法主要通过对齐不同模态的像素分布或特征分布以缓解模态差异,却忽略具有判别性的行人细粒度信息.为了获取不受模态差异影响且更具判别性的行人特征,文中提出模态不变性特征学习和一致性细粒度信息挖掘的跨模态行人重识别方法.方法主要包括模态不变性特征学习模块和语义一致的细粒度信息挖掘模块,联合两个模块,使特征提取网络获取具有判别性的特征.具体地,首先利用模态不变性特征学习模块去除特征图中的模态信息,缓解模态差异.然后,使用语义一致的细粒度信息挖掘模块,对特征图分别进行通道分组和水平分块,在充分挖掘具有判别性的细粒度信息的同时实现语义对齐.实验表明,文中方法性能较优.
About Author:
SHI Linbo, master student. His research interests include computer vision and person re-identification.
LI Huafeng, Ph.D., professor. His research interests include image processing and computer vision.
XIE Minghong, Ph.D., senior engineer. His research interests include computer vision.
In the existing cross-modal person re-identification methods, modal differences are lessened by aligning features or pixel distributions of different modalities. However, the discriminative fine-grained information of pedestrians is ignored in these methods. To obtain more discriminative pedestrian features independent of modal differences, a modal invariance feature learning and consistent fine-grained information mining based cross-modal person re-identification method is proposed. The proposed method is mainly composed of two modules, modal invariance feature learning and semantically consistent fine-grained information mining. The two modules are combined to drive the feature extraction network to obtain discriminative features. Specifically, the modal invariant feature learning module is utilized to remove the modal information from the feature map to reduce the modal differences. Channel grouping and horizontal segmentation are conducted on person feature maps via the semantic consistent fine-grained information mining module. Consequently, the semantic alignment is achieved and the discriminative fine-grained information is fully mined. Experimental results show that the performance of the proposed method is significantly improved compared with the state-of-the-art cross-modal person re-identification methods.
行人重识别[1]是判断跨相机视角拍摄的行人图像是否为同一人的技术.受视角、姿态、光照、背景变化影响, 行人重识别是一个具有挑战性的任务.目前大多数研究[2, 3, 4, 5, 6, 7]针对可见光相机捕捉的行人图像进行匹配, 这是一个单模态行人重识别问题.然而, 在智能监控系统中, 只有可见光摄像机是不够的.因为当光线不足(如晚上)时, 很难从可见光图像(Visible Image, VI)中提取具有判别性的行人信息.先进的监控系统能在光照不足时自动从可见光模式切换到红外模式以捕获行人的红外图像(Infrared Image, IR), 获取行人有效的外观信息.
由于成像原理不同, 可见光图像和红外图像存在严重的模态差异.因此, 相比单模态行人重识别, 红外-可见光跨模态行人重识别是一个极具挑战性的问题.
跨模态行人重识别的目的是将来自一个模态的查询图像(Query)与来自另一个模态的图像库(Gallery)进行匹配, 在现实场景的视频监控中较重要.相比单模态行人重识别, 跨模态行人重识别面临的挑战是巨大的模态差异.因此, 如何较好地缓解模态差异是跨模态行人重识别研究的一个难点.
目前, 跨模态行人重识别中缓解模态差异的方法大致分为3类:基于模态互转的方法[8, 9, 10, 11, 12, 13, 14, 15]、基于度量学习的方法[16, 17, 18]和基于特征对齐的方法[19, 20, 21, 22, 23, 24, 25, 26].
基于模态互转的方法旨在通过一种合理的方式生成当前图像在另一个模态下的图像, 将跨模态行人重识别问题转化为单模态行人重识别问题, 在一定程度上缓解模态间的差异.为了进行模态互转, Wang等[8, 9, 10]提出变分自编码器的模态互转方法, 利用变分自编码器将红外图像转换为可见光图像, 将可见光图像转换为红外图像.Fan等[11]提出基于生成对抗的模态互转方法, 将行人可见光图像和红外图像通过CycleGAN(Cycle-Generative Adversarial Networks)[12]转为对应的红外图像和可见光图像, 把图像统一在相同的模态下.Liu等[13]构建频谱感知特征增强网络, 将VI图像转换为灰度光谱图像, 利用灰度光谱图像代替VI图像同IR图像进行相互检索.Li等[14]提出XIV-ReID(X-Infrared-Visible ReID), 引入X模态的方法, 将VI图像经过一个轻量型生成器转换得到X模态图像, 这是一个介于VI模态和IR模态的中间模态, 可用于缩小模态差异.Wang等[15]提出DPJD(Dual-Path Image Pair Joint Discriminant Model), 使用模态编码器和属性编码器生成图像的模态编码和属性编码, 再交换编码生成与原始图像模态不同的图像.
基于度量学习的方法关键在于如何设计合理的度量方法或损失函数, 使同一行人的相同模态和不同模态图像间的距离尽可能小, 不同行人的相同模态和不同模态图像间的距离尽可能大.Gao等[16]设计EAT(Enumerate Angular Triplet)损失和CMKD(Cross-Modality Knowledge Distillation)损失, EAT损失限制不同嵌入特征之间的内角, 获得角度可分离的公共特征空间, CMKD损失用于在特定的特征提取阶段结束时缩小不同模态特征之间的距离, 提升跨模态行人重识别任务的有效性.Wang等[17]提出DPAN+CMDC Loss(Dual-Path Attention Network and Cross-Modality Dual-Constraint Loss), 建立行人特征图的局部特征之间的空间依赖关系, 增强网路的特征提取能力, 同时, 还提出跨模态双约束损失, 为嵌入空间中的每个类分布添加中心和边界约束, 促进类内的紧凑性, 增强类间的可分离性.Hu等[18]提出DMiR(Adversarial Decoupling and Modality-Invariant Representation Learning), 求解光谱依赖信息, 优化身份信息, 进一步探索跨模态行人潜在的光谱不变但具有判别性的身份表示.
基于特征对齐的方法主要思想是如何约束特征提取网络提取不同模态下图像的共有特征.为了提取共有特征, Hao等[19]设计双对齐(空间对齐和模态对齐)特征嵌入方法, 利用行人局部特征辅助特征网络提取细粒度相机的不变信息, 再引入分布损失函数和相关性损失函数, 对齐VI模态和IR模态的嵌入特征.Park等[20]提出CMAlign, 互换局部的VI图像特征和IR图像特征, 约束互换后的特征在其行人类别的判断上无差别, 通过这种互换思想约束网络提取两个模态的共有特征.Chen等[21]研究神经特征搜索方法, 在身份损失和三元组约束下, 自动在空间和通道两个维度上选择两个模态的行人共有特征.Wu等[22]提出双流特征提取网络(VI模态流和IR模态流), 先使用双流结构分别提取VI图像特征和IR图像特征, 再将两个模态流的特征通过共享参数的网络获取共有特征.
综上所述, 基于模态互转的方法、基于度量学习的方法和基于特征对齐的方法旨在像素级或特征级上对齐不同模态的特征.尽管这些方法取得不错效果, 但主要关注如何缓解模态差异, 未充分考虑行人的细粒度信息, 因此, 提取的行人特征判别性不强, 效果还有待进一步改善.
为了获取更有判别性的行人信息, 一些行人重识方法开始关注行人局部特征的提取.姿态信息是定位人体不同局部部位的一个重要线索, 因此近年来涌现一些基于姿态信息的行人重识别方法, 利用姿态信息将输入的行人图像划分成不同部分.Su等[27]提出PDC(Pose-Driven Deep Convolutional Model), 精准使用人体局部信息, 并将整个人体和局部身体部分转换为标准化和同源状态, 更好地实现特征嵌入.Zheng等[28]通过姿态估计生成一个 PoseBox 结构, 再通过仿射变换将行人与标准姿态对齐, 通过 PoseBox融合卷积神经网络(Convolutional Neural Networks, CNN)架构, 减少姿态估计误差和信息丢失的影响.此外, Tay等[29]提出属性注意网络, 将衣服颜色、头发、背包等基于物理外观的属性融入基于分类的人员重识别的框架中, 增强行人特征表示.Wang等[30]使用关节点模型提取人体14个局部语义特征, 再利用这些局部语义特征建立关节点高阶关系信息和高阶人类拓扑关系信息, 让网络学习具有鲁棒性的特征.
上述方法虽然在一定程度上挖掘行人局部信息, 但存在两个主要的问题:1)需要引入外部网络或属性信息, 不是端到端的学习过程, 不利于在现实环境中进行部署.2)未考虑不同模态细粒度信息语义不一致的问题, 导致其无法直接应用到跨模态行人重识别任务中.基于上述分析, 在缓解模态差异的同时挖掘行人的细粒度信息, 有助于网络获取更有判别性的行人特征, 提升跨模态行人重识别方法的性能.
为此, 本文提出模态不变性特征学习和一致性细粒度信息挖掘的跨模态行人重识别方法, 可在挖掘细粒度信息的同时缓解模态差异.方法的总体框架主要由模态不变性特征学习(Modal Invariance Feature Learning, MIFL)模块和语义一致的细粒度信息挖掘(Semantically Consistent Fine-Grained Infor-mation Mining, SCFIM)模块组成.MIFL模块利用视觉Transformer网络[31]提取模态信息.同时, 提出模态混淆损失, 利用该损失训练模态混淆分类器.该分类器混淆模态信息和身份信息, 约束特征提取网络在特征提取阶段只提取行人模态不变性特征而忽略模态信息.SCFIM模块对特征图进行通道分组和水平分块, 充分挖掘行人细粒度信息.同时, 引入语义一致性损失, 约束网络提取到的不同模态同一行人的细粒度信息是语义一致的.语义一致的行人细粒度信息更具有判别性, 有助于提升网络的行人重识别性能.在两个具有挑战性的红外-可见光跨模态行人重识别数据集(SYSU-MM01、RegDB)上的实验验证本文方法的有效性和优越性.
在跨模态行人重识别数据集上, 使用V={
在一个批次训练数据(Batch)中, x(j, i)表示第j个行人的第i个训练样本, j={1, 2, …, B}, B表示在一个批次训练数据中行人身份的个数, i={1, 2, …, Q}, Q表示在一个批次训练数据中每个行人身份抽取的样本个数.
为了缓解红外-可见光两个模态之间的差异并提取丰富的语义一致的细粒度行人特征, 本文提出模态不变性特征学习和一致性细粒度信息挖掘的跨模态行人重识别方法, 整体网络结构如图1所示.
 | 图1 本文方法的总体框架Fig.1 Overall framework of the proposed method |
本文方法主要包括模态不变性特征学习模块(MIFL)和语义一致的细粒度信息挖掘模块(SCFIM).MIFL模块采用层数为N的视觉Transformer网络(ET)提取模态信息, 并利用模态信息训练一个模态混淆分类器.该分类器在模态混淆损失的约束下, 迫使模型学习模态不变性特征.SCFIM模块采用ResNet50作为骨干网络, 并将骨干网络(前2个块(EL)参数不共享, 后3个块(ER)参数共享)提取的特征复制一份, 一份经过广义平均池化(Generalized-Mean, Gem)[32]后输入MIFL模块, 学习模态不变性特征, 另一份经过通道分组和水平分块两个操作挖掘细粒度信息.
此外, 引入语义对齐损失, 约束网络提取到的不同模态同一行人的细粒度信息是语义一致的.两个模块联合后训练特征提取网络, 使网络提取不受模态影响、包含丰富细粒度信息、语义一致的行人特征.
为了缓解模态差异, 本文设计模态不变性特征学习模块(MIFL).
假设输入图像为xi(i={vi, ir}),
Mvi∈
分别表示xvi和xir经过EL得到的VI特征图和IR特征图, 其中, HT、WT表示特征图的高、宽, CT表示特征图的通道.将特征图在HT×WT维度上进行矩阵形状变换操作后得到特征
Hvi∈
将Hvi和Hir送入ET学习, 得到2个模态的模态信息mvi∈
mi=ET(reshape(EL(xi))), (1)
其中, EL表示卷积块(ResNet50共享参数的2个块), ET表示层数为N的视觉Transformer网络, reshape(·)表示矩阵形状变换操作, xi表示输入图像, mi表示模态信息, i={vi, ir}表示VI模态或IR模态.训练时, 最小化如下损失函数:
Lm=CE(Wm(mi),
约束提取的模态信息.最小化式(2)可优化ET提取模态信息, 其中, Wm(·)表示模态分类器,
得到模态信息后, 利用模态信息训练模态混淆分类器, 约束EL和ER在特征提取阶段只提取模态不变性特征, 达到将模态信息从特征图中去除的目的.具体地, 图像xi经过EL和ET得到模态信息mi, xi经过EL和ER得到的特征图再经过Gem池化得到身份信息fi.将模态信息mi和身份信息fi送入模态混淆分类器, 模态混淆分类器把mi分到VI模态类或IR模态类, 把fi分到既不是VI模态也不是IR模态的第3个类.在损失的约束下, EL和ER在特征提取阶段忽略对模态信息的提取, 因此EL和ER最终提取的是不包含模态信息的模态不变性特征.训练时, 使用如下损失函数:
Lc=CE(Wc(mi),
约束整个过程, 其中, Wc(·)表示模态混淆分类器,
IR模态图像的标签形式为
1.3.1 细粒度信息挖掘
行人拥有的细粒度信息越丰富, 就越具有判别性.为了挖掘行人的细粒度信息, 本文构建图1所示的细粒度信息挖掘(Fine-Grained Information Mi-ning, FIM).将经过EL和ER得到的行人特征图Fi∈
M={M1, M2, …, ML}∈
再将每组在水平维度上分成K块, 得到
P={P1, P2, …, Pk}∈
共得到L×K个细粒度块.该过程表示如下:
P=SH(SC(Fi)),
其中, Fi(i={vi, ir})表示特征图, SC(·)表示在通道维度上的分组操作, SH(·)表示在水平维度上的分块操作.
L×K个细粒度块经过Gem池化、1×1卷积层、BN层和ReLU层得到细粒度特征向量p(l, k)∈
${{L}_{id}}=-\frac{1}{BQ}\sum\limits_{j=1}^{B}{\sum\limits_{i=1}^{Q}{\sum\limits_{l=1}^{L}{\sum\limits_{k=1}^{K}{{{y}_{d}}\log \left( {{G}_{\left( j, i \right)}}\left( {{W}_{id}}\left( p_{\left( l, k \right)}^{\left( j, i \right)} \right) \right) \right)}}}} $ (4)
其中,
中心三元组损失约束如下:
$\begin{align} & {{L}_{tri}}= \sum\limits_{i=1}^{B}{{{\left[ g+{{\left\| c_{vi}^{i}-c_{ir}^{i} \right\|}_{2}}-\underset{\underset{j\ne i}{\mathop{n\in \{vi, ir\}}}\, }{\mathop{\min }}\, {{\left\| c_{vi}^{i}-c_{n}^{j} \right\|}_{2}} \right]}_{+}}} \\ & +\sum\limits_{i=1}^{B}{{{\left[ g+{{\left\| c_{ir}^{i}-c_{vi}^{i} \right\|}_{2}}-\underset{\underset{j\ne i}{\mathop{n\in \{vi, ir\}}}\, }{\mathop{\min }}\, {{\left\| c_{ir}^{i}-c_{n}^{j} \right\|}_{2}} \right]}_{+}}} \end{align}$ (5)
其中, g表示优化阈值, ‖·‖2表示欧氏距离,
分别表示这B个行人在VI模态和IR模态下的特征向量中心,
1.3.2 语义一致性约束
对每个细粒度块进行身份损失和中心三元组损失约束后, 细粒度块可具有一定的判别性, 但仍存在两个潜在问题:1)多个细粒度块可能表示重复的信息, 2)相同行人不同模态的细粒度块表示的特征语义可能不一致.若不解决这两个问题, 会导致方法对细粒度信息挖掘不充分, 对行人重识别的准确性也会产生负面影响.为此, 本文引入语义一致性约束(Semantic Consistency Constraint, SCC), 结构如图2所示.
 | 图2 语义一致性约束结构图Fig.2 Semantic consistency constraint structure |
拼接每个通道分组的水平块, 得到
Tl=[p(i, 1); p(i, 2); …; p(i, K)]∈
再对Tl(l={1, 2, …, L})进行身份损失Lcg(使拼接后的水平块具有判别性)和语义分类损失Lde.在语义分类器中, 设计一个固定的L分类标签, 标签类别数与通道分组数是对应的, 目的是约束相同的通道分组关注行人相同的细粒度信息.对Tl进行的两个损失如下:
Lcg=CE(Wcg(Tl), yd), (6)
Lde=CE(Wde(Tl), yl), (7)
其中, Wcg(·)表示通道分组的身份分类器, yd表示身份标签, Wde(·)表示语义分类器, yl(l={1, 2, …, L})表示一个固定的分类标签, 具体的标签形式为y1=[1 0 … 0], y2=[0 1 … 0], …, yL=[0 0 … 1].
最后, 将Tl(l={1, 2, …, L})按通道分组顺序拼接, 表示为
T=[T1; T2; …; TL]∈
针对T定义一个与式(5)定义相同的中心三元组损失, 记为L'tri.在测试阶段, T作为行人相似性度量的信息.
综合MIFL模块和SCFIM模块, 本文方法的总损失为
L=Lid+Ltri+Lcg+λ1L'tri+λ2Lde+ω(Lm+Lc), (8)
其中, λ1、λ2、ω表示网络的超参数, Lid、Lcg表示身份损失, Ltri表示细粒度特征向量
值得注意的是, 损失函数Lm和Lc与其它损失函数不同, 网络在最开始时不能较好地学习身份信息和模态信息, 如果不对损失函数Lm和Lc的权重进行调整, 方法在反向传播更新网络参数时会出现梯度爆炸情况.因此本文提出动态训练策略, 从模型训练的初始阶段到最终阶段逐渐增加损失函数Lm和Lc, 优化权重ω, 具体计算如下:
ω=
其中, t表示方法的迭代次数, E(Lt-1)表示前一次方法迭代损失的平均值.
为了方便理解, 本文方法具体步骤如算法1所示.
算法1 模态不变性特征学习和一致性细粒度信息挖掘的跨模态行人重识别
输入 带有身份标签(Y={yd}
输出 训练好的网络参数EL和ER
初始化EL, ET, ER, Wm, Wc, Wid, Wcg, Wde
for iter=1, 2, …, Iteration do
# Iteration表示模型训练时的最大迭代次数
#模态不变性特征学习
最小化式(2)更新ET和Wm
最小化式(3)更新EL, ER, ET和Wc
# 语义一致的细粒度信息挖掘
最小化式(4)和式(5)更新EL, ER和Wid
最小化式(6)和式(7)更新EL, ER, Wcg和Wde
end for
本文选择SYSU-MM01[22]、RegDB[34]数据集进行实验.
SYSU-MM01数据集是一个由4个可见光摄像机和2个红外光摄像机拍摄而成的数据集, 有室内和室外两种环境.训练集包含395个行人身份, 其中可见光图像22 258幅, 红外光图像11 909幅.测试集包含96个行人身份.在测试阶段, 查询图像(Query)由96个行人身份的3 903幅红外光图像组成, 图像库(Gallery)由在96个行人身份中随机抽样的301幅单搜索(Single-Shot)图像或3 010幅多搜索(Multi-shot)图像组成.SYSU-M01数据集有全搜索(All-Search)和室内搜索(Indoor-Search)两种不同的测试模式.在All-Search模式下, Gallery的照片包含所有可见光摄像机拍摄的照片, 在Indoor- Search模式下, Gallery的照片只包含来自室内可见光摄像机拍摄的照片.在每个测试模式下都有Single-Shot和Multi-shot两种设置.
RegDB数据集的图像由一个双相机系统收集而成, 包括一个可见光相机和一个红外光相机, 包含412个行人身份的8 240幅图像.每个行人身份包含10幅可见光图像和10幅红外光图像.随机选择206个行人身份的图像作为训练集, 剩下的206个行人身份图像作为测试集.测试模式包含根据可见光图像查找红外图像和根据红外图像查找可见光图像两种模式.
为了与现有方法进行公平对比, 所有实验均遵循现有跨模态行人重识别方法中的常见评估设置[23, 35].
在测试过程中, SYSU-M01数据集上只有将可见光图像作为Gallery, 将红外图像作为Query这一种测试方式.RegDB数据集上有两种测试方式[35].1)可见光图像作为Query, 红外图像作为Gallery, 即可见光图像查找红外图像(visible2infrared).2)红外图像作为Query, 可见光图像作为Gallery, 即红外图像查找可见光图像(infrared2visible).
在2个公共数据集上, 都采用Rank-1, Rank-10, Rank-20和平均精度(Mean Average Precision, mAP)评价方法性能.
本文与文献[23]和文献[24]一样, 都采用在ImageNet数据库[36]上进行预训练过的ResNet50[37]作为骨架网络.ResNet50的5个块提取特征的通道数分别为64, 256, 512, 1 024, 2 048.提取模态特征使用层数为N的视觉Transformer网络, 本文N=4.在SCFIM模块中, 通道分为L=4组, 水平分为K=6块.网络输入图像的尺寸统一为288×144.
训练时采用随机裁剪、随机水平翻转进行数据增强, 裁剪前先对图像四周使用0值进行扩充(扩充的具体值为10像素), 再随机裁剪288×144的区域(如图3中红色虚线所示), 裁剪后图像有50%的概率进行随机水平翻转.数据增强的可视化过程如图3所示.
 | 图3 数据增强示例Fig.3 Example of data enhancement |
训练数据的批次大小(Batchsize)设为96, 对于每个批次, 在VI模态中随机选取6个行人身份, 每个行人身份选取8幅图像, IR模态进行同样选取.
本文采用Pytorch1.7学习框架, 在NVIDIA RTX3090 GPU平台完成实验.采用随机梯度下降(Stochastic Gradient Descent, SGD)优化策略优化网络, 动量(Momentum)设定为0.9, 初始学习率设为0.01, 每经过20代学习率衰减0.1, 共训练60代.
具体代码发布在https://github.com/YafeiZhang-KUST/CMReID.
本节选取如下方法进行对比实验, 对比各方法在2个公共数据集上的性能, 验证本文方法的有效性.
具体对比方法如下.
1)基于模态互转的方法: JSIA-ReID(Joint Set-Level and Instance-Level Alignment ReID)[9], AlignGAN(Alignment GAN)[10], XIV-ReID[14], DPJD[15], Hi-CMD(Hierarchical Cross-Modality Disentangle-ment)[38].
2)基于度量学习的方法:EAT+CMKD[16], DPAN+CMDC Loss[17], DMiR[18], cmGAN(Cross-Modality Generative Adversarial Network)[39], CPN(Cyclic Projection Network)[40], DFLN-ViT(Discri-minative Feature Learning Network Based on a Visual Transformer)[41].
3)基于特征对齐的方法:CMAlign[20], AGW (Attention Generalized Mean Pooling with Weighted Triplet Loss)[23], DDAG(Dynamic Dual-Attentive Aggregation Learning Method)[24], FBP-AL(Flexible Body Partition Model Based Adversarial Learning Method)[42], MAGC(Multi-hop Attention Graph Con- volution Network)[43], CMDSF(Cross-Modality Disen- tanglement and Shared Feedback)[44], DML(Dual Mutual Learning)[45].
各方法在RegDB数据集上的实验结果如表1所示, 表中黑体数字表示最优值, -表示原文献未提供数据.
| 表1 各方法在RegDB数据集上的实验结果对比 Table 1 Experimental result comparison of different methods on RegDB dataset % |
在visible2infrared模式下, 本文方法的Rank-1和mAP(对比实验中最重要的两个性能指标)达到最优值, 比次优方法DFLN-ViT分别提升3.02%和8.95%.
在infrared2visible模式下, 本文方法的Rank-1和mAP也达到最优值, 比DFLN-ViT分别提升3.21%和8.61%.
为了进一步验证本文方法的有效性, 在大数据集SYSU-MM01上进行对比实验, 结果如表2(All-Search模式)和表3(Indoor-Search模式)所示, 表中黑体数字表示最优值, -表示原文献未提供数据.
| 表2 各方法在SYSU-MM01数据集上All-Search模式下的实验结果对比 Table 2 Experimental results comparison of different methods in All-Search mode on SYSU-MM01 dataset % |
| 表3 各方法在SYSU-MM01数据集上Indoor-Search模式下的实验结果对比 Table 3 Experimental results comparison of different methods in Indoor-Search mode on SYSU-MM01 dataset % |
由表2和表3可见, 本文方法在All-Search模式下Rank-1和mAP达到最优值, 在Indoor-Search模式下, Single-Shot设置下的Rank-1与Multi-shot设置下的Rank-1和mAP也达到最优值.
1)在缓解模态差异方面, 相比其它方法, 本文方法创新有效.本文利用一个视觉Transformer提取模态信息, 再设计模态混淆分类器(两层卷积层加上一层全连接层), 将模态信息和ResNet50提取的身份信息送入模态混淆分类器.模态混淆分类器把模态信息分到VI模态类或IR模态类, 把身份信息分到既不是VI模态也不是IR模态的第3个类.在损失约束下, ResNet50在特征提取阶段忽略对模态信息的提取, 因此, ResNet50最终提取的是不包含模态信息的模态不变性特征.
2)本文的SCFIM模块不仅挖掘行人的细粒度信息, 同时也保证挖掘信息的一致性, 最终达到提升行人判别性的效果.
3)本文方法对特征不仅在水平层面上采用PCB(Beyond Part Models)[46]进行分块, 而且还进行通道上的分组, 特征划分的粒度更细, 使网络提取行人更具判别性的特征.
综上所述, 本文方法在两个公共数据集上取得良好效果, 并且在RegDB数据集上的实验结果验证本文方法的优越性, 在SYSU-MM01数据集上的实验结果验证本文方法的有效性.
为了验证MIFL模块和SCFIM模块的有效性, 将它们逐个加入基线网络中.其中, SCFIM模块由细粒度信息挖掘(FIM)和语义一致性约束(SCC)两部分组成.
本文在SYSU-MM01、RegDB数据集上进行消融实验.在SYSU-MM01数据集上, 消融实验在All-Search模式的Single-Shot设置下进行.在RegDB数据集上, 消融实验在visible2infrared模式下进行.
实验对比如下方法.1)Baseline(基线方法).使用ResNet50作为主干网络, 身份损失和中心三元组损失作为损失函数.2)Baseline+MIFL.3)Baseline+MIFL+FIM.4)Baseline+MIFL+FIM+SCC.
4种方法的消融实验结果如表4所示.在SYSU-MM01数据集上, 相比Baseline, Baseline+MIFL的Rank-1和mAP分别提升7.32%和8.03%, 这意味着MIFL达到缓解模态差异的作用.
| 表4 各方法在2个数据集上的消融实验结果 Table 4 Ablation experiment results of different methods on 2 datasets % |
加入FIM之后, Rank-1和mAP分别提升12.19%和9.75%, 说明FIM达到挖掘行人细粒度信息的目的.加入SCC之后, Rank-1和mAP再次提升5.48%和4.8%, 说明SCC确实起到约束行人细粒度语义一致性的作用.在RegDB数据集上也能得到类似的实验结果.
总之, 消融实验表明, 本文方法的每个模块在缓解模态差异或提升特征的辨别性方面都起到有效作用.
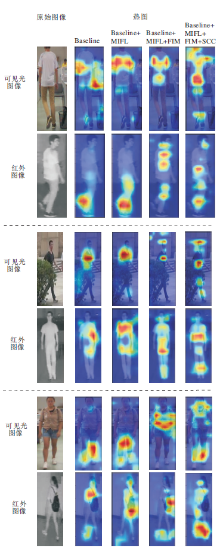
为了直观验证本文方法的有效性, 利用Grad-CAM(Visual Explanations from Deep Networks via Gradient-Based Localization)可视化方法[47], 在SYSU-MM01数据集上生成热图, 具体如图4所示, 图中颜色越深表示网络对该区域越关注.
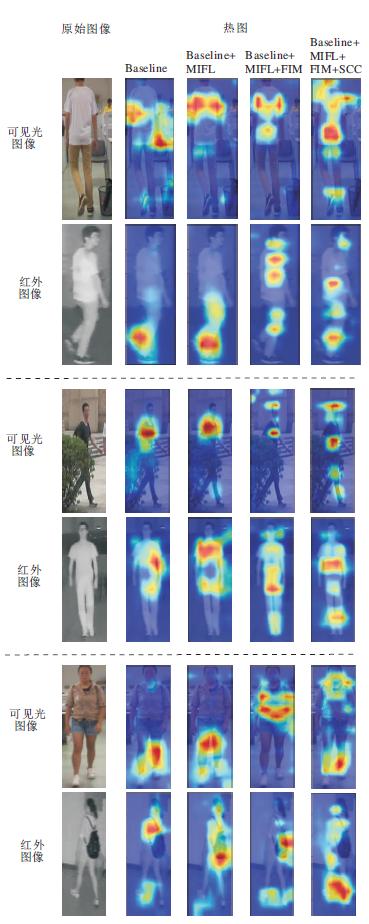 | 图4 各模块生成的热图对比Fig.4 Comparison of heat maps generated by different modules |
由图4可看出, 相比Baseline, Baseline+MIFL加深对模态不变性特征的学习, 但此时网络只关注行人少部分区域.加上FIM后, 网络关注行人更多的细粒度信息, 但存在多个细粒度块关注相同区域的情况和网络在两个模态下关注的行人局部区域是不同的问题, 即语义不一致.再加上SCC后可看出, 网络关注的行人细粒度信息变多且关注的局部区域相同.这表明加上SCC可解决网络在两个模态下关注信息冗余和行人语义不一致的问题.
为了进一步验证本文方法的有效性, 随机选择3个查询实例, 根据计算的余弦相识度得分, 选择前10个检索结果, 绿色框表示检索正确的图像, 红色框表示检索错误的图像.
由于SYSU-MM01数据集上有多个检索模式, 本文任选其中一个, 即选择在All-Search模式的Single-Shot设置下进行, 值得注意的是, 该模式下正确的检索图像最多为4幅, 具体检索结果如图5所示.
 | 图5 各模块在SYSU-MM01数据集上的检索结果Fig.5 Retrieval results of different modules on SYSU-MM01 dataset |
RegDB数据集只有2种检索模式, 在2种模式下正确检索图像最多均为10幅, 具体检索结果分别如图6所示.
 | 图6 各模块在RegDB数据集上的检索结果Fig.6 Retrieval results of different modules on RegDB dataset |
从图5和图6的可视化结果分析可得, 依次加上MIFL、FIM、SCC模块后, 检索的正确图像逐渐变多, 由此再次证实本文方法的有效性.
从近期工作[48, 49, 50, 51]中可知, 行人重识别网络提取的特征图中的特征通道与行人图像的局部区域之间存在对应关系.特征图是由输入图像或前一层的特征图利用不同卷积核进行特征映射得到的, 不同的卷积核可关注行人图像不同的区域, 因此特征图中不同的特征通道对行人局部区域的关注程度不同.本文对通道进行划分, 就能从特征层面关注行人的不同局部信息, 因此对通道划分是合理的.
对特征进行通道和水平层面划分的优势在于PCB仅从人体不同空间区域的视角将身体划分成头部、躯干等不同的部分, 而通道划分是从特征的视角对通道进行分组, 从而使网络关注不同的人体区域.将两者结合能更充分挖掘局部信息.
为了验证通道划分的优势, 将ResNet50最后一层输出特征的2 048个特征通道分别划分为2组、4组和8组.同时, 在SYSU-MM01数据集的 All-Search模式下进行实验, 结果如表5所示, 表中PCB表示仅进行水平层面的划分, CDi表示将特征通道划分为i(i=2, 4, 8)组, 黑体数字表示最优值.
| 表5 通道划分对性能的影响 Table 5 Effect of channel segmentation on performance |
由表5可见, 当通道分组数为4时, 方法性能最优.原因是不进行通道划分或通道分组数为2时, 网络在通道层面关注的局部区域偏少, 而分组数为8时, 会强制网络关注不重要的细粒度信息, 都会造成性能的下降.
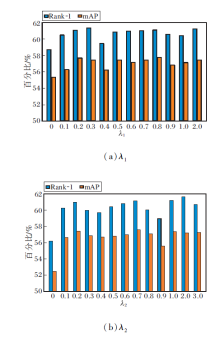
在SYSU-MM01数据集的All-Search模式的Single-Shot 设置下分析式(8)中λ1和λ2对方法性能的影响.
λ1影响三元组损失L'tri在总损失中的占比.设置λ1=0, 0.1, 0.2, …, 1.0, 2.0, Rank-1、mAP与λ1的关系如图7(a)所示, 当λ1=0.3时, Rank-1值最高, 因此, 将λ1设置为0.3.
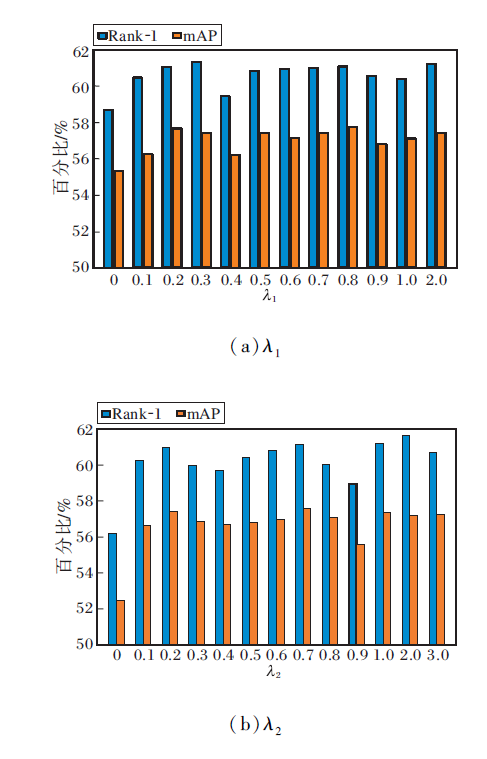 | 图7 超参数变化对方法性能的影响Fig.7 Effect of variation of hyperparameters on method performance |
λ2影响语义一致性损失Lde对总损失的贡献.设置λ2=0.1, 0.2, …, 1.0, 2.0, 3.0, Rank-1、mAP与λ2的关系如图7(b)所示.当λ2=0时, 方法失去语义一致性损失的约束, 导致性能较低, 随着该损失占比逐步变大时, 性能逐渐提升, 当λ2=2时, 性能最优.因此, 将λ2设置为2.
为了解决跨模态行人重识别中存在的模态差异问题和细粒度信息挖掘不充分的问题, 本文提出模态不变性特征学习和一致性细粒度信息挖掘的跨模态行人重识别方法, 侧重于提取模态不变性的语义一致的细粒度特征.具体地, 使用模态不变性特征学习模块去除特征图中的模态信息, 缓解模态差异, 在使用语义一致的细粒度信息挖掘模块挖掘行人细粒度信息的同时保持挖掘的语义一致性.在两个公共的红外-可见光跨模态数据集(SYSU-MM01和Reg-DB)上的实验表明, 本文方法性能较优.此外, 本文方法是一种端到端的网络, 不需要借助例如关节点提取、GAN这样的外部网络.这不仅大幅降低网络的复杂性, 而且还有利于在现实场景中进行部署.今后将在提升特征的判别性方面上进行进一步探索.
本文责任编委 徐 勇
Recommended by Associate Editor XU Yong
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|
| [49] |
|
| [50] |
|
| [51] |
|