


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于残差注意力机制和金字塔卷积的表情识别
[包志龙1  , 陈华辉
, 陈华辉1 ]
, 陈华辉]
|
|



作者简介:
包志龙,硕士研究生,主要研究方向为表情识别、神经网络轻量化等.E-mail:13821003591@163.com.
随着深度学习的应用,表情识别技术得到快速发展,但如何提取多尺度特征及高效利用关键特征仍是表情识别网络面临的挑战.针对上述问题,文中使用金字塔卷积有效提取多尺度特征,使用空间通道注意力机制加强关键特征的表达,构建基于残差注意力机制和金字塔卷积的表情识别网络,提高识别的准确率.网络使用MTCNN(Multi-task Convolutional Neural Network)进行人脸检测、人脸裁剪及人脸对齐,再将预处理后的图像送入特征提取网络.同时,为了缩小同类表情的差异,扩大不同类表情的距离,结合Softmax Loss和Center Loss,进行网络训练.实验表明,文中网络在Fer2013、CK+数据集上的准确率较高,网络参数量较小,适合表情识别在现实场景中的应用.
About Author:
BAO Zhilong, master student. His research interests include expression recognition and neural network lightweight.
With the widespread application of deep learning, facial expression recognition technology develops rapidly. However, how to extract multi-scale features and utilize key features efficiently is still a challenge for facial expression recognition network. To solve these problems, pyramid convolution is employed to extract multi-scale features effectively, and spatial channel attention mechanism is introduced to enhance the expression of key features. An expression recognition network based on residual attention mechanism and pyramidal convolution is constructed to improve the recognition accuracy. Multi-task convolutional neural network is utilized for face detection, face clipping and face alignment, and then the preprocessed images are sent to the feature extraction network. Meanwhile, the network is trained by combining Softmax Loss and the Center Loss to narrow the difference between the same expressions and enlarge the distance between different expressions. Experiments show that the accuracy of the proposed network on Fer2013 dataset and CK+ dataset is high, the number of network parameters is small and the proposed method is more suitable for the application of realistic scenarios of expression recognition.
本文责任编委 封举富
Recommended by Associate Editor FENG Jufu
面部表情是人类日常交流中最直接表达内心感受的方式之一, 传递的有效信息占比高达55%[1], 分析一个人在某一时刻的面部表情可以了解其当前的身体状态和精神状态.近年来, 表情识别技术被广泛应用于医疗智能监护、犯罪调查、疲劳驾驶监测、教育评估及其它人机交互方面[2, 3].面部表情识别包括图像预处理、面部特征提取、表情分类三步.根据是否使用深度学习进行特征提取, 可将面部表情识别分为传统面部表情识别和基于深度学习的面部表情识别.
传统特征提取方法主要分为两类:1)基于人类面部纹理特征的提取方法; 2)基于光流法[4], 利用运动物体在视觉平面成像的原理进行特征提取.由于传统特征提取方法都是基于手工制作, 算法依赖历史经验, 只能提取浅层特征, 容易导致特征丢失.
深度学习可通过叠加多层非线性变换提取深层特征, 大幅降低特征丢失的概率, 因此被逐渐应用于表情识别的研究.Tang等[5] 使用深度学习与支持向量机(SVM)共同训练网络, 在2013年FER挑战赛的验证集和测试集上都取得第一名.Jung等[6]采用模型融合技术设计网络, 融合时间特征和表情特征, 提高整体网络的识别准确率.Liu等[7]从表情图像中提取深层次稳健特征信息, 减少光照、遮挡、低分辨率等条件的影响, 使用增强决策树判别面部表情所属类别, 性能和鲁棒性均较优.Hariri等[8]利用三维图像特征和二维卷积神经网络提取的图像特征进行特征融合, 再使用融合特征的协方差矩阵检测特征融合的效果, 最后利用有监督的支持向量机进行表情分类.为了提高表情识别的效果, Li等[9]使用2个网络分别学习表情数据集上的身份特征和表情特征, 再融合2种特征并送入全连接层进行分类输出, 准确率较高.
深度学习在表情识别领域取得良好效果, 但由于输入图像往往包含大面积的非表情区域, 影响识别准确率.近年来, 受到人类注意力机制的启发, 研究人员开始设计具有注意力机制的网络结构.Hu等[10]提出SENet(Squeeze and Excitation Networks), 调整特征通道的权重, 加强关键特征的使用.Woo等[11]提出CBAM(Convolutional Block Attention Mo-dule), 在SENet的基础上增加空间维度的注意力机制.
注意力机制也被研究人员用于表情识别网络中, 以便增强网络对表情相关区域特征的提取.Sun等[12]提出以聚焦于感兴趣区域(Region of Interest, ROI)为核心的表情识别网络, 并引入数据增强策略— — Artificial Face, 提高网络鲁棒性.Li等[13]提出端到端表情识别网络, 引入局部二值模式(Local Binary Pattern, LBP)特征和注意力机制, 使网络能专注于有效特征信息.Sun等[14]提出具有注意力机制的网络结构, 前10层卷积用于提取人脸局部特征, 再通过注意力机制自动识别与表情相关的特征区域, 汇总这些局部特征并输出表情的具体分类.Gan等[15]提出密集连接的空间注意力卷积神经网络, 可自动定位关键特征区域, 提高表情相关特征的表达.引入注意力机制虽然可提高人脸表情关键特征的表达, 但人脸面部表情复杂多样, 单一尺寸的卷积核无法充分提取表情特征.
金字塔卷积(Pyramidal Convolution, PyConv)[16]是由IIAI(Inception Institute of Artificial Intelligence)提出的一种卷积结构.PyConv对不同尺寸的卷积核进行堆叠, 实现多尺度的特征提取, 在图像分类、目标检测、图像分割等领域都具有较好的应用效果.ResNet(Residual Network)[17]使用残差结构学习高层特征信息, 使数据能跨层流动, 同时解决深层网络梯度下降期间网络性能退化的问题.
因此, 为了充分提取面部表情特征, 增强表情相关特征的表达, 本文提出基于残差注意力机制和金字塔卷积的表情识别网络(Expression Recognition Network Based on Residual Attention Mechanism and Pyramid Convolution, RAPNET).引入PyConv, 有效提取多尺度特征信息, 捕捉不同类表情间的细微变化.引入通道注意力机制和空间注意力机制, 加速网络对于关键特征的定位.使用Center Loss[18]和Softmax Loss的联合损失函数, 缩小同类表情间的距离, 降低系统误判的概率.在Fer2013、CK+数据集上的实验验证RAPNET的有效性, 并通过消融实验, 分析对比在RAPNET中引入金字塔卷积、注意力机制和联合损失函数的效果.
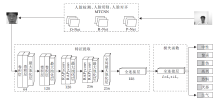
为了捕捉不同表情间的细微变化, 提高关键特征的利用效果, 本文引入金字塔卷积和残差注意力机制, 设计RAPyconv(Residual Attention Pyramidal Convolution)模块, 替代标准卷积进行表情识别中的特征提取.以RAPyconv模块为核心, 基于VGG网络结构, 构建RAPNET进行表情识别, 具体网络结构如图1所示.
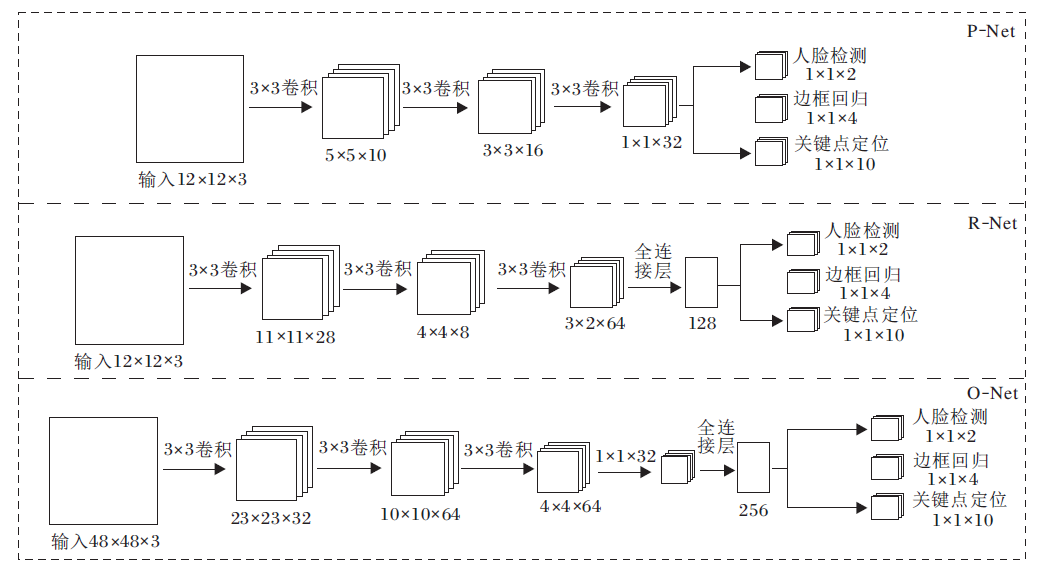
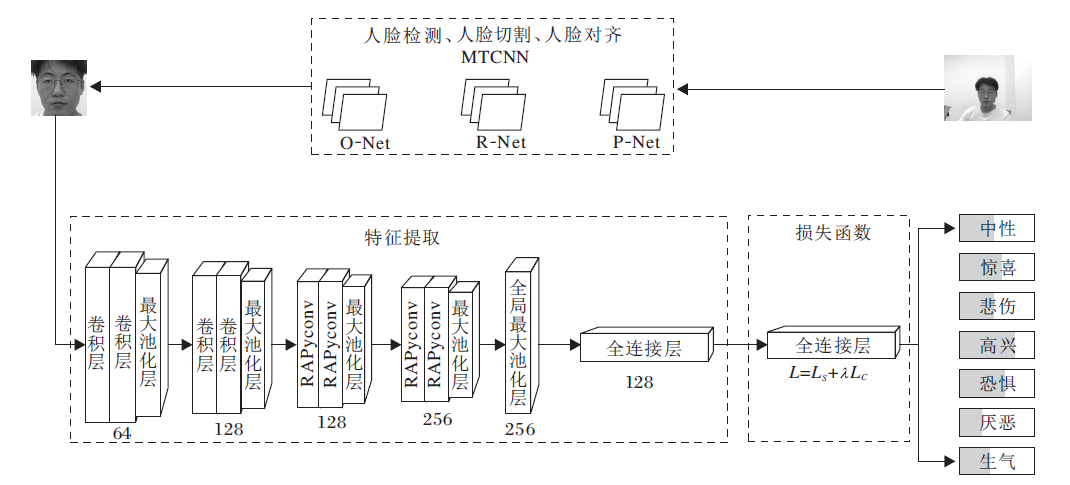 | 图1 RAPNET网络结构Fig.1 RAPNET network structure |
RAPNET由三部分组成:1)MTCNN(Multi-task Convolutional Network)[19], 完成人脸检测、人脸裁切及人脸对齐操作; 2)特征提取网络, 整体采用VGG堆叠式结构, 在第三、四阶段使用RAPyconv; 3)表情识别损失函数, 采用Softmax Loss和Center Loss的联合损失函数, 降低表情误判的概率.
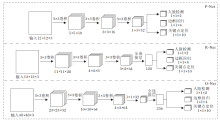
本文选用常用的MTCNN[19]快速有效地完成输入图像中的人脸检测.MTCNN由P-Net、R-Net、O-Net组成, 结构如图2所示.首先, 将输入图像送入P-Net, P-Net先使用三层卷积捕获人脸区域的边界, 再使用NMS(Non Maximum Suppression)合并重叠窗口.针对P-Net输出的候选框, R-Net进行微调, 再继续使用NMS消除重叠的边框.O-Net功能和R-Net类似, 只是在去除重叠边框的同时输出5个人脸关键点.
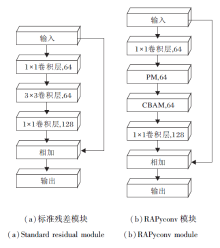
常规PyConv虽然性能较优, 但是无法有效利用图像中的关键特征, 本文结合PyConv的多尺度特征, 提取引入金字塔卷积和残差注意力机制对关键特征的表达能力, 设计RAPyconv模块, 具体结构如图3所示.
 | 图3 RAPyconv模块结构Fig.3 RAPyconv module structure |
为了将RAPyconv应用于深层网络, 解决网络训练过程中性能下降问题, RAPyconv模块整体采用残差结构.RAPyconv标准残差结构的对比如图4所示.本文将标准残差模块(图4(a))中的3× 3标准卷积替换为PM(Pyramid Module)及CBAM模块.
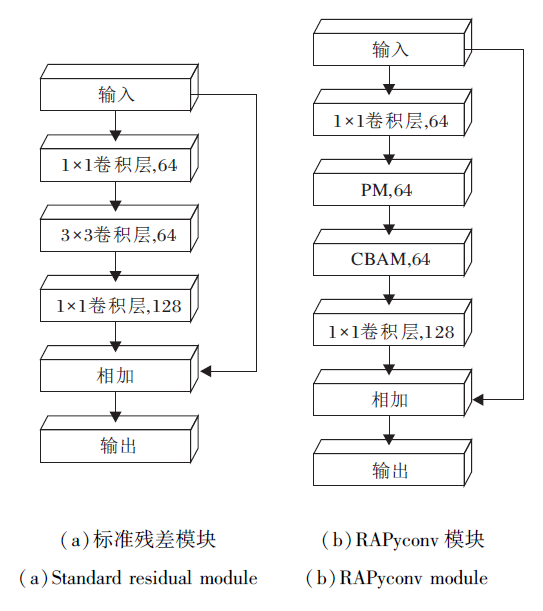 | 图4 标准残差模块与RAPyconv模块结构对比Fig.4 Comparison between standard residual module and RAPyconv module |
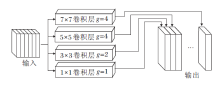
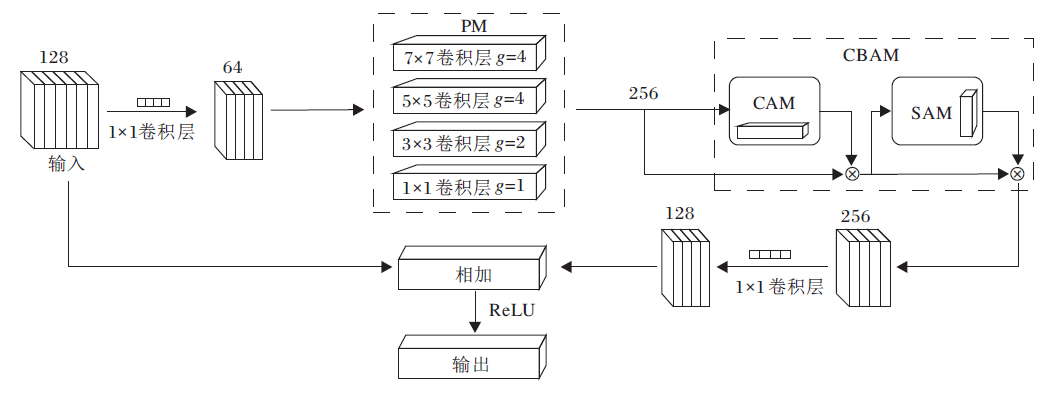
1.2.1 PM模块
常规PyConv模块中输入特征尺寸为Ci× H× W, 卷积核的尺寸从K
为了充分提取面部表情的多尺度特征信息, 受PyConv启发, 本文设计图5所示的PM模块, 采用的卷积核尺寸分别为1× 1、3× 3、5× 5、7× 7, g表示分组卷积中的分组数, 即各层卷积对应的分组数分别为1、2、4、4.
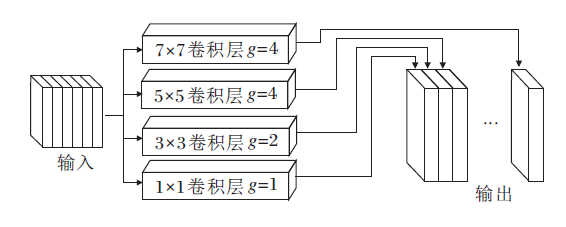 | 图5 PM模块结构Fig.5 PM module structure |
1.2.2 CBAM模块
为了提高多尺度特征中关键特征的权重, 本文将注意力机制CBAM[11]引入模型设计, 对PM模块提取的多尺度特征重新赋予权重, 增强局部关键特征的表达能力.
CBAM由通道注意力机制CAM(Channel Atten-tion Module)和空间注意力机制SAM(Spatial Atten-tion Module)组成, 其中CAM负责关注有效特征信息, SAM在补充通道注意力机制的同时负责生成注意力特征的空间关系.
在CAM中, 输入特征F∈ RH× W× C, 经过平均池化层和最大池化层, 分别得到对应的特征图Favg和Fmax, 再根据特征信息的有效程度, 使用MLP(Multi-layer Perceptron)重新赋予权重矩阵Mc∈ RC× 1× 1, 最后将Mc与F相乘, 得到CAM的输出特征:
$F_{CAM}={{M}_{\text{c}}}(\mathbf{F})\otimes \mathbf{F}$,
${{M}_{c}}(\mathbf{F})=\sigma (MLP(Avgpool(\mathbf{F}))+MLP(Maxpool(\mathbf{F})))$,
其中σ 表示sigmoid激活函数.
在SAM中, 首先使用平均池化层和最大池化层汇总特征通道信息, 得到2个特征F'avg和F'max, 再使用卷积核尺寸为7× 7、激活函数为sigmoid的卷积层进行特征提取, 得到权重矩阵Ms∈ RC× 1× 1, 最后将F与Ms相乘, 得到SAM的输出特征:
$F_{SAM}={{M}_{s}}(\mathbf{F})\otimes \mathbf{F}$,
${{M}_{\text{s}}}(\mathbf{F})=\sigma ({{f}^{7\times 7}}([AvgPool(\mathbf{F}); MaxPool(\mathbf{F})]))$
其中σ 表示sigmoid激活函数.
1.2.3 模块性能分析
RAPyconv模块是本文设计的核心, 根据图4(b)中RAPyconv结构可知, 在RAPyconv模块的特征提取过程中, 输入图像先经过点卷积进行通道压缩, 降低网络参数量, 再通过PM模块和CBAM模块, 最后使用点卷积进行维度扩充.研究表明[11], 引入CBAM模块带来的精度提升对于网络整体而言成本几乎可忽略不计, 因而RAPyconv模块的主要计算量由PM模块产生.针对PM模块, 从参数量Parameter(空间性能)和计算所需FLOPs(Floating Point Operations)(时间性能)两方面进行分析.
假设PM模块输入特征通道数为FMi, 每层卷积的尺寸分别为{
$\left\{ F{{M}_{i}},{F{{M}_{i}}}{(\frac{K_{1}^{2}}{K_{2}^{2}})}{F{{M}_{i}}}{(\frac{K_{\text{1}}^{2}}{K_{3}^{2}})}{F{{M}_{i}}}{(\frac{K_{\text{1}}^{2}}{K_{4}^{2}})} \right\}$,
每层卷积输出的特征通道数分别为{FMo1, FMo2, FMo3, FMo4}, 则PM模块对应的参数量和FLOPs如下:
$\begin{matrix} & \text{pa}rameters=K_{1}^{2} F{{M}_{i}} F{{M}_{o1}}+K_{2}^{2}{F{{M}_{i}}}{\left( \frac{K_{1}^{2}}{K_{2}^{2}} \right)} F{{M}_{o2}}+ \\ & \text{ }K_{3}^{2}{F{{M}_{i}}}{\left( \frac{K_{1}^{2}}{K_{3}^{2}} \right)} F{{M}_{o3}}\text{ }+K_{4}^{2}{F{{M}_{i}}}{\left( \frac{K_{1}^{2}}{K_{4}^{2}} \right)} F{{M}_{o4}} \\ \end{matrix}$,
$\begin{matrix} & FLOPs=K_{1}^{2} F{{M}_{i}} F{{M}_{o1}} \text{(H}\times \text{W)}+K_{2}^{2}{F{{M}_{i}}}{\left( \frac{K_{1}^{2}}{K_{2}^{2}} \right)} F{{M}_{o2}} \text{(H}\times \text{W)}+ \\ & \text{ }K_{3}^{2}{F{{M}_{i}}}{\left( \frac{K_{1}^{2}}{K_{3}^{2}} \right)} F{{M}_{o3}}\text{(H}\times \text{W)}+K_{4}^{2}{F{{M}_{i}}}{\left( \frac{K_{1}^{2}}{K_{4}^{2}} \right)}F{{M}_{o4}} \text{(H}\times \text{W) } \\ \end{matrix}$,
其中, 等式右边4个加法项中的每项对应PM模块中每层卷积的参数量和计算量, $\left( \frac{K_{1}^{2}}{K_{i}^{2}} \right)$表示该卷积层分组卷积的分组数, i=1, 2, 3, 4.
通过公式化简可发现, 虽然PM模块中卷积核的尺寸从
1)多尺度处理.PM模块具有不同尺寸和深度的卷积核, 能从多个尺度解析输入特征, 并通过融合多尺度的特征, 促进面部表情特征的充分表达.
2)高效性.PM模块各层卷积能实现独立并行计算, 甚至可在不同机器上独立运行, 最后进行特征融合即可, 因此整体计算效率较高.
虽然Softmax Loss可扩大不同类间距离, 但缩小类内距离能力较差.现实场景中不同表情可能非常相似, 同类表情也可能差异很大, 仅使用Softmax Loss可能会导致表情误判, 影响整体网络表情识别的准确率.Center Loss[18]缩小类内距离的能力较强, 因此本文将其引入网络, 计算过程如下:
LC=
其中, xi表示输入特征,
因此, RAPNET网络采用的损失函数为
L=LS+λ LC,
其中, λ 表示超参数, 用于平衡Center Loss在总损失中所占比重, 经过多次实验, 确定本文λ =0.000 1.
本文实验基于python3.6, 采用Keras 2.4.3进行深度学习网络的搭建, 训练和测试系统为Windows10 1903.硬件条件如下:CPU为i7-9700K, 基频 3.6 GHz; 内存为32 GB; GPU 为NVIDIA GTX 2080Ti.
本文选择在Fer2013[20]、CK+[21]数据集上进行实验.
Fer2013数据集[20]包含35 887幅图像, 其中训练集图像为28 709幅, 公共测试集图像和私有测试集图像各3 589幅, 图像格式统一为48× 48的灰度图.在给定的训练集中, 标签0表示生气、标签1表示厌恶、标签2表示恐惧、标签3表示高兴、标签4表示悲伤、标签5表示惊喜、标签6表示中性.
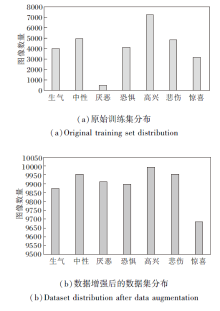
训练集数据的整体分布如图6(a)所示, 其中高兴类图像最多, 为7 215幅, 厌恶类图像最少, 为436幅.
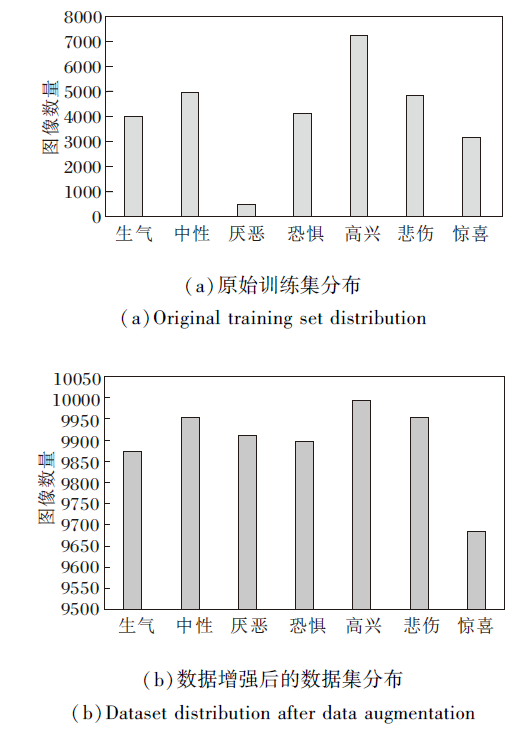 | 图6 Fer2013数据集分布Fig.6 Fer2013 dataset distribution |
针对Fer2013数据集数据分布不均衡、样本中存在大量非人脸区域问题, 进行如下数据预处理.
1)由于厌恶类图像太少, 对厌恶类原始图像采用随机水平翻转、旋转、平移、缩放及灰度化等数据增强处理, 处理后的图像加入厌恶类, 使该类数据从436幅增加至4 280幅, 平衡整体数据分布.
2)使用MTCNN进行人脸裁切和人脸对齐, 去除样本中非人脸区域.
3)为了使图像数据尽可能多样地模拟现实中人脸表情, 针对1)、2)处理后的数据, 采用1)中相同的数据增强操作, 使训练集图像从32 553幅增至69 262幅, 增加后的数据分布如图6(b)所示.
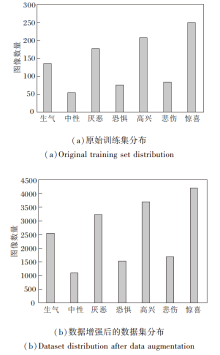
CK+数据集[21]是在实验室内采集完成, 本文选用其中327个带有标签的图像序列(共计981幅图像)作为训练集, 总体数据分布如图7(a)所示, 其中惊喜类图像最多, 为249幅, 中性类图像最少, 为54幅.
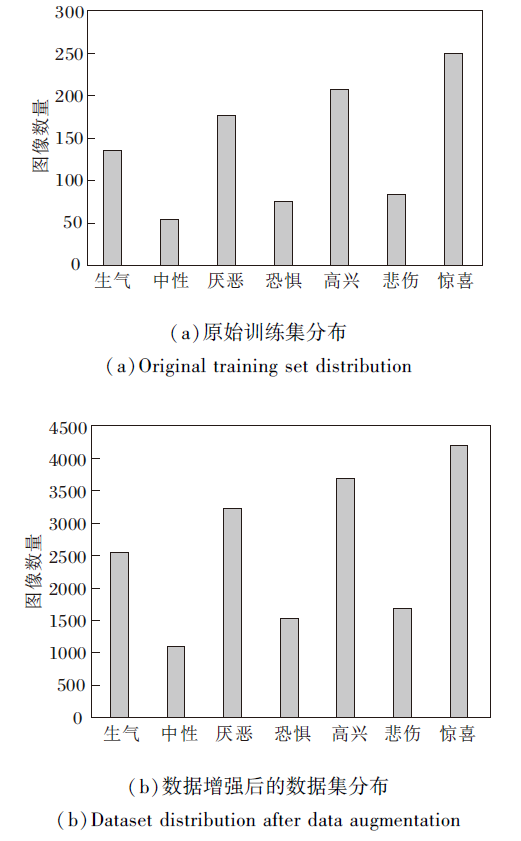 | 图7 CK+数据集分布Fig.7 CK+ dataset distribution |
由于训练集数据量太少, 为了提高模型泛化能力, 同样针对数据集采用随机水平翻转、旋转、平移、缩放等技术进行数据增强, (b)为数据增强之后的分布情况.
实验采用图像分类常用评价指标:精确率、召回率、F1值和准确率(Accuracy, Acc).具体公式如下:
$P=\frac{TP}{TP+FP}$, $R=\frac{TP}{TP+FN}$
$F1=\frac{2P}{2TP+FP+FN}$
$Acc=\frac{(TP+TN)}{(TP+TN+FP+FN)}$
其中, TP表示正样本预测正确的个数, FP表示正样本预测错误的个数, FN表示负样本预测错误的个数, TN表示负样本预测正确的个数, 故F1值为精确率和召回率的调和平均值.
本文超参数的设置如下:批次为140, 批尺寸大小为64, 优化器为Adam(Adaptive Moment Esti-mation), 初始学习率为0.001, 使用ReduceLROn-Plateau回调函数动态调整学习率.具体地, 当验证集损失在20个批次内没有下降时, 学习率降至原来的0.1.
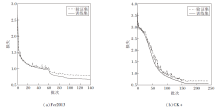
RAPNET在Fer2013、CK+数据集上的准确率曲线和损失曲线如图8和图9所示.由图可知, RAP-NET具有较强的拟合能力, 随着批次的增加, 验证集的准确率和损失在不断优化, 网络并未出现过拟合或欠拟合现象, 由此验证本文构造的网络和损失函数具有良好的泛化能力.
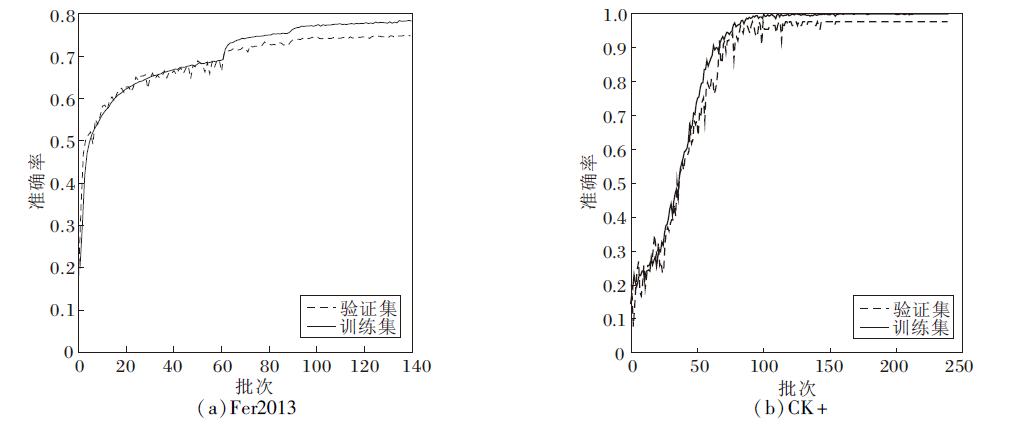 | 图8 RAPNET在2个数据集上的准确率曲线Fig.8 Accuracy curves of RAPNET on 2 datasets |
 | 图9 RAPNET在2个数据集上的损失曲线Fig.9 Loss curves of RAPNET on 2 datasets |
RAPNET在Fer2013测试集上的指标值如表1所示, 总体准确率为72.76%.由于数据集上存在大量负样本, 部分样本亮度较低及面部遮挡较严重, 导致恐惧类和悲伤类样本准确率较低.
| 表1 RAPNET在Fer2013测试集上的指标值 Table 1 Indexes of RAPNET on Fer2013 test set % |
RAPNET在CK+测试集上的指标值如表2所示, 总体准确率为97.75%.由于CK+数据集质量较高, 没有标签错误的训练样本, 因此整体准确率较高.
| 表2 RAPNET在CK+测试集上的指标值 Table 2 Indexes of RAPNET on CK+ test set % |
为了可视化CBAM和PyConv对特征提取的影响, 本文将图像分别送入4个网络中, 4个网络分别使用常规卷积、CBAM、PyConv及CBAM+PyConv进行特征提取, 再对最后一层卷积的输出进行特征图可视化(Class Activation Mapping), 结果如图10所示, 图中橘黄色区域为卷积核提取的特征区域.由图可发现, 常规卷积的特征提取没有针对性, 关键特征的利用率较低.CBAM和PyConv的特征提取都可聚焦于关键器官, 但特征提取区域仍有优化的空间.由于输入高兴表情的图像, 图像的关键特征为嘴部特征, 因此CBAM+PyConv可较好地解决关键器官特征利用率偏低的问题.
 | 图10 四种卷积结构特征的可视化结果Fig.10 Visualization results of 4 convolution features |
为了验证RAPNET的先进性, 在Fer2013、CK+数据集上进行对比实验.对比网络如下:SUN[12]、MobileNets[22]、MobileNetV2[23]、DenseNet121[24]、文献[25]方法~文献[28]方法.各方法实验结果如表3所示, 表中文献[22]~文献[24]的方法在本地环境复现.由于文献[12]、文献[25]~文献[28]未找到可复现的代码, 因此实验结果直接取自原论文.
| 表3 各网络的实验结果对比 Table 3 Comparison of experiment results of different networks |
由表3可知, 在Fer2013数据集上, 相比Mobile-Net、MobileNetV2、DenseNet121, RAPNET的准确率提升2.9%~4.9%.相比文献[25]方法, RAPNET使用金字塔卷积进行多尺度特征提取, 同时注重关键特征的利用, 提高上下文特征的联系.相比文献[26]方法, RAPNET不需要手工提取特征, 网络整体参数量较少, 模型训练和部署对设备内存空间的要求较低.在CK+数据集上, 相比其它方法, RAP-NET准确率提升1.6%~2.1%.文献[27]方法使用卷积层和残差模块搭建一个深度神经网络, 由于缺少注意力机制, 网络无法高效利用关键特征.文献[28]方法虽然引入注意力机制, 但网络整体较深, 参数较多, 容易发生过拟合.
通过实验对比可发现, RAPNET参数量较少, 对于设备的内存空间要求较低, 同时利用注意力机制和金字塔卷积, 有效提取关键特征.
为了验证RAPNET的轻量化特性, 本文在Fer2013数据集上与MobileNetV2和DenseNet121进行对比实验, 结果如表4所示.由表可见, RAPNET的预测时间和FLOPs下降幅度达到80%, 相比DenseNet121, FLOPs下降91%.实验表明RAPNET在实际应用中具有较强的竞争力.
| 表4 各网络的轻量化实验结果对比 Table 4 Comparison of lightweight experiment results of different networks |
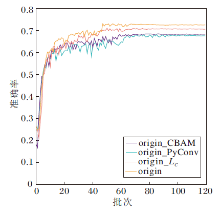
为了验证CBAM、LC损失函数及PyConv的有效性, 同时确定三者的轻重缓急, 在Fer2013数据集(数据增强后)上进行消融实验, 结果如图11所示.origin表示原始网络(含有CBAM、金字塔卷积及LC损失函数); origin_CBAM表示去掉CBAM之后的网络; origin_LC表示去掉LC损失函数之后的网络(采用Softmax损失函数); origin_Pyconv表示去掉金字塔卷积之后的网络.由图可看出, origin网络准确率最高, 为72.5%, origin_LC网络准确率为70.5%, origin_CBAM网络准确率为68.2%, origin_Pyconv网络准确率为67.5%, 都低于origin网络, 从而验证CBAM、LC损失函数及金字塔卷积的有效性.进一步对比发现, origin_Pyconv的准确率最低, 表明去掉PyConv之后网络准确率下降最大, 因此PyConv作用最大, 其次为CBAM, 最后为LC损失函数.
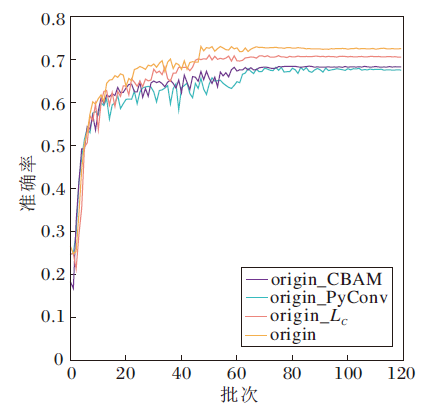 | 图11 消融实验结果Fig.11 Results of ablation experiment |
本文提出基于残差注意力机制和金字塔卷积的表情识别网络(RAPNET), 利用Pyconv模块捕捉上下文多尺度特征, 使用CBAM注意力机制模块提高关键特征的利用率.为了缩小同类表情的距离, 联合Softmax Loss和Center Loss进行网络训练.在Fer-2013、CK+数据集上的测试准确率分别为72.76%和97.75%, 网络参数量仅有0.67 M, 表明RAPNET在现实场景中的应用更具竞争力.今后一方面需要提高算法针对悲伤类表情识别的准确率(相比其它类准确率偏低), 另一方面可结合神经网络轻量化, 进一步减少网络参数量, 提高网络的运行效率.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|