







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于多残差动态融合生成对抗网络的人脸素描-照片合成方法
[孙锐1, 2  , 孙琦景
, 孙琦景1, 2 , 单晓全1, 2 , 张旭东1 ]
, 孙琦景, 单晓全, 张旭东]
|
|



作者简介:

孙琦景,硕士研究生,主要研究方向为图像信息处理、计算机视觉.E⁃mail:861242257@qq.com.

单晓全,硕士研究生,主要研究方向为图像信息处理、计算机视觉.E⁃mail:2334321350@qq.com.

张旭东,博士,教授,主要研究方向为智能信息处理、机器视觉.E⁃mail:xudong@hfut.edu.cn.
针对现阶段人脸素描-照片合成方法合成的图像存在清晰度较低、面部细节模糊等问题,提出基于多残差动态融合生成对抗网络的人脸素描-照片合成方法.首先设计多残差动态融合网络,从不同的密集残差模块分别提取特征并进行残差学习.然后根据不同层次的多样化残差特征生成对应的偏移量,不同位置的卷积核依据偏移量改变采样坐标,使网络自适应地关注特征中重要信息.在避免特征信息逐级丢失和冗余信息干扰的前提下,网络有效整合几何细节信息与高级语义信息.方法同时引入多尺度感知损失,对不同分辨率的合成图像进行感知对比,使网络可由粗到细地对合成图像进行正则化约束.在香港中文大学面部素描数据集上的实验表明,文中方法合成的图像清晰度较高,面部细节完整,颜色一致,接近真实的人脸图像.
About Author:
SUN Qijing, master student. His research interests include image information processing and computer vision.
SHAN Xiaoquan, master student. His research interests include image information processing and computer vision.
ZHANG Xudong, Ph.D., professor. His research interests include intelligent information processing and machine vision.
Aiming at the low definition and blurry details in the current face sketch-photo synthesis methods, a face sketch-photo synthesis method based on multi-residual dynamic fusion generative adversarial network is proposed. Firstly, a multi-residual dynamic fusion network is designed. Features are extracted from different dense residual modules and then the residual learning is conducted. Then, the corresponding offsets are generated on the basis of the diverse residual features at different levels. The sampling coordinates of the convolution kernels in different locations are changed according to the offsets. Consequently, the network is focused on important feature adaptively, and geometric detail information and high-level semantic information are integrated effectively without gradual information dropping and redundant information interference. Moreover, a multi-scale perceptual loss is introduced to conduct perceptual comparison on the synthetic images of different resolutions for the regularization of synthetic images from coarse to fine. Experiments on Chinese University of Hong Kong face sketch dataset show that the proposed method produces high-definition images with full detail and consistent color and the synthesized image is closer to real face images.
本文责任编委 张军平
Recommended by Associate Editor ZHANG Junping
近年来, 生物识别技术取得重大进展, 由于数据收集的便利性与泛在性, 人脸仍是应用广泛的生物识别载体.由于人脸素描-照片的合成在执法、刑事案件和数字娱乐等方面的广泛应用, 该方法成为一个热门的研究领域.人脸素描-照片合成是指将特定的素描或照片的纹理和颜色信息应用于给定的输入人脸图像, 同时保留身份特征.在无法获得人脸素描或照片时, 人脸素描-照片的合成就显得十分重要.
传统的人脸素描-照片合成方法主要分为2种:基于数据驱动的方法和基于模型驱动的方法.基于数据驱动的素描人脸合成方法也称为基于样本的方法.例如:Liu等[1]提出基于子空间学习的局部线性嵌入(Locally Linear Embedding, LLE)方法, Wang等[2]提出基于马尔可夫随机场(Markov Random Field, MRF)方法.基于数据驱动的方法可生成与输入照片对应的人脸素描, 然而, 在合成过程中需要复杂的计算及很多的数据进行训练.一些重要的人脸特征, 如眼镜, 可能会缺失在合成的人脸素描图像中, 因为在训练的人脸图像中这些特征可能未出现.基于数据驱动的方法还会导致生成的图像模糊, 使生成的素描图像通常缺少素描的纹理.基于模型驱动的方法主要有Chang等[3]提出的基于贝叶斯学习的方法和Zhang等[4]提出的基于贪婪搜索稀疏表示的方法.基于模型驱动的方法主要学习素描-照片合成的映射函数, 模型从训练集中的素描-照片对学习素描图像与照片图像之间的映射关系, 学习映射关系后, 输入素描或照片就可直接合成对应的照片或素描, 无需在训练数据中进行搜索, 合成速度较快, 但合成的图像某些地方会丢失素描风格.
由于深度学习技术的突破, 卷积神经网络(Convolutional Neural Network, CNN)在许多计算机视觉任务中取得较大成功, 包括人脸素描照片的合成.Zhang等[5]使用由6个卷积层组成的网络学习从照片到素描的端到端非线性映射, 但在合成结果中带来严重的模糊效果和伪影.生成对抗网络(Gene-rative Adversarial Networks, GAN)[6]和变分自动编码器(Variational Auto-Encoder)[7]等生成模型因其强大生成能力, 在图像生成、图像编辑和表示学习等方面取得较优性能.Isola等[8]提出Pix2Pix, 基于条件生成对抗网络(Conditional GAN, cGAN), 利用语义分割的标签或图像的边缘合成图像.Wang等[9]改进cGAN, 对高分辨率图像进行合成和语义处理.但是, 这些方法都需要大量的成对图像进行训练.
由于难以获取源域和目标域之间成对标注的数据, Zhu等[10]提出使用CycleGAN进行无监督的图像合成.Yi等[11]提出DualGAN, 使用循环一致非配对图像进行图像到图像的合成.Lu等[12]提出使用上下文生成对抗网络, 学习素描图像和相应照片图像的联合分布, 指导图像生成.Wang等[13]在GAN中使用反向投影策略, 改进图像到图像的合成结果.Wang等[14]提出PS2MAN(Photo-Sketch Synthesis Using Multi-adversarial Networks).Chen等[15]提出半监督的野外人脸素描合成框架, 结合基于样本的方法和GAN的优点.Zheng等[16]提出特征编码引导GAN的人脸素描合成方法.Babu等[17]提出CSGAN(Cyc-lic-Synthesized GAN), 用于图像到图像的合成, 使用域的合成图像与另一个域的循环图像之间的循环合成损失.Babu等[18]提出CDGAN(Cyclic Discrimi-native GAN), 用于图像到图像的转换.Han等[19]提出DCLGAN(Dual Contrastive Learning GAN), 用于图像到图像的合成.Yi等[20]在分层生成器和判别器的基础上, 提出APDrawingGAN(Artistic Portrait Drawings GAN).Kim等[21]提出U-GAT-IT(Unsuper-vised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Trans-lation), 以端到端的方式结合注意力模块和可学习归一化函数.Zhu等[22]提出面部素描合成方法, 结合生成概率图形模型和判别深度补丁表示, 共同对深度补丁表示的参数分布和素描补丁重建的参数分布进行建模.Zhu等[23]提出有效的知识蒸馏模型, 提高合成图像的质量.Zhu等[24]提出用于面部照片-素描合成的协作框架, 通过照片域与素描域两者之间的相互映射指导图像合成.
但上述方法在生成高质量的图像方面存在局限性, 这是因为它们在网络前馈时会造成图像细节特征信息的逐级丢失, 并随着网络深度的增加, 虽得到更多抽象的高级语义信息, 但丢失几何细节信息, 出现合成的图像面部模糊、颜色不一致、细节特征缺失等问题.
为了解决上述问题, 生成高质量的合成图像, 本文提出基于多残差动态融合生成对抗网络的人脸素描-照片合成方法.使用2个生成器在素描人脸图像与光学人脸图像之间相互转换, 在生成器中加入多残差动态融合网络, 从不同的残差密集模块分别提取特征并进行残差学习, 根据每个多样化残差特征的不同生成对应的偏移量, 依据偏移量指导卷积核的采样位置, 自适应地关注每个多样化残差特征中最重要的信息.在避免特征信息逐级丢失和冗余信息干扰的前提下, 网络可有效获取图像特征信息的多样性, 并使用多尺度感知损失、合成损失及循环一致损失约束合成图像, 使生成图像与真实图像在纹理、细节等方面更相似.在人脸素描数据库和面部素描人脸识别技术数据库上的大量实验表明本文方法的有效性和优越性.
GAN由生成器和判别器组成, 生成器使用来自判别器子网络的对抗性损失进行训练.生成器的目标是产生尽可能真实的图像, 从而欺骗判别器.而判别器的目的是将生成器生成的样本与真实样本进行分类.理论上GAN可学习一种映射, 产生与目标域相同分布的输出, 但是随着网络深度的增加, 输入的信息在网络中逐级丢失, 导致图像的自然分布和学习模型分布之间的重叠减少, 使合成的图像存在清晰度较低、面部变形、颜色不一致等问题.这些问题会对后续的人脸识别带来很大影响, 所以本文设计多残差动态融合生成对抗网络, 如图1所示, 用于图像合成.
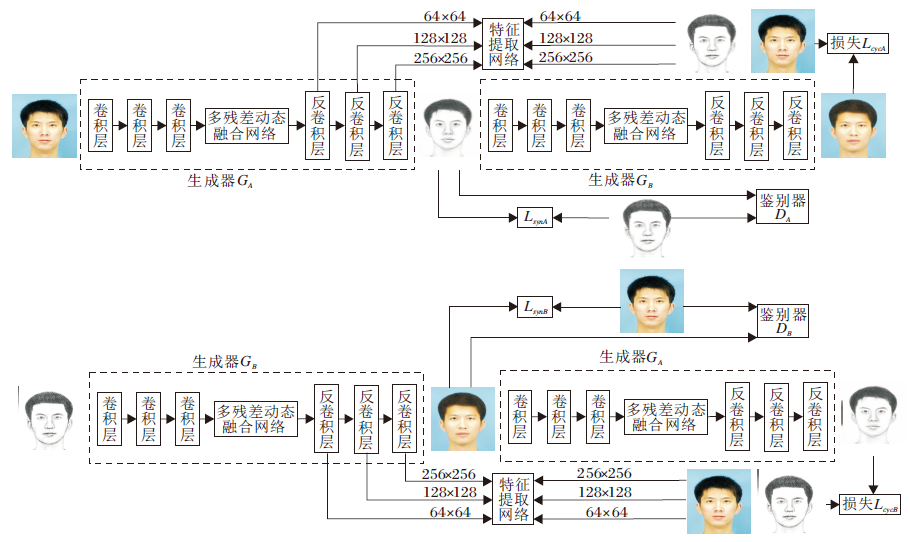 | 图1 网络总体结构Fig.1 Overall structure of network |
网络可自适应地提取丰富的图像特征信息, 并且对合成的图像进行迭代细化, 有效克服合成图像细节特征不明显、清晰度较低、缺乏真实感等问题.
对于给定的数据集M, 由2个不同域的n个成对的图像组成, 其中, A域表示人脸照片图像, B域表示人脸素描图像.素描-照片合成的目标是学习2个转换函数:将素描转换成照片的函数A'=Fsp(B)、将照片转换成素描的函数B'=Fps(A).
本文网络结构包含2个生成器(GA和GB)、2个鉴别器(DA和DB)和1个特征提取网络.生成器GA的功能是将真实的人脸照片图像RA转换成人脸素描图像FB=GA(RA); 生成器GB将生成的人脸素描图像FB转换为循环的人脸照片图像RecA=GB(FB).
同理, 人脸素描图像转换为人脸照片图像的过程可表示为FA=GB(RB), RecB=GA(FA).
在图1中, 生成器GA和GB合成的图像FA和FB分别送入判别器DA和DB中判别真实性.从生成器GA和GB中得到64× 64、128× 128、256× 256分辨率的图像, 分别送入特征提取网络提取图像特征.然后把不同分辨率的真实图像也分别送入特征提取网络提取特征, 计算对应分辨率真实图像与合成图像的感知损失、真实图像与合成图像的合成损失和真实图像与循环图像的循环损失.
生成器的结构如图1所示, 前端由3个卷积层组成.第1个卷积层的卷积核尺寸为7× 7, 步长为1, 在卷积操作前进行镜像填充(ReflectionPad2d)操作.第2个卷积层和第3个卷积层的卷积核尺寸为3× 3, 步长为2, 进行补零(Padding)操作.3个卷积层都采用Leaky ReLU激活函数.通过3个卷积层对输入的人脸图像进行浅层特征提取, 再将提取的浅层特征输入本文网络进行深度多样化特征提取, 自适应地提取输入图像最本质的特征.最后通过反卷积进行上采样, 输出合成的图像.
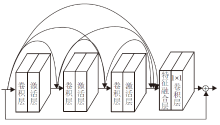
1.3.1 多残差动态融合网络
多残差动态融合网络结构如图2所示, 它是由多个密集残差块组成不同的残差网络, 并对其输出的残差信息进行动态特征融合.第i个残差学习
Gi=Fn+Fi,
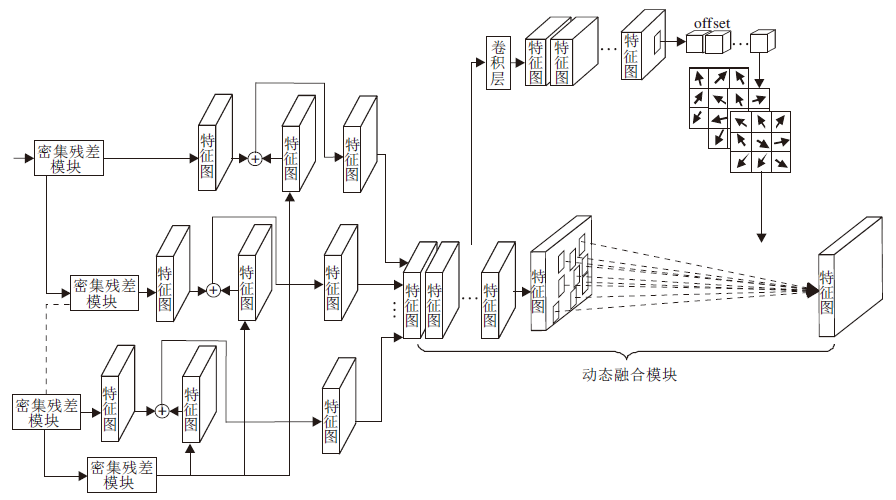 | 图2 多残差动态融合网络结构图Fig.2 Structure of multi-residual dynamic fusion network |
其中, Fi表示第i个密集残差模块的输出, Fn表示最后一个密集残差模块的输出.多残差动态融合的结果是
M=H([G0, G1, …, Gn-1]),
其中, H表示多残差动态融合操作, 是一个操作的复合函数, 如卷积和激活函数(ReLU).
在视觉识别和图像生成领域中, 使用深度神经网络可提高性能, 但随着网络深度的增加可能会出现性能下降、生成图像质量变差等问题, 主要原因是输入图像经过多层卷积, 每经过一层卷积会丢失一些信息, 最终缺失输入图像的很多细节信息, 导致重构后的图像质量变差.本文网络可有效解决上述问题.多残差动态融合网络由不同尺度的残差网络和动态融合模块组成, 将每个密集残差模块的输出分别与最后的密集残差模块的输出进行局部残差学习, 然后将不同层次的残差特征进行动态特征融合.
不同的密集残差模块输出特征表征不同的信息, 靠前的模块输出特征的几何细节信息表征能力较强, 但语义信息表征能力较弱, 而靠后的模块输出特征具有更强的语义信息表征能力.这些特征相互作用, 获得有效的图像信息, 并且多残差路径将不同层次的特征传递到网络的更深层中, 可使不同层次的特征得到有效重用.但是将多样化的残差信息进行直接融合, 会导致融合后的特征保留多样化残差特征之间大量的冗余信息, 这些冗余信息会对合成图像进行干扰, 导致合成图像质量变差.而本文采用动态融合方式融合多样化残差特征, 在卷积单元中增加偏移量, 偏移量根据每个多样化特征信息的不同动态生成, 不同位置的卷积核会根据偏移量改变采样点的位置, 使网络可自适应地获得特征中最重要的信息, 忽略特征中无用的冗余信息.融合后的特征保留多样化残差特征中最重要的部分, 在避免特征信息逐级丢失和冗余信息干扰的前提下, 有效整合几何细节信息与高级语义信息, 使经过反卷积生成的人脸图像面部细节保持得更好, 清晰度更高, 并减少生成图像中伪影的出现.
本文采用通道连接的方式融合不同层次的残差信息.如果直接将对应通道上的元素相加会忽略不同残差信息之间的差异, 而通道融合方式保留不同层次的残差信息, 增加描述图像的特征数, 使重构后的图像面部细节完整、清晰度更高.将不同密集残差块与输出之间进行残差学习, 可使不同的密集残差块输出的信息无阻碍地传递到网络的输出处, 网络可充分利用不同密集残差块提取的层次特征, 提高图像分层特征的利用率, 并且残差结构避免由于网络过深引起的梯度消失和退化问题, 加速网络收敛.与此同时残差网络的剩余路径有助于学习更好的非线性表达能力, 而身份路径有助于在训练期间进行梯度反向传播, 更好地学习素描-照片两者之间的转换.
1.3.2 动态融合模块
动态融合模块由如下2个分支组成.1)偏移量分支.根据输入特征生成对应的偏移量, 第i个残差特征对应的偏移量
Δ pmi=T(G0, G1, …, Gn-1),
其中, T表示偏移量生成操作, 在卷积核为3× 3的卷积过程中, 通过T生成n× 18× h× w的特征图.2)动态卷积分支.将不同位置的卷积核根据偏移量改变采样点的位置, 使经过卷积后得到的特征图是输入特征图中最重要的部分.输入特征为x, 输出特征为y, 则

其中, R表示卷积核各点坐标的集合, w表示卷积核的权值, p0表示特征y中像素点的坐标, pm表示卷积核各点的坐标, 融合结果
M=D(y0, y1, …, yn-1),
其中D表示卷积核为1× 1的卷积操作.
1.3.3 密集残差模块
密集残差模块是由密集网络和残差网络组合而成, 通过密集的连接卷积层提取丰富的局部特征.密集残差模块由密集连接层、局部残差两部分组成, 结构如图3所示.
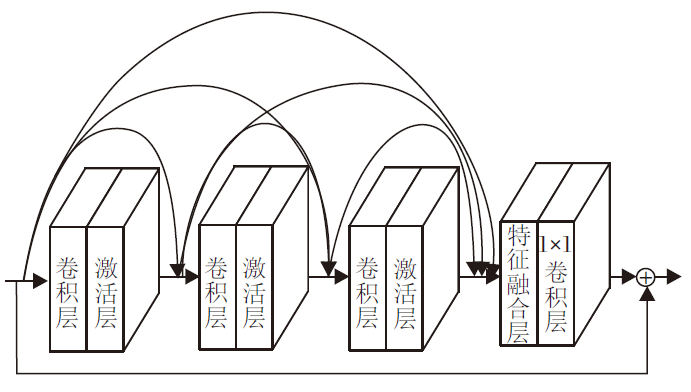 | 图3 密集残差模块结构图Fig.3 Structure of dense residual module |
密集连接层是指拼接前面所有层的输出作为下一层的输入, 将前一个密集残差模块的输出传递给当前密集残差模块的每层, 保证信息的重复利用.第d个密集残差模块的第i个卷积层的输出为:
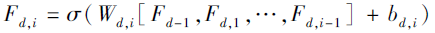
其中, Fj表示第j个密集残差模块的输出, j=1, 2, …, d-1, σ 表示ReLU激活函数, Wd, i和bd, i表示第i个卷积层的权值和偏差.
局部残差将前一个密集残差模块的输出信息与当前密集残差模块中局部特征融合的信息结合, 保证层级信息不被丢失, 并且可进一步改善信息流, 即
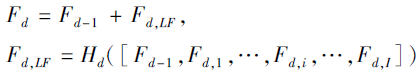
其中Hd表示第d个密集残差模块中1× 1卷积层的函数.
本文使用的判别器是70× 70的PatchGAN[5].网络由5个卷积层组成, 第1个卷积层由卷积和激活函数组成, 中间3个卷积层都是由卷积-实例归一化(Instance Norm)-激活函数组成, 最后一个卷积层由一个卷积组成, PatchGAN将输入的图像映射为N× N的矩阵.
普通的GAN的判别器是将输入图像映射成一个评价值.该值是对生成器生成的整幅图像的评价, 即输入图像为真实图像的概率.而PatchGAN采用全卷积形式, 输入图像经过5个卷积层后最终并不会经过全卷积层, 而是使用卷积将其映射为N× N的矩阵.矩阵中的每个值对应输入图像中某一区域是否为真实样本的概率.
1.5.1 多尺度感知损失
人脸素描-照片合成是指将特定的素描或照片的纹理和颜色信息应用于给定的输入人脸图像, 同时保留身份特征.但是合成的图像容易缺失素描人脸图像或光学人脸图像的纹理及颜色等风格信息, 与真实图像在视觉上存在较大差异.为了改善此问题, 本文设计多尺度感知损失, 提升合成图像的视觉效果.该损失从不同的解码器层提取特征, 经过反卷积, 输出不同分辨率的图像, 再将真实图像也处理成相应分辨率的图像, 分别送入特征提取器中提取特征, 计算对应分辨率的感知损失.
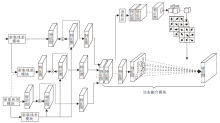
多尺度感知损失的结构如图4所示.利用在ImageNet数据集上预训练的VGG19网络[25]作为特征提取基线网络, 该网络内置在PyTorch平台中, 参数在训练阶段是固定的.VGG19网络提取的深层表征具有较好的扩展性和泛化性, 在风格迁移任务中效果[26, 27]较优.
 | 图4 多尺度感知损失结构图Fig.4 Structure of multi-scale perception loss |
本文将不同分辨率的真实图像与合成图像分别送入特征提取器中提取特征, 在特征提取器ReLU2-2层提取一个特征, 并在ReLU4-4层提取另一个特征, 将对应分辨率的真实图像提取的特征与生成图像提取的特征通过LMSE进行对比.具体多尺度损失函数定义为

其中, Lvgg, 1表示从VGG19特征提取器的ReLU2-2层提取特征计算的感知损失, Lvgg, 2表示从VGG19特征提取器的ReLU4-4层提取特征计算的感知损失, RA、RB表示真实图像, FA、FB表示生成图像, i对应不同的分辨率.
本文任务是素描-照片两者之间的转换, 多尺度感知损失可使生成的图像更真实.通过预训练好的VGG19网络分别提取输入图像的ReLU2-2层特征和ReLU4-4层特征.ReLU2-2层提取的特征有利于生成图像更接近真实图像的颜色和边缘, 而ReLU4-4层提取特征有利于生成的图像在全局结构上与真实图像更接近.本文采用多尺度感知损失, 可从多个不同的分辨率水平约束生成的图像, 对不同分辨率的合成图像与真实图像分别提取不同层次的感知信息进行对比, 使网络可由粗到细地对合成图像进行正则化约束, 促使合成图像更接近真实图像, 更好地克服合成图像存在纹理缺失、颜色不一致及内容丢失等问题.
1.5.2 生成对抗损失
本文采用LSGAN(Least Square GAN)[28]中引入的最小二乘损失作为生成对抗损失, 最小二乘损失使GAN的训练过程变得稳定, 产生高质量的结果.生成器GA和判别器DA的对抗性损失为:
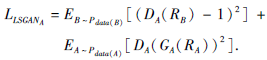
同理, 生成器GB和判别器DB的对抗性损失为:
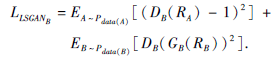
1.5.3 合成损失
为了使生成图像与真实图像更相似, 加入合成损失, 使用L1损失对比真实图像与合成图像, 函数定义为
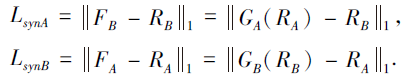
1.5.4 循环一致损失
如同Zhu等[10]的讨论, 在足够大的容量下, 网络中的映射函数很多, 尽管使用对抗损失、合成损失和多尺度感知损失, 但不能保证学习到的函数可将输入图像映射到所需输出, 所以本文加入循环一致损失, 减少可能的映射函数空间.函数定义为
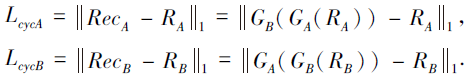
综上所述, 本文最终的损失函数为对抗性损失、合成损失、循环一致损失和多尺度感知损失之和, 最终损失函数的定义为
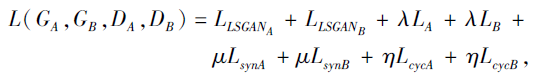
其中, λ 、 μ 、η 用于调整多尺度感知损失、合成损失及循环一致损失的权重.
本文在CUFS人脸素描数据库(CUHK Face Sketch Database, CUFS)[2]和CUFSF面部素描人脸识别技术数据库(CUHK Face Sketch Face Recogni-tion Technology Database, CUFSF)[29]上进行定性和定量测试.CUFS数据库包含606位志愿者, 是一个广泛使用的人脸素描图像数据库, 包括来自CUHK(Chinese University of Hong Kong)学生数据库的188幅人脸、来自AR(Aleix Martinez and Robert Benavente)数据库的123幅人脸和M2VTS(Multi Modal Verification for Teleservices and Security Appli-cations)扩展数据库(Extended M2VTS Database, XM2VTS)的295幅人脸.艺术家根据每人在正常光照下拍摄的正面姿势照片绘制素描图像, 所绘素描都具有中性表情.CUHK学生数据库上共有188对人脸图像, 100对图像用于网络训练, 88对图像用于网络测试.AR数据库上共有123对人脸图像, 80对图像用于网络训练, 43对用于网络测试.XM2VTS数据库上共有295对人脸图像, 100对图像用于网络训练, 195对图像用于网络测试.
CUFSF数据库包括来自FERET数据库的1 194位志愿者的数据, 每人都有一幅带有光线变化的人脸照片和一幅由艺术家绘制的夸张形状的素描.该数据集特别具有挑战性, 因为每人的照片都在光照不同的情况下进行拍摄, 并且相比人脸照片, 艺术家绘制的素描在形状上变得夸张, 但是CUFSF数据库更接近真实的法医素描场景.CUFSF数据库上共有1 194对人脸图像, 800对人脸图像用于训练, 394对人脸图像用于测试.所有图像都简单地将眼睛中心对齐到固定位置, 裁剪到256× 256进行预处理.
实验使用的硬件包括intel (R) Core (TM) i7 -8700CPU@3.20 GHz的CPU, 16 GB内存, NVIDIA GeForce GTX 1070 Ti的显卡, 操作系统为Ubuntu18.04, 基于Pytorch框架, 版本为1.6, 使用python编程语言.
在网络的训练过程中, 输入的每幅人脸图像调整为256× 256.网络从初始状态开始训练, 训练200个周期, 从第1轮到第100轮循环生成器和判别器的学习率设置为0.000 2, 从第101轮到第200轮循环生成器和判别器的学习率线性衰减到0.批处理大小为1, 网络的初始权重从均值为0且标准差为0.02的高斯分布中初始化.损失函数的权重系数分别为λ =5, μ =5, η =10, 网络使用自适应矩估计(Adaptive Moment Estimation, Adam)[30]优化器进行训练.
为了验证本文方法在人脸素描-照片合成时的有效性, 选择如下照片素描合成方法进行对比:Pix2Pix[8]、CycleGAN[10]、DualGAN[11]、PS2-MAN[14]、CSGAN[17]、CDGAN[18]、DCLGAN[19]、APDrawing-GAN[20]、U-GAT-IT[21].
各方法在CUFS数据库上的人脸照片和人脸素描合成结果如图5和图6所示.由图可看出, Pix2Pix合成的图像出现面部模糊不清晰、细节丢失等问题.CycleGAN合成图像出现颜色不一致、伪影现象, 素描图像面部出现模糊.DualGAN合成图像的面部总是出现严重噪声.PS2-MAN合成图像会模糊不清晰.CSGAN会导致生成的图像出现颜色不一致及面部细节的缺失.CDGAN会使生成图像面部器官发生变化及伪影的出现.U-GAT-IT合成图像面部不清晰、颜色不真实.APDrawingGAN合成的素描图像模糊不清晰并出现内容缺失.DCLGAN合成的图像会出现颜色不一致、面部模糊及缺乏真实感.本文方法合成图像可保留高频细节、减少面部细节模糊, 颜色纹理与真实图像更接近, 生成图像更清晰.
 | 图5 各方法在CUFS数据库上素描转换为照片的结果Fig.5 Conversion results of sketch to photo by different methods |
 | 图6 各方法在CUFS数据库上照片转换为素描的结果Fig.6 Conversion results of photo to sketch by different methods on CUFS database |
为了进一步表明本文方法在素描-照片合成上的有效性, 在CUFSF数据库上进行素描人脸合成对比, 结果如图7和图8所示.在CUFSF数据库上进行人脸素描-照片合成更具有挑战性, 因为在CUFSF数据库上, 相比真实图像的特征, 素描图像具有过度夸张的特征.由图可看出, Pix2Pix、Cycle-GAN、Dual-GAN、PS2-MAN、CSGAN、CDGAN、APDrawingGAN、DCLGAN生成的照片或素描都会出现不同程度的面部模糊、颜色不一致、轮廓不清晰、合成的图像不真实等现象.U-GAT-IT合成的照片图像面部模糊不清晰, 但是合成的素描图像效果较优.本文方法合成的照片或素描面部轮廓都较清晰、面部细节保持完整、视觉上更接近真实图像.
 | 图7 各方法在CUFSF数据库上素描转换为照片的结果Fig.7 Conversion results of sketch to photo by different methods on CUFSF database |
 | 图8 各方法在CUFSF数据库上照片转换为素描的结果Fig.8 Conversion results of sketch to photo by different methods on CUFSF database |
为了说明本文方法的有效性, 分别在CUFS、CUFSF数据库上进行定量评估, 采用结构相似度(Structural Similarity, SSIM)、学习感知图像块相似度(Learned Perceptual Image Patch Similarity, LPIPS)、特征相似度(Feature Similarity, FSIM)衡量各方法生成图像的质量.
SSIM通常用于对比人脸素描-照片合成中合成图像与真实图像之间的相似性.FSIM评估生成图像与真实图像的特征相似性.LPIPS强调感知相似性, 计算真实图像与生成图像之间的距离.相比SSIM和FSIM, LPIPS更符合人类的感知情况.LPIPS值越低表示两幅图像越相似, 否则差异越大.各方法在2个数据库上合成的素描图像和照片图像的SSIM、FSIM、LPIPS值如表1~表3所示, 表中使用黑色字体表示最优值.
| 表1 各方法在2个数据库上的SSIM对比 Table 1 SSIM comparison of different methods on 2 databases |
| 表2 各方法在2个数据库上的FSIM对比 Table 2 FSIM comparison of different methods on 2 databases |
| 表3 各方法在2个数据库上的LPIPS对比 Table 3 LPIPS comparison of different methods on 2 databases |
由表1~表3可看出, 在SSIM指标上, 本文方法稍逊于U-GAT-IT, 优于其它方法.在FSIM指标上, 本文方法在AR数据库上合成照片及在XM2VTS、CUFSF数据库上合成素描的指标值稍逊于U-GAT-IT, 优于其它方法.在LPIPS指标上, 本文方法指标值最优.上述结果说明本文方法合成图像更优, 网络通过对输入图像自适应地提取深层多样化特征, 使合成图像与真实图像在结构和特征上更相似, 在视觉上更接近真实图像.
为了验证本文方法合成图像可在人脸识别上取得较优结果, 将各方法合成图像进行人脸识别测试.人脸识别准确率是衡量合成人脸图像质量的有效指标.高质量的合成人脸图像具有较高的识别精度.本文采用主成分分析的方法进行人脸特征提取, 再使用余弦相似度进行距离测量, 计算匹配率.各方法在CUFS数据库上合成图像的识别率如图9所示.
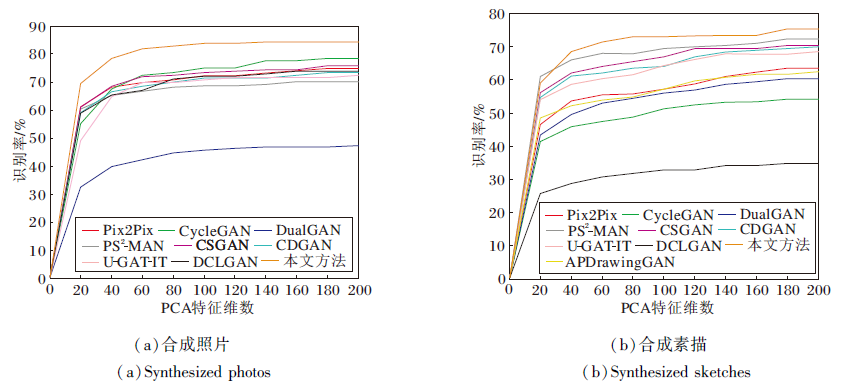 | 图9 各方法在CUFS数据库上合成素描和照片的识别率Fig.9 Recognition rates of synthesized sketches and synthesized photos by different methods on CUFS database |
由图9可看出, 在CUFS数据库上, 本文方法合成图像的识别率更高, 由此说明本文方法的有效性.通过多残差动态融合网络自适应地获取输入图像深层多样化特征, 使经过反卷积合成的图像更好地保留人脸的面部特征, 图像细节信息更完整, 纹理颜色更接近真实图像.在人脸识别时能更好地与对应的真实人脸图像匹配.
为了验证本文方法的鲁棒性, 通过搜索引擎从网络中获取一些真实场景下的人物照片, 利用这些照片测试各方法的合成结果, 如图10所示.
 | 图10 各方法泛化实验结果对比Fig.10 Results comparison of generalization experiments of different methods |
由图10可看出, 其它方法合成的素描图像都出现不同程度的模糊失真, UGATIT、DCLGAN合成的人脸图像缺失素描图像的风格.而本文方法在未经过训练的数据集上合成的素描图像仍能保持较优效果, 并且合成的图像质量更高, 表明本文方法具有较好的泛化能力.
为了探究本文网络中密集残差块数量的不同对生成效果的影响, 分别对采用不同数量密集残差块的网络进行训练.采用SSIM、FSIM、LPIPS和人脸识别率评判不同参数值下合成人脸图像的质量, 具体结果如表4所示.由表可看出, 当密集残差块的数量增加时, 合成图像的质量变优, 但是当密集残差块数量增加到一定程度后, 再增加模块数量, 合成图像的质量就会变差.由表可知, 当密集残差块数量取值为20时, 合成图像的质量最高.
| 表4 不同密集残差块数量合成图像的指标值对比 Table 4 Index comparison of synthesized images with different numbers of dense residual blocks |
为了更好地探究本文的多残差动态融合网络和多尺度感知损失对合成图像的影响, 分别进行CycleGAN、CycleGAN+感知损失、CycleGAN+密集残差块、CycleGAN+多尺度感知损失、CycleGAN+多残差动态融合网络和本文方法的实验对比.由于本文方法使用成对图像, 在网络中使用合成损失而未使用身份保持损失, 所以将原CycleGAN中的身份保持损失替换为合成损失.各方法在CUFS数据库上的合成图像如图11所示.
 | 图11 各方法的消融实验结果对比Fig.11 Results comparison of ablation experiments of different methods |
由图11可看出, 将CycleGAN中的残差网络替换成密集残差网络后, 合成图像质量变差, 因为单方面的增加网络深度并不能提高合成图像的质量.在CycleGAN中加入感知损失后, 合成图像质量有所提高.而将多尺度感知损失加入CycleGAN后, 合成图像视觉效果优于Cycle-GAN, 更接近真实图像, 更好地克服合成图像存在纹理缺失、颜色不一致及轮廓不清晰等问题.相比单尺度感知损失合成的图像, 多尺度感知损失在纹理细节、颜色与轮廓等方面表现更优.将CycleGAN中的残差网络替换为多残差动态融合网络后, 合成图像更好地保留输入图像的特征信息, 使合成图像面部特征更完整, 细节特征更清晰.但是多残差动态融合网络合成的图像纹理会有一定缺失, 所以加入多尺度感知损失可改善合成图像的纹理效果.
为了更直观地说明多残差动态融合网络和多尺度感知损失两部分的有效性, 对CycleGAN、Cycle-GAN+感知损失、CycleGAN+密集残差块、CycleGAN+多尺度感知损失、CycleGAN+多残差动态融合网络及本文方法的合成图像进行定量分析.在CUFS数据库上合成图像的SSIM、FSIM、LPIPS值如表5和表6所示.
| 表5 各方法在CUFS数据库上合成照片的指标值对比 Table 5 Index comparison of photos synthesized by different methods on CUFS database |
| 表6 各方法在CUFS数据库上合成素描的指标值对比 Table 6 Evaluation index comparison of sketches synthesized by different methods on CUFS database |
由表5和表6可看出, 使用密集残差网络替换残差网络合成图像质量相对较差, 在CycleGAN中加入感知损失后合成图像质量有所提高, 但相比加入多尺度感知损失后, 合成图像的质量提升有限.在基线网络中加入多尺度感知损失后合成图像的LPIPS值低于基线网络和多残差动态融合网络, 说明多尺度感知损失可使合成图像在视觉上更接近真实图像, 大幅改善图像视觉效果.而加入多残差动态融合网络合成图像在SSIM、FSIM指标上都取得最优结果, 说明多残差动态融合网络合成图像在结构和特征上与真实图像更接近, 大幅提高合成图像的质量.上述实验说明说多残差动态融合网络和多尺度感知损失的有效性.
本文提出基于多残差动态融合生成对抗网络的人脸素描-照片合成方法.网络中两个生成器和两个判别器循环工作并相互约束.在生成器中融入设计的多残差动态融合网络, 对输入图像提取丰富的多样化特征信息, 减少在网络传播中造成的逐级特征信息丢失, 通过动态融合方式有效去除多样化特征信息中的冗余信息, 减少冗余信息对合成图像的干扰.同时设计多尺度感知损失, 对网络提供额外的正则化, 对不同分辨率的合成图像进行由粗到细的迭代细化, 促使合成图像与真实图像具有相同的风格, 使生成器生成更自然逼真的图像.在CUFS、CUFSF数据库上的定性分析和定量评估结果表明, 本文方法可合成面部清晰、细节完整、颜色一致的高质量图像, 具有良好的鲁棒性.今后将进一步研究人脸图像的多风格化合成.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|