

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
融合多尺度特征的轻量级人脸检测算法
[王建1  , 宋晓宁
, 宋晓宁1 ]
, 宋晓宁]
|
|



作者简介:
王 建,硕士研究生,主要研究方向为计算机视觉、目标检测.E-mail:6201924155@stu.jiangnan.edu.cn.
受到移动设备计算能力和存储资源受限的局限,设计高效、高精度的人脸检测器是一个开放性的挑战.因此,文中提出融合多尺度特征的轻量级人脸检测算法(Lightweight Face Detection Algorithm with Multi-scale Feature Fusion, LFDMF),摒弃被视为人脸检测核心组件的多级检测结构.首先,利用现有的轻量级主干特征提取网络编码输入图像.然后,利用提出的颈部网络扩张特征图感受野,并将含有不同感受野的多尺度信息融至单级特征图中.最后,利用提出的多任务敏感检测头对该单级特征图进行人脸分类、回归和关键点检测.相比分而治之的人脸检测器,LFDMF精度更高、计算量更少.LFDMF按模型计算量高低可构建3个不同大小的网络,大模型LFDMF-L在Wider Face数据集上性能较优,中等模型LFDMF-M和小模型LFDMF-S以极低的模型参数量和计算量实现可观性能.
About Author:
WANG Jian, master student. His research interests include computer vision and object detection.
Due to the limitations in computing capacity and storage resources of mobile devices, it is still an open challenge to design an efficient and high-precision face detector. In this paper, a lightweight face detection algorithm with multi-scale feature fusion(LFDMF) is proposed. The multi-level detection structure, regarded as the core component of face detection, is removed. Firstly, the existing lightweight backbone feature extraction network is introduced to encode the input image. Then, the proposed neck network is utilized to expand the receptive field of the feature map, and the multi-scale information with different receptive fields is fused into the one-level feature map. Finally, the proposed multi-task sensitive detector head is employed to perform face classification, regression and key point detection for the one-level feature map. Compared with the face detectors with RetinaFace and DSFD, LFDMF achieves higher accuracy and less computation burden. LFDMF builds three networks of different sizes. The large model, LFDMF-L, is built to achieve the most advanced performance on the Wider Face dataset, while the medium model, LFDMF-M, and the small model, LFDMF-S, achieve impressive performance with a small number of model parameters and less computation.
本文责任编委 汪增福
Recommended by Associate Editor WANG Zengfu
人脸检测是计算机视觉领域的经典任务.人脸检测作为人脸识别、人脸跟踪、人脸对齐、人脸表情分析的第一步, 对下游任务起到决定性的作用.随着通用目标检测框架的不断进步, 人脸检测作为其中一个子领域, 性能也得到大幅提升, 然而这些性能的提升大多以加深和拓宽网络结构为前提, 增加模型的复杂度, 使模型难以部署到移动平台之中.
现有的人脸检测算法主要还是遵循通用目标检测框架的设计, 一般可分为多阶段检测和单阶段检测, 相比单阶段检测, 多阶段检测增加建议框提取的过程.Zhang等[1]设计三个子网络, 先通过第一个网络获取大量建议框, 后续网络再对上一阶段的输出进行优化.这种做法剔除训练阶段大量的负样本, 使正负样本更均衡.由于采取多阶段的优化方式, 大幅增加检测算法的运行时间, 因此当前人脸检测算法的主流仍是单阶段检测算法, 而且目前对单阶段检测方法的研究已达到和多阶段检测相当的精度, 运行效率较高.
人脸检测中最突出的问题莫过于极端的人脸尺度变化.现实场景图像中人脸尺度具有连续性, 单幅图像中可能同时出现极大人脸和极小人脸.为了处理尺度变化大的问题, 研究者着力于分治处理不同尺度的人脸[2, 3], 提出多级特征检测器.
多级特征检测器结构提高人脸检测的精度, 有效利用骨干网络多个阶段输出的不同分辨率的特征图.这些特征图分别包含不同范围的感受野信息, 巧妙处理不同尺度的目标, Lin等[4]提出特征金字塔网络(Feature Pyramid Network, FPN), 改进多级检测结构, 融合骨干网络相邻阶段的输出特征, 增强低分辨率特征的细节表达能力和高分辨率特征的语义表达能力, 由此产生一系列基于FPN的改进[5, 6, 7], 现有较优的人脸检测网络均采用这种设计[8, 9, 10, 11, 12].Deng等[8]提出RetinaFace, 使用FPN结构并输出5个分支, 处理不同尺度的人脸.Tang等[9]提出Pyramid-Box, 根据经验分析设计不同层级的融合方式, 并输出6个分支处理不同尺度的人脸.Li等[11]提出ASFD(Automatic and Scalable Face Detector), 采用ResNet50[13]作为骨干网络, 采用神经网络架构搜索一个独特的FPN, 然后融合骨干网络输出特征并输出6个尺度不同的特征图.
上述网络均采用特征金字塔结构及其变体的设计, 然而这种网络结构也并非完美, 存在如下缺点:1)输出的多级特征要逐个经过共享头部的推理, 相比直接处理单级特征图, 无疑减缓网络推理速度, 并且FPN会增加推理过程中临时变量的使用, 占用大量显存.2)非常依赖于多级标签分配方法, 不同的标签分配方法产生的差距可能非常大, 这种结构不仅要考虑将哪些位置的锚框分配为正样本, 还需要选择分配至哪一层级.
在通用目标检测中, 也有一些方法仅依赖于单级特征图.Law等[14]提出CornerNet, Duan等[15]提出CenterNet, 都仅使用单级特征图, 并将边界框回归任务转变为关键点检测的任务, 通过对热力图回归定位目标, 然而只有在使用Hourglass[16]这类大型的骨干网络时才能取得较优结果.Chen等[17]提出YOLOF(You Only Look One-Level Feature), 使用空洞编码模块获取较大的感受野, 同时保留较小的感受野特征, 从而将宽范围的感受野融入单级特征图中.该方法使用C5层作为基层特征, 放大其感受野, 这就要求输入图像的分辨率足够大, 否则在提取C5特征时会损失过多的细节信息, 但是高分辨率的输入会增加过多的计算量.同时, YOLOF未有效利用骨干网络的浅层特征, 对小目标检测性能较差.
在人脸检测领域, Xu等[18]提出CenterFace, 仅使用单级特征图, 并取得不错效果.CenterFace基于无锚设计, 在步长为4的特征图上布满锚点, 利用高斯核计算一个等效的热力图以表示真实框.这种无锚设计固然简单, 但在面对遮挡人脸时, 如果两个人脸框的等效热力图中心点重叠, 该位置也仅能检测一幅人脸.另外CenterFace边界框回归仅使用人脸框中心的锚点, 这种回归方式大幅降低锚点的命中率, 不利于网络充分训练.
还有一些方法通过增加额外的监督信息获取精度的提升.He等[19]提出Mask R-CNN, 增加额外的掩码分支, 取得更精确的定位信息.Zhang等[1]提出MTCNN(Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks), Chen等[20]提出STN(Supervised Transformer Network), 联合人脸检测和5个人脸关键点检测, 提升网络对人脸信息的辨识度.然而大部分方法都是将辅助监督信息和分类或回归分支共享特征, 这种处理方式未考虑到不同任务之间的差异.
针对上述分析, 并受到TBCNN(Three-Branch Convolutional Neural Network)[21]对不同特征融合方式的启发, 本文提出融合多尺度特征的轻量级人脸检测网络(Lightweight Face Detection Network with Multi-scale Feature Fusion, LFDMF).与之前的人脸检测网络不同, 输入图像在经过颈部网络后仅输出单级特征图, 该特征图融合不同范围的感受野, 能有效提取各种尺度目标的语义特征.最后将该单级特征图输入头部网络, 进行人脸分类、回归及检测人脸的关键点.实验表明, 该方法融合多尺度特征图至单级特征, 同样能取得较优效果, 并且相比其它多级特征检测的方案, 在参数量和计算量上具有较大优势.另外LFDMF提出多任务敏感检测头, 同样引入人脸关键点检测, 并将分类、回归、关键点检测作为多任务进行处理.该检测头既考虑不同任务之间的差异, 又考虑不同任务之间的相似性.实验表明, 该检测头能进一步提升模型性能.
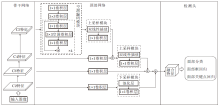
本文提出融合多尺度特征的轻量级人脸检测算法(LFDMF), 整体框架如图1所示.
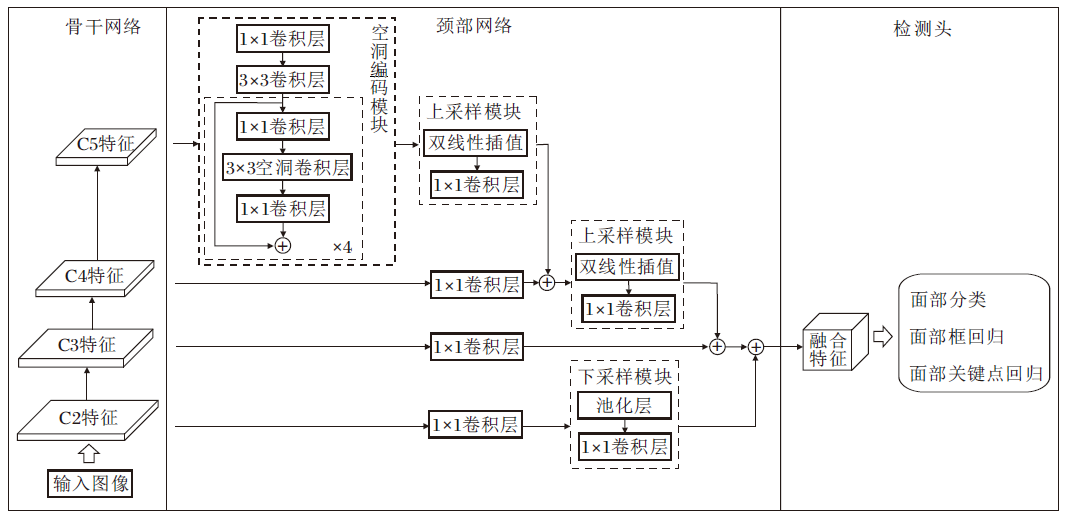 | 图1 LFDMF整体结构Fig.1 Overall structure of LFDMF |
骨干网络的优劣会直接影响特征提取的好坏, 进而影响目标检测的结果.PyramidBox以VGG16网络[22]作为骨干网络, RetinaFace采用ResNet101为骨干网络, 这两类骨干网络计算复杂度较高, 不宜充当轻量级网络的主干.Guo等[23]提出SCRFD(Sam-ple and Computation Redistribution for Efficient Face Detection), 指出目标检测中常用的骨干网络并不适用于人脸检测, 然后基于神经网络架构搜索多个不同计算量的适用于人脸检测的骨干网络, 该骨干网络具有参数较少、计算量较低等优点.因此LFDMF分别选取SCRFD-34g、 SCRFD-2.5g、SCRFD-0.5g三个不同计算量的骨干网络, 构造LFDMF-L、LFDMF-M、LFDMF-S.SCRFD-34g指在输入分辨率为640× 640条件下, 以残差块(Residual Block)为基本搜索单元, 对残差块的通道数、叠加深度等进行搜索, 限制网络整体的浮点运算量为34 G下搜索得到的骨干网络, 同理SCRFD-2.5g限制网络整体浮点运算量为2.5 G, SCRFD-0.5g限制网络整体浮点运算量为0.5 G.
与多级检测网络不同, LFDMF的颈部网络仅输出单级特征图, 因此与多级检测网络的设计思想也有所不同.在多级检测网络中, 颈部网络的主要功能是分治处理不同尺度的目标, 高层特征处理尺度较大的目标, 低层特征处理尺度较小的目标.然而人脸尺度是连续的, 理论上划分越多的层次, 能处理的人脸尺度就更有连续性, 但这显然与轻量化检测目标相矛盾.LFDMF颈部网络的目标是先扩大感受野的范围, 然后将不同的感受野融入单级特征图中, 处理各种尺度的目标人脸, 可通过下采样和空洞卷积的方式实现扩张感受野, 下采样会丢失目标的空间信息, 因此LFDMF选择空洞卷积获取更大的感受野.
图1中空洞编码模块由4个基于空洞卷积的瓶颈块串联组成, 每个瓶颈块中3× 3空洞卷积层的空洞率分别为2、4、6、8, 经过空洞卷积扩张感受野后, 使用残差连接聚合不同感受野的特征.不同于YOLOF, LFDMF在精度和计算量的权衡下, 颈部网络输出步长为8的P3特征图, 另外该网络复用骨干网络前几个阶段的输出特征, 分别通过上采样模块和下采样模块进行融合.这对于较小尺寸人脸检测较有利.实验表明, 相比FPN, 该结构具有更优性能.
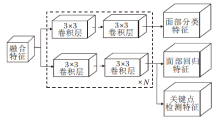
大多数人脸检测头直接从颈部输出引出双分支进行分类和回归.如图2所示的基线检测头, 特征图输入到检测头后先分成2个分支, 每个分支堆叠N个3× 3卷积层, 关键点检测仅作为辅助分支挂载到回归分支和共享特征.虽然这些任务之间有一定的关联性, 但也存在许多差异, 如分类分支更关注人脸的全局信息, 回归分支更关注人脸的边界信息, 关键点检测更关注人脸的关键部位.
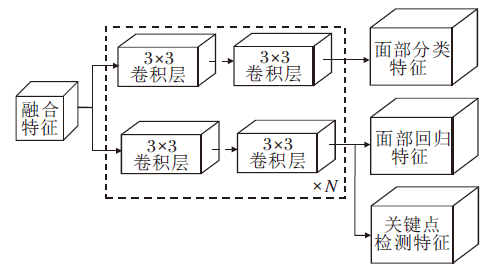 | 图2 基线检测头Fig.2 Baseline detector head |
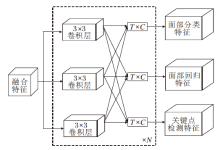
受这种思想的启发, 本文提出任务敏感型的检测头, 如图3所示.
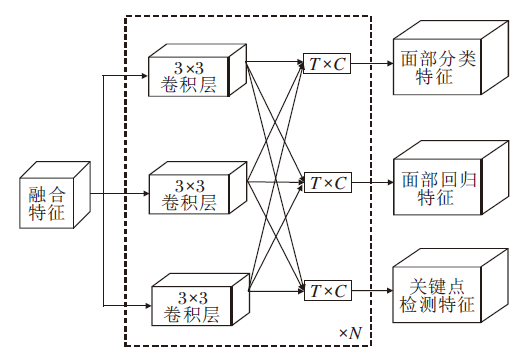 | 图3 多任务敏感检测头Fig.3 Multi-task sensitive detector head |
任务敏感型的检测头的目标是找出不同任务特征图的最佳融合方式.首先, 与常规检测头相同, 从颈部输出的特征图引出T个分支, 每个分支经过一个3× 3卷积层, 再通过任务敏感模块.该模块由T个任务敏感单元组成, 每个单元包含T× C个可学习的参数, C表示输出特征的通道数.该单元计算不同任务特征图在通道维度上的线性结合以得到任务敏感的特征图.网络包含分类、回归、关键点检测分支, 因此T=3, 模块以串联的方式堆叠N次, 通道数C取值与模型大小相关.LFDMF-L、LFDMF-M、LFDMF-S通道数取值分别为128、32、24.
网络整体损失L* 由分类损失Lcls、人脸框回归损失Lreg、关键点检测损失Lkps共同组成:
L* =Lcls+λ 1Lreg+λ 2Lkps,
其中, λ 1、λ 2为任务权重调节因子, 按一定的比例调节并保持不同损失项处于同一数量级.
由于分类和回归分别使用不同的分支, 会导致分类和边界框回归不一致的问题, 以Quality Focal Loss[24]作为分类损失函数可有效解决该问题, 则
Lcls=-|y-σ |β ((1-y)ln(1-σ )+ylnσ ),
其中, y∈ [0, 1]表示基于预测框和真实框交并比(Intersection over Union, IoU)软化的质量标签, σ 表示预测质量, β 表示调节因子, 默认取值为2.
面部框回归以CIoU(Complete IoU) Loss[25]作为损失函数.仅使用IoU有时不能准确反映预测框和真实框的位置关系, CIoU加入最小外接矩形框的惩罚项, 更有效解决这一问题, 则
$v=\frac{4}{{{\pi }^{2}}}{{\left( arctan\left( \frac{{{w}^{gt}}}{{{h}^{gt}}} \right)-arctan\left( \frac{w}{h} \right) \right)}^{2}}$,
其中, ρ (· , · )表示欧氏距离, b表示预测框中心点坐标, bgt表示真实框中心点坐标, c表示预测框和真实框最小外接矩形的对角线距离, w、h表示预测框宽、高, wgt、hgt表示真实框的宽、高.
面部关键点损失函数Lkps采用$smoot{{h}_{{{L}_{1}}}}$损失函数:
其中, ti={tx, ty}表示预测的关键点坐标,
在80× 80的P3特征图上平铺锚框, 对于每个特征点设置6个锚框, 尺度分别为[2, 4, 8, 16, 32, 64].遵循YOLOF的统一匹配(Uniform Match)策略, 采取距离真实框最近的k个锚框作为正样本, 因此所有的真实框匹配同等数量的锚框与真实框大小无关.与YOLOF不同的是, 为了获取更高质量的锚框, LFDMF将网络预测框位置同初始锚框位置共同和真实框计算欧氏距离, 选择其中最近的k个锚框, k默认取值为4.此外, 遵循最大IoU匹配策略, 删除IoU> 0.7的锚框作为负样本及IoU< 0.15的锚框作为正样本.
首先选择在WiderFace数据集上进行训练.WiderFace数据集是最大的人脸检测数据集, 包含32 203幅图像和393 703幅人脸.数据集划分3个级别的检测难度:Easy、Medium、Hard.这些人脸在尺度、姿态、光照、表情、遮挡等方面都有很大的变化范围, 接近现实场景中的人脸变化, 另外数据集上5个人脸关键点标注来源于RetinaFace.
实验使用基于PyTorch的开源框架MMDetec-tion[27]实现, 使用SGD(Stochastic Gradient Descent)优化器(动量设置为0.9, 权重衰减设置为5e-4).使用2张Nvidia 2080Ti显卡, 批大小设置为8× 2, 初始学习率设置为5e-6, 在2个轮次内线性上升至5e-2.训练阶段共训练640个轮次, 在第441个和第545个轮次时, 学习率下降为原来的0.1.所有模型均从头训练而未使用任何预训练模型.数据增强策略使用随机尺度裁剪, 从[0.3, 0.45, 0.6, 0.8, 1.0, 1.2, 1.4, 1.6, 1.8, 2.0]中随机选择一个尺度进行裁剪, 尺度大于1.0时先对原始图像填充至指定尺度, 然后将裁剪后的矩形块拉伸至640× 640.另外对图像进行色彩增强和0.5概率的随机水平翻转.
输入分辨率和模型计算量呈正相关, LFDMF重点关注模型在VGA(640× 480)分辨率上的表现.在未额外指明的情况下, 所有测试和对比方法的输入分辨率均为VGA, 训练输入分辨率为640× 640.
相比通用目标检测, 人脸检测的类别只有一类, 主要评价指标包括精确率(Precision, P), 召回率(Recall, R), 平均精确率(Average Precision, AP), 具体计算公式如下:
P=
其中, 在给定的IoU阈值下, TP表示预测框和真实框匹配的数量, FP表示预测框和真实框不匹配的数量, FN表示未被正确预测的真实框数量, p(r)表示不同IoU阈值下, R和P之间的对应函数, AP表示该函数在0-1区间上的积分.
本文方法复杂度评价指标为浮点运算数(Floating Point Operations, FLOPs), 表示模型前向推理过程中的浮点运算量.
实验选用如下对比算法:RetinaFace[8]、DSFD(Dual Shot Face Detector)[10]、SCRFD[23]、HAMbox(Online High-Quality Anchor Mining Strategy)[28].实验结果如表1所示, 表中黑体数字表示最优值.
| 表1 各算法的实验结果对比 Table 1 Experimental result comparison of different algorithms |
在表1中, LFDMF-L* 、LFDMF-M* 、LFDMF-S* 分别表示使用ResNet50、MobileNet、MobileNet0.25作为骨干网络的模型, 0.25指在原始网络基础上通道数缩放为0.25倍, Bottleneck Res、Basic Res、Depth-wise Conv为SCRFD提出的3个计算量不同的骨干网络.由表可看出, 这3个骨干网络对人脸检测优势较大.
另外本文按模型参数量和计算量划分为3类.由表1可看出, LFDMF-L在Wider Face数据集上性能最优, 并且在模型参数量和计算量上有较大改进.LFDMF-M在中等和困难子集上均优于SCRFD.LFDMF-S以极低的计算量和参数量实现可观的性能.
为了测试算法的极限性能, 遵循RetinaFace对LFDMF-L进行多尺度测试, 分别将测试图像长边拉至[500, 800, 1100, 1400, 1700]进行推理, 选取代表性的对比算法如下:MTCNN[1]、PyramidBox[9]、Two-Stage CNN[26]、DFS[29]、Face R-CNN[30]、SSH[31], 算法命名均遵循WiderFace数据集(http://shuoyang1213.me/WIDERFACE/index.html)上的官方命名.在Wider Face数据集上各算法的精确率-召回率曲线如图4所示.由图可看出, LFDMF性能最优.
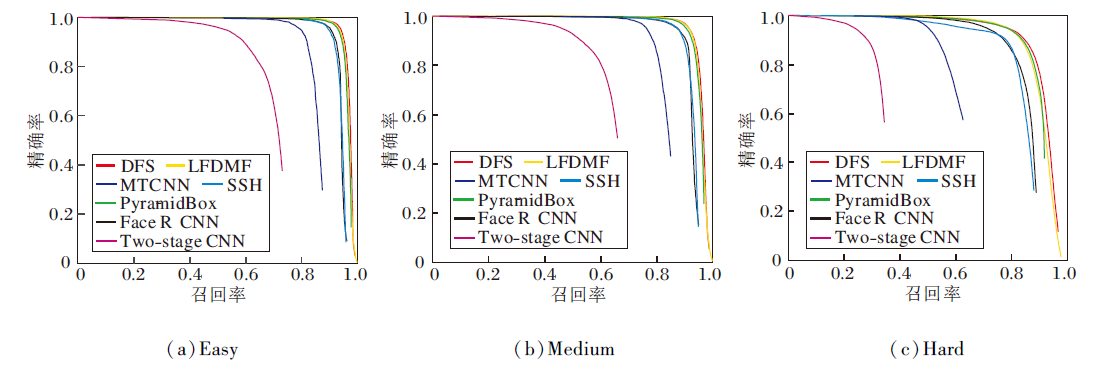 | 图4 各算法在Wider Face数据集上的精确率-召回率曲线Fig.4 Precision-recall curves of different algorithms on Wider Face dataset |
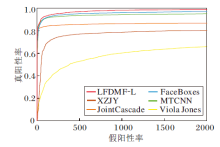
为了评估算法泛化能力, 进一步在FDDB数据集(http://vis-www.cs.umass.edu/fddb)上进行测试.FDDB数据集包含2 845幅图像, 共有5 171幅无约束的人脸.以受试者工作特征(Receiver Ope-rating Characteristic, ROC)曲线为评估指标.选取如下代表性的对比算法:MTCNN[1]、FaceBoxes[2]、JointCascade[32]、XZJY[33]、Viola Jones[34], 具体缩写均遵循FDDB数据集上官方命名.各算法的ROC曲线如图5所示.
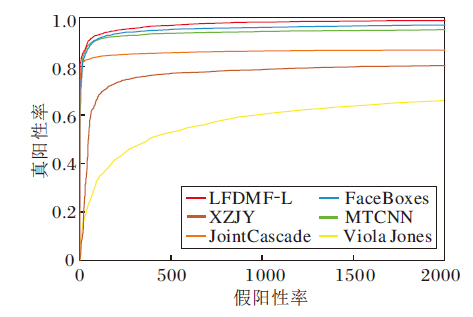 | 图5 各算法在FDDB数据集上的ROC曲线Fig.5 ROC curves of different algorithms on FDDB dataset |
由图5可看出, LFDMF-L表现出良好的泛化能力.
2.4.1 颈部网络输出尺度的选择
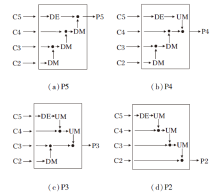
P2~P5不同层级的输出对于锚框的设置和正负样本的分配有极大的影响, 主干网络输出4个不同尺度的特征图C2~C5, 此处探究颈部网络以相似的融合方式输出4层不同的单级特征图对检测结果的影响, 设置任务损失权重λ 1=2, λ 2=0.1.
输出不同层级的单级特征图如图6所示, 图中DE、DM、UM分别表示图1中的空洞编码模块、下采样模块、上采样模块.
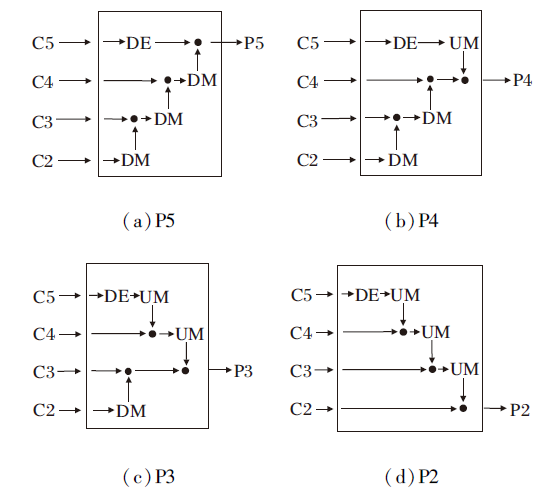 | 图6 输出不同层级的单级特征图Fig.6 Map of one-level feature of outputting different levels |
不同输出层级对结果的影响如表2所示, 表中黑体数字表示最优值.由表可知, 以P4或P5作为颈部网络的输出在Hard子集上的精度较差, 和预期相同, 这是因为Hard子集上小尺寸人脸图像占有很大比重, 而P4、P5层下采样率过高, 许多小尺寸人脸图像无法匹配到优质的锚框.而以P2作为输出层虽能取得较高精确率, 但网络的计算量较高, 最终LFD- MF在基于精确率和计算量的权衡下输出融合后的P3特征图.
| 表2 不同输出层级对实验结果的影响 Table 2 Influence of different output layers on results |
2.4.2 各模块有效性实验
现分析特征金字塔、LFDMF颈部网络、基线检测头、任务敏感检测头这4个模块的有效性, 具体实验结果如表3所示, 表中黑体数字表示最优值.
| 表3 不同模块对实验结果的影响 Table 3 Influence of different modules on results |
对比LFDMF颈部网络, 特征金字塔遵循RetinaFace的多级输出融合和锚框设置方式, 使用C2~C5作为特征金字塔网络的输入, 输出P2~P6共5层金字塔结构.这些层共享相同检测头, 精度有所提升.在使用LFDMF的颈部网络基础上以基线检测头的方式加入关键点检测后, 精确率又有所提升, 表明额外的监督信息能有效提高人脸检测的精确率.在使用任务敏感型头部之后, 模型精确率达到最优值, 这证实人脸检测的3个不同分支之间既有相似性, 又有差异性, 本文提出的检测头能同时兼顾二者, 并改善模型性能.
2.4.3 不同任务损失权重的选择
为了测试不同任务损失权重对结果产生的影响, 在LFDMF-L上进行如下实验.由于同时预测5个人脸关键点的计算的损失较大, 因此实验中给予其较小的权重, 保证各项损失处于同一数量级, 具体实验结果如表4所示, 表中黑体数字表示最优值.
| 表4 不同损失权重对实验结果的影响 Table 4 Influence of different loss weights on results |
由表4可看出, λ 1=2, λ 2=0.1时精确率较优, 这说明人脸检测的主要任务为边界框回归, 适当增加λ 1有益于边界框回归的收敛, 而λ 2设置较大时精确率略有降低, 与预期一致.这是由于数据集上大量的小型人脸图像关键点特征模糊, 无法从中提取有益的特征, 反而会影响网络收敛的方向.
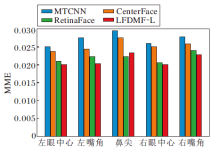
为了进一步验证LFDMF检测头对人脸关键点检测的性能, 在AFLW数据集[35]上进行实验.AFLW数据集包含24 386幅人脸面部标志注释, 这里使用面部框大小(
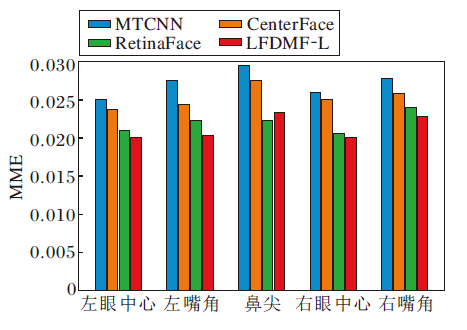 | 图7 各算法在AFLW数据集上的人脸对齐评估Fig.7 Evaluation of different algorithms for face alignment on AFLW dataset |
由图7可看出, LFDMF-L除了在鼻尖关键点检测上的性能略低于RetinaFace以外, 对其余关键点的检测均有明显的优势.
考虑到算法在现实场景中的应用, 分别测试LFDMF-L、LFDMF-M、LFDMF-S的运行效率.在Nvi-dia 2080Ti上以VGA分辨率为输入, 在仅考虑算法推理时间的条件下, LFDMF-L单幅图像用时仅12.1 ms, LFDMF-M单幅图像用时4.4 ms, LFDMF-S单幅图像用时3.6 ms, 完全达到实时性人脸检测的要求.以大模型LFDMF-L为例展示算法在WiderFace数据集上的部分检测结果, 具体如图8所示.由图可看出, 不论是在常规环境下, 或是在肤色、姿态、尺度等影响因素下, LFDMF都能精准检测人脸及其面部关键点.
 | 图8 LFDMF-L在Wider Face 数据集上的检测结果Fig.8 Detection results of LFDMF-L on Wider Face dataset |
本文提出融合多尺度特征的轻量级人脸检测算法, 摒弃特征金字塔网络的多级输出结构, 显著减少模型计算量和参数量.另外引入颈部感受野融合模块, 在性能和计算上均优于传统的多级特征检测网络.最后提出的多任务敏感检测头, 同时兼顾不同任务之间的相似性与差异性, 进一步提升检测效果.近期一些通用目标检测方法主要关注无锚方法的正负样本分配策略, 然而这些分配策略均以多级检测为前提, 今后会考虑针对无锚的单级特征检测方法开展研究.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|