


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
结合注意力机制与自适应记忆性融合网络的纺织品瑕疵检测
[邓世爽1  , 狄岚
, 狄岚1 , 梁久祯2 , 姜代红3 ]
, 狄岚, 梁久祯, 姜代红]
|
|



作者简介:
邓世爽,硕士研究生,主要研究方向为计算机视觉.E-mail:799596785@qq.com.
梁久祯,博士,教授,主要研究方向为计算机视觉.E-mail:jzliang@cczu.edu.cn.
姜代红,博士,教授,主要研究方向为图像处理、计算机视觉.E-mail:jdh@xzit.edu.cn.
为了解决纺织生产工艺中瑕疵检测成本较高、精度较低、速度较慢等问题,文中提出结合注意力机制与自适应记忆性融合网络的纺织品瑕疵检测模型.首先,在YOLOv5骨干网络中引入改进的注意力模块,构建特征提取网络,增强模型对纺织品瑕疵特征的提取能力.然后,为了增强浅层定位信息的传递效应和有效缓解特征融合时产生的混叠效应,提出自适应记忆性融合网络,在提高特征尺度不变性的同时,将骨干网络中的特征信息融入特征融合层.最后,引入CDIoU(Control Distance Intersection over Union)损失函数,提高检测精度.在ZJU-Leaper纺织品瑕疵数据集和天池纺织品瑕疵数据集上的实验表明,文中模型具有较高的检测精度和较快的检测速度.
About Author:
DENG Shishuang, master student. His research interests include computer vision.
LIANG Jiuzhen, Ph.D., professor. His research interests include computer vision.
JIANG Daihong, Ph.D., professor. Her research interests include image processing and computer vision.
To solve the problems of high cost, low precision and slow speed of defect detection in textile production process, a textile defect detection model combining attention mechanism and adaptive memory fusion network is proposed. Firstly, the improved attention module is introduced into the YOLOv5 backbone network to build a SCNet feature extraction network and improve the ability to extract textile defect features. Then, an adaptive memory feature fusion network is proposed to enhance the transfer of shallow localization information and effectively mitigate the confounding effect generated during feature fusion. Thus, the feature scale invariance is improved while feature information in the backbone network is incorporated into the feature fusion layer. Finally, the control distance intersection over union loss function is introduced into the proposed model to increase the detection accuracy. Experiments on ZJU-Leaper and Tianchi textile defect datasets show that the proposed model generates higher detection accuracy and speed.
本文责任编委 徐 勇
Recommended by Associate Editor XU Yong
在纺织生产工艺中, 纺织品的质量对纺织业影响很大, 纺织品瑕疵会严重影响产品质量, 造成各种资源的极大浪费[1].传统的纺织品瑕疵由人工检测, 受人员经验、熟练程度及其它主观因素的影响, 往往导致瑕疵误检、漏检率较高、检测速度较慢、效率较低等问题.因此, 纺织品瑕疵智能检测是困扰行业多年的技术瓶颈.
当前, 已采用的纺织品瑕疵检测方法可分为结构类方法、统计类方法、模型类方法和基于神经网络方法.在结构类方法中, 通常以纹理作为基本单元, 提取纺织品纹理的结构特征, 并结合位置规律进行分析和检测.Wang等[2]根据结构相似性最小原则定位缺陷图像块, 并使用距离测量和阈值分割定位缺陷, 在一定程度上能有效检测瑕疵, 但存在较多漏检.在统计类方法中, 常使用一阶统计和二阶统计提取和处理图像纹理特征, 通过自相关函数和共生矩阵有效检测有色织物瑕疵.Li等[3]结合多向二元算子和灰度共生矩阵(Gray-Level Co-occurrence Matrix, GLCM), 提出无图案织物缺陷检测方法.Liu等[4]通过织物的主要局部二值模式(Local Binary Pattern, LBP)特征检测织物缺陷, 但LBP特征只适用带有周期性的图像纹理, 在处理复杂背景缺陷时效果不佳.Zhao等[5]将边缘方向梯度的金字塔直方图与支持向量机(Support Vector Machine, SVM)应用于织物缺陷检测.但在实际检测中, 由于不同织物尺寸和纹理变化较大, 仍面临巨大挑战.在模型类方法中, 常通过服从特定分布模型的织物纹理解决纺织品缺陷检测问题.纪旋等[6]针对周期性纺织品存在的拉伸变形问题, 提出结合模板校正与低秩分解的纺织品瑕疵检测方法.Shi等[7]提出PG-NLR(Low-Rank Decomposition Model with Noise Regula-rization and Gradient Information).龙涵彬等[8]通过上下文视觉显著性算法提取卡通层的显著性特征, 分离具有高显著性特征的瑕疵与低显著性特征的背景.上述方法大多仅限于简单纹理, 无法解决复杂的现实世界织物缺陷检测问题.
近年来, 神经网络方法被研究者用来解决各种复杂图像瑕疵, 成为检测纺织品瑕疵的有效方式.Liu等[9]训练基于织物纹理结构的生成对抗网络用于检测缺陷, 在现有织物缺陷样本上训练检测模型, 并在不同应用期间自动适应不同的纹理.但该方法对大规模缺陷检测效果不佳, 在训练初期可能会错误地将复杂背景纹理归类为缺陷.Mei等[10]利用多尺度卷积去噪自编码器网络重建图像块, 并结合多个金字塔尺度特征检测缺陷区域, 但准确率较低, 无法满足实际应用要求.
由于纺织品瑕疵检测可视为目标检测领域任务, 研究人员将深度学习技术应用于织物缺陷检测问题中, 并在提高纺织品质量和生产效率方面取得较优结果[11, 12, 13].目前, 基于深度学习的目标检测器可分为一级检测器和二级检测器[14].一级检测器检测速度更快, 而二级检测器精度更高.在纺织行业的实际应用中, 一般希望在满足检测精度的前提下, 提高检测速度.蔡兆信等[15]使用Faster R-CNN自动检测纺织品缺陷.Faster R-CNN得益于其强大的特征工程能力, 可实现较优的检测性能.然而, Faster R-CNN由于采用两阶段目标检测方案, 时空复杂度较大.为了能更好地适用于工业实际生产, 研究人员分别使用SSD(Single Shot MultiBox Detector)[16]、CenterNet[17]、Cascade R-CNN[18]、YOLO(You Only Look Once)系列[19, 20, 21]等一阶段目标检测网络进行纺织品瑕疵检测.
在目标检测领域中, YOLOv5引入CSPNet(Cross Stage Partial Network)[22], 将梯度变化集成到特征图中, 减少模型参数量和计算量, 既保证推理速度和准确率, 又减小模型大小.但纺织品瑕疵通常具有种类多、差异大、分布不均等特点, 使YOLOv5在特征提取部分并不能充分提取瑕疵特征, 并且YOLOv5在特征融合阶段产生的混叠效应也严重影响瑕疵检测精度.
为了解决上述问题, 本文在YOLOv5基础上, 提出结合注意力机制与自适应记忆性融合网络的纺织品瑕疵检测模型(简记为SCNet+AMFN).首先, 在YOLOv5骨干网络中引入改进后的SCBAM(Softpool Convolutional Block Attention Module), 构建骨干网络SCNet(Softpool Cbam Network), 提升模型对纺织品瑕疵特征的提取能力.然后, 为了增强纺织品瑕疵浅层定位信息的传递效应和有效缓解特征融合时产生的混叠效应, 本文提出自适应记忆性融合网络(Adaptive Memory Fusion Network, AMFN), 引入自适应空间特征融合网络(Adaptive Spatial Feature Fusion, ASFF)[23], 提高瑕疵特征尺度不变性, 同时将SCNet中特征信息融入特征融合层, 增强目标定位信息.最后, 引入CDIoU(Control Distance Intersec-tion of Union)[24]损失函数, 提高检测精度.应用本文模型在纺织品瑕疵数据集上开展训练和测试, 结果表明, SCNet+AMFN是一种精确有效且快速的纺织品瑕疵检测模型.
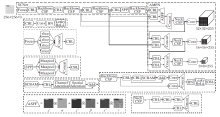
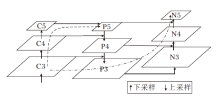
在目标检测任务中, YOLOv5在模型中引入CSPNet[22], 通过分割梯度流, 使梯度流通过不同的网络路径传播, 进而使传播的梯度信息具有较大相关性差异.在特征融合部分, 添加特征金字塔(Feature Pyramid Networks, FPN)和像素聚合网络(Pixel Aggregation Network, PAN)[25]组合结构, 在进行多尺度特征信息融合的同时增强对浅层信息的传递效应.但对于种类多、形态差异大、边缘不确定的纺织品瑕疵目标, YOLOv5对其特征提取能力仍有待提高.同时, YOLOv5在特征融合阶段产生的混叠效应也降低模型对纺织品瑕疵的检测效果.因此, 本文在此基础上提出SCNet+AMFN, 整体结构如图1所示.
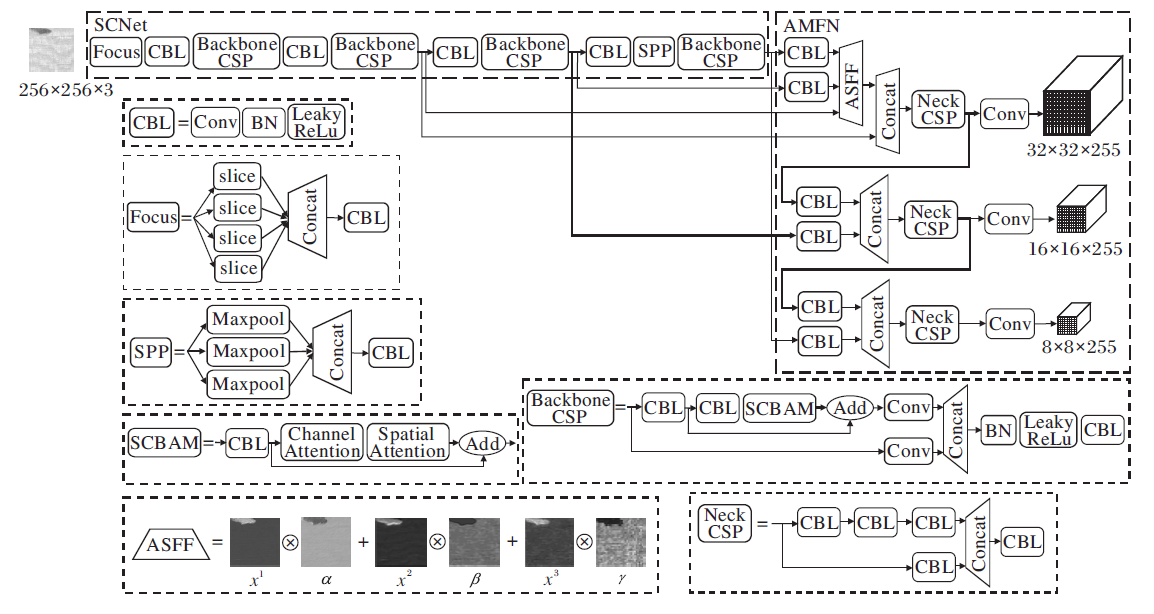 | 图1 SCNet+AMFN网络结构Fig.1 SCNet+AMFN network structure |
由图1可知, 本文模型主要分为SCNet和AMFN两部分.其中, SCNet部分用于提取瑕疵的3个不同尺度的基本特征信息, 由Focus层、4个CBL层、4个引入SCBAM注意力模块的Backbone CSP层、空间金字塔池化(Spatial Pyramid Pooling, SPP)层组成.Focus层将图像切片后连接, 使图像在下采样后仍可保留全部信息, CBL层由卷积层(Conv)、归一化层(Batch Normalization, BN)和LeakyReLu激活函数构成, Backbone CSP层在SCBAM基础上引入残差结构, 增加层与层之间反向传播的梯度值, 防止梯度消失.AMFN部分对SCNet提取的3个基本特征进行充分融合, 使模型在增强浅层定位信息传递效应的同时, 有效融合高层语义特征, 最终输出3个不同尺度的融合特征图, 分别用于检测不同大小瑕疵目标.
本文模型整体训练流程如下.首先将瑕疵图像输入SCNet, 提取3个不同尺度的瑕疵基本特征, 再采用AMFN充分融合3种不同尺度的基本特征, 得到融合特征后, 通过3个检测头模块, 分别对不同尺度瑕疵目标进行定位和分类.
为了有效提高模型对纺织品瑕疵特征的提取能力, 本文借助软池化(SoftPool)[26], 在下采样激活映射中保留更多信息的特点, 设计SCBAM.此外, 在YOLOv5骨干网络的基础上, 引入SCBAM, 构成骨干网络SCNet.
1.1.1 SoftPool下采样
目前, 常用的池化操作(平均值池化和最大值池化)在池化过程中会丢失图像中的大多数信息, 降低整个网络的性能.例如, 平均池化操作仅能提取特定区域中的平均值作为输出, 而最大池化只选择特定区域内最高的单个激活值.SoftPool通过Soft-max加权方式, 保留输入的基本属性, 同时放大更大强度的特征激活值, 因此可在保持池化层功能的同时, 尽可能减少池化过程中带来的信息损失.
SoftPool以自然指数e为底数, 确保越大的激活值对输出具有越大影响.同时, 得益于其可微的特点, 在反向传播期间, 局部邻域R内的所有激活至少被分配一个最小梯度值.在SoftPool池化过程中, 每个激活ai都被赋予权重wi, 该权重为该激活的自然指数相对于邻域R内所有激活的自然指数之和的比值:
${{w}_{i}}={{e}^{{{a}_{i}}}}{{\left( \underset{j\in \text{R}}{\mathop{\sum }}\, {{e}^{{{a}_{j}}}} \right)}^{-1}}$.
通过对内核邻域内所有激活的加权求和得到SoftPool输出值:
1.1.2 SCBAM模块
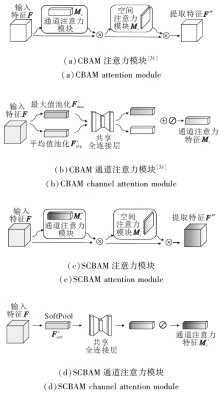
在计算机视觉领域任务中, 研究人员通过各种注意力机制, 增强模型对关键特征信息的提取能力, 提高模型检测效果[27, 28].CBAM(Convolutional Block Attention Module)[29]是一种结合通道和空间两个维度的注意力机制模块, 结构简单, 可有效提高网络的特征提取能力, 广泛应用于神经网络中.
如图2(a)所示, F∈ RC× H× W表示网络中生成的特征图, 其中, C表示特征图通道数, H、W表示输入特征图的高度和宽度.CBAM会按照通道和空间顺序计算一维的通道注意力映射Mc∈ RC× 1× 1和二维的空间注意力映射Ms∈ R1× H× W, 整个过程公式如下:
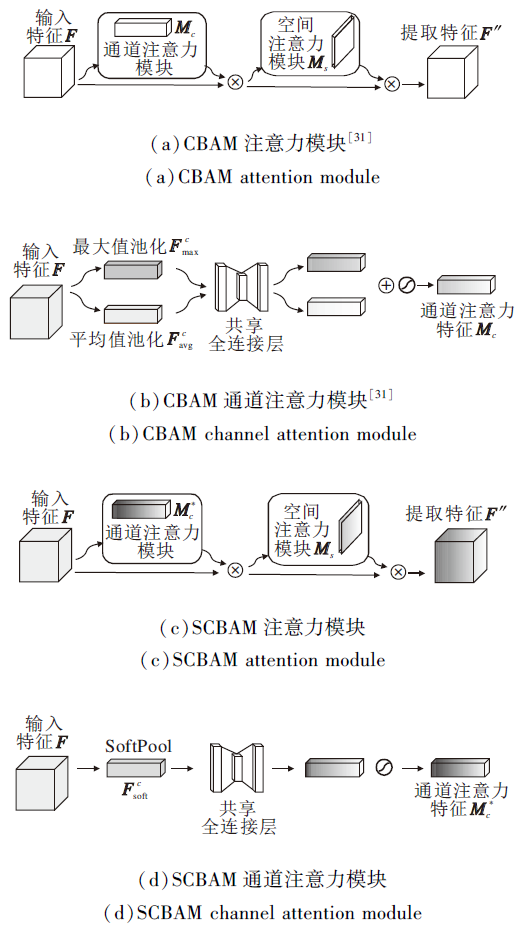 | 图2 CBAM与SCBAM注意力模块对比Fig.2 Comparison of CBAM and SCBAM attention modules |
F'=Mc(F)$\otimes$F, F″=Ms(F')$\otimes$F',
其中$\otimes$表示对应位置元素相乘.
由图2(b)可知, 在CBAM通道维度中, 为了高效计算通道注意力特征, CBAM先使用最大池化和平均池化对输入特征F在空间维度上进行压缩, 得到2个不同的空间背景表示
其中, W0∈ R(C/r)× C, W1∈ RC× C/r, 表示MLP权重, r表示神经元个数减少率.
在CBAM空间维度中, 为了计算空间注意力特征, 首先在通道维度上使用最大池化和平均池化, 得到
其中, f7× 7表示7× 7的卷积层, σ 表示Sigmoid激活函数.
由此, CBAM模块在两个维度计算注意力映射时, 均通过最大值池化和均值池化提取输入注意力信息.然而对于种类多、边缘不确定、背景重合度较高的纺织品瑕疵, 直接引入CBAM模块会大量丢失纺织品瑕疵细节信息, 影响模型检测效果.鉴于此种情况, 本文利用SoftPool, 在下采样中既能最大限度保留细节信息又增强重要特征的特点, 将其引入CBAM, 建立SCBAM.
图2(c)为SCBAM注意力模块结构, 考虑到Soft-Pool池化过程中指数运算影响模型效率的局限性, 因此, 本文仅在CBAM通道维度使用SoftPool代替最大值池化和平均值池化, 在保留更多瑕疵细节特征的同时, 增强瑕疵显著特征的提取.
如图2(d)所示, 在SCBAM通道维度中, 首先通过SoftPool操作, 对输入特征F∈ RC× H× W在空间维度上进行压缩, 得到空间背景特征表示
其中,
再将
F'=
1.1.3 SCNet网络
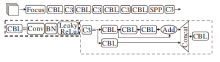
如图3所示, 在YOLOv5骨干网络部分, 网络由Focus层、4个CBL层、4个C3模块和SPP构成.输入图像首先通过Focus层进行切片, 再经过4个CBL层下采样, 每个CBL后面接C3模块, 用于提取该层特征信息, 同时通过SPP扩大感受野, 提高目标检测精度.
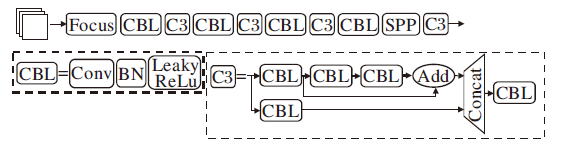 | 图3 YOLOv5骨干网络结构Fig.3 YOLOv5 backbone network structure |
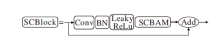
为了进一步增强模型对纺织品瑕疵特征的提取能力, 基于SCBAM, 加入残差结构, 构建SCBlock(SCBAM Block)模块, 并引入CSPNet, 得到特征提取模块Backbone CSP, 替换原YOLOv5骨干网络中C3模块, 构成SCNet, 整个过程如图4所示.由图可知, 在SCBlock模块中, 输入特征经过一个1× 1的CBL层后, 送入SCBAM进行特征提取, 再通过残差结构与初始输入特征相加, 以防止网络过深产生梯度消失问题.
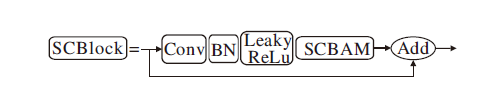 | 图4 SCBlock结构Fig.4 SCBlock structure |
CSPNet通过分割梯度流, 使梯度流通过不同的网络路径传播, 提高卷积神经网络的学习能力, 保证高精度和轻量级, 同时, 降低内存成本和复杂度, 因此被广泛用于缓解网络优化中出现的重复梯度信息问题.本文也沿用CSP思想, 将SCBlock结构CSP化, 得到Backbone CSP.Backbone CSP将特征分成两个支路后进行Concat操作, 结果经过BN层、Leaky-ReLu层和CBL层.
优化后的SCNet由Focus层、4个CBL层、4个引入SCBAM的Backbone CSP层和SPP层组成.Focus层将图像切片后连接, 使图像在下采样后仍可保留全部信息.CBL层由卷积层、BN层和LeakyReLu激活函数构成, 对输入特征进行下采样, 得到不同尺度特征图.Backbone CSP层在SCBAM的基础上, 引入残差结构, 增加层与层之间反向传播的梯度值, 防止梯度消失.该层主要用于瑕疵特征的提取.SPP层通过不同大小池化操作, 进行多尺度融合, 增大模型感受野, 提高模型检测效果.
在基于深度学习的目标检测网络中, 底层特征语义信息较少, 但定位信息丰富; 高层特征语义信息丰富, 但定位信息不足.因此, 为了充分利用高层特征的语义信息和底层特征的细粒度特征, YOLOv5采用FPN+PAN(Path Aggregation Network)方式输出多层特征, 如图5所示.FPN采用自顶向下方式, 将骨干网络提取的特征信息进行融合增强, 但因骨干网络中通常会存在大量卷积操作, 导致浅层特征传到输出层时丢失严重, 影响检测定位精度, 见图5中虚线.对此, PAN在FPN后面添加一个自底向上的金字塔, 对FPN进行补充, 缩短低层的强定位特征传递的路径, 有效增强模型对目标检测效果, 见图5中点虚线.
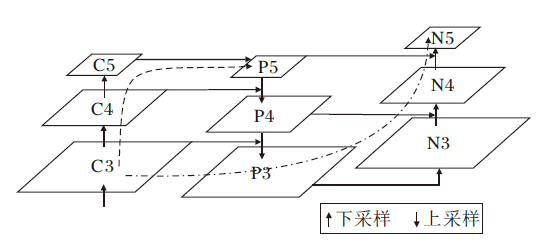 | 图5 FPN+PAN结构Fig.5 FPN+PAN structure |
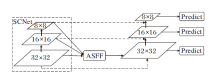
采用FPN+PAN组合方式仍然会产生两个问题:1)在不同特征信息进行融合时, 大多采用concatenation或element-wise此类直接衔接或相加的方法, 然而此类方式并不能充分利用不同尺度的特征信息, 依然会造成对特征信息的丢失; 2)尽管PAN添加一条自底向上的通路, 增强浅层信息的传递, 但同时网络会对浅层特征进行多次融合, 产生混叠效应, 降低特征准确性.针对上述两个问题, 本文设计AMFN, 结构如图6所示.
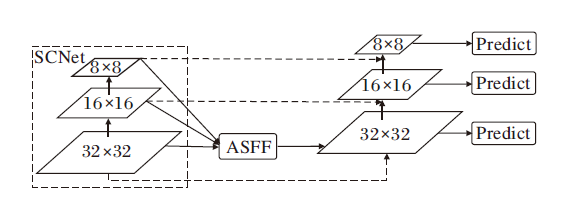 | 图6 AMFN结构Fig.6 AMFN structure |
在图6中, AMFN首先采用ASFF[23]方式融合骨干网络SCNet提取的3个不同尺度基本特征, 在融合之前, 需要将3个不同尺度特征调整到统一尺寸, 然后再根据自适应学习到的权重进行加权融合, 得到融合后的特征:
Iij=α ij
α ij=
β ij=
γ ij=
α ij+β ij+γ ij=1,
其中,
在得到融合特征Iij后, 借鉴PAN思想, 增加一条自底向上的通路, 同时将SCNet输出特征引入特征融合层, 增强对浅层特征的使用.相比FPN+PAN融合方式, AMFN中间融合模块更少, 模型更小.另外, AMFN通过自适应权重对输入特征进行加权融合, 有效融合多尺度特征, 同时增强对浅层信息的利用.因此, AMFN可有效提高检测效果.
在目标检测任务中, IoU(Intersection over Union)的计算通常用于评估RP(Region Proposal)和GT(Ground Truth)之间的相似性, IoU计算值的高低通常也是正负样本挑选的依据.在评估反馈模块中, 表现较优的是CIoU(Complete-IoU), 它考虑重叠区域、中心点距离和长宽比, 定义如下:
$\upsilon =\frac{4}{{{\pi }^{2}}}{{\left( \arctan \left( \frac{{{w}^{gt}}}{{{h}^{gt}}} \right)-\arctan \left( \frac{w}{h} \right) \right)}^{2}}$,
其中, b表示预测框的中心点, bgt表示真实框的中心点, ρ 2表示两点之间的欧氏距离, c表示能同时包含预测框和真实框之间的最小闭包区域的对角线距离, wgt、hgt表示真实框宽和高, w、h表示预测框宽和高.
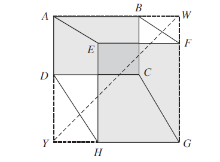
针对纺织品瑕疵形态差异较大、尺度多变的特点, 本文在CIoU基础上引入CDIoU损失[24], 在基本不增加计算开销的前提下提高纺织品瑕疵检测精度.CDIoU计算RP和GT四个坐标点之间的距离以计算损失, 如图7所示.
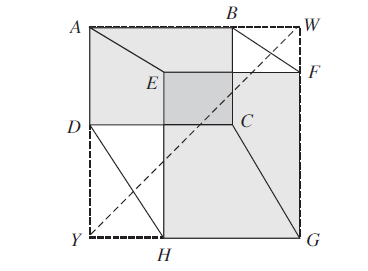 | 图7 CDIoU示意图Fig.7 Sketch map of CDIoU |
CIoU损失的计算公式如下:
其中d为预测框和真实框之间最小闭包区域的对角线距离.
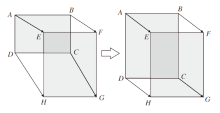
相比CIoU损失, CDIoU多一项diou, 在反向传播之后, 倾向于将RP的4个顶点拉向GT的4个顶点, 直到重叠为止, 如图8所示.
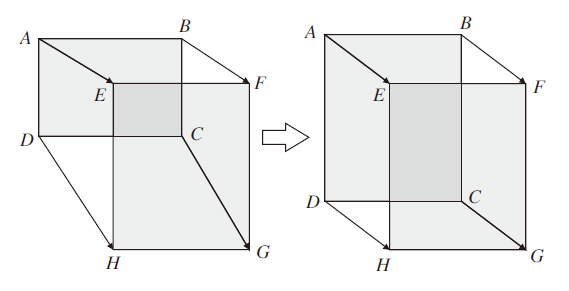 | 图8 CDIoU损失下预测框变化趋势Fig.8 Trend of prediction frame with CDIoU loss |
实验采用Ubuntu操作系统, 处理器为Intel(R) Xeon(R) CPU E5-2678 v3 @2.50 GHz, NVIDIA-Tesla V100 PCIe显卡, 显存32 GB.本次研究均基于PyTorch深度学习框架构建网络模型.实验开发环境为PyTorch1.9.1, cuda11.0, python3.7.
ZJU-Leaper纺织品瑕疵数据集[30]包括多种场景下的多种瑕疵类型, 但并未对瑕疵进行标注和分类.因此, 本文基于该数据集, 利用Matlab中Image Labeler标注工具对数据集上纺织品瑕疵依次进行标注, 最终共标记1 536幅瑕疵图像, 图像大小统一为256× 256, 背景分为素色和花纹两种类型, 瑕疵类型分为4类:污渍、破损、褶皱、油污, 各类瑕疵标签数量如表1所示.
| 表1 ZJU-Leaper纺织品瑕疵数据集标签统计 Table 1 Label statistics of ZJU-Leaper textile defect dataset |
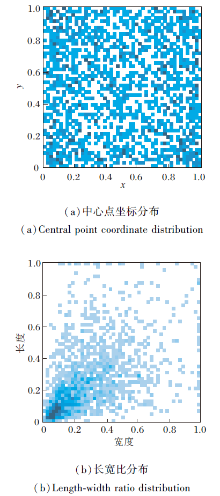
实验中将数据集分为训练集和测试集, 比例为3∶ 1, 即训练集为1 152幅图像, 测试集为384幅图像.图9为该数据集瑕疵位置和长宽比分布图, 图中小方块表示一个瑕疵标签, 尺度均进行归一化处理.由图可知, 瑕疵位置分布较均衡, 长宽比分布较集中.标记后的纺织品瑕疵图像示例如图10所示.
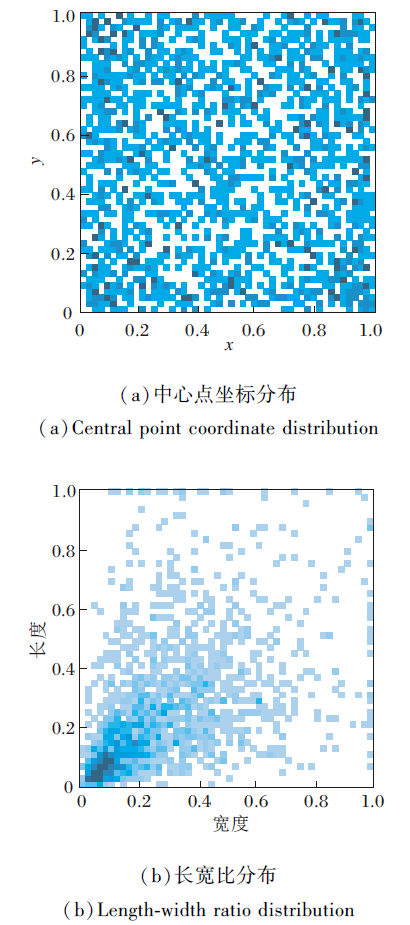 | 图9 ZJU-Leaper纺织品瑕疵数据集标签分布Fig.9 Distribution of labels of ZJU-Leaper textile defect dataset |
 | 图10 ZJU-Leaper纺织品瑕疵数据集图像示例Fig.10 Examples of ZJU-Leaper textile defect dataset |
天池纺织品瑕疵数据集采集于佛山南海纺织车间, 图像数量共706幅, 大小为2 560× 1 920, 瑕疵共分为8种类型:擦洞、缺经、扎洞、织稀、跳花、毛洞、吊经、毛斑.实验前使用翻转、旋转、尺度变换、随机抠取、色彩抖动等数据增强方法, 将图像数量扩充到5 520幅, 各类瑕疵标签数量如表2所示.
| 表2 天池纺织品瑕疵数据集标签统计 Table 2 Label statistics of Tianchi textile defect dataset |
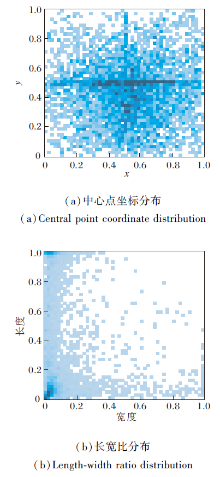
实验时将数据集分为训练集和测试集, 比例为3∶ 1, 即训练集为4 140幅图像, 测试集为1 380幅图像.为了加快模型训练速度, 实验时统一将图像尺寸调整为512× 512.该数据集标签分布情况如图11所示, 尺度均进行归一化处理.
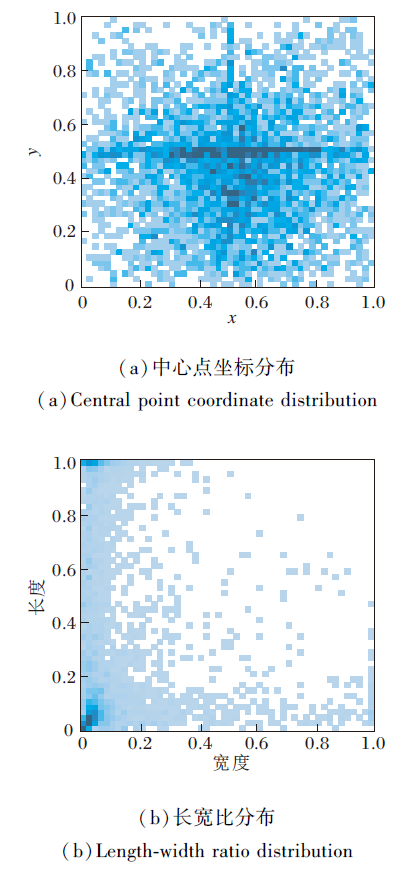 | 图11 天池纺织品瑕疵数据集标签分布Fig.11 Distribution of labels of Tianchi textile defect dataset |
由图11可知, 该数据集瑕疵位置分布较集中, 长宽比分布较分散, 这表明该数据集瑕疵尺度变化较大.标记后的纺织品瑕疵图像示例如图12所示.
 | 图12 天池纺织品瑕疵数据集示例Fig.12 Examples of Tianchi textile defect dataset |
本文选择mAP@0.5和mAP@0.5∶ 0.95作为评价指标, mAP@0.5表示IoU阈值设为0.5时, 所有类别的平均AP, mAP@0.5∶ 0.95表示在不同IoU阈值下的平均mAP, 下面实验中mAP@0.5∶ 0.95均由mAP表示.因此需要计算模型的精确率(Precision)和召回率(Recall).
具体指标值公式如下:
其中:TP(True Positive)为检测正确的正样本个数; FP(False Positive)为检测错误的正样本个数; FN(False Negative)为检测错误的负样本个数.
在CDIoU损失函数中, 为了选取最有效的超参数λ , 取λ =1.0, 0.1, 0.01, 0.001, 在ZJU-Leaper纺织品瑕疵数据集上的实验结果如表3所示, 表中黑体数字表示最优值.由表可知, 当λ =0.01时, mAP@0.5和mAP达到最优值, 显著高于取其它参数值时的精度.分析其原因:当λ 取值较大时, 模型在训练后期, diou项梯度过大, 导致模型难以收敛到更高精度; 当λ 取值过小时, diou项权重过小, 难以提高模型收敛效果.因此, 本文模型选择λ =0.01, 此时模型对于纺织品瑕疵的检测效果最佳.
| 表3 λ 不同时的实验结果 Table 3 Experimental results with different λ |
为了验证本文模型的有效性, 在ZJU-Leaper纺织品瑕疵数据集上进行消融实验, 评估SCBAM、AMFN和CDIoU对纺织品瑕疵检测的效果.实验以YOLOv5为基础模型, 检测结果对比见图13.实验图像输入大小统一为256× 256.
 | 图13 YOLOv5和SCNet+AMFN检测结果对比Fig.13 Detection result comparison of YOLOv5 and SCNet+AMFN |
在YOLOv5s中分别引入CBAM、SCBAM、AMFN、CDIoU, 具体消融实验结果如表4所示, 表中黑体数字表示最优值.
| 表4 各模块消融实验对比 Table 4 Comparison of ablation experiments of different modules |
由表4可知, 引入CBAM和SCBAM之后, 检测精度均有所提高, 但引入SCBAM后, 精度提升更明显, 相比YOLOv5s, mAP@0.5提高1%, mAP提高0.5%, 这表明SCBAM有效并有助于纺织品瑕疵的检测.
另外, 本文测试AMFN的有效性.AMFN由于减少特征融合模块的数量, 降低模型大小, 但需要额外计算自适应权重, 这也导致检测速度略有下降.最后, 将CDIoU损失函数引入模型损失计算中, mAP@0.5和mAP都有所提升.上述实验表明, 本文模型均具有一定效果, 有助于提高纺织品瑕疵的检测精度.
为了进一步衡量本文模型对于纺织品瑕疵检测的性能, 在ZJU-Leaper纺织品瑕疵数据集、天池纺织品瑕疵数据集上将选择如下对比模型:Faster R-CNN[15]、Cascade R-CNN[18]、YOLOv3[20]、YOLO-v4[21]、YOLOv5[31]、YOLOX[32]、YOLOR(You Only Learn One Representation)[33], 其中, YOLOv5选择YOLOv5s、YOLOv5m和YOLOv5l版本, YOLOX选择YOLOX-s版本、YOLOR选择YOLOR-P6和YOLOR-CSP版本.
各模型在ZJU-Leaper数据集上的实验结果如表5所示, 表中黑体数字表示最优值.由表可知, 相比基线模型YOLOv5s, 本文模型的mAP@0.5提升2.6%, mAP提升1.5%.特别是在褶皱类瑕疵检测任务上, 本文模型mAP@0.5提升5.2%, mAP值提升2.5%, 这得益于AMFN既能有效融合瑕疵特征又能增强对浅层定位信息的传递, 因此AMFN显著提高对背景重合度较高、不易区分的瑕疵检测精度.虽然本文模型的mAP值未达到最高, 相比YOLOX-s, 相差0.5%, 但本文模型检测速度达到500帧/秒, 比YOLOX-s加快65%, 并且模型大小仅有13.6M, 显著低于其它模型.另外, 对于油污类瑕疵, 由于该类瑕疵样本较少, 模型对于该类瑕疵提取到的特征不足, 导致精度较差, 这也表明本文模型对于小样本的特征提取能力还有待提高.
| 表5 各模型在ZJU-Leaper数据集上的实验结果对比 Table 5 Experimental result comparison of different models on ZJU-Leaper dataset |
此外, 为了进一步验证本文模型的适用性和广泛性, 在天池纺织品瑕疵数据集上, 进行对比实验, 实验中输入图像大小统一为512× 512, 实验结果如表6所示, 表中黑体数字表示最优值.由表可知, 本文模型在精度和速度上超过大部分现有网络, 而模型大小仅有13.6 M, 低于其它模型.YOLOv5l和YOLOR-CSP由于其强大的参数拟合能力, 与本文模型取得相当的检测精度, 但参数量过多、模型运算量较大, 导致检测速度低于本文模型.另外, 在ZJU-Leaper纺织品瑕疵数据集上表现优异的YOLOX-s, 在天池纺织品瑕疵数据集上检测效果却不佳.原因是天池瑕疵数据集上各类瑕疵尺度变化明显且长宽比差异过大, 使该数据集对于基于无锚点的YOLOX-s并不友好.
| 表6 各模型在天池纺织品数据集上的实验结果对比 Table 6 Experimental result comparison of different models on Tianchi textile dataset |
本文模型在2个数据集上检测效果较优, 检测速度较快, 模型尺度较小, 这表明本文模型具有良好的适用性和广泛性, 能满足实际应用需要.
本文针对纺织品瑕疵检测任务, 提出结合注意力机制与自适应记忆性融合网络的纺织品瑕疵检测模型(SCNet+AMFN).在YOLOv5骨干网络中引入改进的注意力模块SCBAM, 构建骨干网络SCNet, 获取更多瑕疵细节特征, 提高模型对纺织品瑕疵特征的表征能力.然后, 设计自适应记忆性融合网络(AMFN), 学习空间滤波冲突信息, 抑制特征尺度不一致性, 同时利用浅层特征增强对目标的定位和检测效果.此外, 引入CDIoU损失函数, 在基本不增加计算开销的前提下提高瑕疵检测精度.实验表明, 本文模型在纺织品瑕疵数据集上取得较优检测效果.下一步工作是解决模型对于小样本特征提取能力不足的问题, 进一步优化本文模型.同时, 扩建纺织品瑕疵数据集, 标注更多种类纺织品瑕疵, 包括断纬、粗经、粗纬、扭结等瑕疵类型, 提高模型的检测能力.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|