
{kind=link}
{kind=link}
{kind=link}
{kind=link}
自监督聚类重训练的语音表示学习
引用本文
张文林, 刘雪鹏, 牛铜, 杨绪魁, 屈丹. 自监督聚类重训练的语音表示学习. 模式识别与人工智能, 2022,35(5): 461-471
ZHANG Wenlin, LIU Xuepeng, NIU Tong, YANG Xukui, QU Dan. Clustering and Retraining Based Self-Supervised Speech Representation Learning Method. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2022,35(5): 461-471.
Doi: 10.16451/j.cnki.issn1003-6059.202205007
ZHANG Wenlin, LIU Xuepeng, NIU Tong, YANG Xukui, QU Dan. Clustering and Retraining Based Self-Supervised Speech Representation Learning Method. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2022,35(5): 461-471.
Permissions
Copyright©2022, 《模式识别与人工智能》编辑部
《模式识别与人工智能》编辑部
自监督聚类重训练的语音表示学习

张文林,博士,副教授,主要研究方向为语音信号处理、语音识别、机器学习等.E-mail:zwlin_2004@163.com.
作者简介: 
刘雪鹏,硕士研究生,主要研究方向为智能信息处理、无监督学习、语音表示学习.E-mail:liuxp1996@163.com. 
牛 铜,博士,副教授,主要研究方向为语音识别、深度学习等.E-mail:jerry_newton@sina.com. 
杨绪魁,博士,讲师,主要研究方向为语种识别、连续语音识别、机器学习等.E-mail:gzyangxk@163.com. 
屈 丹,博士,教授、主要研究方向为机器学习、深度学习、语音识别等.E-mail:qudanqudan@163.com.
摘要
现有的基于重建的自监督预训练方法往往通过对语音帧的还原重建进行训练,未充分利用语音帧包含的音素信息.因此,文中结合自监督学习方法与噪声学生训练,提出基于自监督聚类重训练的语音表示学习方法.基于一个初始的语音表示模型(教师模型),利用无监督聚类得到音素类别伪标签.结合伪标签预测任务与重构任务,重新训练表示模型(学生模型).将学生模型作为新的教师模型,借助聚类与重训练,不断优化伪标签与语音表示模型.对比实验表明,经过聚类重训练后,语音表示模型在音素识别和说话人识别两项下游任务上均优于聚类重训练前的模型,性能较优.
关键词:
无监督学习; 自监督学习; 语音表示; 预训练模型; 掩蔽重建; 噪声学生训练
中图分类号:TP912.34
Clustering and Retraining Based Self-Supervised Speech Representation Learning Method
ZHANG Wenlin, Ph.D., associate professor. His research in-terests include speech signal processing, speech recognition and machine learning.
About Author:
LIU Xuepeng, master student. His research interests include intelligent information processing, unsupervised learning and speech representation learning.
NIU Tong, Ph.D., associate professor. His research interests include speech recognition and deep learning.
YANG Xukui, Ph.D., lecturer. His research interests include language identification, continuous speech recognition and machine learning.
QU Dan, Ph.D., professor. Her research interests include machine learning, deep lear-ning and speech recognition.
Abstract
The existing self-supervised speech representation learning methods based on reconstruction are trained by restoring and rebuilding speech frames. However, the phoneme category information contained in the speech frame is underutilized. Combining self-supervised learning and noisy student training, a clustering and retraining based self-supervised speech representation learning method is proposed. Firstly, based on an initial self-supervised speech representation model (the teacher model),the pseudo-label reflecting the phoneme class information is obtained via unsupervised clustering. Secondly, the pseudo-label prediction task and the original masked frame reconstruction task are combined to retrain the speech representation model(the student model). Finally, the new student model is taken as the new teacher model to optimize pseudo-labels and representation models continually by iterating the whole clustering and retraining processes. Experimental results show that the speech representation model after clustering and retraining achieves better performance in downstream phoneme recognition and speaker recognition tasks.
Key words:
Unsupervised Learning; Self-Supervised Learning; Speech Representation; Pretrained Model; Mask Reconstruction; Noisy Student Training
本文责任编委 杨 明
Recommended by Associate Editor YANG Ming
语音表示学习的目的是从语音信号中提取特征, 并使用学习到的向量表示语音信号.一个好的语音表示应当包含语音信号中各种不同层次的信息, 如音素或类音素、说话人信息、词语、语种等, 以便于将语音表示用于后续的连续语音识别、说话人识别、语种识别等下游任务中[1].从语音信号中提取语音表示, 能有效降低下游任务的学习难度, 减少其对标注数据量的要求.
目前人类使用的语言有近7 000种, 很多语言的语音数据十分匮乏, 缺少语言学专家知识, 甚至没有文字系统.对这些小语种语言构建语音识别系统, 往往需要依赖代价极大的语音数据收集及人工标注工作.为了解决这一问题, 学者们转向使用“ 无监督预训练+微调” 的方法构建小语种语音识别系统.首先在大量无标注的语音数据上学习一个好的语音表示模型, 然后利用少量的标注数据对下游任务进行微调, 得到与大量标注数据直接训练性能相当的系统, 其中第一阶段的预训练过程涉及无监督的语音表示学习技术.相比有监督学习方法, 无监督的语音表示学习方法最大优势在于可利用大量的无标注语音数据, 甚至是多语言数据.在如今的大数据时代, 获取无标注数据相对容易.
自监督学习是无监督学习的一个分支, 基本思想是通过构造辅助任务, 从无监督数据自身构造监督信息进行训练, 从而学习对下游任务有价值的表示.近年来, 自监督语音表示学习取得一定进展, 已成为智能语音处理领域热门的研究方向之一, 语音自监督表示学习方法主要通过掩蔽语音帧重建或前后帧对比预测等预训练任务进行学习, 模型提取的语音表示能在说话人识别、音素分类、自动语音识别(Automatic Speech Recognition, ASR)、情感分类等多种下游任务中, 取得与有监督方法相当的结果.
目前, 语音的自监督表示学习方法主要有基于对比损失的表示学习方法和基于重建的表示学习方法两类.
基于对比损失的表示学习方法是对比预测编码(Contrastive Predictive Coding, CPC)[2].通过当前帧预测邻近的几帧, 同时对比来自其它序列的帧或来自更遥远时间的帧, 使时间上距离相近的表示被拉得更近, 时间上距离较远的表示被推得更远.典型方法是wav2vec系列模型.Schneider等[3]首次提出wav2vec, 将CPC损失直接用于语音表示学习.wav2vec是无监督预训练在具有完全卷积模型的语音识别中的首次应用, 并已在基于语音识别的下游任务中验证有效性.Baevski等[4]提出改进方法— — vq-wav2vec, 结合wav2vec与BERT(Bidirectional En-coder Representations from Transformers)[5], 并使用矢量量化对提取的表示进行量化, 可学习离散的语音表示.更进一步地, Baevski等[6]提出wav2vec 2.0, 基于vq-wav2vec的思路, 结合掩码语言模型(Masked Language Model)[5]训练具有上下文表示的离散语音单元.目前, wav2vec 2.0是低资源语音识别领域中使用最广泛的语音预训练方法之一, 具有良好的跨语言特性[7], 并可与自训练等方法结合, 实现基于少量标注语料的半监督语音识别[8].
基于重建的表示学习方法利用部分语音帧对其它语音帧进行还原重建, 根据最小化重建损失得到语音表示.这类方法的典型方法有自回归预测编码(Autoregressive Predictive Coding, APC)[9, 10]和BERT式掩蔽重构[5]等.APC采用自回归模型对声音序列进行编码, 根据当前帧对未来帧进行预测重建.BERT式掩蔽重构基于掩蔽语言模型, 根据未掩蔽语音帧的编码重构掩蔽的语音帧, 学习得到较好的语音表示.
近年来, 借鉴自然语言处理领域中的BERT等预训练模型, 在语音处理领域也涌现很多基于BERT式掩蔽重构的语音表示学习方法.Liu等[11]提出Mockingjay, 使用掩蔽声学模型(Masked Acoustic Model, MAM)任务对模型进行训练.Mockingjay中的掩蔽声学模型仅对语音帧进行时间维度上的掩蔽.Liu等[12]在文献[11]的基础上提出TERA (Trans-former Encoder Representations from Alteration), 将语音帧的掩蔽扩展到时间、通道和幅度三个维度, 使学习的语音表示能包含更多的信息.Chi等[13]将ALBERT(A Lite BERT)[14]参数共享的思想引入语音表示网络的构建, 提出AALBERT(Audio ALBERT), 在保证模型性能的同时有效减少模型参数.
本文主要讨论基于无标注数据的语音表示学习方法.事实上, 在无监督数据的利用方面, 噪声学生训练(Noisy Student Training)[15]是一种目前常用的方法, 基本思想是迭代自训练, 即首先使用少量有标注数据训练得到初始教师模型, 利用教师模型生成无标注数据的伪标注, 然后利用伪标注数据和标注数据联合训练学生模型.在训练学生模型过程中, 为了提高表示的稳健性, 对输入的语音数据进行随机扰动[16, 17, 18].噪声学生训练基本出发点是对于一个好的表示模型, 扰动后语音得到的表示应与扰动前语音得到的表示一致.Park等[19]将噪声学生训练方法用于半监督语音识别, 取得不错效果.Xu等[8]证明基于教师-学生训练的自训练方法与基于wav2vec 2.0的自监督预训练方法在下游语音识别任务上具有互补性, 两者结合可进一步提高半监督语音识别的效果.然而, 原始的噪声学生训练方法是一种半监督学习方法, 仍需少量的标注语料以训练初始的教师模型, 因此往往只用于下游任务的微调阶段, 在预训练阶段仍需要借助自监督方法学习语音表示.
现有的基于掩蔽重建的自监督语音表示学习方法对语音帧添加掩蔽, 最小化重建损失以训练模型.这些方法的共同缺点是未较好利用语音帧本身包含的音素类别信息.音素(Phoneme)是根据语音的自然属性划分的最小语音单位, 在对输入语音进行分帧处理的过程中, 一帧通常为25 ms或10 ms, 对于同个音素分割产生的语音帧, 从发音的角度上看, 应属于一类.这种隐藏的类别信息并未直接利用在现有的无监督预训练方法中.
因此, 本文提出基于自监督聚类重训练的语音表示学习方法, 在现有的基于掩蔽重建的自监督方法的基础上, 构造伪音素标签以引入音素类别预测任务, 较好地利用语音数据中隐藏的音素类别信息.具体思路是:基于当前的预训练语音表示模型, 通过无监督聚类的方法构造语音表示单元的音素类别标签, 结合重建任务与音素类别标签预测任务, 更新语音表示模型.在模型更新过程中, 借鉴噪声学生训练方法的思想, 对输入语音信号进行随机噪声扰动, 得到较稳健的语音表示.基于多个数据集上的音素识别、说话人识别等下游任务测试表明, 本文方法达到与现有模型相当甚至更优的性能, 同时模型训练和推理所需的计算资源和时间较少.
1 自监督聚类重训练的语音表示学习方法
1.1 聚类-重训练基本框架
无监督语音表示任务的关键在于如何有效利用无标注语音数据得到包含其主要信息的高层表示.针对这一问题, 基于重建损失的语音表示学习方法认为一个好的语音表示应可较好重建原始的语音信号.因此, 利用自编码器的思想, 通过一个编码器得到语音表示, 通过一个解码器根据语音表示重构原始语音信号, 进而通过最小化重构信号和原始信号之间的误差(称为重构误差)优化语音表示模型.在重建任务训练过程中, 现有方法未利用语音的音素类别信息.
而在基于噪声学生训练的半监督语音识别中, 使用另一种有效的无标注数据利用方法, 即将无标注数据对应的标注视为隐藏变量, 通过一个类似于EM算法(Expectation-Maximization Algorithm)的迭代过程优化声学模型的参数, 具体做法如下.
1)使用标注数据训练一个初始模型, 作为教师模型.
2)通过教师模型对无标注的数据进行识别, 将识别结果视为伪标注(类似于EM算法中的E步).
3)对于无标注数据, 将伪标注视为正确标签, 结合标注数据, 通过最小化标签预测任务的交叉熵损失函数更新模型参数, 得到学生模型(类似于EM算法中的M步).
4)将新的学生模型作为教师模型, 重复1)、2), 得到不断精确的伪标注(类别信息)和识别模型.
在上述过程中, 基于一致性准则, 通过对输入信号添加随机噪声扰动以提高学生模型的鲁棒性.
受到上述噪声学生训练方法的启发, 为了在无监督表示学习过程中充分利用语音帧自身隐含的类别信息, 本文结合语音重建任务和伪标签预测任务, 提出聚类-重训练框架.基本思想是:基于现有表示模型(教师模型), 利用无监督聚类得到隐含的语音帧类别信息, 进而基于该类别信息构造标签预测任务, 结合已有的基于重建损失的表示学习任务, 重训语音表示模型(学生模型).将上述过程不断迭代以得到最优表示模型.下面将利用EM算法框架从理论上证明方法的有效性.
令x为某一帧语音信号, y为其音素类别标签, 对于无标注语音数据, x为观测变量, y为隐藏变量, 采用EM算法估计语音表示模型的参数θ .根据EM算法原理, 在第k次迭代中E步在给定当前模型的参数θ (k-1)的条件下, 估计隐藏变量的最大后验概率, 即计算
q(y|x; θ (k-1))=p(y|x; θ (k-1)).
在M步最大化观测变量与隐藏变量联合概率的对数期望值, 即优化目标函数
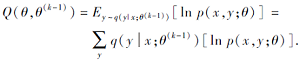
最大化上述目标函数相当于最小化
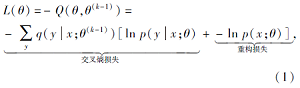
其中后验概率p(y|x; θ )表示对应音素分类任务的输出.将q(y|x; θ (k-1))视为类别软标签, 式(1)右侧第1项相当于音素分类预测问题的交叉熵损失函数.在本文的聚类-重训练框架中, 将当前模型(参数为θ (k-1))视为教师模型, 利用教师模型的输出和聚类算法得到概率分布q(y|x; θ (k-1))的近似值, 即
q(y=i|x; θ (k-1))=
其中, Enc(x)表示语音信号x对应的编码表示, Ci表示聚类结果中的第i个类别.上述近似值本质上就是将聚类结果作为硬标签的独热编码.
利用自编码器对语音信号的概率分布p(x; θ )进行建模.令Enc为编码器网络, Dec为解码器网络, 假设给定编码表示Enc(x)的条件下, x服从均值为Dec(Enc(x))、方差为σ 2I的高斯分布, 则式(1)右侧第2项可写为
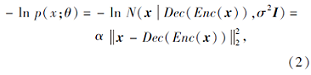
其中, N表示高斯分布, α 表示与方差σ 2I相关的常数.
式(2)对应L2重构损失函数.将上述高斯分布替换为拉普拉斯分布, 即得到L1重构损失函数.
综上所述, 最小化目标函数式(1)的第1项对应标签预测任务的交叉熵损失函数, 第2项对应重构任务的重构损失函数, 结合二者求解学生模型的参数θ , 本质上是在给定当前教师模型参数θ (k-1)的条件下执行EM算法中的M步, 对模型参数进行更新, 得到新的参数θ =θ (k).这也就从理论上证明本文方法的有效性.
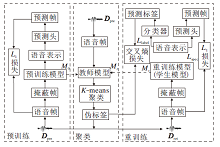
上述聚类-重训练框架的基本流程如图1所示.
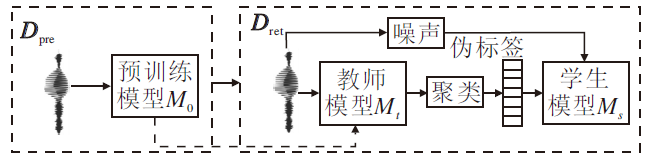 | 图1 聚类-重训练框架流程图Fig.1 Flow chart of clustering-retraining framework |
对于无标注数据集
Dpre={x1, x2, …, xn},
其中xi表示第i条语音数据, 由mi帧组成, 将其第j帧记为xi, j, 则
xi=[xi, 1, xi, 2, …,
首先训练得到预训练模型M0后, 以预训练模型M0作为教师模型Mt, 执行如下步骤.
1)利用教师模型, 提取数据Dpre中各语音帧对应的语音表示, 使用K-means算法对语音表示进行聚类.
2)使用聚类分配的类别标签构造伪标签集合
Y={y1, y2, …, yn},
其中yi表示第i条语音数据对应的伪标签序列, 将其中第j帧的伪标签记为yi, j, 则
yi=[yi, 1, yi, 2, …,
3)使用无标注数据和伪标签构造新的数据集Dret, Dret中每条语音信号的标签由其语音帧对应的伪标签序列组成, 记为
Dret={(x1, y1), (x2, y2), …, (xn, yn)}.
4)在数据集Dret上, 结合伪标签预测任务和已有自监督学习中的重建任务(如CPC、APC等)重新训练学生模型Ms.
5)将学生模型Ms作为新的教师模型, 重复1)~4)进行迭代训练.
1.2 自监督聚类重训练的语音表示方法步骤
基于聚类-重训练框架, 本文针对TERA[13]进行聚类重训练, 提出自监督聚类重训练的语音表示方法.使用TERA预训练方法得到初始的预训练模型.
TERA对于输入的连续语音帧, 在时间、通道和幅度三个维度上进行掩蔽, 通过最小化原始语音帧的重构损失进行模型训练.在时间维度上, 随机选定15%的语音帧进行掩蔽, 在被掩蔽的语音帧中, 80%的语音帧全部置为0, 10%的语音帧被替换为随机帧, 剩下10%的语音帧保持不变.在通道维度上, 对于整个输入语音序列, 将选中的连续通道块的值随机替换为0.在幅度维度上, 对选定的语音帧添加随机采样的高斯噪声(Sampled Gaussian Noise).
得到初始的教师模型后, 使用聚类-重训练框架, 迭代训练得到学生模型.在学生模型的训练过程中, 对于语音帧类别预测任务和语音重建任务, 均采用TERA中的三维度掩蔽策略对输入的语音进行随机扰动, 增强学生模型的鲁棒性.
本文方法框图如图2所示, 分为预训练、聚类和重训练三阶段.首先在预训练阶段, 对无标注训练集Dpre中的语音数据进行随机掩蔽, 并按照TERA预训练方法得到初始教师模型.在聚类阶段, 使用教师模型对Dpre中的语音数据提取语音表示, 利用K-means聚类模块对其进行聚类并分配伪标签.在重训练阶段, 利用无标注数据集Dpre及其伪标签构建新的伪标注数据集Dret, 在重训练部分训练得到学生模型.
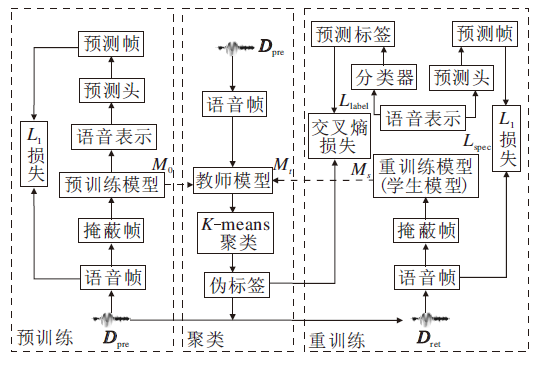 | 图2 本文方法框图Fig.2 Framework of the proposed method |
在具体的重训练过程中, 对语音帧使用与预训练部分相同的掩蔽策略, 将学生模型提取的语音表示分别送入一个分类器网络和预测头网络, 分类器网络用于预测输出语音帧的类别标签, 预测头网络用于重建被掩蔽的语音帧.通过最小化类别预测损失与重建损失的加权和更新学生模型, 并将其作为新的教师模型重复进行聚类和重训练过程.
对于语音帧类别标签预测任务, 使用单层线性网络作为分类器, 使用交叉熵损失作为预测标签与聚类得到的伪标签之间的距离度量.对于第i条语音的第j个语音帧, 将分类器输出的音素类别概率记为${{\hat{y}}_{i, j}}$, 则该帧的标签预测损失
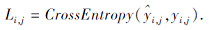
将总的伪标签预测损失记为Llabel, 则
Llabel=
对于语音帧重建任务, 与TERA类似, 使用重建语音帧$\hat{x}$与原始语音帧x的频谱间的L1距离衡量语音帧的重建效果, 即
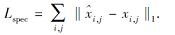
最终聚类重训练的总损失函数:
Lret=Lspec+λ Llabel, (3)
其中, λ 为标签预测损失的权重因子, 实验中设为0.1.
综上所述, 本文提出的自监督聚类重训练的语音表示学习方法具体步骤如下.
算法 自监督聚类重训练的语音表示学习方法
step 1 使用无标注数据集Dpre, 基于TERA预训练方法对语音帧进行掩蔽, 并根据L1损失训练得到初始表示模型M0, 令教师模型Mt=M0.
step 2 将数据集Dpre送入Mt, 提取语音信号对应的语音表示.
step 3 将语音表示作为K-means算法的输入, 利用聚类得到伪标签集合Y.
step 4 使用Dpre和Y构建新的训练数据集Dret.
step 5 使用数据集Dret, 基于式(3)中的多任务损失函数Lret对学生模型Ms进行多任务训练.
step 6 令教师模型Mt=Ms, 返回step 2.
上述过程经过若干次迭代后, 将最终的学生模型作为语音表示模型.在工程实践中, 当学生模型在下游任务上的表现随迭代次数增加而保持不变或稳定时, 可认为模型已收敛.
2 实验及结果分析
2.1 实验设置
本文实验主要使用公开的LibriSpeech语料库[20]和TIMIT语料库[21].为了验证不同数据量下模型的性能, 分别使用LibriSpeech的100 h子集(train-clean-100)和960 h子集(train-clean-100、train-clean-360、train-other-500)对模型进行训练.实验使用mel谱作为预训练模型的输入.
实验中采用TERA作为基础的预训练模型和教师模型, 预训练模型的结构和参数与文献[12]中TERA设置相同.对于本文方法训练的学生模型, 结构和参数与其对应的教师模型保持一致.对于100 h训练数据条件, 将初始模型的预训练和每次聚类后重训练的训练步数均设置为2 000 000.对于960 h训练数据条件, 预训练和重训练的训练步数均设置为10 000 000.模型使用4个2080Ti GPU训练, 训练批次大小为8, 相当于约12 s的语音数据.
在得到教师语音表示模型后, 语音帧类别的聚类过程采用文献[22]中的K-means++算法.该算法选择有更高概率接近最终质心的初始质心, 避免经典的K-means算法中随机初始化的缺陷, 可快速收敛.实验中使用train-clean-100子集进行训练, 迭代次数为15次.
关于聚类类别数K的设置, 本文参考LibriSpeech中的音素个数设置及ZEROSPEECH无监督语音识别挑战赛中声学单元个数设置, 进行对比实验.具体来说, 根据文献[2]的实验设置, 在LibriSpeech数据集的train-clean-100子集上, 经过强制对齐后, 可能的音素个数为41, 其中包含静音音素silence(SIL)和口语噪声音素SPN, SPN包括噪声和集外词.实验中可将其作为先验知识, 并据此设置语音帧的类别数.根据ZEROSPEECH2021中无监督声学单元发现任务的基线系统设计, 当K=50时系统取得最佳性能, 因此本文也测试K=50的结果.
在聚类重训练过程中, 对学生模型进行多次迭代训练, 保留每次迭代训练后的模型, 分别在下游任务中进行实验, 以验证迭代训练的效果.
2.2 下游任务设置
为了验证语音表示模型的效果, 本文选择音素分类和说话人分类两种下游任务, 分别测试初始表示模型和不同迭代次数后改进的表示模型在下游任务中的识别准确率.两个下游任务的微调与测试均采用S3PRL工具箱进行.
音素分类任务的实验遵循文献[12]的设置, 并使用kaldi工具箱获得音素的强制对齐.实验在LibriSpeech数据集的train-clean-100子集上进行, 并根据文献[12]的实验设置, 将其划分为训练集和测试集.将表示模型得到的语音表示作为输入, 分别对比使用单个线性层的分类器网络和含一个非线性隐藏层的分类器网络的音素分类性能.
说话人识别任务的实验也在train-clean-100子集上进行, 同样参照文献[12]的实验设置, 对数据集进行划分.使用语音表示作为输入, 训练单层线性网络作为分类器, 分别测试模型在帧级别和句子级别的说话人分类准确率.
在上述两个下游任务的微调过程中, 语音表示模型的参数均被冻结, 只训练音素分类和说话人分类任务的分类器网络参数.下游模型的训练步数均设置为5 000 000.
2.3 实验结果
2.3.1 音素分类任务
各模型在音素分类任务上的实验结果如表1所示.表中TERA0表示采用原始TERA训练得到的初始表示模型, TERAi表示第i次聚类重训练后得到的改进的表示模型, TERAi- 41和TERAi- 50分别表示聚类时的类别数K=41, 50时得到的模型, 黑体数字表示最优值.
由表1可看出, 相比TERA训练得到的初始教师模型(TERA0), 经过聚类重训练得到的学生模型使音素分类的准确率有明显提升.在100 h训练条件下, 经过一次聚类重训练得到的学生模型TERA1-41在两种测试任务上的准确率比TERA0分别提升5.4%和1.7%.随着聚类重训练迭代次数增加, 所得学生模型的准确率进一步提高.在960 h训练条件下, 学生模型的表现与100 h条件下的表现有相同趋势.
在960 h训练条件下, 迭代3次后的结果不如迭代2次后的结果, 出现这一现象的原因可能是在训练数据充足条件下, 参数迭代2次已收敛, 而第3次迭代后出现过拟合.由于本文的初始教师模型采用TERA训练的模型, 可认为在迭代之初模型就已有一个不错的初值, 因此不需要迭代太多次即可接近收敛.
为了验证模型已达到收敛, 本文进一步增加聚类重训练的迭代次数, 并对第4、5次迭代后得到的学生模型进行测试.从实验结果可看到, 模型在多个下游任务中的测试结果基本稳定, 可判断模型已经收敛.
由表1中结果可看出, K=41时学生模型的整体性能优于K=50时.出现这种结果的原因可能是train-clean-100子集上共有41个不同的音素, 因此当聚类过程中K=41时, 模型能更好地适应数据特点.同时还注意到, 在960 h训练数据条件下, 由于数据量更大, 潜在的类别信息更丰富, 因此K=50时模型的准确率与K=41时的准确率相差不大.
由表1还可发现, 当分类器为单层线性网络时, 相比采用单层非线性网络的分类器, 聚类重训练后的模型性能提高更明显, 这一结果表明采用本文方法进行聚类重训练后, 通过音素分类任务的引入, 有效利用隐藏的音素类别信息, 使得到的语音表示更适合于下游的音素分类任务.
| 表1 各模型在音素分类任务上的准确率对比 Table 1 Accuracy comparison of different models for phoneme classification task % |
为了进一步验证本文方法在音素分类任务上的有效性, 进一步对使用960 h数据训练的第三代学生模型TERA3-41和TERA3-50在测试过程中进行微调, 分类器使用单层线性层.在微调过程中, 预训练模型与下游任务的分类器一起调整, 具体结果如表2所示.由表可见, 当仅微调1 000步时, 两个模型的分类准确率已达到83.6%和83.8%.微调5 000步时, 准确率进一步提升到86.8%和86.9%.而微调步数达到10 000步时, 模型性能提升明显减慢, 相比微调5 000步时仅提升约0.6%.
| 表2 2个模型在音素分类任务上微调后的准确率对比 Table 2 Accuracy comparison of 2 models after fine-tuning for phoneme classification task |
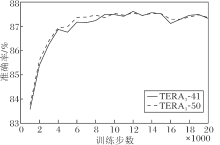
TERA3-41和TERA3-50训练前20 000步时, 准确率随训练步数的变化曲线如图3所示.由图可看出, 训练9 000步时, 两个模型的准确率已达到87.5%, 已收敛.这表明模型在使用标注数据进行微调时, 性能较优, 并能较快达到收敛.
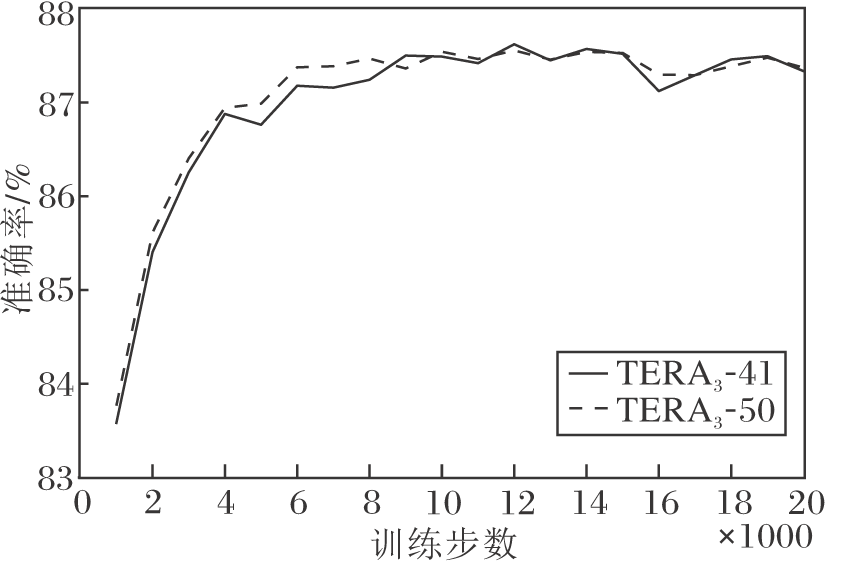 | 图3 2个模型在音素分类任务上微调后的准确率曲线Fig.3 Accuracy curves of 2 models after fine-tuning for phoneme classification task |
2.3.2 说话人识别下游任务
为了测试本文方法得到的语音表示能否保留除音素类别以外的信息, 进一步在说话人识别下游任务上测试模型性能.
选择帧级别和句子级别, 各模型在说话人识别任务上的实验结果如表3所示, 表中黑体数字表示最优值.由帧级别的说话人识别测试结果可看出, 在100 h训练数据条件下, K=41, 50时得到的说话人识别准确率较接近, 分别为99.4%(TERA1-50)和99.5%(TERA1-41), 相比初始的教师模型(TERA0), 提高0.6%.在960 h时训练数据条件下, 重训练后的说话人识别准确率与重训前的初始模型基本一致, 约为99.2%.
而从句子级别的说话人识别测试结果来看, 相比初始教师模型, 学生模型的性能并未得到明显提升.这一现象出现的原因可能是因为在聚类过程中, 训练数据按帧进行聚类, 因此学生模型倾向于更多地学习帧级别的语音信息.
此外, 在几轮迭代过程中, 学生模型在多次测试中基本保持性能不变.这是由于迭代过程中主要考虑语音帧的类别信息, 并没有针对说话人的信息进行专门的利用, 因此在聚类重训练迭代过程中, 模型在说话人识别任务中的性能得到保留, 并未随着迭代次数增加而明显提高.
| 表3 各模型在说话人识别任务上的准确率对比 Table 3 Accuracy comparison of different models for speaker recognition task % |
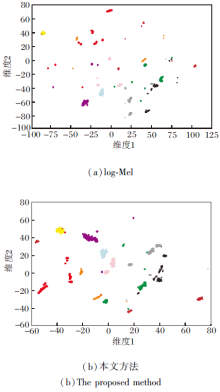
为了进一步评估本文方法对说话人信息的表示能力, 随机挑选10名说话人, 使用t分布随机邻域嵌入(t-Distributed Stochastic Neighbour Embedding, t-SNE)[24]对语音的频谱特征log-Mel谱和本文方法学习得到的语音表示进行可视化分析.
对于每条音频数据, 首先对其进行平均, 产生该句子的表示, 然后使用主成分分析(Principal Com-ponents Analysis, PCA)进行降维, 最后使用scikit-learn工具箱, 将t-SNE应用于降维之后的向量, 进行二维空间的可视化.结果如图4所示, 图中每种颜色和形状表示一位说话人.
由图4(a)可看出, 原始的log-Mel谱对说话人区分性很差, 不同说话人对应的向量都混杂在一起, 说明频谱特征并不能较好地表征说话人的信息.由(b)可看出, 相同说话人对应的语音表示聚集在同个数据簇中, 而不同说话人的语音表示明显对应不同的数据簇, 表明本文方法学习到的语音表示能较好地提取说话人信息.
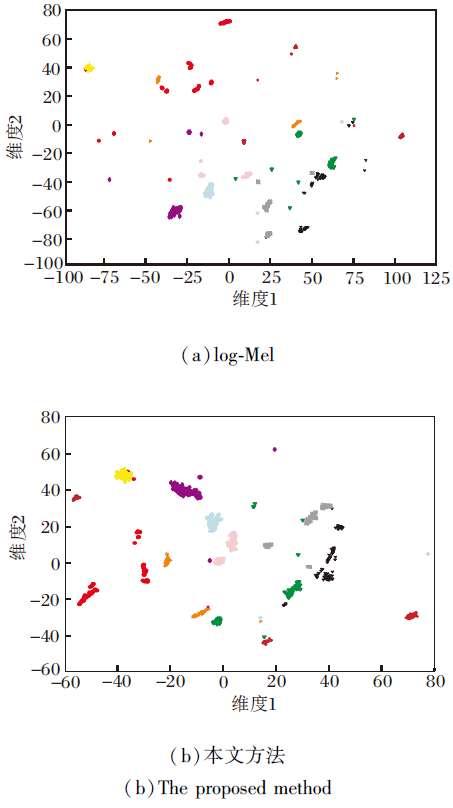 | 图4 2种方法对10名说话人的t-SNE可视化结果Fig.4 t-SNE visualization results of 2 methods for 10 speakers |
2.3.3 对比实验结果
首先, 为了研究K-means聚类类别数的影响, 在实验中进一步增加对不同类别数的测试.实验使用100 h训练数据对模型进行预训练, 将类别数K分别设置为42、45, 并使用初始的教师模型训练一代学生模型(TERA1-42、TERA1-45).在下游任务中, 音素分类分别在LibriSpeech数据集的train-clean-100子集和TIMIT数据集上进行测试, 使用单层线性网络作为分类器.说话人识别任务的设置与2.3.2节相同, K=41, 42, 45, 50时各模型在帧级别的准确率对比如表4所示.
| 表4 K不同时各模型的准确率对比 Table 4 Accuracy comparison of different models with different K % |
进一步, 选择如下对比方法:Mockingjay、AALB-ERT、TERA、wav2vec 2.0的Base版本(wav2vec 2.0-Base).同时, 还测试当K=500时的实验结果, 希望模型能通过聚类重训练过程, 学习更多细粒度的语音类别信息.此外, 考虑到教师模型和学生模型提取的语音表示包含的信息可能不会完全相同, 因此采用拼接和相加方式, 将教师模型与一次聚类重训练后学生模型提取的语音表示进行融合, 进一步测试融合后的语音表示性能.各模型的准确率对比如表5所示, 表中黑体数字表示最优值.
| 表5 各模型的准确率对比 Table 5 Accuracy comparison of different models % |
由表5可知, 使用100 h数据训练模型, 在说话人识别任务中, 当K=41, 50时, 不同方法性能接近, 相加和拼接的方法分别将准确率提升到99.6%和99.7%.在音素分类任务中, K=41时方法性能更优, TERA1-41(相加)在两个数据集上的准确率比TERA1-41均提升1%.TERA1-41(拼接)在两个音素识别任务上比TERA1-41分别提升4.5%和2.6%.相比预训练的TERA, TERA1-41(拼接)在音素识别任务中的准确率分别提升8.4%和7.4%, 且在所有任务中均达到最佳性能.
使用960 h数据训练的模型在K=50时的性能达到最佳, 在说话人识别任务中, TERA1-50(拼接)准确率达到99.6%.在两个数据集上的音素分类任务中, TERA1-50(拼接)的准确率分别达到74.2%和73.5%.相比wav2vec 2.0-Base, 在多种下游任务中, TERA1-50(拼接)性能达到或超过其水平.
本文方法与wav2vec2.0-Base的参数值对比如表6所示.在模型的训练过程中, 本文方法的训练批次大小为8, 相当于约12 s的语音数据, 仅使用4个2080Ti GPU训练, 训练一代学生模型需要约10天.而wav2vec2.0-Base在训练过程中使用64个V100 GPU, 训练需要1.6天, 总的训练批次大小为1.6 h的语音数据.即使在不考虑不同GPU性能的情况下, 本文方法使用单个GPU需要训练40天, wav2-vec2.0-Base相当于使用单个GPU, 需要训练约102天, 因此本文方法所需计算资源更少, 训练所需的总时间相对更短, 参数约为wav2vec 2.0-Base的1/4.此外, 在下游任务的微调和推理测试过程中, 相比wav2vec 2.0, 本文方法所需的时间大幅减少.以TIMIT数据集上的音素分类测试为例, 实验对比表明在训练相同步数时, 本文方法的训练时间约是wav2vec 2.0的1/4.
| 表6 本文方法和wav2vec 2.0-Base的参数值对比 Table 6 Parameter comparison of the proposed method and wav2vec 2.0-Base model |
2.3.4 消融实验结果
本节验证本文方法中将标签预测任务与重建任务结合的有效性.将仅使用标签预测任务训练的学生模型与仅使用重建任务、使用预测与重建任务结合训练(即本文方法)的学生模型在下游任务中的测试结果进行对比.实验中均使用100 h训练数据对模型进行预训练, 聚类重训练过程中的类别数均设置为41.在训练下游任务时, 语音表示模型的参数均被冻结, 实验设置与2.3.3节相同.
两种下游任务的实验结果如表7所示.
| 表7 本文方法中使用不同下游任务的准确率对比 Table 7 Accuracy comparison of the proposed method with different pretraining tasks % |
由表7可看出, 相比仅使用重建任务, 仅使用伪标签预测任务得到的语音表示模型在说话人识别和音素分类任务中的性能均有所下降, 特别是在说话人识别任务中性能下降更明显.这可能是由于标签预测任务更关注音素的类别信息, 对说话人信息不敏感, 从而使得到的语音表示中说话人信息有所损失.将两种任务结合进行训练后, 模型性能在两个下游任务中都得到提高, 表明标签预测任务和重建任务具有互补性, 由此表明本文方法的有效性.
3 结束语
本文在自监督语音表示学习过程中引入隐藏的语音帧类别信息, 借鉴噪声学生训练的思想, 构造类别标签预测任务, 提出基于自监督聚类重训练的语音表示学习方法.首先使用原始预训练模型作为教师模型, 提取语音信号的初始表示, 利用无监督聚类得到语音帧的类别信息, 进而结合类别预测任务和原始的语音重建任务, 对预训练模型进行重训练, 获得学生模型.在这一过程中, 引入噪声学生训练的思想, 对输入语音进行随机扰动, 增强语音表示的稳健性.基于TERA语音表示学习模型, 给出本文方法的具体实现过程.实验表明, 本文方法通过引入潜在的音素类别信息, 得到更好的语音表示模型.经过聚类重训练后, 所得模型在音素识别和说话人识别等下游任务上, 性能均得到一定提升.事实上, 本文方法具有通用性, 可与目前大部分的预训练方法结合, 提高现有语音表示模型的语义信息表达能力.预训练模型的性能会随着训练数据、训练时间的增加而得到提升, 今后会使用更大的语料库对模型进行训练, 并引入更多的下游任务, 验证本文模型的有效性.
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|