

{kind=link}
{kind=link}
{kind=link}
{kind=link}
空间约束下自相互注意力的RGB-D显著目标检测
[袁晓1  , 肖云
, 肖云2 , 江波1, 3 , 汤进1 ]
, 肖云, 江波, 汤进]
|
|



作者简介:
袁 晓,硕士研究生,主要研究方向为显著性检测.E-mail:yuanx25@163.com.
肖 云,博士,副教授,主要研究方向为显著目标检测、多模态分析等.E-mail:xiaoyun@ahu.edu.cn.
汤 进,博士,教授,主要研究方向为图像视频的表示与识别、多模态分析等.E-mail:tangjin@ahu.edu.cn.
针对RGB-D显著目标检测问题,提出空间约束下自相互注意力的RGB-D显著目标检测方法.首先,引入空间约束自相互注意力模块,利用多模态特征的互补性,学习具有空间上下文感知的多模态特征表示,同时计算两种模态查询位置与周围区域的成对关系以集成自注意力和相互注意力,进而聚合两个模态的上下文特征.然后,为了获得更互补的信息,进一步将金字塔结构应用在一组空间约束自相互注意力模块中,适应不同空间约束下感受野不同的特征,学习到局部和全局的特征表示.最后,将多模态融合模块嵌入双分支编码-解码网络中,解决RGB-D显著目标检测问题.在4个公开数据集上的实验表明,文中方法在RGB-D显著目标检测任务上具有较强的竞争性.
About Author:
YUAN Xiao, master student. Her research interests include saliency detection.
XIAO Yun, Ph.D., associate professor. Her research interests include salient object detection and multi-modal analysis.
TANG Jin, Ph.D., professor. His research interests include image and video re-presentation and recognition, and multi-modal analysis.
Aiming at the problem of RGB-D salient object detection, a RGB-D salient object detection method is proposed based on pyramid spatial constrained self-mutual attention. Firstly, a spatial constrained self-mutual attention module is introduced to learn multi-modal feature representations with spatial context awareness by the complementarity of multi-modal features. Meanwhile, the pairwise relationships between the query positions and surrounding areas are calculated to integrate self-attention and mutual attention, and thus the contextual features of the two modalities are aggregated. Then, to obtain more complementary information, the pyramid structure is applied to a set of spatial constrained self-mutual attention modules to adapt to different features of the receptive field under different spatial constraints and learn local and global feature representations. Finally, the multi-modal fusion module is embedded into a two-branch encoder-decoder network model, and the RGB-D salient object detection task is solved. Experiments on four benchmark datasets show strong competitiveness of the proposed me-thod in RGB-D salient object detection.
本文责任编委 叶东毅
Recommended by Associate Editor YE Dongyi
显著目标检测(Salient Object Detection, SOD)[1, 2, 3]是从视觉图像中定位最显著目标(或区域)的方法之一.SOD可作为许多其它视觉任务的预处理步骤, 如目标追踪[4]、语义分割[5]、行人重识别[6]等.近年来, 研究者们提出很多显著目标检测模型[7, 8], 性能具有大幅提升.但由于背景杂乱、场景复杂、光照条件不同等因素, 像素被错误分类, 因此SOD目前仍是一个具有挑战性的问题.
近年来, 基于RGB-D的显著目标检测越来越受到人们的关注, 但如何合理、充分利用两种模态的信息仍是一个巨大的挑战.为了结合RGB信息和深度(Depth)信息进行RGB-D显著目标检测, 之前的一些工作主要集中在研究融合策略[9], 包括早期融合、特征级融合和后期结果融合.
在早期融合模型中, 直接融合RGB信息和Depth信息的原始数据或低层特征, 并输入一个统一的模型中.Qu等[10]使用卷积神经网络(Convolu-tional Neural Network, CNN)融合RGB图像特征和Depth图像特征, 并使用拉普拉斯传播得到最终的预测结果.然而, 由于两种模态的分布差异, 这种统一的模型很难进一步融合两种模态下的数据.
后期融合方法首先生成两种模态的显著性预测图, 再融合两个显著性结果.Han等[11]提出CTMF(Cross-View Transfer and Multiview Fusion), 先利用CNN学习RGB图像和Depth图像的高级特征表示, 再通过全连接层融合多视图特征.
特征级融合方法[2, 7, 12]首先使用2个CNN分别提取RGB图像特征和Depth图像特征, 再学习跨模态交互, 并融入特征学习网络中, 得到最终的显著性预测图.Chen等[12]引入通道注意力机制, 解决多模态跨级别融合问题.Piao等[13]提出DMRANet(Depth-Induced Multi-scale Recurrent Attention Network), 分别提取RGB图像特征和Depth图像特征, 再输入深度细化模块进行集成.Chen等[14]提出PCA(Progre-ssively Complementarity-Aware Fusion Network), 采用特征级融合策略, 设计互补感知融合模块, 用于融合多模态和多尺度特征.此方法避免分布差异问题, 融合多模态-多尺度特征和交互信息.
自注意力网络模型[15, 16]和局部关系网络模型[17, 18]广泛应用于计算机视觉领域.Wang等[19]将非局部思想引入视频分类任务, 将所有位置对某个位置的特征加权和作为该位置的响应值, 以此利用视频中的长距离信息.Huang等[20]提出CCNet(Criss-Cross Network), 多次计算当前位置与其同行或同列特征的关系, 逐步传播到全局, 大幅降低非局部模型的计算开销和内存占用.Zhang等[21]在空间和通道上进行非局部操作, 获得2个维度的长距离依赖关系.Liu等[22]提出生成对抗网络模型, 并引入自注意力机制, 用于生成器网络的解码过程和判别器网络的判别过程.
综上所述, RGB-D显著目标检测现已快速发展, 并且在性能上取得大幅提升.使用自注意力网络模型解决计算机视觉任务也越来越受到研究者们的关注.由于引入全局信息, 能获得更大的感受野, 有助于学习到更结构化的特征表示, 但是目前自注意力网络模型在RGB-D显著目标检测任务中的应用很少.Liu等[2]提出S2MA(Selective Self-Mutual Attention)模块, 融合RGB图像特征和Depth图像特征, 集成自注意力和相互注意力以传播上下文信息.S2MA可提供来自另一个模态的补充信息, 克服仅使用单一模态的局限性.为了降低低质量Depth线索的影响, S2MA进一步使用选择机制, 重新加权相互注意力, 过滤不准确信息.但是, S2MA中的自注意力机制采用非局部操作, 首先计算每个位置的一组空间注意力, 再使用这些空间注意力聚合所有位置的特征.由于非局部操作是一种空间上与距离无关的操作, 倾向于学习全局的上下文信息, 因此缺乏对局部空间约束的考虑.Gu等[23]采用约束的自注意力机制关注目标的局部运动, 捕获单模态视频帧中的运动线索.
鉴于上述情况, 本文采用特征级融合策略, 进一步考虑空间约束, 提出空间约束自相互注意力模块(Spatial Constrained Self-Mutual Attention, CSMA), 实现RGB-D不同模态间有效的信息融合.与非局部操作在全局范围内学习密集的成对关系不同, CSMA关注查询位置周围区域中的成对关系, 获得局部的特征表示.相比非局部操作, CSMA减少内存占用和计算开销.与文献[23]不同, CSMA模块利用多模态的补充信息, 实现不同模态间的信息融合, 在获得局部特征表示的同时, 考虑多模态数据的一致性和互补性.
此外, 扩大感受野在视觉任务中应用广泛且有效, 同时在不同的空间约束下获得的感受野并不一样.因此本文进一步提出金字塔结构的空间约束自相互注意力模块(Pyramid Spatial Constrained Self-Mutual Attention, PSMA), 整合这些不同空间约束下的信息, 得到局部和全局的特征表达, 实现多尺度的特征融合.在双分支CNN网络中引入PSMA, 提出RGB-D显著目标检测方法, 融合2个模态的信息, 完成RGB-D显著目标检测任务.实验表明, 本文方法具有较优性能.
通用的非局部操作[19]主要包括3步:线性转换、相似度计算、上下文聚合.将提取的特征X∈ RH× W× C作为输入, 特征的通道数为C, 尺寸(高、宽)为H× W.
在线性转换中, 分别使用3个线性转换公式:
θ (X)=XWθ , ϕ (X)=XWϕ , g(X)=XWg,
得到嵌入特征, 其中, Wθ ∈
A=f(X)=θ (X)ϕ (X)T, (1)
其中, f(X)∈ RHW× HW, 元素fi, j表示X中第i个特征和第j个特征的相似度.在上下文聚合中, g中的特征通过加权求和进行聚合[19], 即
Y=Ag(X)∈
并且进一步重塑为H× W× C1块.
为了可以在任何预训练网络中插入非局部模块, 而不破坏它原始的特征, 通用的做法是使用残差连接[19]:
Z=YWZ+X,
其中, WZ∈
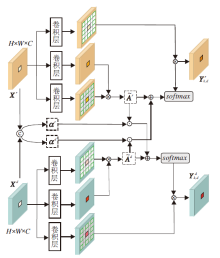
如式(1)所示, 非局部模块中的注意力是由原始特征进行线性转换后相乘得到的.对于多模态任务, 如RGB-D显著目标检测, 可利用多模态特征获得更互补的信息.然而, 非局部模块倾向于学习与距离无关的全局上下文信息, 基于文献[2]和文献[23], 本文进一步考虑空间约束, 提出空间约束自相互注意力模块(CSMA), 适用于多模态数据.CSMA结构如图1所示.
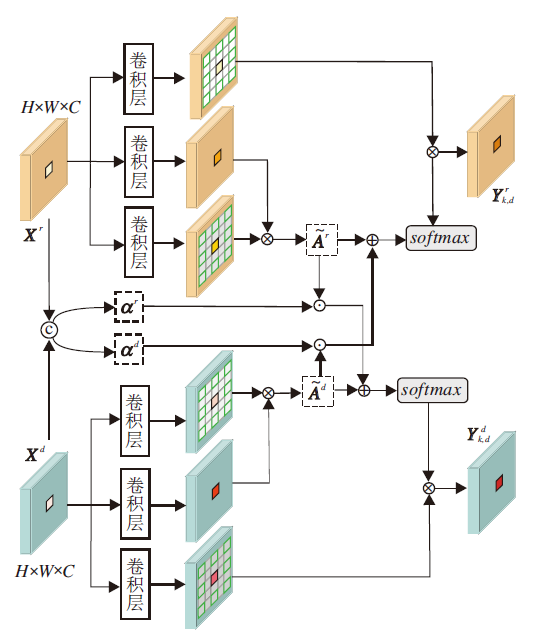 | 图1 CSMA结构图Fig.1 Structure of CSMA |
对于来自RGB模态和Depth模态的特征Xr∈ RH× W× C和Xd∈ RH× W× C, 和非局部模块一样, 先使用线性转换公式得到嵌入特征.在此基础上, 查询θ (X)中特征元素xi时, 利用ϕ 中xi周围区域的特征元素Nk, d(i)计算相似度, k表示xi周围区域特征采样数, d表示空洞率.对于RGB图像特征, 相似度矩阵
同理, 对于Depth图像特征, 相似度矩阵
这2个相似度矩阵仅由各自模态的特征计算得到.由于一些低质量的Depth图像是有噪声且不准确的, 为了融合不同模态的特征且抑制模态中不准确的信息, 本文计算每个位置的选择注意权重, 重新加权相互注意力, 进行上下文的传播[2].首先将Xr和Xd在通道维度上拼接, 再使用1× 1卷积和softmax激活函数计算选择注意力:
α =softmax(Conv([Xr, Xd]))∈ RH× W× 2,
其中[· ]表示在通道维度的拼接操作.再将α 分解为α r∈ RH× W× 1和α d∈ RH× W× 1, 分别表示RGB模态和Depth模态所有位置的选择注意权重[2], 权重值越大表示该位置的信息质量越高, 否则, 信息质量越低.对2个相似度矩阵
$\widetilde{A}_{\text{k}, \text{d}}^{r}=A_{\text{k}, \text{d}}^{r}+{{\alpha }^{d}}A_{\text{k}, \text{d}}^{d}$,
$\widetilde{A}_{\text{k}, \text{d}}^{d}=A_{\text{k}, \text{d}}^{d}{{\alpha }^{r}}A_{\text{k}, \text{d}}^{r}$,
其中☉为按通道的Hadamard积.通过α 选择另一模态中质量较高的信息, 补充当前模态, 从而抑制原模态中不准确的信息.再分别使用 $\widetilde{A}_{\text{k},\text{d}}^{r}$和$\widetilde{A}_{\text{k},\text{d}}^{d}$聚合2个模态的上下文特征[2]:
$Y_{k, d}^{r}=\widetilde{A}_{\text{k}, \text{d}}^{r}{{g}^{r}}({{X}^{r}})$,
$Y_{k, d}^{r}=\widetilde{A}_{\text{k}, \text{d}}^{d}{{g}^{d}}({{X}^{d}})$,
最后, 通过残差连接分别得到2个模态特定的输出:
$\begin{matrix} Z_{k, d}^{r}=Y_{k, d}^{r}W_{Z}^{r}+{{X}^{r}}, \\ Z_{k, d}^{d}=Y_{k, d}^{d}W_{Z}^{d}+{{X}^{d}}, \\ \end{matrix}$ (2)
其中,
在各种视觉任务中, 如检测和分割, 学习局部和全局感受野的特征表示对于模型性能非常重要.为了保持一个较大的感受野, 同时减少计算量和内存占用, 将金字塔的结构[23]应用在CSMA中, 提出金字塔结构的空间约束自相互注意力模块(PSMA).
本文整合一组具有不同空洞率d=(d1, d2, …, dn)和周围区域特征采样数k的CSMA{CSMA-di, i=1, 2, …, n}, 构成PSMA, 可表示为
其中, {
与式(2)相似, 利用得到的特征Yr和Yd, 通过残差连接改进原始特征Xr和Xd, 得到最终输出:
$\begin{matrix} {{Z}^{r}}=Y{}^{r}W_{Z}^{r}+{{X}^{r}}, \\ {{Z}^{d}}=Y{}^{d}W_{Z}^{d}+{{X}^{d}}. \\ \end{matrix}$
固定周围区域特征采样数k和空洞率d的单个CSMA对不同目标有一定限制.相比单个CSMA, PSMA综合不同感受野的信息(式(3)), 得到局部和全局的特征表示, 保留单个CSMA的局部信息或长距离信息.
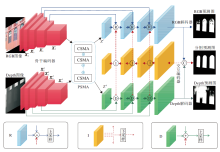
基于PSMA模块, 本文提出RGB-D显著目标检测方法, 整体结构如图2所示.
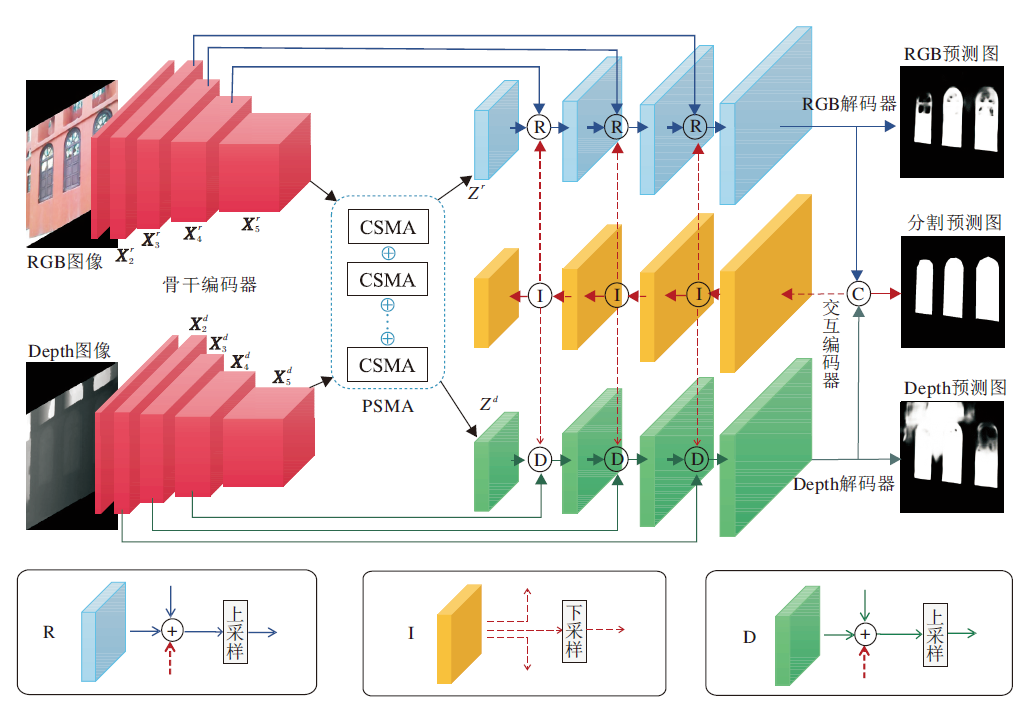 | 图2 RGB-D显著目标检测网络模型的整体结构Fig.2 Architecture of RGB-D salient object detection network |
本文网络整体为通用的编码器-解码器架构[24, 25], 总体上由骨干编码器、交互编码器、RGB解码器、Depth解码器组成.
具体地, 采用ResNet50[26]作为骨干网络.给定一对RGB模态和Depth模态的输入图像, 分别得到不同尺度的特征.为了减少参数和提高网络性能, 采用1× 1卷积, 通道降维到64.分别将这些特征表示为
${{X}^{r}}=\{X_{i}^{r}|i=2, 3, 4, 5\}, {{X}^{d}}=\{X_{i}^{d}|i=2, 3, 4, 5\}.$
将RGB图像特征和Depth图像特征
在得到2个分支的输出特征之后, 为了更好地挖掘不同模态的共同特征, 使用交互编码器促进2个模态之间的信息交换.与文献[27]类似, 交互编码器将RGB解码器和Depth解码器的拼接特征作为输入, 叠加多个卷积, 提取多层次交互特征, 再分别使用不同的卷积, 得到适用于RGB解码器和Depth解码器的交互信息(如图2中I).将融合交互特征和主干编码器的特征直接相加, 充分利用不同模态的特征.在本文方法中, 特征交互由多次迭代组成.在第1次迭代中, RGB解码器和Depth解码器这2个分支在不交换信息时输出融合特征, 从第2次迭代开始, 将前一次迭代后的拼接特征作为交互编码器的输入, 从而实现2个分支之间的交互融合.
类似于文献[27], 定义损失函数为所有迭代输出的总和:
L=
其中, l(k)表示第k次迭代的损失, K表示迭代总数.实验中每次迭代得到3个输出:RGB预测图、Depth预测图、分割预测图.每个输出对应一个损失, l(k)定义为如下3种损失的组合:
l(k)=
其中
lBCE(P, G)=-
其中, P表示预测图, G表示真值图.BCE只独立计算每个像素的损失, 忽略图像的全局结构.为了解决此问题, 在计算
lIoU=1-
实验选择如下4个公开的RGB-D基准数据集:NJU2K数据集[29](包含1 985个样本)、NLPR数据集[30](包含1 000个样本)、STERE数据集[31](包含1 000个样本)、SIP数据集[32](包含929个样本).和之前的一些工作[27, 28]一样, 从NLPR、NJU2K数据集上分别选取700幅和1 500幅图像训练本文方法.NJU2K、NLPR数据集剩下的图像及整个STERE、SIP数据集上图像用于测试.
本文使用如下5个广泛使用的评估指标:准确率-召回率曲线(Precision-Recall, PR)[33], S-mea-sure(Sm)[34], maximum F-measure(Fm)[35], maxi-mum E-measure(Em)[36]和平均绝对误差(Mean Absolute Error, MAE)[33, 37].
准确率和召回率定义为
其中, TP表示真正率, FP表示假正率, FN表示假负率.
Sm计算预测的显著性结果和真值图之间的结构相似性[34], 综合考虑对象结构和区域结构的相似性:
Sm=α Sobject+(1-α )Sregion,
其中α 根据经验设置为0.5.
Fm计算平均精度和召回率的调和平均值[35], 定义为
Fm=
其中, β 2如文献[32]设置为0.3.
Em捕获显著性图的全局综合信息和局部像素匹配信息以评估显著性二值图.
MAE测量所有像素的显著性预测图和真值图之间绝对误差的平均值[37]:
MAE=
在单个NVIDIA 1080Ti GPU上用Pytorch实现并训练本文方法.ImageNet[38]上的预训练模型用于初始化主干模型ResNet50[26]的参数, 同时去掉最后的池化层和全连接层.其它参数随机初始化.将Res-Net50[26]主干网络的最大学习速率设置为0.005, 其它部分的最大学习速率设置为0.05.网络的特征交互迭代次数设置为2.整个网络通过随机梯度下降(Stochastic Gradient Descent, SGD)进行端到端训练, 动量设置为0.9, 权重衰减设置为0.000 5.所有图像统一调整为352× 352, 再输入相应的主干网络提取特征.所有的训练图像使用随机翻转、旋转和边界裁减进行数据增强.
本文设置批次大小为32, 训练模型200轮, 大约需要10 h.
为了验证本文方法的有效性, 选择如下13种RGB-D显著性方法作为对比方法:S2MA[2]、MMCI(Multi-scale Multi-path Fusion Network with Cross-Modal Interactions)[7]、CTMF[11]、TANet(Three-Stream Attention-Aware Network)[12]、DMRANet[13]、PCA[14]、UC-Net(Uncertainty Network)[24]、SSF(Select, Supple-ment and Focus)[25]、CPFP(Contrast Prior and Fluid Pyramid Integration)[28]、D3Net(Deep Depth-Depura-tor Network)[32]、A2dele(Adaptive and Attentive Depth Distiller)[39]、cmMF(Cross-Modality Feature Modula-tion)[40]、DANet(Depth-Enhanced Attention)[41].
各方法在4个数据集上的指标值对比如表1所示.在4个基准数据集上, 相比S2MA, 本文方法取得更好的检测结果, 相比其它方法, 也获得更好结果, 这进一步表明本文方法的有效性.
| 表1 各方法在4个数据集上的指标值对比 Table 1 Index value comparison of different methods on 4 datasets |
各方法在4个数据集上的PR曲线对比如图3所示.由图可知, 本文方法准确率最高.各方法的可视化结果如图4所示.由图可看出, 本文方法能有效抑制背景干扰, 检测更完整的目标.综上所述, 本文方法可精确定位和分割显著物体, 而其它方法在这些复杂的场景中会受到严重干扰.
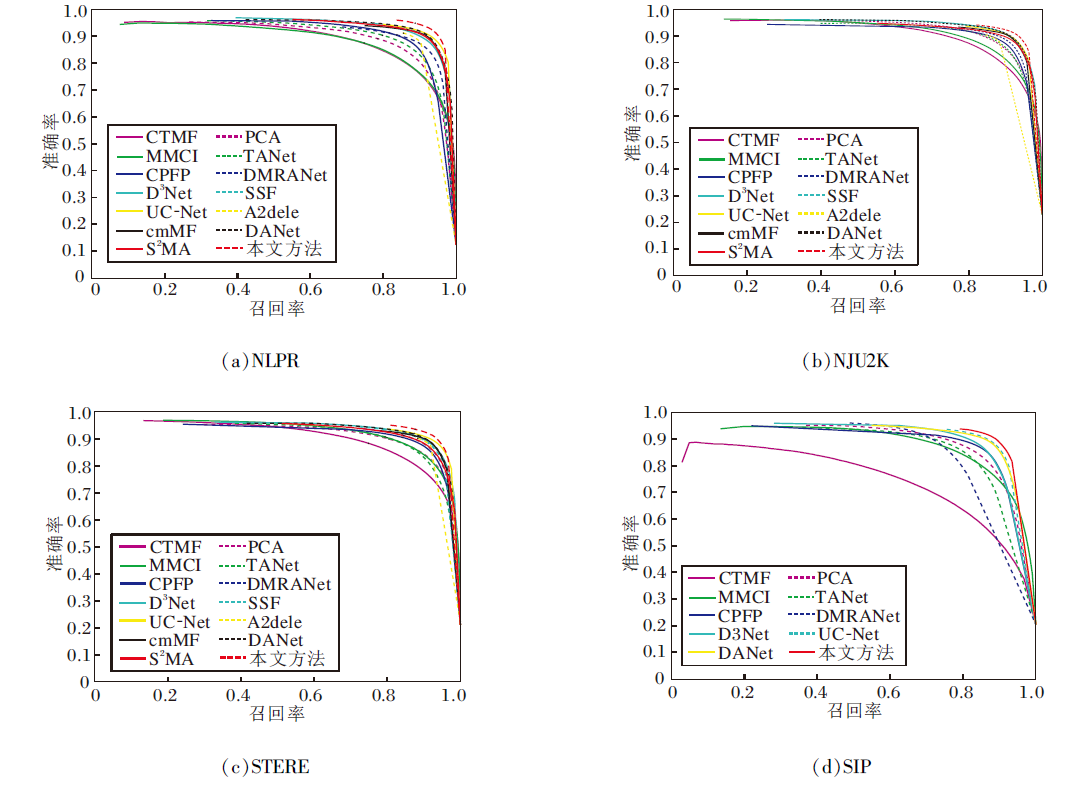 | 图3 各方法在4个数据集上的PR曲线对比Fig.3 PR curves of different methods on 4 datasets |
 | 图4 各方法的可视化结果Fig.4 Visualization results of different methods |
本文方法主要包含2个模块:CSMA和PSMA.为了验证这两个模块的有效性, 本节进行消融实验.选取2.1节中不带PSMA模块的编码-解码架构作为本文的基准方法(baseline).本文将PSMA模块(k=8, d={0, 1, 2})、S2MA模块和单一的CSMA模块在4个数据集上进行对比, 其中S2MA模块采用非局部操作.还对比在CSMA操作中使用相同周围区域采样(k=8) 和不同空洞率d, 具体结果如表2所示, 表中黑体数字表示最优值.由表可知, 添加CSMA模块时, 随着空洞率d的增加, 各项指标值无明显提升.d较小时, 更能关注局部信息, 但缺少长距离信息; d较大时, 可扩大感受野, 得到长距离关系, 但是会缺失周围邻居的信息.PSMA(k=8, d={0, 1, 2})集成不同空间约束下的信息, 在扩大感受野的同时也能关注局部, 得到更互补的信息, 因此性能优于单一CSMA操作.
| 表2 增加不同模块时各方法在4个数据集上的指标值对比 Table 2 Index value comparison of different models on 4 datasets |
本文提出空间约束下自相互注意力的RGB-D显著目标检测方法.引入金字塔结构的空间约束自相互注意力模块(PSMA), 学习多模态图像的空间上下文和多模态感知特征表示.PSMA可嵌入任何多模态任务的学习框架.PSMA由一组空间约束自相互注意力模块(CSMA)组成, 学习查询位置周围区域中的成对关系, 充分利用多模态特征在空间上的互补信息, 金字塔结构可整合一组CSMA特征, 适应不同空间约束下的特征.实验表明, 本文方法具有较优性能.今后将进一步研究多模态特征融合方法.Transformer模型具有建立长距离依赖关系的优势, 可考虑用于多模态特征融合, 进一步提升RGB-D显著性检测性能.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|
| [41] |
|