{kind=link}
{kind=link}
融合标签关系的法律文本多标签分类方法
[宋泽宇1  , 李旸
, 李旸2 , 李德玉1, 3 1, 3 ]
, 李旸, 李德玉, 王素格]
|
|


通信作者:

宋泽宇,硕士研究生,主要研究方向为文本挖掘、自然语言处理.E-mail:szy5403@163.com.
作者简介:

李旸,博士,讲师,主要研究方向为文本情感分析.E-mail:liyangprimrose@163.com.

王素格,博士,教授,主要研究方向为自然语言处理、情感分析.E-mail:wsg@sxu.edu.cn.
随着大数据技术的快速发展,多标签文本分类在司法领域也催生出诸多应用.在法律文本中通常存在多个要素标签,标签之间往往具有相互依赖性或相关性,准确识别这些标签需要多标签分类方法的支持.因此,文中提出融合标签关系的法律文本多标签分类方法.方法构建标签的共现矩阵,利用图卷积网络捕捉标签之间的依赖关系,并结合标签注意力机制,计算法律文本和标签每个词的相关程度,得到特定标签的法律文本语义表示.最后,融合标签图构建的依赖关系和特定标签的法律文本语义表示,对文本进行综合表示,实现文本的多标签分类.在法律数据集上的实验表明,文中方法获得较好的分类精度和稳定性.
Corresponding author:
LI Deyu, Ph.D., professor. His research interests include gra-nular computing and machine learning.
About Author:
SONG Zeyu, master student. His research interests include text mining and natural language processing.
LI Yang, Ph.D., lecturer. Her research interests include text sentiment analysis.
WANG Suge, Ph.D., professor. Her research interests include natural language processing and sentiment analysis
With the rapid development of big data technology, multi-label text classification spawns many applications in the judicial field. There are multiple element labels in legal texts, and the labels are interdependent or correlated. Accurate identification of these labels requires the support of multi-label classification method. In this paper, a multi-label classification method of legal texts with fusion of label relations(MLC-FLR) is proposed. A graph convolution network model is utilized to capture the dependency relationship between labels by constructing the co-occurrence matrix of labels. The label attention mechanism is employed to calculate the degrees of correlation between a legal text and each label word, and the legal text semantic representation of a specific label can be obtained. Finally, the comprehensive representation of a text for multi-label classification is carried out by combining the dependency relationship and the legal text semantic representation of a specific label. Experimental results on the legal text datasets show that MLC-FLR achieves better classification accuracy and stability.
近年来, 深度学习的发展使司法大数据越来越受到人们的关注, 催生出很多面向司法领域的应用, 智慧法院建设也被纳入国家司法建设进程.在司法领域, 法官阅读案情描述, 依据相关法律条文, 最终确定案件罪名.然而, 在同一案件中, 通常存在多个要素标签, 这些标签的准确识别与分类对于案情摘要、可解释类案件推送等司法领域的实际业务具有重要的支撑作用.
目前, 学者们已提出许多方法用于解决多标签分类问题, 主要是基于传统机器学习方法, 包含问题转换方法和算法适应方法两类.
问题转换方法通过分解样本集, 将多标签分类任务转换为传统的多个单标签分类任务, 该策略与算法无关.常见的是二元相关算法(Binary Correla-tion, BR)[1], 核心思想是将每个标签视为一个单独的二类变量, 分别为每个标签训练一个二元分类器, 不考虑标签间的相关性[2], 但会造成预测性能下降.为了捕捉标签间的关系, 标签集算法(Label Powerset, LP)将所有标签可能的组合取值视为一个新类, 但是, 由于标签的可能组合取值随标签数指数增长, 训练较复杂[3].分类器链算法(Classifier Chain, CC)以“ 链” 的方式连接标签, 一个标签的预测值可帮助预测另一个标签的不确定性, 但只能捕捉标签的低阶相关性[4].
算法适应方法是对已有算法进行适当变换, 以适应多标签分类问题.Elisseeff等[5]提出排序支持向量机(Rank-Support Vector Machine, Rank-SVM), 采用基于多标签熵的决策树进行多标签分类.针对司法领域, Thompson[6]采用最近邻算法和决策树算法等, 实现裁判文书的分类.针对罪名标签预测中的多标签问题, ulea等[7]采用支持向量机(SVM)进行分类, 并以犯罪事实、犯罪时间等作为特征, 取得较优效果.
随着深度学习的快速发展, 各种神经网络模型开始用于多标签文本分类(Multi-label Text Classi-fication, MLTC)任务中.Conneau等[8]和Yao等[9]将多标签分类视为一系列单标签文本分类任务.Reyes等[10]简单地将单标签文本分类扩展到MLTC.但是这种简化往往使分类性能下降, 原因之一是单标签文本分类不涉及标签依赖问题, 而多标签文本分类任务中各标签之间可能存在语义依赖.另外, 当涉及某些标签的训练数据不足时, 标签间的语义依赖作用更明显[11].Liu等[12]设计极端多标签-卷积神经网络模型(Extreme Multi-label-CNN, XML-CNN), 侧重于文档表示, 忽略标签间的相关性.卷积神经网络-循环神经网络模型(Convolutional Neural Network-Recurrent Neural Network, CNN-RNN)[13]和序列生成模型(Sequence Generation Model, SGM)[14]使用循环神经网络(RNN)解码器生成一系列可能的标签.在司法领域中, Ye等[15]从自然语言生成(Natural Language Generation, NLG)的角度, 使用基于编码端罪名标签的集合到集合(Sequence-to-Sequence, seq2seq)模型, 生成判决观点.
虽然标签差异可通过关注解码器的状态捕捉, 但任何两个标签的相关性并不能通过固定的递归解码器动态建模.Yang等[16]提出分层注意力网络(Hierarchical Attention Network, HAN), 使用分层注意的门控循环单元(Gate Recurrent Unit, GRU)进行多标签文档分类.Yang等[17]提出序列到集合(Sequence-to-Set, Seq2set)模型, 利用集合的无序性, 降低错误标签序列带来的影响, 不仅捕捉标签之间的相互关系, 而且减少对标签序列的依赖, 分类性能得到一定提高.在司法领域中, Luo等[18]使用注意力机制, 将法律条文信息融入文本建模部分, 用于辅助罪名预测的多标签文本分类.
在实际应用中, 多标签文本分类任务中的标签具有语义信息, 上述方法将标签看成原子符号, 忽略关联于标签的文本内容的潜在知识.一些研究者希望利用标签信息捕获单词间的相似性和规律性.Du等[19]交互单词表示和标签表示, 获得每个词与标签的匹配得分, 度量词与标签的关联, 但并未考虑不同标签应关注不同文档更深层语义表示.Byrd等[20]通过欠采样标签类别对应较多的文本、Chawla等[21]利用过采样标签类别对应较少的文本、Cui等[22]通过在损失函数中为“ 尾标签” 分配较大权重的方式, 处理标签分布极端不平衡的问题.
多标签文本分类是研究单个篇章中存在多个标签的情况, 从不同标签在篇章中的位置来看, 语义关联较强的标签往往在文本中距离较近.当文本内容较长时, 复杂的标签语义关联信息可能隐藏在繁杂或冗余的内容中.此外, 法律文本数据集上也同样存在部分标签训练数据不足, 导致标签分布不平衡的问题, 即大量“ 尾部标签” 仅包含在较少的正面文本中.因此, 针对上述标签关联的信息, 并结合法律文本分类的角度, 需要解决如下3方面的问题:1)如何从法律文本中充分捕获细粒度的文本语义信息; 2)如何从每个法律文本中提取与相应标签相关的区别性信息; 3)如何准确挖掘法律标签之间的依赖性或相关性关系.
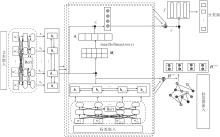
为此, 本文提出融合标签关系的法律文本多标签分类方法(Multi-label Classification of Legal Text with Fusion of Label Relations, MLC-FLR), 利用图卷积网络(Graph Convolutional Network, GCN)的特征矩阵和相关矩阵, 捕捉和探索标签之间的关键依赖关系, 建立标签间的依赖结构.再利用不同样本对于标签的关注度也不同这一特性, 提出标签注意机制, 从样本内容信息中识别与标签相关的文本表示.最后, 将两者结合并输入到编码器中进行分类.在3个法律数据集上的实验表明, 本文方法性能较优.
给定法律文本数据集D和对应的标签集Y, D={< d(i), y(i)>
 | 图1 MLC-FLR框图Fig.1 Architecture of MLC-FLR |
为了更好地表示文本内容, 使用预先训练的Bert模型实现每个词的上下文感知表示[23].
假设dt=[
为了捕获每个词的前向和后向上下文语义, 采用双向长短时记忆网络(Bi-directional Long-Short Term Memory, Bi-LSTM), 获得法律文本和标签的隐层语义表示.
将法律文本的嵌入向量X=[x1, x2, …, xn]输入Bi-LSTM, 通过时刻i-1和输入更新时刻i的隐层状态分别为:
其中,
Ht=
同理, 给定一个标签yj, 整个标签的隐层表示H
已有研究表明, 在多标签文本分类中, 通常标签之间具有相关性, 如何准确捕获隐藏在数据中的标签关系是多标签分类的重要问题.本文使用标签图反映标签关系, 设计基于邻近度的相似标签图构造方法, 用于模拟标签之间的相关关系.方法将每个标签视为一个节点, 每个节点收集所有邻居的特征以形成表示.每条边反映节点之间的语义相关性:如果标签共现, 存在边; 否则, 不存在边.
设标签图G=(V, E), 其中, V为节点集, 每个节点表示一个标签, E为边集, 每个边表示其连接的2个标签具有相关性, 边上的权重表示标签相关性的强弱.标签图可用邻接矩阵A∈ Rk× k表示, Aij表示第i个标签和第j个标签的相关性大小.
一个多标签文本数据集的标签图可通过学习的方式获得, 具有k个节点vi∈ V, 边(vi, vj)∈ E, 邻接矩阵A, 共现矩阵M∈ Rk× k和频率向量F∈ Rk.通过数据驱动的方式建立邻接矩阵.首先, 利用样本在训练集上的标签标注统计所有标签对之间的出现次数, 得到共现矩阵M, 频率向量F, 其中, k为标签数, Fi为标签i在训练集中的频率.利用这个标签共现矩阵和频率向量, 可得到归一化的邻接矩阵A=M/F.这类似于相关矩阵如何内置[24], 除了不采用二值化.
标签嵌入由标签共存图确定, 并捕获由图结构定义的标签语义信息.图卷积网络(GCN)聚合所有相邻节点的值以更新当前节点.每个卷积层只处理一阶邻域信息.多阶邻域信息可通过堆叠几个卷积层实现.对于每个节点vi∈ V, 使用标签在经过Bi-LSTM后得到最后一个隐层表示作为节点特征, 标签集Y中的k个标签形成Hk× d, 为了区分, 记作M.标签嵌入可表示为
H(l)=σ (AHlW0), H(l+1)=σ (AHlWl),
其中, σ (· )表示激活函数, A表示邻接矩阵, Wl表示第l层的卷积权重.输出H(l+1)为融合共现标签关系的特征表示.
由于多标签文本可由一个或多个标签进行标记, 并且对于每个文本, 具有与其对应标签最相关的上下文, 即一个文本中的单词对每个标签的贡献不同, 因此, 为了得到具有与标签相关的法律文本表示, 本文设计标签注意力机制, 更好地从每个法律文本中提取相应标签的区别性信息.
首先, 将1.2节得到的法律文本隐层表示Ht和标签隐层表示H
Vj=HtH
再将Vj按行进行softmax运算, 得到每个标签词对于法律文本中词的相关分布:
qj(e)=softmax(Vj(e, 1), Vj(e, 2), …, Vj(e, m)).
然后将qj(e)按行进行max运算, 并将得到所有最大值进行拼接, 得到最大相关矩阵:
Bj=max(qj(1))max(qj(2))…max(qj(n))∈ Rn× 1.
将得到的Bj与1.2节得到的法律文本隐层表示Ht进行点积, 得到与标签yj相关的法律文本表示:
M
同样, 针对法律文本与所有标签执行上述过程, 得到k个融合标签信息的法律文本表示, 再将其拼接, 可得
Mt=[M
至此, 得到标签的图表示H(l+1)和标签相关的文档表示Mt, 前者侧重于标签内容的表示, 后者在一定程度上反映文本内容与标签之间的语义关联, 将两者相乘并进行分类:
f=H(l+1)Mt.
利用标签注意力机制, 获得标签相关的法律文本表示f后, 再通过全连接层和sigmoid函数构建多标签分类器:
其中, W为可训练模型参数, sigmoid函数将输出值转化为概率.
交叉熵损失可作为损失函数, 已被证明适用于多标签文本分类任务[25], 具体公式如下:
loss=-
其中, n表示法律文本数, k表示标签总数,
本文在NVIDIA 1080Ti上使用Pytorch完成实验, GCN嵌入维度设为768维, 批处理大小为8, Bert的词向量维度为768维, 在维基百科上进行预训练, 使用自适应矩估计(Adaptive Moment Estimation, Adam)优化器最小化最终目标函数, 学习率为2e-5, 设置失活率为0.5, 降低过拟合的影响.
本文的数据来源于2019 “ 中国法研杯” 司法人工智能挑战赛, 该数据集来源于中国裁判文书网, 包括婚姻家庭(Divorce)、劳动争议(Labor)和借款合同(Loan)领域.自行将数据集划分为训练集、验证集和测试集[26], 数据集具体信息如表1所示.
| 表1 数据集信息 Table 1 Information of datasets |
本文采用的评价指标为汉明损失(Hamming Loss)、Macro-F1和Micro-F1.
汉明损失评估被错误分类的标签对的个数:
HL=
数值越小表明模型分类能力越强.
Macro-F1先计算每个类别的F1值, 再对所有类求平均值:
Macro-F1=
Micro-F1先计算所有类别总的精确率和召回率, 再计算F1值:
Micro-p=
Micro-R=
Micro-F1=
其中, TPi表示被正确分类的正例, FNi表示正例被错分为负例, FPi表示负例被错分为正例.
本文选择如下5种对比方法.
1)SGM[14].将多标签分类任务看作序列生成问题, 不但考虑标签间的相关性, 还自动获取输入文本的关键信息.
2)SGM+GE[14].该方法是对SGM的改进, 提出带有全局嵌入(Global Embedding, GE)的解码器结构.
3)基于语义单元的多标签文本分类(Seman-tic-Unit-Based Dilated Convolution for Multi-label Text Classification, SU4MLC)[27].通过多层扩展卷积产生更高层次的语义单位表示, 并产生相应的混合注意机制, 在词级和语义单位级提取信息.
4)Seq2set[17].利用集合的无序性, 降低错误的标签序列带来的影响, 不仅捕捉标签之间的相互关系, 而且减少对标签序列的依赖.
5)特定标签的注意力网络(Label Specific Atten-tion Network, LSAN)[28].对于文档内容和标签文本, 借助自注意力和标签注意力机制, 学习特定于标签的文档表示, 最终有效集成这两部分, 提高最终预测性能.
上述5种对比方法均采用原文代码.
各方法在Divorce、Labor、Loan数据集上的实验结果如表2所示, 表中汉明损失值越小越好, Macro-F1、Micro-F1值越大越好, 黑体数字为最优结果.
由表2可知, 除去Loan数据集上的Micro-F1指标, MLC-FLR的其余指标值均优于其它方法, 说明MLC-FLR对法律文书多标签分类的有效性.由于SGM、SGM+GE和MU4MLC的主体都是将多标签分类作为序列生成问题进行处理, SGM+GE效果最优, 其原因是SGM+GE加入全局嵌入, 有效减少错误传播.Seq2set的结果优于SGM、SGM+GE和MU4MLC, 是因为Seq2set利用集合的无序性, 降低错误标签序列带来的影响, 较好地捕捉标签间的关系.相比SGM、SGM+GE、MU4MLC、Seq2set, LSAN的Macro-F1值有很大的提升, 说明有效的集成标签语义和文档内容可提高分类性能.在3个数据集上, Micro-F1值均大于Macro-F1值, 主要原因是数据类别不均衡造成的, 样本数目较多的类别结果影响整体性能.MLC-FLR的Micro-F1与Macro-F1差值最小, 说明本文对少数类数据标签的标注性能有所提升.
| 表2 各方法在3个数据集上的指标值对比 Table 2 Index value comparison of different methods on 3 datasets% |
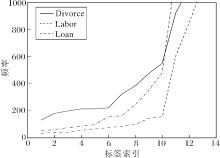
在3个数据集上的标签频率分布如图2所示.由图可知, Labor数据集上尾标签出现频率大多分布在100次左右, Divorce数据集上标签频率明显高于Labor数据集.汉明损失用于衡量被错误标记的标签个数, 只有少量尾标签的预测错误不会对汉明损失产生较大的影响, 因此相比而言Labor数据集上的汉明损失值更低.
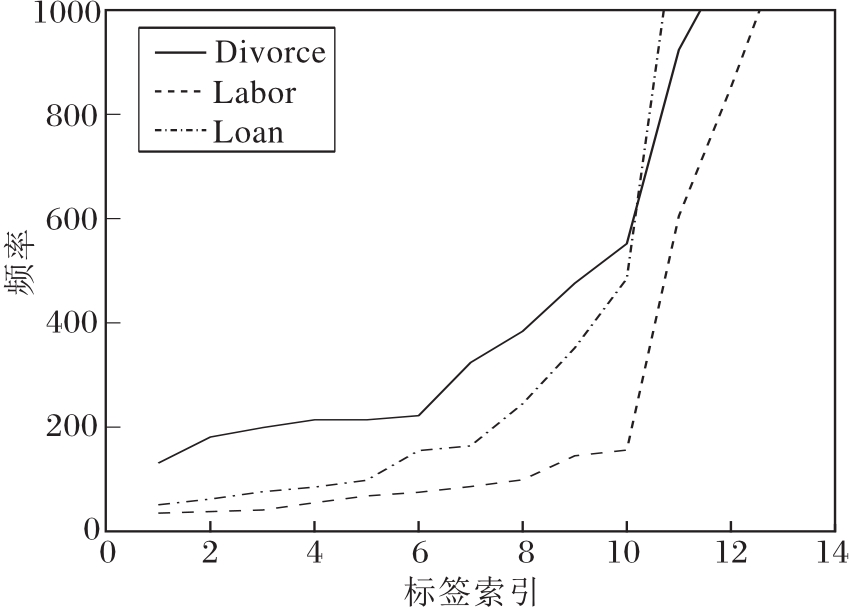 | 图2 标签频率分布图Fig.2 Label frequency distribution |
在Loan数据集上, MLC-FLR的Micro-F1值较低, 原因如下:一方面, Loan数据集的大小明显小于Divorce、Loan数据集, 使方法不能充分学习标签的特征; 另一方面, Loan数据集同样含有相对较多的长尾标签, 而MLC-FLR是基于训练集构建标签之间的关系, 对于不均衡且数据量较小的文本, 构建的共现矩阵较稀疏, 影响最终结果.因此, 采用随机采样的方式, 从呈现长尾分布的数据样本集中随机重复抽取样本(有放回), 可得到更多的样本.
在数据是否增强的情况下, MLC-FLR在Loan数据集上的实验结果如表3所示.由表可看出, 在进行少量数据增强的情况下, MLC-FLR取得不错结果, 从而证实上述分析的合理性.
| 表3 数据是否增强时MLC-FLR的指标值 Table 3 Index value of MLC-FLR with and without data enrichment on Loan dataset |
MLC-FLR主要由2个协同工作的关键模块组成, 即标签图嵌入模块和标签注意力模块.本节通过消融实验验证每个模块的效果.
为了证实每个模块的重要性, 定义LAM为去除标签图嵌入模块的模型, LAM-W为LAM中的词嵌入采用Word2vec(Word to Vector)的模型, GCN-LAM-W为MLC-FLR中的词嵌入采用Word2vec的模型.分别在3个数据集上进行实验, 实验结果如表4所示.
| 表4 各方法在3个数据集上的消融实验结果 Table 4 Results of ablation experiment of different methods on 3 datasets% |
由表4可看出, 对比使用Bert作为词嵌入的MLC-FLR和LAM, 指标值说明标签图在实验中的有效性, 标签之间的关系形成的标签图更有效地捕获标签之间的关系, 提升方法的分类能力.相比使用Word2vec作为词嵌入的LAM-W和MLC-FLR-W, 指标值同样表明MLC-FLR-W的分类效果优于LAM-W, 指标值说明标签图在分类中的重要性, 而LAM-W更侧重于捕获文本信息, 仅用于提取与相应标签相关的区别性信息, 而加入标签图嵌入时可更有效地捕获标签之间的关系, 但同时二者都不可或缺, 结合两部分, 才能有助于更好地提升方法的分类性能.
针对多标签文本分类问题, 本文提出融合标签关系的法律文本多标签分类方法(MLC-FLR).为了充分挖掘标签之间的相关关系, 提出基于邻近度的相似标签图构造方法, 利用GCN得到标签的带有关系特征的语义嵌入.此外, 提出特定标签的注意力机制, 用于获取具有标签特征的文本表示, 捕获有用的标签特定信息.最终结合两者用于分类.在3个法律数据集上的实验结果说明本文方法的有效性.在对Loan数据集进行分类时, MLC-FLR在Micro-F1值上并未取得最优结果, 经过仔细分析发现, 该方法对于类似于Loan这样的数据分布极不均衡的数据集或小样本数据集, 效果并不理想.因此, 下一阶段的任务主要是研究在数据分布不均衡或处理小样本数据时, 如何提升方法的分类性能.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|