
{kind=link}
{kind=link}
基于梯度的对抗排序攻击方法
[吴晨1, 2  , 张儒清
, 张儒清1, 2 , 郭嘉丰1, 2 , 范意兴1, 2 ]
, 张儒清, 郭嘉丰, 范意兴]
|
|



作者简介:

吴 晨,博士研究生,主要研究方向为信息检索、自然语言处理.E⁃mail:wuchen17z@ict.ac.cn.

郭嘉丰,博士,研究员,主要研究方向为数据挖掘、信息检索.E⁃mail:guojiafeng@ict.ac.cn.

范意兴,博士,助理研究员,主要研究方向为数据挖掘、信息检索.E⁃mail:fanyixing@ict.ac.cn.
互联网检索中普遍存在排名竞争这种对抗攻击行为,会产生许多不良影响,因此对攻击方法的研究有助于设计更鲁棒的排序模型.已有的攻击方法容易被人识别且无法有效攻击神经排序模型.因此,文中提出基于梯度的对抗排序攻击方法.方法分为3个模块:基于梯度大小的词重要度排序、基于梯度的排序攻击和基于词嵌入的同义词替换.针对给定的目标排序模型,首先基于构建的排序攻击目标进行梯度回传,利用梯度信息在指定文档上找到最重要的词.然后,基于投影梯度攻击原理,在词向量空间上对这些最重要的词进行扰动.最后,利用同义词替换技术将这些最重要的词替换为和原词语义相近且和扰动后的词向量最近邻的词,完成文档扰动.在MQ2007、MS MARCO数据集上的实验验证文中方法的有效性.
About Author:
WU Chen, Ph.D. candidate. His research interests include information retrieval and na-tural language processing.
GUO Jiafeng, Ph.D., professor. His research interests include data mining and information retrieval.
FAN Yixing, Ph.D., assistant professor. His research interests include data mining and information retrieval.
Ranking competition is prevalent in Web retrieval, and undesirable effects are caused by this adversarial attack behavior. Thus, the study on attack methods is conducive to designing a more robust ranking model.The existing attack methods are recognized by people easily and cannot attack neural ranking models effectively.In this paper, a gradient-based adversarial attack method(GARA) is proposed, including gradient-based word importance ranking, gradient-based adversarial ranking attack and embedding-based word replacement. Given a target ranking model, the backpropagation is firstly conducted based on the constructed ranking-based adversarial attack objective. Then the most important words of a specific document is recognized based on the gradient information. These important words are perturbed in the word embedding space based on the projected gradient descent. Finally, by adopting the counter-fitting technology, the document perturbation is completed by substituting the important word with its synonym which is semantically similar to the original word and nearest to the perturbed word vector.Experiments on MQ2007 and MS MARCO datasets demonstrate the effectiveness of the proposed method.
本文责任编委 马少平
Recommended by Associate Editor MA Shaoping
在互联网检索中普遍存在排名竞争现象[1]:一些文档的内容拥有者故意改变文档内容, 使文档的排序位置在某些特定的查询下更靠前, 获得更高的关注度.这种排名竞争会产生不良影响, 整体的排序性能会因这种行为而有所下降.因此, 针对排名竞争攻击的研究对于维护检索结果的公平性具有积极意义.
随着深度学习的发展, 神经排序模型因为其强大的表示能力被越来越多地运用到搜索引擎当中.然而, 面向图像和文本分类的深度模型对于对抗攻击十分脆弱[2, 3].因此深度排序模型也存在类似的脆弱性.对于单个文档, 在文档内容上十分细微的扰动可能会极大地影响排序结果.这对排序模型的危害很大.因此, 在文本检索的场景下, 研究深度排序模型的对抗攻击, 设计更鲁棒的排序模型具有积极意义.
对抗攻击在图像领域已被广泛研究[3, 4, 5, 6, 7].核心思想是寻找一个难以被人发觉的最小扰动以最大化预测失误的风险.强大的攻击方法之一是投影梯度下降(Projected Gradient Descent, PGD)[8], 它利用模型的梯度信息扰动输入, 使分类错误.
在文本领域, 对抗攻击的方法也运用到如文本分类[9, 10, 11, 12]、情感分析[11, 12, 13, 14]和自然语言推断[13, 15]等任务中.面对文本的离散性挑战, Gong等[16]提出在词嵌入空间中使用快速符号梯度法(Fast Gradient Sign Method, FGSM)[3]造成扰动, 并使用最近邻搜索法产生词粒度的攻击.然而, 此方法容易造成扰动后的文本和原文本语义相差甚远, 甚至语法上也不通顺[17].近年来, Jin等[18]通过词重要度排序, 将原文本中的重要词替换为和原词语义近似、能使目标模型预测错误的风险最大的词.这一框架保证对抗攻击的稀疏性, 也确保文本的语义连贯性, 在文本对抗攻击中的很多工作都使用这一框架.然而, 这一框架完全舍弃梯度攻击的优势, 替换词的过程过于启发式, 无法保证攻击的效率和成功率.
在信息检索领域, 对抗攻击仍未得到充分研究.对抗信息检索中的早期工作集中在识别和解决不同类别的垃圾网页[19].近年来, Goren等[20]研究网页检索中的排名竞争现象.在图像检索领域, Liu等[21]认为对抗的查询会导致不正确的检索结果.Li等[22]使用通用扰动, 对基于列表的排序结果造成相似的攻击.Zhou等[23]设计基于排序的攻击目标, 结合PGD提出对候选图像提升或下降排序位置的攻击.然而, 上述工作未考虑文本的离散化特性, 攻击方法难以直接应用到文本信息检索中.
排名竞争中已有的传统攻击方法, 如基于内容的Spamming方法[24], 忽略改变后的文档和原始文档的语义相似性, 导致人们能够轻易识别攻击.同时, 方法没有针对神经排序模型进行设计, 无法有效攻击神经排序模型.因此, 本文提出基于梯度的对抗排序攻击方法(Gradient-Based Adversarial Ranking Attack, GARA).通过梯度攻击的原理, 将原文档中最重要的部分词修改为其语义空间上相近的近似词, 提升文档的排序位置.具体地, GARA分为3个模块:基于梯度大小的词重要度排序、基于梯度的排序攻击和基于词嵌入的同义词替换.针对给定的目标排序模型, 首先基于构建的排序攻击目标进行梯度回传, 利用梯度信息在指定文档上找到最重要的词.再基于投影梯度攻击的原理, 对这些词在词向量空间上进行扰动.最后, 利用同义词替换(Counter-Fitting)算法[25]将这些词替换为和原词语义相近且和扰动后的词向量最近邻的词, 完成文档扰动.在MQ2007、MS MARCO数据集上的实验表明, GARA能有效攻击神经排序模型, 上升文档的排序位置, 同时保持良好的语义相似性.
给定一组查询Q={q1, q2, …, qm}和一个训练好的目标排序模型f, 并指定一篇需要攻击的文档d', 本文提出的基于梯度的对抗排序攻击方法(GARA)在文档d'上添加一定的扰动, 提升排序位置.
总体上, GARA由3步组成.1)基于梯度大小的词重要度排序.针对目标排序模型, 在指定的文档d'上找到其最重要的N个词.2)基于梯度的排序攻击.基于投影梯度攻击原理, 对这些词在词向量空间上进行扰动攻击.3)基于词嵌入的词替换.将这些词替换为和原词语义相近的词.
GARA具体步骤如算法1所示.
算法 1 GARA
输入 一组查询Q={q1, q2, …, qm},
训练好的目标排序模型f,
指定要攻击的文档d'
输出 被攻击后的文档dadv
基于梯度大小的词重要度排序
d'={w1, …, wi, …} // 输入指定文档中的词
通过Q和f检索m个排序列表D={l1, l2, …, lm}
for wi in d' do
计算词重要度打分
end for
得到待攻击词列表L= {wt1, wt2, …, wtN}
//使用
个词列表
基于梯度的排序攻击
待攻击词集合watk={wt1, wt2, …, wtN}
映射到词向量集合为eatk={
计算攻击词向量
得到扰动后的词向量集合
基于词嵌入的词替换
for wti in watkdo
在原词嵌入Counter-Fitted后的词嵌入空间中,
找到top k个最近邻的相似词,
将top k个词映射回原词嵌入空间
找到和扰动后的词向量e
为最终的替换词
end for
返回 被攻击后的文档dadv
不同于计算机视觉中的对抗攻击可针对整幅图像, 在文本中词的改变相对容易被人发现.所以寻找最重要的词攻击, 可有效减少词数目的改变, 使人们不易察觉这一扰动, 并使攻击的效率更高.受到Xu等[26]的启发, 本文的核心思想是利用梯度越大的词对于优化目标的影响力越大的假设, 针对排序攻击的场景设计相应的攻击目标, 挑选其中梯度最大的前N个词进行攻击.
假设d'={w1, w2, …, wi, …}表示输入文档中的词, 词wi的重要度打分为:
其中, LRA为本文定义的针对排序场景的攻击目标,
再根据计算的重要度得分
不同于分类对抗攻击中直接加分到目标类概率或减分到正确类概率的简单攻击目标, 排序对抗攻击问题不仅要考虑文档本身, 还要考虑整个文档列表的相关性.本文的核心思想是根据排序场景的特点, 构造基于排序的对抗攻击目标, 并使用投影梯度下降法在词向量空间上对文档进行扰动.
本文想找到指定文档d'上的扰动r, 对所有的q∈ Q, 提升该文档的排序位置:
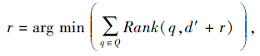
其中Rank为文档的排序位置.但是, 排序位置Rank(q, d'+r)是离散的, 不能直接解决这一优化问题.为了解决这一问题, 需要一个替代优化目标.
首先利用给定的目标排序模型f, 结合查询集合Q, 检索m个排序列表:
D={l1, l2, …, lm}, li={di1, di2, …, diu}.
因为想让指定文档d'对所有的q∈ Q都排到最前面, 所以对∀ dij∈ li, 有
这里, 结合神经排序模型中常用的基于文档对的排序损失, 将这一系列不等关系建模成基于排序的攻击目标:
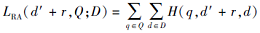
其中,
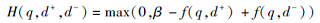
为Hinge loss, β 为边距超参数, 一般指定为1.通过这种方式, 原始问题可转化为针对基于排序的攻击目标的优化问题, 即找到文档上扰动r以最小化攻击目标:
r=arg min LRA(d'+r, Q; D).
本文使用投影梯度下降法[8]解决这一优化问题.具体地, 为了找到对抗扰动r以得到扰动后的文档dadv=d'+r, 投影梯度下降法在每轮t=1, 2, …, η 中, 使用梯度g(
其中,
g(
为文档在第t轮的梯度, α 为攻击步长的超参数,
在η 轮迭代之后, 原始文档改成满足尽可能多的不等式(式(2))的文档.因为每条不等式都表示一个文档对排序的子问题, 因此最终得到的文档会对Q中的任意查询都排到其它文档的前面.
因为文本中的词是离散的, 所以只对1.2节中选择的最重要的N个词的词向量进行梯度攻击.假设这些词watk={wt1, wt2, …, wtN}, 对应的词向量eatk={
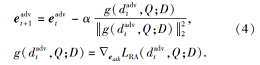
基于梯度攻击的方式针对排序攻击的目标直接优化, 相比启发式的替换词方法更高效.
在词向量空间产生攻击后, 需要找到具体的词来替换原词.在1.2节中, 确保攻击尽量少的词; 在1.3节中, 保证攻击的高效达成.本节需要确保替换后的词和原词的语义一致性, 保证这一扰动不易被人发觉.核心思想是找到待替换的词在同义词嵌入空间中最临近的词集合, 选择其中和被攻击后的词向量在原词嵌入空间最相邻的词并进行替换.
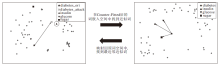
这一过程如图1所示.因为在模型原始的词空间(如基于全局词向量(Global Vectors for Word Representations, GloVe)[27]的词嵌入空间等)直接寻找相似的词进行替换面临着如下的问题:不仅相似的词(如同义词)和原词的距离较接近, 相关的词(如反义词)也会较接近[28].所以使用Counter-Fitted后的词嵌入[25]解决这一问题.Counter-Fitting是对词嵌入快速后处理的过程, 能将相似词推得更近, 同时将相关的词推得更远.其结果是产生只有同义词更靠近彼此的词嵌入.
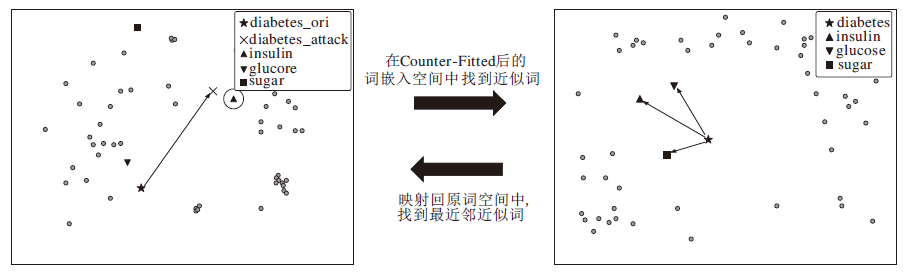 | 图1 词替换过程示意图Fig.1 Sketch map of word replacement process |
对于1.2节中选择的重要词, 首先对原词嵌入矩阵进行Counter-Fitting, 并在Counter-Fitted后的词嵌入空间中找到近似词.例如, 针对词diabetes找到近似词, 分别为insulin、glucose、sugar.然后, 将其映射回原词空间, 并选择其中被梯度攻击后的词向量(如× 所示, 标记为diabetes_attack)最近的词(如▲所示, 标记为insulin), 作为最终的替换词.
这种攻击方式不仅确保替换后的词和原词的语义一致性, 也最大程度地保留梯度攻击的高效性, 达到两者间的平衡.
采用ad-hoc检索下的MQ2007、MS MARCO公开数据集进行实验.MQ2007数据集是一个LETOR数据集[29], 包含1 692个TREC 2007 Million Query Track的查询, 及65 233个从GOV2的25万网页中采样的文档.平均每个查询有10个相关文档.MS MAR-CO数据集为TREC 2020 Deep Learning Track发布的用于网页文档检索的数据集, 包含3 210 000个文档, 其中367 013个查询用于训练, 5 193个查询用于测试.大多数查询只有一个相关文档.
本文采取如下评价指标:扰动后的文档比原文档的排序提升百分比和扰动后的文档和原文档的语义相似度, 分别衡量扰动对于排序提升的效果和对于语义一致性的保持.
假设对于查询集合Q, dadv为原文档d扰动后的文档, 排序提升定义为
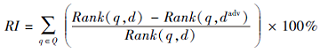
其中Rank为文档的排序位置.
本文使用通用句子编码器(Universal Sentence Encoder, USE)[30]衡量原文档和扰动后文档的语义相似度.2个对比文档通过通用句子编码器后表示为余弦相似度, 输出值在-1~1之间, 值越大表示两个文档的语义相似度越大.
因为之前还没有相应工作探索过文本检索领域的对抗攻击, 所以对比的基线方法如下.
1)随机替换词的方法(简记为Random swap).随机选取原文档中的词, 并替换成随机的词.
2)基于内容的Spamming方法(简记为Spam-ming)[24].选取原文档中末尾的词, 并替换为查询中的词.
为了公平对比, 在基线方法中, 设置选取的原文档的词的个数和GARA中的重要词个数N相同.
GARA可对任意使用词嵌入的神经排序模型进行攻击.这里选择被广泛使用的BERT(Bidirectional Encoder Representations from Transformers)和卷积化的基于核的神经排序模型(Convolutional Kernel-Based Neural Ranking Model, Conv-KNRM)进行攻击.BERT应用多层双向Transformer 编码器架构对语言建模.将查询和文档进行拼接, 加入[CLS]和[SEP]后, 输入BERT进行交叉注意力交互, 得到表达.再将表达输入全连接层, 得到相应打分.Conv-KNRM是一个以交互为中心的神经排序模型, 基于卷积和核池化, 建模文档和查询的n-gram软匹配.
本文的神经排序模型使用Matchzoo[31]进行训练, BERT采用谷歌公布的BERTbase参数进行初始化.Conv-KNRM中设置最大n-gram数为3, 核数为11.采用自适应矩估计(Adaptive Moment Estimation, Adam)[32]优化器进行优化, 并对学习率进行动态调整.
对于GARA, 尝试调整不同的重要词个数N、不同的攻击步长α 和迭代轮数η , 并选择最优值.
本文分别测试在查询个数为1, 3, 5时, 各方法对于文档的排名提升效果.在MQ2007、MS MARCO数据集上, 对BERT和Conv-KNRM进行攻击, 结果如表1和表2所示.
| 表1 各方法在MQ2007数据集上的攻击结果 Table 1 Attack result of different methods on MQ2007 dataset |
| 表2 各方法在MS MARCO数据集上的攻击结果 Table 2 Attack result of different methods on MS MARCO dataset |
由表1和表2可知:1)随机替换词的方法不能有效提升文档的排序位置, 甚至还可能降低排序, 并且扰动后的文档和原文档的语义相似度很低.2)传统的Spamming方法虽然可提升文档的排序, 但未注意保持文档的语义连贯性, 导致扰动后的文档和原文档的语义相似度较低, 容易被人发觉.另外, Spam-ming方法对于排序的提升远低于GARA.这说明传统的攻击方法没有针对神经排序模型设计, 无法有效攻击神经排序模型.3)当给定的查询数目提升时, GARA的排序提升和语义相似度呈现下降趋势.这是因为GARA需要对多个查询寻找一个最优的扰动文档, 当查询数目提升时, 优化的难度增加.4)GARA取得最高的排序提升和语义相似性.例如在MQ2007数据集上, BERT作为神经排序模型, 对于给定的3个查询, GARA能提升90%的排序并达到0.63的语义相似度.这说明GARA能有效攻击神经排序模型, 保持良好的语义相似性.
本文分析基于词嵌入的同义词替换对于扰动的不易觉察性(Imperceptibility)的作用.基于BERT模型, 在MS MARCO数据集关于“ 争论辩论的含义” 的查询上进行个例分析, 对比基于词嵌入的同义词替换和去掉该模块, 即直接在梯度攻击后的词向量附近寻找最近邻词以这两种方式产生的扰动文档.
实验结果如表3所示.原文档文本片段中的黑体字母表示原文档中被选中要攻击的词, 其余的黑体字母分别表示GARA产生的扰动文档中改动的词和去掉同义词替换后产生的扰动文档中改动的词.由表可看到, 基于词嵌入的同义词替换把原文档中的词替换成语义相近的同义词, 如entry→ entries, cite→ quoting等, 读起来和原文档十分接近, 所以和原文档达到0.87的语义相似度.而去掉这一同义词替换模块后, 产生的扰动词和原文档中的词意思相差甚远甚至完全无关, 如up→ bonaparte, papers→ sword等.这是因为词向量上的扰动只保证目标文档会在排序上得到提升, 因此扰动后的词向量可能和原词向量的差别非常大, 甚至造成对应的词和原词丝毫没有关联.
| 表3 去掉同义词替换模块前后的对比 Table 3 Comparison before and after removing synonym replacement module |
这一结果表明, GARA产生的扰动文档和原文档非常接近, 不易被人轻易觉察, 符合对抗攻击中微小的扰动能产生深刻影响的原则.而没有同义词替换模块的算法产生的扰动相当随意, 容易被人识别.
选择多少个最重要的词进行攻击也是GARA中重要的超参数.本节分析攻击词的个数对于攻击结果的影响.基于BERT模型, 在MQ2007数据集上进行分析实验, 让攻击词的个数N在1~150(接近文档中包含最多不重复词的个数)之间变化, 查看攻击效果.N不同时对语义相似度和排序位置的影响如图2所示.
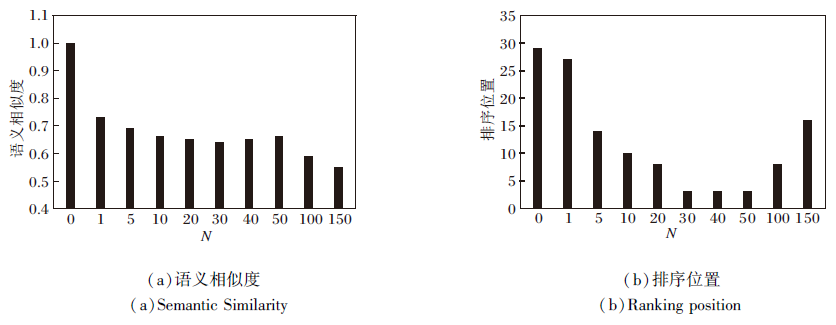 | 图2 攻击词的个数对于排序位置和语义相似度的影响Fig.2 Effect of different numbers of attacking words on ranking position and semantic similarity |
由图2可看到, 随着攻击词数目的上升, 语义相似度整体呈现下降的趋势, 这说明替换的词越多, 扰动后的文本和原文本越不相似.随着攻击词数目的上升, 扰动文档的排序位置先下降后上升, 说明当扰动词小于一定的阈值时, 替换越多的词文档的排序会越靠前.但是, 当扰动词的数目大于一定值时, 再扰动新的词不但不能使文档继续上升排名, 反而会使文档的排名下降.这可能是因为后续的扰动加入更多的同义词噪声, 干扰神经排序模型.
本文针对信息检索中排名竞争的场景, 提出基于梯度的对抗排序攻击方法(GARA).通过寻找原文档中最重要词, 结合针对排序场景的对抗攻击目标和投影梯度方法, 在词嵌入空间上对重要词的词向量产生扰动.最后, 结合Counter-Fitting算法将待攻击的词替换成同义词, 完成文档攻击.选择BERT模型和Conv-KNRM模型进行攻击, 在MQ-2007、MS MARCO数据集上的实验表明, GARA能有效攻击神经排序模型, 上升文档的排序位置, 并且保持良好的语义相似性.同时还通过分析实验, 说明同义词替换对于造成不易被人察觉的攻击的重要性.另外也探索不同的攻击词数目对于攻击效果的影响.今后可探索如何针对目前的攻击方法设计相应的防御方法, 设计更鲁棒的神经排序模型.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|