











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于传递注意力机制的非均匀雾图去雾算法
引用本文
王科平, 段雨朦, 杨艺, 费树岷. 基于传递注意力机制的非均匀雾图去雾算法. 模式识别与人工智能, 2022,35(7): 575-588
WANG Keping, DUAN Yumeng, YANG Yi, FEI Shumin. Uneven Hazy Image Dehazing Based on Transmitted Attention Mechanism. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2022,35(7): 575-588.
Doi: 10.16451/j.cnki.issn1003-6059.202207001
WANG Keping, DUAN Yumeng, YANG Yi, FEI Shumin. Uneven Hazy Image Dehazing Based on Transmitted Attention Mechanism. PATTERN RECOGNITION AND ARTIFICIAL INTELLIGENCE, 2022,35(7): 575-588.
Permissions
Copyright©2022, 《模式识别与人工智能》编辑部
《模式识别与人工智能》编辑部 所有
基于传递注意力机制的非均匀雾图去雾算法

杨 艺,博士,副教授,主要研究方向为人工智能、机器视觉.E-mail:yangyi@hpu.edu.cn.
作者简介:
王科平,博士,副教授,主要研究方向为图像去雾处理、目标检测跟踪.E-mail:wangkp@hpu.edu.cn.

段雨朦,硕士研究生,主要研究方向为图像去雾、深度学习.E-mail:1220613678@qq.com.

费树岷,博士,教授,主要研究方向为非线性控制系统设计和综合、神经网络控制、时滞系统控制.E-mail:smfei@seu.edu.cn.
摘要
针对非均匀雾霾图像难以建模、去雾时容易出现残留的问题,文中提出基于传递注意力机制的非均匀雾图去雾算法.针对雾霾分布的非均匀性,在网络中构建传递注意力机制,使注意力特征图中的权重信息在各个注意力块之间流动,有针对性地处理非均匀有雾图像中的雾霾噪声.为了减少普通深度卷积导致复原图像中细节信息丢失问题,构建稀疏结构平滑空洞卷积,用于提取图像特征,在保证较大感受野的同时保留更多的细节信息.最后,并联一个轻量级的残差块结构,用于补充重构图像的色彩、细节信息.实验表明,文中算法在非均匀有雾图像数据集和人工合成有雾图像数据集上均能取得较优效果,在主观效果和客观指标上都具有较大优势.
关键词:
图像去雾; 深度学习; 稀疏块; 平滑空洞卷积
中图分类号:TP 391.4
Uneven Hazy Image Dehazing Based on Transmitted Attention Mechanism
YANG Yi, Ph.D., associate professor. His research interests include artificial intelligence and machine vision)
About Author:
WANG Keping, Ph.D., associate profe-ssor. Her research interests include image dehazing and target detection and tracking.
DUAN Yumeng, master student. Her research interests include image dehazing and deep learning.
FEI Shumin, Ph.D., professor. His research interests include nonlinear control system design and synthesis, neural network control and delay system control.
Abstract
It is difficult to model accurate uneven hazy image and solve residual problems during dehazing process. Therefore, an uneven hazy image dehazing method based on transmitted attention mechanism is proposed in this paper. Aiming at the heterogeneity of haze distribution, the transmitted attentions mechanism is designed in the network. The weight information in different modules can flow and cooperate to target and deal with the noise in the uneven hazy image. To reduce the loss of detail information caused by the common deep convolution, sparse smoothed dilated convolution is built to extract image features. Consequently, the receptive field is larger with more details retained. Finally, a lightweight residual block is utilized in parallel to supplement the color and detail information for the reconstructed image. Compared with mainstream methods, experiments on the uneven hazy image datasets and synthetic hazy image datasets show that the proposed method holds the advantages in subjective effects and objective evaluations.
Key words:
Key Words Image Dehazing; Deep Learning; Sparse Block; Smoothed Dilated Convolution
本文责任编委 杨 健
Recommended by Associate Editor YANG Jian
在雾天条件下, 空气中悬浮的各种雾霾微粒会对光线进行吸收和散射, 导致采集到的户外图像出现对比度降低、颜色失真、边缘模糊等现象.在此类环境下获取的雾霾图像既不利于图像的视觉观察, 也阻碍人工智能领域中以图像为主要处理对象的计算机视觉任务的进行[1].因此, 研究雾霾图像的降质原理, 提高其清晰化程度具有重要的研究意义和应用前景.
早期的图像去雾算法主要采用图像增强手段以改善图像的对比度、清晰度, 提升图像的视觉效果, 如直方图均衡化[2]、Retinex[3]算法、同态滤波[4]、大气散射模型[5]等.依据算法的发展脉络.图像去雾算法可划分为两类:基于先验知识的图像去雾算法和基于深度学习的图像去雾算法.
基于先验知识的图像去雾算法常通过一些额外的先验信息或约束条件辅助估计模型中的参数, 再反演清晰图像.He等[6]提出DCP(Dark Channel Prior)信息约束大气散射模型, 能准确预测雾霾图像的透射率, 消除局部区域的雾霾.Zhu等[7]提出CAP(Color Attenuation Prior), 通过监督学习的方式训练线性模型, 依次估计场景深度信息和透射图, 可复原较多的细节信息, 但仍存在一定程度的雾残留.
近年来, 深度学习因其强大的非线性映射能力和优秀的学习能力受到广泛关注, 学者们将其应用到图像去雾领域.Cai等[8]提出DehazeNet, 利用卷积神经网络(Convolutional Neural Network, CNN)估计大气散射模型的中间参数, 构建雾霾图像到参数的映射关系.Ren等[9]提出MSCNN(Multi-scale CNN), 通过粗尺度神经网络和细尺度神经网络提取图像中的特征信息, 可有效学习有雾图像与其对应透射率之间的映射关系.Zhang等[10]提出DCPDN(Densely Connected Pyramid Dehazing Network), 共同学习透射率、大气光值和去雾图像, 并通过基于生成式对抗网络(Generative Adversarial Networks, GAN)[11]的联合鉴别器, 判断得到的去雾图像和透射率是否真实.陈永等[12]将雾图进行双域分解后送入深度学习模型中训练, 将学习到的高/低频透射率进行融合, 得到场景透射率图, 去雾后图像质量较好.
上述方法包括两个阶段:1)参数估计, 2)将参数代入大气散射模型反演清晰图像.这种两阶段式去雾算法一方面要求参数估计准确无误, 另一方面需要模型较好地描述雾霾图像成像过程, 否则会出现误差累积, 无法获得清晰图像全局的最优效果.
针对这一问题, 学者们提出一些端到端的图像去雾网络, 直接构建有雾图像与无雾图像之间的映射关系.Li等[13]提出AOD-Net(All-in-One Dehazing Network), 转换大气散射模型, 并将其嵌入去雾网络中, 直接学习有雾图像与无雾图像之间的映射关系, 最后结合Faster R-CNN[14]评价去雾效果对高水平视觉任务的影响.Qin等[15]提出FFA-Net(End-to-End Feature Fusion Attention Network), 利用像素注意力与通道注意力结合的特征注意力模块, 灵活处理不同的特征和像素, 取得较好的去雾效果.Wang等[16]提出MST-Net(Multi-scale Transposed Convolutional Network), 利用级联的多尺度转置重建去雾图像, 取得较优的去雾效果且无颜色失真.Chen等[17]提出GCANet(End-to-End Gated Context Aggregation Net-work), 通过平滑空洞卷积避免网格化伪影, 并使用门控子网融合不同级别的特征, 大幅提升去雾效果.Swinehart等[18]分别从深度多区域角度和多尺度角度提出分层网络结构, 去除图像中的非均匀雾霾.Zheng等[19]提出解决高分辨率图像的去雾算法, 由3个CNN组成, 分别实现低分辨率雾霾特征提取、高分辨率图像高频特征重构及特征映射融合的功能.Wu等[20]提出对比正则化算法, 不仅利用清晰图像指导图像去雾, 而且将雾霾图像作为负样本, 在表示空间中将恢复后的图像拉近到清晰图像, 并将恢复后的图像远离模糊图像.Li等[21]提出基于GAN的去雾算法, 通过对损失函数的重构, 有效消除一般GAN容易出现的雾霾残留问题.Raj等[22]提出改进条件GAN, 实现图像去雾算法, 采用具有较高参数学习效率的Tiramisu模型[23]代替经典的U-Net模型作为生成器, 并选择基于块的判别算法, 减少重构图像的伪影.
基于端到端的图像去雾算法无需考虑构建雾霾图像的成像模型, 也无需通过估计模型参数再重建图像, 直接由深度神经网络建立清晰图像与雾霾图像的映射, 获得全局最优解.上述算法在图像去雾方面取得显著成果, 但仍存在一些不足:算法主要以均匀雾霾图像作为研究内容.然而, 自然界中雾霾产生的因素较多, 产生雾霾的位置也较随机, 所以, 大气中的雾霾介质可能会产生随机、不均匀的噪声, 其在图像中呈现非均匀分布特性.上述算法在处理非均匀雾霾图像时, 容易出现雾霾残留的问题.
为此, 本文提出基于传递注意力机制的非均匀雾图去雾算法.首先, 针对雾霾分布不均匀的特点, 融合视觉注意力机制, 在学习过程中更关注图像中雾较重的区域.将各个注意力模块学习到的注意力特征图传递到下一个注意力模块, 使模块间可相互配合, 充分发挥注意力机制的优势.为了避免深度卷积网络下采样和池化容易造成的细节信息丢失, 保证网络的去雾性能和计算效率, 以由普通卷积与平滑空洞卷积交错构成的稀疏块为主体框架提取图像特征信息, 加强复原图像的细节信息.
1 基于传递注意力机制的非均匀雾图去雾算法
针对雾霾浓度的随机性和非均匀性, 本文提出基于传递注意力机制的非均匀雾图去雾算法.算法充分学习不同级别特征图中不同位置的注意力权重, 并通过通道拼接的方式连接注意力模块, 使权重信息在各个注意力模块之间流动并相互配合, 充分发挥注意力机制的优势.构建稀疏结构平滑空洞卷积, 进行特征提取及图像复原, 在扩大感受野的同时减少细节特征信息的丢失.
本文算法整体结构如图1所示, 虚线框内为网络的主体部分.先通过3个卷积层初步提取输入图像的特征信息, 卷积层3的步长为2, 可减小特征图尺寸, 降低网络的计算复杂度.再利用5个级连的稀疏块(S1~S5)提取图像中不同层的特征, 避免下采样操作的使用, 从而减少细节信息的丢失.然后, 利用门控融合网络, 直接将提取的低、中、高级别的特征图进行门控融合, 有效聚合不同级别的图像特征, 获得包含丰富特征信息的特征图.最后, 通过转置卷积, 将融合后的特征图还原到与输入雾图相同的尺寸.
 | 图1 本文算法结构图Fig.1 Structure of the proposed method |
为了处理输入图像中复杂的非均匀雾噪声, 本文在网络中加入注意力模块(A0~A6), 用于学习中间特征图中不同位置的权重信息, 为不同的特征赋予相应的注意力.并利用通道拼接的方式, 使注意力模块中的注意力特征图逐级向后传递, 引导网络的特征提取过程, 充分发挥注意力机制的优势.为了抑制转置卷积带来的“ 棋盘效应” , 加入卷积层6和卷积层7.并通过并联残差结构ResNet Block提取输入雾图中的颜色特征, 弥补复原图像中缺失的颜色信息.
1.1 稀疏平滑空洞卷积特征提取
图像去雾算法是像素级别的重建过程, 大量的下采样操作容易丢失图像细节信息, 为无雾图像的重建带来巨大的挑战.因此, 在扩大图像感受野的同时尽可能多地保留细节信息尤为重要.本文提出稀疏结构平滑空洞卷积, 实现特征提取, 并采用门控融合的方式融合不同级别的特征.
由文献[24]可知, 稀疏机制可有效应用于图像修复领域.与文献[24]类似, 本文采用平滑空洞卷积与普通卷积交错的形式构建稀疏块.平滑空洞卷积可扩大感受野, 映射更多的背景信息, 这些层可视为稀疏机制中的高能激活部分.普通卷积层可视为稀疏机制中的低能量激活点.普通卷积与平滑空洞卷积交错组合构成稀疏块, 提取图像中不同级别的特征信息, 共同表征图像.
稀疏块结构如图2所示, 先利用两层普通卷积层提取图像中的特征信息, 并引入跳跃连接抑制过拟合现象.之后, 利用两层级联的平滑空洞卷积, 更大范围地提取图像中的特征信息.跳跃连接的加入可有效抑制深层网络梯度消失的问题, 提高网络学习能力.在本文算法中, 5个级联稀疏块用于提取输入图像的特征信息, 稀疏块中平滑空洞卷积的扩张率分别为2, 2, 4, 4, 4.
 | 图2 稀疏块结构图Fig.2 Structure of sparse blocks |
平滑空洞卷积的使用在扩大卷积核感受野的同时避免池化等下采样操作造成信息丢失, 有效消除“ 网格伪影” 的现象, 有利于无雾图像的重建.另一方面, 普通卷积与平滑空洞卷积交错组成的稀疏结构虽然加深网络深度, 但不会大幅增加计算量, 有效提高算法整体性能, 使去雾算法在计算效率与去雾性能上达到平衡.
1.2 基于传递注意力机制非均匀雾霾特征处理
雾霾在人的视觉感官中呈现明显的随机分布特征, 当人观察图像时, 注意力机制会引导人类给予雾霾更多的关注度, 从而更好地获取图像信息.以清晰样本为标准, 在大量训练数据指导下, 注意力算法会逐渐从输入信息中选择和去雾任务相关的信息, 主动聚焦雾霾图像中的浓雾区域, 并在保留图像背景特征的同时有区别地处理不同浓度的雾噪声.
在图像中, 雾霾表现颜色相对一致, 多为白色.因此, 从色彩通道上考虑雾霾, 存在天然的注意力机制.为此, 可在处理过程中加入通道注意力.同时, 在网络结构中同样引入空间注意力.通道注意力实质是一个可学习的向量, 用于表述通道的重要程度.空间注意力也是一个可学习的二维向量, 用于表述像素或特征在空间中的注意力.本文将不同级别的注意力进行传递并进行自适应融合, 即将上一级的注意信息传递到下一级处理, 建立注意力信息传输链路.该链路与图像特征链路相对分离, 以此提升图像特征处理的能力.
本文算法融入传递注意力算法, 分别学习不同级别特征图中的通道注意力特征图与像素注意力特征图, 赋予每个通道不同的权重值, 并使网络更关注浓雾区域和高频区域, 自适应地学习特征图在不同权值下的特征映射.然后将模块中的通道注意力特征图与像素注意力特征图分别向后传递, 使注意力特征图中的权重信息在各个注意力块之间流动并相互配合, 充分发挥注意力机制优势.
为了方便表述, 本文从去雾网络中拆分注意力机制, 具体传递注意力机制结构如图3所示, 图中A0~A6表示图1中的注意力模块, 每个模块结构相同, 都由通道注意力与像素注意力组成, …表示去雾网络中除注意力机制以外的其它部分.
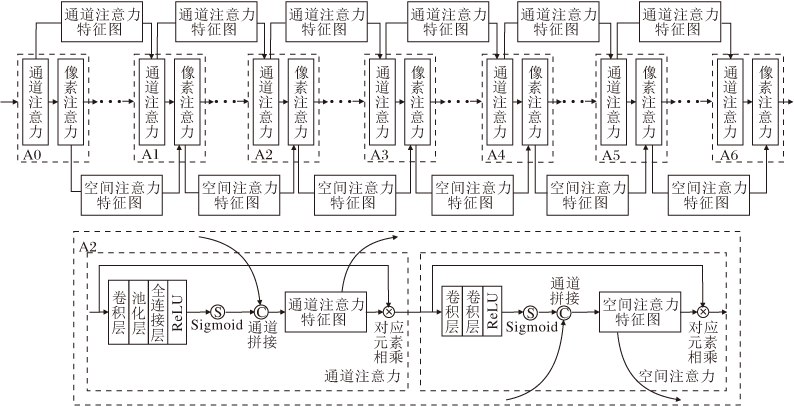 | 图3 传递注意力机制结构图Fig.3 Structure of transmitted attention mechanism |
1.2.1 注意力机制
特征图中不同通道的重要程度不尽相同, 为了提高去雾网络的学习能力, 利用通道注意力学习特征图中各通道的权重值并赋予网络.通道注意力结构如图3所示, 先通过一层卷积核大小为3× 3、步长为2的卷积层, 对特征图特征进行预处理, 降低特征图尺寸.然后利用池化层对预处理特征图逐通道平均池化, 得到每个通道的特征描述, 经过一层全连接层卷积和激活函数的处理后, 得到各通道的权重系数, 即通道注意力特征图.最后将原始特征图与对应通道的权重系数逐像素相乘.
为了处理有雾图像中不同像素位置上非均匀雾噪声, 在通道注意力后连接像素注意力, 用于学习不同像素的权重系数, 使网络更关注雾图中的高频区域和浓雾区域.像素注意力结构如图3所示, 通过两层卷积层学习特征图的像素权重信息, 并在通道维度上对其进行压缩, 经过激活函数处理后得到1通道的像素注意力特征图, 再与各特征图中对应元素相乘, 赋予每个像素不同的权重值.
1.2.2 传递注意力
注意力模块根据输入图像特征的重要程度在通道维度和像素维度上分别生成注意力特征图, 为特征图不同位置赋予不同的权重值, 使算法在学习过程中更灵活处理非均匀有雾图像中的雾噪声, 提升算法对不同特征的处理能力.然而, 每个注意力模块只是根据算法中当前位置的特征生成注意力特征图, 并未考虑不同级别的注意力特征图之间的联系, 无法充分挖掘注意力机制的优势.为此, 本文提出传递注意力机制, 将每个注意力模块中的通道注意力特征图和像素注意力特征图使用通道拼接的方式分别传递到下一个注意力模块中, 使注意力特征图中的权重信息在各个注意力块之间流动.合并后的通道注意力特征图和像素注意力特征图均采用卷积层与原始特征图进行维度匹配.
由于注意力机制中传递结构的引入, 网络中各层的注意力信息在模块之间流动, 可相互配合学习输入图像中的不同特征及各个特征的权重信息, 并不局限于当前特征图, 引导整体网络的学习过程, 有效避免模块之间信息的频繁变动, 提升算法对非均匀有雾图像的去雾效果.
为了更直观地说明传递注意力机制可有效处理非均匀雾霾噪声, 为不同特征赋予相应的权重值, 将注意力模块A6的输出特征图进行可视化, 转化为热力图, 具体如图4所示.热力图中红色区域对应权重值最大, 蓝色区域对应权重值最小.由图可清楚地看到, 本文算法可自适应地识别非均匀雾霾图像中的噪声区域, 为不同区域赋予相应的权重.在浓雾区域, 对应权重值较高, 大多显示为红色, 薄雾区域及无雾区域对应权重值较低, 普遍呈蓝色.
 | 图4 非均匀雾霾图像及其热力图示例Fig.4 Uneven hazy images and their corresponding heat maps |
注意力机制确实能较好地聚焦到浓雾区域, 但是在非纯白色背景下, 当背景中存在小部分白色目标物体时, 由于这部分的色彩信息与雾霾较相似, 容易被误判为雾霾区域, 呈现红色.
1.3 其它网络结构
1.3.1 门控融合网络
不同层的网络提取的图像特征并不相同, 浅层网络往往更容易提取图像中的纹理等局部特征, 而深层网络倾向于提取图像的轮廓、形状等全局特征.不同层的网络提取的图像特征对图像去雾任务的重要性不同.
本文算法引入门控融合网络, 具体结构如图5所示.
 | 图5 门控融合网络结构图Fig.5 Structure of gated aggregation network |
门控融合网络将主体模块提取到的低、中、高级别的特征图, 即输入特征图F1、中间特征图F2、输出特征图F3, 进行加权融合, 并根据3种特征图对去雾任务的重要程度, 分配相应的权重值w1、w2、w3.这3个权值作为超参数由网络训练学习得到.融合后的特征输出为:
F=F1w1+F2w2+F3w3.
图5中虚线框内的结构与图1总体结构一致.由于门控融合网络的引入, 可直接融合提取不同层的特征图, 从而有效聚合不同级别的图像特征, 提升网络的整体表达能力.
1.3.2 轻量级特征补全模块
颜色能量信息和边缘细节信息是彩色图像中重要的特征信息, 描述图像对应景物的基本表面性质.这些信息常包含于深度神经网络的底层特征中.随着卷积网络结构的加深, 能较好地提取图像中具有强分辨力的高层语义信息, 但图像的底层特征信息随着下采样、池化等操作容易丢失.图像去雾是像素级别的重建过程, 底层特征信息的丢失会导致重构图像出现模糊不清、颜色失真的现象.
本文在主体网络中并联一个由残差块组成的轻量级特征补全模块, 从输入雾图中提取底层特征信息, 直接传递到重构图像中, 弥补由去雾网络在经过深层卷积后损失的底层信息.
轻量级特征补全模块由3个残差块级联而成, 分别为残差块1~残差块3, 每个残差块结构相同, 具体如图6所示.通过两层普通卷积提取图像的特征信息, 引入跳跃连接, 抑制网络过拟合现象及梯度消失的问题.残差块中卷积核大小均为3× 3, 步长为1, 输入输出通道数均为16, 卷积后的激活函数均采用ReLU函数.
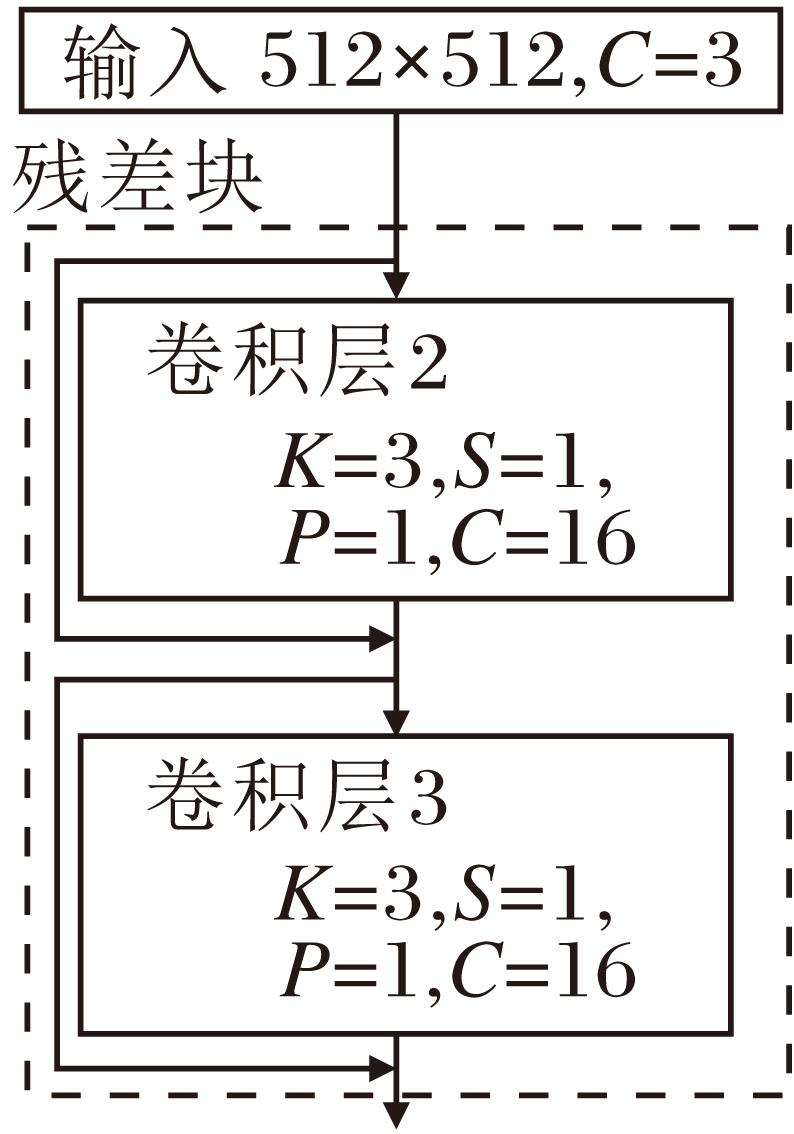 | 图6 残差块结构图Fig.6 Structure of ResNet Blocks |
1.3.3 转置卷积层
转置卷积是CNN中较常见的一种操作, 可看作是卷积操作的一个逆运算过程.通过在输入特征图中的元素之间加入0填充(Padding)以实现上采样操作.当步长大于1时, 转置卷积的输出图像尺寸大于输入图像尺寸, 使图像从较低的分辨率转为较高的分辨率.
为了保证去雾算法的输入图像与输出图像尺寸相同, 与网络前端卷积层1~卷积层3对应, 本文在融合特征图后引入转置卷积层TranConv1, 转置卷积核大小为4× 4, 步长为2, padding大小为1. 经过转置卷积层操作后, 输出的特征图为512× 512.
1.4 损失函数
网络训练过程中使用Smooth L1 loss作为损失函数.该损失函数对异常值不太敏感, 在网络训练初始阶段, 变化小于L2 loss的梯度, 具有更强的鲁棒性.当差值接近0时, 比L1 loss平滑, 使网络在后续的训练过程中更容易收敛.Smooth L1 loss表达式为
其中:Θ 表示需要学习的网络参数; F表示本文主体网络, 可将雾霾图像进行清晰化处理; Igt表示作为标签的无雾图像; Ihaze表示输入的有雾图像; N表示图像像素个数.
Smooth L1 loss可从两个方面限制梯度:当预测值与真实值差别过大时, 使梯度值不至于过大, 避免破坏网络参数; 当预测值与真实值差别较小时, 使梯度值足够小, 有利于网络收敛, 提高去雾算法的鲁棒性.
2 实验及结果分析
本节对本文算法的去雾性能进行广泛评估, 分别在非均匀有雾图像数据集、合成有雾图像数据集、真实有雾图像数据集上与已有的去雾算法进行对比, 具体对比算法如下:DCP[6]、AOD-Net[13]、FFA-Net[15]、GCANet[17]、文献[19]算法.选择结构相似性(Structural Similarity, SSIM)和峰值信噪比(Peak Signal to Noise Ratio, PSNR)作为评价指标, 对各算法的去雾效果进行定量分析.
整个实验过程在NVIDIA GeForce GTX 1080Ti的PC上进行, 网络基于PyTorch框架实现.在训练过程中, 选取大小为512× 512图像作为输入图像与标签, 整个网络共训练100轮, 采用Adadelta[25]作为优化算法, 可自适应地调整学习速率.初始学习率设定为0.05, 批尺寸设置为2.
2.1 实验数据集
为了验证本文算法对非均匀有雾图像的效果, 设计并制作81组包含清晰图像和对应有雾图像的数据, 共3 240幅.每组数据由1幅清晰图像和对应26~181幅不等的有雾图像组成, 有雾图像的雾浓度不同且随机分布.通过在同一环境中拍摄无雾图像与对应的有雾图像, 拍摄设备为位置固定的HIKVISION EXIR红外点阵筒型网络摄像机, 雾层由拍摄专用烟饼燃烧的轻烟产生.为了避免光照条件变化带来的额外影响, 同组数据采集的时间间隔应尽可能缩短.为了扩展训练数据, 将数据集上的图像随机裁剪为512× 512并筛选, 最终得到6 486幅图像作为室内数据.部分样本如图7所示.
 | 图7 本文拍摄的数据集样本Fig.7 Image samples of the dataset created in this paper |
为了验证本文算法的泛化能力, 还在真实有雾图像数据集I-HAZE[26]、O-HAZE[27]上进行扩展实验.I-HAZE数据集包含35组不同场景的室内图像对, O-HAZE数据集包含45组不同场景的室外图像对.每组图像对包含一幅清晰图像和对应的有雾图像, 数据集上有雾图像的雾是由烟雾机器生成.本文在I-Haze、O-Haze数据集上分别随机选取27幅、40幅图像生成训练数据集, 其余图像生成测试集.
在合成有雾图像数据集上进行对比实验.选择RESIDE-standard数据集[28]中的ITS (Indoor Training Set)-V2作为室内训练数据集.ITS-V2数据集包含13 990幅合成的室内有雾图像, 是由1 399幅室内清晰图像生成, 每幅清晰图像生成10幅不同的有雾图像.随机选取10 000幅室内有雾图像作为训练数据, 其余有雾图像作为非重叠测试数据.另外, 选择RESIDE数据集上的SOTS数据集作为验证集, 测试本文算法的去雾效果.
2.2 在自建数据集上的实验结果
从本文拍摄的数据集上随机选取200幅与训练集非重叠的有雾图像作为测试集, 验证本文算法对非均匀有雾图像的去雾效果.
各算法在本文拍摄的数据集上的去雾效果如图8所示.由图可知, DCP能有效消除一些雾噪声, 但去雾后的图像整体色彩饱和度偏高, 在部分区域容易产生较大程度颜色偏差, 视觉效果不太理想(如(c)中第2幅图像).AOD-Net和文献[19]算法有一定的去雾效果, 但都存在去雾结果整体偏暗的问题.FFA-Net去雾后的图像整体色彩较自然, 但去雾后的图像中仍存在较多的雾噪声(如(e)中第1幅、第4幅图像).GCANet可有效去除非均匀有雾图像中的大部分区域的雾, 但在雾较重的区域仍有部分雾残留(如(f)中第1幅图像中的建筑区域和第2幅图像), 去雾结果整体上有一定的颜色偏差.本文算法在保持较高的色彩一致性的前提下去雾效果更彻底, 在浓雾区域和薄雾区域均有较好的去雾效果, 相比其它算法, 结果图最接近无雾图像参考图.本文所选样本雾霾浓度较重, 所以, 相比清晰标签, 重建图像也存在一定的偏色现象.
 | 图8 各算法在本文拍摄的数据集上的去雾效果Fig.8 Dehazing results of different algorithms on the dataset created in this paper |
表1为各算法在本文拍摄的数据集上去雾效果的指标值对比.由表可看出, DCP、AOD-Net、文献[19]算法的指标值较低, 而FFA-Net和GCANet这两个基于端到端的图像去雾算法的指标值相对有大幅提升, 但本文算法的SSIM值和PSNR值最高.综上所述, 本文算法针对非均匀有雾图像的去雾结果更接近真实的无雾图像.
| 表1 各算法在本文拍摄的数据集上的指标值对比 Table1 Index value comparisons of different algorithms on the dataset created in this paper |
2.3 在I-HAZE、O-HAZE数据集上的实验结果
在本文处理后的I-HAZE数据集上随机选取270幅与训练集非重叠的有雾图像作为室内测试集, 验证本文算法对室内非均匀有雾图像的去雾效果.
各算法的去雾效果如图9所示.由图可看出, DCP整体上有明显的去雾效果, 可较好地去除图像中的雾, 但会引入一些额外噪声(如(c)中第1幅图像中最左侧区域), 且图像整体偏暗.AOD-Net和FFA-Net对输入图像均有一定的去雾效果, 去雾后的图像整体无颜色失真, 但图像中仍存在较多的雾噪声, 去雾效果并不彻底.GCANet可有效去除室内非均匀有雾图像中的大部分雾, 但在一些物体边缘区域仍有部分雾残留(如(f)中第1幅图像中的金属柱体), 部分区域有一定的颜色偏差(如(f)中第3幅图像中背景区域和第4幅图像中左上角的书橱).文献[19]算法有较好的去雾效果, 但是与清晰标签相比, 整体图像偏暗.本文算法有较好的去雾效果, 整体上去雾更彻底, 与无雾图像相比几乎无颜色失真.
 | 图9 各算法在I-HAZE数据集上的去雾效果对比Fig.9 Dehazing result comparison of different algorithms on I-HAZE dataset |
各算法在I-HAZE数据集上去雾效果的指标值对比如表2所示.由表可看出, DCP与GCANet的指标值较低, 而AOD-Net和FFA-Net的指标值相对较高, 文献[19]算法居中, 本文算法的指标值最高.
| 表2 各算法在I-HAZE测试集上的指标值对比 Table 2 Index value comparison of different algorithms on I-HAZE dataset |
为了验证本文算法在O-HAZE数据集上针对雾图的去雾效果, 在处理后的O-HAZE数据集上随机选择428幅与训练集非重叠的图像作为测试集, 验证本文算法的去雾效果.
各算法在O-HAZE数据集上的部分输出结果如图10所示.由图可看出, DCP整体上有一定的去雾效果, 但去雾后的图像存在颜色失真, 特别是在天空区域(如(c)中第2幅、第3幅图像中的天空区域), 输出图像整体颜色偏暗.AOD-Net和FFA-Net对输入雾图均有去雾效果, 但图像中仍存在较多的雾噪声, 去雾效果并不彻底(如(d)、(e)中第3幅图像中树木上仍有雾存在).GCANet去雾效果更明显, 颜色失真大幅减少, 但在较复杂的区域仍有部分雾残留(如(f)第2幅图像中天空区域有颜色失真, 第3幅图像中最下方区域有雾存在).文献[19]算法不论是在无雾上还是在图像复原上效果都不太令人满意.本文算法几乎无颜色失真, 去雾效果最彻底, 整体更接近无雾图像.
 | 图10 各算法在O-HAZE数据集上的去雾效果对比Fig.10 Dehazing result comparison of different algorithms on O-HAZE dataset |
各算法在O-HAZE数据集上去雾效果的指标值对比如表3所示.由表可见, 本文算法的SSIM值和PSNR值最高.
| 表3 各算法在O-HAZE数据集上的指标值对比 Table 3 Index value comparison of different algorithms on O-HAZE dataset |
2.4 在合成数据集上的实验结果
本文算法是针对雾层分布较复杂的非均匀有雾图像提出的, 但对于雾层分布较均匀的合成有雾图像也有较好的去雾效果.选择RESIDE数据集上的ITS-V2数据集作为训练集训练算法, 包含500幅室内合成有雾图像的SOTS数据集作为验证集, 验证本文算法的去雾效果, 并与DCP、AOD-Net、FFA-Net、GCANet、文献[19]算法进行对比.
各算法在SOTS数据集上的去雾效果对比如图11所示.由图可知, DCP能有效去雾, 但去雾后的图像整体色彩偏暗, 容易产生过饱和的现象(如(c)中第1幅图像左下角地板处颜色偏暗), 视觉效果不太理想.AOD-Net去雾效果较好, 但也存在去雾效果不彻底的现象.FFA-Net较好地保留图像的细节信息, 但去雾效果不是很理想, 有较多雾残留.GCANet的去雾效果较理想, 去雾彻底, 几乎无颜色失真, 但在部分区域引入额外的噪声(如(f)中第2幅图像左侧黑色噪声).本文算法在保证去雾效果较彻底的前提下, 保持较高的色彩一致性和图像的细节信息, 去雾后结果图最接近于无雾图像参考图, 在整体视觉效果上优于其它对比算法.
 | 图11 各算法在SOTS数据集上的去雾效果对比Fig.11 Dehazing result comparison of different algorithms on SOTS dataset |
为了更直观地展示各算法的去雾效果, 将实验结果中的部分区域放大进行对比, 如图12所示.
由图12可知, DCP、GCANet和文献[19]算法可较好地实现室内图像去雾, 但均有不同程度的颜色失真.AOD-Net和FFA-Net可完整恢复有雾图像的原始色彩, 但去雾效果并不彻底, 特别是FFA-Net仍保留大量的雾.相比之下, 本文算法可更彻底地去除室内有雾图像中的雾, 更接近于清晰无雾图像.
 | 图12 各算法在SOTS数据集上的去雾效果放大图对比Fig.12 Dehazing result comparison of magnified images by different algorithms on SOTS dataset |
各算法在SOTS测试集上去雾效果的指标值对比如表4所示, 表中黑体数字表示最优值.由表可看出, 本文算法的SSIM值最高, PSNR值高于DCP、AOD-Net和FFA-Net, 但低于GCANet.
| 表4 各算法在SOTS测试集上的指标值对比 Table 4 Index value comparisons of different algorithms on SOTS dataset |
2.5 在真实有雾图像上的实验结果
为了进一步验证本文算法的泛化能力, 选择一些常用真实雾图作为测试图像, 对比去雾效果.
各算法去雾效果对比如图13所示.
 | 图13 各算法在真实有雾图像上的实验结果对比Fig.13 Dehazing result comparison of different algorithms on real hazy images |
由图13可看出, DCP去雾后的图像整体色调变暗, 出现较明显的颜色失真, 尤其是天空区域较严重.GCANet在第1幅公路区域和第3幅景深较深的区域也存在色彩失调现象.FFA-Net处理后图像存在雾残留.AOD-Net图像变暗, 影响图像的整体视觉效果.文献[19]算法复原的图像存在一定偏色现象, 如第1幅和第4幅的大路.相比之下, 本文算法在保证去雾效果良好的前提下, 能重建更自然的色彩效果.
2.6 消融实验结果
为了验证本文算法各结构的有效性, 进行消融实验, 包括如下4个模型:1)算法中去掉所有注意力模块的传递部分.2)算法中去掉所有注意力模块部分.3)算法中去掉稀疏结构平滑空洞卷积部分, 以普通空洞卷积替代.4)算法中去掉轻量级特征补全模块.
在拍摄的非均匀雾图数据集上对上述4个模型进行质量评价, 计算PSNR值和SSIM值.本文算法的SSIM值为0.80, PSNR值为21.80 dB.模型1的SSIM值为0.76, 比本文算法降低0.04, PSNR值为19.29 dB, 比本文算法降低2.51 dB.模型2的SSIM值同样为0.76, 比本文算法降低0.04, PSNR值为19.08 dB, 比本文算法降低2.72 dB.模型3的SSIM值为0.68, 比本文算法降低0.12, PSNR值为15.51 dB, 比本文算法降低6.29 dB.模型4的SSIM值为0.74, 比本文算法降低0.06, PSNR值为17.14 dB, 比本文算法降低4.66 dB.由此表明基于残差块的轻量级网络能较好地补全部分色彩信息.
注意力机制是模拟人类视觉过程开发的算法, 运算机制主要以图像的像素值为基础, 倾向于对引起视觉感知的亮度、对比度等色彩信息的关注度更高.所以引入传递注意力机制的模型2的PSNR值比模型1提升0.21 dB, 但SSIM值一致.从这两个指标的角度上看, 传递注意力对去雾性能峰值信噪能起到一定的提升作用.
3 结束语
本文提出基于传递注意力机制的非均匀雾图去雾算法, 以端到端的方式实现, 可直接学习输入图像与清晰图像之间的映射关系.针对非均匀雾图中复杂的雾噪声, 加入传递注意力机制, 使模块中的权重信息流动并相互配合, 充分发挥注意力机制的优势.算法利用稀疏块中稀疏结构的平滑空洞卷积提取图像特征, 在扩大卷积核感受野的同时减少特征信息的丢失.实验表明, 本文算法在真实的非均匀有雾图像及合成的有雾图像上均能取得良好的去雾效果, 恢复的无雾图像整体更清晰、色彩更自然.
本文算法能有效处理非均匀有雾图像中的雾噪声, 较好地还原图像的原始色彩, 对非均匀雾图的去雾效果良好, 但还存在如下不足之处:对于雾较浓的区域, 算法处理后的图像去雾效果不够理想; 在浓雾区域去雾不够彻底, 仍有部分雾霾残留; 容易引入新的噪声, 出现颜色不均匀的色块.这些都是今后需要改进的方面.
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|