
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
用于方面情感三元组抽取的词对关系学习方法
[夏鸿斌1, 2  , 李强
, 李强1 , 肖奕飞1 ]
, 李强, 肖奕飞]
|
|



作者简介:

李 强,硕士研究生.主要研究方向为自然语言处理、机器学习.E⁃mail:1712127663@qq.com.

肖奕飞,硕士研究生,主要研究方向为自然语言处理.E⁃mail:462627212@qq.com.
方面情感三元组抽取旨在识别一条评论中的方面项及其情感倾向,并提取与其相关的观点项.现有方法大多将该类任务分为多个子任务,将子任务组成流水线并完成这类任务.然而,基于流水线思想的方法在实际应用中会受到误差传播、不易使用等因素的影响.为此,文中提出词对关系学习方法,将方面情感三元组抽取任务转化为端到端的词对关系学习任务.方法包含一种可将句中的词对关系进行统一标注以表示所有三元组的词对关系标注的方法,以及为此特别构建的可输出词对关系的词对关系网络.首先,使用双向门控循环单元和混合式注意力对句子进行编码表示.然后,使用注意力图转换模块将句子编码转换为各项标签概率.最后,从词对关系标签结果中提取三元组.此外,将预训练的BERT(Bidirectional Encoder Representation from Transformer)应用于文中方法.在4个标准数据集上的实验表明,文中方法性能较优.
About Author:
LI Qiang, master student. His research interests include natural language processing and machine learning.
XIAO Yifei, master student. His research interests include natural language processing.
Aspect sentiment triplet extraction is designed to identify aspect items with their sentiment tendencies in a comment and to extract the related opinion items. In most of the existing methods, this type of task is divided into several sub-tasks, and then the task is completed by the pipeline composed of the sub-tasks. However, the methods based on pipeline are affected by error propagation and inconvenience for use in practice. Therefore, a word-pair relation learning method for aspect sentiment triplet extraction is proposed, which transforms the aspect sentiment triplet extraction task into an end-to-end word-pair relation learning task. The method contains a word-pair relation tagging scheme, which can unify word-pair relations in sentences to represent all triplets, and a specially built word-pair relation network to output word-pair relation. Firstly, the sentence is encoded by bidirectional grated recurrent unit and mixed attention. Then, sentence coding is converted into tag probabilities through the attention map transform module. Finally, the triplets are extracted from the result of the word-pair relation tag. In addition, the pre-trained bidirectional encoder representation from transformer is applied to the proposed method. Experiments on four standard datasets show that the proposed method is superior.
本文责任编委 马少平
Recommended by Associate Editor MA Shaoping
在自然语言处理领域中, 设计能自动执行情感分析和观点挖掘的有效算法是一项具有挑战性的任务[1, 2].近几年, 基于方面的情感分析(Aspect-Based Sentiment Analysis, ABSA)任务受到广泛关注, 研究者们将ABSA分为方面项提取任务、观点项提取任务和方面情感分类任务.Xue等[3]提出MTNA(Multi-task Neural Networks for Aspect Classification and Ex-traction), 通过BiLSTM(Bi-directional Long Short-Term Memory)对句子进行编码, 再使用卷积神经网络(Convolutional Neural Network, CNN)建立局部依赖, 最后将BiLSTM的输出与CNN的输出相加, 得到词语的最终表示, 并使用softmax层对各词进行分类, 得到方面项.Yang等[4]提出选取格编码(Con-stituency Lattice Encoding)完成方面项抽取任务, 首先根据句子的短语结构树(Constituency Tree)构建包含短语的选取格结构, 然后融合每个选取格的词向量, 最后使用BiLSTM-CRF(BiLSTM-Conditional Random Field)或BERT(Bidirectional Encoder Representation from Transformers)对选取格向量进行编码并分类.
方面情感分类任务是ABSA中的一个子任务, 主要是对方面项和上下文的依赖进行建模, 再进行情感分类.Tang等[5]提出TD-LSTM(Target-Dependent LSTM), 首先使用两个方向的LSTM(Long Short-Term Memory)分别对方面项的上下文进行建模, 再拼接两者的输出, 最后进行情感分类, 这在一定程度上捕获方面项和上下文之间的联系.Ruder等[6]使用BiLSTM对整个上下文进行建模, 获得更好的上下文表示.Wang等[7]和Liu等[8]将注意力机制引入方面情感分类任务, 加强方面项与上下文的依赖关系, 提高模型对观点项的关注.Zhang等[9]和Wang等[10]认为句子本身的语法复杂性使模型对观点项的捕获变得困难, 因此使用图神经网络建模句子的语法结构, 提高模型对观点项的关注.
将方面项提取任务、观点项提取任务和方面情感分类任务作为单独的任务进行研究, 对于实际应用的贡献十分有限, 因此一些研究者联合各个子任务, 完成一个完整的ABSA任务.Li等[11]提出统一的序列标注模型, 致力于解决结合方面项抽取和方面情感分类的联合任务, 结合BIOES标签与情感标签以标注整个序列, 并使用神经网络模型预测联合的标签.网络主要由两层LSTM组成, 上层LSTM用于预测联合的标签, 下层LSTM用于执行辅助任务— — 方面项的边界检测.He等[12]提出交互式多任务学习网络, 具有消息传递机制, 能在单词级别和文档级别同时学习多个任务.
然而, 上述研究都不能算是一个完善的解决方案.为此, Peng等[13]提出ASTE(Aspect Sentiment Trip-let Extraction)任务, 结合3个子任务, 提取句子中的方面-情感-观点三元组.为了解决ASTE任务, Peng等[13]提出两段式流水线模型.在第一阶段, 提取潜在的方面项及其情感极性, 并提取潜在的观点项.在第二阶段, 将各方面项与相应的观点项配对.Chen等[14]提出RACL(Relation-Aware Collaborative Lear-ning), 每层由AE(Aspect Term Extraction)、OE(Opi-nion Term Extraction)和SC(Aspect-Level Sentiment Classification)3个模块构成, 分别用于相应子任务.各模块拥有独立的特征抽取器, 通过矩阵乘法结合3个任务间的联系, 达到最终预测性能提升的目的.Chen等[15]将ASTE任务转换为一个多轮机器阅读理解(Multi-turn Machine Reading Comprehension)任务, 提出BMRC(Bidirectional Machine Reading Com-prehension)框架.Jian等[16]提出分层强化学习框架, 首先识别句子中具有的情感极性, 再使用单独的强化学习过程识别与相应情感相关的方面项和观点项, 这种分层强化学习结构可有效处理多个三元组和重叠的三元组.Xu等[17]提出Span-Based ASTE, 在预测方面-观点对的关系上直接捕捉跨度到跨度而非词间的交互关系, 使用神经网络显示生成所有可能的方面项和观点项的跨度表示, 并独立预测所有可能方面-观点对的情感关系.
虽然上述方法对ASTE任务的完成具有一定帮助, 但多段式方法难以有效结合各阶段的信息, 会受到误差传播及不易使用等因素的影响, 对实际应用的提升效果有限.
Xu等[18]提出位置感知标注方法, 将序列抽取任务中常用的BIOES标签中的B和S融入方面的情感及方面项与观点项的相对距离, 以此完成一个端到端的三元组抽取任务.然而, 这种方法只能处理固定窗口中的方面项和观点项.Wu等[19]提出GTS(Grid Tagging Scheme), 通过网格标注句子中所有的词对关系, 以便于三元组的抽取, 并基于此标注方法设计相应模型, 以端到端的形式解决ABSA任务.但是, 该标注方法将方面项或观点项中各单词视作同等重要的地位, 不利于模型找全多个单词组成的方面项和观点项.GTS拼接词对表示, 用于生成网格标签, 使最终的分类结果只考虑到词对之间的关系, 却忽略其它词对它们的影响.
因此, 本文提出词对关系学习方法, 完成ASTE任务, 将ASTE任务视作一个词对关系学习(Word-Pair Relation Learning, WPRL)任务.首先, 在GTS[19]的基础上提出词对关系标注方法(Word-Pair Rela-tion Tagging Scheme, WPRTS), 将句子中的三元组信息融入词对关系标签, 然后, 借鉴多头自注意力的思想构建词对关系网络(Word-Pair Relation Net-work, WPRN), 学习标签.在4个标准数据集上的实验表明, 本文方法性能较优.
给定一个句子c={wi|i∈ [1, n]}, 包含n个单词, ASTE任务的目标是从中抽取出一个方面-情感-观点三元组
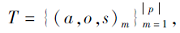
其中, a表示一个方面项, o表示与方面项a相关的一个观点项, s表示方面项的情感倾向, 且一个a可能对应多个不同的o, 一个o也可能具有多个不同的a.
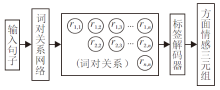
为了完成ASTE任务, 本文提出词对关系学习方法, 首先将句子中蕴含的三元组关系通过一种统一的关系标签进行表示, 然后使用神经网络模型学习并预测该标签.使用词对关系网络将句子进行编码并输出各词对关系表示, 同时使用词对关系标签解码器将词对关系标签进行解码, 得到句子中所有的方面情感三元组.本文方法整体框图如图1所示.
 | 图1 本文方法整体框图Fig.1 Overall structure of the proposed method |
1.1.1 标签构造
为了完成ASTE任务, 词对关系标注方法(WPRTS)使用8个标签{A, AR, O, OR, Pos, Neu, Neg, N}表示一个句子中任意单词对(wi, wj)的关系.此处的单词对(wi, wj)是无序的, 因此, 单词对(wi, wj)和(wj, wi)具有相同的标签.8个标签表示的含义如表1所示.
| 表1 WPRTS中标签含义 Table 1 Meaning of WPRTS tags |
相比GTS[19], 本文主要改进如下:使用词语片段末端的单词表示整个词语项, 因为通常认为一个词语片段中最后一个词往往是整个词语的语义中心, 对于词语项内部的其它词, 视作与该词语项具有相关关系.如使用A(Aspect)表示同一方面项(末端)词之间的关系, 而使用AR(Aspect-Related)表示方向项中其它单词与方面项(末端)的关系.
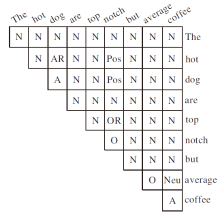
同时, 为了促进神经网络对方面项和观点项的建模, 本文只对观点项末端词和方面项中所有单词标记为情感极性的标签(Pos, Neu, Neg), 因为本文认为观点项末端词表示整个观点项, 只有它才能完整表示情感倾向, 而方面项的情感由各方面词共同决定较恰当, 同时单个末端词的标签也不利于神经网络的建模.为了加快计算, 使用一个上三角矩阵构造标签, 图2为句子“ The hot dog are top notch but average coffee” 构造的词对关系标签.
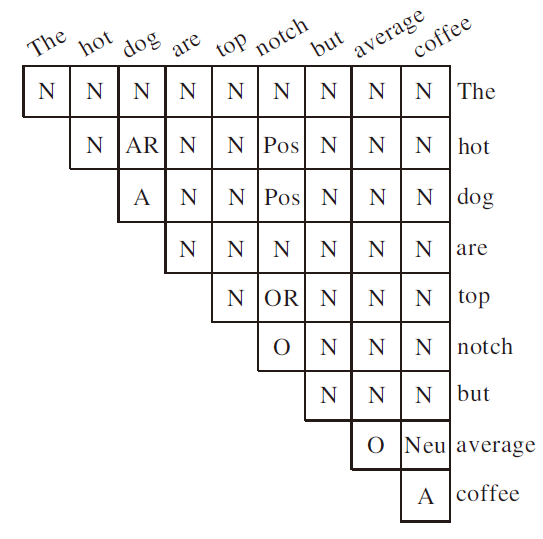 | 图2 WPRTS标注示例Fig.2 Tagging example with WPRTS |
1.1.2 标签解码器
本节关注如何根据所有标签的结果进行解码, 得到最终的方面-情感-观点三元组.实际上, 本文使用神经网络及标签进行训练并预测.
当获得一个句子的WPRTS标注结果后, 可通过严格的匹配从如图2的标签中提取三元组.然而, 由于WPRTS标注结果中包含大量无用的N标签, 可能会降低三元组的整体召回率, 因此, 需要降低三元组匹配的限制.
解码细节如算法1所示.首先, 在标签矩阵的对角线找到标签A、O, 向上找到标签AR、OR, 组成完整的方面项或观点项.遍历每个方面项和观点项交点处的标签, 如果存在情感极性的标签, 将该方面-观点对的情感设置为最多标签的情感, 如果存在标签数相同的情况, 选择顺序为{消极, 积极, 中性}.最后, 组成三元组.
算法 1 WPRTS解码算法
输入 一个句子的WPRTS标注结果R(wi, wj)
输出 方面-情感-观点三元组T
初始化 方面项集A、观点项集O、三元组T为空集
1./* 第2行到第9行为方面项提取伪代码, 观点
项提取与此同理, 不再赘述* /
2. while a span left index 0< l≤ r and right index
r< n do
3. if R(wi, wi)=A then
4. r← i
5. if F(wi, wr)=A or AR and R(wi-1, wr)≠ A_I
6. l← i, 将单词片段(wl, …, wj)视为一个方
面项a, A← A∪ {a}
7. end if
8. end if
9.end while
10.while a∈ A and o∈ O do
11. while wi∈ a and wj=o_end do
12. 初始化s为None
13. if num(Neg)≥ num(Neu) and
num(Neg)≥ num(Pos)
14. then s← Neg
15. else if num(Pos)≥ num(Neg) and
num(Pos)≥ num(Neu)
16. then s← Pos
17. else if num(Neu)≥ num(Neg) and
num(Neu)≥ num(Pos)
18. then s← Neu
19. end if
20. if s≠ None
21. then T∪ {a, s, o}
22. end if
23. end while
24.end while
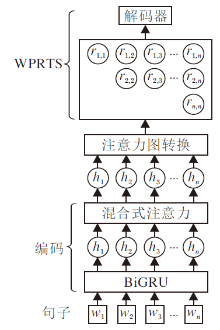
为了验证词对关系学习方法的有效性, 设计基于双向GRU(Bi-directional Gate Recurrent Unit, BiGRU)的词对关系网络(WPRN), 整体架构如图3所示.
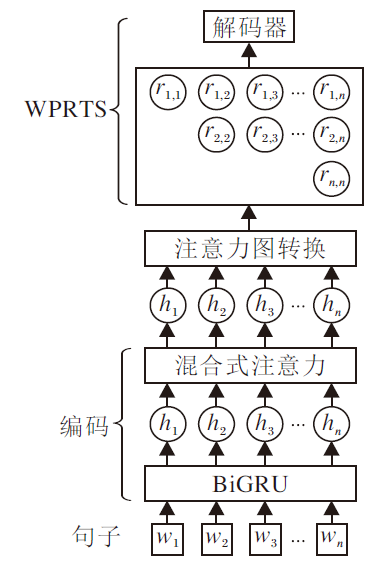 | 图3 WPRN整体架构Fig.3 Overall structure of WPRN |
WPRN首先使用由BiGRU和混合式注意力组成的编码层对输入句子进行编码, 然后使用注意力图转换(Attention Map Transform)模块将句子编码转换为词对间的注意力图, 以此表示单词对间的关系, 最后使用1.1.2节描述的解码器对得到的标签进行解码, 得到句子中的所有三元组.
1.2.1 编码
给定一个句子c={wi|i∈ [1, n]}, 将其映射到一个高维度空间, 得到一个初步的句向量V∈
GRU(Gate Recurrent Unit)是循环神经网络的一种, 如同LSTM, 也是为了解决长期记忆和反向传播中的梯度等问题而提出的.相比LSTM, 使用GRU能达到较优效果, 更容易进行训练, 大幅提高训练效率, 因此本文在编码层使用GRU.将句子的词向量V输入BiGRU编码层后, BiGRU会拼接两个方向的GRU输出的隐藏状态向量, 得到H∈
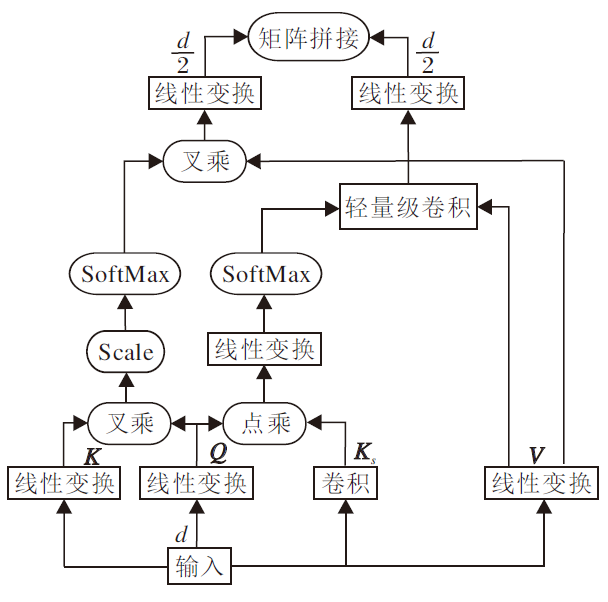
为了获得更好的表示, 并加强各词之间的联系, 本文使用一个注意力层.在方面情感分析中, 方面项与观点项通常在一段局部上下文中, 而非全局上下文中, 因此, 使用混合式注意力加强编码.混合式注意力的结构[20]如图4所示.
混合式注意力由可建模局部依赖的区间动态卷积和可建模全局依赖的自注意力混合而成, 兼具两者优点.
自注意力可以对输入序列中的全局依赖进行建模.首先对输入X进行三次线性变换, 得到键K∈

轻量级卷积可有效建模局部依赖.相比标准卷积, 轻量级卷积沿通道维度绑定权重, 显著减少参数.计算公式如下:
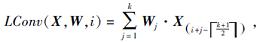
其中, X为输入向量, Wj∈ Rk, k为卷积核尺寸.
区间动态卷积首先使用深度可分离卷积收集区间内token的信息, 然后动态生成卷积核.输入token的局部关系是根据局部上下文而不是单个token生成的, 这有助于卷积核更有效地学习局部依赖.计算公式如下:
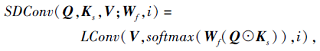
其中☉表示逐点相乘.
最终的混合式注意力为:
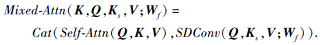
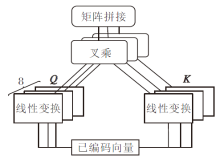
1.2.2 注意力图转换
受transformer[21]的启发, 本文将自注意力的注意力图作为句子中各词对的关系图, 并使用多头注意力得到注意力关系图R.使用多头注意力的每个头表示一种标签关系.注意力图转换模块结构如图5所示.
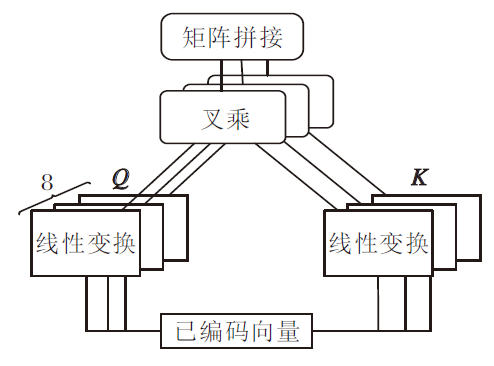 | 图5 注意力图转换模块结构图Fig.5 Structure of attention map transform |
具体计算过程如下:
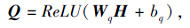

其中, Q∈ Rn× d, K∈ Rn× d, R∈ Rn× n× 8, n表示句子长度.
最后, 对注意力关系图R的最后一维使用一层softmax层, 获取每个标签的概率:
p=softmax(R).
1.2.3 损失函数
在得到词对的注意力关系图后, 对每个位置的标签计算交叉熵:
L=-
其中C为标签集{A, AR, O, OR, Pos, Neu, Neg, N}.
本文实验环境如下:CPU为Intel Core i7 8700K, GPU为GeForce GTX 1080, 内存为DDR4 16 GB, 开发环境为Linux64位系统和pytorch1.5.0.
为了验证本文方法的有效性, 在4个来源于SemEval竞赛[22, 23, 24]的ASTE基准数据集(https://github.com/xuuuluuu/SemEval-Triplet-data)上进行实验, 分别是SemEval 2014的笔记本电脑数据集(14lap)和Semeval 2014~2016的餐厅数据集(14res, 15res, 16res).其中的观点标签来源于文献[25].数据划分依据文献[9]的划分方式, 具体数据信息如表2所示.
| 表2 ASTE数据集统计信息 Table 2 Statistics information of ASTE datasets |
使用准确率(P)、召回率(R)和F1分数作为评估指标.只有当预测的方面范围、情感、观点范围和真实数据的方面范围、情感、观点范围完全相同时, 提取的三元组才被认为是正确的.
2.2.1 基线模型
为了测试本文方法的有效性, 使用目前用于解决ASTE任务的方法作为基线方法.
1)Peng等[13]为ASTE提出的一个两段式流水线模型.第一阶段提取句子中所有的方面项和情感倾向, 并提取观点项.第二阶段使用一个关系分类器, 将第一阶段得到的结果进行配对, 形成完整的三元组.
2)RINANTE+. Peng等[13]基于RINANTE(Rule Incorporated Neural Aspect and Opinion Term Extrac-tion)[25]构建的类似文献[13]模型的两段式模型.第一阶段使用RINANTE提取方面-情感对和观点项.第二阶段使用文献[13]模型中的关系分类器进行关系匹配.其中, RINANTE通过句子中词的关系共同抽取方面项和观点项.
3)CMLA+. Peng 等[13]基于CMLA(Coupled Multi-layer Attention)[26]构建的类似文献[13]模型的两段式模型.第一阶段使用CMLA抽取方面-情感对和观点项, 第二阶段使用文献[13]模型的关系分类器进行关系匹配.其中, CMLA 利用注意力机制捕获单词之间的依赖关系, 共同提取方面及其情感、观点项.
4)Li-unified-R.Peng等[13]基于Li 等[11]提出的模型构建的类似文献[13]模型的两段式模型.第一阶段使用文献[11]模型提取方面-情感对和观点项, 第二阶段使用文献[13]模型的关系分类器进行关系匹配.文献[11]模型通过一个定制的多层 LSTM 神经结构对方面及情感、观点项进行抽取.
5)JETt和JETo.Xu等[18]提出的以方面或观点为中心的位置感知标注方案, 并提出相应模型.
6)GTS.Wu等[19]提出的网格标注方法, 并分别基于CNN、BiLSTM及BERT设计的3个模型.
7)BMRC.Chen等[15]将ASTE任务转换为一个多轮机器阅读理解任务, 并使用预训练模型BERT进行训练.
8)RACL+R.Chen等[15]使用RACL(Relation-Aware Collaborative Learning)[14]抽取方面、观点和情感项, 然后使用BMRC匹配为三元组.此外, 这个模型也是基于BERT的.
9)WPRL.结合WPRTS和WPRN的词对关系学习方法.WPRL+BERT为将WPRN的编码部分替换为预训练的BERT模型.
2.2.2 参数设置
本文实验中使用预训练的300维GloVe(Glo-bal Vectors for Word Representation)(http://nlp.stanford.edu/projects/glove)向量初始化单词嵌入, 所有方法权重均按均匀分布进行初始化, 隐藏状态向量的维数设置为64, 使用自适应矩估计(Adaptive Moment Estimation, Adam)优化器, 学习率为0.001, 批尺寸大小为32.基于BERT的模型, 使用BERT-BASE(https://github.com/huggingface/transformers)模型.
各方法在4个数据集上的指标值对比如表3所示, 方法后加* 为本文训练得到的结果, 其它结果引用自原论文, 黑体数字表示最佳值.由表可知, 首先, 在未使用BERT的模型中, WPRL具有显著的性能提升, F1值具有4%~12%的提升, 这充分说明WPRL的有效性.其次, 在14res、16res数据集上, WPRL与使用BERT的WPRL+BERT的性能较接近, 甚至WPRL具有更高的精确率, 这说明本文提出的编码层的有效性, BiGRU结合混合注意力, 有效增强模型对句子的表示能力.最后, WPRL+BERT的F1值最高.此外, 本文方法在各数据集上表现均优于基线方法, 这表明本文提出的标注方法及网络模型的鲁棒性.
| 表3 各方法在4个数据集上的指标值对比 Table 3 Index value comparison of different methods on 4 datasets % |
2.4.1 标注消融实验
由于本文标注方法自GTS改进而来, 因此特地设计关于标注方法的消融实验, 验证WPRTS的有效性.两种标注方法都运行在WPRN上, 各项超参数设置均相同.
此外, 为了全面反映两种标注方法的性能, 将模型搜索方面项及观点项及最终的三元组匹配的F1指标作为评价标准, 结果如表4所示, 表中黑体数字表示最佳值.
| 表4 标注消融实验结果 Table 4 Results of tag ablation experiment % |
由表4所示, 本文的标注方法各项性能都优于GTS, 尤其是WPRTS对方面项和观点项查找的F1值有10%左右的提升.这说明本文提出的将词语片段中末端单词与其它单词分开标注的方式可有效提高模型对词语片段的查全率.
2.4.2 模型消融实验
为了评估WPRN中各组件的合理性, 设计模型消融实验进行验证, 结果如表5所示, 表中黑体数字表示最佳值.
| 表5 模型消融实验结果 Table 5 Results of model ablation experiment % |
由表5可知, 注意力层对方法性能提升有显著作用, 相比删除注意力层后, 完整的WPRN在14lap数据集上的F1值提高近6%, 且删除的注意力层在各数据集上的回归率都较低.而使用普通自注意力模块在各项指标上均不如使用混合式注意力的WPRN.实验结果表明, 虽然在模块缺失的情况下, 某项指标可能略高一些, 但完整的WPRN的各项指标均表现较优, 这表明注意力层增加模型的鲁棒性, 增加的混合式注意力是不可缺少的且有效的.
方面情感三元组抽取(ASTE)包括方面项提取任务、观点项提取任务及方面情感分类任务3个子任务, 大多数策略需要进行多步操作才能完成这项任务, 会导致错误传播、不易使用等问题.因此, 本文提出词对关系学习方法, 将ASTE任务转化为一个统一的端到端的词对关系学习任务.该方法的核心是使用词对关系标注方法将句子中的各词对关系, 包括方面情感三元组关系, 进行统一标注, 再使用特别为此构建的词对关系网络学习并预测各词对关系, 最后使用解码算法从词对关系标签中得到所有的方面-情感-观点三元组.词对关系网络首先使用BiGRU和混合注意力对句子进行编码表示, 再利用注意力图转换模块为句子编码转换为词对关系标签的概率.此外, 还将预训练的BERT应用于本文方法.实验表明, 本文方法在ASTE任务上取得较优性能.今后将考虑把外部语义知识, 如句法依存树的信息, 结合到模型中, 增强模型对句子语义信息的建模.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|