


{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于相邻特征融合的红外与可见光图像自适应融合网络
[徐少平1  , 陈晓军
, 陈晓军1 , 罗洁2 , 程晓慧1 , 肖楠1 ]
, 陈晓军, 罗洁, 程晓慧, 肖楠]
|
|



作者简介:

陈晓军,硕士研究生,主要研究方向为图形图像处理技术.E-mail:401030920025@email.ncu.edu.cn.

罗 洁,学士,主要研究方向为医学图像处理技术.E-mail:406100210094@email.ncu.edu.cn.

程晓慧,硕士研究生,主要研究方向为图形图像处理技术.E-mail:406100210094@email.ncu.edu.cn.

肖 楠,硕士研究生,主要研究方向为图形图像处理技术.E-mail:406100210085@email.ncu.edu.cn.
为了获得目标边缘清晰且细节丰富的红外与可见光融合图像,以前馈去噪卷积神经网络(Denoising Convolutional Neural Network, DnCNN)的骨干网络为基础,从网络架构和损失函数两方面对其进行全面改进,提出基于相邻特征融合的红外与可见光图像自适应融合网络(Adjacent Feature Combination Based Adaptive Fusion Network, AFCAFNet).具体地,采取扩大通道数及双分支特征交换机制策略将DnCNN前段若干相邻卷积层的特征通道进行充分交叉与融合,增强特征信息的提取与传递能力.同时,取消网络中所有的批量归一化层,提高计算效率,并将原修正线性激活层替换为带泄露线性激活层,改善梯度消失问题.为了更好地适应各种不同场景内容图像的融合,基于VGG16图像分类模型,分别提取红外图像和可见光图像梯度化特征响应值,经过归一化处理后,分别作为红外图像和可见光图像参与构建均方误差、结构化相似度和总变分三种类型损失函数的加权系数.在基准测试数据库上的实验表明,AFCAFNet在主客观评价上均具有一定优势.在各项客观评价指标中综合性能较优,在主观视觉效果上,在特定目标边缘上较清晰、纹理细节也较丰富,符合人眼视觉感知特点.
About Author:
CHEN Xiaojun, master student. His research interests include graphics and image processing technology.
LUO Jie, bachelor. Her research interests include medical image processing technology.
CHENG Xiaohui, master student. Her research interests include graphics and image processing technology.
XIAO Nan, master student. His research interests include graphics and image proce-ssing technology.
To obtain an infrared and visible fusion image with clear target edges and rich texture details,a fusion network model, adjacent feature combination based adaptive fusion network(AFCAFNet) is proposed based on the classical feed-forward denoising convolutional neural network(DnCNN) backbone network by improving the network architecture and the loss function of the model. The feature channels of several adjacent convolutional layers in the first half of DnCNN network are fully fused by adopting the strategy of expanding the number of channels, and the abilities of the model to extract and transmit feature information are consequently enhanced. All batch normalization layers in the network are removed to improve the computational efficiency, and the original rectified linear unit(ReLU) is replaced with the leaky ReLU to alleviate the gradient disappearance problem. To better handle the fusion of images with different scene contents, the gradient feature responses of infrared and visible images are extracted respectively based on the VGG16 image classification model. After normalization, they are regarded as the weight coefficients for the infrared image and visible image ,respectively. The weight coefficients are applied to three loss functions, namely mean square error, structural similarity and total variation. Experimental results on the benchmark databases show that AFCAFNet holds significant advantages in both subjective and objective evaluations. In addition, AFCAFNet achieves superior overall performance in subjective visual perception with clearer edges and richer texture details for specific targets and it is more in line with the characteristics of human visual perception.
红外与可见光图像的融合技术在智能监控、目标监视、视频分析等领域具有广泛的应用前景, 有利于后续图像处理任务的执行, 能辅助人们更全面和直观地进行分析或决策.根据发展历程, 现有红外与可见光图像融合方法可划分为传统融合方法和基于深度学习的融合方法两类.
传统融合方法的执行流程大致可分为特征提取、特征融合和图像重构3个阶段[1, 2, 3].具体地, 此类融合方法通常首先利用某种图像变换方法将图像从空域转换到某个容易提取特征的转换域表示, 并提取相应特征, 然后利用某种融合规则将分别在源图像(红外图像和可见光图像)上提取的特征进行融合, 最后将融合后的特征逆变换回空域表示, 从而完成图像融合.Jin等[4]首先利用离散平稳小波变换(Discrete Stationary Wavelet Transform, DSWT)将源图像中的重要特征分解为一系列不同层次和空间分辨率的子图集合; 再利用离散余弦变换(Discrete Cosine Transform, DCT)根据不同频率的能量分离子图集合中的显著细节; 然后利用局部空间频率(Local Spatial Frequency, LSF)增强DCT系数的区域特征, 为了融合源图像中显著特征, 基于LSF预设阈值, 采用分段策略完成DCT系数融合; 最后, 依次执行DCT和DSWT的逆变换重构融合图像.任亚飞等[5]提出基于非下采样剪切波(Non-subsampled Shearlet Transform, NSST)多尺度熵的红外与可见光图像融合方法, 首先将源图像进行NSST多尺度分解, 得到高频信息与低频信息; 然后在不同尺度分别融合高频信息和低频信息, 融合时的权重值由多尺度熵确定; 最后将不同尺度的融合结果通过逆NSST变换获得融合图像.由此可见:在传统融合方法的框架下, 解决融合问题的关键在于如何有效地将红外与可见光图像场景内容表示为特征及设计合理的融合规则, 最大限度地在融合图像中保留两者之间互补性的内容, 而这些工作很大程度上依靠算法设计者积累的经验, 因此融合效果具有很大的局限性, 不能适应复杂的场景变化.
随着近年来深度学习技术的兴起及其在底层视觉(Low-level Vision)处理领域的成功应用, 研究者不断提出各类用于红外与可见光图像融合的网络并取得一系列的成果[6, 7, 8, 9, 10].根据红外和可见光图像特征融合阶段不同, 基于深度学习的融合方法可划分为如下3种.
1)早期融合.Ma等[6]提出Infrared and Visible Image Fusion via Detail Preserving Adversarial Lear-ning, 实现图像融合的网络架构仅是将网络输入改为可接受红外图像和可见光图像的双通道模式, 故对原骨干网络的改动较小, 实现简单.然而, 由于网络结构上几乎没有相应实现图像特征融合的机制, 不能较好地分别提取红外图像与可见光图像互补的有效信息, 故这类方法获得的融合效果较一般.
2)中期融合[7].Li等[8]提出DenseFuse用于红外和可见光图像融合, 网络由编码器、融合层和解码器组成.其中, 编码器由1个卷积核大小为3×3的卷积层和稠密块(Dense Block)组成, 稠密块中每层的输出都连接到其它网络层.相比文献[6]的网络结构, 使用稠密块能利用不同网络层上的特征信息, 有利于提取深度特征.然而任意层之间均建立连接关系并不能确保一定有利于提升特征融合的质量.融合层能实现若干不同类型的融合规则操作, 但融合层的网络结构还是相对简单.解码器由普通的连续4个卷积核大小为3×3的卷积层组成, 对融合后的特征进行调制并重构为融合图像.在损失函数方面, DenseFuse使用均方误差(Mean Squared Error, MSE)和结构相似性(Structure Similarity, SSIM)两种类型的损失函数, 在融合后图像与源图像之间进行约束.
3)后期融合[9].Li等[10]将多尺度注意机制集成到生成对抗网络(Generative Adversarial Networks, GAN)中, 提出AttentionFGAN(Infrared and Visible Image Fusion Using Attention-Based GAN).加入多尺度注意力机制的目的在于捕获更全面的空间信息, 使生成器聚焦于红外图像的前景目标信息和可见光图像中的背景细节信息, 而判别器更多地聚焦于注意区域而不是整个输入图像.在构建网络时, 将2个多尺度注意网络和1个融合网络共同组成AttentionFGAN的生成器.其中, 2个多尺度注意网络分别用于捕获红外图像与可见光图像的注意映射图, 随后通过融合网络将得到的注意映射图重构为最终的融合图像.虽然AttentionFGAN通过多尺度注意机制提取更多的重要信息, 但在并行的2个注意网络之间无任何约束, 而是通过融合网络获得融合图像.这并不能有效引导注意网络生成高质量的映射, 从而影响后继的融合效果, 这也是多数后期融合模型的弊端.
由上述工作可知:基于深度学习的融合方法在设计使用上都是较方便的.然而, 这也同时决定提升突破基于深度学习的融合方法性能的关键环节在于网络架构与损失函数设计两方面.网络结构设计方面决定红外图像和可见光图像特征提取与融合效果, 损失函数设计方面决定融合后图像的质量是否能达到最优.
为了最大限度地保留红外图像与可见光图像中的互补信息, 获得在各项客观评价指标上具有最佳综合优势的融合图像, 本文提出基于相邻特征融合的红外与可见光图像自适应融合网络(Adjacent Feature Combination Based Adaptive Fusion Network, AFCAFNet).首先, 在深入分析现有网络模型实现特征融合主要策略的基础上, 以网络拓扑结构简单的前馈去噪卷积神经网络(Feed-Forward Denoising Convolutional Neural Networks, DnCNN)[11]骨干网络为基础构建融合网络, 提出相邻特征融合(Adjacent Feature Fusion, AFF)模块, 用于网络中段之前各相邻卷积层上特征信息的融合, 减少网络在特征提取与融合过程中的信息丢失.然后, 组合利用MSE、SSIM和总变分(Total Variation, TV)3种类型损失函数构建总损失函数.为了让总损失函数在网络训练中发挥最佳的导引作用, 利用内容自适应权重分配, 根据红外图像和可见光图像中提取的特征响应, 分别为各类损失函数自动设置红外图像和可见光图像所占权重值.该权重系数值完全依据图像内容的特征响应以确定(特征响应值大小是由VGG16[12]图像分类网络模型提取并计算), 可让融合网络输出的融合图像获得符合人眼视觉感知特点的最优融合效果.实验表明:AFCAFNet在各项普遍采用的客观评价指标上更具综合优势, 在视觉效果方面也更符合人眼习惯.
由Zhang等[11]提出的DnCNN骨干网络原本被设计用于图像复原任务, 是深度网络成功应用于底层视觉图像处理的案例.DnCNN充分利用深度网络、残差学习和正则化技术.DnCNN骨干网络首先利用卷积层(Convolutional Layer, Conv)和修正线性单元(Rectifier Linear Unit, ReLU)处理输入图像, 再在Conv和ReLU之间加入批归一化(Batch Norma-lization, BN)操作, 减少内部协变量转移(Internal Covariate Shift)对网络参数选取的影响, 加快网络的收敛速度.通过连续的15个Conv+BN+ReLU和1个Conv卷积操作后, 得到残差估计, 输入图像和估计残差相减可得最后的图像, 其中网络中卷积层的卷积核大小为3×3.在网络训练阶段, 最小化残差图像和网络估计残差的均方误差以调整网络参数.
DnCNN作为经典的深度卷积神经网络架构, Conv+BN+ReLU核心模块在已提出的深度网络中占比较高, 研究者们在其基础上设计更多适合特定任务的变体.
根据基于深度学习融合方法中图像特征融合所在阶段(即早期、中期和后期)的不同, 各选择1个典型模型为例进行简要介绍.
Ma等[13]基于GAN, 提出FusionGAN, 旨在通过生成器生成一个具有红外图像中主要强度信息和可见光图像中额外梯度信息的融合图像, 判别器约束融合图像具有更多可见光图像的细节, 从而保证最终的融合图像同时保持红外图像中的热辐射信息和可见光图像中的纹理信息.此外, 生成器为几个简单的卷积层构成, 不同卷积层之间也无其它特殊处理.在损失函数的构建中, 生成器的损失函数除对抗损失外还加入信息损失项.信息损失由MSE和TV这两种损失项构成.
Ma等[14]提出STDFusionNet(Infrared and Visi-ble Image Fusion Network Based on Salient Target Detection), 首先通过两个并行的特征提取网络, 分别选择性地从红外图像和可见光图像中各自提取显著目标特征和背景纹理特征, 上述图像特征经过拼接(Concatenation, Concat)操作, 再由重构网络对提取的特征进行有效融合得到融合图像.具体地, STDFusionNet中的特征提取网络分支由1个Conv+LReLU(卷积核大小为5×5)组成的卷积层和连续的3个残差复合块构成, LReLU(Leaky ReLU)表示带泄露的修正线性单元.特征重构网络为4个残差复合块连接而成.残差复合块包含上下两分支, 上分支由Conv+LReLU+Conv+LReLU+Conv组成, 卷积核大小依次为1×1、3×3和1×1, 而下分支只是1个卷积核大小为1×1的卷积, 最后将上下分支得到的特征块相加后再接一个LReLU.在损失函数构建方面, STDFusionNet采用1范数分别约束融合图像和源图像之间的像素损失和梯度损失.
Zhang等[15]提出PMGI(Unified Image Fusion Net-work Based on Proportional Maintenance of Gradient and Intensity), 基于梯度与强度的比例, 利用两个分支网络(梯度路径和强度路径)对红外图像和可见光图像进行信息提取, 还利用PTB(Path-Wise Transfer Block)模块在两个特征提取分支网络之间相互交换信息.通过引入的PTB可完成梯度信息与强度信息的预融合工作, 还为后续的特征提取块提供额外信息.最终在网络末端将不同的特征信息联接后实现融合.通过2范数构建融合图像与源图像之间的强度损失和梯度损失, 构成模型的最终损失函数.
分析3种典型的融合网络结构(FusionGAN、STDFusionNet和PMGI)可知:这些网络的骨干核心结构均是基于DnCNN中的Conv+BN+ReLU复合结构, 通过设计具有不同卷积核大小的卷积层、替换激活层及改变重复次数等策略演化而来.
基于早期特征融合的网络架构首先将源图像按照某种融合策略进行直接融合, 由于图像没有专门独立的特征提取过程, 这一实现方案会引入源图像中大量的冗余信息, 导致后期图像重建任务复杂困难.
基于中期特征融合的网络架构首先对源图像分别进行特征提取, 再将提取到的特征按照设定的融合策略进行融合, 最后通过相对较复杂的特征重建模块, 将融合的特征重建为最终融合图像.虽然这种结构的融合框架避免早期特征融合结构中冗余信息的引入, 但特征融合模块相对而言还是较简单(往往就是简单的Concat操作), 导致图像特征的融合效果不佳, 后期重构融合图像的图像质量仍有待改进.
基于后期特征融合的网络架构构建相对较复杂的特征提取网络, 分别对源图像进行充分的特征提取, 并直接将提取的特征块融合并重构融合图像.这种后期融合的网络架构中图像重构模块的处理能力相对较弱, 导致最终的融合效果仍存在改进空间.
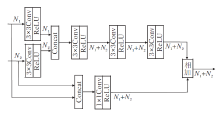
本文提出基于相邻特征融合的红外与可见光图像自适应融合网络(AFCAFNet), 框架如图1所示.
 | 图1 AFCAFNet框架图Fig.1 Framework of AFCAFNet |
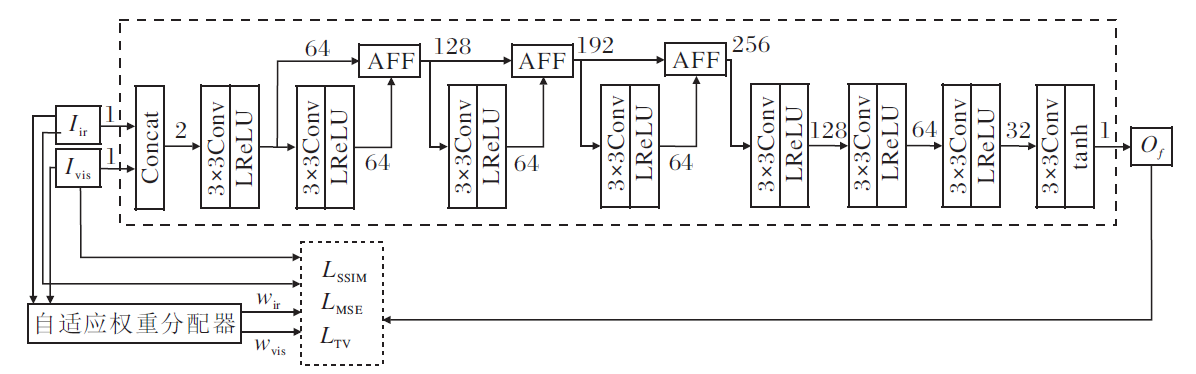
AFCAFNet同时接受红外图像和可见光图像, 在深度卷积神经网络海量参数作用下获得输出图像(即融合后图像).为了训练AFCAFNet, 基于MSE、SSIM和TV这3种类型损失函数构建总损失函数.为了让各损失函数自动设置红外图像和可见光图像所占权重值, 设计自适应损失函数权重分配器.该权重分配器利用VGG16网络分别提取红外图像和可见光图像不同网络层次上的特征, 在计算特征相应值并归一化处理后, 为红外图像和可见光图像分别生成相应的权重值wir和wvis.该权重值在各损失函数构建中发挥重要的调节作用, 能最大限度地将红外图像或可见光图像中显著的纹理细节信息保留在最终的融合图像中.
理论上, 主流的U-Net[16]、DenseNet(Dense Convo-lutional Network)[17]、ResNet(Residual Network)[18]等类型的卷积神经网络(Convolutional Neural Net-work, CNN)均可用于构建AFCAFNet骨干网络.现有主流的图像融合网络模型(即早期、中期和后期融合策略)均在特征提取、特征融合和融合图像重构这3个阶段存在不同程度的弱势, 导致最终的融合效果不佳.为此, 本文提出融合网络, 将提取的图像特征充分融合及融合后的特征经过相对复杂的重构过程调制, 从而确保最终的融合图像具有较高的图像质量.
如图1虚线框中主干网络所示, 经过大量实验和筛选, 本文选定以DnCNN为基础构建AFCAF-Net.AFCAFNet与DnCNN最大的区别如下.
1)输入端.将网络输入改为双通道输入, 允许同时接受红外图像和可见光图像.
2)新增AFF模块, 加强信息的传递能力.由于DnCNN骨干网络属于前馈型网络, 网络特征依次由前向后传递, 随着网络的深度增加, 不同卷积层输出的特征之间并未建立直接联系, 不利于充分融合特征.为此, 本文提出的AFF模块将上一个卷积层输出的特征信息与当前卷积层的输出进行融合后再传递到下一个卷积层.网络中标注的数字表示特征的通道数, 通道数从开始的2(表示待融合的2幅可见光图像和红外图像)依次递增到256, 然后逐层降低, 最终回落到1通道(即融合后图像).由此可见, 在网络的前段和中段, 图像特征在不断的提取和充分融合后再传递给下一层.而在网络的中后段, 融合后的网络特征在不断地逐层重构后传递给下一层, 最终获得融合图像.因此, AFCAFNet能保证图像融合模型中的特征提取、特征融合和融合图像重构三项任务均得到更有序均衡地执行.特别地, 就整个主干网络而言, AFCAFNet更容易搭建.
AFF模块框架图如图2所示.AFF模块的特征提取与融合过程分为如下两个分支执行.在第一分支中, 首先通过两个并行的卷积层分别提取两个输入端的特征信息(每个卷积层由卷积和激活函数构成), 再利用连续的三个卷积层对提取的特征信息进行再调制.在第二分支中, 将两个输入端直接Concat后共同输入一个卷积层中提取特征.最后, 将两个分支上提取的特征相加, 完成融合.
 | 图2 AFF模块框架图Fig.2 Framework of AFF block |
3)取消BN层.一般地, BN层能在训练时加快收敛, 同时提高训练效果.然而, 考虑到AFCAFNet主要利用通道数变化实现图像特征融合, 深度相对较浅而通道数较大, 所以为了节省计算开销未使用BN层.
4)替换ReLU层.为了解决ReLU层无法处理负值的问题, 替换为LReLU以解决梯度消失问题.
AFCAFNet执行的任务是图像融合, 其核心问题其实是在最终融合图像中调节红外图像和可见光图像对应像素点所占权重值.相比DnCNN的图像复原任务, AFCAFNet对网络的非线性映射能力要求更低, 故最终共使用8层卷积层.其中, 网络中段之前的4层用于特征提取与融合, 网络后段的4层卷积层用于融合后的特征信息再调制, 所以AFCAFNet采用的网络架构能确保特征提取、特征融合和融合图像重构3个子任务得到均衡的执行, 从而保证融合后图像的质量.
总之, 相对当前主流的融合网络, AFCAFNet的拓扑结构和实现复杂度相对较低, 但通过合理的网络结构与损失函数设计, 融合效果在各项客观评价指标上超越当前通用的融合网络.
VGG16最初用于图像分类, 主要提取反映图像内容的各网络层次上的特征响应.本文提出利用上述特征响应, 根据红外图像与可见光图像在相同特征层上的响应大小, 自适应生成红外图像与可见光图像分别在MSE、SSIM和TV损失函数中的权重系数.具体地, 共提取VGG16最大池化层前面的5个卷积层上的特征响应, 计算各损失函数中红外图像和可见光图像各自的权重系数.定义第i个卷积层上的特征响应为Fi(·), 这样红外图像与可见光图像在第i个卷积层上的特征响应分别记为Fi(Iir)和Fi(Ivis).因此, 第i个卷积层上拉普拉斯特征响应值为:
Ri(·)=
其中, Hi、Wi分别表示第i层特征的长和宽, C表示特征层的通道数,
R(·)=
基于上述定义, 将红外图像和可见光图像的总体特征响应值R(Iir)和R(Ivis)进行归一化处理, 得到最终权重系数:
wir=
归一化后的权重系数wir和wvis的值在[0, 1]内, wir+wvis=1.基于权重系数wir和wvis, 本文总损失函数定义为
LTotal=LSSIM+λ1LMSE+λ2LTV,
其中, λ1和λ2为超参数, 用于调节不同距离类型损失函数的权重.而MSE、SSIM与TV损失函数的定义如下:
LMSE=wirMSE(Iir, Of)+wvisMSE(Ivis, Of),
LSSIM=wir(1-SSIM(Iir, Of))+ wvis(1-SSIM(Ivis, Of)),
LTV=wirTV(Iir, Of)+wvisTV(Ivis, Of).
具体地, MSE、SSIM与TV函数的计算公式如下:
MSE(x, y)=‖x-y‖2,
SSIM(x, y)=
TV(x, y)=‖∂ x-∂ y‖1,
其中, ‖·‖2表示2范数操作, μx、 μy表示x、 y的平均值,
总之, 为了获得导引能力更强的损失函数, 本文综合采用MSE、SSIM和TV这3种损失函数.这是因为将MSE引入损失函数, 能在像素级别上约束图像之间的差异程度, 但仅靠MSE作为损失函数的网络融合结果并不符合人眼视觉习惯.考虑到SSIM能从亮度(Luminance)、对比度(Contrast)和结构(Stru-cture)度量图像局部结构, 于是在损失函数中加入SSIM, 使融合后的图像视觉效果更佳.此外, 在红外图像与可见光图像融合任务中, 融合图像中物体轮廓清晰与否是评判该图像质量优劣的一项重要标准.因此在损失函数中还引入TV损失项, 这是因为TV约束图像的梯度信息, 而梯度信息直接反映图像中物体的轮廓、边缘信息.特别地, 在每种损失函数的构建中, 根据人眼感知特性的不同, 为红外与可见光图像设置相应的权重值, 分别作用在MSE、SSIM和TV损失函数中.
为了全面对比AFCAFNet性能, 选择如下对比网络:RFN-Nest(End-to-End Fusion Network Archi-tecture)[7]、DenseFuse[8]、STDFusionNet[14]、PMGI[15]、GTF(Gradient Transfer Fusion)[19]、CSR(Convolu-tional Sparse Representation)[20]、DCHWT(Discrete Cosine Harmonic Wavelet)[21]、DDcGAN(Dual-Dis-criminator Conditional GAN)[22]和U2Fusion(Unified and Unsupervised End-to-End Image Fusion Net-work)[23].
测试图像包括RoadScene[23]、TNO[24]、VOT2020-RGBT数据集[25].RoadScene数据集包含221组红外与可见光图像, TNO数据集包含21组红外与可见光图像, VOT2020-RGBT数据集包含40组红外与可见光图像.
测试结果采用的客观评价指标分别为:熵(Entropy, En)[26]、标准差(Standard Deviation, SD)[27]、互信息(Mutual Information, MI)[28]、差异相关性之和(Sum of Correlations of Differences, SCD)[29]、多尺度结构相似性(Multi-scale SSIM, MS-SSIM)[30]、视觉信息保真度(Visual Information Fidelity, VIF)[31]和基于对比度失真的无参考图像质量度量(No-reference Image Quality Metric for Contrast Distortion, NIQMC)[32].指标值越高, 表明融合效果越优.此外, 融合后图像还采用人工视觉进行主观评价.
所有网络都在相同硬件平台(Intel(R) Xeon(R) CPU E5-1603 v4@2.80 GHz RAM 16 GB)和软件环境(Window10操作系统)上运行.
在本节中, 将对自适应权重分配器的效果、损失函数中超参数值的选择和AFF模块的效果进行实验验证.所有参数及各种网络结构下的训练结果均在TNO数据集上获得.
3.2.1 自适应权重分配器
有无使用自适应权重分配器的融合效果对比如表1所示, 表中N表示在损失函数中将wir和wvis设为0.5的情况(即不进行自适应调整), Y表示使用权重分配器自适应生成权重系数, 黑体数字表示最优值.由表1可知, 权重系数在Y模式下获得的各项评价指标均优于N模式, 这表明权重分配器能自动根据融合图像内容自适应生成权重系数, 优化损失函数对网络参数的导引能力, 保证融合图像获得更高的图像质量.
| 表1 有无使用自适应权重分配器的融合效果对比 Table 1 Comparison of fusion results with and without adaptive weight assigner |
3.2.2 损失函数
为了确定损失函数的组成项目, 对SSIM、MSE和TV这3种损失函数类型进行组合分析, 得到如表2所示的7种组合情况, 表中黑体数字表示最优值.这里, 参与组合的子损失函数权重均设置为1.由表2可看出, 以单个类型的损失函数作为网络损失函数时, SSIM的指标值相对较优.在此基础上添加MSE损失函数能使融合效果在7个指标上均有较大幅度的提升.虽然进一步添加TV损失函数后SD值有所下降, 但其它6个指标值均有所上升.因此, 确定AFCAFNet损失函数的组成形式为这3种类型损失函数的某种加权组合.
| 表2 不同损失函数组合模式下的融合效果对比 Table 2 Fusion result comparison of different combinations of loss functions |
在确定好损失函数的组合后, 为了最佳融合效果, 采用网格搜索法确定损失函数中超参数λ1和λ2的最优值.分别以步长0.5 和0.1 进行粗精两级搜索, 最终发现λ1=20, λ2=29.3时的融合结果在7个指标中均取得最优值.详细情况如表3所示, 表中黑体数字表示最优值.
| 表3 λ1=20, λ2不同时的融合效果对比 Table 3 Comparison of fusion results with different values of λ2 and λ1=20 |
3.2.3 相邻特征融合模块
为了进一步验证AFF模块的有效性, 将AFF直接替换成最简化的Concat操作(即仅完成特征信息的连接而不含特征信息交互机制), 保持其它参数不变训练替换后的网络, 将训练后的模型与AFCAFNet进行对比, 结果如表 4所示.由表4可知, 引入AFF模块后, 融合网络的性能在7项指标上均有提升.
| 表4 使用拼接操作和AFF模块的融合效果对比 Table 4 Fusion result comparison of concatenation operation and AFF block |
为了分析AFF模块两分支中用于特征信息调制的卷积个数对融合性能的影响, 设置不同的卷积个数, 具体结果如表5所示, 表中第1列卷积个数括号内的2个数字分别对应上、下两分支的卷积个数, 黑体数字表示最优值.由表5可看出, 当上、下两分支的卷积个数分别设置为3和1时, 所有指标值最高, 故在AFF模块中的卷积层个数最终采用这种配置.
| 表5 AFF模块中上下分支卷积个数不同时的融合效果对比 Table 5 Comparison of fusion results with different convolution numbers in upper and lower branches of AFF block |
3.2.4 主干网络结构
为了验证主干网络结构不同时的效果, 设计图3所示的4种网络结构, (a)、(b)、(c)和(d)网络结构中的最大通道数分别为128、192、256和320.具体地, 每个网络的特征提取层数量与特征重构层一致, 在相邻的两个特征提取层之间包含一个AFF模块, 并且在特征重构过程中, 通道数每次均减小为上一层的一半, 直至为1.
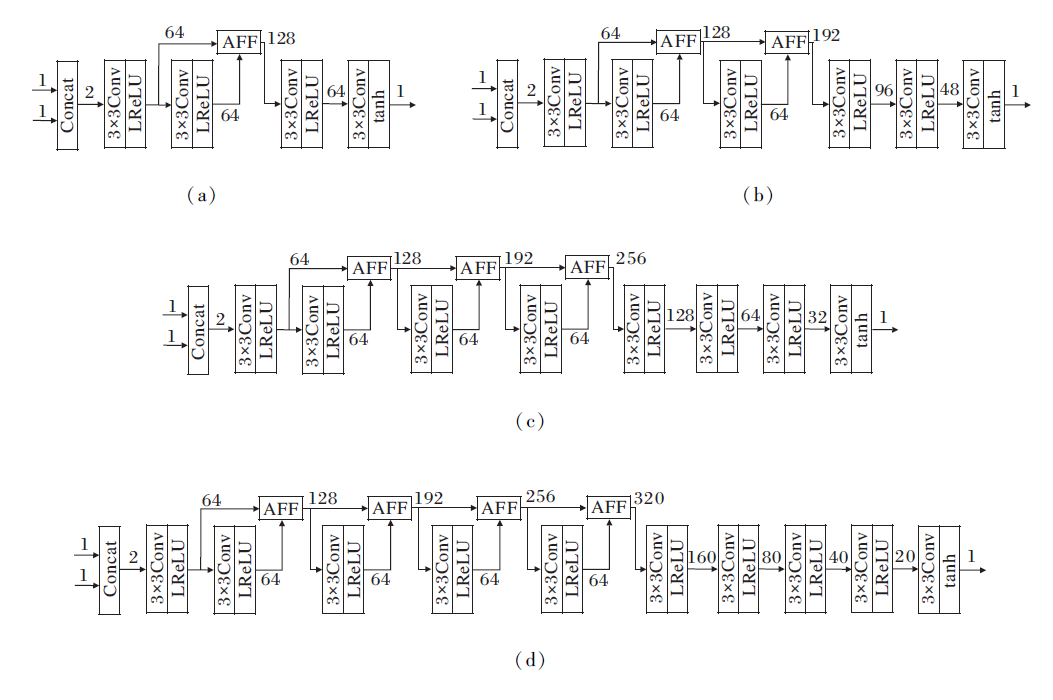 | 图3 不同深度的主干网络结构图Fig.3 Backbone network structures with different depths |
测试图3的四种网络结构, 具体融合效果如表6所示.由表可知, 图3(c)的网络结构在7个指标中均表现最优, 因此可采用这一网络结构作为AFCAFNet最终的网络配置.
| 表6 不同主干网络的融合效果对比 Table 6 Fusion result comparison of different backbone networks |
3.3.1 客观评价
为了全面客观对比AFCAFNet的融合性能, 在RoadScene、TNO、VOT2020-RGBT这3个基准测试集上进行对比实验, 结果分别如表7~表9所示, 表中黑体数字表示最优值.由表可见, 在3个数据集上, AFCAFNet在各项指标上共获得14次最优, STDFusionNet获得5次最优, RFN-Nest获得2次最优, 其它网络均未获得最优.所以, AFCAFNet具有最优的综合性能.需要特别指出的是, 即使获得数次最优的STDFusionNet和RFN-Nest都属于中期融合方法, 但其融合性能仍不如AFCAFNet.
| 表7 各网络在RoadScene数据集上的指标值对比 Table 7 Index values of different networks on RoadScene dataset |
| 表8 各网络在TNO数据集上的指标值对比 Table 8 Index values of different networks on TNO dataset |
| 表9 各网络在VOT2020数据集上的指标值对比 Table 9 Index values of different networks on VOT2020 dataset |
3.3.2 主观评价
为了直观评价各对比网络获得融合图像的融合效果, 进行人工视觉主观对比, 结果如图4所示, 重点观察图中矩形框内图像.由图4红色矩形框所在的区域可看出, GTF、DCHWT、STDFusionNet、DDc-GAN和U2Fusion的融合结果存在白化或物体偏暗的现象, DenseFuse、RFN-Nest的人物(蓝框内)不够清晰, PMGI不能较好保留可见光图像中的纹理信息(黄框内).尽管CSR取得较优效果, 但相比AFCAFNet, 在视觉效果上仍处于劣势.综上所述, AFCAFNet输出的融合图像具有目标对象轮廓更清晰、细节纹理更丰富的优势.
 | 图4 各网络在TNO数据集上的融合图像对比Fig.4 Fusion image comparison of different networks on TNO dataset |
本文在DnCNN骨干网络的基础上, 全面改进网络结构和损失函数, 提出基于相邻特征融合的红外与可见光图像自适应融合网络(AFCAFNet).在基准测试数据集上的实验表明, AFCAFNet输出的融合图像在主、客观指标上均具有一定优势.今后将进一步改进网络架构和损失函数, 提高网络的泛化能力, 以便将该网络推广到诸如多曝光图像、多模态医学图像等其它融合任务上.
本文责任编委 黄 华
Recommended by Associate Editor HUANG Hua
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|