
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
面向三维目标的矢量型卷积网络
[邱起璐1  , 赵杰煜
, 赵杰煜1, 2 , 陈瑜1 ]
, 赵杰煜, 陈瑜]
|
|



作者简介:

邱起璐,硕士研究生,主要研究方向为三维卷积网络、模式识别.E⁃mail:jdqql@163.com.

陈 瑜,博士研究生,主要研究方向为图像处理、深度学习.E⁃mail:chenyu_cycy@126.com.
目前,三维目标识别方法大多基于卷积神经网络,在特征聚合过程中过多使用池化层,导致三维目标的空间信息丢失.针对上述问题,文中提出面向三维目标的矢量型卷积网络,用于完成三维目标的识别.首先,使用曲面多项式拟合网格目标的局部区域.然后,使用聚类算法得出曲面形状卷积核,通过卷积核和目标表面的相似度度量生成结构感知的特征向量,再利用多头自注意力机制模块实现局部区域到更大范围的特征聚集,得到部件层次特征向量.最后,使用三维矢量型网络实现目标分类.文中网络在SHREC10、SHREC11、SHREC15数据集上均取得较高的分类精度.此外,多分辨率目标对比实验和多采样点对比实验验证文中网络具有较强的泛化性和鲁棒性.
About Author:
QIU Qilu, master student. His research interests include three-dimensional convolutio-nal networks and pattern recognition.
CHEN Yu, Ph.D. candidate. Her research interests include image processing and deep learning.
The 3D object recognition is usually based on convolutional neural networks. The spatial information of 3D objects is lost due to too many pooling layers used in the process of feature aggregation. To solve the above problem, a convolutional vector network for 3D mesh object recognition is proposed in this paper. Firstly, the surface polynomials are introduced to fit the local mesh of the object, and then the surface shape convolution kernels are clustered. The feature vector of structure-aware is generated by self-measuring the similarity between the local mesh in the object and convolution kernels. The multi-headed attention mechanism module is then employed to achieve feature aggregation from local regions to a larger scale to obtain component-level feature vectors. Finally, the 3D objects are classified through the 3D vector network. The proposed network achieves a high classification accuracy on SHREC10, SHREC11 and SHREC15 datasets. In addition, generalization and robustness of the proposed network are demonstrated through the multi-resolution object comparison experiment and the multi-sampling point comparison experiment.
本文责任编委 张军平
Recommended by Associate Editor ZHANG Junping
随着自动驾驶、无人超市等与计算机视觉应用相关的新技术的迅速发展, 二维数据已无法契合三维应用, 将计算机视觉主要的处理数据从二维转变到三维势在必行.如何结合在图像处理领域性能较优的深度学习方法, 识别比二维数据更庞大、复杂、多变的三维目标, 受到学者的广泛关注.
目前对三维目标的研究大多利用卷积神经网络(Convolutional Neural Network, CNN)高效的特征提取能力, 完成分类分割或其它任务[1].早期的三维目标识别研究主要通过特征描述符提取低层特征, 再通过简单机器学习方法进行分类.Saupe等[2]先将数据离散化, 再用主成分分析对目标降维, 用欧氏距离求出几何距离, 以此作为目标特征.Paquet等[3]在数据离散化和数据降维后, 以目标表面面片的质心作为几何矩, 在特定条件下获取的表征更有效.
为了解决手工提取特征方法计算量较大、局限特定目标的问题, 学者们结合在二维图像处理领域突破性的深度学习方法, 提出基于视图的深度学习方法.Shi等[4]将三维目标转化成全景视图, 利用CNN提取高层特征, 该方法是最早通过视图方法处理三维数据的方法之一.Sinha等[5]将三维目标生成球面, 结合基于热核特征和主曲率特征的低层次特征提取方法, 获得特征图.
然而, 基于视图方法在转换过程中会丢失三维数据的整体结构信息和视图间的相关性, 这在一定程度上降低深度网络的鉴别能力[6], 因此, 学者们提出多种直接处理三维数据的深度神经网络.Wu等[7]提出针对三维数据体素目标的深度置信网络, 把深度学习方法扩展到三维领域.Brock等[8]基于体素, 结合变分自编码器和卷积神经网络, 提出基于变分自编码器的三维目标分类网络.Qi等[9]使用深度学习网络直接处理点云数据, 使用空间不变网络组件和最大池化, 解决点云数据的不规则特性问题.Lan等[10]强调局部区域点之间的几何结构, 将点和点之间向量拆分成三个基本方向的向量, 再通过对应的权值比重, 学习每个方向的特征.Hanocka等[1]将特征放在边上传递, 使用固定边的邻边读取顺序的方法设计卷积, 解决网格目标的不规则性问题, 再使用网格简化算法聚合特征, 实现直接针对网格目标数据的特征提取.Vakalopoulou等[11]提出形状生成框架, 主要思想是任何一块三维目标表面都可通过二维平面挤压、撕裂、折叠等操作得到, 提取代表这些操作的参数, 生成三维网格目标的转换表示.
上述方法均在三维目标上沿用二维图像处理方法, 在数据前向传播过程中, 内含的CNN通过最大池化或平均池化之类的操作获得图像变换的不变性、更紧凑的表征、更好的噪声和聚类的鲁棒性[12].然而, 因为池化过程只完成特征的聚集, 却丢失对应特征的来源, 从而丢弃高层特征其它参数信息和编码特征间的相对位置关系, 因此使用池化操作提取的特征不会随视角的变化而变化, 即存在位置不变性(Positional-Invariance).区分三维目标需要综合目标本身表征和目标内部结构的相对空间关系, 空间信息的缺失会对三维目标的识别提取造成重大影响[13].
为了解决CNN使用池化采样而丢失空间信息的问题, Hinton等[14]提出使用矢量型特征代替标量型特征, 并基于此实现胶囊网络.用动态路由引入位置等变性(Positional-Equivariance)[15]替代CNN中的位置不变性, 更好地保留空间信息.目前已有实验验证胶囊网络在二维图像分类上更具优势[16].在应用方面, Iesmantas等[17]将基于二进制分类的胶囊网络应用于乳腺癌的检测.Jaiswal等[18]设计基于胶囊的生成式对抗网络.Zhao等[19]将胶囊网络应用到文本领域.Nguyen等[20]将胶囊网络应用于数字媒体取证.这些研究验证胶囊网络在多个领域的有效性, 但目前大多数基于胶囊网络的矢量型研究仍局限于二维图像处理领域.这是因为三维模型数据的结构更复杂、无规则, 卷积操作难以通用, 这使提取数据特征更困难.
三维网格(Mesh)数据是三维目标中最复杂的数据, 但作为点、面、边的集合, 通过三角面片进行拓扑组合, 能准确表达点的邻域信息, 具有表达物体复杂表面的天然优势[21].不同于二维数据, 如何获取三维目标的矢量型特征, 并进一步设计能在三维领域使用的矢量型网络, 成为目前的研究热点.
此外, 虽然动态路由能较好地学习初级胶囊之间的全局关系, 却忽视局部特征和高于初级胶囊层次的信息的重要性, 因此, 需要设计一个改进的结构, 解决胶囊网络的局限性问题[22].
因此, 本文提出面向三维目标的矢量型卷积网络, 实现矢量型网络在三维网格数据上的应用.首先, 使用曲面多项式拟合网格目标的局部区域.然后, 使用聚类算法得出曲面形状卷积核, 通过卷积核和目标表面的相似度度量生成结构感知的特征向量, 局部区域的特征向量通过多头自注意力机制模块组成目标部件.最后, 使用三维矢量型网络实现目标分类.本文网络在SHREC10、SHREC11、SHREC15数据集上均取得较高的分类精度.此外, 多分辨率目标对比实验和多采样点数量对比实验表明本文网络具有较强的泛化性和鲁棒性.
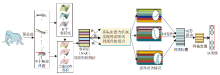
本文从学习局部特征到整体目标关系的角度出发, 提出面向三维目标的矢量型卷积网络, 具体网络框架如图1所示.网络可分成3部分:三维网格卷积特征提取模块、多头自注意力特征整合模块、矢量型分类网络.受到二维图像处理中卷积的启发, 三维网格卷积特征模块使用曲面多项式拟合网格目标的局部区域, 通过聚类生成曲面形状卷积核, 得到高层语义信息特征.多头自注意力特征整合模块学习局部区域特征到目标部件特征的组合关系, 实现从局部特征到高级特征的转化.矢量型分类网络根据动态路由特点保留相对空间信息, 学习部件特征和目标整体的构成关系, 最终获取目标的整体特征.
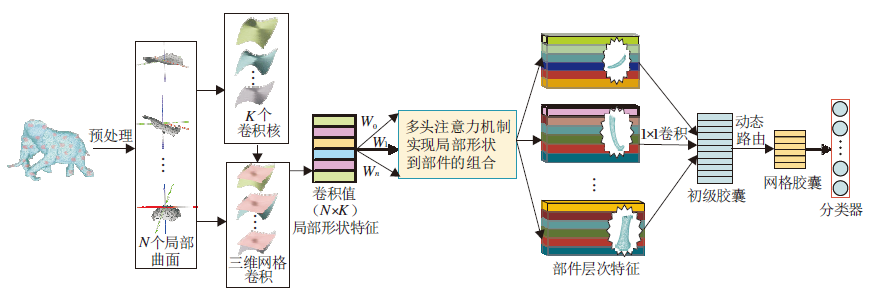 | 图1 三维目标的矢量型卷积网络框图Fig.1 Framework of 3D object vector convolutional network |
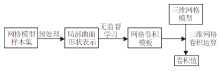
相比点云目标和体素目标, 三维网格(Mesh)目标表现形式更复杂, 除了简单的三维坐标信息以外, 增加顶点间的关联信息.常规的三维卷积特征提取方法无法直接用于不规则的网格目标, 因此本文提出新的特征提取方法, 参照二维数据构造卷积模板, 进行特征提取.具体做法如下:先使用曲面多项式拟合网格目标的局部区域, 在多项式整合后使用谱聚类生成K种曲面形状卷积核(卷积模板); 再使用原始目标的局部区域和卷积核进行相似度度量, 每个目标点都会得到K维的高层特征.三维网格卷积特征提取过程如图2所示.
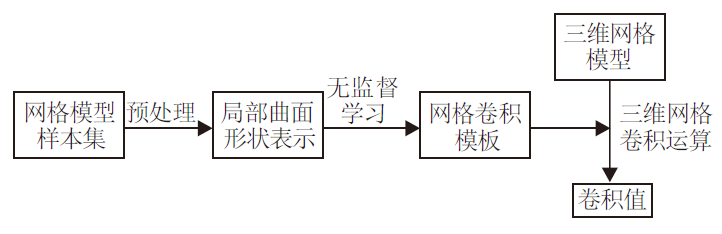 | 图2 三维网格卷积特征提取过程Fig.2 Feature extraction process of 3D mesh convolution |
1.1.1 网格目标局部区域表示
给定一个网格目标Mesh, 可看成点集 V和边集E的集合.局部区域定义为:从点集V中的任一点出发, 进行广度优先搜索, 获取M-1个邻域点后, 该M个点组成的点集Vl加上边两端顶点都在Vl内的边组成的边集El, 即为局部区域S.
为了防止目标旋转和绝对坐标对局部区域造成影响, 需建立相对坐标系, 将局部区域归一化.以出发点Vi为坐标轴原点, 以局部区域所有顶点平均法向量的方向为z轴, 将所有顶点投射到XOY平面上, 选取距离原点最远的点Vt并连接原点, 以Vi至Vt方向为x轴, 根据现有坐标增加y轴, 相对坐标系建立完成.归一化后采用高阶多项式
F(vc, θ )=0
描述局部区域, 其中, vc为局部区域内顶点信息, θ 为高阶多项式参数.单纯使用顶点坐标信息(X, Y, Z)无法充分利用网格目标的信息, 在实验中发现增加顶点到局部坐标系原点的最短距离属性D可有效携带网格目标的语义信息, 使形状相似的局部区域之间的区分度更高.因此, 定义vc=(X, Y, Z, D), 最终得到的高阶多项式:
F(vc, θ )=θ 0+θ 1X+θ 2Y+θ 3D+θ 4X2+θ 5Y2+ θ 6D2+θ 7XY+θ 8XD+θ 9YD-Z, (1)
采用最小二乘法求解多项式参数
θ =(θ 0, θ 1, …, θ 9).
1.1.2 局部区域相似度度量
两个局部区域的相似性很难使用高阶多项式衡量, 每个高阶多项式系数对局部区域整体构造的影响程度不同.最直观的相似度度量是直接计算两个曲面的平均距离, 本文结合式(1), 给出起始局部区域Sf到目标局部区域St的度量公式:
Dist(Sf, St)=
其中, θ t为目标局部区域St对应的多项式参数, vc为起始局部区域Sf中的顶点属性.因每个局部区域顶点数相同, 所以略去平均过程.单向度量公式只能衡量单向误差, 进一步给出2个局部区域之间的度量公式:
Diff(f, t)=
1.1.3 三维网格卷积
在二维图像处理领域, 卷积核(卷积模板)被定义为小尺度二维图像, 在原图像上规律滑动, 得到高维特征图.本文参照这一过程, 以典型的局部区域形状为卷积核, 与目标内每个顶点为中心的局部区域进行对比, 计算每个局部区域卷积核的相似度差异大小, 即局部区域属于该卷积核的概率, 并将其对应二维图像中的卷积操作.
假设在当前三维目标数据集上存在K类曲面形状卷积核, 对应K个典型局部区域形状.本文采用谱聚类算法对数据样本进行无监督学习, 获得K类曲面形状卷积核的多项式表达.
给定一类曲面形状集合, 可用高阶多项式Fk(vc, θ k), k∈ {1, 2, …, K}表示, 假设该类曲面形状在网格数据目标数据集服从高斯分布, 分布方差为σ k, 那么当前的局部区域SX属于该类曲面形状集合的概率为:
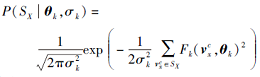
化简为
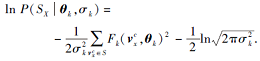
可以看出, 这里的表现形式和二维图像中的卷积操作
H* =WH+b
相似, 将其一一对应, 可转化为
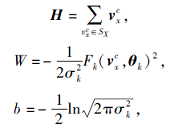
其中, H对应局部区域内所有顶点的属性, W对应曲面形状卷积核的高阶多项式和其分布方差的组合, b对应曲面形状卷积核分布方差和常数的组合, θ k、σ k为曲面形状卷积核的相关参数, 在选取曲面形状卷积核时得到.
1.1.4 卷积模板选取
根据1.1.3节定义的网格卷积, 介绍卷积模板的选取.与二维图像处理领域的卷积模板不同, 为了保证所有的卷积模板都是高效的, 本文的卷积模板是由现有目标中提取的局部区域聚类得到.
为了保证局部区域的多样性, 本文从每种类别的目标中选取一个点, 再从每个目标中选取5%的点, 搜索该点旁的M个邻域点, 生成局部区域.将得到的所有局部区域作为模板库, 使用式(2)计算局部区域之间的相似度, 构建相似矩阵, 进行谱聚类, 得到聚类结果.聚类结果是抽象的曲面形状, 无法用之前对局部区域中的点集和边集表示, 因此采用高阶多项式描述.对每类局部区域集合Sk, 聚类后都有类中心为
其中nk 为局部区域集合Sk中局部区域的数量.
在1.1节得到目标上每点的K维特征, 直观上可看成是以当前点为中心生成的局部区域分别与K种曲面形状卷积核的拟合情况, 即使用K种已有的曲面形状卷积核, 通过对应的权值组合, 得到当前点生成的局部区域.
但是, 仅依靠局部区域很难高效区分目标, 现实世界区分物体更倾向于部件而不是纹理和细节.直接依据局部区域或直接聚集所有局部区域细节都无法提取高区分度的部位特征(如人手、鱼尾等), 需要引入新的结构, 实现局部区域到更大范围的特征聚集, 得到部件层次特征.
针对此问题, 本文提出基于多头自注意力机制的转化组件, 实现局部区域到目标部件的特征整合.
1.2.1 网络性能影响因素
直接使用局部区域层次特征为分类依据会存在如下问题.
1)冗余曲面形状卷积核信息干扰.每个局部区域包含若干个曲面形状卷积核信息, 但在网络使用当前局部区域信息时, 不是所有的曲面形状卷积核信息都有正作用, 冗余的信息会导致网络性能下降.
2)局部区域语义信息不足.虽然局部区域可有效描述网格目标的构成比例, 但在目标整体构成相似的情况下, 会忽略明显不同的特征.然而, 这两种目标的局部区域组成相似度非常高, 只要局部区域有差异, 就会产生将两种目标数据归为一类的情况.
1.2.2 多头自注意力模块结构
想要实现局部区域到目标部件的特征整合, 显然不能完全依赖目标部件中局部区域简单的权值计算, 应当给予关键局部区域更多的关注.此外, 复杂的几何轮廓需要长距离依赖(Long-Range Depen-dencies), 而卷积的特点就是局部性, 受到感受野大小的限制很难提取目标中这些长距离依赖.虽然可通过加深网络或扩大卷积核的尺寸在一定程度上解决该问题, 但这会使卷积网络丧失其参数和计算的效率优势.本文使用自注意力机制[23]实现局部区域重要程度的自适应调整, 并进一步得到距离更远的特征, 解决冗余曲面形状卷积核信息干扰和局部区域语义信息不足的问题.
多头自注意力模块结构如图3所示.
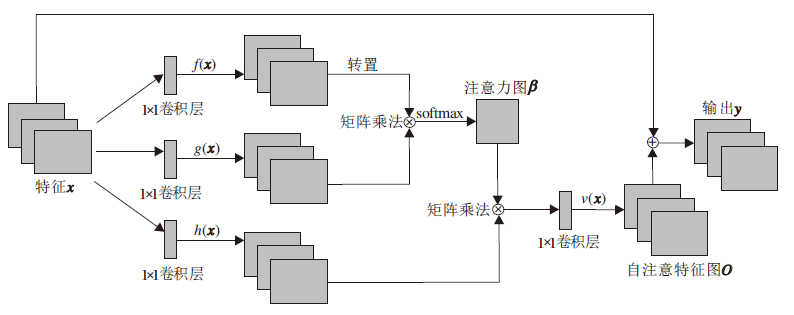 | 图3 多头自注意力模块结构图Fig.3 Structure of multi-headed self-attention module |
特征图为局部区域层次提取的特征, f(x)=Wf · x和g(x)=Wgx用于计算对应局部区域特征的注意力, 其中Wf和Wg为学习的权重矩阵.自注意力矩阵经过f(x)和g(x)进行矩阵乘法之后, 再通过Sigmoid函数, 得
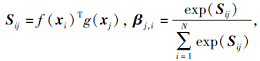
其中, i=1, 2, …, d, j=1, 2, …, d, d为特征维度.自注意力特征图如下所示:
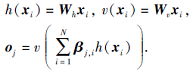
输出的自注意力特征图O=(o1, o2, …, od)为自注意力层的输出.
最终该模块输出如下:
yi=γ oi+xi.
本文遵循自注意力机制的相关工作, 将其中的γ 初始化为0[24].这样做模块一开始可充分利用当前局部区域信息, 并且通过对参数γ 的学习, 逐渐将权重分给关键局部区域特征.
通过自注意力模块, 能避免冗余的曲面形状卷积核信息干扰, 实现比局部区域更远范围的特征聚集, 让网络自适应学习, 构建由局部区域特征组合而成的部件层次特征, 达到更好的分类效果.此外, 现在的自注意力机制多是直接作用于输入, 输入层的冗余和干扰较多、规模较大导致效率较低, 也使在网络训练时需要更多的数据量和更久的时间.本文将自注意力机制运用于特征层, 规模较小但效率较高.
部件层次特征加上后续矢量型分类网络保证的相对空间位置关系已可精确表达三维模型, 能否选取合适的部件层次特征成为影响模型精度的关键因素.多头结构在自然语言处理和计算机视觉中均表现优异[25], 仅靠单一部件生成方式不能较好地体现多种目标相互间的相似度与差别大小.本文引入多头机制, 对局部区域到目标部件的特征整合进行扩展, 同时生成目标的多个不同部件, 增加特征广度, 进一步增加网络的稳定性.
基于胶囊网络, 本文构建矢量型分类网络, 以生成的部件作为初始胶囊的构成部分.为了使网络多元化, 基于原始胶囊网络的建议[15]构造多个网络分支, 形成多个部件, 不同部件集合不同局部区域的组合方式, 提高分类网络的泛化能力.
不同于CNN, 胶囊网络的输入输出都是向量, 中间的权值不是简单的标量权重, 而是矩阵形式, 可看作是空间中位置关系的变化系数, 可学习部件到整体目标之间的空间位置信息, 契合本文提取的高层特征.
1.3.1 胶囊网络流程
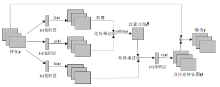
胶囊网络的流程如图4所示, 可概括为如下步骤.
 | 图4 胶囊网络流程图Fig.4 Flow chart of capsule network |
1)将初始向量ui和矩阵Wij相乘, 得到新输出向量
2)将输入向量
3)对所有的cij
4)使用压缩激活函数Squash, 将sj转化为vj.
1.3.2 压缩激活函数
胶囊网络采用压缩激活函数Squash, 即
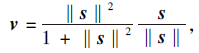
其中v、s为压缩激活函数前后的特征向量.该函数的作用是在保持向量方向不变的情况下, 将输出向量的模长压缩到0~1之间.前半部分得到0~1之间的常数, 输入向量s的模长越大, 值越接近1, 否则接近0.后半部分得到单位长度的方向向量.
1.3.3 动态路由算法
动态路由算法的核心思想是增加与输出向量相似度较高的输入向量的权值, 也可看作聚类过程, 相似特征越多, 该类特征就越强, 以此进行特征选择.具体算法步骤如下.
算法 1 动态路由算法
输入 输入向量
输出 输出向量vj
INITIALIZE bij← 0
FOR r iterations DO
FOR all capsule i: ci← softmax(bi)
FOR all capsule j: sj←
FOR all capsule j: vj← squash(sj)
FOR all capsule: bij← (bij+
RETURN vj
在算法1中, i表示输入层, j表示输出层.
1.3.4 胶囊网络损失
胶囊网络会输出目标类别数个胶囊作为最终结果, 每个胶囊里的向量范数表示目标属于对应类别的可能性, 范数越大, 可能性越大, 每个目标对应的输出长度为目标总类别数的向量.损失通过2个向量反传:1)目标所属类别的one-hot编码; 2)长度相同的网络输出结果, 每维对应目标属于该类别概率.胶囊网络使用分离边界损失函数:
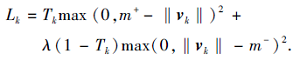
其中:‖ vk‖ 为输出结果第k维对应数值; Tk当且仅当one-hot编码1所在维度为k时为1, 其余情况等于0; λ 为权值参数; m+、m-为损失给定的上下界.
为了有效评判本文网络的泛化能力和鲁棒性, 采用三维非刚性数据集SHREC10、SHREC11、SHREC15作为对比数据集.SHEREC10数据集包含10类, 每类20个, 共200个三维目标数据, 每个目标平均含顶点数约为1 000个.SHEREC11数据集包含30类, 每类20个, 共600个三维目标数据.SHREC15数据集包含50类, 每类24个, 共1 200个三维目标数据, 每个目标平均包含顶点数约为10 000个.三维非刚性目标的特点是复杂的形变, 因此处理难度高于普通三维目标.
实验中如无特别指出, 默认以数据集上80%的数据作为训练集, 其余20%的数据作为测试集.SHREC15数据集的局部区域类别数为45, 每个局部区域含有的顶点数为128, 对每个目标数据随机采取10组进行数据扩充, 每组700个点, 得到低级特征作为后续网络的输入.经过多头自注意力特征整合模块后为16× 700× 1 024, 通过1× 1卷积后为16× 1 024, 以此作为初级胶囊, 其中, 1 024为胶囊数量, 16为胶囊维度.经过3次动态路由算法, 得到50× 32的最终胶囊.故最终得到50维的分类结果.
为了验证本文网络的高效性, 选择如下基于深度学习的方法.1)手工提取的低层特征参与的方法:GA-BoF(Geodesics-Aware Bag-of-Features)[26]、SA-BoF(Shape-Aware Bag-of-Features)[27]、SGWC(Spectral Graph Wavelet Codes)-BoF(Bag-of-Fea-tures)[28]、DeepShape(Deep Learned Shape Descriptor for 3D Shape Matching and Retrieval)[29]、DeepGM(Deep Geodesic Moment)[30]、结构感知深度学习的三维形状分类方法(简记为文献[31]方法)[31].2)基于多视图的深度学习方法:MVCNN(Multi-view CNN)[32].3)原始数据为点云的深度学习方法:PointNet++[33]、SpiderCNN[34].4)直接对网格数据进行处理的深度学习方法:FeaStNet[35]、PFCNN(CNN on 3D Surfaces Using Parallel Frames)[36].
实验中使用AP(Average Precision)和mAP(mean AP)作为评价指标.
各方法的分类性能如表1所示.由表可知, GA-BoF基于热核提取局部的底层特征, 再通过测地线核函数提取目标整体特征, 将所得结果输入深度信念网络.SA-BoF、SGWC-BoF采用谱图小波作为底层特征.SA-BoF使用自编码器.SGWC-BoF使用多类支持向量机.DeepShape以热核特征描述符提取特征, 采用多对一编码的神经网络作为分类网络.实验结果都表明手动提取底层特征结合深度学习方法在三维目标特征提取与分析上的有效性, 但导致它们效果低于其它方法的主要原因是后接的深度学习网络较老旧.DeepGM将基于测地线距离的底层特征放入自编码器分类.虽然网络结构不是最新, 但由于深度网络对几何特征更敏感, 因此分类效果略优于上述方法.
| 表1 各方法在3个数据集上的分类性能对比 Table 1 Classification performance comparison of different methods on 3 datasets % |
MVCNN是经典的多视图方法, 投影多角度的三维目标样本, 再以图像形式并行输入CNN, 得益于投影对目标的全覆盖和CNN对图像的高性能处理, 效果优于早期的基于低层次特征的深度学习方法, 但由于转换过程中不同视图只能获取当前视图特征, 对目标整体和不同视图间的相互联系把握不足, 性能仍有提升空间.文献[31]方法结合低层次特征提取和多视图, 先提取多尺度热核特征, 再提取多视图的空间特征, 结合后对三维目标进行分类.对比两种方法的分类性能可看出, 低层次特征对于三维目标分类具有额外的指导作用.
PointNet++和SpiderCNN是针对点云数据的深度学习方法, 两种方法根据点云数据特点构建深度学习网络, 在刚性数据集上表现较优, 但在非刚性数据集上, 效果略差于MVCNN.主要原因是点云数据无法完全表达非刚性目标之间的相似性, 仅靠数据的空间位置和网络参数无法完成差异度较小的非刚性目标分类.
FeaStNet和PFCNN都是直接针对网格数据的深度学习方法.FeaStNet在局部区域使用动态图卷积算子提取特征, PFCNN使用平行标架场(Parallel Frames)构造局部的平直联络(Locally Flat Con-nection)和欧氏平移结构.网格数据携带信息丰富, 端到端的网络结构不会有信息丢失, 因此能在三维数据目标上表现较优.然而, 本文网络依然优于FeaStNet和PFCNN, 说明本文网络在非刚性数据集上的性能远高于对比方法.
为了验证本文网络为多部分相互协作, 在识别目标局部特征和内部相对空间关系上起到良好作用, 而不是单独部分功能过于强大, 本节给出详细的消融实验.
2.3.1 特征提取有效性
为了说明本文提取的低层特征给予后续网络指导作用, 而不是网络本身的性能强大, 采用3种不同的输入进行验证:1)坐标点信息.直接针对对应目标数据采样相同点数, 每点的携带信息即为顶点对应三维坐标信息.2)多项式参数, 即在采样点生成的局部区域函数化后, 对应函数的多项式参数.3)相似度.采样点生成的局部区域和曲面形状卷积核之间的相似度, 即本文提出的三维网格聚集特征提取的结果.
不同输入数据的分类准确率对比如表2所示.由表可看出, 以多项式参数为输入的网络结果优于以坐标点信息为输入的结果.这是因为多项式参数输入实质上是一小块局部区域的提取特征, 而坐标点信息只考虑当前节点坐标点信息, 未完全考虑局部关系, 实际上可看作点云网络.点云网络性能可随着非刚性目标的点云密度逐渐增强, 因为密集的点云也可捕获非刚性变化.例如, SHREC15数据集就可捕获一部分, 但SHREC10数据集因为平均顶点数只有1 000左右, 效果很差.而本文采用的相似度输入提取的特征效果优于利用多项式参数的效果.
| 表2 不同输入数据的分类准确率对比 Table 2 Classification accuracy comparison of different input data % |
2.3.2 特征整合模块的必要性
为了验证本文的多头自注意力特征整合模块学到局部区域和目标部件关系的有效性, 对两种数据集进行有/无多头自注意力特征整合部分的对比实验, 分类准确率如表3所示, 表中的不存在对应直接以输入数据构建初级胶囊的网络结构.
| 表3 多头自注意力特征整合模块的有效性对比 Table 3 Effectiveness comparison of multi-headed self-attention feature integration module % |
由表3可看出, 多头自注意力特征整合模块在整个网络结构中起到至关重要的作用, 该部分缺失会直接导致网络无法起到识别作用.因为SHREC15数据集的数据比SHREC10数据集更复杂, 需要学习的局部区域到目标部件关系的参数也更多, 起到的作用也更大.因此缺失多头自注意力特征整合部分对SHREC15数据集的影响大于SHREC10数据集.
2.3.3 分类网络优越性
为了说明本文网络是特征提取部分和分类网络的互补组合, 而不是完全依赖表征提取的高效性, 本文在使用同样输入特征的情况下, 采用不同网络对数据集进行分类, 分类准确率如表4所示.由表可看出, 当本文网络提取的特征用于其它分类网络时, 能提升识别精度, 但幅度有限, 相比本文的分类网络, 表现并不突出, 在PointNet++上的结果甚至低于对应论文的结果.其原因在于原文献中该网络输入不是基础的三维坐标信息, 而是先用测地距离提取的高阶特征, 再使用传统特征提取方式进一步得到富含目标内部结构信息的特征.可看出特征提取部分虽然能有效聚集局部区域特征, 但优势并不明显.结合2.3.1节可证实, 本文网络是特征提取部分和分类网络两部分相互作用的结果, 这也表明从区域到部件再到整体的算法思路切实可行.
| 表4 相同输入特征在不同网络中的效果对比 Table 4 Result comparison of same features in different networks % |
2.3.4 顶点携带信息的优异性
为了说明顶点到局部坐标原点的最短距离D能有效携带语义信息, 本文对多种包含信息不同的输入数据进行对比, 分类准确率如表5所示.
| 表5 包含不同信息输入数据的对比结果 Table 5 Result comparison of input data with different Information % |
由表5可看出, 单纯使用相对三维空间坐标和顶点到局部坐标原点的最短距离D时分类效果不佳, 主要原因是对形变目标进行分析时, 相对三维空间坐标虽然可作为主要分类凭据, 但当形变明显时, 类测地距离可使同类目标联系紧密.例如, 对于一个握紧的手和一个分开的手, 可通过相对空间坐标划分手掌和手指的部分, 手掌和手指的局部数据点都是相对固定的.然而, 手掌到手指的相对距离发生改变, 这会对识别结果造成影响.本文引入类测地距离, 抓住手指沿皮肤到手掌的距离不变性, 拉近两种目标联系, 优化识别结果.
为了测试本文网络对目标的泛化性和通用性, 下面在不同训练集样本比例和不同分辨率数据下进行详细的对比实验.
2.4.1 不同训练集样本比例
通用性算法应当具有较强的泛化能力, 是否能在训练数据足够少的情况下, 目标识别仍具有高精度是重要的泛化性评价标准.本文针对SHREC10、SHREC15数据集, 调整训练集大小, 进行对比实验, 分类准确率如表6所示.由表可看出, 本文网络具有极强的泛化能力.在SHREC15数据集上只需使用20%的训练数据, 就可达到98.42%的分类准确率.在SHREC10数据集上只需使用40%的训练数据就能达到正常训练的分类准确率.随着训练数据的减少, SHREC10数据集受到的影响大于SHREC15数据集, 并不是因为网络在SHREC10数据集上需要更多的参数, 而是因为SHREC10数据集数据量太少, 40%的数据量只有80个目标, 很难使网络拟合.
| 表6 训练集占比不同时本文网络的分类准确率对比 Table 6 Comparison of classification accuracy of the proposed network with different percentages of training set % |
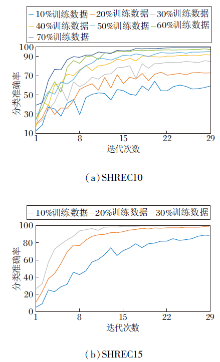
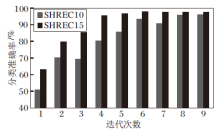
训练集占比不同时, 本文网络的分类准确率随迭代次数的变化情况如图5所示.(a)为本文网络在SHREC10数据集上的拟合情况, 当选取70%的训练数据时, 在15次迭代后网络就基本稳定, 而选取10%的训练数据时, 在28次迭代后网络还未完全稳定.(b)为本文网络在SHREC15数据集上的拟合情况, 当选取30%的训练数据时, 曲线走向已趋近正常训练, 故无需给出更高比例测试集占比训练结果.在同等训练集比例的情况下, SHREC15数据集上的网络稳定速度要明显快于SHREC10数据集上.这是因为数据集本身限制网络性能, 在更大型的数据集上, 使用同等比例的数据集进行训练, 效果应更优.
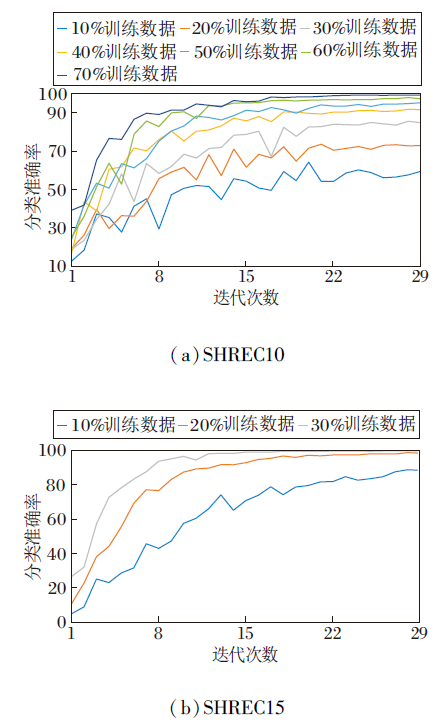 | 图5 本文网络在2个数据集上的拟合情况Fig.5 Convergence trend of the proposed network on 2 datasets |
2.4.2 不同尺度数据
为了验证本文网络在不同分辨率数据集上的通用性, 使用QEM(Quadric Error Metrics)三维网络简化算法对SHREC15数据集进行简化, 将原本平均目标含顶点数约10 000个的数据集简化到多个分辨率, 再使用本文网络对其进行分类, 参考参数如表7所示.
| 表7 SHREC15数据集的参考参数 Table 7 Recommended parameters of SHREC15 dataset |
对于多分辨率的数据, 无论数据集平均目标含顶点数多少, 本文网络都能达到99.9%的分类正确率, 充分说明本文网络的通用性和泛化性.值得注意的是, 随着数据集分辨率变动, 对应的局部区域采样范围和曲面形状卷积核数量都应适当改变.然而这种改变并不意味需要长时间的调参, 只要局部区域采样范围控制合理即可.以人体目标为例, 局部采样范围为手指、手掌, 乃至手臂都是可以的, 但不能太大采样到半个身体或太小采样到一小块皮肤.
2.4.3 迁移学习
考虑到泛化性能较强的网络大多能基于网络进行迁移学习, 遵循基于网络的深度迁移学习的相关标准[37], 保持特征提取部分的网络结构和参数不变, 探究本文网络在SHREC15、SHREC10数据集之间的迁移能力, 结果如图6所示.图中, SHREC10表示基于SHREC15数据集进行训练得到的网络迁移到SHREC10数据集上得到的测试效果, SHREC15则恰好相反.
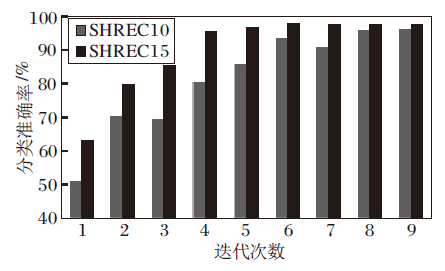 | 图6 本文网络的迁移学习性能Fig.6 Transfer learning performance of the proposed network |
由图6可看出, 预训练的网络在跨域训练时, 一开始就获得更高的正确率且收敛速度更快, 表示预先训练得到的特征提取器在不同数据集上同样发挥效果.但在训练曲线稳定后发现最终效果不如重新开始训练的结果, 这是因为不同数据集之间的基础特征提取侧重点不同, 在网络提取部分参数不变的情况下, 分类网络缺失该数据集的特殊特征, 导致网络性能下降.
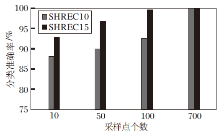
除了泛化性能以外, 鲁棒性是决定一种算法是否具有实用价值的重要评判标准.在实际应用场景中, 精度可达到数据集标准, 但目标完整度取决于采样环境和采样设备, 相对来说更难保证.一种算法能否识别低完整度目标是算法的重要评判标准.本文在SHREC10、SHREC15数据集上以减少输入数据采样点的方式模拟识别低完整度目标, 实际运用到的目标数据点数为采样点数乘以局部区域含顶点数, 结果如图7所示.
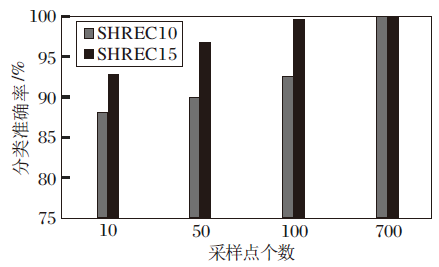 | 图7 不同采样点个数下的鲁棒性实验结果Fig.7 Results of robustness experiments with different numbers of sampling points |
SHREC10数据集上的局部区域含顶点数为32个, SHREC15数据集上的局部区域含顶点数为128个.当SHREC10数据集上的分类采样点个数为10个时, 最多利用目标中320个顶点, 就可达到88.1%的分类准确率.而且本文实验是随机采样, 若采样点距离过近, 实际利用顶点数会远低于该数值.SHREC15数据集上分类采样点数为10个时, 最多利用目标中1 280个顶点, 只占目标总顶点数的1/9, 就可达到92.9%的分类准确率.SHREC10数据集在同等采样点数的情况下分类准确率差于SHREC15数据集的原因是, SHREC10数据集上局部区域较相似且局部区域形状平缓, 在少量采样点的情况下, 区分度更小.上述实验表明, 本文网络对不同比例的采样点输入均有良好的分类性能和较强的鲁棒性.
本文提出三维目标的矢量型卷积网络, 基于构成目标的局部区域形状不同, 聚类曲面形状卷积核, 构建局部区域模板, 通过和目标表面局部区域相似度度量, 获取低层次目标特征.使用基于多头自注意力机制的转化组件, 实现局部区域到目标部件的特征整合.再借鉴胶囊网络构建矢量型卷积网络, 学习部件之间的相对空间位置和组合关系, 完成对三维网格数据集的分类.本文网络结合基于低层特征提取方法和基于深度网络方法的优点, 为三维目标识别提供新思路.实验表明, 本文网络在SHREC10、SHREC11、SHREC15数据集上表现较优, 并且具有良好的泛化性和鲁棒性.本文网络可有效识别三维网格目标, 但由于三维目标的结构和表征更复杂, 识别新的数据集需要重新进行特征提取, 才能达到最佳效果.因此, 今后将针对提取更普适的特征设计有效的目标函数, 优化网络结构, 最终实现泛化性能更强的三维目标识别网络.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|