{kind=link}
标签指导的双注意力深度神经网络模型
[彭展望1  , 朱小飞
, 朱小飞1 2 ]
, 朱小飞, 郭嘉丰]
|
|


通信作者:

朱小飞,博士,教授,主要研究方向为自然语言处理、数据挖掘、信息检索.E-mail:zxf@cqut.edu.cn.
作者简介:

彭展望,硕士研究生,主要研究方向为自然语言处理、数据挖掘.E-mail:51190324101@2019.cqut.edu.cn.

郭嘉丰,博士,研究员.主要研究方向为数据挖掘、信息检索.E-mail:guojiafeng@ict.ac.cn.
在数据集不包含标签文本信息时,现有的显式交互分类模型无法显式计算文本单词和标签之间的语义关系.针对此问题,文中提出标签指导的双注意力深度神经网络模型.首先,提出基于逆标签频次的自动类别标签描述生成方法,为每个标签生成特定的标签描述,用于显式计算文本单词与标签之间的语义关系.在此基础上,使用文本编码器学习具有上下文语境信息的评论文本表示,并提出标签指导的双注意力网络,分别学习基于自注意力的文本表示和基于标签注意力的文本表示.然后,使用自适应门控机制融合这两个文本表示,得到文本最终表示.最后,使用两层前馈神经网络作为分类器,进行情感分类.在3个公开的真实数据集上的实验表明,文中模型分类效果较优,可减少计算代价和训练时长.
Corresponding author:
ZHU Xiaofei, Ph.D., professor. His research interests include natural language processing, data mi-ning and information retrieval.
About Author:
PENG Zhanwang, master student. His research interests include natural language processing and data mining.
GUO Jiafeng, Ph.D., professor. His research interests include data mining and information retrieval.
Since the text information of labels is not included in some datasets, the semantic relationship between text words and labels cannot be explicitly calculated in the existing explicit interactive classification models. To solve this problem, a label-guided dual-attention deep neural network model is proposed in this paper. Firstly, an automatic category label description generation method based on inverse label frequency is proposed. According to the label description generation method, a specific label description for each label is generated. The generated specific label description is applied to explicitly calculate the semantic relationship between text words and labels. On the basis of the above, review text representation with contextual information is learned by a text encoder. A label-guided dual-attention network is proposed to learn the text representation based on self-attention and the text representation based on label attention, respectively. Then, an adaptive gating mechanism is employed to fuse two mentioned text representations and the final text representation is thus obtained. Finally, a two-layer feedforward neural network is utilized as a classifier for sentiment classification. Experiments on three publicly available real-world datasets show that the proposed model produces better classification performance.
随着互联网的飞速发展, 网上购物变得越来越普遍.用户在电商平台购物的过程中会留下相关评论, 这对于商家提高服务水平和产品质量具有重要价值.目前, 情感分类已成为研究者们重点关注的研究方向.情感分类的目的是给评论文本分配一个情感标签, 情感标签反映评论文本的情感倾向.评论情感分类任务可分为文档级别的情感分类、句子级别的情感分类和方面级别的情感分类[1, 2].本文关注文档级别的情感分类, 即为输入文档分配一个整体的情感倾向.通常将文档级别的情感分类视为一种文档分类任务[3, 4].
传统的情感分类方法基于人工提取有效特征, 这些特征可用于有监督的学习方法[5, 6]或半监督的方法[7].Gao等[5]建模用户宽容度和产品流行度, 提高情感分类性能.Goldberg等[7]提出基于图的半监督算法, 在标记数据和未标记数据上创建一个图, 为这项任务编码, 提高未标记样本的预测准确率.但是, 上述方法依赖于人工提取有效特征, 在面对海量数据时, 将会耗费大量的时间与精力.
基于深度学习的方法主要采用词嵌入表示技术表示文本词语, 利用深层神经网络从低层的文本表示中学习抽象文本语义特征, 如将卷积神经网络(Convolutional Neural Network, CNN)[8]和循环神经网络(Recurrent Neural Network, RNN)[9]应用于学习文档表示.相比传统方法, 基于深度学习的方法不需要人工提取特征即可取得显著的分类效果.Tang等[10]提出基于神经网络的层次编码模型, 学习有效的评论表示.层次注意力机制[11, 12, 13]也广泛应用于构建评论的有效特征.
近些年, 研究者们引入摘要生成模块, 提升模型分类性能.Ma 等[14]提出HSSC(Hierarchical Summa-rization and Sentiment Classification), 包含一个摘要层和一个情感分类层, 同时优化摘要生成任务和情感分类任务性能, 实现更好的情感分类效果.Chan等[15]进一步提出Dual-view, 首先使用编码器学习评论的上下文表示, 摘要解码器应用复制机制(Copy Mechanism)[16]逐字生成评论摘要.然后, 摘要视图情感分类器预测生成摘要的情感标签, 评论视图情感分类器预测评论的情感标签.在训练过程中, 引入不一致性损失函数, 惩罚这两个分类器之间的不一致性.不同于文献[14], Chan等[15]将评论内容和生成的摘要作为两个不同的视图, 分别在其上输出分类结果.相比以往方法, 文献[15]方法虽然取得更好的情感分类结果, 但同时也面临模型复杂程度较高、在训练时需要消耗更多计算资源的问题.
上述研究方法只是将类别表示作为标签词汇表中的索引, 模型缺乏关于分类的细粒度标签指导信息.近年来, 研究者们提出利用标签描述带有的语义信息显式指导文本分类, 相继提出一些方法.Du等[17]认为基于深度学习的模型在分类时主要依赖文本级表示, 忽略细粒度(词与类之间的匹配信息)分类线索.为了解决此问题, 他们提出EXAM(Explicit Interaction Model), 利用标签文本信息编码每类, 得到可训练的矩阵(每行表示一类), 再采用点积作为交互函数, 计算目标词和标签之间的匹配分数, 提取更丰富的信息, 提高分类效果.但是, 此方法未考虑不同的标签可能会有相似的文本, 影响分类性能.Xiao 等[18]提出LSAN(Label-Specific Atten-tion Network), 利用标签语义信息确定标签和文档之间的语义连接, 构造特定于标签的文档表示.同时, 采用自注意力机制从文档内容中学习标签特定的文档表示.为了实现上述两部分的无缝融合, 设计自适应融合策略, 有效输出综合的文档表示, 构建多标签文本分类器.上述两种方法都依赖于数据集带有标签文本信息描述标签, 例如使用“ 积极” 描述简单的类别标签“ 1” .虽然标签“ 1” 不具有情感语义信息, 但单词“ 积极” 具有丰富的情感信息, 可用于显式计算文本单词和标签之间的语义关系.然而, 在一些应用场景中, 无法获得相应的类别标签表述信息, 只含有简单的类别标签, 标签本身不具有情感语义信息, 而且数据集没有关于标签的描述信息, 从而无法应用相关方法.
为了解决上述问题, 本文提出标签指导的双注意力深度神经网络模型(Label-Guided Dual-Atten-tion Deep Neural Network Model, LGDA).首先, 提出基于逆标签频次(Inverse Label Frequency, ILF)的自动类别标签描述生成方法, 为每个标签生成特定的标签描述, 用于显式计算文本单词与标签之间的语义关系.在此基础上, 使用文本编码器学习具有上下文语境信息的评论文本表示, 并提出标签指导的双注意力网络, 分别学习基于自注意力的文本表示和基于标签注意力的文本表示.然后, 使用自适应门控机制融合这两个文本表示, 得到文本最终表示.最后, 使用两层前馈神经网络作为分类器, 进行情感分类.在3个公开的真实数据集上的实验表明, LGDA的分类效果较优, 减少训练时长和计算代价.
标签指导的双注意力深度神经网络模型(LGDA)框架包含如下5个部分:标签描述生成、文本编码器、标签指导的双注意力网络、自适应门控机制、情感分类器.模型框架如图1所示.
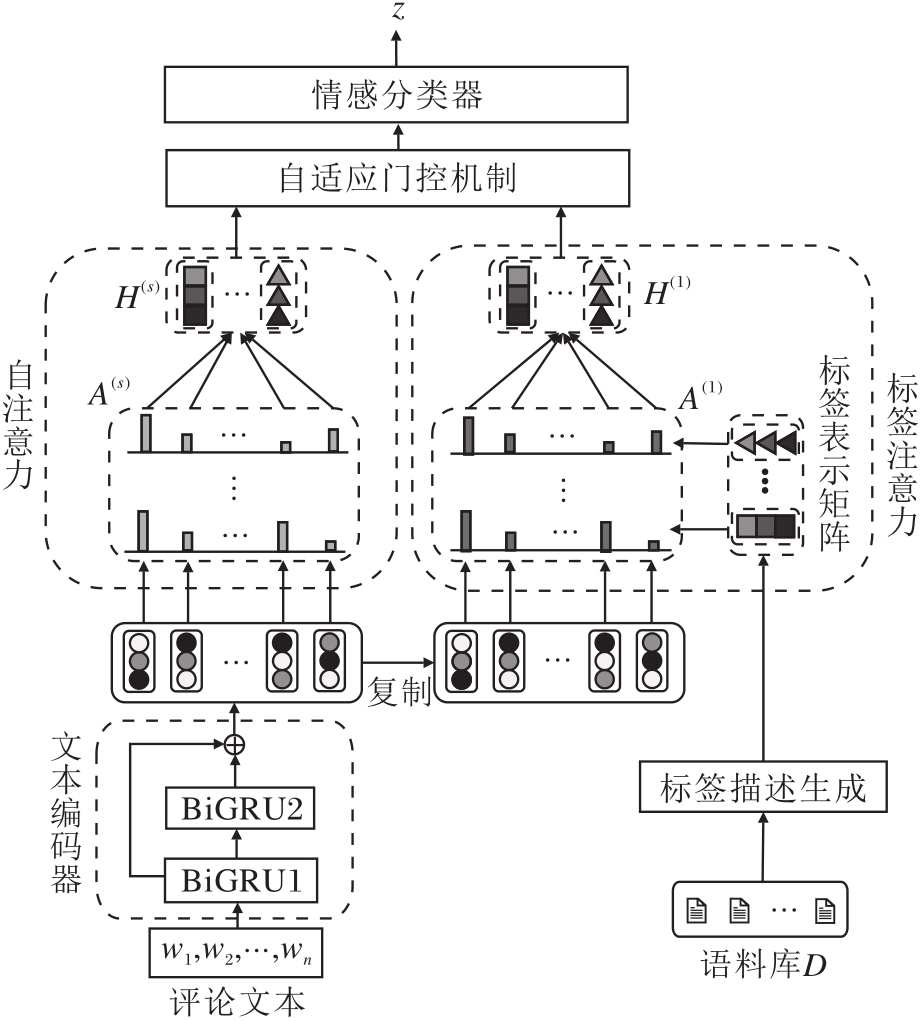 | 图1 标签指导的双注意力深度神经网络模型框图Fig.1 Framework of label-guided dual-attention deep neural network model |
本节探讨如何为每个情感标签生成有效描述, 以学习标签指导的文本表示.直观上, 一个有效的标签描述应满足2个关键要求.1)相关性.标签描述中的单词应在语义上表示该标签, 即每个单词应与标签有很强的相关性.2)区分力.标签描述应具有对不同标签的高区分能力, 即标签描述中的单词与该标签的相关性较强, 而与其它标签的相关性较弱.
为了解决相关性, 测量一个单词对给定标签的相关性得分.给定一个语料库D, 一个情感标签c∈ {1, 2, …, C}, 其中, C表示标签集合大小, 一个单词w, 一个评论文本d∈ D, 计算单词w与标签c的相关性得分:
rw, c=
其中, Dc表示在D中所有标签为c的文本, sw, d表示单词w在d中的重要性得分.
值得注意的是, 现有多种方法可计算重要性分数sw, d, 鉴于TF-IDF(Term Frequency-Inverse Docu-ment Frequency)[19]的良好性能, 本文使用TF-IDF计算sw, d.单词w在评论文本d中的TF-IDF值为
sw, d=TFIDF(w, d)=fw, d· ln
其中, fw, d表示单词w在d中出现的次数, |D|表示语料库D的大小, fw, D表示语料库中包含单词w的评论文本的数量.计算单词w与标签c相关性得分:
rw, c=
为了处理区分力, 需要评估一个单词对所有情感标签的区分能力, 由此提出逆标签频次(ILF), ILF定义如下.受TF-IDF的启发, 基于与逆文档频次(Inverse Document Frequency, IDF)相似的策略衡量一个单词的识别能力, 即本文提出的ILF中的标签频次(Label Frequency, LF)等于单词w出现在相应文本中的不同情感标签的数量:
LF(w)=|
其中yd表示文本d对应的情感标签.得到单词w相对于标签c的基于ILF的相关性分数:
为标签c选取
qc=
得到标签c的表示.
同理, 可计算其它标签的表示.最终得到标签表示矩阵:
QL=(q1, q2, …, qC)∈
在文本编码器模块, 可选择BiGRU(Bi-direc-tional Gated-Recurrent Unit)[20]、BiLSTM(Bi-direc-tional Long Short-Term Memory)[21]、Transformer[22]等作为文本编码器, 学习评论文本的隐藏状态.本文与Dual-view一致, 选择BiGRU作为文本编码器.
首先, 将评论文本序列d=(w1, w2, …, wn)输入编码器中, 使用词向量矩阵E∈
其中, GRU11表示第一个前向GRU, GRU12表示第一个后向GRU.拼接
ui=
由此得到评论文本的浅层隐藏表示
U=(u1, u2, …, un).
然后, 把浅层隐藏表示输入到第2个BiGRU中, 学习评论文本单词之间更复杂的交互作用:
拼接
其中, γ ∈ [0, 1], 表示超参数.
最后得到编码器输出的文本表示
本文提出标签指导的双注意力网络, 目的是寻找评论文本中与不同标签相关的单词, 进一步确定整个评论文本的情感倾向.事实上, 这个策略对于评论文本情感分类是很直观的.例如, 对于评论“ …This baby doll is perfect! She loved it as soon as we handed it to her, and she carries it all around with her…” , 情感标签为5, 表示非常积极的态度.显然, 单词perfect与第5类更相关, we、is等词偏中性, 与第3类更相关, 而整个文本与第5类最相关.所以, 注意力网络应更关注单词perfect.下面将使用注意力网络捕获这个特征.
1.3.1 自注意力机制
一个评论文本中不同单词对每个标签有不同的贡献.为了确定文本中与每个标签最相关的单词, 采用自注意力机制(Self-Attention Mechanism)[24].使用
A(s)=softmax
计算label-word注意力分数, 其中, W1∈
同理, 可计算评论文本沿其它标签的新表示.最后整个矩阵H(s)∈
1.3.2 标签注意力机制
自注意力机制只考虑文本内容, 可视为基于内容的注意力.众所周知, 标签在文本分类中具有特定语义, 一般隐藏在标签文本或描述中, 对文本分类具有指导作用.然而, 一些应用场景中没有标签文本或描述.对于没有标签文本或描述的数据集, 使用1.1节中方法, 得到标签表示矩阵QL.然后, 将标签表示矩阵映射到与
其中W3∈
A(l)=
类似于自我注意力机制, 标签指导的特定于标签的文本表示如下:
H(l)=A(l)
在标签的指导作用下, 评论文本被重新表示为H(l)∈
虽然H(s)和H(l)都是特定于标签的文本表示, 但侧重点不同.H(s)更侧重于文本内容, 而H(l)更注重文本内容与标签表示之间的语义关系.为了更好地利用这两部分的优势, 使用自适应门控机制, 从这两部分中自适应地提取有效信息, 用于构建全面的标签指导的文本表示.
本文利用2个权重向量α ∈ RC, μ ∈ RC, 决定H(s)和H(l)的重要性, 即
α =sigmoid(H(s)W4), μ =sigmoid(H(l)W5),
其中, W4∈
α j=
进行正则化.然后, 利用α j和μ j计算得到沿第j个标签的最终文本表示:
H'j=α j
所有标签的特定于标签的文本表示可描述为矩阵H'∈
在得到文本的最终表示后, 使用两层前馈神经网络作为分类器.在网络输出端应用softmax函数生成情感标签上的概率分布:
P(z|
其中, W6∈
最后, 将概率最高的情感标签作为评论文本的预测情感标签.
本文使用负对数似然作为损失函数:
L=-ln(P(z* |d)),
其中z* 表示真实的评论文本情感标签.
本文使用Chan等[15]从Amazon 5-core review repository[25]收集的3个公开数据集.采用如下3个领域的商品评论作为数据集:Sports & Outdoors(表示为Sports); Toys & Games(表示为Toys); Home & Kitchen(表示为Home).实验中每个数据样本由一个评论文本和一个评分组成.把评分作为情感标签, 取整数, 取值范围是[1, 5].
为了公平对比, 在数据预处理时, 遵循Chan等[15]做法:将所有字母转换为小写并使用Stanford CoreNLP[26]对文本进行分词.为了减少数据集的噪音, 过滤评论文本长度小于16或大于800的数据样本.把每个数据集随机分割为训练集、验证集和测试集.数据集的统计信息如表1所示.在表中, Ave.RL表示训练集中评论文本的平均长度, L+c表示情感标签为c的数据样本在训练集中的比例.
| 表1 实验数据集统计信息 Table 1 Statistics of experimental datasets |
从表1中可发现, 情感标签的类别分布不均衡, 所以本文使用Macro-averaged F1(M.F1)和Balan-ced Accuracy(B.Acc)[27]作为评价指标.
M.F1用于评估所有不同类别标签的平均F1.M.F1赋予每个标签相同的权重, 定义如下:
M.F1=
其中,
Pi=
TPi表示预测标签为i且真实标签为i的样本数, FPi表示预测标签为i且真实标签为非i的样本数, FNi表示预测标签非i且真实标签为i的样本数, |C|表示标签集合的大小.
B.Acc为准确率针对不平衡数据集的一种变体, 定义如下:
B.Acc=
在每个数据集的训练集上训练一个128维的word2vec[28], 用于初始化包括基线模型在内的所有模型的词嵌入.定义词汇表为训练集中出现次数最频繁的50 000个单词.在实验中de设置为128, du设置为512, γ 设置为0.5, 批尺寸大小设置为32.优化器使用自适应矩估计(Adaptive Moment Estimation, Adam)[29], 初始学习率设置为0.001, 如果验证集损失停止下降, 学习率减少一半.
基线模型可分为如下两组.
1)只做情感分类的模型, 包括:
(1)BiGRU+Attention.首先, 使用BiGRU单元层[20]将输入的评论文本编码成隐藏状态.然后利用attention mechanism[30] with glimpse operation[31], 从编码器生成的隐藏状态中聚合信息, 生成一个向量.这个向量再经过一个两层前馈神经网络预测情感标签.
(2)BiLSTM+Attention.首先, 使用BiLSTM[21]将输入的评论文本编码成隐藏状态.然后利用attention mechanism[30] with glimpse operation[31], 从编码器生成的隐藏状态中聚合信息, 生成一个向量.这个向量再经过一个分类器预测情感标签.
(3)Transformer+Attention.首先使用一个标准的Transformer[22], 将输入的评论文本编码成隐藏状态.然后利用注意力机制把编码器生成的隐藏状态聚合成一个向量.这个向量再经过一个情感分类器预测情感标签.
(4)DARLM(Differentiated Attentive Represen-tation Learning Model)[32].试图缓解句子分类中的注意力偏向问题.模型具有两个注意力子网分支和一个示例鉴别器.这两个分支联合训练, 其中一个分支尽量对所有句子进行分类, 另一个分支对前者不能较好处理的句子进行分类.最后示例鉴别器选择合适的注意力子网, 进行句子分类.
2)联合评论摘要与情感分类的模型, 包括:
(1)HSSC[14].联合改进评论摘要和情感分类的模型.由一个摘要层和一个情感分类层组成.摘要层将原文压缩成短句, 情感分类层进一步将文本“ 概括” 成情感类.层次结构在文本摘要和情感分类之间建立紧密联系, 使这两个任务可以相互改进.使用摘要压缩文本后, 情感分类器更容易预测较短文本的情感标签.
2)Max[14].使用BiGRU单元层[20]将输入的评论编码为隐藏状态.摘要解码器和情感分类器共享这些隐藏状态.情感分类器利用最大池化将编码器生成的隐藏状态聚合成一个向量, 再通过一个两层前馈神经网络预测情感标签.
3)HSSC+copy.把copy mechanism[16]应用到HSSC中, 作为一个强基线.
4)Max+copy.把copy mechanism[16]应用到Max中, 作为另外一个强基线.
5)Dual-view[15].联合改进评论摘要和情感分类的模型.首先使用编码器学习评论的上下文表示, 摘要解码器应用copy mechanism[16]逐字生成评论摘要.然后, 评论视图情感分类器使用编码器输出的上下文表示预测评论的情感标签, 而摘要视图情感分类器使用解码器的隐藏状态预测生成摘要的情感标签.在训练过程中引入不一致性损失, 惩罚这两个分类器之间的不一致.
本文在3个公开的数据集上进行实验, 各模型的情感分类结果如表2所示.表中最优结果使用黑体数字表示, 次优结果使用斜体数字表示.
在Toys数据集上, LGDA的M.F1值达到57.55%, B.Acc值达到57.59%, 比次优的Dual-view分别提升1.85%和3.53%.在Sports数据集上, LGDA的M.F1值达到56.89%, B.Acc值达到55.70%, 比次优的Dual-view分别提升0.58%和1.42%.在Home数据集上, LGDA的M.F1值达到60.95%, B.Acc值达到59.81%, 比次优的Dual-view分别提升0.22%和0.18%.由此表明LGDA比基线模型更准确地预测评论情感标签.另外, Toys、Sports、Home数据集上训练样本数依次增加, LGDA在3个数据集上的M.F1值和B.Acc值比Dual-view的提升依次减少.这表明训练数据越充分, 相比Dual-view, LGDA提升越少.
| 表2 各模型在3个数据集上的情感分类结果对比 Table 2 Result comparison of sentiment classification of different models on 3 datasets% |
为了验证LGDA中的自注意力、标签注意力、自适应门控机制及逆标签频次的有效性, 在3个数据集上进行消融实验, 结果如表3所示.在表中:-L表示移除标签注意力; -S表示移除自注意力; -G表示移除自适应门控机制, 使用拼接; -ILF表示在生成标签描述时不使用ILF, 只用TF-IDF; -BiGRU(+BiLSTM)和-BiGRU(+Transformer)表示在文本编码器部分分别使用BiLSTM和Transformer替代BiGRU.
考虑到BiGCN(Bi-level Interactive Graph Con-volution Network)更适用于短文本分类[33], 因此在实验中只新增与BiLSTM和Transformer的对比.表中黑体数字表示最优结果.
| 表3 各模型在3个数据集上的消融实验结果 Table 3 Result comparison of ablation experiment of different models on 3 datasets% |
由表3可看到, 分别移除标签注意力、自注意力、逆标签频次及使用拼接代替自适应门控机制之后, 2个指标值都有不同程度的下降, 表明这4个部分都有积极作用.另外, 在所有数据集上的分类结果显示, 使用BiLSTM和Transformer代替BiGRU之后, 分类性能均有不同程度的下降, 因此使用BiGRU比使用BiLSTM和Transformer更适合LGDA.
为了探究生成标签描述时K值的影响, 在3个数据集上进行参数敏感性实验. 分别取K=10、30、50、70、90, 结果如表4所示.
| 表4 K不同对指标值的影响 Table 4 Influence of different K values on index values |
由表4可看到:在Sports、Toys数据集上, K=50时, 分类效果最优; 在Home数据集上, K=70时, 分类效果最优.
另外, 随着K值增大, 所有指标值都是先升后降.这是因为当K值过小时, 选取的关键词较少, 信息不充分, 无法较好地描述标签, 分类性能较差.随着K值的增加, 选取的关键词增加, 信息变得丰富, 可更好地描述标签, 提升分类效果.当K到达某个值时, 分类效果最优.若K值继续增大, 分类效果开始下降, 这是因为选取的关键词过多, 引入噪音, 降低分类效果.
LGDA与Dual-view的计算代价对比如表4所示.表中GPU内存表示训练模型时, GPU内存使用量, 训练时长表示模型训练所需时长.在训练过程中, 2个模型的批尺寸大小均设置为32, 采用相同的早停策略.由表可见, LGDA在GPU内存消耗及训练时长上都显著低于Dual-view.这是因为LGDA没有联合摘要生成进行训练, 过程更简单, 消耗GPU内存更小, 训练时长更短.但是LGDA通过生成标签描述指导模型分类, 在简化模型、降低计算代价的同时, 可提高分类效果.
为了更直观地对比LGDA与Dual-view之间捕获情感特征词的能力, 本文将2个模型对于同一个评论文本单词的注意力权重可视化, 具体如表6所示, 颜色越深表示权重越大, 颜色越浅表示权重越小.由表5可看到, Dual-view虽然关注love、good等积极的情感词, 但是分配的权重较小, 同时对于与情感无关的词buy、product等也分配较大的权重.而LGDA对于情感词love、good、favors、well分配较大的权重, 对于与情感无关的词, 分配很少的权重.所以, LGDA正确预测情感标签, 而Dual-view预测错误.这表明LGDA拥有更好的捕捉情感特征的能力.
本文提出标签指导的双注意力深度神经网络模型(LGDA).首先, 提出基于逆标签频次的自动类别标签描述生成方法, 为每个标签生成特定的标签描述, 用于显式计算文本单词与标签之间的语义关系.在此基础上, 使用文本编码器学习有效的评论上下文表示, 并提出标签指导的双注意力网络, 分别学习基于自注意力的文本表示和基于标签注意力的文本表示.然后, 使用自适应门控机制融合这两个文本表示, 得到文本最终表示.最后, 使用两层前馈神经网络作为分类器, 进行情感分类.在3个公开的真实数据集上的实验表明, LGDA分类效果较优, 减少计算代价与训练时长.今后将探索更好的生成标签描述的方法, 提高分类性能.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|