



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于Vision Transformer的中文唇语识别
[薛峰1  , 洪自坤
, 洪自坤2 , 李书杰1 , 李雨2 , 谢胤岑2 ]
, 洪自坤, 李书杰, 李雨, 谢胤岑]
|
|



作者简介:

洪自坤,硕士研究生,主要研究方向为计算机视觉.E-mail:hongzikun@mail.hfut.edu.cn.

李书杰,博士,讲师,主要研究方向为计算机视觉、人体姿态估计.E-mail:lisjhfut@hfut.edu.cn.

李 雨,博士研究生,主要研究方向为计算机视觉.E-mail:yuli@mail.hfut.edu.cn.

谢胤岑,硕士研究生,主要研究方向为计算机视觉.E-mail:2021111090@mail.hfut.edu.cn.
唇语识别作为一种将唇读视频转换为文本的多模态任务,旨在理解说话者在无声情况下表达的意思.目前唇语识别主要利用卷积神经网络提取唇部视觉特征,捕获短距离像素关系,难以区分相似发音字符的唇形.为了捕获视频图像中唇部区域像素之间的长距离关系,文中提出基于Vision Transformer(ViT)的端到端中文句子级唇语识别模型,融合ViT和门控循环单元(Gate Recurrent Unit, GRU),提高对嘴唇视频的视觉时空特征提取能力.具体地,首先使用ViT的自注意力模块提取嘴唇图像的全局空间特征,再通过GRU对帧序列时序建模,最后使用基于注意力机制的级联序列到序列模型实现对拼音和汉字语句的预测.在中文唇语识别数据集CMLR上的实验表明,文中模型的汉字错误率较低.
About Author:
HONG Zikun, master student. His research interests include computer vision.
LI Shujie, Ph.D., lecturer. Her research interests include computer vision and human pose estimation.
LI Yu, Ph.D. candidate. Her research interests include computer vision.
XIE Yincen, master student. His research interests include computer vision.
Lipreading is a multimodal task to convert lipreading videos into text, and it is intended to understand the meaning expressed by a speaker in the absence of sound. In the existing lipreading methods, convolutional neural networks are adopted to extract visual features of the lips and capture short-distance pixel relationships, resulting in difficulties in distinguishing lip shapes of similarly pronounced characters. To capture the long-distance relationship between pixels in the lip region of the video images, an end-to-end Chinese sentence-level lipreading model based on vision transformer(ViT) is proposed. The ability of the model to extract visual spatio-temporal features from lip videos is improved by fusing ViT and Gate Recurrent Unit(GRU). Firstly, the global spatial features of lip images are extracted using the self-attention module of ViT. Then, GRU is employed to model the temporal sequence of frames. Finally, the cascading sequence-to-sequence model based on the attention mechanism is utilized to predict Chinese pinyin and Chinese character utterances. Experimental results on Chinese lipreading dataset CMLR show that the proposed model produces a lower Chinese character error rate.
唇语识别主要任务是基于说话人的视觉图像序列预测说话文本, 可应用在公共场所的无声听写、嘈杂环境下的语音识别、辅助听力和公共安全视频中的关键词识别等场景, 具有较高的应用价值[1].
人类通过听觉可轻易识别并理解说话人的话语, 然而仅通过观察说话人的唇部动作很难理解说话人的意图.人在说话时嘴唇运动幅度不大, 一个嘴唇动作不仅可对应多个不同的词, 而且每个人说同一个词的嘴唇动作也存在差异, 因此不管对于人类还是计算机, 唇语识别任务都面临较大挑战[2].
按照识别语言元素不同, 唇语识别可分为单词级识别和句子级识别.单词级识别任务中每个唇读视频对应一个单词, 具有固定的词库.Weng等[3]引入视频光流信息作为视频视觉特征, 提高单词识别的正确率.句子级别的唇语理解满足交流需要, 更具有应用价值, 其识别的一般流程为:首先预处理唇语视频, 裁剪视频帧的嘴唇区域; 然后由模型前端提取视频特征; 最后由模型后端解码得到预测文本.
在句子级唇语识别任务上, Assael等[1]提出LipNet, 以3D 卷积神经网络(3D Convolutional Neu-ral Network, 3D CNN)[4]作为视频的时空特征提取模块, 使用双向门控循环单元(Gated Recurrent Unit, GRU)[5]和CTC(Connectionist Temporal Classification)[6]解码得到唇读语句.CTC是一种编码方式, 可在无需对齐视频和文本序列的情况下实现变长序列的预测, 但缺少对语义信息的处理.Chung等[7]提出WLAS(Watch, Listen, Attend and Spell), 通过两个共用解码器的序列到序列模型(Sequence-to-Sequence)[8]分别处理唇读视频特征序列和音频特征序列, 得到上下文向量, 并联合注意力模块进行文本预测.Zhang等[9]使用TCN(Temporal Con-volutional Network)进行序列建模, 克服句子级唇读训练过程中的梯度消失问题, 提高收敛速度.Ma等[10]提出DS-TCN(Depthwise Separable TCN), 使用深度可分离TCN, 减少唇读模型的参数, 并以自身作为教师模型进行知识蒸馏, 实现模型优化.Ma等[11]还引入基于唇读视频音频模态的辅助任务和更多的额外数据, 提高唇读模型的识别能力.
按照识别语种不同, 唇语识别还可分为英文唇语识别[1, 7]和中文唇语识别[12, 13].目前英文唇语识别研究已取得较大发展, 而对中文唇语识别的关注较少.中文唇语识别和英文唇语识别在处理流程上具有明显差异.具体而言, 传统英文唇语识别通常把唇读视频作为输入, 生成以词或字符为单位的句子.而汉字是一种象形文字, 拼音表示发音, 因此中文句子唇读任务通常分为拼音预测和汉字预测两个阶段.Zhang等[12]提出LipCH-Net, 在从新闻联播节目收集的数据集上进行训练.LipCH-Net是一个分两步进行训练的架构, 首先分别训练从视频序列到拼音和拼音到汉字这两种不同模型, 然后再将两个模型进行联合优化, 得到最终的识别模型.Zhao等[13]公开大规模的句子级别中文普通话唇语识别数据集CMLR, 视频来自CCTV新闻联播.同时, 作者提出CSSMCM(Cascade Sequence-to-Sequence Model for Chinese Mandarin), 利用中文特有的拼音和音调信息, 级联3个序列到序列模型, 分别渐进地推理语句的拼音、音调和汉字, 实现端到端的训练.使用表示发音的信息作为中间结果的策略也被应用在英文唇语识别中, Deng等[14]将代表发音且边界更短的音素作为中间结果的预测单元, 提高英文结果的识别准确性.
现有视觉特征提取模型的空间建模大多数是基于2D CNN或3D CNN架构.Chung等[15]使用堆叠的2D CNN VGG(Visual Geometry Group), 从嘴唇图像中提取特征, 并对比不同的视频帧特征融合策略对唇语识别正确率的影响.Stafylakis等[16]使用3D CNN提取视频的时空特征, 再通过2D的ResNet(Residual Network)传递每个时间步的特征并预测, 在唇读模型中结合2D卷积和3D卷积.Xu等[17]提出LCANet, 使用堆叠的3D CNN和高速公路网络自适应组合嘴唇局部特征, 提高视觉特征的建模能力.Jeon等[18]为了解决唇语识别视觉信息不足的挑战, 提出融合不同3D CNN模块的架构, 获得更好的视觉和运动信息表示, 进一步提升唇语识别效果.由此可见, CNN的卷积计算能捕获像素之间的结构信息, 较好地提取唇部视觉特征.
然而, 受到卷积核大小的限制, CNN通常只能关注短距离像素之间的结构, 难以捕获远距离像素之间的关系, 造成唇语识别任务中相似发音字符的识别效果不佳.这是因为相近发音的字符在表达时嘴唇的局部图像具有相似性, 它们的差异主要体现在嘴唇发音时的整体运动, 因此区分这些字符需要同时关注不同距离区域的唇形.通常, CNN架构对图像特征的提取是基于局部性的归纳偏置, 这种对局部像素的卷积计算难以挖掘唇形的整体差异, 导致识别精度的下降.
针对上述问题, 本文基于Vision Transformer(ViT)[19]架构在提取图像全局视觉特征的优异表现, 提出基于Vision Transformer的中文唇语识别模型(Chinese Lipreading Network Based on Vision Trans-former, ViTCLN), 融合ViT和GRU, 分别提取视频序列的高质量空间特征和时间特征.其中ViT可处理原始图像块的线性映射, 它的自注意力机制允许关注图像中长距离的像素间关系, 动态计算区域之间的权重, 提取嘴唇区域整体视觉特征, 提高区分唇形的能力.此外, ViTCLN以级联序列到序列模型作为中文文本解码模块, 通过注意力模块实现视频、拼音和汉字序列的对齐.在中文句子级唇语识别数据集上的实验表明, ViTCLN具有较好的中文唇语识别性能.
本节提出基于Vision Transformer的中文唇语识别模型(ViTCLN), 完整模型架构如图1所示.首先使用ViT捕捉视频每帧图像全局细节的空间特征表示.然后, 使用循环神经网络(Recurrent Neural Network, RNN)[20]构建图像帧空间特征的时间序列关系, 得到视频中唇部动作的视觉空间特征和时序特征的联合表示.最后, 使用级联的序列到序列模型预测说话人的文本, 预测分为拼音和汉字两个阶段.
 | 图1 ViTCLN的模型架构图Fig.1 Structure of ViTCLN |
1.1.1 视频预处理
本文将裁剪唇读视频得到的嘴唇区域帧序列作为预处理的输入数据, 使模型集中关注嘴唇区域信息.具体地, 使用Face Alignment人脸检测库提取视频帧的人脸唇部特征点, 并基于这些唇部特征点确定嘴唇区域, 最终裁剪得到嘴唇居中的图像序列, 大小为128×64像素.
1.1.2 视频帧嵌入
基于Transformer[21] 架构, ViT将图像按块(Patch)划分构建与自然语言处理中相似的线性映射序列, 实现标准 Transformer在图像处理上的原生应用.相比传统卷积操作, ViT的自注意力模块根据整幅图像计算动态权重, 有助于获得说话人唇部区域像素之间的更大范围、更远距离的结构关联信息, 因此能获得更具表达能力的视觉空间特征.
由于Transformer架构需要输入嵌入向量序列, ViT将每个输入视频序列x∈RW×H×C划分为固定大小的块序列xp∈RN×(P×P×C), 其中W、H表示视频帧的宽、高, C表示视频帧的通道数, N表示块数, P表示块边长.本文采用16×16像素的块大小.然后, ViT利用一个可学习的线性投影E将图像块映射到嵌入向量, 作为Transformer的标准输入.同时在嵌入向量序列中引入分类标记zcls, 用于生成图像表示.ViT对图像块的理解依赖位置嵌入Epos, 因此模型使用实现简单且性能出色的一维位置嵌入, 将图像块视为有序的一维序列, 并将位置嵌入叠加到嵌入向量上.完整的嵌入向量序列为:
z0=[zcls,
其中np表示图像块长度.
1.1.3 ViT编码器
视频嵌入序列z0输入ViT的Transformer层叠编码器模块中, 其中每个编码器层都由多头自注意力模块和前馈网络两部分构成, 同时还引入残差连接和层归一化.
多头注意力模块基于多头注意力机制[21], 允许模型关注来自不同位置的不同表示子空间的信息.
自注意力模块将输入序列z生成query Q, key K和value V三个矩阵, 通过点积计算query与当前key的相关程度, 缩放得到权重系数, 并对value进行加权, 得到自注意力输出向量.自注意力权重的计算过程如下:
$\text{Attention}(Q, K, V)=softmax(\frac{Q{{K}^{T}}}{\sqrt{d}})V$
其中d表示输入序列z中向量的长度.
多头注意力机制扩展自注意力机制, 对输入序列进行h次自注意力计算, 将多个输出结果拼接后通过WMHA投影得到最终输出向量.每个头都使用3个可学习的投影WQ、WK和WV, 将Q、K、V投影到不同的向量空间.多头注意力模块为:
MHA(Q, K, V)=[head1, head2, …, headh]WMHA,
其中
headi=Attention(QW
每个编码器层包含一个前馈网络, 由两层全连接层(Fully Connected Layers, FC)构成, 使用 GeLU(Gaussian Error Linear Unit)[22]激活函数转换输出.前馈网络为:
FFN(x)=FC(GeLU(FC(x))).
综上所述, 块嵌入序列在ViT模块经过L个编码器层计算, 并使用层归一化提高网络的泛化能力.计算过程如下:
z'l=MHA(LN(zl))+zl,
zl+1=FFN(LN(z'l))+z'l,
其中, LN(·)为层归一化, zl为第l层Transformer编码器输入, l=0, 1, …, L-1.
把Transformer编码器分类标记的最终输出
y=FC(LN(
对视频序列x1, x2, …, xnf的每帧都使用ViT模块并行计算, 得到特征表示构成视觉特征序列y1, y2, …,
1.1.4 时序特征提取
在视觉的空间特征表达的基础上补充和增强在时序维度的特征表示, 有助于提高唇语识别的精度.使用ViT模块提取的视觉特征, 只能表示唇部区域的空间特征, 无法表示不同帧之间嘴唇运动变化特征, 因此需要获取视频帧的视觉特征之间的时序关系.
GRU是RNN[22]的一种变体, 在时序建模上解决传统RNN 长期记忆能力不足的问题, 同时避免梯度消失和梯度爆炸, 广泛应用于自然语言处理、语音识别等序列处理任务.双向GRU 包含两层隐藏层, 可在时间维度的正反方向上处理输入序列.ViTCLN使用两层双向GRU向视觉特征中融合视频的上下文, 弥补时序特征的不足, 得到视频的融合空间和时间维度的特征序列
ev={
文本解码部分负责将视觉模态的时空特征转换为文本模态的表示.
1.2.1 序列到序列模型
序列到序列模型作为一种编码器-解码器架构, 常用于文本解码.由GRU作为编码器处理输入向量ein, 计算隐藏层向量
$\begin{align} & {{(h_{e}^{in})}_{i}}=\text{GRU}_{e}^{in}({{(h_{e}^{in})}_{i-1}}, e_{i}^{in}) \\ & e_{i}^{out}=\text{Embedding}(ou{{t}_{i}}) \\ & {{(h_{d}^{out})}_{i}}=\text{GRU}_{d}^{out}({{(h_{d}^{out})}_{i-1}}, e_{i-1}^{out}) \end{align}$
其中, in表示输入模态, out表示输出模态, i表示GRU的时间步, Embedding(·)表示嵌入函数, 将文本字符映射到向量空间.
为了进一步利用输入向量包含的信息, 本文引入注意力机制, 处理编码器输出的隐藏层向量.具体地, 在解码器的每个时间步上, 注意力模块会计算编码器上所有隐藏层输出的权重, 生成上下文向量辅助解码器预测.注意力模块Attn的权重为:
$\text{Attn}=softmax(\text{FC}(\tanh (\text{FC}(\text{Concat}({{(h_{d}^{out})}_{i}}, h_{e}^{out})))$
加权得到的注意力上下文向量:
(
其中Att
1.2.2 级联文本预测
由于拼音类别更少, 与发音的唇形关联性更强, 更容易预测拼音, 因此将拼音预测作为中间阶段能保证中文唇语识别的精度.本文使用视频到拼音和拼音到汉字两个序列到序列模块级联, 汉字解码器除了需要关注拼音隐藏层序列, 同样也需要关注视频隐藏层序列, 融合视频和拼音信息进行预测.
级联序列到序列模块包含三个注意力模块:视频编码器和拼音解码器之间的注意力模块Att
以视频特征序列ev和拼音特征序列ep分别作为两个序列到序列模块的输入, 应用式(1)得到的注意力上下文向量和两者的解码器GRU输出拼接, 计算每个时间步输出模态字符的概率分布:
$\begin{align} P({{p}_{i}}|{{p}_{<i}}, x)=softmax(\text{FC}({{(h_{d}^{p})}_{i}}, {{(c_{p}^{v})}_{i}})) \\ P({{c}_{i}}|{{c}_{<i}}, x)= softmax(\text{FC}({{(h_{d}^{c})}_{i}}, {{(c_{c}^{p})}_{i}}, {{(c_{c}^{v})}_{i}})) \end{align}$
其中,
在文本解码阶段, 模型通过两个子网络预测视频中的拼音和汉字, 因此目标是通过模型训练最大化拼音和汉字的条件概率, 即最小化两者的目标函数, 分别定义如下:
$\begin{align} & {{L}_{pinyin}}=-\sum\limits_{n=1}^{{{n}_{t}}}{\log P({{p}_{n}}|x, {{p}_{1}}, {{p}_{2}}, ...}, {{p}_{n-1}}) \\ & {{L}_{character}}=-\sum\limits_{n=1}^{{{n}_{t}}}{\log P({{c}_{n}}|x, {{c}_{1}}, {{c}_{2}}, ...}, {{c}_{n-1}}) \\ \end{align}$
其中, p={p1, p2, …, pn-1}表示拼音序列, c={c1, c2, …, cn-1}表示汉字序列.
为了同时提高拼音和汉字预测的准确性, 本文联合优化两个目标函数, 最终的损失函数如下:
L=Lpinyin+Lcharacter.
目标函数计算中会忽略标签填充的影响, 使用Adam(Adaptive Moment Estimation)优化器优化, 并裁剪梯度.
本文使用CMLR数据集[13]验证ViTCLN的有效性.CMLR数据集是目前可获取的最大中文句子级唇语识别数据集, 由超过十万个新闻联播说话视频构成, 包含11位说话人, 共有394类拼音和3 517类汉字字符, 字典覆盖范围广(同时也意味着存在更多的同音字).CMLR数据集的视频帧率为25 fps, 帧长从15帧到223帧不等, 最长的句子可达29个汉字.
目前公开的中文句子级唇语识别数据集较少, 本文另外选取英文句子级唇语识别数据集GRID[23]、英文和中文单词级唇语识别数据集LRW[15]和LRW-1000[24], 验证本文视觉提取模块的鲁棒性和泛化性.在英文句子级数据集上的实验简化文本解码器, 只使用单个基于注意力机制的序列到序列模块.在单词级数据集上的实验将序列到序列模块替换为分类网络.在实验中仅使用数据集上的视频数据.
在句子级数据集使用的词汇表中, 除了原有的字符之外, 还包含3个额外标记:<sos> , <eos> 和<pad> , 分别表示句子的开始, 结束和填充.为了避免消融实验中简单增加模型参数量带来的性能影响, ViT模块中Transformer的输入向量长度设置为192, 并使用在ImageNet2012数据集上预训练的ViT模型作为初始模型.
模型训练时, 为了提高收敛速度和稳定性, 本文采用学习率预热策略, 学习率在前5个轮次线性增长到基本学习率.使用Scheduled Sampling策略[25]训练模型, 利用真实标签引导预测, 消除训练和测试中的差异, 采样率为0.5.此外, 采用学习率衰减优化, 基础学习率为0.000 3, 当错误率不再下降时, 学习率降低为原来的一半.
本文通过编辑距离计算预测语句的错误率以衡量语句的正确性, 定义为使预测语句变换为标签语句所需的最少操作次数.编辑距离会找出将预测语句变换到标签语句所需的3种基本编辑操作:替换(S)、删除(D)和插入(I).可得错误率(Error Rate, ER)为:
ER=
其中N表示标签语句的长度.错误率越低表明模型预测性能越优.拼音错误率(Pinyin ER, PER)、字符错误率(Character ER, CER)和词错误率(Word ER, WER)分别为拼音、汉字字符和单词在预测结果和标签之间的编辑距离.本文使用PER、CER和WER作为句子级数据集上模型性能的评价指标.此外, 在单词级数据集上使用正确率(Accuracy, ACC)作为评价指标.
本节对比ViTCLN和经典唇语识别模型, 评估本文模型性能.具体基线模型如下所示.
1)LipNet[1].端到端英文句子级唇语识别模型, 利用CTC解决文本序列的对齐问题.
2)CALLip[2].使用属性学习模块提取说话人的身份特征, 消除跨说话人的差异.在训练过程中, 在视觉信号和音频信号之间设计对比学习, 加强对视觉特征的辨别.
3)WAS(Watch, Attend and Spell)[7].利用视频信息, 基于注意力的序列到序列模型预测句子, 在对比中只使用Watch的视频信息.
4)TCN[9].基于3D CNN、ResNet50、TCN和CTC模块, 使用TCN部分消除RNN梯度消失和性能不足的缺陷.
5)DS-TCN[10].基于深度可分离时空卷积(Depth-wise Separable TCN), 并通过自我蒸馏的方式在迭代中学习原有唇读模型.
6)LipCH-Net[12].端到端中文句子级唇语识别模型, 以VGG和ResNet提取视觉特征.在训练时, 采用两种模型分别进行视频到拼音和拼音到汉字两个阶段的预测, 然后进行联合优化.
7)CSSMCM[13].采用VGG提取视觉特征, 使用多个序列到序列模型依次预测拼音、音调和汉字序列, 同时使用注意力机制对齐之前生成的序列.
8)LIBS(Lip by Speech)[26].知识蒸馏方法, 将预训练模型作为教师模型, 从序列、上下文和帧级多种尺度的层面上进行知识蒸馏.
9)InvNet[27].改进传统卷积操作, 在减少模型参数的同时, 保证唇读模型的性能.
10)SE-ResNet[28].训练中引入图像混合、标签平滑、词边界等策略, 降低唇读模型的训练难度.
11)3DCvT(A Lip Reading Method Based on 3D Convolutional Vision Transformer)[29].使用Trans-former处理3D CNN提取的特征图, 作为视觉特征.
ViTCLN和基线模型在各数据集上的实验结果如表1和表2所示, 其中, PER列中-表示对应模型不包含预测拼音的步骤而直接预测汉字, WER列中-表示原文献中无此结果.
| 表1 各模型在CMLR、GRID数据集上的性能对比 Table 1 Performance comparison of different models on CMLR and GRID datasets % |
由表1可见, ViTCLN性能最优, 在CMLR测试集上达到24.94%的PER 和26.87%的CER, 相比CSSMCM, PER和CER分别下降31%和17%.ViTCLN在GRID测试集上的WER达到1.09%, 为最优值.
由表2可见, ViTCLN在单词级数据集LRW和LRW-1000上也取得和基线模型相当的性能, 可应用于不同的唇语识别任务, 从而验证本文视频特征提取模块的鲁棒性和泛化性.
| 表2 各模型在LRW、LRW-1000数据集上的ACC对比 Table 2 ACC comparison of different models on LRW and LRW-1000 datasets % |
不合适的学习率会使模型无法收敛, 同时, 训练初期使用较大的学习率, 可能导致模型参数优化方向的不稳定.为了对比基础学习率和预热轮次两个超参数对ViTCLN的影响, 分别调整学习率和学习率预热轮次, 在CMLR数据集上进行实验, 结果如下所示.当基础学习率分别为1e-4, 3e-4, 5e-4, 7e-4时, CER为27.73%, 26.87%, 32.31%, 44.55%.当预热轮次分别为0, 3, 5, 7时, CER为30.02%, 28.48%, 26.87%, 27.03%.因此, 当基础学习率为3e-4, 预热轮次为5时, 模型性能最优.
为了验证视觉空间特征提取模块ViT和时序特征提取模块GRU的有效性, 构建如下变体模型:1)模型1.ViT模块替换为2D CNN, 移除GRU模块.2)模型2. ViT模块替换为3D CNN, 移除GRU模块.3)模型3.保留ViT模块, 移除GRU模块.4)模型4.ViT模块替换为2D CNN, 保留GRU模块.5)模型5.ViT模块替换为3D CNN, 保留GRU模块.6)模型6.ViTCLN.
各模型在CMLR、GRID数据集上的性能对比如表3所示.各模型训练过程中, 在CMLR验证集上的错误率下降曲线如图2所示.
| 表3 各模型在CMLR、GRID数据集上的性能对比 Table 3 Performance comparison of different models on CMLR and GRID datasets % |
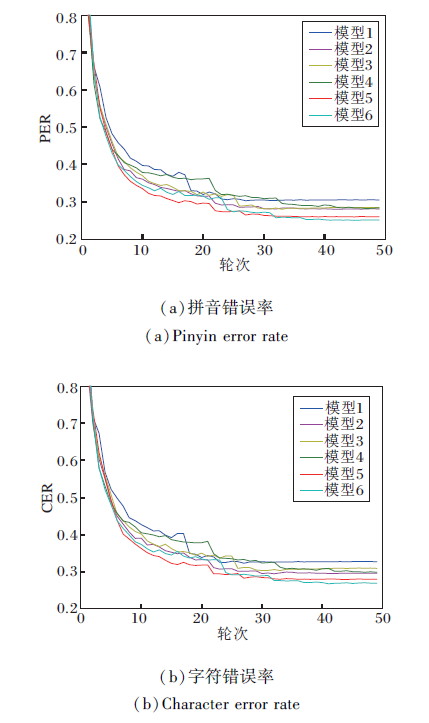 | 图2 各模型在CMLR训练集上的错误率下降曲线Fig.2 Decreasing curves of error rate for different models on CMLR training set |
由表3和图2可知, 模型4和模型5分别将ViTCLN中用于提取视频特征的ViT模块替换为2D CNN和3D CNN, CER均高于ViTCLN.ViTCLN在CMLR、GRID数据集上均取得最优值, 表明ViT捕获嘴唇的整体视觉空间特征, 相比CNN架构, 具有更高的区分度.
相比模型4~模型6, 模型1~模型3的错误率显著上升, 这是因为它们移除时序特征提取GRU模块, 说明GRU模块可有效捕获视频帧序列的时间关系, 并且为文本解码提供运动信息.
在去除GRU的模型中, 3D CNN前端(模型2)优于ViT前端(模型3), 这是因为3D CNN具有一定的时序图像处理能力, 而ViT虽然具有优秀的视觉特征提取能力, 但其独立处理视频帧, 导致缺少序列信息的捕获.因此GRU在模型中与ViT形成互补模块, 在序列任务中额外挖掘时序关系供编解码器处理具有必要性.
为了分析各模块对模型复杂度的影响, 相同条件下模型4~模型6在CMLR数据集上的参数量和训练时间如表4所示.
| 表4 各模型在CMLR数据集上的参数量和训练时间 Table 4 Parameters and training time of different models on CMLR dataset |
ViTCLN的文本解码模块级联两个编解码器, 少于CSSMCM的三个.在后端模块相同的情况下, CNN模型使用和ViT模型参数量相近的模块, 对模型带来的性能差异并非由增加参数量带来的.变体模型的训练时间相近, 由于2D CNN和ViT需要对每帧图像前向计算, 因此相比3DCNN, 需要更多的训练时间.
上述消融实验表明, ViTCLN中的ViT和GRU组合结构既可充分捕获说话时唇部区域图像像素的长距离视觉特征, 也可有效建模不同图像帧之间的运动关联关系, 得到最佳的唇语识别效果.
为了定性分析模型效果, 本文从CMLR数据集的测试结果中选取部分案例进行对比分析.各模型预测得到的句子如表5所示, 表中黑体字符表示预测错误的字符.由表可见, 在第1个案例上, 基于CNN的模型在拼音和汉字上均产生错误预测.模型2对时间特征提取不足导致未实现拼音和汉字的对齐, 模型4和模型5没有区分字符拼音“ su” 和“ zu” 的差异, 两者的声母均为平舌音, 发声时嘴唇相似性较高, 导致中文的词预测错误, 需要关注唇形的整体形状和变化才能正确识别.在案例2的句子识别中, 基于CNN的模型错误地将“ tong guo” 识别成韵母相同的“ gong zuo” , 以及将“ tong” 识别成声母发音相似的“ tou” , 声母或韵母的相似发音方式使唇形从视觉上更难区分.模型3虽然正确识别汉字“ 通过” , 但仍出现预测错误, 这可能是由于缺少上下文关联信息.ViTCLN正确识别这些相近发音的字符, 降低中文唇语识别的错误率.
| 表5 各模型在CMLR数据集上的预测结果对比 Table 5 Prediction result comparison of different models on CMLR dataset |
为了分析不同变体模型下输入图像对预测结果的贡献程度, 本文使用显著性图[30]进行可视化分析, 结果如图3所示.像素的显著性反映其对字符分类评分的贡献, 其中模型4和模型5得到的显著性区域包含大量远离唇部的面部区域, 然而这些区域对识别唇语的影响较小.ViTCLN使用自注意力机制对图像整体计算权重, 所得图像的显著性区域集中在唇部附近的块中, 而背景和脸颊等区域显著性较低, 对预测结果的贡献更准确.
 | 图3 各模型的显著性图Fig.3 Saliency maps of different models |
本文将变体模型在CMLR测试集上得到的易混淆音字特征可视化以观察其分布情况.选择表5中案例2产生混淆的拼音“ tong” 、“ gong” 和“ tou” , 特征来自于拼音解码器的输出特征, 降维后绘制散点图, 如图4所示.这些易混淆音字的区分是唇语识别的难点所在, 在图4(a)、(b)中, 案例2标签中拼音“ tong” 的特征整体上较分散, 部分特征分布在其它拼音聚类中, 容易发生混淆.在图4(c)中, 拼音“ tong” 的特征相对聚集, 不同拼音特征聚类的可区分程度更高.
 | 图4 各模型的易混淆音字特征分布图Fig.4 Distribution of confused phonetic features of different models |
在CMLR数据集上, ViTCLN的文本预测模块使用3个注意力机制, 提高视频特征序列和拼音序列对预测结果的贡献, 有效性体现在注意力权重矩阵和序列的对齐上.
为了可视化理解这些注意力机制的作用, 本文根据3个注意力机制计算得到的注意力权重矩阵绘制图5所示的热力图.图中每行表示解码器预测该字符时, 在编码器输出结果上的注意力权重, 图5(a)、(b)中高亮区域意味着在视频的这几帧中, 说话人正在讲这些字.同时, 每个字符覆盖的连续几帧符合每个字符的发声时间窗口, 这也会帮助解码器更准确预测序列中的每个字.得益于ViTCLN提取的空间特征和时间特征, 级联序列到序列模块的注意力模块具有更好的对齐效果.
 | 图5 注意力权重可视化热力图Fig.5 Heatmaps of attention weight visualization |
在图5 (c)中预测第i个汉字时, 拼音编码器的第i+1个隐藏层输出最大注意力权重, 其中包含GRU编码器计算得到的语义信息, 并据此将拼音映射为合理的汉字语句.
本文研究ViT在句子级别中文唇语识别中的应用, 提出基于ViT的中文唇语识别模型(ViTCLN).通过ViT的图像映射和自注意力机制, 提取全局的嘴唇图像特征, 避免CNN的归纳偏置和卷积的局限性.ViTCLN融合ViT和GRU, 实现对唇读视频视觉和运动信息的准确理解, 通过互补的时空特征提高唇读发音的区分度.最后通过级联序列到序列模型对齐拼音和汉字预测结果, 实现更准确的中文唇语识别.在最大的公开句子级别中文唇语识别数据集CMLR上的实验表明, ViTCLN性能较优.进一步的消融实验表明, ViT在视觉特征提取方面比CNN架构更出色.此外, 本文为了降低训练和预测的计算需求, 使用复杂度最低的ViT变体, 选择更长的向量表征可能会获得更优效果.今后将考虑从减少不同说话人差异带来的视觉影响展开研究, 进一步提高唇读模型的泛化能力.
本文责任编委 张军平
Recommended by Associate Editor ZHANG Junping
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|