

{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于全局多尺度特征融合的伪装目标检测网络
[童旭巍1  , 张光建
, 张光建1 ]
, 张光建]
|
|



作者简介:

童旭巍,硕士研究生,主要研究方向为图像处理、机器学习.E-mail:1124694813@qq.com.
在伪装目标检测中,由于伪装目标的外观与背景相似度极高,很难精确分割伪装目标.针对上下文感知跨级融合网络中,高层次语义信息在向浅层网络融合传递时因被稀释及丢失而导致精度降低的问题,文中提出基于全局多尺度特征融合的伪装目标检测网络.先设计全局增强融合模块,捕捉不同尺度下的上下文信息,再通过不同的融合增强分支,将高层次语义信息输送至浅层网络中,减少多尺度融合过程中特征的丢失.在高层网络中设计定位捕获机制,对伪装目标进行位置信息提取与细化.在浅层网络中对较高分辨率图像进行特征提取与融合,强化高分辨率特征细节信息.在3个基准数据集上的实验表明文中网络性能较优.
About Author:
TONG Xuwei, master student. His research interests include image processing and machine learning.
In the detection of camouflaged object, it is difficult to segment camouflaged object accurately due to the high similarity between appearance and backgrounds. In context-aware cross-level fusion network, the high-level semantic information is diluted and lost when it is transmitted to the shallow network fusion, resulting in the reduction of accuracy. Aiming at the problem, an camouflaged object detection(COD) network based on global multi-scale feature fusion(GMF2Net) is proposed. Firstly, the global enhanced fusion module(GEFM) is designed to capture the context information at different scales, and then the high-level semantic information is transmitted to the shallow network through different fusion enhanced branches to reduce the feature loss during multi-scale fusion. The location capture mechanism is designed in the high-level network to extract and refine the location of the camouflaged object, and feature extraction and fusion for high-resolution images are carried out in shallow network to enhance high-resolution feature details. Experiments on three benchmark datasets show that GMF2Net produces better performance.
伪装目标是指那些与背景高度相似, 或被背景遮挡的对象.它们通常会与环境巧妙融合, 让自身的颜色、姿态等与环境高度相似, 从而伪装自身, 难以被发现.例如, 生活在沙漠中的蜥蜴、冰层上的北极熊及穿迷彩服的士兵等, 都被称为伪装目标.
伪装目标检测(Camouflaged Object Detection, COD)旨在检测视觉场景中的伪装目标, 并与背景分割.COD比显著目标检测更具有挑战性.
近年来, COD渐渐引起研究者的兴趣, 除了本身具有的科学研究价值以外, 还可应用于计算机视觉(如搜救工作、珍稀动物的发现), 医学图像分割(如息肉分割[1]、肺部感染分割[2]、视网膜图像分割), 农业检测(灾害检测[3]、蝗虫检测[4]), 艺术处理(逼真混合、娱乐艺术)等领域.但是, 由于伪装目标与背景之间的高度相似性, 想要消除视觉上的歧义, 突出伪装目标与背景之间的关系, 并彻底分割是一件具有挑战性的事情.
早期的COD工作主要还是依赖于手工制作的纹理[5]、凸度[6]、颜色、边界等底层特征以区分前景和背景, 受到很多限制, 在伪装目标与环境融合较深、前景与背景高度相似的复杂场景下, 基于手工提取特征的方法往往会失效.
近年来, 随着深度学习的蓬勃发展, 研究者们提出许多有效的COD方法, 并取得良好效果.Yan等[7]观察到翻转的图像能帮助检测伪装目标, 提出MirrorNet, 将原始图像和翻转后的图像作为输入数据.Fan等[1]提出PraNet(Parallel Reverse Attention Network), 先预测粗略区域, 再细化边界.Li 等[8]提出联合SOD(Salient Object Detection)和COD的对抗性网络, 利用矛盾信息增强SOD和COD.Yang等[9]提出UGTR(Uncertainty-Guided Transformer Rea-soning), 首先学习骨干输出的条件分布, 获得初始估计和相关的不确定性, 然后通过注意力机制对这些不确定性区域进行推理, 产生最终预测.Ji等[10]提出ERRNet(Edge-Based Reversible Re-calibration Network), 设计SEA(Selective Edge Aggregation)和RRU(Reversible Re-calibration Unit)两个模块, 模拟视觉感知行为, 实现对伪装区域与背景之间的边缘识别.Mei等[11]提出分心挖掘策略, 并用此策略构建PFNet(Positioning and Focus Network).Fan等[12]提出SINet(Search Identification Network), 模仿猎人狩猎的过程, 使用搜索模块与识别模块定位和识别伪装目标, 并收集第1个用于伪装目标检测的大规模数据集COD10K.COD10K数据集包含真实自然环境下的各种伪装属性.Sun等[13]提出C2F-Net(Context-Aware Cross-Level Fusion Network), 设计两个跨级融合模块, 融合不同尺度的特征.同样地, Guo等[14]提出DADNet(Dilated-Attention-Defor-mable ConvNet), 有效学习多尺度特征的视觉上下文线索, 利用不同扩张率的尺度感知的注意力融合, 捕获有效信息.Li等[15]将时间序列进行多尺度提取, 逐步补充时间上下文以获得查询活动的位置, 展现多尺度融合网络的有效性.
尽管上述方法在COD上取得良好效果, 但大多数方法在面对一些具有挑战性的场景时, 检测性能会下降.由于在多尺度融合网络中, 高层的特征图提取网络的层数过深, 以及卷积层和池化层的使用, 会让特征图损失部分高层次语义信息, 导致检测结果不理想.高层次语义信息在向浅层网络传递, 自顶向下进行多尺度融合时, 较深层次获取的位置信息也会被逐渐稀释, 浅层网络获取的高层次语义信息不足, 从而导致网络的检测能力下降.并且伪装目标特征信息中存在大量噪声, 如何精细化特征信息也成为一个问题.因此, 研究者们在COD上还有较大的探索与改进空间.
为此, 本文以Sun等[13]的工作为基础, 设计全局增强融合模块与定位与捕获机制, 提出基于全局多尺度特征融合的伪装目标检测网络(COD Net-work Based on Global Multi-scale Feature Fusion, GMF2Net).首先使用多层次骨干网络提取多尺度特征, 将最高层次特征通过全局增强融合模块(Global Enhanced Fusion Module, GEFM), 用于捕捉不同尺度的高层次全局语义信息, 再将捕捉的高层次语义信息送至浅层网络, 与注意诱导跨层融合模块(Attention-Induced Cross-Level Fusion Module, ACFM)输出的特征进行融合, 融合后的特征通过双分支全局上下文模块(Dual-Branch Global Context Module, DGCM)挖掘丰富的全局上下文信息, 细化伪装目标.并且, 本文在高层网络中利用定位模块(Posi-tioning Module, PM)与聚焦模块(Focus Module, FM)设计定位与捕获机制, 对伪装目标进行定位与细化, 为后续的融合提供有效的先验信息.在浅层网络中对较高分辨率图像进行特征提取与融合, 提取高分辨率特征细节, 减小细节的退化而导致的图像模糊问题.在3个广泛使用的基准数据集上的实验证实GMF2Net的性能较优.
本文提出基于全局多尺度特征融合的伪装目标检测网络(GMF2Net), 网络整体架构图如图1所示.首先采用Res2Net-50[16]在5个不同尺度层提取特征, 特征图分别表示为Fi∈RH×W×C, i=1, 2, …, 5表示不同尺度层的层数, H表示高度, W表示宽度, C表示通道数, 5个尺度层的通道数分别为64, 256, 512, 1 024, 2 048.将最高层次提取的特征F5送入金字塔池化模块(Pyramid Pooling Module, PPM)[17], 提取不同尺度上下文信息, 并将通道缩减为64.将特征F2~F5依次输入RFB模块(Receptive Field Block)[18], 通过扩大感受野, 获取特定层中更丰富的特征, 通道缩减为64.经过RFB模块后的特征再经过定位模块(PM)与注意诱导跨层融合模块(ACFM)自顶向下进行特征融合, 并且在通过双分支全局上下文模块(DGCM)之前, 将PPM模块捕获的高层次语义信息通过3个不同的特征增强分支与ACFM输出的特征进行融合, 在进行3次迭代后, 输出预测图.RFB、ACFM、DGCM具体参数设置与文献[14]保持一致.
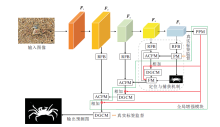 | 图1 GMF2Net架构图Fig.1 Structure of GMF2Net |
Res2Net-50提供一个自底向上提取多层次不同尺度特征的主干网络.然而, 在特征自顶向下进行传递时, 高层次语义信息会逐步稀释, 特别是在深层次的网络中, 多层次卷积的使用到最终图像的恢复, 高层次语义信息会越来越少, 难以捕捉图像的全局信息.而高层次语义信息往往包含潜在的伪装目标的位置信息.因此, 本文设计全局增强融合模块(GEFM), 用于增强浅层网络中的高层次语义信息, 减少在多尺度特征融合时特征信息的损失.
具体地, GEFM模块主要包括3部分:PPM模块, 特征增强分支部分, 相加融合部分.
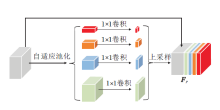
PPM模块可进行不同尺度不同接收场的特征提取, 增强伪装目标具有的全局上下文语义信息.PPM模块结构如图2所示, 采用的PPM参数设置与PSPNet(Pyramid Scene Parsing Network)[17]保持一致.
 | 图2 金字塔池化模块结构图Fig.2 PPM structure |
PPM模块包含1个主分支和4个自适应池化分支, 用于处理5个尺度的特征Pi∈RH×W×C, i=1, 2, …, 5.主分支P1为恒等映射, 4个副分支P2~P5进行自适应池化, 尺寸分别为1×1, 2×2, 3×3, 6×6, 输出的特征图Fpi都进行1×1的卷积以减少通道数.然后通过双线性差值进行上采样.此过程可描述如下.
Fp1=Conv1×1(F5),
Fp2=Up(Conv1×1(AvgPool1×1(F5))),
Fp3=Up(Conv1×1(AvgPool2×2(F5))),
Fp4=Up(Conv1×1(AvgPool3×3(F5))),
Fp5=Up(Conv1×1(AvgPool6×6(F5))),
其中, Up(·)为双线性差值上采样操作, Conv1×1(·)为1×1的卷积操作, AvgPooli×i(·)为尺度为i×i的自适应池化操作.最后将Fp1~Fp5进行拼接, 输出通道为64, 得到最后的特征图:
Fp=Cat(Fp1, Fp2, Fp3, Fp4, Fp5),
其中Cat(·)为通道间的级联操作.
与PSPNet中的PPM模块不同, 本文的PPM模块放置在最高层特征输出F5上, 作为主干网络中额外的特征提取模块, 扩大最高层次的感受野, 捕捉不同尺度丰富的全局上下文信息.
特征增强分支部分将PPM模块捕获的高层次语义信息通过不同上采样尺度的特征增强分支进行组合连接, 并直接通过图2中的3个分支将高层次语义信息依次送入浅层网络中, 与浅层网络中特征图进行相加融合, 得到特征图:
F
其中, i=1, 2, 3, 4, 5, 为第i层的尺度层, F
上述方式可增强多尺度特征融合过程中包含的全局语义信息, 提高伪装目标分割的精度.
动物在捕捉猎物时, 首先会通过观察定位清楚猎物所在的位置, 再出击进行捕获.通过模仿动物捕猎或人眼定位伪装物体的过程, 对伪装目标进行位置信息的提取与目标的细化工作, 为后续的融合提供有效的先验信息.受到文献[12]的启发, 本文在高层网络中利用定位模块(PM)与聚焦模块(FM)设计定位与捕获机制.
PM模块通过通道注意力机制与空间注意力机制, 捕获通道和空间位置方面的长期依赖关系, 获取语义增强的高级特征, 并进一步生成初始分割图, 此处PM模块采用与文献[11]相同的设置, 放置在第5尺度层, 接收来自RFB处理后的最高层特征.
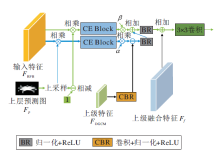
FM模块放置在PM的下一层, 目的是发现并消除错误预测(假阳性与假阴性的预测).FM模块将输入特征、上级特征和预测结果作为输入, 输出细化后的特征和更准确的预测结果.
本文改进FM模块, 为了增强融合后的语义信息与保证融合后特征的平滑, 本文加入上级融合后的特征, 并进行一个3×3的卷积后再输出.
FM模块的结构图如图3所示.FM模块首先对上层的预测图进行上采样, 并归一化.然后, 分别生成前景关注特征和背景关注特征.最后, 将这两种类型的特征输入两个平行的上下文语义探索模块(Context Exploration Block, CE Block)中进行推理, 分别发现假阳性和假阴性.CE Block由4个上下文探索分支组成, 每个分支包括3×3卷积、Ki×Ki卷积及扩张率为Ri的扩张卷积, 其中K=1, 3, 5, 7, R=1, 2, 4, 8, i=1, 2, 3, 4.然后经过逐元素减法消除假阳性(歧义背景), 通过归一化和ReLU函数激活后再进行逐元素的加法补充假阴性(缺失的背景), α 、 β 为可学习的比例参数.最后再通过一次归一化与ReLU激活, 加入上级融合的特征后进行一次3×3的卷积操作后输出特征.CE Block可描述如下:
FCE1=CE(1-Up(FP)),
FCE2=CE(FRFB$\otimes$Up(FP)),
Fout=Conv3×3(BR(β FCE1⊕
BR(CBR(FDGCM)-α FCE2))⊕Ff),
其中, $\otimes$为相乘, Conv3×3(·)为3×3的卷积操作.
 | 图3 聚焦模块结构图Fig.3 FM structure |
如图1所示, 提取的特征F4、F5通过RFB提取更丰富的特征, 然后F4通过ACFM模块, F5通过PM模块.ACFM模块对来自RFB模块与PM模块的特征有效融合跨级别特征, 可利用多尺度信息缓解尺度变化, 获得基于信息注意的融合特征, 再与来自GEFM模块的特征融合, 送入DGCM模块, 挖掘更丰富的上下文信息, 增强融合后的特征, 最后送入FM模块进行细化与融合.同样, 通过PM模块获得的特征与预测图会传输到第4尺度层的FM模块进行融合.具体过程可描述如下:
$\boldsymbol{F}_{4}^{\prime}=\operatorname{RF} B^{4}\left(\boldsymbol{F}_{4}\right), $
$\boldsymbol{F}_{5}^{\prime}=\operatorname{RF} B^{5}\left(\boldsymbol{F}_{5}\right), $
$\boldsymbol{F}_{\mathrm{ACFM}}^{4}=A C F M^{4}\left(\boldsymbol{F}_{4}^{\prime}, P M\left(\boldsymbol{F}_{5}^{\prime}\right)\right), $
$\boldsymbol{F}_{f}^{4}=\boldsymbol{F}_{\mathrm{ACFM}}^{4} \oplus U p(P P M), $
$\boldsymbol{F}_{\mathrm{DGCM}}^{4}=D G C M^{4}\left(\boldsymbol{F}_{f}\right), $
$\boldsymbol{F}_{\mathrm{FM}}=\operatorname{Conv}_{3 \times 3}\left(F M\left(\boldsymbol{F}_{4}^{\prime}, \boldsymbol{F}_{\mathrm{DGCM}}^{4}, \boldsymbol{F}_{P}\right) \oplus \boldsymbol{F}_{f}\right), $
其中Ff为第4尺度层全局增强模块融合后的特征.
实验平台的操作系统为Ubuntu 16.04.7 LTS, 配置Python 3.8环境.基于PyTorch框架实现网络模型, 计算机显卡型号为NVIDIATeslaT4 16GB.采用Res2Net-50在ImageNet上的预训练模型作为主干网络, 初始学习率为1e-4.训练过程中采用“ Poly” 学习率衰减策略, 在迭代30次后衰减为初始的0.1.使用AdaX[20]作为优化器, 迭代次数设置为40, 批量化大小设置为16, 聚焦模块中参数α 与β 初始值设置为1.
本文在3个公共数据集上评估网络性能.由于伪装目标检测数据集较少, 这也是COD领域目前使用最广泛的3个基准数据集.
1)CAMO数据集[21].包含1 250幅图像(训练集1 000幅, 测试集250幅), 8个类别.
2)CHAMELEON数据集(https://www.polsl.pl/rau6/chameleon-database-animal-camouflage-analysis).包含76幅图像, 是一个小数据集, 通过谷歌搜索收集, 全用于训练与测试.
3)COD10K数据集[12].包含5 066幅伪装图像(训练集3 040幅, 测试集2 026幅), 分为5个大类和69个子类, 是目前最大的COD数据集.
为了进行较好的全面综合对比, 采用目前COD使用最广泛的4个指标对网络进行评估分析, 具体如下.
1)E-measure[22].增强的对齐度量, 结合局部像素与图像级平均值, 可同时考虑局部信息和全局信息.具体表示为
E=
其中, φ s为增强的校准矩阵, 反映预测图S和真实标签G减去其全局平均值后的相关性, W为宽度, H为高度.
2)S-measure[23].基于结构的度量, 考虑对象感知(So)和区域感知(Sr)结构的相似性.具体表示为
S=α So+(1-α )Sr,
其中α 根据经验设置为0.5.
3)Weighted F-measure[24].综合考虑加权精度和加权召回的整体性能度量.具体表示为
F
其中,
Precision=
TP为真正例, TN为真反例, FP为假正例, FN为假反例, β 2为一个权衡参数, 设置为0.3.
4)平均绝对误差(Mean Absolute Error, MAE)[25].评估归一化预测和真实标签值之间的平均像素级相对误差.具体表示为
MAE=
其中, G为真实标签, S为预测图, W为宽度, H为高度.
下面将GMF2Net预测图像进行可视化, 与C2F-Net[13]进行定性对比, 结果如图4所示, 由图可看出, GMF2Net的检测结果和真实标注之间具有更高的视觉一致性, 在融合高层次特征之后, 加强图像特征中的上下文联系, 预测区域比C2F-Net更准确、广泛, 并且对于边缘及一些图像细节的预测也更精细.但对于一些极其有挑战性的图像, 如遮挡、边缘对比度模糊的图像, 也存在边缘部分预测不完全及预测失败的情况.
 | 图4 GMF2Net和C2F-Net的定性对比Fig.4 Qualitative comparison between GMF2Net and C2F-Net |
为了验证GMF2Net性能, 选择如下对比网络:PraNet[1], MirrorNet[7], PFNet[11], SINet[12], PSPNet[17], F3Net(Fusion, Feedback and Focus for Salient Object Detection)[19], PiCANet(Pixel-Wise Contex-tual Attention Network)[26], PoolNet[27], BASNet(Boundary-Aware Network)[28], EGNet(Edge Gui-dance Network)[29], MGL(Mutual Graph Learning Model)[30], 文献[31]网络.各网络在3个数据集上的指标值对比如表1所示, 表中黑体数字表示最优值.由表可看出, GMF2Net优于其它网络.在CHAMELEON数据集上的E-measure值达到0.954, 并且在3个数据集上都能取得较优效果.
| 表1 各网络在3个数据集上的指标值对比 Table 1 Index value comparison of different networks on 3 datasets |
本节首先对主干网络层数进行消融实验, 采用Res2Net-50与Res2Net-101两个骨干网络, 在3个数据集上进行实验, 对比结果如表2所示, 表中黑体数字表示最优值, 由表可看出, 主干网络为Res2Net-101的网络在场景最复杂且种类较多的COD10K数据集上的表现优于主干网络为Res2Net-50的网络, 在更复杂、种类更多的数据集上, 增加网络的卷积层数, 能捕获更深层次的上下文信息.但是对于场景种类较简单的CHAMELEON、CAMO数据集, 太多层的卷积会产生过拟合现象, 产生更多参数, 造成信息冗余, 导致性能差于主干网络为Res2Net-50的网络.所以从评价指标、网络参数、运行效率综合考虑, 最终采用Res2Net-50作为主干网络.
| 表2 主干网络不同时的指标值对比 Table 2 Index value comparison of different backbone networks |
下面讨论改变FM模块与PM模块的位置对网络性能的影响.在实验中, 将之前放置在第5尺度层的PM模块放置在第4尺度层的RFB模块与ACFM模块之间, 将FM模块放置在第3尺度层, 其它各模块的输入输出与原位置保持一致.
各模块训练得到的结果如表3所示, 表中黑体数字表示最优值.由表可见, 放置在第3尺度层的FM模块与第4尺度层的PM模块(PM4, FM3)虽然能实现大部分指标的提升, 但是与GMF2Net的性能仍有一定差距.在较低层次的语义信息通道数较少, 主要侧重于图像细节, 而更高层次的特征信息却包含轮廓、纹理及潜在的位置信息等, 因此放置在最高层次的PM模块更能捕获伪装目标的位置信息, 达到更优效果.
| 表3 PM模块和FM模块位置不同时的指标值对比 Table 3 Index value comparison of PM module and FM module at different positions |
最后, 为了验证本文设计的模块与机制的有效性, 探究高低层特征信息与特征提取细化方式的影响, 对各模块进行消融实验, 结果如表3所示, 表中黑体数字表示最优值.
由表3可见, 在baseline基础上, 在最高层次中添加PM模块, 通道注意力机制与空间注意力机制对深层次位置信息的获取有利于网络性能提升.在PM模块的基础上, 加入与之相配的FM模块, 绝大部分指标都有所提升, 这表明FM模块的有效性.虽然在极个别指标出现下降, 但移除假阳性的本身方法是合理有效的, 这是由于加入未细化处理的RFB模块输入特征以挖掘假阳性, 在极其复杂的场景下, 一定程度上增大假阳性发现的难度.当保留所有的模块(本文完整网络)时, 在加入GEFM模块后, 各项指标几乎都有提升, 这也证实全局信息对于网络性能提升的有效性.相比baseline, 在融入高层次信息与改变特征提取细化的方式之后, 各项指标均有较好提升.
| 表4 各模块的消融实验结果 Table 4 Ablation experiment results of different modules |
本文提出基于全局多尺度特征融合的伪装目标检测网络(GMF2Net).本文设计的全局增强融合模块, 可捕获丰富全局信息并传送到浅层网络进行融合, 减少高层次信息损失.通过设计的定位捕获机制, 捕捉伪装目标的位置信息和进一步的特征细化.在3个基准数据集上的实验表明, 本文网络性能较优.今后将进一步研究COD特征融合方法与特征提取方法, 以及边缘特征用于COD方法性能的提升.
本文责任编委 张军平
Recommended by Associate Editor ZHANG Junping
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|