


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于时间卷积注意力神经网络的序列推荐模型
引用本文
杜永萍, 牛晋宇, 王陆霖, 闫瑞. 基于时间卷积注意力神经网络的序列推荐模型. 模式识别与人工智能, 2022,35(5): 472-480
DU Yongping, NIU Jinyu, WANG Lulin, YAN Rui. Sequential Recommendation Model Based on Temporal Convolution Attention Neural Network. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2022,35(5): 472-480.
Doi: 10.16451/j.cnki.issn1003-6059.202205008
DU Yongping, NIU Jinyu, WANG Lulin, YAN Rui. Sequential Recommendation Model Based on Temporal Convolution Attention Neural Network. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2022,35(5): 472-480.
Permissions
Copyright©2022, 《模式识别与人工智能》编辑部
《模式识别与人工智能》编辑部
基于时间卷积注意力神经网络的序列推荐模型

杜永萍,博士,教授,主要研究方向为信息检索、信息抽取、自然语言处理.E-mail:ypdu@bjut.edu.cn.
作者简介:

牛晋宇,硕士研究生,主要研究方向为推荐系统、知识蒸馏.E-mail:Niujinyu@emails.bjut.edu.cn. 
王陆霖,硕士,工程师,主要研究方向为智能信息处理、推荐系统.E-mail:linwang20448@163.com. 
闫 瑞,硕士研究生,主要研究方向为自然语言处理.E-mail:yanrui@emails.bjut.edu.cn.
摘要
序列推荐任务根据用户与项目的交互记录动态建模用户兴趣,并进行项目推荐.序列推荐模型通常将用户行为视为兴趣进行建模,仅考虑用户行为的顺序,忽略用户行为之间的时间间隔信息.文中将行为序列的时间间隔信息作为预测用户行为的重要因素,提出基于时间卷积注意力神经网络的序列推荐模型.在词嵌入层中引入序列位置信息和时间间隔信息,并设计时间卷积网络对位置信息进行建模,获取用户的长期偏好特征.使用双层自注意力机制对用户短期行为序列中项目之间的关联进行建模,并融合时间间隔信息获取用户短期兴趣特征.最后,通过预训练引入训练数据的全局信息,提升模型推荐性能.在Amazon等数据集上的实验表明,文中模型可有效提升推荐性能.
关键词:
序列推荐; 自注意力机制; 时间卷积网络; 长短期兴趣
中图分类号:TP391.1
Sequential Recommendation Model Based on Temporal Convolution Attention Neural Network
DU Yongping, Ph.D., professor. Her research interests include information retrieval, information extraction and natural language processing.
About Author:
NIU Jinyu, master student. His research interests include recommendation system and knowledge distillation.
WANG Lulin, master, engineer. His research interests include intelligent information processing and recommendation system.
YAN Rui, master student. His research interests include natural language processing.
Abstract
Sequential recommendation task aims to dynamically model user interests based on user-item interaction records for item recommendation. In sequential recommendation models, user behaviors are usually modeled as interests. The models only consider the order of user behaviors while ignoring the time interval information between users. In this paper, the time interval information of behavior sequences is taken as an important factor for prediction. A temporal convolution attention neural network model(TCAN) is proposed. In the word embedding layer, the sequential position information and time interval information are introduced, and a temporal convolutional network is designed to model the position information to obtain user's long-term preference features. In addition, the two-layer self-attention mechanism is adopted to model the association between items in the user's short-term behavior sequence, and the time interval information is fused to obtain the user's short-term interest. Finally, the global information of the training data is introduced through pre-training to improve the model recommendation performance. Experiments on three datasets show that the proposed model effectively improves recommendation performance.
Key words:
Sequential Recommendation; Self-Attention Mechanism; Temporal Convolution Network; Long and Short Term Interest
本文责任编委 林鸿飞
Recommended by Associate Editor LIN Hongfei
近年来, 推荐系统通过用户与项目交互的历史记录, 为用户提供个性化的推荐服务, 受到学术界和工业界的广泛关注.序列推荐根据用户与项目交互的历史记录构建用户行为序列, 获取用户的动态兴趣表示, 并以此为依据进行推荐.传统的序列推荐模型常采用矩阵分解[1]、马尔可夫链[2]等捕获用户兴趣偏好, 但仅考虑潜在因素的低阶交互, 存在无法处理长序列依赖关系等问题.
针对上述情况, Hidasi等[3]提出GRU4Rec, 采用循环神经网络(Recurrent Neural Network, RNN)对用户行为序列中项目间的依赖关系进行建模.Tang等[4]提出Caser(Convolutional Sequence Embe-dding Recommendation Model), 针对历史行为仅会单独影响下一个行为的问题, 将用户之前交互的N项项目的嵌入矩阵视为“ 图像” , 分别使用水平卷积核和垂直卷积核获取点级、联合级及跳跃行为的序列模式.但是, 基于RNN或卷积神经网络(Convolu-tional Neural Network, CNN)的方法不能捕获在会话内和跨会话中用户兴趣的层次性质, 此外, 基于CNN的方法具有较高的内存消耗.You等[5]提出HierTCN(Hierarchical Temporal Convolutional Net-works), 利用RNN获取用户的长期偏好特征, 并结合时间卷积网络模型, 预测下一次交互行为, 提高内存的使用效率及训练速度.针对基于RNN的方法只考虑会话的行为顺序, 无法解决序列中噪声造成的影响, Kang等[6]提出SASRec(Self-Attention Based Sequential Model), 采用自注意力机制, 在每个时间步中, 自适应地为历史行为中的项目分配权重, 并利用其进行预测.上述模型均具有从左到右单向学习的特点, 限制历史序列中项目的隐藏表示能力.
序列推荐的关键在于构建用户兴趣表示, 上述工作均仅对长期偏好或短期偏好进行建模, 无法充分刻画实际场景中的用户兴趣和行为.王鸿伟等[7]提出循环记忆网络(Recurrent Memory Network, RMN), 分别构建记忆读取和写入单元, 捕获用户短期兴趣波动和长期兴趣转移.冯永等[8]提出长短兴趣多神经网络混合动态推荐模型, 分别使用RNN和前馈神经网络(Feedforward Neural Network, FNN), 对用户短期兴趣和长期偏好进行建模, 通过模型融合进行动态推荐.阎世宏等[9]提出结合用户长期兴趣和短期兴趣的深度强化学习模型, 重新设计深度Q-网络框架, 将长短期兴趣表示应用在深度Q-网络中, 预测用户对项目的反馈.
上述模型虽然可较好地捕获序列模式的动态性, 但随着时间推移, 用户兴趣不断变化, 通常短时间内的两种行为的相关性强于长时间内的.在只考虑行为顺序位置的模型中, 这两种情况会被视为相同情况, 使模型存在一定的局限性.
为了引入时间因素, Wu等[10]提出RRN(Recur-rent Recommender Networks), 将绝对时间戳作为影响因素, 采用长短期记忆网络(Long Short-Term Me-mory, LSTM)构建自回归模型, 动态捕获用户和项目的表示, 但序列中噪声造成的影响仍存在.Liu等[11]提出短期注意/记忆优先模型, 能从会话上下文的长期记忆中获取用户的一般兴趣, 同时考虑用户最后一次点击的短期记忆, 获取当前兴趣, 但并未将时间信息引入模型进行训练.袁涛等[12]针对推荐项目对不同时间尺度兴趣的不确定性, 利用尺度维卷积, 对不同时间尺度的兴趣特征进行建模, 获取多尺度时间的用户兴趣特征.Li等[13]不仅考虑行为序列中项目的绝对位置, 进一步将时间间隔信息作为重要影响因子, 通过自注意力机制学习不同项目、绝对位置及时间间隔的权重, 并进行推荐, 但仍无法解决更细粒度的序列行为模式.
针对上述问题, Ji等[14]提出多跳时间感知的注意力记忆网络, 捕获长期偏好和短期偏好, 设计时间感知的门控循环单元(Gated Recurrent Unit, GRU), 学习短期意图.Zhou等[15]根据时间跨度较大时, 用户兴趣会发生漂移的现象, 构建图神经网络, 动态学习增强项目表示.Hsu等[16]提出关系时间注意力图神经网络, 构建关系注意力图神经网络, 学习关于用户、项目和属性之间的各种关系, 同时提出序列自注意力机制, 对用户的长期偏好和短期偏好时间模式进行编码.上述模型采用RNN或图神经网络(Graph Neural Network, GNN)捕获用户行为序列时间信息, 增加模型的时间复杂度和空间复杂度, 训练效率相对较低.
为了将时间间隔信息融入模型, 同时平衡长短期兴趣影响的程度, 本文提出基于时间卷积注意力神经网络的序列推荐模型(Sequential Recommen-dation Model Based on Temporal Convolution Attention Neural Network, TCAN), 采用长短期偏好融合方法, 将时间信息分别融入长期偏好和短期兴趣中, 并利用时间卷积网络和自注意力机制的并行性, 进一步提高模型性能和训练效率.
1 任务描述
在序列推荐任务中, 假设用户u的长期行为序列
基于长短期偏好融合序列推荐的目标是构建长期偏好和短期兴趣特征表示, 并添加相关辅助信息, 融合三者的特征嵌入表示向量以预测用户下一个可能交互的项目
2 基于时间卷积注意力神经网络的序列推荐模型
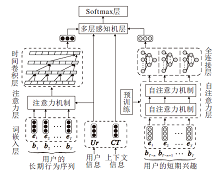
本文提出基于时间卷积注意力神经网络的序列推荐模型(TCAN), 结构如图1所示.
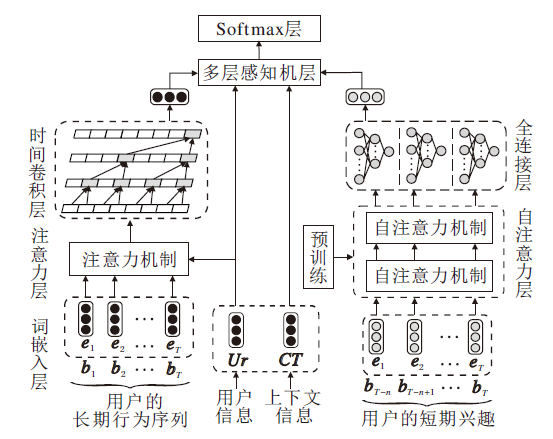 | 图1 TCAN结构图Fig.1 Structure of TCAN |
TCAN分别对长/短期行为序列进行建模.词嵌入层采用Item2vec词向量表示方法, 并引入位置编码信息及时间间隔信息作为辅助.时间卷积层采用扩张卷积并行提取用户行为特征, 在提高模型训练效率的前提下, 降低内存消耗.自注意力层并行计算用户行为之间的注意力权重, 提高模型训练的效率, 使模型更关注用户行为之间的关联.全连接层将自注意力层聚合后的线性特征表示转换为非线性特征表示, 考虑不同潜在维度的相互作用.多层感知机层和Softmax层融合所有用户相关特征, 获取最终用户特征表示, 实现序列推荐.
2.1 嵌入层
本文采用Item2vec词向量方法, 将用户行为序列的项目从独热编码形式转换为词嵌入向量:
Bu=[
其中, T表示用户u行为序列的长度, de表示词向量的维度大小.由于模型中未使用类似于RNN处理序列型信息的步骤, 在嵌入层中, 采用位置编码方法[17]丰富嵌入向量的信息表示.将用户行为序列Bu中每个项目
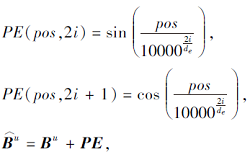
其中, pos为项目在行为序列中的位置, i∈ [0,
在序列推荐任务中, 时间间隔信息通常是会被忽略的影响因子, 但用户行为的周期性模式是用户行为模式的一种关键结构.本文采用个性化时间间隔编码方法[13], 通过时间序列Tu=[
最后, 构成用户时间间隔矩阵:
在构成时间间隔矩阵后, 本文采用文献[18]方法设定时间间隔最大值k(Mu中大于k值的元素均设置为k), 并且构建2个可学习的时间信息嵌入矩阵PK∈
2.2 基于时间卷积网络的用户长期偏好建模
TCAN引入注意力机制, 计算用户行为序列中的元素与用户信息相关程度, 增强相关信息的影响程度, 同时有利于时间卷积网络发现和建模用户长期行为中的周期性行为模式.
将用户长期行为序列嵌入
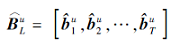
输入注意力层, 注意力单元会通过一个隐藏层的前馈网络计算用户行为$\hat{b}_{t}^{u}$与用户信息嵌入向量Ur∈
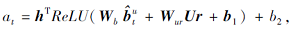
其中, Wb∈
使用Softmax对注意力得分进行归一化处理, 得到每个用户行为$\hat{b}_{t}^{u}$的注意力权重:
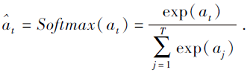
将用户行为与其对应的注意力权重相乘, 得到注意力层的输出$e_{t}^{u}=\hat{b}_{t}^{u}{{\hat{a}}_{t}}$.经过注意力机制增强后的用户长期行为序列
在时间卷积层中, 利用扩张因果卷积对用户长期行为序列进行建模, 改变扩张系数大小, 增强其行为特征的感受野, 使时间卷积网络能以较小的参数构建长期记忆.时间卷积网络的卷积核定义为
f=[w0, …, wk, …, wK-1]∈
使用eu表示用户u行为序列
F(
其中, K为卷积核大小, d∈ [1, 2, 4, …, 2n]为时间卷积网络的扩张系数, ReLU为激活函数.
为了缓解多层卷积层叠加导致的梯度消失问题, 在卷积层使用残差结构, 对于第m层时间卷积网络应用残差模块, 得到输出
Hm(
其中,
时间卷积网络最后一层M的输出HM(
2.3 基于自注意力机制的用户短期兴趣建模
除了用户的长期偏好以外, 模型能否正确建模用户短期行为的演变过程也十分关键.短期行为模式通常是用户的连续性购买行为, 行为之间一般都具有重要关联.TCAN采用自注意力机制, 不同于计算序列所有元素之间的注意力权重, 根据用户行为的时序性, 每个用户行为只计算与其前项行为之间的注意力权重.全连接层将加权聚合的线性用户特征表示转换成非线性用户特征表示, 挖掘潜在维度之间的相互作用.自注意力层结构如图2所示.
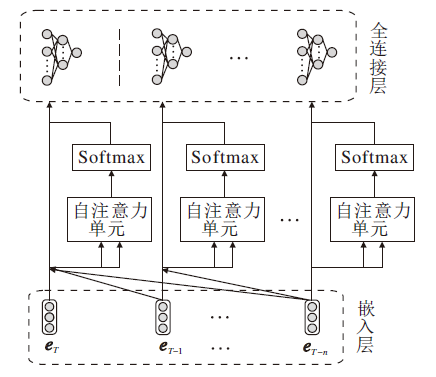 | 图2 自注意力层结构Fig.2 Structure of self-attention layer |
由于查询语句和序列信息维度相同, TCAN采用Self-Attention机制中的缩放点积(Scaled-dot Product), 构造自注意力机制中的注意力单元.基于缩放点积的注意力机制的定义为
Attention(Q, K, V)=softmax(
其中, Q为查询语句, K为序列数据, V为内容信息,
TCAN采用Self-Attention机制将嵌入的用户短期行为序列
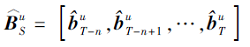
作为输入, 通过线性变换将
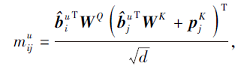
其中, WQ∈
计算项目间的自注意力权重:
最后, 融入时间间隔信息的用户短期行为序列
将输入短期行为序列的项目嵌入向量和时间间隔嵌入向量与自注意力权重进行加权求和, 得
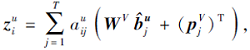
其中, WV∈
为了使自注意力层能考虑不同潜在维度之间的相互作用, TCAN采用双层注意力机制.在Self-Attention层上连接一个多层感知机, 捕获用户短期行为序列模式:
S1=
其中:WZ∈
基于自注意力的短期行为建模的输出
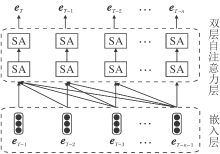
自注意力机制模型结构复杂, 参数量较大, 无法单独对整体模型的端到端进行训练, 限制模型性能.因此在自注意力层中加入预训练过程, 结构如图3所示.
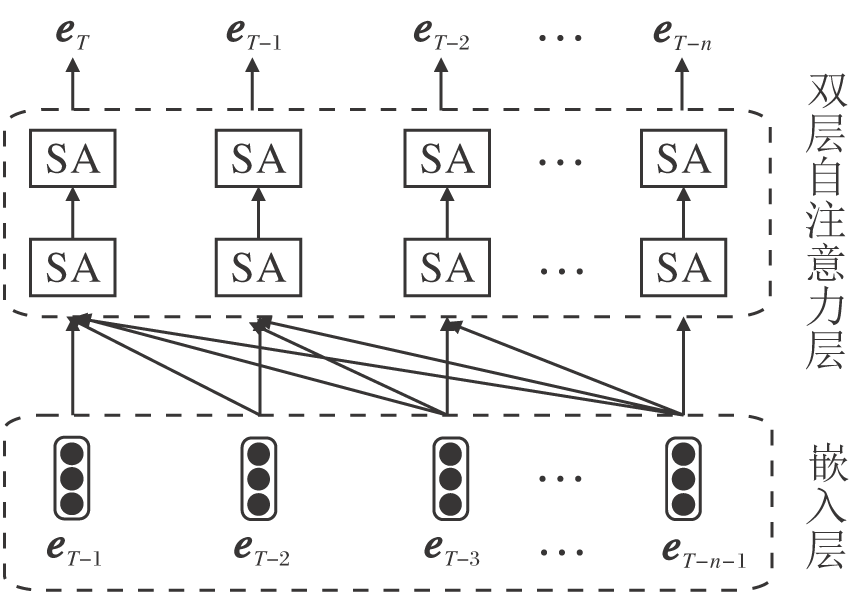 | 图3 预训练过程 图3中SA表示一个自注意力单元和全连接层的结合, 利用用户t时刻之前及t时刻的行为信息预测用户在t+1时刻的行为, 使模型在训练之前融入全部输入用户行为序列的信息.Fig.3 Pretraining process |
双层自注意力层在预训练方法训练过程中学习给定某一时刻的历史行为序列, 即对于输入序列[bT-1, bT-2, …, bT-n-1], 能预测下一时刻的行为序列, 即目标输出序列为[bT, bT-1, …, bT-n].对于双自注意力层中bT-1输入对应的输出节点bT来说, 其结果是双层注意力层融合全部输入序列得到的预测结果.
通过预训练方法得到的双自注意力层参数会在整体模型建立时加载到模型对应的双自注意力层中, 作为初始化参数, 并在整体训练时进行参数微调.
3 实验及结果分析
3.1 实验数据集
本文选择如下3个数据集评测模型性能:Amazon数据集(http://jmcauley.ucsd.edu/data/amazon/)、Steam数据集(https://cseweb.ucsd.edu/~jmcauley/datasets.html#steam_data)和MovieLens数据集(https://grouplens.org/datasets/movielens).Amazon数据集是大规模商品评论集, 实验选取其中具有高稀疏性和多样性的Amazon Beauty、Amazon Games数据集.Steam数据集是大型在线电子游戏销售平台上的游戏评分和评论数据集.MovieLens数据集是在推荐系统领域被广泛使用的基准数据集, 实验选取MovieLens-1M数据集.数据集统计信息如表1所示.由表可见, Amazon Beauty、Amazon Games数据集较稀疏, Steam数据集的用户点击行为和商品被点击量较不对称, MovieLens-1M数据集最稠密.
| 表1 实验数据集统计数据 Table 1 Statistics of experimental datasets |
为了准确评估模型性能, 使用Hit Rate@10和NDCG@10进行评价.Hit Rate@10计算模型预估的用户点击列表中与用户真实点击列表前10项中击中的次数, NDCG@10包含击中项的前后位置权重.
3.2 实验设置
为了评价TCAN性能, 选择如下基线模型.
1)PopRec[6].根据项目被用户购买的次数对项目进行排序, 即待推荐列表中按照被购买次数进行排序.
2)BPR-MF(Bayesian Personalized Ranking)[1].使用偏置矩阵分解法作为隐式反馈的学习方法.
3)TransRec(Translation-Based Recommendation)[19].
将每位用户建模为变换向量, 捕获用户从当前项目到下一项目的变换过程, 达到一阶序列推荐方法中的最优效果.
4)GRU4Rec+[3].使用RNN对用户行为序列中项目间的依赖关系进行建模.
5)Caser[4].采用垂直卷积核和水平卷积核捕获序列的点级、联合级及跳跃行为模式.
6)SASRec[6].通过Transformer中的自注意力机制自适应寻找与目标相关的项目并进行推荐.
7)TiSASRec(Time Interval Aware Self-Attention Based Sequential Recommendation)[13].将时间间隔信息作为重要特征, 通过自注意力机制学习不同项目、绝对位置及时间间隔的权重, 并进行推荐.
上述基线模型的所有超参数和初始化方法都遵循原作者的最佳设置.
使用自适应矩估计优化器(Adaptive Moment Estimation, Adam)优化模型参数, 损失函数设置为交叉熵损失:
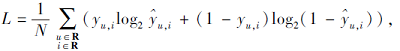
其中, 以点击行为为例, N为用户-项目点击行为数量, yu, i∈ {0, 1}为用户u对项目i的真实点击行为, ${{\hat{y}}_{u, i}}$为模型输出, 表示用户u点击项目i的预测概率.
实验设置训练次数为200, 采用Adam动量梯度下降法进行损失函数优化.在嵌入层中, 用户行为的词嵌入维度de=50, 在时间卷积层中卷积核大小K=3, 卷积网络的扩张系数d=1, 2, 4.在自注意力层中参照文献[13]给出的最大时间间隔{1, 16, 64, 256, 512, 1 024, 2 048}分别进行实验.
实验系统为Linux, 实验平台是Pycharm, 并且借助Pytorch1.7深度学习框架, 及NVIDIA RTX3090 GPU算力完成实验.
3.3 实验结果
各模型在4个数据集上的序列推荐性能对比如表2所示, 其中黑体数字表示性能最优, 斜体数字表示性能次优, TCAN-Pt表示TCAN中的双自注意力层未加载预训练参数, 而是使用随机初始化参数的模型.
| 表2 各模型在4个数据集上的性能对比 Table 2 Performance comparison of different models on 4 datasets |
由表2可知, TCAN在全部指标上均达到最优性能, 能同时建模用户的长期行为和短期行为, 使模型在较长用户行为序列的建模上具有更好优势, 这也解释为什么模型在用户平均点击行为最多、用户行为最稠密的MovieLens-1M数据集上性能提升最明显.
在Amazon Games、Steam数据集上, 模型在没有经过预训练的情况下性能表现不佳, 但经过预训练后性能有较大幅度的提升.分析认为, 模型对于用户短期行为的建模仅通过端到端的训练是不充分的, 限制模型的预估性能.双层自注意力层通过预训练方法在模型整体训练的初期就能捕捉用户短期行为序列中的顺序行为模式, 对于整体模型的训练起到促进作用, 预训练方法通过增强模型对用户短期行为的建模, 进一步增强模型的用户短期行为特征, 提升模型的序列推荐性能.
为了验证TCAN中各个模块的有效性, 进行消融实验, 结果如表3所示.TCAN-Lh为TCAN去除用户长期行为特征的模型, TCAN-Sh为TCAN去除用户短期行为特征的模型, TCAN-Ti为TCAN去除时间间隔辅助信息的模型.
| 表3 TCAN的消融实验结果 Table 3 Ablation experiment results of TCAN |
由表3可知, TCAN中的各个模块对于提升模型的序列推荐性能均具有积极效果.只有用户短期行为特征的TCAN-Lh, 由于仅建模用户短期行为, 对用户行为的分析较片面, 导致性能欠佳.只有用户
长期行为特征的TCAN-Sh效果优于TCAN-Lh, 在用户行为最稠密的MovieLens-1M数据集上的性能提升最大.因为该数据集内用户行为数据更丰富, 需要模型具备对于用户长期行为的建模能力.去除时间间隔信息的TCAN-Ti性能差于TCAN, 这说明项目-用户交互的时间间隔更能体现用户行为序列的周期性行为模式, 对于序列推荐任务是一个重要的影响因素.在消融实验中, 基于用户短期行为序列的预训练方法对于模型性能的提升较明显.
各模型在Movie-Lens-1M数据集上的训练效率如图4所示.由图可知, 相比TiSASRec, TCAN收敛时间仅是TiSASRec的1/3, TCAN大约在1 000s内达到收敛, 在性能大幅提升的基础上, 收敛时间仅增加数百秒.这说明TCAN能在保证训练效率的前提下, 提高模型性能.
 | 图4 各模型训练效率对比Fig.4 Training efficiency comparison of different models |
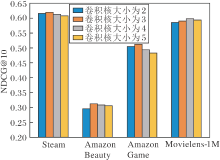
在保持其它最优超参数不变的情况下, TCAN的卷积核大小对模型性能的影响程度如图5所示.由图可知, 在相对用户行为稠密的Movielens-1M数据集上, 当TCAN的卷积核大小为4时, 性能达到最优, 而在其余数据集上, 当TCAN的卷积核大小为3时, 性能达到最优.这表明, 用户行为数量稠密后, 可通过增加时间卷积网络中卷积核的大小增加其感受野大小, 提高模型性能.
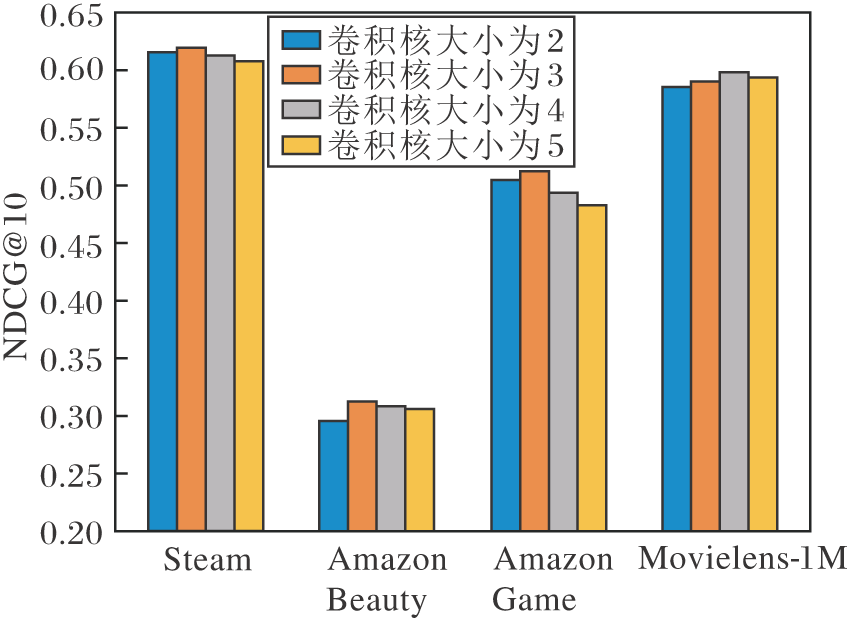 | 图5 卷积核大小对TCAN的影响Fig.5 Effect of size of convolution kernels on TCAN |
用户行为序列建模中的注意力层在Amazon Beauty数据集上的权重可视化结果如图6所示, 图中显示数据集上ID为AKJHHD5VEH7VG的用户在对ID为B0040KTTZI的目标商品进行序列推荐时, 注意力层对于用户行为序列中不同商品的权重分布情况.由图可看出, 注意力层对与目标商品相似品类的商品赋予的权重较大, 与目标商品无关的商品的注意力权重较小, 说明注意力层将用户行为序列中与目标商品相关的商品进行增强, 同时削弱无关商品的影响.图6中用户对于“ Hair Care” 类商品和“ Skin Care” 类商品的购买行为均呈现周期性的购买形式, 这也说明用户购买商品的行为中确实存在周期性的行为模式.
 | 图6 注意力层的可视化结果Fig.6 Visualization of attention layer |
4 结束语
序列推荐的研究重点是对用户行为序列的建模, 本文使用长短期多维度特征建模方式对用户的长期行为序列和用户的短期行为序列进行建模, 提出基于时间卷积注意力神经网络的序列推荐模型(TCAN).模型使用注意力层和时间卷积网络建模用户的长期行为序列, 同时利用自注意力机制建模用户的短期行为序列.用户短期行为序列较复杂, 为了能更好地建模用户短期行为, 进一步采用基于用户短期行为的预训练方法.通过对用户短期行为和长期行为分别建模, 综合考虑用户的周期性行为模式和用户的连续行为模式.
在不同领域、不同稀疏性的数据集上的实验表明, TCAN在序列推荐任务上性能较优, 消融实验也证实TCAN中的短期行为序列建模、长期行为序列建模及添加时间信息均对性能提升具有积极作用.采用的预训练方法也有效提升模型对于用户短期行为的建模能力.今后可考虑使用更复杂的网络, 精确建模用户短期行为.
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|