



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于多尺度注意力机制的场景文本擦除
[何平1, 2  , 张恒
, 张恒2 , 刘成林2, 3 ]
, 张恒, 刘成林]
|
|



作者简介:
何 平,硕士研究生,主要研究方向为场景文本风格变换.E-mail:ping.he@nlpr.ia.ac.cn. 
张 恒,博士,副研究员,主要研究方向为文档图像分析与识别.E-mail:heng.zhang@ia.ac.cn.
自然场景文本擦除技术可应用在图像通信中的隐私保护、图像编辑等领域,然而现阶段的场景文本擦除在面对背景复杂、文本尺度变化较大的场景图像时,难以提取鲁棒的文本特征,出现文本检测不全、背景修复不完整等问题.针对上述问题,文中提出基于多尺度注意力机制的场景文本擦除框架.该框架主要由背景修复网络和文本检测网络共同组成,它们共享一个主干网络.在背景修复网络中,设计纹理自适应模块,从原始特征的通道和空间两个维度进行特征编码,自适应地集成局部特征与全局特征,有效修复因重构文本区域而导致的阴影部分.在文本检测网络中,设计上下文感知模块,学习图像中文本区域和非文本区域之间的判别关系,有效区分文本区域和非文本区域,提升文本检测的效果.此外,为了增强网络的感受野,改进不同尺度文本的擦除效果,提出多尺度特征损失函数,同时优化背景修复网络和文本检测网络.SCUT-SYN、SCUT-EnsText数据集上的实验表明,文中框架可取得较优的文本擦除性能.
About Author:HE Ping, master student. His research interests include scene text style transformation.
ZHANG Heng, Ph.D., associate professor. His research interests include document image analysis and recognition.
Scene text removal is of great significance for privacy protection and image editing in image communication. However, existing scene text removal models are insufficient in extracting robust features for images with complex background and multi-scale texts, resulting in incomplete text detection and background repair. To solve this problem, a scene text removal framework based on multi-scale attention mechanism is proposed for robust background repair and text detection. The proposed framework is mainly composed of background repair network and text detection network, sharing a backbone network. In the background repair network, a texture adaptive module is designed to encode the channel/spatial features and adaptively integrate local/global features, effectively repairing shadow parts in text reconstruction. To improve text detection, a context aware module is designed to learn the discriminative features between texts and non-texts in the image. Besides, to enhance the receptive field of the network and improve the removal of multi-scale texts, a multi-scale feature loss function is designed to optimize the background repair and text detection modules. Experimental results on SCUT-SYN and SCUT-EnsText datasets show that the proposed method can achieve the state-of-the-art performance in text removal.
本文责任编委 徐 勇
Recommended by Associate Editor XU Yong
场景文本作为信息传递的媒介, 不管是在现实世界还是在虚拟世界, 都与人类的生活、生产息息相关.除了新闻、报纸、招聘等共有信息之外, 场景文本也包含很多的私人信息或敏感信息, 包括交易信息、通信记录和内容、征信信息、账号密码、财产信息、行踪轨迹等[1, 2].如何保护个人信息不受不法分子的利用, 直接关系到个人的生命和财产安全.现有保护隐私的方法一般是直接删除图像文字中涉及个人隐私的信息, 但对于大量的图像文字, 删除需要高昂的人工成本.随着人工智能的发展, 基于深度学习的自然场景文本擦除[3, 4]成为一个新兴的研究方向, 相比自然场景文本检测[5, 6]技术, 场景文本擦除中的背景修复面临更多的挑战.
文本擦除借鉴图像修复的思想, 需要对文本区域进行背景复原, 但文本擦除比图像修复更困难, 因为文本擦除不仅需要关注文本区域, 还需要关注非文本区域, 防止非文本区域被网络误擦除.Shi等[7]通过局部相似性约束和稀疏建模, 提出有效的基于样本的修复算法, 先计算需要填充的顺序, 再重建目标文本区域, 以视觉合理的方式有效填充缺失像素.随着生成对抗网络(Generative Adversarial Networks, GAN)[8]应用于图像生成领域, Isola等[9]提出pix2pix, 使用条件生成对抗网络(Conditional GAN, cGAN)作为图像到图像的转换方法, 改变卷积核大小以提高网络的感受野.Isola等[9]证实使用PixelGAN(Pixel-Based GAN)[10]擦除文本会导致擦除的像素点变成红色, 而PatchGAN(Patch-Based GAN)[9]虽然可改进网络输出的清晰度, 但也会导致图像重影, 难以训练.相对来说, cGAN着色效果更优, 但是生成的图像中偶尔会产生部分灰度区域.
上述文本擦除方法虽然取得一定效果, 但鲁棒性较差, 只能在背景单一的图像上产生较好的擦除效果.而自然场景文本图像往往存在背景复杂多变、文本方向随意或字体多变等问题, 现有方法难以准确识别文本区域和非文本区域, 导致擦除效果较差.为了使文本擦除技术更好地满足人们日常生活的应用需求, 学者们开始研究复杂背景的自然场景文本擦除方法.近年来, 主要采用基于深度神经网络的方法.这些方法主要可分为两阶段方法和一阶段方法.
两阶段方法是将文本检测和背景修复作为上下游任务.先检测图像中的文本区域, 再将文本区域的掩码作为背景修复网络的输入, 对检测的文本区域进行修复.Tursun等[11]提出MTRNet(Mask-Based Text Removal Network), 使用人工提供的文本掩码辅助文本检测网络精准定位图像中的文本区域, 再修复检测的文本区域, 实现文本擦除区域的可控性.Zdenek等[12]提出不需要成对训练图像的弱监督方法, 利用现有的文字检测数据集[1, 13]和图像修复数据集[14, 15, 16]进行文本检测网络和背景修复网络的预训练, 只需要额外少量强标注数据进行模型调优.Tang等[4]和Cho等[17]优化文本检测网络, 使文本区域的定位更准确, 进一步提升文本擦除的性能.
一阶段方法使用端到端技术, 即只用一个网络框架完成文本擦除任务.Nakamura等[18]提出STE(Scene Text Eraser), 采用图像变换的方法, 对滑动窗口裁剪的图像进行快速处理.该方法为了提高模型输出的分辨率, 保留图像中非文本区域.Tursun等[19]为了解决图像裁剪会破坏上下文信息的问题, 提出DCNN(Deep Convolution Neural Networks), 通过“ 软注意力” 减少对文本区域裁剪残缺的负面影响, 使用“ 硬注意力” 准确识别图像中的文字信息, 进一步提升文本区域的擦除效果.为了加速网络训练的速度, Zhang等[20]提出EnsNet(Ensconce Net-work), 并使用4个损失函数增强文本区域的检测和擦除, 以保证非文本区域的完整性.为了解决文本定位问题, Liu等[3]和Tursun等[21]将文本检测网络和背景修复网络并行训练, 通过文本检测网络感知图像中的文本区域, 但在实际应用中, 输出的文本检测结果并未应用到背景修复网络, 只是为了使网络可更好地定位和修复自然图像中的文本.
相比一阶段方法, 两阶段方法的可解释性更强, 研究人员可通过可视化结果判断是文本检测网络需要优化, 还是背景修复网络需要优化.但是, 一阶段方法网络参数更少, 运行效率更高.现有的文本擦除方法忽视文本区域和非文本区域像素点之间的联系, 以及原始特征的通道和空间维度的相互关联, 所以都存在文字检测不准确、文本区域修复不连贯等问题.
为了解决上述问题, 本文提出基于多尺度注意力机制的场景文本擦除框架(Scene Text Removal Based on Multi-scale Attention Mechanism, MASTR).框架主要由文本检测网络和背景修复网络组成.文本检测网络可使背景修复网络感知图像中的文本区域, 文本擦除、背景生成、文本区域的重构与恢复由背景修复网络一步完成.在SCUT-SYN[20]、SCUT-EnsText[3]这2个文本擦除数据集上的实验表明, MASTR的擦除效果较优.
本文提出基于多尺度注意力机制的场景文本擦除框架, 整体框架如图1所示.文本检测网络和背景修复网络共享一个主干网络, 训练过程中并行优化.网络的整体训练是一个端到端过程.
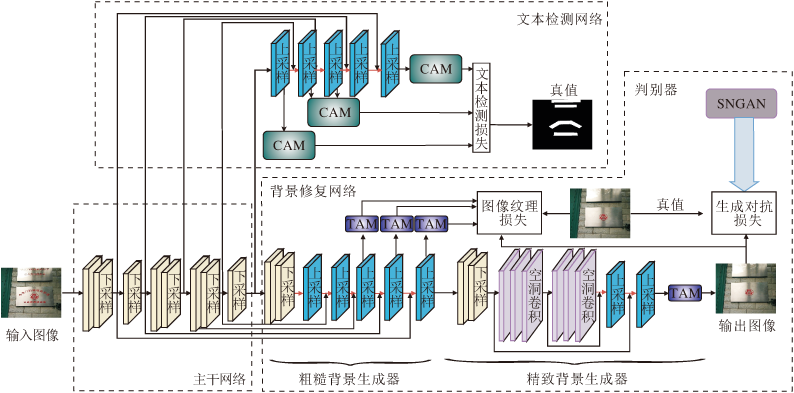 | 图1 MASTR整体框架Fig.1 Framework of MASTR |
受文献[22]的启发, 在场景文本擦除框架中设计上下文感知模块(Context Aware Module, CAM)和纹理自适应模块(Texture Adaptive Module, TAM).CAM学习图像中文本区域和非文本区域之间的判别特征, 增强网络的文本检测性能.TAM从原始特征的通道和空间2个维度进行特征提取, 有效修复因重构文本区域而导致的阴影部分.此外, 在文本检测网络和粗糙背景生成器中加入多尺度特征损失, 有效增强网络感受野, 提升网络对不同尺度文本的检测和擦除性能.
借鉴GAN的思想, 背景修复网络由生成器G和判别器D共同组成, 通过交替更新G、D的网络参数, 不断促进生成器学习图像中空间信息和语义信息的分布, 生成和目标域相同的图像, 最终使判别器无法对数据来源做出正确判断.
1.2.1 生成器结构
由以往场景文本擦除方法[4, 21]可知, 深度神经网络通过提取更丰富的特征信息, 可缓解大规模文本区域难以修复的问题, 而浅层神经网络[21]提取的特征抽象程度不高, 常因感受野较小导致文本区域修复不完整.因此本文也采取两阶段生成器, 第1阶段为粗糙背景生成器, 第2阶段为精致背景生成器.粗糙背景生成器和文本检测网络共享一个主干网络, 主干网络由2个卷积层和6个残差模块[23]组成.
为了加强特征的纹理特征表示能力, 本文设计TAM, 结构如图2所示.TAM从原始特征的通道和空间2个维度进行特征表示, 自适应地集成局部特征与全局特征, 有效提升背景修复效果.学习过程分为两步, 先学习原始特征的通道注意力得分, 再在此基础上学习该特征的空间注意力得分.
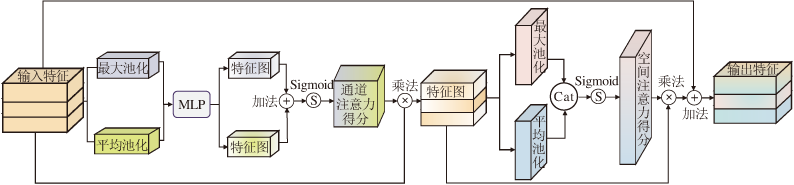 | 图2 TAM模块结构Fig.2 Structure of TAM module |
记输入到TAM的特征图x∈ (C, H, W) , 其中, C表示通道数, H表示高度, W表示宽度, 通道注意力得分为:
Cscore(x)=S(MLP(Max(x))+MLP(Mean(x))),
其中, S(· )表示Sigmoid激活函数, Max(· )表示对特征图进行最大池化, Mean(· )表示对特征图进行平均池化.多层感知机(Multilayer Perception, MLP)是一个两层的神经网络, 第1层神经元个数为C/16, 第2层神经元个数为C.空间注意力得分为:
Sscore(x)=S(Max(x)‖ Mean(x)),
其中‖ 表示矢量拼接操作.
粗糙背景生成器将输入的原始图像进行5次下采样和5次上采样, 在上采样过程中矢量拼接下采样特征, 通过矢量拼接不同层次的特征, 缓解因网络加深而导致空间信息损失的问题.借鉴特征金字塔网络(Feature Pyramid Networks, FPN)[24]的思想, 基于修复区域的尺度大小不一, 利用网络的每层卷积对图像进行多尺度特征提取, 使图像可产生丰富的特征表示.在上采样过程中, 将128× 128、256× 256、512× 512的图像分别送入TAM中, 自适应地集成局部特征与全局特征, 再分别计算相应分辨率真值图像和经过TAM输出图像的L1损失函数.
精致背景生成器的输入是粗糙背景生成器的输出, 可加深网络层数, 获取更丰富的语义信息.精致背景生成器为了有效增强网络感受野, 尽量获取更大范围的图像信息, 在128× 128的特征上进行6次空洞卷积[25], 并应用跳跃连接集成低级语义信息与高级语义信息.为了防止信息冗余, 只在精致背景生成器网络中的最后一层应用TAM, 再计算网络最终输出和对应真值的L1损失函数.
1.2.2 判别器结构
本文使用的判别器为SNGAN(Spectral Norm GAN)[26], 在cGAN基础上使用SpectralNorm函数代替BatchNorm2d函数, 使判别器满足Lipschitz约束, 优化网络的训练.
判别器的输入是
其中, Maskgt表示对应的文本掩码真值, 0表示非文本区域, 1表示文本区域, Fimg表示输入到MASTR的图像, Feg表示精致背景生成器的最终输出.
当输入的原始图像进行背景修复时, 网络应提供精准的文本区域定位, 保证背景修复的连贯性及非文本区域的完整性.由于背景修复是从粗糙背景生成器开始, 因此文本检测网络和粗糙背景生成器共享一个主干网络.
由于文本区域在一幅图像上只占有较少的一部分, 应使网络着重关注于文本区域而非整幅图像, 特征提取过程中给文本区域赋予更高的权重, 过滤噪声信息.其次, 文本区域的像素点一般都是连续出现, 不会在非文本区域存在几个孤立的文本像素点, 所以需要过滤独立噪声.基于上述分析, 本文在TAM的基础上进一步改进, 设计CAM, 结构如图3所示.
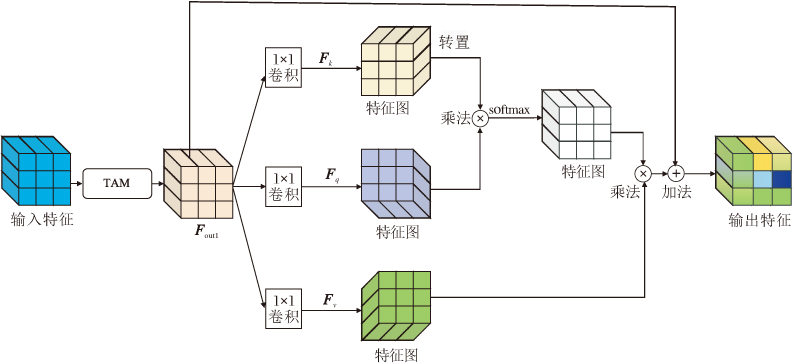 | 图3 CAM模块结构Fig.3 Structure of CAM module |
先将特征输入TAM, 自适应学习其中的纹理特征, 得到Fout1.再进行自注意力学习, 充分挖掘图像中像素点之间的依赖关系, 得到最终的特征输出Fout2.具体过程如下.
将Fout1∈ RC× H× W分别送入3个卷积核均为(1, 1)、输出通道数为C/16、C/16、C的特征空间Fk(x)、Fq(x)和Fv(x):
Fk(x)=Wkx, Fq(x)=Wqx, Fv(x)=Wvx,
其中, Wk、Wq、Wv分别表示特征空间Fk(x)、Fq(x)、Fv(x)对应的权重矩阵, Wk∈
Bj, i=
与此同时, 特征图Fout1经过特征空间Fv(x)与Bj, i构成的注意力权重矩阵相乘, 得到注意力层的输出:
qi=
其中Fv(x)表示输入信息xi与权重矩阵Wv∈ RC× H× W的乘积.
最后, 将注意力层的输出与比例系数ε 相乘, 并和输入特征图Fout1加权, 得到最终输出:
Fout2=ε qi+Fout1,
其中ε 的初始值为0.随着网络训练的推进, 注意力特征图逐渐为文本区域分配更多的权重.
同样, 文本检测网络也借鉴FPN的思想, 在上采样过程中, 将32× 32、128× 128、512× 512的图像分别送入CAM, 用于增强图像文本特征.再分别计算相应分辨率真值图像和经过CAM输出图像的损失函数.
1.4.1 生成对抗损失
GAN是训练背景修复网络的核心损失, 本文采用SNGAN中谱归一化的合页损失函数(Hinge Loss).Hinge Loss可使GAN训练更稳定, 并且额外的计算成本很少.具体公式如下:
其中, D表示判别器结构, G表示生成器结构, x表示网络输入, y表示网络输出, z表示相对应真值.
1.4.2 自适应纹理损失
为了使生成器可自适应地生成背景纹理, 粗糙背景生成器在128× 128、256× 256、512× 512的图像上应用多尺度L1损失.为了防止监督信息冗余, 精致背景生成器只在512× 512的图像上应用L1损失.自适应纹理总体损失定义为
LG=LRBG+LEBG,
其中, LRBG表示粗糙背景生成器损失, LEBG表示精致背景生成器损失.
τ 1=5, τ 2=6, τ 3=8, κ =0.8, ψ =10, ω =2.
1.4.3 文本检测损失
对于文本检测网络的学习, 由于文本区域经常在整幅图像中只占部分区域, 因此使用Dice损失函数[27], 使网络在训练过程中更侧重于文本区域的挖掘.由于自然场景文本的特殊性, 根据经验在32× 32、128× 128、512× 512的特征上进行多尺度特征损失计算, S为文本检测网络的输出, (h, w)为像素值, 则文本检测损失函数定义为
1.4.4 内容风格损失
正如文献[3]所述, 不同的高级特征监督学习对背景修复和文本检测较有效, 在高级特征中引入内容风格约束, 可强制输出图像和对应的真值匹配.使用在ImageNet[28]上预训练的VGG-16网络提取输出图像和相应真值的特征, VGG-16在特征提取上具有较好的泛化性和扩展性.内容风格损失如下:
其中, Lcontent表示内容损失函数, Lstyle表示风格损失函数, Vi表示预训练的VGG-16的第i个池化层, 设置超参数η =0.05, ξ =120.
综上所述, 本文最终的损失函数为生成对抗损失、自适应纹理损失、文本检测损失和内容风格损失之和, 由于生成对抗网络开始生成的图像质量较差, 导致总的损失函数为负.为了平衡网络的训练, 设置生成对抗损失的权重为0.1, 因此, 最终损失函数定义为
Lfinal=0.1LadvG+LG+LTD+LCS.
本文分别在2个代表性的场景文本擦除数据集SCUT-SYN和SCUT-EnsText上进行网络训练, 分别在它们各自相应的测试集上进行评估.SCUT-SYN数据集的训练集包含8 000幅图像, 测试集包含800幅图像.数据集本身未提供文本区域的定位坐标, 因此本文将训练集上的图像和对应的真值相减, 之后将RGB图像转换成二值图像, 得到文本掩码真值, 根据经验设置像素阈值为25, 大于25定义为文本区域, 小于25定义为非文本区域.SCUT-EnsText数据集的训练集包含2 749幅图像, 测试集包含813幅图像, 本身提供文本区域的定位坐标.这2个数据集的图像尺寸都为512× 512.SCUT-EnsText数据集包含更多现实场景文本可能存在的复杂情况, 如光线微弱、背景复杂、字体多变等, 擦除难度更大.
训练过程中按概率0.3随机将图像最大旋转10° , 进行数据增强.优化器选用Adam(Adaptive Moment Estimation), 生成器网络的学习率设置为0.000 1, 判别器网络的学习率设置为0.000 4, 批尺寸设置为4.在显卡TITAN RTX上单卡训练.
为了全面评估输出图像的质量, 本文采用如下6种评价指标.
1)均方误差(Mean Square Error, MSE), 计算两幅图像的均方误差.图像X∈ (h, w)、Y∈ (h, w)在像素点上的均方误差为:
MSE=
2)峰值信噪比(Peak Signal to Noise Ratio, PSNR).由于场景文本擦除技术在根本上是对比文本区域像素点的差别, 而MSE对像素点细微变化并不敏感, 因此PSNR可细致表达像素点之间的误差, 具体公式如下:
3)平均结构相似性(Mean Structural Similarity, MSSIM).主要从亮度、结构和对比度方面考查图像的相似性, 具体公式如下:
其中, l(X, Y)表示亮度, c(X, Y)表示结构, s(X, Y)表示对比度, uX表示图像X像素点的均值, uY表示图像Y像素点的均值, σ X表示图像X像素点的方差, σ Y表示图像Y像素点的方差, σ XY表示图像X、Y关于像素点的协方差.为了防止分母为0, 设置常数
c1=(0.01× 255)2, c2=(0.03× 255)2.
4)灰度像素平均值(AGE).表示两幅图像经过灰度处理后的平均误差, 具体公式如下:
其中, D(h, w)表示两幅灰度图像之间差值的绝对值, g(· )表示对彩色图像进行灰度处理.
5)灰度像素百分比(pEPs).对比2幅图像经过灰度处理后的错误像素百分比, 当像素点误差在20以内被认为是相同像素, 误差在20以外被认为是不同像素, 具体公式如下:
6)灰度像素聚合百分比(pCEPs).在pEPs基础上进一步优化, 当4个相邻的像素点误差都在20以外, 认定该像素点是不同像素, 否则是相同像素, 具体公式如下:
Ec(x1, x2, x3, x4)=
在各项指标中:PSNR、MSSIM值越高, 擦除性能越优; MSE、AGE、pEPs、pCEPs值越低, 擦除性能越优.
本次实验选用如下对比方法:EraseNet(Erase Network)[3]、pix2pix[9]、STE[18]、EnsNet[20].在场景文本擦除的合成数据集SCUT-SYN和真实数据集SCUT-EnsText上对比各方法的指标值, 结果如表1所示.在表中, EraseNet* 为复现结果, 其余结果直接引自相应文献, 黑体数字表示最优值.
| 表1 各方法在2个数据集上的指标值对比 Table 1 Index value comparison of different methods on 2 datasets |
Isola等[9]提出pix2pix, 使用cGAN作为图像到图像转换问题的通用解决方案, 虽然相比传统方法在修复速度和效率上都有明显提升, 但是由于场景文本的特殊性, 在SCUT-SYN数据集上的修复效果并不好, PSNR仅为26.76, MSSIM仅为 91.08%.Nakamura等[18]提出STE, 将整幅图像裁剪成各小块再输入训练网络中, 使网络可在小尺度上删除文本区域, 缺点是破坏图像的全局上下文信息, 导致擦除不全面.Zhang等[20]改进STE, 提出EnsNet, 首先在整幅图像上进行端到端训练, 然后提出4个损失函数, 确保非文本区域和文本区域的完整性, 缺点是在网络训练时未利用文本的位置信息, 导致网络修复时不能准确定位文本位置.Liu等[3]在EnsNet的基础上进一步优化, 提出EraseNet, 在网络训练时加入文本位置信息, 在生成器中使用两次擦除, 保证文本区域擦除得更干净, 缺点是在加入文本位置信息时, 忽略场景文本的多尺度特性, 在网络训练过程中未意识到文本区域和非文本区域在图像中的纹理关系.本文的MASTR在训练过程中有效结合多尺度特征和注意力机制, 设计TAM和CAM.TAM从原始特征的通道和空间2个维度进行特征提取, 自适应地集成局部特征与全局特征.CAM学习图像中文本区域和非文本区域像素点之间的判别关系.同时, 设计多尺度特征损失函数优化这两个模块, 增强网络的感受野, 提升处理不同尺度文本的能力.
由表1可见, MASTR在2个数据集上都达到最优.结果提升幅度较小的原因是, 评估结果是在整幅图像上, 而文本区域往往在图像中只占很少部分.
为了公平对比方法的推理速度, 在SCUT-Ens-Text测试集上测试擦除速度, 结果如表2所示.由表可见, MASTR仍是轻量级网络, 擦除一幅图像需要47 ms, 网络参数仅占用内存19.74 M.
| 表2 各方法在SCUT-EnsText测试集上的擦除速度对比 Table 2 Removal speed comparison of different methods on SCUT-Enstext test dataset |
为了验证MASTR中TAM、CAM和多尺度特征损失的有效性, 在SCUT-EnsText数据集上进行消融实验, 共进行6组对比实验:1)Baseline[3].2)背景修复网络使用TAM(记为Baseline* +TAM1).3)背景修复网络和文本检测网络都使用TAM(记为Baseline* +TAM2).4)背景修复网络使用TAM, 文本检测网络使用CAM(记为Baseline* +TAM1+CAM1).5)背景修复网络和文本检测网络都使用CAM(记为Baseline* +CAM2).6)MASTR.
各方法消融实验结果如表3所示, 表中黑体数字为最优值, Baseline* 为复现结果.相关可视化结果如图4所示.
| 表3 各方法在SCUT-EnsText数据集上的消融实验结果 Table 3 Results of ablation experiments of different methods on SCUT-EnsText dataset |
 | 图4 消融实验的可视化结果Fig.4 Visualization results of ablation experiments |
对比Baseline和Baseline* +TAM1, 在背景修复网络中使用TAM后, 各指标值均有所提高, 表明TAM可有效学习通道和空间2个维度上的特征, 自适应集成局部特征与全局特征, 有效提升背景修复效果.图4的可视化结果也直接验证TAM的有效性.
对比Baseline* +TAM1和Baseline* +TAM1+CAM1, 可验证CAM的有效性.通过学习图像中文本区域和非文本区域像素点之间的判别关系, 提升检测模型的文本检测效果.图4的可视化结果也表明, 基于CAM的方法对于Baseline中未擦除干净的小区域文本更有效.
对比Baseline* +TAM1+CAM1和MASTR可看出, 使用多尺度特征损失在纹理细节特征表示、多尺度文本擦除方面表现更优, 擦除后的图像更完整, 细节特征更清晰, 提升模型处理不同尺度文本的能力.
为了验证CAM和TAM的独特性, 本文尝试使用CAM替换TAM或使用TAM替换CAM.由表3可看出, 替换后的精度都有所下降, 图4的可视化结果中替换后的擦除效果也较差.当CAM替换TAM后, 由于文本检测网络不能学习像素点之间的特征关系, 检测效果减弱.当TAM替换CAM后, 单方面的加深网络并不能提升擦除效果, 反而破坏图像的空间信息.因此, 通过消融实验可看出MASTR的有效性和独特性.
MASTR在SCUT-EnsText真实数据集上修复文本区域的结果如图5所示, 图中MASTR_text为场景文本检测网络的输出.MASTR更有利于修复文字大小适中、背景和前景颜色容易区分、背景颜色为纯色的图像, 如图5中第1幅~第3幅图像所示.第4幅图像中文本区域周围纹理较复杂, 导致文本检测网络无法准确定位文字轮廓, 并且周围背景过于复杂, 导致背景修复网络无法修复与周围背景区域相似的纹理.在第5幅图像中, MASTR对艺术字体检测不全, 导致文本擦除不全, 主要由于训练模型时, 训练集并未包含与之对应的艺术字体, 导致网络检测失败.在第6幅图像中, MASTR检测到文本区域, 但大尺寸的文字会导致背景修复网络产生很差的修复效果, 主要是因为背景修复网络的感受野不足.
 | 图5 MASTR在SCUT-EnsText数据集上的可视化结果Fig.5 Visualization results of MASTR on SCUT-EnsText dataset |
为了验证MASTR的泛化性, 使用ICDAR-2013测试集[1]测试MASTR的擦除性能.由于此数据集没有擦除后的真值图像, 因此对擦除后的图像使用在SynText、ICDAR-2013、MLT-2017数据集上的预训练模型CRAFT(Character Region Awareness for Text Detection)[29]进行文本检测, 检测的文本框越少, 表明MASTR擦除文本的性能越优.具体泛化结果如表4所示, 表中黑体数字为最优值, Baseline* 为复现结果, 其余结果直接引自原文献, Original images表示文本擦除前ICDAR-2013测试集上的评估结果.由表4可知, MASTR泛化性能最优.
| 表4 各方法在ICDAR-2013数据集上的泛化实验结果 Table 4 Results of generalization experiments of different methods on ICDAR-2013 dataset % |
MASTR在ICDAR-2013测试集上的擦除结果如图6所示, 每组图像左边为原图, 右边为擦除后图像经过CRAFT文本检测网络后的输出, 红色边框表示CRAFT文本检测网络检测的文本框.
 | 图6 MASTR在ICDAR-2103数据集上泛化性能的可视化Fig.6 Visualization of generalization performance of MASTR on ICDAR-2013 dataset |
本文提出基于多尺度注意力机制的场景文本擦除框架(MASTR).在文本检测网络中设计上下文感知模块, 更好地学习图像中文本区域和非文本区域像素点之间的判别特征, 增强网络的文本检测性能.同时在背景修复网络中设计纹理自适应模块, 从原始特征的通道和空间2个维度进行特征提取, 有效修复因重构文本区域而导致的阴影部分.此外, 在文本检测网络和背景修复网络中分别计算多尺度特征损失, 有效增强网络感受野, 加强网络对不同尺度文本的检测和擦除.在SCUT-SYN、SCUT-EnsText数据集上的实验表明, MASTR擦除效果较优.
今后可从两个方向着手进行改进:1)提出更有效、精准的擦除模型, 使网络学习更具体、细致的纹理, 更有效地检测多尺度文本区域并进行擦除.2)提高网络的训练速度, 快速、有效地训练网络, 更好地运用于现实场景.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|