



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于Lmser-in-Lmser双向网络的人脸素描图像生成方法
[盛庆杰1 , 苏锐丹1 , 涂仕奎1 , 徐雷1  ]
]
]
|
|



作者简介:
盛庆杰,硕士研究生,主要研究方向为人脸素描图像生成、双向深度学习.E-mail:seansheng@sjtu.edu.cn.

苏锐丹,博士,助理研究员,主要研究方向为机器学习、双向智能.E-mail:suruidan@sjtu.edu.cn.

涂仕奎博士,副教授,主要研究方向为机器学习、生物信息学.E-mail:tushikui@sjtu.edu.cn.
人脸素描图像生成问题目的是将人脸照片转换为对应的素描图像,已有方法生成的素描图像或缺乏素描纹理,或需要在额外的大规模数据集上进行预训练.针对上述问题,文中基于Lmser(Least Mean Square Error Reconstruction)构建内外嵌套的深度双向网络,即Lmser-in-Lmser双向网络,用于人脸素描图像的生成.利用Lmser的神经元对偶特性,即编码神经元和解码神经元之间形成双向短路连接,在内部Lmser子网络的编码器和解码器之间通过前向传递不同网络层进行学习,得到多层级特征,增强素描生成的纹理细节.同时建立具有同样结构的网络,反向建立素描映射到照片的模型.外部通过在2个Lmser子网络上施加一致性约束,实现反馈链接,改善素描特征.在基准数据集上的实验表明,文中方法性能较优,并且不需要在额外的数据集上进行预训练,可应用性较强.
About Author:
SHENG Qingjie, master student. His research interests include face sketch synthesis and deep bidirectional learning.
SU Ruidan, Ph.D., assistant professor. His research interests include machine lear-ning and bidirectional intelligence.
Tu Shikui, Ph.D., associate professor. His research interests include machine lear-ning and bioinformatics.
Face sketch synthesis aims to transform a face photo into a face sketch. For existing methods, the generated sketches are over-smooth and the pre-training on additional large scale datasets is required. In this paper, a deep bidirectional network based on the least mean square error reconstruction(Lmser) self-organizing network is constructed with a feature of duality in paired neurons(DPN) to generate face sketch. DPN is realized with bidirectional shortcuts between encoder and decoder. It helps transfer features learn from different layers of the Lmser to improve texture details in synthesized sketch. Another sketch-to-photo mapping network is built by a complement Lmser with converse direction sharing the same structure. The bidirectional mappings form an outer Lmser network with DPN enforce consistency between the paired blocks in a global manner. Experiments on benchmark datasets demonstrate that the performance of the proposed method is superior, and it is more applicable and does not need pre-training on additional datasets.
本文责任编委 兰旭光
Recommended by Associate Editor LAN Xuguang
人脸素描图像生成是指将给定的人脸照片生成相应的素描图像.对此类问题的研究可协助缩小犯罪嫌疑人的范围, 并且随着科技的发展, 该研究成果也出现在一些数字产品中, 如特色人物肖像图生成.迄今发展起来的方法可粗略分为两类:数据驱动方法和模型驱动方法[1].数据驱动方法的核心在于人脸照片切片和素描图像切片的相似度搜索, 从训练集上的素描图像切片集合中, 选定与人脸照片相似的切片进行线性组合, 合成最终的素描图像[2, 3].模型驱动方法的核心在于学习一种从人脸照片映射到素描图像的模型, 直接获得生成结果[4, 5, 6, 7].
Tang等[8]提出基于特征变换的数据驱动方法, 通过主成分分析将测试照片映射到训练图像集的特征空间中, 再通过这个映射将训练素描集进行加权线性组合, 生成最后的素描图像.Liu等[9]将整个人脸照片细分为方形切片, 各切片与邻近切片部分重叠, 再通过近邻相似度搜索, 使用欧氏距离, 在切片级别上计算加权线性组合, 生成素描图像.Wang等[1]采用马尔可夫随机场模型, 并考虑近邻一致性.
考虑到上述方法中相似度搜索的过程效率很低, Song等[2]提出SSD(Spatial Sketch Denoising), 将人脸素描图像生成问题视为一种素描空间降噪问题并进行处理.Wang等[3]提出RSLCR(Random Sampling with Locality Constraint for Face Sketch Synthesis Me-thod), 采用随机采样策略搜索最近邻切片.这两种方法将生成一幅素描图像的效率提升到可接受的层级, 但相比那些没有类似相似度搜索机制的模型驱动方法, 仍存在很大差距.Zhu等[10]提出DPGM(Learning Deep Patch Representation for Probabilistic Graphical Model), 利用深度神经网络统一提取图像切片的特征, 采用离线的候选切片索引方法加速切片相似度的搜索过程.Zhu等[11]提出基于知识蒸馏的模型, 从大规模数据集上学习人脸照片知识和素描图像知识, 传递给素描图像生成模型, 提高生成图像质量.
传统的模型驱动方法基于CNN网络学习一个由人脸照片直接到素描图像的生成模型.Zhang等[4]提出FCN(Fully Convolutional Network), 采用7层的完全全连接网络, 结合最小平方误差损失函数构造生成模型.Zhang等[6]提出分支的完全全连接网络模型, 一分支生成脸部结构, 另一分支生成脸部纹理, 再根据人脸解析的结果组合两者.近期, 学者们开始关注基于生成对抗网络(Generative Adver-sarial Network, GAN)[12]的模型, 以求生成更高质量的人脸素描图像.相比数据驱动方法和传统模型驱动方法, 基于GAN的模型可扩展网络并结合其它机制[13, 14], 提高生成素描图像的质量, 减少污点和变形, 视觉感受更自然.Isola等[15]提出pix2pix, 能适应多种有成对训练样本的图像到图像转换问题, 如图像风格转换[16]、标签到街道场景图像、语义分割等.Zhu等[17]提出CycleGAN, 是一种无监督学习模型, 由2个循环组成, 分别是X→ Y→ X和Y→ X→ Y, 目标是让2个循环的输入和最终输出保持一致.Wang等[5]提出BP-GAN, 结合条件GAN与反向投影策略, 进一步提升生成素描图像的质量.Wan等[18]提出一种细节损失函数, 加强素描图像生成的细节表现.Zhang等[19]提出由多重特征生成器与级联低阶表示以优化不同光照条件下的人脸素描图像生成方法.Li 等[20]提出基于正则化的广义学习系统, 当提取的特征映射节点不足时, 无需重新训练便可重构生成网络.Yu等[7]提出SCA-GANs(Stacked Composition-Aided GAN), 扩展pix2pix框架, 以人脸图像中组成部位的结构信息指导素描图像的生成, 并采用结构性损失[6, 21]增强人脸各部位和结构的信息, 结合感知损失和网络堆叠策略, 表现较优.
然而, 上述数据驱动方法由于采用相似素描图像切片线性组合的生成方式, 导致最终合成的图像过于平滑, 与画师绘制的人脸素描图像差异较大, 而且在测试阶段, 相似度搜索的过程较耗时, 不利于实际应用.模型驱动方法在人脸素描图像生成领域的研究和应用较突出, 但较早的研究考虑到网络的训练难度和效率, 采用相对简单的网络模型, 相比画师绘制的人脸素描, 生成的素描图像质量较差、污点较多, 在细微的结构和纹理上有所欠缺, 存在扭曲变形的问题, 仍有较大的改进空间.Yu等[7]和Johson等[22]引入感知损失(Perceptual Loss)和人脸解析机制, 提高网络表现, 但通常需要在大型数据集上进行预训练, 受限于本身的数据集与辅助数据集之间数据模式和分布的差异, 应用场景改变后可能不再对模型起正向作用, 并且这些辅助的大型数据集收集成本较高, 实际应用门槛较高.
为了克服这些问题, 使模型在不依赖辅助数据集的同时, 依然具有良好表现, 本文基于Lmser(Least Mean Square Error Reconstruction)[23], 构建内外嵌套的深度双向学习模型, 即Lmser-in-Lmser双向网络.进而提出基于Lmser-in-Lmser双向网络的人脸素描图像生成方法.首先, Lmser-in-Lmser双向网络结合内部神经元对偶(Duality in Paired Neurons, DPN)前向传递和外部DPN反馈传递信息的特性, 强化人脸照片到素描图像的生成效果.引入并改进感知损失机制, 以素描图像的特征一致性正则化约束素描图像生成网络, 提高生成性能.直接采用模型本身的子网络作为感知网络以提取素描图像的特征, 使模型不再依赖额外数据集, 可应用性较强.
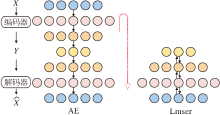
自编码器(AutoEncoder, AE)[24]是早期的一种深度双向学习神经网络, 如图1左图所示, 圆圈表示全连接神经网络中的神经元.入向网络(X→ Y)是编码器, 产生输入数据的内部编码或表示, 如图像、文字等转化为隐空间中的编码; 出向网络(Y→
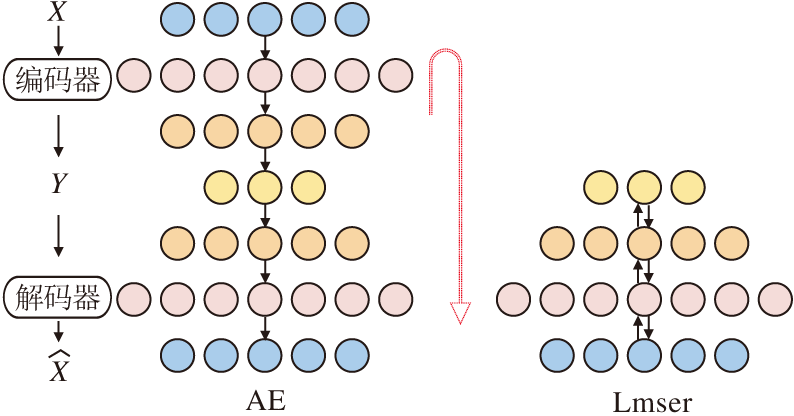 | 图1 AE和Lmser结构对比Fig.1 Structure comparison of AE and Lmser |
Lmser是AE的进一步发展, 如图1右图所示, 将AE沿着中间编码层Y对折得到.对折使神经元融合后同时承担编码和解码两个角色, 因此具有多种对偶特性[25].例如, 它的神经元具有编码和解码的双重特性, 称为DPN对偶性.早期的Lmser相关研究是在全连接网络上展开的, 然而受限于算力和数据, 仅实现含一个隐层的Lmser网络.最近, 学者们回顾和扩展Lmser[25, 26], 不仅实现为深度神经网络[26], 还拓展到卷积神经网络[27]中.Lmser能利用DPN在不同方向上、在一个或多个网络层的连接上扩展网络功能, 成功应用到图像修复[27]、图像超分辨率[28]、图像分割[29, 30]等研究.这些研究结果验证Lmser被提出时认为具有的各种功能, 包括图像联想、记忆等[23].
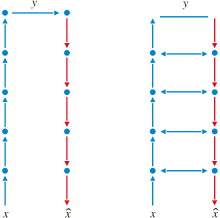
Lmser的DPN特性可视为编码器和解码器之间对应神经元的双向短路连接.如图2所示, 图中箭头表示全连接神经网络的连接方向(修改自Xu[25]的图1).DPN使对应神经元可相互融合信息, 所在特征层可互相传递信息.研究结果表明, DPN特性是有效的信息交换、融合机制, 可提升深度神经网络的表示学习能力.本文采用的Lmser就是基于卷积神经网络设计的, 并通过内外嵌套两种层次的DPN特性以强化信息的融合、共享, 达到提高模型鲁棒性和表现的目的.
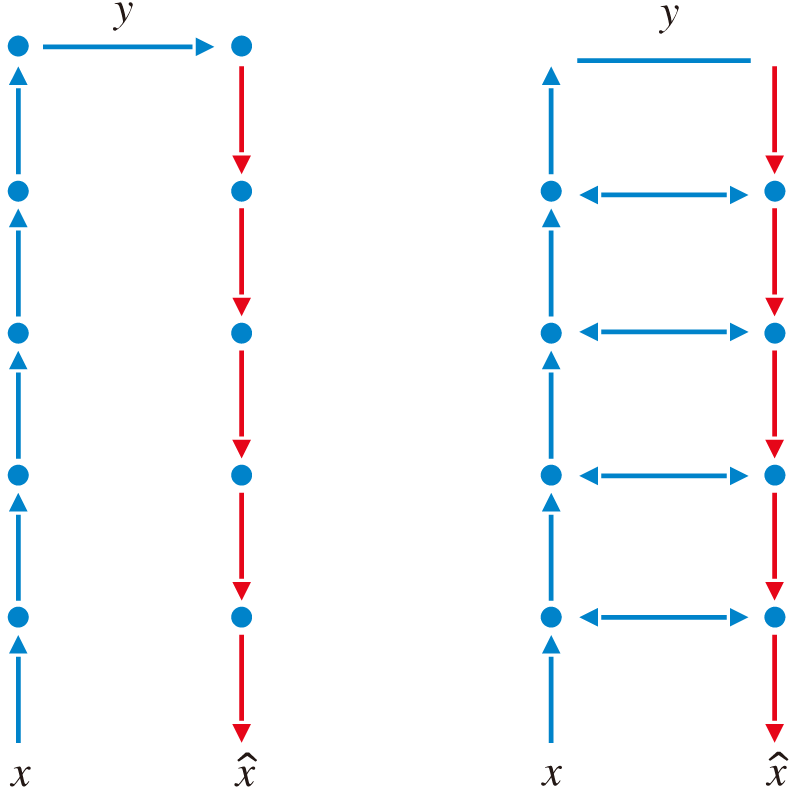 | 图2 Lmser的DPN特性Fig.2 DPN of Lmser |
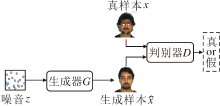
传统的GAN由一个生成器G和一个判别器D组成, G和D均由神经网络实现.GAN结构如图3所示.
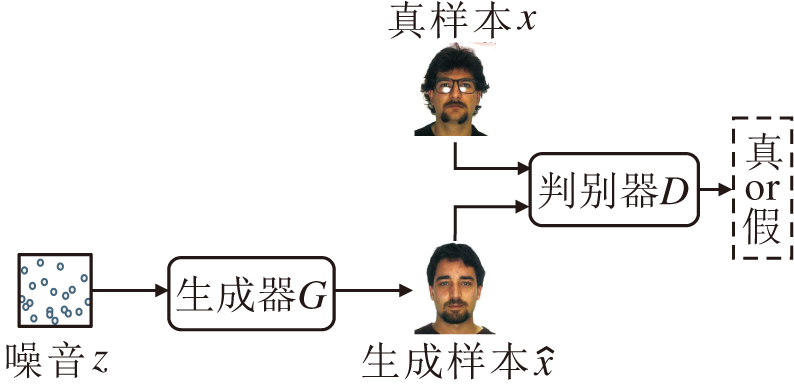 | 图3 生成对抗网络结构图Fig.3 Structure of GAN |
生成器G的输入服从某高斯分布的随机噪音z~pz(z), 输出期望符合某些特征的数据
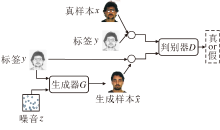
条件生成对抗网络(Conditional GAN, cGAN)[31]是对GAN的一种扩展, 结构如图4所示.在cGAN中, 生成器G和判别器D都以某些额外信息y作为条件, 即G的输入为{z, y}, D的输入为
Isola等[15]针对图像转换问题进一步扩展cGAN, 生成器G的输入不再是随机噪音, 而是特定的图像数据, 达到通过给定图像生成期望图像的目的.为了使生成的图像具有多样性, 在生成器G的隐空间中也引入随机噪音z.
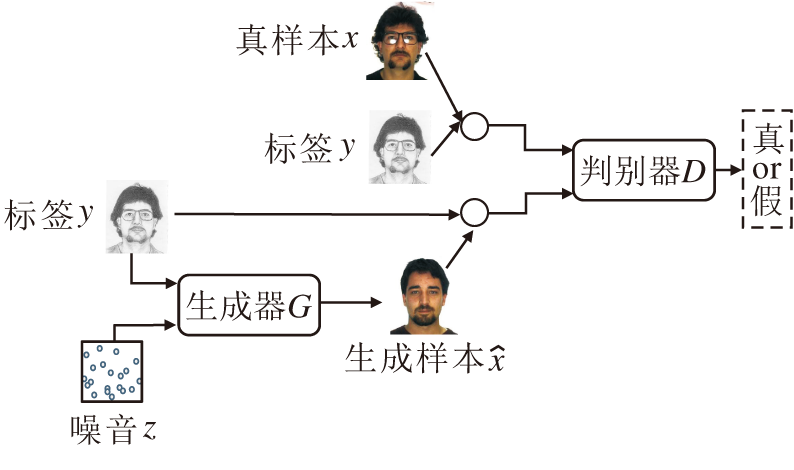 | 图4 条件生成对抗网络结构Fig.4 Structure of cGAN |
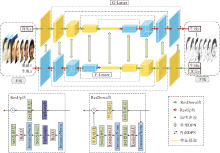
本文提出Lmser-in-Lmser双向网络, 整体结构如图5所示.
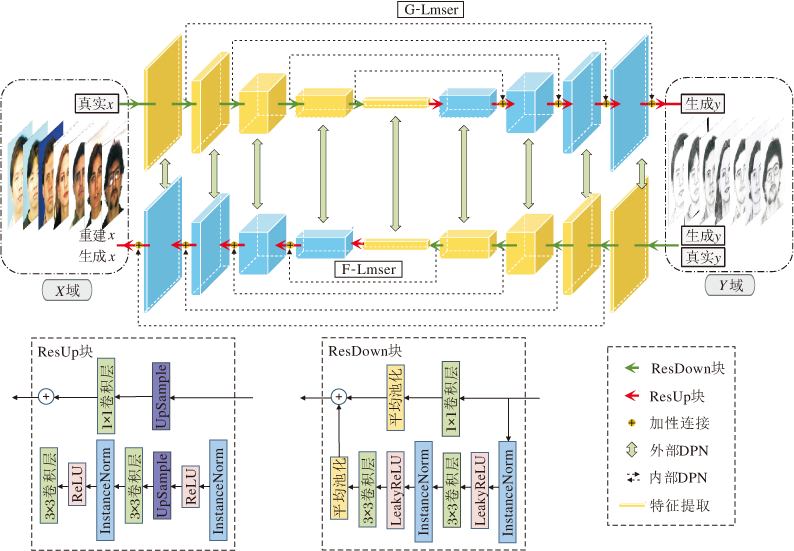 | 图5 Lmser-in-Lmser双向网络结构图Fig.5 Structure of Lmser-in-Lmser bidirectional network |
记X为人脸照片域, Y为素描图像域.网络的目的在于学习一个从X域到Y域的映射, 即给定人脸照片找到对应的素描图像.X的样本集合为
内部DPN位于内部的2个Lmser网络中, 具体表现为从特征图的收缩路径到对应的扩展路径上的跳跃连接, 以往相关工作绝大部分采用拼接式的跳跃连接, 而预实验结果表明, 加性和拼接式方式在图像生成能力上几乎相同.本文为了让内部DPN更好地适配外部DPN, 在每个Lmser网络中采用加性跳跃连接.
外部DPN是指在G-Lmser和F-Lmser中, 施加在两者之间匹配的网络块上的一致性约束:
Ldpn(G, F, X, Y)=
其中, Ψ i、Φ i分别表示G-Lmser和F-Lmser中对应的第i层特征图(如图5中浅绿色双向箭头所示),
本文将人脸照片数据表示在RGB色彩空间中, 素描图像数据表示在灰度色彩空间中.G-Lmser网络结构见图5上面的子网络, F-Lmser与G-Lmser具有相同的结构但方向相反, 见图5下面的子网络.以G-Lmser为例, 包括解码器和编码器两个部分, 图5中G-Lmser左侧黄色部为解码器, 包括5个残差模块(ResDown块), 右侧蓝色部为解码器, 也包括5个残差模块(ResUp块).ResDown块和ResUp块具体网络结构见图5下方2个虚线框, 分别用Di/j和Ui/j表示, 在ResDown块中使用斜率为0.2的ReLU激活函数, i为输入通道数, j为输出通道数, Lmser具体如下:
Din/128→ D128/256→ D256/512→ D512/512→ D512/1024→ U1024/512→ U512/512→ U512/256→ U256/128→ U128/out.
网络使用2个对抗式判别器DY和DX.DY用于区分素描图像是生成网络生成的还是画师所画的真素描图像, 即区分{x, G(x)}与{x, y}, DX用于区分人脸照片是生成网络生成的还是真正的照片, 即区分{y, F(y)}与{y, x}.判别器DX和Dy均沿用Isola等[15]提出的70× 70 patchGAN(Patch-Based GAN)结构.
本文将F-Lmser用作感知网络, 从y和G(x)中提取高层特征.然后, 采用一致性损失让两者对应的特征相互趋近.此做法与文献[7]和文献[22]类似.不同的是, 文献[7]和文献[22]是使用一个预训练好的网络提取人为指定的多层特征图, 在训练过程中保持这部分网络参数不变.这类方法采用的感知网络都由其它大规模数据集预训练所得, 通常在图像数据的模式上与当前训练集兼容性较差, 并不能总提高模型的表现.另外, 本文还考虑感知网络输出层的一致性, 将感知损失和输出层的一致性损失融合为一个损失函数:
其中Φ 5表示网络中间隐藏层提取的特征图.
在两个映射模型中, 采用LSGAN(Least Squares GAN)[33].具体实现时, 本文将LSGAN与条件GAN结合应用, 使网络更容易收敛, 表现也更优.由于本文目的在于生成确定的素描图像, 所以不再引入条件GAN中的随机噪音.以G-Lmser G∶ X→ Y和其对应的判别器DY为例, 损失函数可表示为
Ladv(G, DY, X, Y)=Ex, y[(1-D(x, y))2]+Ex[(D(x, G(x)))2].
参考文献[7]和文献[15], 本文还采用L1损失激励“ 假” 输出拟合“ 真” 样本的分布, 即
完整的损失函数如下:
L(G, DY, X, Y)=Ladv(G, DY, X, Y)+λ
L(F, DX, Y, X)=Ladv(F, DX, Y, X)+λ
其中, λ 、 β 、α 表示权重因子, 实验设置λ =10, β =1, α =5.最终目的在于求解以下问题:
(G* ,
(F* ,
为了优化方法, 本文先交替使用梯度下降法训练DX和DY, 再训练G和F.使用Adam(Adaptive Moment Estimation)优化器, 批大小为1, 生成器的学习率为0.000 1, 判别器的学习率为0.000 2.优化算法步骤如下所示.
算法 Lmser-in-Lmser双向网络优化算法
输入 训练照片和素描图像的集合, 迭代步数t=0, 最大迭代步数T
输出 生成样本
当t< T时, 操作如下.
step 1 随机挑选一组训练样本.
step 2 估计生成素描图像和生成人脸照片:
step 3 估计重建人脸照片:
step 4 更新DX, DY:
step 5 更新G, F:
G* =arg
结束循环
算法中训练照片和素描图像的集合表示为二元素形式, 如[1幅人脸照片x, 1幅匹配的素描图像y].
实验在使用单个显卡(Nvidia Titan X型号)的服务器上进行, 运行环境为Anaconda, python 3.6, 详细代码和数据公布在GitHub上.
在CUFS[1]、CUFSF数据集[34]这2种广泛应用和开源的公共数据集上进行实验.CUFS数据集共包含606对人脸照片和素描图像, 由3个子数据集组成, 分别是CUHK student数据集[35](188对)、AR人脸数据集[36](123对)和XM2VTS数据集[37](295对).CUFSF数据集共包含1 194对人脸照片和素描图像.由于此数据集中的人脸照片是在多种光照条件下采集, 并且素描图像有较剧烈的变形和夸张元素, 因此更具挑战性.
为了与代表性方法进行对比, 本文遵循Wang等[3]的数据集划分方式.将CUHK student数据集上的88对、AR人脸数据集上的80对和XM2VTS数据集上的100对人脸照片和素描图像用于训练, 其余用于测试.对于CUFSF数据集, 250对人脸照片和素描图像用于训练, 其余用于测试.
在对原始数据的处理上, 本文采用Yu等[7]的设置, 对原始数据集上未对齐的数据, 根据双眼和嘴唇中间三点进行几何校正, 然后将所有图像裁剪至250× 200尺寸.由上述方式得到的图像无法直接输入方法中, 需要进一步调整.在pix2pix[15]中, 直接将图像数据调整到256× 256尺寸, 但会从一定程度上破坏原图像中人脸的结构, 对实验结果有一定干扰.本文采用先填充再裁剪的数据预处理方式, 即先将图像环绕填充到286× 286尺寸, 并且在训练中为了增强数据, 以随机方式裁剪到256× 256尺寸, 而在测试时裁剪中央尺寸为256× 256的部分.Yu等[7]使用0值(即黑色)填充, 在本文实验中发现, 相比采用255值(即白色)填充, 这样设置会使生成的图像产生更多的污点, 所以本文采用255值环绕填充.
为了验证本文方法的有效性, 采用如下3种普遍使用的测试指标进行定量分析.
1)FID(Fré chet Inception Distance)[38].衡量真实图像与生成图像在特征上的推土机距离(Earth Mover's Distance, EMD).越低的FID数值意味着真实图像与生成图像之间的分布和感知特征越接近.
2)FSIM(Feature Similarity)[39].以图像相位一致性和梯度幅值衡量真实图像与生成图像一致性的指标.
3)NLDA(Null-Space Linear Discriminant Analy-sis)[3].人脸识别是人脸素描图像生成问题的一个重要应用.Wang等[3]使用NLDA进行人脸识别实验, 本文同样采用NLDA评估真实素描与生成素描的人脸识别准确率.
针对Lmser-in-Lmser双向网络中的各种不同模块进行消融实验, 评估各模块对网络的影响.针对网络中不同的组件及其组合, 分别进行6组实验.在CUFSF数据集上的消融实验结果如表1所示, Baseline表示以加性内部DPN实现的生成器G结合pix2pix框架组成的基本模型, concat表示以拼接式跳跃连接方式实现的内部DPN, global DPN表示引入外部DPN, Lvgg表示Yu等[7]采用的传统感知损失, Lc为本文2.3节定义的损失.
| 表1 各模块在CUFSF数据集上的消融实验结果 Table 1 Results of ablation experiments of different components on CUFSF dataset |
由表1可见, 只采用pix2pix框架时, Lmser-in-Lmser双向网络中的内部DPN采用加性和传统拼接式跳跃连接的表现几乎相同.在引入外部DPN之后, 性能获得明显提升, FID值从15.2降至14.0.由此可验证外部DPN确实会实现通过F-Lmser达到正则化约束G-Lmser的目的, 强化2个Lmser生成器之间的信息流动, 以间接方式实现信息共享, 从而使G-Lmser从另一方得到支持和增强.
相比Yu等[7]采用传统的感知损失, Baseline+Lc将FID值从15.2降至14.3, 但是Baseline+Lvgg将FID值从15.2增至17.7, 这是因为Yu等[7]采用的感知网络由VGGFace数据集预训练所得, 此数据集上人脸照片的样式与CUFSF数据集上的样式存在较大差异, 训练的感知网络不能有效提取CUFSF数据集上的数据特征.
在2种DPN特性基础上引入本文采用的感知损失之后, 性能得到进一步改进, FID值从14.0降至13.6.这意味着本文的感知损失有助于提升Lmser-in-Lmser双向网络的性能, 并且由于直接在Lmser-in-Lmser双向网络上实现, 未引入额外的感知网络, 整个网络的参数量更少.
本文选择如下方法进行对比实验.1)数据驱动方法:SSD[2]、RSLCR[3]、BP-GAN[5]、DGFL(Deep Graphical Feature Learning)[40].2)模型驱动方法:SCA-GANs[7]、DPGM[10]、pix2pix[15].
各方法在2个数据集上的指标值对比如表2所示, 表中黑体数字表示最优值.由表可见, 本文方法取得最小的FID值.另外, 相比其它方法, 本文方法在FSIM值和NLDA值上也具有竞争力.值得一提的是, 在更具挑战性的CUFSF数据集上, 本文方法改进更明显, 鲁棒性更强, 可应对更复杂的情形.
| 表2 各方法在2个数据集上的指标值对比 Table 2 Index value comparison of different methods on 2 datasets |
各方法在CUFS、CUFSF数据集上一些图像样本生成的素描图像如图6所示.由图可看出, 数据驱动方法, 如SSD、RSLCR, 和一些结合神经网络模块的数据驱动方法, 如DGFL、BP-GAN、DPGM, 生成的人脸素描较平滑.BP-GAN、DPGM生成的素描图像有较清楚的轮廓和结构, 但FID值相对较高, FSIM值也相对较低, 可见素描图像的平滑程度是与图像的感知相似度密切相关的.
 | 图6 各方法在2个数据集上生成的人脸素描图像Fig.6 Face sketch images generated by different methods on 2 datasets |
pix2pix没有这种平滑的问题, 然而生成的结果污点很多.SCA-GANs是基于pix2pix框架, 并结合人脸结构解析和感知损失机制的方法, 而人脸结构解析和采用的感知损失方法均依赖不同的辅助大型数据集.SCA-GANs改进效果较明显, 生成的素描图像人脸细节较丰富、清晰, 但在一些细微的结构和纹理上仍存在不足, 如眼镜框部位和人脸腮部纹理.本文方法能生成视觉上更真实的人脸素描图像, 特别是在人脸细微之处.以图6结果来说, Lmser-in-Lmser双向网络能生成完整的眼镜框(AR、XM2VTS数据集上的取样)、脸部皱纹(AR数据集上的取样)、细致丰富的脸部纹理(CUHK、XM2VTS数据集上的取样), 并且扭曲和变形更少(CUFSF数据集上的取样).这是由于本文网络的结构和机制更优, 外部DPN中的一致性约束增强模型的鲁棒性, 从而最终的表现更优.
本文从两个角度验证Lmser-in-Lmser双向网络的鲁棒性:1)测试不同尺寸大小照片的输出结果; 2)测试不同数据模式下的输出结果.在CUFS数据集上训练本文方法, 进行如下实验.
为了验证Lmser-in-Lmser双向网络在不同分辨率图像上的鲁棒性, 对CUFS数据集上的测试数据进行下采样和上采样处理后再作为输入, 模拟不同分辨率的情况, 结果如图7所示.由图可知, 相比正常尺寸, 分辨率为125× 100的输出结果较模糊, 损失较多的细节信息, 生成效果不够理想.分辨率为500× 400的输出结果在视觉上清晰度较高, 仍保持轮廓和纹理信息, 但一些区域引入污点, 生成效果也低于分辨率为250× 200的结果.
 | 图7 不同输入尺寸照片生成的素描图像Fig. 7 Generated face sketch with different input sizes |
以在光照、姿态、场景等数据模式上与训练集差异较大的图像作为输入, 验证本文方法的鲁棒性.本文采集一些符合要求的图像数据, 并简单裁剪处理成方法需要的250× 200的尺寸, 不做几何校正.图像及其测试结果如图8所示.
 | 图8 特定条件和种类照片生成结果的素描图像Fig.8 Generated sketch of different sorts of images and different conditions |
由图8可知, 图像a、b是在极端光照条件下的照片.图像c~e是在网络上采集的3张人物照片, 这3张人脸照片未经过三点几何校正, 姿态也有所差异.图像f、g为2种不同宠物犬的照片, 图像h、i为2个不同场景的建筑照片.这些照片与训练集上的数据模式差别都较大, 虽然不是人类的照片, 但本文方法仍能有效工作.
pix2pix是应用在图像转换问题上的.为了验证Lmser-in-Lmser双向网络在图像转换问题上的表现也较优, 同时也为了观察Lmser-in-Lmser双向网络在较大规模数据集上的表现, 开展pix2pix中与本课题相似的鞋类照片→ 边缘图的图像转换实验.实验在Edges2shoes数据集上进行.该数据集上, 训练集共49 825对样本, 测试集共200对样本.训练时的图像尺寸均为256× 256, 鞋类照片表示在RGB色彩空间中, 鞋类边缘图表示在灰度空间中.
本文方法和pix2pix在Edges2shoes数据集上的转换结果如图9所示.由图可见, 相比目标边缘图, pix2pix生成的边缘图只有轮廓部分较完整, 缺少内部的细节线条.而本文方法生成的结果包含更细致准确的特征, 内部线条更丰富.由此可见, G-Lmser经过F-Lmser的激励之后, 生成能力更出色, 这表明Lmser-in-Lmser双向网络能有效工作在具有不同规模数据集的任务上.
 | 图9 各方法在Edges2Shoes数据集上的转换结果Fig.9 Synthesis results of different methods on Edges2Shoes dataset |
同时, 以本文方法在CUFS数据集上训练的模型进行鲁棒性测试, 结果见图9(e), 由于训练集数据的模式差异, 生成的结果素描色彩较浓重.
鞋类照片→ 边缘图转换实验的FID值如下:pix2pix为72.7, 本文方法为66.4, 鲁棒性测试结果为336.5.这也从客观上说明本文方法更优.
本文针对人脸素描图像生成问题, 提出Lmser-in-Lmser双向网络, 用于人脸素描图像的生成.融合内部DPN和外部DPN这两种Lmser中对偶特性的变种, 实现信息的前向传递和反馈传递.内部DPN采用加性跳跃连接, 将编码器提取的特征前向传递到解码器, 促进内部Lmser子网络的学习, 同时外部DPN又激励G-Lmser与F-Lmser中的网络块保持一致性倾向, 将F-Lmser的高层语义特征和底层细节信息间接反馈给G-Lmser.这不仅加强局部和全局方式的信息流, 而且让模型直接实现一种新形式的感知损失机制, 进一步提高模型的表现.在CUFS、CUFSF数据集上的实验说明, Lmser-in-Lmser双向网络可合成高质量的人脸素描图像, 改进效果较明显.此外, Lmser-in-Lmser双向网络不依赖其它大型数据集补充信息, 双向网络可在缺乏大型数据集辅助或大型数据集收集成本难以承受的情况下较好的工作.今后考虑尝试引入Lmser网络的其它对偶特性, 如网络权重对偶特性, 提高模型性能.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|