











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
YOLOv5上融合多特征的实时火焰检测方法
[张大胜1  , 肖汉光
, 肖汉光1 , 文杰2, 3 , 徐勇2, 3 ]
, 肖汉光, 文杰, 徐勇]
|
|



作者简介:
张大胜,硕士研究生,主要研究方向为计算机视觉、图像处理、目标检测.E-mail:dashengzhangxm@163.com.
文 杰,博士,助理教授,主要研究方向为机器学习、模式识别.E-mail:jiewen_pr@126.com.
徐 勇,博士,教授,主要研究方向为模式识别、图像处理、深度学习、生物特征识别、生物信息学.E-mail:laterfall@hit.edu.cn.
在自然场景中,天气情况、光照强度、背景干扰等问题影响火焰检测的准确性.为了实现复杂场景下实时准确的火焰检测,在目标检测网络YOLOv5的基础上,结合Focal Loss焦点损失函数、CIoU(Complete Intersection over Union)损失函数与多特征融合,提出实时高效的火焰检测方法.为了缓解正负样本不均衡问题,并充分利用困难样本的信息,引入焦点损失函数,同时结合火焰静态特征和动态特征,设计多特征融合方法,达到剔除误报火焰的目的.针对国内外缺乏火焰数据集的问题,构建大规模、高质量的十万量级火焰数据集(http://www.yongxu.org/databases.html).实验表明,文中方法在准确率、速度、精度和泛化能力等方面均有明显提升,同时降低误报率.
About Author:
ZHANG Dasheng, master student. His research interests include computer vision, image processing and object detection.
WEN Jie, Ph.D., assistant professor. His research interests include machine learning and pattern recognition.
XU Yong, Ph.D., professor. His research interests include pattern recognition, image processing, deep learning, biometric recognition and bio-informatics.
In natural scenes, the accuracy of fire detection is affected by weather conditions, light intensity and background interference. To achieve real-time accurate fire detection in complex scenarios, a real-time efficient fire detection method based on improved YOLOv5 is proposed. The proposed method is combined with Focal Loss, complete intersection over union loss function and multi-feature fusion to detect fires in real time. The focal loss function is introduced to alleviate the imbalance between positive and negative samples and make full use of the information of difficult samples. Meanwhile, combining the static and dynamic features of fires, a multi-feature fusion method is designed to eliminate false alarm fires. Aiming at the lack of fire datasets at home and abroad, a large-scale and high-quality fire dataset of 100 000 magnitude is constructed(http://www.yongxu.org/databases.html). Experiments show that the accuracy, speed, precision and generalization ability of the proposed method are significantly improved.
本文责任编委 王士同
Recommended by Associate Editor WANG Shitong
目前的火焰监测主要使用烟雾传感器与温度传感器[1].传统火焰传感器凭借廉价、易用的优势被广泛应用, 然而此类传感器仅限于小型封闭式空间, 无法满足大空间和室外等场景下的火焰检测.近年来, 随着视频摄像头的广泛使用和图像处理技术的快速发展, 基于视频监控的火焰检测技术被广泛应用于安防领域[2].相比传统火焰传感器, 视频火焰检测技术具有识别速度较快、泛化能力较强等优势.
传统的火焰检测方法主要依赖于多特征融合, 通过提取火焰的静态特征和动态特征进行判识.Prema等[3]分析森林场景中火焰的颜色空间和纹理, 基于YCbCr颜色空间获取火焰区域, 并通过混合纹理特征检测候选火焰区域.Zhu等[4]使用梯度特征(Gradient Features)表示RGB通道中的颜色变化, 并应用支持向量机和决策树模型判断火焰区域, 但该模型对光照强度敏感, 泛化性能较差.Chen等[5]提出基于RGB颜色模型的聚类方法, 获取疑似火焰区域, 再提取火焰闪烁频率, 判别是否为火焰, 但在火灾初始阶段假阳率较高, 实时性能不佳.Zhang等[6]提出基于RGB和HIS的色彩空间模型, 提取疑似火焰区域, 并结合三帧差分法和ViBe背景差分算法识别火焰.上述火焰检测方法在一定程度上能有效检测火焰, 但存在大量误检和漏检, 火焰检测速度较慢.
近年来, 深度学习在目标检测领域取得突破性进展, 目标检测的精确度和效率都得到大幅提升[7, 8].Muhammad等[9]提出基于GoogleNet架构的高效卷积神经网络模型, 但火焰检测时误报率较高.Cai等[10]提出基于改进深度卷积神经网络的火焰检测方法, 使用全局平均池化代替全连接层, 防止模型过拟合并提高检测速度, 但未在大型公开火焰数据集上进行验证.Kim等[11]提出基于深度学习的火焰检测方法, 采用Faster R-CNN(Faster Region-Based Convolutional Neural Network)[12]检测可疑火焰区域后, 再利用长短期记忆网络(Long-Short Term Me-mory Neural Network, LSTM)[13]进行分类, 但网络参数量过大, 检测速度较慢.Muhammad等[14]提出较小卷积核且较低计算量的卷积神经网络(Convo-lutional Neural Network, CNN)架构, 实现检测速度的提升.Wang等[15]提出基于火焰颜色特征和运动特征的两阶段火焰检测方法, 使用帧差法和颜色阈值确定火焰区域, 再对火焰区域进行二次判识, 但无法实时检测火焰.白岩等[16]运用运动学理论、特征提取、CNN等方法, 克服传统方法对室内烟雾和火焰识别不准确的缺点, 但缺少足够的火焰训练数据供给模型学习, 导致泛化能力不强.Chaoxia等[17]提出信息引导的火焰检测方法, 采用并行网络生成图像全局信息, 并改进Faster R-CNN, 执行火焰检测, 但R-CNN(Region CNN)[18]和GIN(Global Informa-tion Network)共享特征图时计算量较大, 方法难以满足实际应用需求.Choueiri等[19]提出基于人工神经网络的火焰检测方法, 借助传感器辅助估计火焰.Zhang等[20]提出改进的特征提取方法, 利用火焰的形态特征(如圆度、矩形)消除干扰, 但在火焰早期检测精度较低.Saponara等[21]提出基于YOLOv2(YOLO9000: Better, Faster, Stronger)[22]的实时视频火焰检测方法, 并部署在低成本的嵌入式设备, 但精度仍有待提高.Shahid等[23]通过时空网络结合火焰形状和运动频闪特征获得候选区, 再利用分类器对火焰候选区域进行二次甄别.李欣健等[24]使用深度可分离卷积设计轻量化火焰检测方法, 实现准确性和速度的提升, 但疑似火焰误报问题仍有待进一步改善.Xu等[25]提出集成学习方法检测森林火焰, 采用集成模型综合得分判识火焰, 在一定程度上降低误报率, 但网络结构十分复杂, 导致检测速度较慢.
YOLOv5(You Only Look Once Version5)轻量、灵活、易用, 是当前通用的目标检测算法之一.文献[26]采用缩放、色彩空间调整和Mosaic数据增强策略, 其中Mosaic数据增强将4幅图像以随机缩放、随机裁剪、随机分布方式进行拼接.主干网络使用CSPNet(Cross Stage Partial Network)[26], 从图像中提取丰富的特征信息.YOLOv5凭借较强的灵活性和较高的推理速度, 被应用于不同对象的检测中, 但由于火焰数据样本不均衡、对光照变化敏感、容易受背景干扰等因素, 火焰识别率较低且存在大量真实火焰漏检和疑似火焰误检的问题, 该模型无法直接应用于火焰检测.
为了解决上述问题, 本文提出YOLOv5融合多特征的实时火焰检测方法.在YOLOv5中引入Focal Loss损失函数[27], 解决火焰检测中正负样本严重失衡的问题.同时为了解决GIoU(Generalized Intersec-tion over Union)收敛较慢的问题, 并提高回归精度, 利用CIoU(Complete Intersection over Union)损失函数[28], 进一步加速收敛并提升性能.结合火焰静态特征和动态特征, 对候选火焰区域进行二次判别.对YOLOv5检测结果区域进行颜色特征、相邻帧差和时序信息分析, 在一定程度上消除由于环境光照变化和易混疑似背景干扰引起的误报, 实现实时高效的火焰检测方法.针对火焰数据集缺少的问题, 建立大型高质量的十万量级火焰数据集(http://www.yongxu.org/databases.html), 采集大量不同场景下的火焰图像, 提升数据的多样性.最后, 在多个公开火焰数据集上评估方法, 实验表明, 本文方法不仅有效降低误报率, 而且拥有实时检测的速度.
自然场景下的火焰检测任务主要存在如下3个困难:1)由于火焰训练数据集存在正负样本、难易样本极度不均衡问题, 同时实现低误报率与低漏报率是一个很大的挑战.在应用深度网络进行火焰检测时, 仍存在收敛效率与火焰检测精度不高的问题.2)火焰的纹理、尖角、边缘、频闪等特征具有多样性和不确定性, 并且现实世界中存在大量易混疑似火焰图像, 基于单一模型的火焰检测方法无法有效剔除并解决问题.3)自然场景中火焰易受光照强度变化、天气情况的改变、易混疑似背景等因素的干扰, YOLOv5无法适应全天候实时火焰检测.
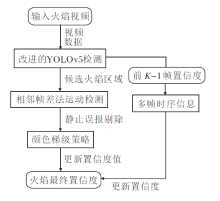
为了解决上述问题, 本文设计YOLOv5融合多特征的实时火焰检测方法, 总体流程如图1所示.
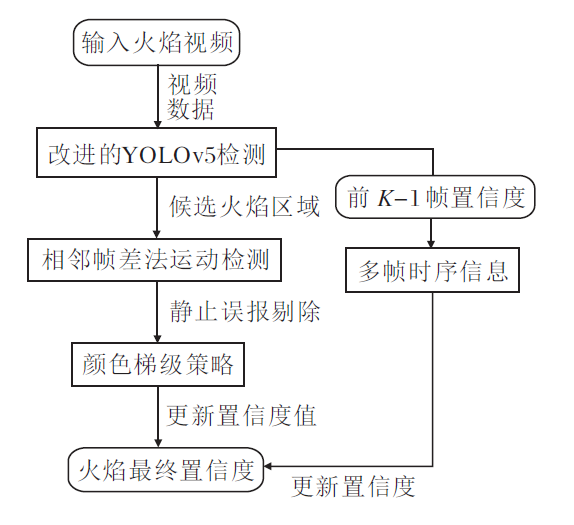 | 图1 本文方法总体流程Fig.1 Flow chart of the proposed method |
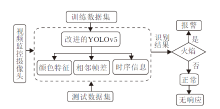
本文方法首先利用改进的YOLOv5进行火焰的初步检测, 得出候选火焰区域.然后利用设计的误报剔除策略和视频序列的信息, 去除候选火焰区域中存在的虚假火焰区域, 最终保留的火焰区域被认为是真正的火焰区域.误报剔除策略同时利用火焰的动态信息与静态颜色信息, 具体包括视频中对应候选火焰区域的帧差时序信息及RGB与HIS颜色空间中的信息.方法涉及的深度网络与模型训练及应用的流程如图2所示.
 | 图2 深度网络、模型训练及应用流程Fig.2 Flow chart of deep network, model training and model application |
类别不均衡是影响火焰检测模型精度的一大难点, 其中最严重的是正负样本不均衡问题, 因为一幅火焰图像中前景、背景类别极度不平衡, 只有很少一部分包含真实火焰.易分负样本过多会主导梯度和损失, 导致模型进行无效学习, 不能较好地学习检测火焰区域.针对火焰检测的特点, 为了缓解正负样本不均衡的问题并充分利用困难样本的信息, 在YOLOv5网络中使用Focal Loss损失函数和CIoU损失函数, 最大程度辨识真实火焰区域.
Focal Loss损失函数基于标准交叉熵损失, 能动态调整训练过程中简单样本的权重, 使模型更专注于困难样本.标准交叉熵可表示为
其中, p表示预测样本属于1的概率, y表示类别标签, 取值为± 1.为了解决类别不均衡问题, 引入权重因子α , 定义
则均衡交叉熵(α -balanced CE) 可表示为
CE(pt)=-α tln pt.
虽然α 能平衡正负样本, 但不能区分难易样本.Focal Loss降低简单样本的权重, 并专注于对困难样本的训练, 具体可表示为
FL(pt)=-α t(1-pt)γ ln pt.
其中:α t表示样本权重, 用于平衡正负样本, 解决样本的不平衡问题; (1-pt)γ 表示调节因子, 减少简单样本对损失函数的影响, 使模型专注于难分类的样本, 解决难易样本不平衡的问题.
本文引入改进标准的二元交叉熵损失函数, 控制对正负样本的训练, 消除由于火焰数据正负样本比例严重失衡引起的检测精度下降的问题.
目标检测模型的损失函数包括类别损失和位置损失, 损失函数的主要功能是使火焰识别准确率更高, 定位更精确.YOLOv5采用GIoU Loss计算边界框(Bounding Box)回归损失.GIoU Loss可表示为
GIoU=IoU-
其中, A、B表示2个任意框, C表示2个框的最小外接矩阵面积.GIoU包含IoU(Intersection over Union)所有的优点, 同时克服IoU损失在检测框不重叠时出现的梯度问题.但是, 由于严重依赖IoU项, GIoU收敛较慢.
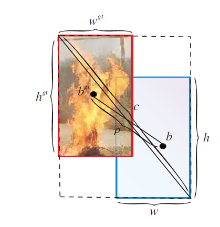
为了解决GIoU收敛较慢的问题并提高回归精度, 同时考虑框回归的三要素(重叠区域、中心点距离、宽高比), 本文使用CIoU损失函数, 进一步加速收敛和提升性能.CIoU损失函数可表示为
LCIoU=1-IoU+
CIoU在IoU损失的基础上增加惩罚项
RCIoU=
其中
α =
为权重函数,
$v=\frac{4}{{{\pi }^{2}}}{{\left( \arctan \left( \frac{{{w}^{gt}}}{{{h}^{gt}}} \right)-\arctan \left( \frac{w}{h} \right) \right)}^{2}}$,
度量长宽比的相似性, wgt、hgt表示真实框的宽和高, w、h表示预测框的宽和高.CIoU参数信息如图3所示.
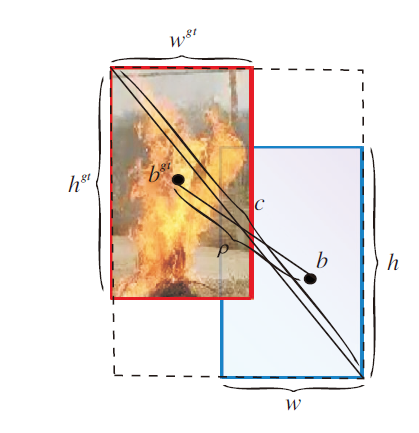 | 图3 CIoU参数示意图Fig.3 Illustration of CIoU parameters |
在不同场景下采集82 443幅真实火焰数据图像和17 312幅易混疑似火焰数据图像.改进的YOLOv5适合对正样本火焰的检测.负样本包括室内外各种光照强度、不同天气情况和易混疑似背景等场景, 检测结果存在较多误检情况, 必须通过后处理机制进一步剔除误报.
本文基于模型检测得出的候选火焰区域进行后处理, 提取火焰颜色特征、运动特征和多帧时序信息并进一步过滤, 使用火焰静/动态特征剔除误检目标后, 最终得到置信度较高的火焰区域.本文同时发现, 限定适量疑似易混火焰图像作为负样本, 能有效增强算法的鲁棒性和准确性.
1.2.1 火焰颜色梯级策略
基于火焰独有的颜色特征, 结合Chen等[29]提出的RGB和HIS判断依据, 对模型检测截取的候选火焰区域进行二次筛选判别, 提高火焰检测方法整体准确度.RGB和HIS约束规则可表示如下:
Rule1 R≥ G> B;
Rule2 R> RT, RT∈ [115, 135];
Rule3 S≥ (255-R)
其中:RT表示红色分量阈值, ST表示饱和度阈值.选择合适的阈值条件至关重要, 本文将RT红色分量阈值设为115, ST饱和度阈值设为60.先利用RGB和HIS约束规则筛选候选火焰截图, 再将图像进行二值化处理, 并通过中值滤波消除噪声干扰, 使用形态学膨胀操作连接相邻元素, 最后得到火焰轮廓区域.
火焰颜色特征提取流程如图4所示.颜色模型轮廓检测结果如图5所示.
 | 图4 火焰颜色特征提取流程Fig.4 Fire color feature extraction process |
 | 图5 颜色模型轮廓检测结果Fig.5 Results of color model contour detection |
研究颜色特征轮廓区域图发现, 对于改进的YOLOv5检测结果截取后的候选火焰区域图像, 真实火焰图像颜色轮廓面积与候选区域总面积占比较高, 且误报火焰图像占比极低.本文根据颜色轮廓面积与候选区域总面积占比大小, 建立颜色梯级模型.通过实验选择合适阈值对不同梯级占比进行抑扬, 剔除部分误报疑似火焰.选取22 231幅真实火焰图像和1 914幅误报火焰图像进行实验, 最终得出合理的占比高低阈值(0.2和0.05).当占比大于上限阈值时, 认为存在真实火焰, 并进行置信度增强.当占比小于下限阈值时, 认为不存在火焰, 并进行置信度削弱, 抑制疑似火焰图像误检.不同的颜色轮廓占比阈值对应的误报统计结果如表1所示.
| 表1 不同颜色轮廓占比阈值的误报统计信息 Table 1 False positive statistics for different color contour percentage thresholds |
由表1可见, 当轮廓占比阈值取0.05时, 误报率为0.106, 能达到误报和漏报的折衷.因此, 当颜色轮廓占比低于0.05时, 对其置信度进行梯级抑制.由于大多数真实火焰图像颜色轮廓占比高于0.2, 对其置信度进行梯级增强.通过火焰颜色梯级策略, 能较好地抑制疑似火焰图像误检, 最终达到提升本文方法在自然场景下检测精度的效果.
1.2.2 火焰区域运动特征策略
在火焰检测中存在大量误检的静止目标, 该类目标与真实火焰具有相似的颜色、形状、尖角和纹理等特征, 但不具备运动趋势.然而, 由于火焰本身的特点, 火焰在燃烧过程中总有运动趋势, 因此可对改进的YOLOv5检测的候选火焰区域进行运动检测, 剔除静止目标误检.
帧差法[30]是较常见的运动目标检测算法, 具有运行速度较快, 对环境光照变化不敏感等优势.本文通过对视频图像中连续N帧图像进行差分运算, 获得运动目标的轮廓.由于候选火焰区域背景基本静止不变, 只有当出现火焰目标运动时, 相邻帧图像间才会出现明显的差别, 因此可分析物体的运动特征, 具体公式如下:
其中, D(x, y)表示连续两帧间差分图像, I(t-1)、I(t)表示前后帧图像, Threshold表示差分图像二值化时阈值.
本文使用相邻帧差法进行运动检测, 对当前候选火焰区域与前一帧候选火焰区域进行差分运算, 获得运动目标轮廓总面积.若轮廓总面积不小于Tarea, 符合火焰运动特征, 否则剔除当前静态目标误检.实验中N=2, Tarea=300.
1.2.3 火焰视频多帧时序策略
针对视频火焰数据, 为了充分挖掘视频前后帧时序信息, 提高火焰检测准确率并有效降低误报率, 基于统计滤波的思想, 本文提出多帧时序信息策略.多帧时序策略类似于一个面向分类的“ 级联过滤器” , 即只有在连续的多个帧都判别为火焰时, 才认为视频中存在“ 真正的” 火焰, 这样可有效应对深度模型产生的火焰误报.
计算前K-1帧与当前帧图像置信度均值, 作为当前帧最终得分, 利用火焰多帧置信度平均法, 有效降低异常疑似火焰的单帧误报.多帧策略能有效抑制单帧疑似火焰误报, 并显著提高真实火焰置信度.多帧时序均值如下所示:
$Con{{f}_{1}}=Con{{f}_{2}}=\cdots =Con{{f}_{K-1}}=threshold\text{ K}\ge 2$
$Con{{f}_{n}}\text{=}\left\{ \begin{matrix} Con{{f}_{n-1}}=Con{{f}_{n-2}}=\cdots =Con{{f}_{n-K+2}}=0\text{ }fire=False \\ \frac{1}{K}\left( Con{{f}_{n}}+Con{{f}_{n-1}}+\ldots +Con{{f}_{n-K+1}} \right)\text{ }fire=True \\\end{matrix} \right.$
其中, Confn表示视频中第n帧图像置信度, K表示进行平均的帧数, threshold表示判定为真实火焰的阈值.第1个公式为初始化前K-1帧图像置信度等于真实火焰阈值.在第2个公式中, 当前帧判定为非火焰时, 设置其前K-2帧图像置信度为0, 当前帧判定为火焰时, 利用多帧时序信息设置当前帧置信度为当前帧与前K-1帧的均值.
多帧时序策略流程如图6所示.该策略充分挖掘多帧间时序信息, 利用多帧置信度平均法, 能有效过滤非连续单帧误报, 并提升连续多帧真实火焰的检测.实验中K=3.
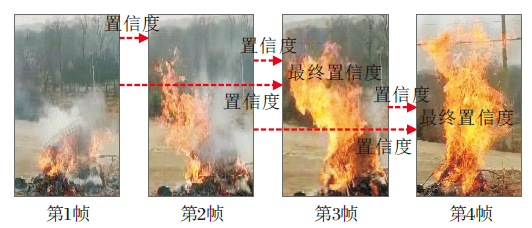 | 图6 多帧时序策略流程图Fig.6 Flow chart of multi-frame strategy |
实验中使用的平台是AMD R7-5800H 3.2 GHz和NVIDIA GeForce RTX 2060(6 GB独显).实验开发环境为Python, 火焰检测模型由PyTorch框架构建.
在计算机视觉领域, 数据集发挥重要作用, 数据驱动模型.大规模、高质量、多场景的标注数据集有助于充分释放模型性能.然而, 由于数据集采集和数据标注需要昂贵的人力成本, 目前公开可用的火焰数据集相对较少.因此, 本文构建一个大规模、高质量的火焰数据集, 包括远距离、多目标、小目标、不同光照条件、黑夜条件下的82 443幅真实火焰图像和17 312幅易混疑似火焰图像.为了保证数据集规范化, 本文对数据集进行统一格式化命名并逐幅标注.
为了得到不同质量火焰数据, 通过筛选分类将数据集分为best(优质火焰)、good(良好火焰)、normal(一般火焰)、special(特殊火焰)、nofire(易混火焰)5类, 其中易混火焰用作负样本训练模型.
本文使用收集的部分数据训练模型, 使用剩余数据验证模型性能.应用数据集上标注的5类数据, 不仅可充分测试模型性能, 而且有利于观察模型在不同情况下的表现, 并据此对模型进行有针对性的进一步训练, 降低模型的误报率和漏报率.同时, 本文发现, 建立火焰检测数据集时, 负样本限定为疑似火焰图像是一个较好的办法, 有利于训练出结果更优的模型和方法.
2.1.1 火焰图像采集
在火焰图像采集过程中, 为了确保训练数据集的多样性和丰富性, 提高模型泛化性能, 本文收集不同来源的火焰图像.同时为了有效降低误报率, 收集大量容易混淆的疑似火焰图像作为负样本.数据集主要来源包括公开视频集(MIVIA[2]、KMU CVPR Lab Fire[31]、Bilkent University火焰视频库、Ultimate Chase视频火焰数据集)、Corsician Fire数据集、BoWFire数据集[32]、MS COCO2014数据集、互联网火焰图像数据集(百度、谷歌)、自建火焰图像数据集.该数据集以自建火焰图像为主, 详细统计信息如表2所示.
| 表2 数据集详细统计信息 Table 2 Detailed information of datasets |
本文在不同场景和不同天气与光照情况下拍摄71 523幅真实火焰的图像, 注重小目标火焰图像的采集.这些图像可用于提升模型的泛化性能和鲁棒性.真实火焰数据集样本如图7所示, 包括实地拍摄图像与收集的火焰图像.
 | 图7 真实火焰数据集样本示例Fig.7 Samples of real flame dataset |
由图7可知, 本文提出的火焰数据集场景丰富, 质量较高.在火焰图像采集过程中, 人工制造火焰并通过手机、摄像机等移动设备拍摄录制火焰数据, 再对视频数据每隔20帧进行分帧保存火焰图像.最终收集到的火焰数据集涵盖室内、室外、白天、黑夜、森林、工厂、房屋、池塘、公路、山地等不同场景, 较好地拟合不同实际场景.
同时为了解决样本不均衡问题和提升模型泛化性能, 本文收集17 312幅易混火焰.易混疑似火焰图像如图8所示.
 | 图8 易混疑似火焰样本示例Fig.8 Samples of easily confused suspected flames |
针对负样本, 本文提出的数据集涵盖朝霞、夕阳、汽车尾灯、卧室灯光、路灯、橙色衣物、枯树叶等疑似火焰.
2.1.2 火焰图像标注
由于采集的火焰图像均无标签数据, 因此本文使用LabelImg标注工具逐一标注每幅火焰图像, 并保存成VOC格式.对于负样本图像, 生成YOLO格式空标签并存储在txt文件中.为了保证82 443幅火焰图像的一致性和高质量, 所有标签数据都逐一标注并手动多轮交叉检查.经过1 800多个工时的艰苦工作, 完成整个数据集中火焰区域的精确标记.
2.1.3 图像分类筛选
为了验证不同质量数据集对方法性能的影响, 本文通过筛选分类, 将全部数据集分为5类.数据集分类统计信息如表3所示.由表可知, 把数据集分为5类的同时, 为了保证数据集的可扩充性, 对所有数据集进行统一规范化命名, 方便后续补充丰富数据集.
| 表3 数据集分类统计信息 Table 3 Dataset classification statistics |
为了评估方法性能, 本文使用的评价指标包括精确率(Precision, P)、召回率(Recall, R)、综合评价指标(F-Measure)、准确率(Accuracy, ACC)、误报率(False Positive Rate, FPR)、漏报率(False Negative Rate, FNR).精确率反映模型正确预测正样本精度的能力, 召回率反映模型正确预测正样本全度的能力, F-Measure是精确率和召回率的加权调和平均.准确率反映模型判断正确的能力, 误报率反映模型正确预测正样本纯度的能力, 漏报率反映模型正确预测负样本纯度的能力.精确率、召回率越大, 模型性能越优.误报率、漏报率值越小, 模型性能越优.评价指标定义如下:
$P=\frac{TP}{TP+FP}$,
$R=\frac{TP}{TP+FN}=\frac{TP}{{{N}_{P}}}$,
$F-Measure=\frac{2\cdot P\cdot R}{P+R}$,
$ACC=\frac{TP+TN}{{{N}_{P}}+{{N}_{N}}}$,
$FPR=\frac{FP}{FP+TN}=\frac{FP}{{{N}_{N}}}$,
$FNR=\frac{FN}{TP+FN}=\frac{FN}{{{N}_{P}}}$,
其中, NP表示真实火焰样例数, NN表示非火焰样例数, TP(True Positive)表示真实火焰被正确预测数, FN(False Negative)表示真实火焰被错误预测数, FP(False Positive)表示非火焰被错误预测数, TN(True Negative)表示非火焰被正确预测数.
2.3.1 BoWFire数据集上实验结果
BoWFire数据集较小却十分经典, 包含大量与真实火焰高度相似、容易混淆的负样本, 如夕阳、晚霞、强光、夜景等场景.因此检测时具有挑战性.BoWFire数据集样例信息如图9所示.
 | 图9 BoWFire数据集样例信息Fig.9 Samples of BoWFire dataset |
本文选择如下对比方法:文献[9]方法、文献[14]方法、文献[17]方法、文献[29]方法、文献[32]方法.文献[9]方法和文献[14]方法使用SqueezeNet和MobileNet.文献[17]方法使用Faster R-CNN进行检测.文献[32]方法整合颜色、纹理特征进行检测.
各方法在BoWFire数据集上的性能对比如表4所示, 表中黑体数字表示最优值.由表可知, 本文方法在精确率、F-Measure、误报率、准确率等指标上优于其它方法, 在速度方面也较好地达到实时性要求.
| 表4 各方法在BoWFire数据集上的性能对比 Table 4 Performance comparison of different methods on BoWFire dataset |
在BoWFire数据集的119幅火焰图像和107幅非火焰图像上, 本文方法漏报7幅火焰图像, 误报4幅非火焰图像.本文方法具体检测效果如图10所示.
 | 图10 本文方法在BoWFire数据集上的检测效果Fig.10 Detection results of the proposed method on BoWFire dataset |
2.3.2 MIVIA数据集上实验结果
MIVIA数据集[2]包含从真实环境中获取的31个视频.其中前14个视频为真实火焰, 包括室外、室内、远距离、森林等不同场景火焰.后17个视频为非火焰数据, 包含移动中的红色物体、森林烟雾、疑似云朵等干扰信息.MIVIA数据集需要申请权限下载, 难以获得.
本文鉴于MIVIA数据集上31个视频中27个来自土耳其Bilkent大学火焰视频库, 其余4个视频由作者拍摄.因此, 使用收集自Bilkent大学的27个视频及1个作者拍摄视频用于实验.MIVIA数据集样例信息如图11所示.
 | 图11 MIVIA数据集样例信息Fig.11 Samples of MIVIA dataset |
由图11可见, MIVIA数据集场景丰富, 贴切现实世界, 包含庭院火焰(伴随人员移动干扰)、400米远距离火焰、山林人为火焰、室内小火焰及存在大量云烟、山雾、红色建筑、暖色强光、移动物体干扰下的疑似火焰视频, 检测难度较大.
鉴于MIVIA为视频数据集, 部分视频中火焰非连续存在, 因此计算评价指标时, 针对真实火焰帧数进行统计.
本文对比文献[2]方法、文献[9]方法、文献[14]方法、文献[29]方法, 具体性能如表5所示, 表中黑体数字表示最优值.
| 表5 各方法在MIVIA数据集上的性能对比 Table 5 Performance comparison of different methods on MIVIA dataset % |
由表5可知, 本文方法在误报率、准确率等指标上优于其它方法, 但漏报率略高, 主要表现在对暖色光源、远距离火焰检测有待提高.
本文方法较好地控制疑似火焰误报问题, 目前仅存的个别误报主要是因为疑似火焰图像颜色、形状与真实火焰高度相似.本文方法具体检测效果如图12所示.
 | 图12 本文方法在MIVIA数据集上的检测效果Fig.12 Detection results of the proposed method on MIVIA dataset |
2.3.3 其它数据集上实验结果
为进一步验证模型性能, 本文分别在KMU CVPR Lab Fire[31]、Ultimate Chase火焰视频、自建火焰测试视频上进行测试.
KMU CVPR Lab Fire数据集包含38个视频, 分为近距离火焰、近距离烟雾、野火烟雾、疑似火焰烟雾4类.KMU CVPR Lab Fire数据集样例信息如图13所示.
 | 图13 CVPR Lab Fire数据集样例信息Fig.13 Samples of CVPR Lab Fire dataset |
Ultimate Chase火焰视频包含14个视频, 12个为不同场景下的火焰视频, 2个为易混疑似火焰视频.火焰视频包括极端火焰、小船着火、炼油厂火焰、房屋着火、车辆火焰等不同场景.易混疑似火焰视频包括森林烟雾、太阳光叠影、高速公路远距离浓烟.Ultimate Chase火焰数据集样例信息如图14所示.
 | 图14 Ultimate Chase火焰数据集样例信息Fig.14 Samples of Ultimate Chase Fire dataset |
本文自建测试火焰数据集包括90个视频, 13个为监控视频, 34个为实地拍摄录制视频, 43个为网络爬取非火焰视频.监控视频主要来自高速公路、教学楼、加油站, 火焰视频主要来自农村实景拍摄, 非火焰视频主要来自互联网爬取.监控视频、爬取视频与真实火焰视频极度相似.自建测试火焰数据集样例信息如图15所示.
 | 图15 自建测试火焰数据集样例信息Fig.15 Samples of test flame dataset built in this paper |
本文方法在3个数据集上的实验结果如表6所示, 由此验证方法性能较优.
| 表6 本文方法在3个数据集上的实验结果 Table 6 Experimental results of the proposed method on 3 datasets % |
在自建火焰数据集上进行消融实验, 对比分析不同模块对火焰检测误报率、漏报率和准确率的影响, 结果如表7所示.由表可见, 在引入Focal Loss、CIoU Loss后, 火焰检测误报率得到有效抑制, 同时准确率提升0.2%.
| 表7 改进前后YOLOv5的检测性能对比 Table 7 Comparison of detection performance of YOLOv5 before and after improvement % |
综合2.3节和2.4节实验结果发现, 本文方法在各大公开数据集上均表现较佳, 同时小目标火焰检测、实时速度均有明显提升.经过大量实践测试发现, 本文方法在低误报、低漏报下较好地满足实时性要求, 火焰检测速度可达25帧/秒, 并支持8路摄像头实时并行火焰检测.本文方法在不同场景下均表现出强大的实时火焰检测性能.
本文提出在YOLOv5上融合多特征的实时火焰检测方法.在各公认的火焰测试数据集上的实验证实本文方法的有效性和优越性, 不仅可有效降低误报率, 而且能提高小目标火焰检测率.
此外, 针对公开火焰数据集规模较小和现有方法火焰检测效果不佳的问题, 本文构建一个大规模、多样性的高质量火焰数据集, 不仅场景丰富、数据量大, 而且注重小目标和疑似负样本的收集, 并耗费大量时间对其逐张标注、筛选.实验结果充分表明适当疑似易混的火焰负样本的采集是提升数据集性能的重要手段, 也是使模型训练具有强泛化性能的重要方式, 但仍存在特定疑似火焰图像误报的问题.今后将深入研究3D卷积神经网络在火焰误报剔除上的应用.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|