{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
融合信任隐性影响和信任度的推荐模型
[张槟淇1  , 任丽芳
, 任丽芳2 , 王文剑1, 3 ]
, 任丽芳, 王文剑]
|
|



作者简介:

张槟淇,硕士研究生,主要研究方向为推荐算法.E-mail:843545395@qq.com.

任丽芳,博士,讲师,主要研究方向为服务计算、推荐算法.E-mail:renlf@sxufe.edu.cn.
现有一些方法通过结合传统推荐技术和社交信息,缓解推荐系统中的冷启动问题,但由于可用的社交信息较少,效果不佳.因此,文中提出融合信任隐性影响和信任度的推荐模型,在引入社交信息中信任关系的前提下,不仅考虑用户在信任关系中的显式行为数据,还考虑信任关系的隐性影响(如被信任用户的潜在特征向量),用于获取冷启动用户的偏好特征,有效缓解在社交信息较少时不能准确地为冷启动用户进行推荐这一问题.此外,文中提出综合信任度的度量,体现目标用户与信任用户之间不同的社交影响,发挥信任用户的积极影响,提升推荐系统的性能.在3个常用数据集上的实验表明,文中方法推荐精度较高.
About Author:
ZHANG Binqi, master student. Her research interests include recommendation algorithms.
REN Lifang, Ph.D., lecturer. Her research interests include service calculation and recommendation algorithms.
Some methods alleviate the cold start problem in recommender systems by combining traditional recommendation techniques and social information. However, the effect is poor due to the less available social information. Therefore, a recommendation model combining implicit influence of trust and trust degree(RIITD) is proposed in this paper. On the premise of introducing the trust relationship in social information, both the explicit behavior data of the user in the trust relationship and the implicit influence of trust relationship, such as the potential feature vector of trusted users, are taken into account to obtain the preference characteristics of cold start users. Consequently, the problem of inaccurate recommen-dation for the cold start users caused by less social information is alleviated. Moreover, the compre-hensive trust degree is introduced to reflect the different social influences between the target user and the trusted users, make the trusted users play a positive impact and improve the performance of the recommender system. Experiments on 3 commonly used datasets show that the proposed method can achieve high accuracy.
本文责任编委 林鸿飞
Recommended by Associate Editor LIN Hongfei
冷启动问题一直是困扰推荐系统的主要问题之一, 随着微博、Facebook、维基等社交平台的出现, 学者们提出很多利用用户之间社交信息的方法, 缓解这一问题.这些方法是基于有社交连接的用户更趋向于有相似的行为偏好, 同时行为偏好相似的用户更容易建立连接这一理论, 因此可通过信任用户的行为特征预测目标用户的偏好特征, 缓解冷启动问题.信任用户是指与目标用户存在某种社交关系, 如朋友关系、师生关系、亲人关系的其它用户, 但由于冷启动用户拥有的社交信息可能也是稀疏的, 仅考虑社交信息的显式数据可能并不能为所有的冷启动用户提供准确的推荐, 因此需要考虑社交信息(信任关系)的隐性影响.
自推荐系统成为一个独立的研究领域之后, 学者们提出许多推荐系统, 一般可分为基于协同过滤(Collaborative Filtering, CF)[1, 2]的推荐系统、基于内容的推荐系统和混合的推荐系统.
基于CF的推荐系统大体可分为基于邻域的方法[3]和基于模型的方法[4].基于邻域的方法使用用户对已有项的评分, 直接预测该用户对新项的评分, 意在找出项与项之间的联系(基于项的CF), 或用户与用户之间的联系(基于用户的CF).基于模型的方法使用一些机器学习算法训练物品和用户向量, 再建立模型预测用户对于物品的评分.Koren[5]提出SVD++(Singular Value Decomposition++), 对评分矩阵进行矩阵分解, 并考虑评分矩阵的隐性影响与显性影响, 预测用户对项目的评分.但是, 这些方法都面临冷启动问题(新项目或新用户)和数据稀疏问题.
基于内容的推荐系统[6]源于信息检索和信息过滤的研究, 存在如下限制:1)内容分析有限, 很难应用于具有自动特征提取固有问题的领域; 2)过度专业化, 向用户推荐的项目局限于与该用户已评级项目相似的项目; 3)存在新用户问题, 为了了解用户的偏好, 用户必须对足够数量的项目评级.
混合的推荐系统[7]使用加权等方式融合两种或两种以上的推荐方法, 以此缓解各种方法的缺点, 但需要大量的工作才能找到正确的混合方式.
现阶段社交网络已成为人们生活不可或缺的一部分, 用户之间的信任度影响也更突出.如何将信任度融合到推荐系统中, 实现更精准的个性化推荐成为现在研究的热点问题.
一些研究结果表明, 将用户之间的信任关系融入推荐系统可提高推荐性能, 减轻数据稀疏和冷启动问题[8].由于社会信任关系会提供除项目评级之外的另一种用户偏好, 研究者开始广泛研究信任感知的推荐系统[9].Ma等[10]提出SoRec(Social Re-commendation Using Probabilistic Matrix Factoriza-tion), 考虑社会关系的约束, 共享一个由评分和信任矩阵分解而成的通用用户特征矩阵.之后, Ma等[11]提出RSTE(Recommendation with Social Trust Ensemble), 线性组合基本矩阵分解模型和基于信任的邻域模型.Ma等[12]进一步提出, 活跃用户特定于用户的向量应接近其可信邻居的平均值, 并将其改成正则化形式, 形成新的矩阵分解模型SR(Reco-mmender Systems with Social Regularization).Jamali等[13]在SR的基础上, 构建SocialMF(Matrix Factori-zation Based Model for Recommendation in Social Rating Networks), 将信任用户特征向量加权平均表示目标用户的特征向量.Yang等[14]提出TrustMF(Social Collaborative Filtering by Trust), 从信任者和被信任者的角度考虑用户, 结合信任者模型和被信任者模型, 即信任该用户的用户和被该用户信任的用户都将影响用户对未知项目的评分.Tang等[15]提出LOCABAL(Exploiting Local and Global Social Context for Recommendation), 将全局信任和局部信任视为上下文信息, 通过单独的算法计算全局信任.
上述方法表明, 社交信息对于改进传统的推荐算法是有效的.但是, 在现实世界中, 并非所有的推荐系统中都存在显式社交关系.Ma[16]明确显式社交和隐式社交的定义, 同时给出对于两种社交信息的有效性验证.Yao等[17]考虑推荐模型中信任者和被信任者之间的显式交互和隐式交互.Guo等[18]提出TrustSVD, 在SVD++的基础上引入隐式社交信息, 不仅考虑用户的显式评分数据与社交关系, 也考虑用户的隐式行为数据及社交关系.Xiong等[19]提出SoInp(Information Propagation-Based Social Reco-mmendation Method), 从信息传播的角度对隐式用户影响进行建模, 并在矩阵分解框架中加入隐式用户影响和显式信任信息.Ahmadian等[20]提出SoRIR(Social Recommender Based on Reliable Implicit Relationships), 基于Dempster-Shafer理论计算用户之间隐式关系, 还引入一种度量, 评估预测的可靠性, 并使用邻域改进机制重新计算不可靠的预测.Liu等[21]提出DGE(Dynamic Graph-Based Embedding Model), 将时间语义效应、社会关系和用户行为顺序模式整合到网络嵌入过程中, 实现实时社交推荐.
所有这些工作表明, 通过信任正则化的矩阵分解模型性能优于没有信任的矩阵因式分解模型, 即信任有助于提高预测准确性.其中通过隐式信息加强用户特征的方法准确率高于仅考虑显式信息的方法, 说明隐性影响更能反映用户特点, 并可较好地缓解冷启动问题.但是这些方法忽略信任用户对目标用户具有不同的隐性影响, 即用户之间的信任度不同.因此, 本文提出融合信任隐性影响和信任度的推荐模型(Recommendation Model Combining the Impli-cit Influence of Trust with Trust Degree, RIITD), 在引入社交信息中信任关系的前提下, 不仅考虑用户在信任关系中的显式行为数据, 还考虑信任关系的隐性影响(如被信任用户的潜在特征向量), 用于获取冷启动用户的偏好特征, 有效缓解在社交信息较少时不能准确地为冷启动用户进行推荐这一问题.此外, 本文提出综合信任度的度量, 体现目标用户与信任用户之间不同的社交影响, 发挥信任用户的积极影响, 提升推荐系统的性能.在3个常用数据集上的实验表明, 本文方法推荐精度较高.
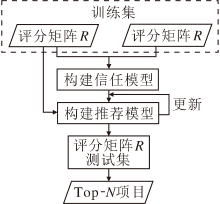
本文提出融合信任隐性影响和信任度的推荐模型(RIITD), 整个流程如图1所示.在RIITD中, 考虑用户-项目评分矩阵和用户-用户信任矩阵的显性影响和隐性影响, 并融入信任用户的信任度, 区分不同信任用户对目标用户产生的不同社交影响, 提高信任数据的可靠性.显性影响是指用户对于项目的真实评级数据和信任矩阵中用户直接的信任关系等显式信息; 隐性影响是指用户过去已评分项目的特征(历史评分数据的特征)和目标用户信任用户的特点等隐式信息.
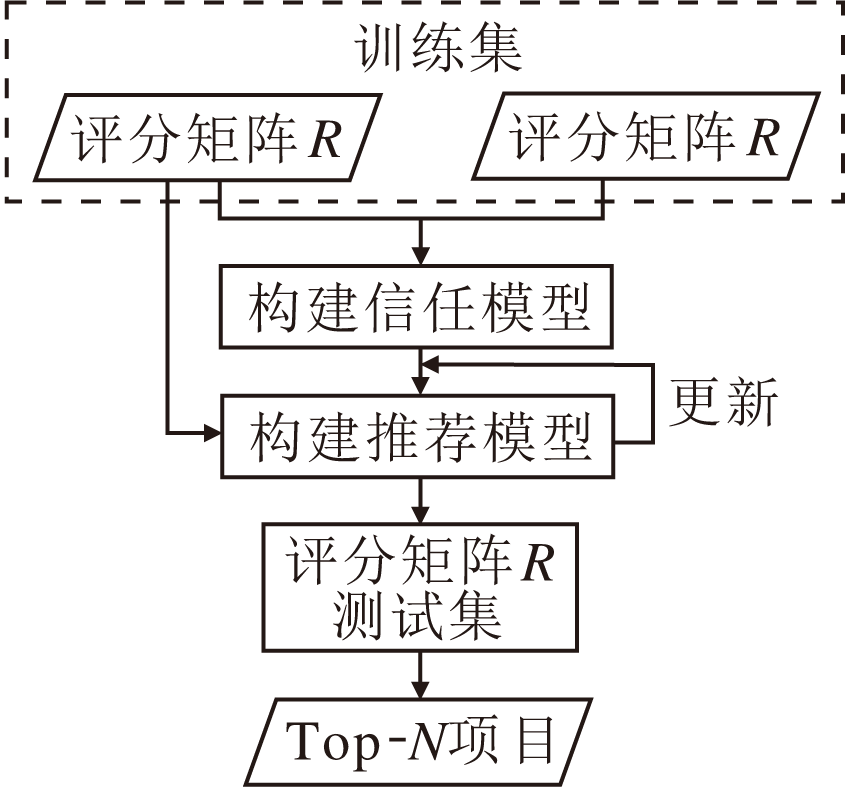 | 图1 RIITD流程图Fig.1 Flowchart of RIITD |
在RIITD中, 信任的显性影响被用来约束用户的特征向量应符合该用户的社会信任关系, 并通过扩展用户建模将信任的隐性影响添加到模型中.模型确保即使用户很少或没有给出评级, 也可从用户的信任信息中获取用户的特定向量, 得到其偏好特征, 从而更好地缓解冷启动问题.但是, 现实生活中信任用户推荐的项目并不一定总是好的和目标用户喜欢的, 这样就需要一个指标以确定信任用户对目标用户的选择起多大作用.因此引入用户信任度, 将信任用户进行分类, 使更可靠的用户起更大的影响作用, 避免虚假恶意用户的影响.
本文的推荐问题是基于用户-项目评分矩阵和用户-用户信任矩阵预测用户对未知项目的评分.R=[ru, i]m× n表示用户-项目评分矩阵, 其中每个条目ru, i表示用户u对项目i给出的评分, 通常范围在1~5内, 较高值意味着具有更强的偏好.在后文中使用u、v表示用户, i、 j表示项目.Iu表示用户u已评分过的项目集.通过对用户-项目矩阵进行因式分解得到两个低秩矩阵:用户特征矩阵P∈ Rd× m和项目特征矩阵Q∈ Rd× n, 其中pu、qi分别表示用户u和项目i的d维潜在特征向量.通过P、Q恢复原评分矩阵, 即R≈ PTQ, 其中PT为P的转置矩阵.因此, 用户u对项目j的评分可通过用户特征向量pu和项目特征向量qj的内积预测, 即
$\begin{align}L_{r}\left(\boldsymbol{q}_{j}, \boldsymbol{p}_{u}\right)=\frac{1}{2} \sum_{u} \sum_{j \in I_{u}}\left(\boldsymbol{q}_{j}^{\mathrm{T}} \boldsymbol{p}_{u}-\boldsymbol{r}_{u, j}\right)^{2}+ \\ \frac{\lambda}{2}\left(\sum_{u}\left\|\boldsymbol{p}_{u}\right\|_{\mathrm{F}}^{2}+\sum_{j}\left\|\boldsymbol{q}_{j}\right\|_{\mathrm{F}}^{2}\right)\end{align}$,
学习用户和项目的特征矩阵, 其中, ‖ · ‖ F为Frobenius范数, λ 为控制模型复杂度和避免过拟合的参数.
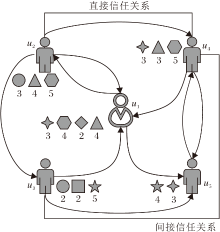
另一方面, 假设一个社交网络由图G=(V, E)表示, 其中, V表示m个节点(用户), E表示用户之间的定向信任关系.如图2所示, 图中有5个节点, 分别表示用户u1~u5, 每位用户节点旁边的图形表示该用户已评分过的不同项目种类和评分值.因为信任关系是有向的, 所以节点之间使用有向边.
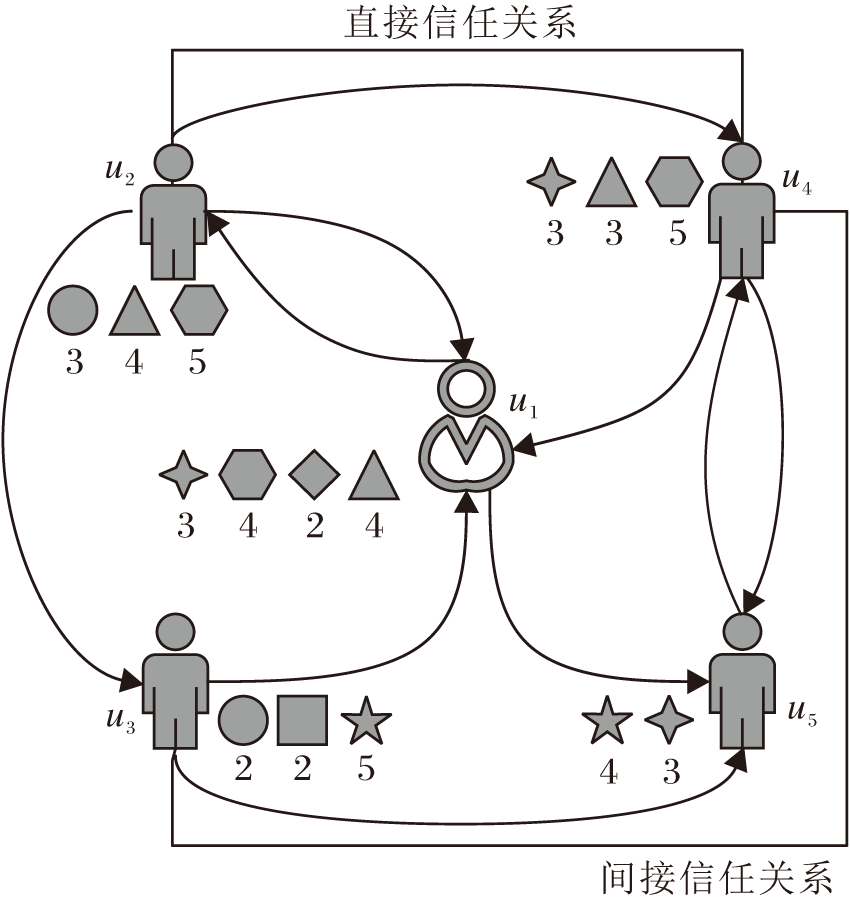 | 图2 社会化网络图Fig.2 Social network diagram |
在图2中, 用户u1信任用户u2、u5, 用户u2、u3、u4信任用户u1.使用邻接矩阵T=[tu, v]m× m表示图2, 其中tu, v表示用户u对用户v的信任关系.使用pu、wv分别表示信任者和被信任者的d维潜在特征向量.此外, 将信任矩阵中的信任者和评级矩阵中的活跃用户共享相同的用户特征空间, 以此连接二者, 可得信任者特征矩阵P∈ Rd× m和被信任者特征矩阵W∈ Rd× m, 通过T≈ PTW恢复信任矩阵, 利用
$\begin{align}L_{t}\left(\boldsymbol{p}_{u}, \boldsymbol{w}_{v}\right)=\frac{1}{2} \sum_{u} \sum_{v \in T_{u}}\left(\boldsymbol{w}_{v}^{\mathrm{T}} \boldsymbol{p}_{u}-\boldsymbol{t}_{u, v}\right)^{2}+\\ \frac{\lambda}{2}\left(\sum_{u}\left\|\boldsymbol{p}_{u}\right\|_{F}^{2}+\sum_{v}\left\|\boldsymbol{w}_{v}\right\|_{F}^{2}\right)\end{align}$,
其中Tu为用户u信任的用户集.
在社交网络快速发展的时代, 用户之间的交互增加, 信任关系的建立也变得方便快速.利用信任关系预测用户喜好成为学者研究的新方向.但是, 单纯将信任关系加入推荐系统并不符合现实生活的情况.在现实世界, 信任用户的喜好并不总和自己的喜好一致, 很多情况下会有一定差别.本文考虑目标用户与信任用户之间的喜好差别, 建立信任模型, 引入综合信任度度量信任用户对目标用户的不同影响, 综合信任度的定义如下:
Truu, v=β DTu, v+(1-β )IDTu, v, (1)
其中, DTu, v、IDTu, v分别表示用户u、v的直接信任度和间接信任度, β 表示用户直接信任度和间接信任度所占的比重.
用户间的直接信任关系是指在社会化网络中具有直接好友关系, 可进行直接交流的信任关系, 如图2, 用户u2、u4之间为直接信任关系.用户间的直接信任度包括用户之间的熟悉程度和被信任用户的权威度.直接信任度表示为:
DTu, v=α Famu, v+(1-α )Authv,
其中, Famu, v表示目标用户u和推荐用户v的熟悉度, Authv表示推荐用户v的权威度, α 表示熟悉度和权威度的权重因子.
熟悉度和权威度的具体介绍如下.用户熟悉度根据用户之间的互动频率表现, 即认为互动频率越高, 两者越熟悉, 熟悉度为:
Famu, v=
其中, Iu, v表示用户u、v的交互次数, Iu, max、Iu, min分别表示用户u与其他用户交互的最大/最小次数.
用户的权威度包括全局权威度和个人权威度.在社交平台中, 部分用户拥有很多关注者, 这类用户可极大地影响其它用户做出决策, 本文将这类用户视为权威用户, 根据这一特性计算全局权威度.一般认为权威用户对于物品的评分与大众评分较符合, 即接近物品评分均值, 因此考虑用户评分与物品平均评分间的差异, 将该差异定义为用户个人权威度, 即计算用户对项目的评分与该项目全局平均评分之差, 差值越小表示该用户的个人权威度越高.因此, 得出用户权威度的计算方法:
$\begin{align}Auth_{v}=\delta\left(\frac{F_{v}-\operatorname{Min}_{F}}{\operatorname{Max}_{F}-\operatorname{Min}_{F}}\right)+\\(1-\delta) \sum_{i \in I_{v}}\left(\frac{1-\left|r_{v, i}-\bar{r}_{i}\right|}{\left|I_{v}\right|}\right)\end{align}$
其中:δ 用于调节全局权威度和个人权威度所占比例, 常认为全局权威度和个人权威度对用户的影响程度相同, 所以取δ =0.5; Fv表示关注用户u的用户数量; MinF和MaxF分别表示所有用户中关注者数的最小值和最大值;
间接信任关系是指用户之间并不是直接的好友关系, 而是通过若干好友进行联系, 体现信任的传递性特点.如图2所示, 用户u3、u4之间无直接联系, 但是可通过不同的用户路径建立联系(u3→ u5→ u4、u3→ u1→ u2→ u4), 因此两者为间接信任关系.
六度分割理论指出, 世界上2个陌生人之间间隔的人数不会超过6个, 因此在本文中信任度在社会化网络中的最大传播路径长度应小于等于6, 传播路径长度过长已不具备参考价值.由图2可知, 两位用户间的传播路径有多条, 所以在计算间接信任度时, 必须考虑用户间的最大传播路径.本文根据社交用户的总数量和每位用户社交数量的平均数计算最大传播路径长度:
dmax=
其中, N表示社交用户总数量, I表示社交网络中每位用户交互数量的平均数.
推荐用户与目标用户之间有多条路径进行关联, 中间用户可以是一位也可以是多位, 所以用户的间接信任度与两位用户间的关系路径长度、数量、边权重和中间用户的直接信任度有关:
$I D T_{u, v}=\frac{\sum_{k=1}^{n}\left[e^{-\left|p_{k}\right|} \prod_{x \in p_{k}, y \in p_{k}} D T_{x, y}\right]}{\sum_{k=1}^{n} e^{-p_{k}}}$
其中:
RIITD建立在已有的推荐模型TrustSVD[18]的基础上.TrustSVD的基本原理是考虑用户和项目的偏差, 以及已评分项目和信任用户对评分预测的影响.
首先将项目和用户转换到相同的潜在特征空间, 从而使它们直接具有可比性.除考虑目标用户和待评分项目的潜在特征向量以外, 还考虑用户和项目的偏差、目标用户已评分项目和目标用户的信任用户的隐性影响.用户u对项目j的预测评分为:
$\begin{aligned} \hat{{r}}_{u, j}={b}_{u} & amp; +{b}_{j}+{\mu}+\\ & {q}_{j}^{\mathrm{T}}\left({p}_{u}+\left|I_{u}\right|^{-\frac{1}{2}} \sum_{i \in I_{u}} {y}_{i}+\left|T_{u}\right|^{-\frac{1}{2}} \sum_{v \in T_{u}} {w}_{v}\right) . \end{aligned}$
其中:bu表示用户偏差; bj表示项目偏差; μ 表示全局平均评级; Iu表示用户u已评分过的项目集; Tu表示用户u信任的用户集; yi表示用户u过去已评级项目的潜在特征向量, 包含用户过去对未来未知项目评分的隐性影响; wv表示用户u信任用户的潜在特征向量, 因此
pu+|Iu|
RIITD在TrustSVD的基础上进一步扩展用户模型, 考虑用户的行为特点, 除从历史评分数据的特点和目标用户信任用户的特点之外, 考虑信任用户对评分的影响并不能一概而论.目标用户对信任用户的信任程度越大, 该信任用户的评分对目标用户的影响也越大.因此, 利用信任度这一用户特性, 根据信任度的大小改变信任用户对目标用户的影响, 使信任影响的融入更具有可靠性.此时用户u对项目j的预测评分为:
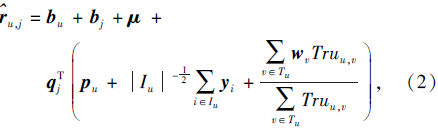
其中Truu, v为用户u、v结合用户间的直接信任度和间接信任度得到的用户之间的综合信任度.
为了避免过拟合, 本文采取正则化技术.由于活跃用户和活跃项目过拟合的机率较小, 而冷启动用户和项目过拟合的机率更大, 所以对活跃用户和项目进行弱惩罚, 而冷启动用户和项目更加正则化.虽然给不同的变量单独分配正则化参数可实现更精细的控制和调优, 但与不同的模型进行对比会导致很大的复杂度.所以为了降低模型复杂度, 所有变量使用相同的正则化参数λ .目标函数如下:
$\begin{align}L\left({b}_{u}, {b}_{j}, {p}_{u}, {q}_{j}, {y}_{i}, {w}_{v}\right)=\frac{1}{2} \sum_{u} \sum_{j \in I_{u}}\left(\hat{{r}}_{u, j}-{r}_{u, j}\right)^{2}+\\ \frac{\lambda_{t}}{2} \sum_{u} \sum_{v \in T_{u}}\left(\hat{{t}}_{u, v}-{t}_{u, v}\right)^{2}+\frac{\lambda}{2} \sum_{u}\left|I_{u}\right|^{-\frac{1}{2}} {b}_{u}^{2}+\\ \frac{\lambda}{2} \sum_{j}\left|U_{j}\right|^{-\frac{1}{2}} {b}_{j}^{2}+\sum_{j}\left|U_{j}\right|^{-\frac{1}{2}}\left\|{q}_{j}\right\|_{\mathrm{F}}^{2}+\\ \sum_{i}\left|U_{i}\right|{ }^{-\frac{1}{2}}\left\|{y}_{i}\right\|_{\mathrm{F}}^{2}+\left|T_{v}^{+}\right|^{-\frac{1}{2}}\left\|{w}_{v}\right\|_{\mathrm{F}}^{2}+\\ \sum_{u}\left(\frac{\lambda}{2}\left|I_{u}\right|{ }^{-\frac{1}{2}}+\frac{\lambda_{t}}{2}\left|T_{u}\right|^{-\frac{1}{2}}\right)\left\|{p}_{u}\right\|_{\mathrm{F}}^{2}\end{align}$, (3)
其中, Ui、Uj分别表示给项目i、 j评分过的用户集,
为了得到上述目标函数的局部最优解, 本文对各部分使用梯度下降法求解:
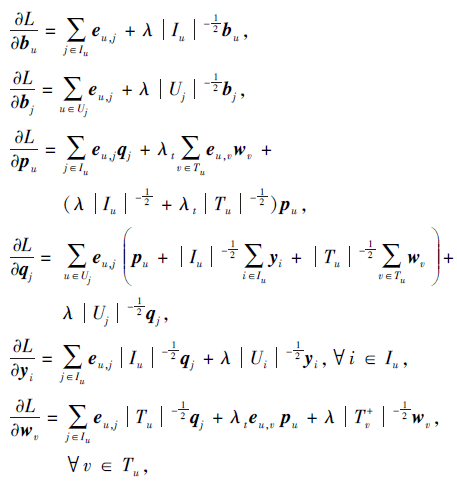
其中, eu, j=
RIITD伪代码如算法1所示.
算法1 RIITD
输入 Rating matrix R, Trust matrix T,
number of iterations K
输出 RMSE, MAE
Split data set into training set Tr and test set Te;
for each u∈ R, v∈ R do
Calculate the Truu, v using Eq(1);
end for
Initialize User bias bu, Item bias bi, Item feature vector qj, User feature vector pu, Potential feature vector of the items that user u has rated in the past yi, Potential feature vector of users trusted by user u wu
for k=1 to K do
for u∈ Tr, i∈ Tr do
Calculate the predicted rating
for the target user u using Eq(2);
Calculate the error between the predicted rating
and the true rating err=
update bu, bj, qj, pu, yi, wu using Eq(3);
end for
end for
for u∈ Te, i∈ Te do
Calculate the predicted rating
for the target user u using Eq(2)
Calculate RMSE and MAE
end for
return RMSE, MAE
RIITD的时间主要花费在计算信任度、最小化目标函数和对各变量进行梯度下降的过程中.计算信任度的时间为T(|R|+|T|), 计算目标函数的时间为T(d|R|+d|T|).对各个向量进行梯度下降法求解,
T(d|R|), T(d|R|), T(d|R|+d|T|),
T(d|R|+d|T|), T(d|R|n),
T(d|R|m+d|T|m),
所以一次迭代的总体时间为
$\begin{align}T(|{R}|+|{T}|)+T(d|{R}|+d|{T}|)+\\ T(d|{R}|)+T(d|{R}|)+T(d|{R}|+d|{T}|)+\\T(d|{R}|+d|{T}|)+T(d|{R}| n)+\\T(d|{R}| m+d|{T}| m)\end{align}$
时间复杂度为
O(dc(|R|+|T|))=O(|R|+|T|),
其中, d表示特征向量维数, |R|、|T|表示评分矩阵和信任矩阵中的已知项数, n表示项目得到评分的平均数量, m表示用户得到的信任声明的平均数量, c=max(n, m), 由于评分矩阵和信任矩阵都是稀疏的, 所以c≪|R|或c≪|T|.
已有的社会推荐模型, 如SoRec[10]、SR[12]、TrustSVD[18]等, 一次迭代的时间复杂度均为O(|R|+|T|), 可见RIITD在考虑信任隐性影响和信任度的情况下, 并未降低时间效率.由于总体的时间复杂度与评分矩阵和信任矩阵中的已知项数呈线性关系, RIITD可扩展到非常大的数据集.
本文在Epinions、FilmTrust、Ciao这3个社交推荐领域常用数据集上进行实验.3个数据集均包含各模型中需要的用户评级数据和信任关系.
Epinions数据集是一个从网站收集的数据集, 人们可在这里查看多个类别的产品, 如电影、电脑和体育.用户可给每个项目分配1~5范围内的评级.此外, 用户通过信任声明表达他们的信任关系.数据集包含40 163位用户和139 738个不同的项目.
FilmTrust数据集包括1 508位用户、2 071个项目和35 497个评级.用户可对项目给出0.5~4.0范围内的评分数据以表达他们的兴趣.此外, 用户之间的链接信息作为FilmTrust数据集中的信任信息.
Ciao数据集是从http://dvd.ciao.co.uk网站上抓取的DVD类别数据集, 包括7 375位用户、99 746个项目和280 391个评级, 评级范围为1~5.数据集中用户的信任关系也通过信任声明表达.
各数据集的详细信息如表1所示.
| 表1 实验数据集详细信息 Table 1 Detailed information of experimental datasets |
为了验证RIITD的有效性, 本文选择如下5种模型进行对比.这5种模型分别从3个方面选择:1)仅考虑评分矩阵显性影响和隐性影响的SVD++[5]; 2)不考虑隐性影响, 但结合社交关系的SoRec[10]、RSTE[11]和SR[12]; 3)考虑评分矩阵和社交矩阵的显性影响和隐性影响, 但未考虑信任度的TrustSVD[18].具体描述如下.
1)SVD++.利用评分矩阵的隐性影响与显性影响, 但不考虑信任信息.
2)SoRec.考虑社会关系的约束, 共享一个由评分矩阵和信任矩阵分解而成的通用用户特征矩阵.
3)SR.活跃用户特定于用户的向量应接近其可信邻居的平均值, 并用作正则化形式, 形成新的矩阵分解模型.
4)RSTE.组合基本矩阵分解模型和基于信任的邻域线性模型.
5)TrustSVD.是SVD++融入社交信息的推广, 即将社交矩阵的显式关系作为隐式反馈信息加入SVD++.
实验在LENOVO台式机上进行, 使用 Intel Core CPU, i7-6700, 3.4 GHz, 16 GB RAM, 编程环境为Python 3.7.实验在所有用户和冷启动用户两种视图下分别与5种模型进行对比, 以MAE、RMSE和F-Measure作为评价指标.所有用户表示所有评级都用作测试集, 冷启动用户表示只有评分少于5项的用户参与测试集.
评分预测的预测准确率通常通过均方根误差(Root Mean Square Error, RMSE)和平均绝对误差(Mean Absolute Error, MAE)计算, RMSE和MAE的计算公式为
RMSE=
$M A E=\frac{1}{|N|} \sum_{u, i}\left|\hat{r}_{u, i}-r_{u, i}\right|$,
其中N为测试集评级数量.RMSE和MAE数值越小表明预测精度越高.
准确率(Precision)和召回率(Recall)是广泛用于信息检索和统计学分类领域的两个度量值, 用于评价结果的质量.准确率检验推荐的项目有多少是准确的, 召回率检验所有准确的条目有多少被推荐.
由于有时准确率和召回率会出现矛盾的情况, 因此需要综合考虑, 由此引入综合评价指标F-Measure.
准确率、召回率和F-Measure计算公式如下:
Precision=
Recall=
F-Measure=
此外, 使用五折交叉验证训练和测试模型.具体而言, 将原始的评分数据随机分成5个子集, 将每个子集数据分别做一次测试集(Testing Test), 其余的4组子集数据作为训练集(Training Test).进行5次循环以确保所有的子集都进行测试, 平均测试性能作为最终结果.
SVD++、SoRec、SR、RSTE、TrustSVD的参数来自于相应的参考文献, RIITD的参数通过设置不同的值, 训练不同模型和选择更好的测试值以决定, 具体如表2所示.
| 表2 参数设置 Table 2 Parameter settings |
2.4.1 α 取值对推荐结果的影响
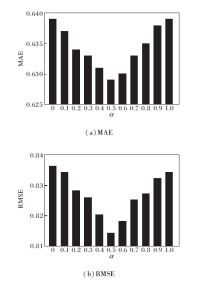
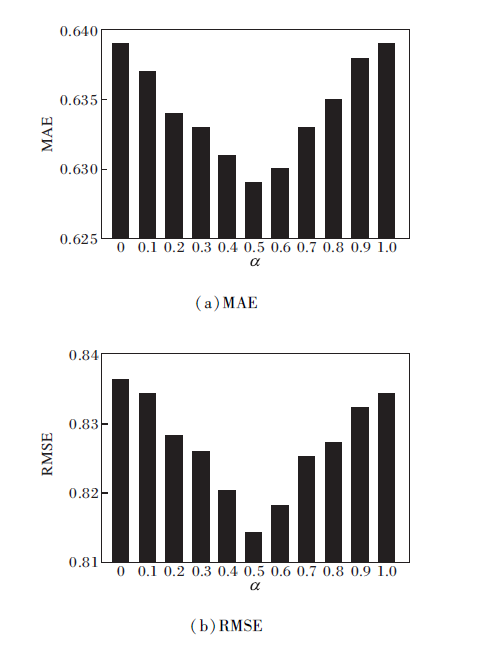
在计算直接信任度时, 考虑用户熟悉度和权威度两个因素, α 为调整两个因素的权重因子.α 的取值直接影响最终的推荐结果, 本次实验设定β =0.5, 即直接信任与间接信任各占一半, 设α =0, 0.1, ···, 1.0, MAE、RMSE值如图3所示.
 | 图3 α 值对MAE和RMSE的影响Fig.3 Effect of α on MAE and RMSE |
图3是在FilmTrust数据集上所有用户视图下的结果, 其它数据集上的实验结果与其类似.由图可看出, MAE、RMSE值都随α 值先减后增, 并在α =0.5时取得最小值, 表明在直接信任中, 用户之间的熟悉度和用户的权威度同样重要.
2.4.2 β 取值对推荐结果的影响
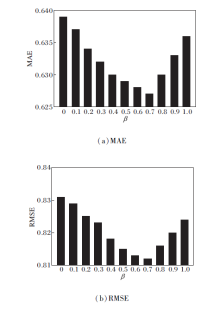
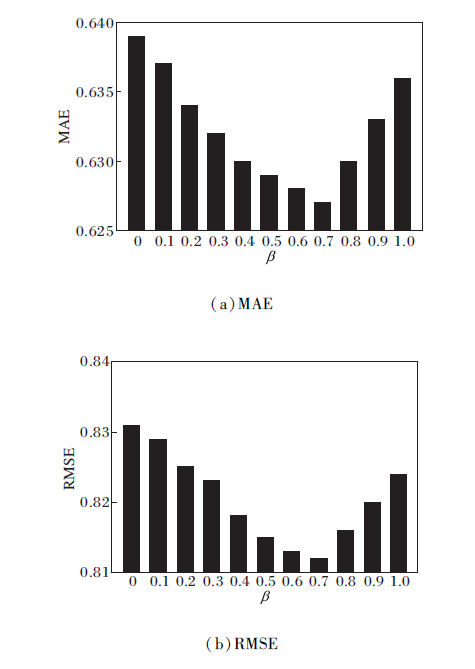
在计算综合信任度时, 结合直接信任度和间接信任度, 其中, β 为调节两者所占比例的权重因子, β 的不同取值会影响综合信任度的值.根据上述实验结果取α =0.5, β =0, 0.1, ···, 1.0.MAE、RMSE值如图4所示.
 | 图4 β 值对MAE和RMSE的影响Fig.4 Effect of β on MAE and RMSE |
图4是在FilmTrust数据集上所有用户视图下的结果, 其它数据集的实验结果与其类似.由图可看出, MAE、RMSE值都随β 值先减后增, 并在β =0.7时取得最小值.该结果表明, 在计算综合信任度时, 直接信任度的占比更大, 在社交网络中用户之间的直接信任关系更影响用户的选择, 即用户更愿意听取有直接信任关系的朋友的意见.
2.4.3 潜在特征向量维数d对模型性能的影响
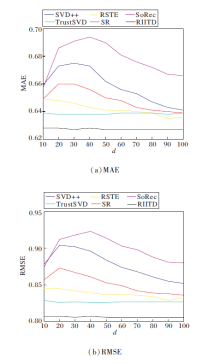
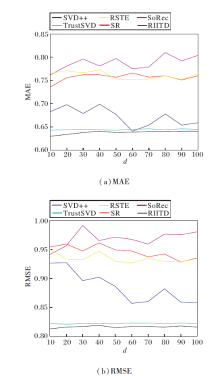
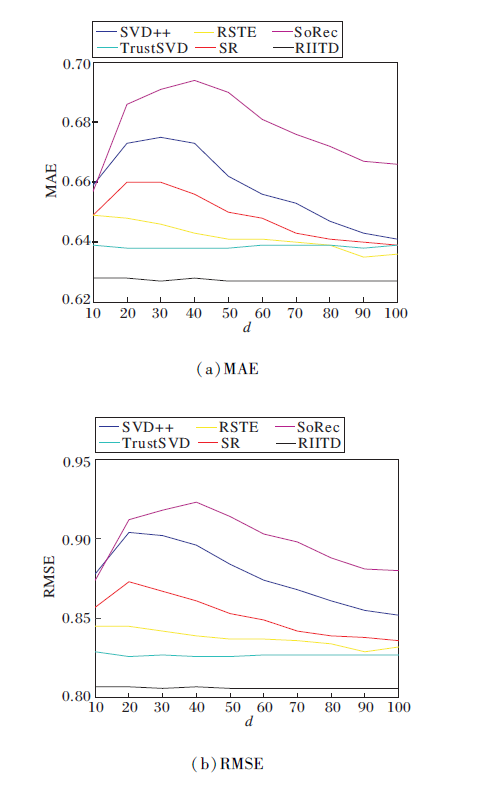
由于各模型都使用矩阵分解技术, 本文首先研究潜在特征维数d的取值对各模型的稳定性的影响, 结果如图5和图6所示.
 | 图5 d不同时, 所有用户视图下的MAE和RMSE对比Fig.5 Comparison of MAE and RMSE in all users views with different d |
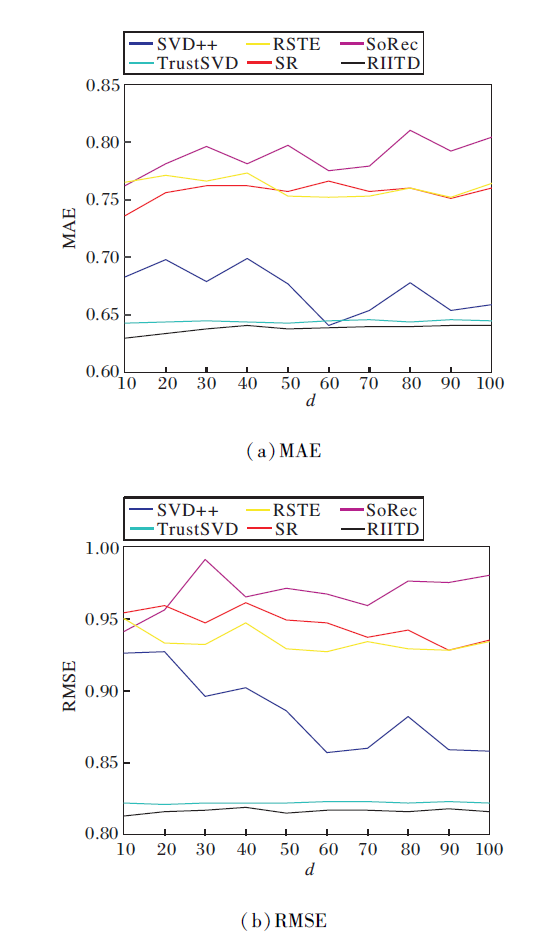 | 图6 d不同时, 冷启动用户视图下的MAE和RMSE对比Fig.6 Comparison of MAE and RMSE in cold-start users views with different d |
图5和图6是当潜在特征向量维数d取不同值时, 所有用户和冷启动用户视图下的MAE、RMSE值对比.采用FilmTrust数据集, 其余两个数据集与图5和图6中结果变化趋势类似.由图可看出, 除了RIITD与TrustSVD, 其它模型在特征向量维数变化时, 两类指标都呈现无规律浮动, 而RIITD浮动范围很小, 体现模型相对于特征维数的可靠性.这是因为RIITD从多层次、多方面、多角度考虑评级数据和信任数据的各种影响, 不仅依靠评分矩阵和信任矩阵的显性影响进行矩阵分解, 还考虑隐性影响, 充分发挥数据的效用.
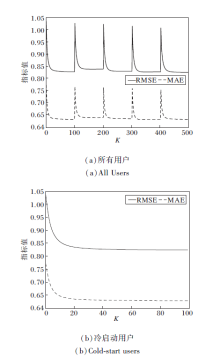
2.4.4 迭代次数K的选择
设置各参数后, 迭代次数K的选择成为影响算法的关键.本文将迭代次数K设为100, 在FilmTrust数据集上分别在所有用户和冷启动用户视图下进行实验, MAE、RMSE值如图7所示.
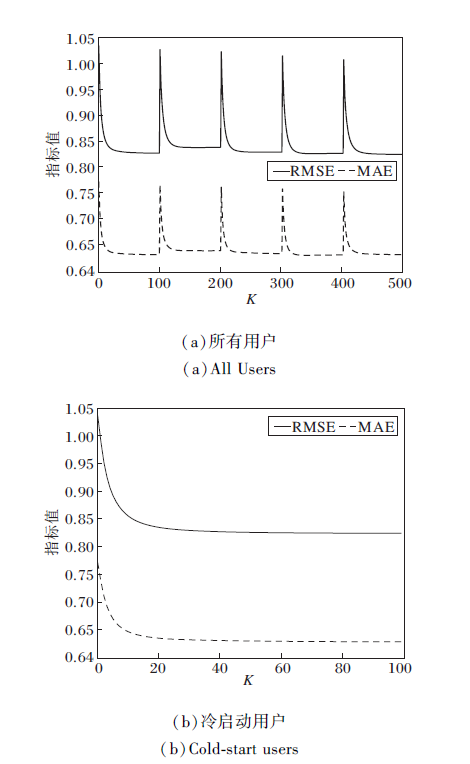 | 图7 迭代次数K对MAE和RMSE的影响Fig.7 Effect of iteration number K on MAE and RMSE |
图7(a)中[0, 100]、[100, 200]、[200, 300]、[300, 400]、[400, 500]分别对应在所有用户视图下进行实验时, 五折交叉验证中每折交叉验证MAE、RMSE值随迭代次数的变化情况.由图可观察到, 5个区间的变化趋势一样, 在0~20次迭代时, MAE、RMSE值下降速度很快, 在20~60次迭代时下降缓慢, 60~100次迭代时趋于稳定.(b)为在冷启动用户视图下进行实验的结果, 变化趋势与在所有用户视图下的结果基本一致.因此, 本文将迭代次数设为K=100.
2.4.5 实验结果对比
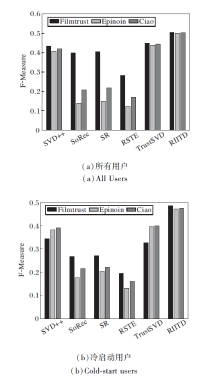
设置α =0.5, β =0.7, K=100, 分别在3个数据集上进行实验, F-Measure值如图8所示.
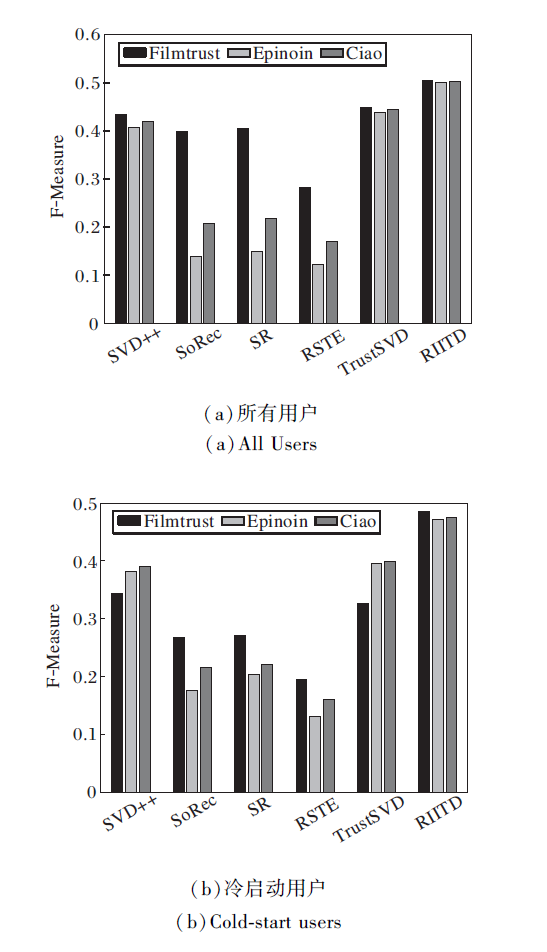 | 图8 各模型在3个数据集上的F-Measure值对比Fig.8 F-Measure comparison of different models on 3 datasets |
由图8可看出, 在3个不同的数据集上, RIITD的F-Measure值最高, TrustSVD的F-Measure值次高.但RIITD的F-Measure仍低于0.6, 这是因为对于RIITD推荐预测评分前几的项目, 在计算准确率和召回率时考虑推荐项目列表与用户在测试集的真实评分列表的交集, 而用户真实评分列表中低分项目占了一定比例, 这些项目一般是不会进行推荐的.
由于维数d的变化对RIITD影响不大, 但考虑对比模型大多数在d=100时效果更优, 选择d=10, 100进行实验.在表3和表4中, 黑体数字表示最优结果, 斜体数字表示次优结果.
| 表3 各模型在所有用户视图下的实验结果 Table 3 Experimental results of different models in all users views |
| 表4 各模型在冷启动用户视图下的实验结果 Table 4 Experimental results of different models in cold-start users views |
表3为所有用户视图下6种模型在3个数据集上的实验结果.由表可看出, 在FilmTrust、Ciao数据集上, RIITD最优并取得更小的MAE、RMSE值.在Epinions数据集上d=100时SocialRste优于RIITD, 但二者相差很小.
表4为冷启动用户视图下6种模型在3个数据集上的实验结果.由表可看出, 除了在Ciao数据集上d=100时SVD++的MAE更小以外, 其余情况在数据集上都取得更小的MAE和RMSE值.
表3和表4的最后一列为RIITD最优时与次优模型相比的改进率, 改进率最高达2.05%, 最小也有0.17%.即使MAE和RMSE的改进很小, 在实践中也可能导致推荐的重大差异.
由表3和表4可看出, 除了RIITD以外, SVD++和TrustSVD表现最优.SVD++虽然没有结合信任信息, 但仍优于其它基于信任的模型, 这是因为SVD++考虑评分数据的隐性影响, 进一步降低预测误差.
TrustSVD虽然也考虑评级和信任数据的隐性影响, 但并未考虑信任用户影响的差别.在RIITD中, 考虑可信用户的信任度, 区分每位可信用户对目标用户造成的影响, 增加可信用户的可靠性.实验结果表明, 在考虑评级和信任的隐性影响的同时, 考虑信任度是非常必要的.
本文提出融合信任隐性影响和信任度的推荐模型(RIITD), 不仅考虑显式评分数据和显式社交关系, 还考虑用户历史评分项目和信任用户的潜在特征对目标用户的影响, 丰富预测目标用户偏好特征的依据, 有效缓解冷启动用户问题.将信任度引入模型, 体现目标用户与信任用户之间不同的社交影响, 发挥信任用户的积极影响.实验表明, RIITD无论是在全体用户还是在冷启动用户视图下, 预测精度均较优.
信任是一个复杂的概念, 在不同的语境下有不同的解释, 而对于信任的不同理解, 研究者可能会提出不同的社会推荐方法.这意味着需要更细致的利用信任关系的推荐方法.今后将考虑社交网络信任的来源和产生机制等因素对推荐性能的影响, 提出新的推荐模型和推荐方法.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|