



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
逐点特征匹配的跨域行人重识别方法
[杨萍1  , 吴晓红
, 吴晓红1 , 何小海1 , 陈洪刚1 , 刘强1 , 李波1 ]
, 吴晓红, 何小海, 陈洪刚, 刘强]
|
|



作者简介:
杨 萍,硕士研究生,主要研究方向为深度学习、行人重识别.E-mail:1047798178@qq.com.
吴晓红,博士,副教授,主要研究方向为图像处理、模式识别、计算机视觉.E-mail:wxh@scu.edu.cn.
陈洪刚,博士,副研究员,主要研究方向为图像/视频处理、计算机视觉、人工智能.E-mail:honggang_chen@scu.edu.cn.
刘 强,博士研究生,主要研究方向为图像处理、行人重识别、计算机视觉.E-mail:liuliu408@163.com.
李 波,硕士研究生,主要研究方向为计算机视觉、模式识别.E-mail:804463592@qq.com.
针对现有的直接跨数据集的行人重识别方法泛化性不足、跨域能力较差的问题,文中提出逐点特征匹配的跨域行人重识别方法,只需在源域上进行模型训练,在目标域上进行测试,就可达到较好效果.首先,为了解决网络对于跨域的行人图像风格、颜色等鲁棒性不高的问题,在ResNet50基础网络中引入实例归一化层,提取图像特征.然后,利用Transformer的多头自注意力模块与卷积结合,增强特征的表示能力.最后,通过在深层特征中建立一种逐点的特征映射关系,将图像匹配视为逐点寻找局部最优的过程,在未知场景中提升模型的抗视角变化能力,增强模型的泛化性.实验表明,文中方法在提高模型泛化能力上具有一定的优越性.
About Author:
YANG Ping, master student. Her research interests include deep learning and person re-identification.
WU Xiaohong, Ph.D., associate profe-ssor. Her research interests include image processing, pattern recognition and computer vision.
CHEN Honggang, Ph.D., associate professor. His research interests include image/video processing, computer vision and artificial intelligence.
LIU Qiang, Ph.D. candidate. His research interests include image processing, person re-identification and computer vision.
LI Bo, master student. His research inte-rests include computer vision and pattern re-cognition.
To improve the poor generalization and cross-domain capability of the existing direct cross-dataset person re-identification methods, a cross-domain person re-identification method based on point-by-point feature matching is proposed. By the proposed method, the model only needs to be trained on the source domain and tested on the target domain to achieve better results. Firstly, to improve the poor robustness of the network for style and color of cross-domain pedestrian images, instance normalization layer(IN) is introduced into the ResNet50 basic network to extract image features. Secondly, the multi-head self-attention module of Transformer is combined with convolution to enhance the representation ability of features. Finally, by establishing a point-by-point feature mapping relationship in the deep features, image matching is regarded as a point-by-point process of finding the local optimum to improve the ability of the proposed model to resist perspective changes in unknown scenes and enhance its generalization. The experimental results show that the advantages of the proposed method in improving the generalization ability.
本文责任编委 叶东毅
Recommended by Associate Editor YE Dongyi
行人重识别旨在解决跨摄像头下相同身份的图像匹配问题, 在智能视频监控、智慧安防方面具有广泛的应用前景.早期的行人重识别[1]主要是基于人工特征设计和度量学习的方法, 近年来, 基于深度学习[2, 3, 4, 5, 6, 7, 8]的行人重识别方法也取得不错性能.
然而, 由于不同域之间的偏差较大, 利用源域数据训练的模型直接应用在目标域上性能将严重衰退, 很多基于深度学习的方法在新的未知场景下泛化能力较差.因此, 一些研究者提出无监督域自适应的方法, 主要思想是利用聚类算法[2, 3, 4]将没有标签信息的目标域图像特征聚类生成伪标签, 在目标域上使用聚类生成的伪标签进行有监督的学习, 或利用生成对抗网络[5, 6, 7]将有标签的源域数据迁移到目标域, 再用生成的目标域数据训练模型.典型基于聚类的伪标签方法包括:Yu等[2]联合非对称度量和聚类方法, 通过共享空间学习行人特征, 减轻不同域间的视图偏差, 实现更优的匹配性能.Ge等[3]提出MMT(Mutual Mean-Teaching), 对伪标签进行在线优化, 降低标签噪声, 提供更具鲁棒性的伪标签.Zhai等[4]在得到初始聚类结果后, 通过生成对抗网络得到新的样本数据, 并再次聚类以更新标签.典型基于生成对抗网络的方法包括:针对域间变化, Deng等[5]提出域间的风格迁移, 将源域训练集图像的风格迁移到目标域图像上, 减小域间差异.针对域内变化, Zhong等[6]提出在目标域内部进行细粒度风格迁移, 使用StarGAN(Star Generative Adversarial Networks)[7]将目标域中不同图像进行风格迁移.
相比传统的行人重识别方法, 无监督域自适应方法确实在性能上有所提升.但是, 无监督域自适应方法都需要在目标域上进一步学习, 部署时需要消耗大量的资源和时间, 限制模型在实际场景中的应用.因此, 提升模型跨域时的泛化能力是研究者们目前关注的热点.Muandet等[9]通过最小化域之间的差异学习不变变换, 学习理论分析表明, 减少差异性可提高模型在新领域的泛化能力.Shankar等[10]将采样步骤作为数据扩充, 利用域分类器和类别分类器损失梯度中的扰动进行模型训练.Jin等[11]利用IN(Instance Normalization)过滤图像风格变化的影响, 引入双重因果损失约束, 从过滤的信息中提取与身份相关的特征并恢复到网络中, 提高模型性能.
现有的大多数基于深度学习的行人重识别方法[12, 13]都是对每幅图像计算一个固定的表示向量, 并使用距离或相似度度量进行图像匹配, 未考虑到两幅输入图像之间的实际内容对应关系.独立处理每幅图像, 当模型不进行域自适应, 只在源域上进行训练时, 学习到的模型是不变的, 泛化能力较差.若关注模型的泛化能力, 将模型直接应用在目标域上, 需要源域训练的模型具有自适应能力.
为了增强数据的特征表示能力, 获得更有判别性的行人特征, 研究者们将注意力机制应用于行人重识别网络设计中.为了解决背景噪声的干扰, Xu等[14]提出AACN(Attention-Aware Compositional Net-work), 利用注意力机制提取行人的姿态信息.为了解决行人图像误对齐对特征提取造成的负面影响, Li等[15]提出HA-CNN(Harmonious Attention Convo-lutional Neural Network), 结合像素点的软注意力机制和空间的硬注意力机制, 优化特征表示.为了加强局部特征学习, Chen等[16]提出SCALM(Self-Critical Attention Learning Method), 利用空间信息和通道信息, 通过强化学习进行训练.Zheng等[17]提出CASN(Consistent Attentive Siamese Network), 定位感兴趣的行人区域, 强制同一行人的不同图像之间注意力的一致性.
传统的注意力机制大多采用简单的单头单层结构, 卷积注意力模块未充分利用部件之间的相对位置信息.Transformer是一种基于多头结构的注意力模型, 能捕获全局依赖性, 具有更大的感受野.Dosovitskiy等[18]提出Vision Transformer, 对原始图像进行分块, 展平成序列, 输入纯粹的Transformer编码器进行特征学习和图像分类.Carion等[19]提出DETR(Detection Transformer), 结合卷积神经网络(Convolutional Neural Network, CNN)与Transformer结构, 使用CNN提取图像特征, 再展平传递到Trans-former编码器, 进行位置编码补充.He等[20]提出Trans-ReID(Transformer-Based Object Re-identification), 将Transformer应用到行人重识别领域, 多头注意力机制可让模型关注到人体不同部位的特征, 增强特征表示能力.
综上所述, 针对跨域行人重识别模型泛化性不足的问题, 本文提出逐点特征匹配的跨域行人重识别方法.在ResNet50中引入IN层作为骨干网络, 提升网络模型的域自适应能力.为了提取有用的行人特征, 引入Transformer多头自注意力机制, 利用多头注意力机制, 提取更好的行人局部特征和全局特征.在不同领域下寻找的局部最优具有普遍适用性, 能较好地用于未知的场景, 故将图像匹配问题看作是逐点匹配寻找局部最优的过程, 提升模型在未知场景的抗错位能力, 增强模型的泛化性.在行人重识别公开数据集Market1501、DukeMTMC-reID上的实验表明, 本文方法在提高模型泛化能力方面具有一定优越性.
本文提出逐点特征匹配的跨域行人重识别方法, 整体框图如图1所示.将输入图像送入卷积网络进行初步的特征提取, 由于IN层对图像的外观变化具有鲁棒性[21, 22], 因此, 在残差网络ResNet50中引入IN层作为特征提取骨干网络, 减小跨域的行人图像风格、颜色等视觉变换的影响.将经过卷积得到的特征图展平为二维的子特征图, 输入Transformer多头自注意力模块, 利用多头注意力机制使模型提取更好的局部特征和全局特征.再将得到的特征图进行逐点匹配, 即特征图逐点寻找局部最优的过程, 强化模型应对行人视角变化和姿态错位的能力.将特征点逐点匹配后, 进行水平最大池化和竖直最大池化, 串联两组相似度输出, 再通过一系列卷积操作得到匹配相似度.但是, 若将所有图像都通过两两匹配的方法计算相似度, 在数据采样的过程中, 输入图像有多种不同的组合方式, 当数据集过大时, 会耗费大量资源.因此, 在训练过程中构建一个特征缓存池, 缓存每位行人最新的样本特征图, 特征缓存池的大小即行人的身份数量.输入图像只需和缓存池内的特征图进行匹配, 大幅减小计算资源的消耗.模型训练过程中使用Focal loss进行损失计算.
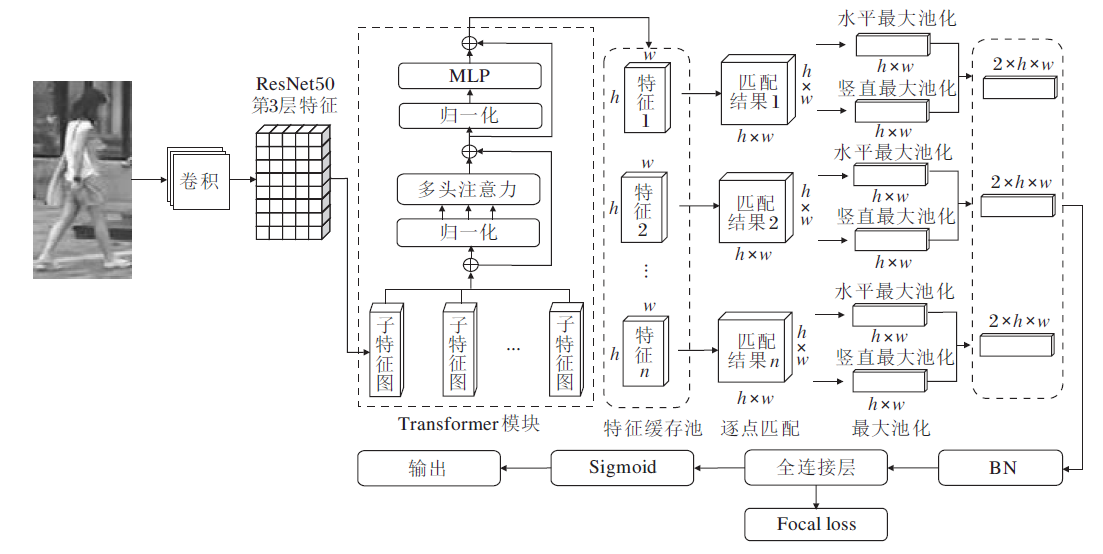 | 图1 本文方法框图Fig.1 Framework of the proposed method |
图2(a)为一幅特征图, h、w表示特征图的宽、高, c表示通道数.
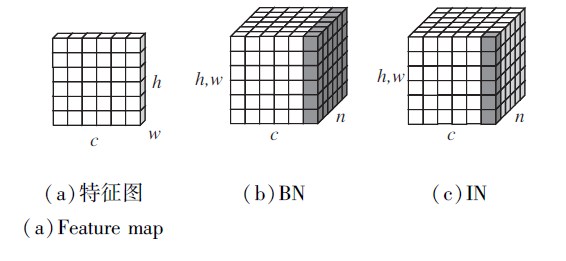 | 图2 BN和IN示意图Fig.2 Sketch map of BN and IN |
图2(b)为批归一化层(Batch Normalization, BN), n为批处理大小, BN是对一个批次内的相同特征通道从h、w和n上进行归一化, BN层能加速训练模型的过程, 学习与内容相关的特征信息, 保留单个样本之间的不同之处, 增强语义特征的差异性, 得到具有区分性的特征.
图2(c)为IN层, IN是对每个特征图在h、w上进行归一化, 网络模型不受批处理大小的影响, 保留图像特征间的独立性, 能学习风格、颜色等视觉变换的相关性, 减小个体之间不同外观的差异, 对目标行人的外观变化具有较好的鲁棒性.
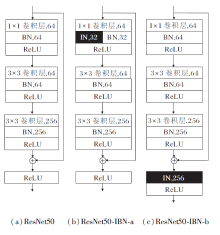
因此在ResNet50中引入IN层与BN层, 形成ResNet50-IBN网络, 对特征进行联合归一化处理, 解决只使用BN层对特征风格变换不敏感的问题.如图3所示, (a)为ResNet50的原始结构, (b)为ResNet50-IBN-a结构, 将原始的BN层一半变为IN层, 同时为了保留低层网络中的语义信息, 在低层网络中也保留BN层, (c)为ResNet50-IBN-b结构, 直接在残差连接之后加入一个IN层.
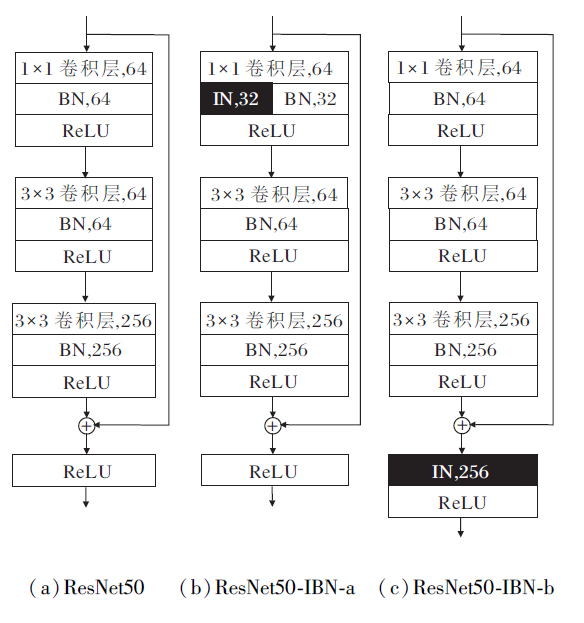 | 图3 ResNet50引入IBN后的网络结构Fig.3 Network structure after introducing IBN into ResNet50 |
每个Transformer编码器包含两个子层, 分别是多头注意力层和全连接层, 子层之间使用残差连接.将经过CNN卷积的行人特征图x∈ Rh× w× c展平为二维的子特征图xp∈
Transformer中的核心模块是多头注意力层:
其中, Q表示查询矩阵Query, K表示被查询矩阵Key, V表示实际特征矩阵Value.从输入的特征图z∈ Rn× D中进行线性映射产生
Q=z× WQ, K=z× WK, V=z× WV,
随机初始化WQ、WK、WV.多头就是通过注意力机制提取多重的语义信息, 得出行人的特征向量, Q× KT计算注意力矩阵, 除以
多头注意力机制会初始化多组WQ、WK、WV, 得到多组特征向量Attention(Q, K, V), 拼接特征, 再通过全连接层降低维度, 以此提取更多的行人全局信息和局部信息:
headi=Attention(
特征逐点匹配过程如图4所示, 每幅图像经过骨干CNN网络提取特征, 再经过Transformer编码器后, 得到[1, c, h, w]大小的特征图, 其中, c为输出的通道数量, h、w为特征图的高和宽.将特征图缓存到特征缓存池中, 与缓存池中所有的行人特征图进行匹配.训练刚开始时, 缓存池中并无行人特征图, 只能对行人身份特征进行缓存, 若已存在该行人的身份特征图, 将原始的行人特征图替换成最新的特征图.直到所有行人都有最新缓存特征图后, 开始进行行人的特征点逐点匹配过程.由于模型在训练过程中会变得越来越好, 最新生成的特征优于模型刚开始训练时提取的特征, 更能反映模型的最新状态, 更容易进行损失计算, 故采用最新行人特征更新特征缓存池.
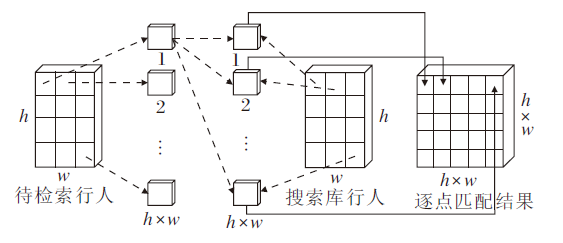 | 图4 特征逐点匹配过程Fig.4 Process of point-by-point feature matching |
将两位行人的身份特征进行逐点匹配后, 得到[w× h, w× h]大小的相似度矩阵.矩阵第1行表示第1幅特征图的第1个点与第2幅特征图的所有点的特征匹配结果, 其它行相同, 第1列表示第2幅特征图的第1个点与第1幅特征图的所有点的特征匹配结果, 其它列相同.之后, 分别对水平方向和竖直方向进行全局最大池化(Global Max Pooling)操作, 串联两组相似度输出, 得到2× w× h的最佳局部匹配向量.最后再通过BN层和全连接层, 输出最终相似度结果.
假设输入网络的图像x∈ Rb× c× h× w的形状为[b, c, h, w], 每幅图像xi的特征输出为yi∈ Rc× w× h, 缓存池中缓存所有行人的身份特征, 假设其中第j位行人特征yj∈ Rc× w× h, 经过特征点匹配后得到长度为2× w× h的向量dij, 向量中的每个元素
k=0, 1, …, w+h-1,
其中, D(· )表示欧氏距离度量, ∥表示地板除, %表示取模.
把dij通过全连接Wf下采样2× w× h倍, 再使用激活函数sigmoid将dij归一化到[0, 1]内, 得到最终的相似度p∈ Rn, 其中n为特征缓存池中的特征数量.使用角度形式的向量积, 输入图像xi为类别f的概率:
${{p}_{i}}\left( f \right)=\frac{{{e}^{W_{f}^{T}{{d}_{if}}}}}{\mathop{\sum }_{j=1}^{n}{{e}^{W_{j}^{T}{{d}_{ij}}}}}=\frac{{{e}^{\parallel W_{f}^{T}\parallel \parallel {{d}_{if}}\parallel \cos \left( {{\theta }_{if}} \right)}}}{\mathop{\sum }_{j=1}^{n}{{e}^{\parallel W_{j}^{T}\parallel \parallel {{d}_{ij}}\parallel \cos \left( {{\theta }_{ij}} \right)}}}$
其中,
‖
在训练过程中, 将所有的匹配图像对的相似度向量以近似相同的长度投影到一个超球面上, 使模型更倾向使用角度进行判断, 输入图像xi是类别f的概率可重新表示为
引入超参数t, 增大损失效果, 提升模型的判别能力, 提升同种类别的聚合能力, 缩放系数m能加速模型收敛.
本文方法使用Focal Loss[24]作为损失函数, 假设输入的训练批次大小为[b, c, h, w], 特征缓存池的大小为[n, c, h, w], 经过特征匹配运算及全连接层、sigmoid函数后得到行人的相似度pi(f).但在匹配过程中, 身份信息不同的负样本对明显多于相同的正样本对, 为了平衡正负样本对的权重, 使用Focal Loss对损失进行加权:
loss=-
其中:当pi(f)=1时, 表示正样本对, 当pi(f)=0时, 表示负样本对; θ 1、θ 2用于平衡正负样本对; γ 表示聚焦参数, 用于加强困难样本数据的权重.
本文选择在Market1501、DukeMTMC-ReID数据集上完成实验.Market1501数据集采自清华大学的6台不同场景的摄像机, 包含1 501位行人的32 668幅图像.训练集包含751位行人的12 936幅图像, 测试集包含750位行人的19 732幅图像.DukeMTMC-reID数据集采自杜克大学的8台摄像机, 每120帧采样一幅图像, 最终获得包含1 404幅行人的36 411幅图像.训练集包含702位行人的16 522幅图像, 测试集包含702位行人的17 661幅图像.
本文采用平均精度均值(Mean Average Preci-sion, mAP)和Rank-n(n=1, 5, 10)指标进行性能评估, Rank-n表示前n幅图像中包含与查询图像是同一身份行人的概率.
本文实验是基于Pytorch深度学习框架实现的, 采用的硬件设备为Intel(R) Xeon(R) E52678 v3@2.50 GHz CPU NVIDIA 2080TI.
骨干网络加载在ImageNet数据集上进行预训练的ResNet50参数, 并在ResNet50中引入IBN-b, 将输入的行人图像分辨率统一缩放为384× 128.将第3层的输出特征输入Transformer后进行特征匹配操作.训练60批次, 训练时批尺寸为48, ResNet50的学习率在前50个批次设置为0.01, 从第51个批次开始, 学习率衰减为0.001.Transformer编码器的多头数设置为2, 重复2次.参考相关研究[23], 超参数t=0.3, 缩放系数m=64.聚焦参数γ =4, 用于平衡正负样本的参数θ 1=0.6, θ 2=0.4.在测试阶段, 引入重排序[25]和TLift(Temporal Lifting)[26], 进一步提高准确率.
本文方法直接在跨数据集上进行对比, 没有在目标域上进行无监督的学习, 因此选择如下两组跨域的重识别方法作为对比方法.第1组为无监督域自适应方法(Unsupervised Domain Adaption, UDA), 需要使用目标域的数据训练模型, 包括:TJ-AIDL(Transferable Joint Attribute-Identity Deep Lear-ning)[27], PAUL(Patch-Based Unsupervised Lear-ning Framework)[28], ECN[29], D-MMD(Dissimilarity-Based Maximum Mean Discrepancy)[30].第2组为域泛化方法(Domain Generalization, DG), 只需要在源域上进行训练, 可直接在目标域上进行部署, 包括:IBN-Net(Instance-Batch Normalization ResNet)[22], QAConv(Query-Adaptive Convolution Method)[26], ECNbaseline[29], SBS(Stronger-Baseline)[31], OSNet(Omni-Scale Network)[32].
在Market1501、DukeMTMC-reID数据集上训练、测试, 具体实验结果如表1所示.由表可看出, 未使用重排序和TLift时, 相比主流的域泛化方法(IBN-Net、SBS、OSNet、QAConv), 本文方法取得更优结果.由此可得, 引入IBN-Net能有效消除背景带来的影响, Transformer能提取更全面的行人特征用于特征匹配.在测试时使用重排序和TLift后, 相比无监督域自适应方法, 本文方法也达到最佳, 无需使用目标域数据进行进一步的训练, 可大幅节约时间和资源, 由此证实本文方法的有效性.
| 表1 各方法在2个数据集上的指标值对比 Table 1 Index value comparison of different methods on 2 datasets |
在Market1501数据集上训练模型, 在Duke-MTMC-reID数据集上进行测试, 对比ResNet50、ResNet50+IBN-a、ResNet50+IBN-b, 具体实验结果如表2所示.由表可看出, 在ResNet50中引入IBN-Net后性能都有所提升, 表明IBN-Net对样本风格、颜色等变化具有较好的鲁棒性.对比ResNet50-IBN-a和ResNet50-IBN-b发现Res-Net50-IBN-b性能更优, 故在ResNet50-IBN-b中添加Transformer多头自注意力机制模块进行后续实验.
| 表2 不同的IBN-Net实验结果 Table 2 Experimental results of different IBN-Net % |
在Market1501→ DukeMTMC-reID和DukeMTMC-reID→ Market1501上进行实验, 分别添加ResNet50、IBN-b、Transformer、重排序、TLift模块, 具体消融实验结果如表3和表4所示.由表可见, 在ResNet50+IBN-b上添加Transformer模块后, 性能有所提升, 表明Transformer模块能使方法更好地提取全局特征和局部特征, 提升方法的泛化能力, 能有效提升跨域的行人重识别性能.引入重排序后, mAP值具有大幅增长, 再使用TLift后, 可通过检索行人同一摄像头中附近的人以提升检索结果.同时, 对比网络的计算复杂度和模型参数.在Market1501→ DukeMTMC-reID上, 使用ResNet50和在ResNet50中引入IBN-b时, 浮点计算量和参数量几乎没有变化, 但精度具有明显提升.增加Transformer模块后, 浮点计算量和参数量略有提高, 性能整体增强.在两组实验中, 网络是相同的, 因此, 最终得到的浮点计算量和参数量也是相同的.
| 表3 各模块在Market1501→ DukeMTMC-reID上的消融实验结果 Table 3 Ablation experiment results of different modules on Market1501 → DukeMTMC-reID |
| 表4 各模块在DukeMTMC-reID→ Market1501上的消融实验结果 Table 4 Ablation experiment results of different modules on DukeMTMC-reID→ Market1501 |
本文网络在使用Transformer进行特征提取时, 对特征图进行分块, 每个分块子特征图xp的大小为p× p.现分析p的大小对实验结果的影响, 具体如表5所示.
| 表5 特征图分块p不同时的消融实验结果 Table 5 Ablation experiment results with different feature map partitioning p |
由表5可知, 当p=1时, 结果最佳.所以当本文采用的逐点匹配方式将分块大小p设置为1时, 分块更小, 通过匹配方式获得的细节信息更准确, 效果最佳.
本文利用Transformer的多头注意力机制提取更好的局部特征和全局特征, 现对比Transformer的多头数及层数对实验结果的影响, 分别对多头数取2、4、8, 层数n取1、2、3、4, 实验结果如表6所示.由表可知, 并不是多头数越多、层数越深, 得到的结果越优.当多头数为2, n=2时, 模型性能最优.因此, 将多头数设置为2, n设置为2.
| 表6 Transformer多头数和层数n不同时的消融实验结果 Table 6 Ablation experiment results with different numbers of heads and layer number n of Transformer |
θ 1、θ 2主要用于平衡正负样本数量, 如表7所示, 当θ 1=0.6, θ 2=0.4时, 网络性能达到最优.
| 表7 θ 1和θ 2不同时的消融实验结果 Table 7 Ablation experiment results with different θ 1 and θ 2 |
聚焦参数γ 用于平衡简单样本与困难样本, 如表8所示, 当γ =4时, 网络性能达到最优.
| 表8 γ 不同时的消融实验结果 Table 8 Ablation experiment results with different γ |
因此, 在实验中设置θ 1=0.6, θ 2=0.4, γ =4.
在Market1501数据集上训练模型, 在Duke-MTMC-reID数据集上将正样本对匹配结果进行可视化, 如图5所示, 将每组图像匹配可视化10组连线.可视化方式即逐点匹配的过程, 使用左图在右图中寻找局部的最佳匹配点, 即将匹配度最高的点相连.由于是逐点的局部特征匹配, 由图可看到, 本文方法能较好地克服行人错位不对齐的问题, 并应用于行人重识别跨域的方向.
 | 图5 逐点匹配可视化结果Fig.5 Visualization results of point-by-point matching |
使用ResNet50和本文方法在Market1501数据集上训练得到的热图对比如图6所示, 图中红色部分就是模型主要关注的地方.
 | 图6 行人图像热图对比Fig.6 Comparison of person image heatmaps |
由图6可见, 直接使用ResNet50进行训练的模型会关注较多不需要的背景信息.使用本文方法通过引入IBN-b且使用Transformer与卷积结合后, 行人图像的背景几乎没有什么颜色, 模型将更多的注意力集中到行人的肢体特征上, 由此可较好地消除背景信息的干扰, 提取更有用的行人特征.而跨域的重识别方法正是需要尽量忽略背景的影响, 由此可看出本文方法的有效性.
本文提出逐点特征匹配的跨域行人重识别方法, 在ResNet50中引入IN层, 减小跨域行人图像的风格、颜色等视觉变换的影响, 利用Transformer多头自注意力机制, 更好地捕捉行人的局部特征和全局特征, 增强特征表示能力.将图像匹配看作是深层特征中寻找局部最优的过程, 提升模型的抗错位能力, 增强泛化性.建立特征缓存池, 缓存行人最新特征, 减小资源消耗.在行人重识别数据集上的实验表明本文方法具有良好的泛化性.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|