
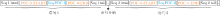


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于语句融合和自监督训练的文本摘要生成模型
[邹傲1  , 郝文宁
, 郝文宁1 , 靳大尉1 , 陈刚1 ]
, 郝文宁, 靳大尉, 陈刚]
|
|



作者简介: 
邹 傲,博士研究生,主要研究方向为自然语言处理、深度学习.E-mail:zouao@aeu.edu.cn. 
靳大尉,硕士,副教授,主要研究方向为大数据、文本数据挖掘.E-mail:dwjin@yandex.com. 
陈 刚,硕士,教授,主要研究方向为数据仿真、深度学习.E-mail:13376067283@aeu.edu.cn.
为了提高深度神经网络文本生成技术的语句融合能力,文中提出基于语句融合和自监督训练的文本摘要生成模型.在模型训练前,首先根据语句融合理论中的信息联系点概念对训练数据进行预处理,使其满足之后模型训练的需要.文中模型可分为两个阶段的训练.在第一阶段,根据语句融合现象在数据集上的分布情况,设计以信息联系点为最小语义单元的排列语言模型训练任务,增强模型对融合语句上下文的信息捕捉能力.在第二阶段,采用基于语句融合信息的注意力掩码策略控制模型在生成文本过程中的信息摄入程度,加强文本生成阶段的语句融合能力.在公开数据集上的实验表明,文中模型在基于统计、深层语义和语句融合比例等多个评测指标上都较优.
About Author:
ZOU Ao, Ph.D. candidate. His research interests include natural language processing and deep learning.
JIN Dawei, master, associate professor. His research interests include big data and text data mining.
CHEN Gang, master, professor. His research interests include data simulation and deep learning.
To improve the capability of sentence fusion of deep neural network text generation technique, a text summary generation model based on sentence fusion and self-supervised training is proposed. Before the model training, the training data are firstly pre-processed according to the concept of points of correspondence in the theory of sentence fusion, and thus the data can meet the needs of model training. The training of the proposed model falls into two parts. In the first stage, according to the distribution of the sentence fusion phenomenon in the dataset, the training task of the permutation language model is designed with the points of correspondence as the minimum semantic unit to enhance the ability to capture the information of the fused sentence context. In the second stage, an attention masking strategy based on the fusion information is utilized to control the information intake of the model during the text generation process to enhance the fusion ability in the text generation stage. Experiments on the open dataset show that the proposed model is superior in several evaluation metrics, including those based on statistics, deep semantics and sentence fusion ratio.
本文责任编委 林鸿飞
Recommended by Associate Editor LIN Hongfei
自然语言处理(Natural Language Processing, NLP)领域的研究可分为自然语言理解(Natural Language Understanding, NLU)和自然语言生成(Natural Language Generation, NLG)两方面.NLU侧重于使计算机理解自然语言并提取有用的信息, 以便于下游任务的使用.常见的NLU任务包括分词、词性标注、句法分析等.NLG需要计算机能输出人类可理解的自然语言文本, 常见的NLG任务有翻译、文本摘要等.
文本自动摘要(Automatic Text Summarization)是NLG领域中最具挑战性的任务之一, 根据Luhn等[1]的定义, 文本摘要的形式化表达如下:输入为包含n个单词的原始文档D, 目标输出为包含原始文档主要内容的摘要Y, 其中Y由m个单词组成, 满足m≪n.
根据生成方式的不同, 文本自动摘要技术可分为抽取式自动摘要和生成式自动摘要, 涉及的技术包含特征评分、分类算法、线性规划、次模函数、图排序、序列标注和深度学习算法等[2].早期研究大多采用抽取式方法进行自动文本摘要[3, 4, 5], 这类方法直接从原始文档中提取关键文本序列, 直观且容易实现.然而, 抽取式方法生成的摘要文本全部来源于原始文档中连续的文本序列, 不可避免地带有大量冗余信息.此外, 通过选取原始文档若干语句组成的文本概括性有限, 只能提取原始文档中的关键语句, 并不是在理解原始文本的基础上进行概括.因此, 抽取式方法生成的摘要文本从本质上讲是受限的, 难以生成概括性较强的高质量摘要文本.
随着深度学习研究的不断深入, 文本自动摘要领域开始出现一批生成式自动摘要的高质量研究[6, 7, 8, 9, 10].2018年以后, ELMo(Embeddings from Lan-guage Models)[11]、GPT(Generative Pre-training)[12]及BERT(Bidirectional Encoder Representation from Transformers)[13]相继出现, 使预训练语言模型+微调的模式成为自然语言处理领域实用的应用模式之一.将经过充分预训练的语言模型应用到生成式自动摘要任务只需少量的模型微调(Fine-Tune)即可达到与之前最优模型(State-of-the-Art, SOTA)相媲美的性能表现, 并在GLUE(General Language Under-standing Evaluation)[14]、SQuAD(Stanford Question Answering Dataset)[15]、RACE(Large-Scale Reading Comprehension Dataset)[16]等NLP的多个下游任务中持续领先.因此, 基于Transformer结构的神经网络模型也成为生成式摘要生成模型中基准方法之一.
根据Lebanoff等[17]的总结, 生成式文本自动摘要技术主要通过两种方法概括原始文档.1)语句压缩(Sentence Compression), 去除句子中的单词和短语, 减小单个语句的长度[18, 19, 20, 21].2)语句融合(Sen-tence Fusion), 从若干语句中分别选取部分内容并融成一个语句.由于删除语句中不重要的内容, 仍能保持原句的语法语义正确, 因此语句压缩的难度相对较小[22].相比之下, 语句融合需要对若干输入语句进行凝练概括, 难度较大, 是生成式自动文本摘要模型的主要性能瓶颈.
受文献[23]工作的启发, Lebanoff等[24]提出语句间信息联系点(Points of Correspondence, PoC)的概念, 用于研究摘要文本中的语句融合现象.Lebanoff等[17]对Pointer-Generator Networks[6]等方法的生成文本进行定量分析, 并与人工生成的参考摘要进行对比, 发现前期方法生成的文本虽然在ROUGE(Recall-Oriented Understudy for Gisting Evalua-tion)[25]等指标上能取得不错成绩, 但其中通过语句融合方法的使用比例远低于人类的平均水平.为了解决该问题, Lebanoff等[26]采用基于预训练语言模型的思路, 设计两个定制的模型, 试图提升生成文本中采用语句融合方法的数量和质量, 从而提升生成的摘要文本的质量.
综上所述, 基于深度神经网络模型的生成式自动文本摘要模型主要存在如下缺点.1)所有方法基本都是基于序列到序列(Sequence to Sequence, Seq-2Seq)架构, 以生成摘要中含有人类参考摘要文本中单词重叠的统计学指标进行激励, 并不能较好地引导模型融合语句、概括内容, 生成的文本中语句融合比例较少, 概括性较弱.2)在解决生成式自动摘要中语句融合问题的方面, 已有少数研究取得一定进展, 但性能提升较有限, 相关研究尚处于起步阶段.
为此, 本文对包含语句融合标注的文本摘要数据集进行深入探究, 并添加细化标注, 以便于后续研究的开展.针对利用语句融合进行生成式文本自动摘要任务, 提出基于语句融合和自监督训练的文本摘要生成模型, 设计类语言模型训练任务, 利用数据标注构造一个文本序列级别的置换语言模型(Per-mutation Language Model, PLM)并进行训练.又针对较通用的Seq2Seq结构在处理语句融合方面能力不足的问题, 在解码端(Decoder)设计基于PoC的掩码策略, 加强生成阶段的语句融合能力.在公开数据集上的实验表明, 本文模型能取得性能提升.此外, 本文还通过模型隐层状态可视化的方式进一步探究本文模型的可解释性.
语句融合在文本自动摘要中起着突出的作用, 重要性已得到学界的共识[27].现有的文本自动摘要数据集(如CNN/Daily Mail)[28, 29]并未在训练数据中标注有关语句融合的信息.Lebanoff等[24]填补这方面的空白, 受Halliday等[23]关于英语文法中信息融合相关研究的启发, 提出基于PoC信息在CNN/Daily Mail数据集上进行标注的思路, 通过外包方式完成标注并公开数据集, 为后续有关语句融合的研究提供便利.
文献[24]中数据集将语句融合所需的PoC分为5种类型:代词指称(Pronominal Referencing)、名义指称(Nominal Referencing)、普通名词指称(Com-mon-Noun Referencing), 重复(Repetition)及事件驱动(Event Triggers).在该数据集中, 每个样本由两个包含PoC的源语句和一个摘要语句构成, 且标注PoC类型及其在源语句和摘要语句中的具体出现位置.
自监督训练(Self-Supervised Training)是指模型可直接从无标签数据中自行学习, 无需标注数据.作为自监督训练的一种, 预训练语言模型(Pre-Trained Models, PTM)是指在大规模无标注文本上学习统一的语言表示, 方便下游NLP任务的使用, 避免从头开始为新任务训练新模型[30].自监督训练的核心在于如何自动为数据产生标签, 预训练语言模型的训练任务基本都是语言模型任务或各种变体, 因此不同PTM的训练数据标注方式也是与其自身的训练任务特定相关的.
从训练任务上分, PTM可分为因果语言模型(Causal Language Model, CLM)和掩码语言模型(Masked Language Model, MLM)两种.CLM又被称作自回归模型(Autoregressive Model), 代表性的模型包括GPT系列模型[12, 31, 32]、CTRL(Conditional Trans-former Language Model)[33]、Transformer-XL(Attentive Language Models beyond a Fixed-Length Context)[34]、Reformer[35]及XLNet(Generalized Autoregressive Pre-training for Language Understanding)[36]等.训练任务通过依次输入文本中的单词预测下一个单词, 假设文本序列
x1∶ T=[x1, x2, …, xT],
则在CLM的训练过程中该文本序列的联合概率分布
p(x1∶ T)=p(x1)p(x2|x1)…p(xT|x1, x2, …, xT-1)=
MLM又被称为自编码模型(Autoencoding Mo-del), 通常采用随机添加掩码的方式遮盖输入文本序列中的部分单词, 然后根据输入文本的剩余部分预测被遮盖的单词, 常见的模型包括BERT[13]、AL-BERT(A Lite BERT)[37]、RoBERTa(Robustly Opti-mized BERT Pretraining Approach)[38]、DistilBERT (Distilled Version of BERT)[39]及XLMs(Cross-Lin-gual Language Models)[40]等.
假设输入文本序列为
x1∶ T=[x1, x2, …, xT],
对输入语句进行掩码操作后的m(x)表示被遮盖的单词, 而x\m(x)表示原始文本去除被遮盖单词后的其余文本, 则在MLM训练过程中, 该文本序列的联合概率分布为:
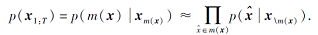
深度学习流行后, 目前主流的文本自动摘要数据集上性能较优的方案都是基于深度神经网络的模型, 且大多都以Seq2Seq结构作为基本的模型框架.以BERT的发布为界限, 这些方法又可分为前预训练时代的模型[6, 7, 8, 9, 10]及后预训练时代的模型, 即基于预训练语言模型进行摘要文本生成的各种方法.前预训练时代的模型大多数基于循环神经网络(Recurrent Neural Network, RNN), 包括长短时记忆网络(Long Short-Term Memory, LSTM)[41]、门限循环网络(Gated Recurrent Unit, GRU)[42]及其它RNN变体.后预训练时代的各种模型基本都是基于Transformer结构[43].
本文提出基于语句融合和自监督训练的文本摘要生成模型, 包含两阶段的训练步骤.第一阶段在无标签数据上执行Cohesion-Permutation语言模型自监督训练任务, 第二阶段在有标签的标准“ 文档-摘要” 数据集上执行有监督训练任务.
本文主要研究方向是利用原文语句间的信息联系点(PoC), 提升模型在生成摘要文本过程中的语句融合能力, 进而提高生成文本的质量.因此本文实验采用Labanoff等[24]在CNN/Daily Mail数据集[28]上进行PoC标注的数据集.该数据集全部来自CNN/Daily Mail数据集, 人工进行细粒度的PoC标注, 共包含1 174篇文档, 其中含有1 599个PoC标注信息.
由于原数据集只标注各种关键信息的起止位置, 不便于本文实验的具体开展, 因此首先对原始数据集进行预处理和再标注, 具体做法如下:根据原数据集中的索引标注, 在每条数据中原文档内PoC内容部分的前后添加特殊标记符号, 每出现一组PoC, 在这组PoC内容的前后添加相同的标记符号“ [POC-X-START]” 和“ [POC-X-END]” , 其中X的取值为从“ 0” 开始的递增整数, 用于标记不同的PoC.以其中一个数据项为例, 经过处理后原文中的PoC标注结果如下.
The President is headed to Panama for a regional summit, and Julie Pace of The Associated Press reports one of the big questions is whether he'll make history and have a[POC-0-START] face-to-face meeting[POC-0-END] with[POC-1-START] Cuban leader Raul Castro[POC-1-END]. And so what the White House is going to be weighing is whether[POC-0-START] this meeting[POC-0-END] would be a way to ge-nerate more progress or whether it would be a premature reward for[POC-1-START] the Castros[POC-1-END].
从标注结果可看出, 第1组PoC内容“ face-to-face meeting” 和“ this meeting” 都已分别在其前后添加“ [POC-0-START]” 和“ [POC-0-END]” 标识, 同理, 第2组PoC内容“ Cuban leader Raul Castro” 和“ the Castros” 都已分别标记“ [POC-1-START]” 和“ [POC-1-END]” .通过这样的处理方式, 方便模型直接捕捉与处理输入文本中包含的PoC信息.
正如1.2节所述, 预训练语言模型从广义上都可归为自编码语言模型和自回归语言模型, 以BERT为代表的自编码语言模型由于引入特殊的掩码机制, 能在训练中同时关注上下文的文本信息, 但掩码的出现破坏原文结构并造成模型在训练和使用两个场景下的差异, 除此以外, 被掩码单词之间的独立性假设同样是不可忽视的问题.出于上述原因, 本文更倾向于采用自回归语言模型.相比自编码语言模型, 自回归语言模型最大优势在于其从左到右的顺序训练模式与自然语言按序生成的时序特性相一致, 这也解释自回归语言模型在文本生成子任务中优于自编码语言模型的原因.自回归语言模型的相对劣势在于其自左向右的训练模式使其只能关注到一个方向的文本信息, 不能像自编码模型那样同时获得前后两个方向的文本信息.为了解决此问题, XLNet采用PLM的训练方式, 通过将文本输入顺序随机打乱的方式在自回归语言模型的条件下得以同时关注前后两个方向的文本信息.受此启发, 本文提出Cohesion-Permutation语言模型.
为了更直观地描述Cohesion-Permutation语言模型的运作方式, 本文采用如图1所示的数据项作为基本示例.图1为已经过预处理后的一个数据项, 在该数据项中只包含一组PoC信息, 黑字标记普通文本, 蓝字标记PoC文本, 红字标记PoC标注符号, 直观体现文本中各部分内容.
 | 图1 预处理后的PoC数据项Fig.1 PoC data item after preprocessing |
对应于图1所示的一个数据项示例, 进一步的抽象如图2所示.对包含同组PoC信息的同一文档中的两个语句, 对其内容按照其所属种类进行抽象.首先, 分别使用“ Seq-POC-1” 和“ Seq-POC-2” 表示PoC部分的文本本身, 即对应于图2中的蓝字部分.分别使用“ Seq-1-head” 、“ Seq-2-head” 、“ Seq-1-tail” 、“ Seq-2-tail” 表示这两处PoC内容在该语句中的前后两部分文本, 即对应于图2中的黑字部分.依旧使用PoC标记表示PoC内容与其它文本之间的界限, 即图2中的红字部分.
 | 图2 PoC数据项的抽象示意图Fig.2 Flow chart of abstract of PoC data item |
对于两个语句中的同一组PoC信息, 正如Labanoff等[24]对其的定义, 这一组PoC内容在语法上基本属于同一实体, 或在少数情况下表示一对存在因果关联的内容.语句融合的目的是将两个或多个语句融成一个语句, 对于包含一组PoC信息的两个语句, 它们分别描述同一实体的两方面内容, 而这两方面内容必然在语义上存在相互联系或信息冗余.若使用传统的自回归语言模型结构, 模型在生成图2中“ Seq-POC-1” 内容时, 仅能关注其前面“ Seq-1-head” 的相关信息, 而无法利用与其有关的“ Seq-1-tail” 内容及包含与“ Seq-POC-1” 同一组PoC信息的整个语句2.自编码语言模型结构在文本生成领域中弱于自回归语言模型, 因此采用以BERT为代表的模型同样不能较好地解决该问题.XLNet采用的PLM结构在自回归的框架下实现文本对上下文信息的双向关注, 为本文方法提供启示.
对于原始输入, Cohesion-Permutation语言模型按图3的方式进行随机打乱.Cohesion-Permutation语言模型并未选择类似于传统PLM将输入数据随机打乱的方法, 原因如下.1)本文解决的主要问题是文本生成中的语句融合问题, XLNet作为代表的PLM模型可看作一种普适性的方法, 而Cohesion-Permu-tation语言模型则针对输入语句中的PoC信息进行特殊设计.2)为了提高模型生成摘要文本的可读性和连贯性, Cohesion-Permutation语言模型以文本序列为最小单位进行随机打乱, 保留每个划分部分的相对位置信息, 有别于传统PLM在单词(token)级别的随机打乱.
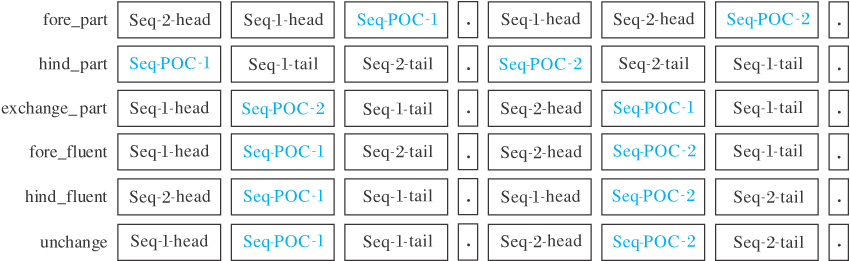 | 图3 Cohesion-permutation语言模型的训练模式Fig.3 Training mode of cohesion-permutation language model |
如图3所示, Cohesion-Permutation语言模型将输入文本按照fore_part、hind_part、exchange_part、fore_fluent、hind_fluent及unchange这6种方式进行重组.
以第1种处理方式fore_part为例, 该操作的目的是为了让模型在识别同组PoC信息时能同时关注来自两个语句的前置文本, 相比已有方法能更精准、高效地将所需信息应用到模型的训练中.
在具体实验中, 对输入文本进行fore_part、hind_part、exchange_part、fore_fluent、hind_fluent操作的概率分别设为16%, 而对输入文本不进行任何调整操作, 即unchange的概率设为20%.
图3中对原数据集进行任意打乱操作后的语料集合定义为
ZT={z1, z2, …, zn}.
在实验中, 采用36层堆叠的Transformer Decoder[43]构建Cohesion-Permutation语言模型, 训练损失函数
L(Z)=
其中, k表示输入文本范围的滑动窗口尺寸, 条件概率P采用Cohesion-Permutation语言模型进行建模, Θ 表示模型的全体参数.由于Cohesion-Permutation语言模型属于自回归语言模型的框架, 因此避免自编码语言模型存在的问题.
经过自监督的Cohesion-Permutation语言模型训练任务之后, 模型已初步具备识别和处理不同语句之间PoC信息的能力, 但为了让模型在文本自动摘要任务上获得更优性能, 还需要对本文模型进行第二阶段的有监督微调训练.
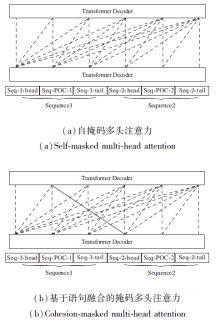
本文模型的微调训练过程如图4所示, 在微调阶段与基于Transformer Decoder结构的语言模型主要区别在于针对输入文本的掩码操作.在原始Trans-former Decoder结构中, 采用自掩码多头注意力(Masked Multi-head Attention), 而本文模型使用基于语句融合的掩码多头注意力机制(Cohesion-Masked Multi-head Attention), 其目的在于引入不同语句中包含的PoC信息, 提高模型进行语句融合的能力.
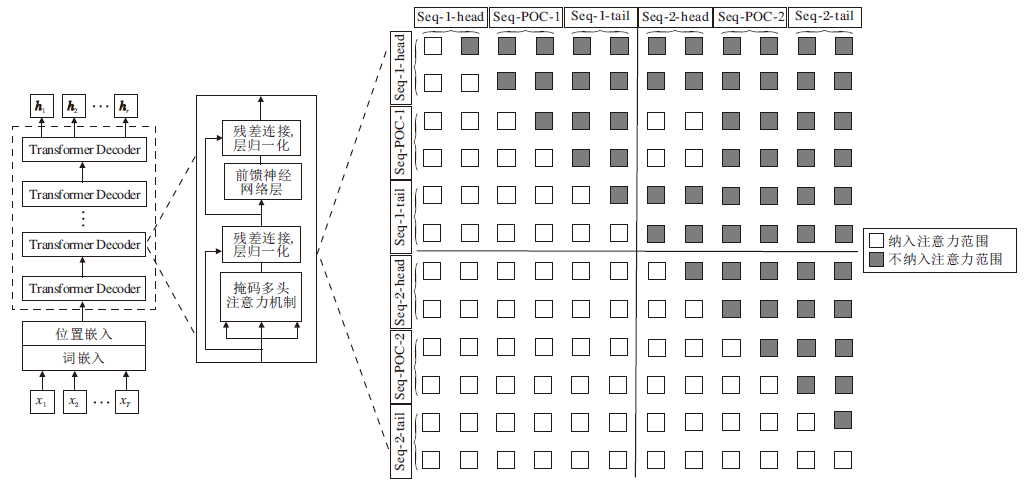 | 图4 本文方法的微调训练过程Fig.4 Training process of the proposed method with fine-tuning |
在单个文本
x=[x1, x2, …, xT]
输入到模型之前, 首先通过词向量和位置向量对其进行向量化, 得
H0=XWe+Wp=[
其中We表示初始化的词向量矩阵.输入文本通过词索引的方式从词向量矩阵中提取相应的词向量, 再和初始化的位置向量矩阵Wp进行按位相加操作, 得到H0.
本文模型由L=36层Transformer Decoder堆叠而成.模型输入可在第l层获得对应层的嵌入表示:
Hl=TransformerDecoder(Hl-1)=[
具体地, 对于模型的第l(1≤ l≤ L)层, 任意一个注意力头的输出为:
Al=softmax(
其中,
Ql=Hl-1
Mi, j=
在上述运算中, 模型上一层的输出Hl-1∈
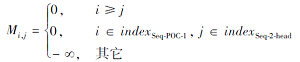
其中, indexSeq-POC-1和indexSeq-2-head分别表示Seq-POC-1及Seq-2-head的位置索引组成的集合.设计特殊的掩码矩阵Mcohesion是为了让模型能更好地利用来自不同语句的同组PoC含有的文本信息, 其与正常Transformer Decoder结构的区别如图5所示.
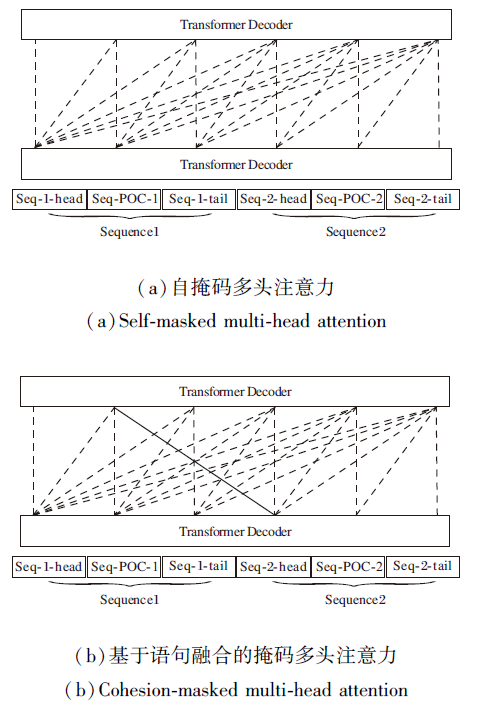 | 图5 基于语句融合的掩码多头注意力与自掩码多头注意力的区别Fig.5 Difference of cohesion-masked multi-head attention and self-masked multi-head attention |
本文实验首先在训练集上进行微调训练, 然后在测试集上进行评估.训练集包含107 000条样本, 样本中的PoC信息全部通过spaCy库中的指代消解方法标注.测试集为Labanoff等[24]标注的CNN/Daily Mail数据集(https://github.com/ucfnlp/sent-fusion-transformers), 包含1 494个人工标注的测试样本.
实验中采用的评价指标分为两类:1)传统的基于词语共现频率统计的生成文本评价指标ROUGE[25]、BLEU(Bilingual Evaluation Understudy)[44]; 2)基于BERT进行语义相似度衡量的生成文本评价指标BERTScore[45].
本文模型是由36层Transformer Decoder堆叠而成, 本文采用Wolf等[46]提供的开源模型GPT2-large(https://huggingface.co/gpt2-large)进行参数初始化.每个自注意力层由20个注意力头构成, Transformer Decoder的隐层维度为1 280, 模型的最长输入序列长度为1 024.在训练过程中, 选择Adam(Adaptive Moment Estimation)作为优化器, 采用带有总训练步数15%比例热身策略及线性衰减的学习率动态调整方式.在模型的前馈传播中, 采用概率为10%失活参数的失活机制抑制模型过度拟合.
为了验证本文模型在文本自动摘要任务上的有效性, 实验中选择多个具有代表性的基准模型进行对比.
1)Pointer-Generator Networks[6].采用一个由循环神经网络组成的encoder-decoder结构, 将输入语句压缩成一个向量表示, 然后再将其解码成需要输出的融合语句.
2)UNILM(Unified Pre-trained Language Model)[47].
采用与BERT基本一致的模型框架, 但训练方式不同.通过联合训练单向、双向及Seq2Seq三种不同的语言模型得到UNILM, 旨在使模型可同时应用于NLU和NLG任务.
3)GPT-2[31].本文模型在结构方面与GPT-2基本一致, 因此将GPT-2作为基准模型之一.在具体实验中, 直接采用经过预训练的模型进行文本输出.
4)TRANS-LINKING[26].模型结构同样是堆叠的多层Transformer, 不同之处在于其使用特殊标记对输入文本的PoC内容的界限进行标注, 然后直接将经过标记的数据放入模型中进行训练.
5)TRANS-SHARERPER[26].模型结构与TRANS-LINKING类似.受文献[48]的启发, 单独使用一个注意力头捕捉属于同组PoC的文本信息, 并且该PoC包含的所有文本内容在这个注意力头中共享同一组语义表示.
6)Concat-Baseline.借鉴文献[26]的做法, 在一般的基准模型外添加一个Concat-Baseline, 该基准不包含具体模型, 而是直接将包含PoC的两个或多个句子拼接后作为生成文本并输出.
除本文模型以外, 为与已有的最优性能模型TRANS-LINKING和TRANS-SHARERPER进行对比, 实验中还设计一个参数缩减版的本文模型, 该模型由24个Transformer Decoder层堆叠而成, 模型参数采用经过预训练的GPT-2-medium进行初始化.该模型与TRANS-LINKING和TRANS-SHARERPER拥有同样大小的参数量, 从而能更直观地体现模型结构带来的性能提升.上述对比模型全部统一在自动标注的PoC训练集上进行训练, 之后在有人工PoC标注的测试集上进行最终评估.
各模型在测试集上的指标值如表1所示, 表中黑体数字表示最优值.为了分别检验模型中两阶段训练任务的有效性, 本文在对比实验外还进行模型的消融研究.具体来讲, 在本文模型上, 分别只采用第一阶段的自监督训练及第二阶段基于语句融合信息的注意力掩码策略进行训练, 并将得到的模型在测试集上进行评估.
| 表1 多种文本生成模型在测试集上的实验结果 Table 1 Experimental results various text generation models on test set |
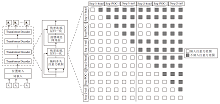
为了直观展现模型在进行文本生成时的内部状态, 实验中还借助热力图对模型内的注意力矩阵进行可视化.
普通的Transformer深度模型和本文模型对同段输入文本的信息捕获情况如图6所示.具体来讲, 两幅图都随机取自模型的任意一层的任意一个注意力头, 并通过热力图的形式将该注意力矩阵进行可视化.由图6可见, 输入文本是总共包含40个单词的2个语句, 这两句话以第13个索引进行分隔.在输入的文本中包含一组PoC, 分别位于索引4~7的第1句和索引22~24的第2句中.由(a)可看出, 基于Transformer的模型并未针对PoC进行特定的关注, 而在(b)中可发现, 模型在处理第1句PoC部分内容时额外关注第2句PoC信息之前的文本内容, 因此能融入更多的语义信息, 这也解释本文模型能获得优异性能表现的原因.
 | 图6 2个模型中某一注意力头的注意力矩阵参数可视化Fig.6 Parameter visualization of attention matrix of an attention head in 2 models |
本文提出基于语句融合和自监督训练的文本自动摘要模型.该模型以Transformer Decoder为基本结构, 设计自监督和有监督的两阶段训练任务, 使模型在公开的文本自动摘要数据集上取得较优性能.本文模型在训练过程中充分利用数据集上的PoC标注, 根据PoC信息在排列语言模型的训练过程及模型在文本生成阶段的信息摄入程度进行针对处理, 以求在生成摘要文本的过程中尽量采用语句融合技术而非对冗余重复信息的简单去除, 进一步增强生成摘要的概括性和流畅性.基于多个公开评测指标的评估结果及模型在应用过程中部分参数的可视化结果都验证本文模型的有效性.
然而, 本文的工作也存在如下两点问题:1)虽然针对文本生成过程中的语句融合进行针对性的模型结构修改, 但从实验结果上看, 取得的效果并没有预期的明显, 尤其是在屏蔽模型参数量提升带来的影响之后.2)实验数据来自对CNN/Daily Mail数据集进行特定人工标注的公开数据集, 由于涉及到文本的语义融合现象较复杂, 标注成本较高, 而该公开数据集的总数据量相对较小, 因此本文模型还需更大、更有针对性的数据集进行更进一步的验证和分析, 这也是下一步的研究方向.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|
| [42] |
|
| [43] |
|
| [44] |
|
| [45] |
|
| [46] |
|
| [47] |
|
| [48] |
|