



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
多视野特征表示的灰度图像彩色化方法
[李洪安1  , 郑峭雪
, 郑峭雪1 , 马天1 , 张婧1 , 李占利1 , 康宝生2 ]
, 郑峭雪, 马天, 张婧, 李占利, 康宝生]
|
|



作者简介:
郑峭雪,硕士研究生,主要研究方向为可视媒体计算、人工智能.E-mail:20208088025@stu.xust.edu.cn.

马 天,博士,副教授,主要研究方向为三维仿真、图像处理、数据可视化.E-mail:matian@xust.edu.cn.

张 婧,博士,讲师,主要研究方向为图形图像处理、智能信息处理.E-mail:zhangjing21@xust.edu.cn.

李占利,博士,教授,主要研究方向为智能信息处理、视觉计算与可视化.E-mail:lizl@xust.edu.cn.

康宝生,博士,教授,主要研究方向为计算机图形学、图像处理.E-mail:bskang@nwu.edu.cn.
图像彩色化是指预测灰度图像的颜色信息,虽然使用深度学习方法可自动地对灰度图像彩色化,但对图像中不同尺度目标的彩色化质量不高,尤其是在对复杂物体和小目标物体彩色化时,存在颜色溢出、误着色和图像颜色不一致的问题.针对上述问题,文中提出多视野特征表示的灰度图像彩色化方法.首先,设计多视野特征表示模块(Multi-field Feature Represented Block, MFRB),与改进的U-Net结合得到多视野特征表示U-Net.然后,将灰度图像输入U-Net中,并通过与判别器的对抗训练得到彩色图像.最后,利用VGG-19网络在不同尺度上计算图像的感知损失,提高图像彩色化结果的整体一致性.在不同类别的6个数据集上的实验表明,文中方法能有效提高彩色化图像质量,产生颜色更丰富、色调更一致的彩色图像,并在客观评价指标和主观感受上都较优.
About Author:
ZHENG Qiaoxue, master student. His research interests include visual media computing and artificial intelligence.
MA Tian, Ph.D., associate professor. His research interests include 3D simulation, image processing and data visualization.
ZHANG Jing, Ph.D., lecturer. Her research interests include graphic image processing and intelligent information proce-ssing.
LI Zhanli, Ph.D., professor. His research interests include intelligent information processing, visual computing and visualization.
KANG Baosheng, Ph.D., professor. His research interests include computer graphics and image processing.
Image colorization improves image quality by predicting color information of gray-scale images. Although the grayscale images can be colored automatically by deep learning methods, the colorization quality of targets with different scales in the images is not satifactory. Especially, the existing colorizing methods is confronted with problems of color overflow, mis-coloring and inconsistent image colors, while dealing with complex objects and small target objects. To address these problems, a method for image colorization of multi-field features representation is proposed in the paper. Firstly, the multi-field feature representation block(MFRB) is designed and combined with the upgraded U-Net to acquire multi-field feature representation U-Net. Then, a grayscale image is input into the U-Net and the color image is obtained by adversarial training with PatchGAN. Finally, the VGG-19 network is employed to compute the perceptual loss of pictures at different scales to enhance the general consistency of the image colorization results. Experimental results on six distinct datasets demonstrate that the proposed method successfully enhances the quality of colorized images and creates color images with richer colors and more consistent tones. The results of the proposed method outperform the main colorization algorithms in both quantitative assessment and subjective perception.
本文责任编委 高 隽
Recommended by Associate Editor GAO Jun
图像彩色化是计算机视觉和数字图像处理等领域的一个研究热点.使用相关算法对灰度图像进行彩色化, 可增强图像的视觉表达能力, 提供更多的语义信息.因此, 图像彩色化方法在老旧黑白照片上色、图像视频渲染、医学影像分析等方面具有良好的应用前景[1, 2, 3, 4].
对灰度图像进行着色的本质是预测图像中的每个像素值.然而在没有先验条件的情况下, 一个像素对应的颜色值具有多样性, 对同个像素进行颜色预测的结果具有不确定性[5].根据在相邻邻域内, 具有相同亮度信息的像素应具有相似颜色值的理论[6, 7], 使用人为标记的颜色点或颜色线条对灰度图像进行标记, 通过颜色传递的方法对灰度图像进行上色成为可能.较早的图像着色方法也大多基于这种思想对灰度图像进行着色, 着色效果受颜色标记值的影响较大.
传统着色方法需要提供大量的颜色点对图像中的每个物体进行标记, 因此学者们提出一些改进算法[8, 9].曹丽琴等[10]使用图像滤波对匹配像素点进行颜色迁移, 克服彩色化结果容易产生过度平滑的问题.李洪安等[11]利用图像分块特征建立图像彩色扩散优化模型, 在低采样条件下, 达到保持图像结构和自然渲染图像色彩的效果.Li等[12]将图像彩色化视为优化问题, 把图像转化为图双拉普拉斯矩阵进行线性优化求解, 提高传统图像彩色化方法的速度.这些改进方法减少用户的参与量, 仅需对相似物体进行颜色标记, 即可达到图像彩色化效果.
虽然使用改进的颜色标记算法可提高对图像着色效率, 但对用户的艺术绘画水平具有一定要求, 因此学者们提出基于参考示例和风格迁移的图像着色算法, 使用匹配算法在参考图像和待着色图像中寻找结构相似的像素进行颜色迁移, 使着色后的图像在整体上与参考图像颜色一致.但此算法也存在一些不足, 在进行着色时需要用户提供一幅结构和内容相似的图像, 增加用户选择参考图像的难度和工作量.为了解决这类问题, 学者们提出一些根据目标图像结构信息提供参考颜色和参考图像的优化算法.Zhang等[13]提出颜色分解优化方法, 将原始图像中的颜色分解为线性组合, 再通过颜色板对图像重新上色.Li等[14]从局部匹配尺度和全局优化两方面进行改进, 提出串级纹理匹配的图像彩色化方法.上述方法提高用户的可操作性, 使用自建数据库图像, 可为用户提供较可靠的选择, 克服需要用户自己寻找参考图像的困难.
目前神经网络已应用于目标识别、目标检测、图像分割等方面[15, 16, 17].学者们开始使用人工神经网络的方法对灰度图像进行着色, 利用神经网络强大的学习和拟合能力, 向网络输入灰度图像或草图信息, 经过一定阶段的学习训练, 网络输出一幅着色好的彩色图像或颜色预测值.基于深度学习的图像着色方法普遍使用卷积神经网络(Convolutional Neural Network, CNN)、编码解码器网络和生成对抗网络(Generative Adversarial Networks, GAN)产生彩色图像.Li等[18, 19]提出基于GAN的灰度图像彩色化方法, 利用Gabor滤波和深层次网络结构提取图像的特征信息, 实现全自动的图像彩色化.Sangkloy等[20]提出深度对抗图像合成网络, 同时输入物体轮廓和颜色信息, 生成逼真的彩色图像.Yoo等[21]设计记忆增强着色模型, 在无需类别标签下也可进行无监督训练, 解决图像彩色化受小样本学习限制的问题.Johari等[22]将图像彩色化分为两阶段, 第1阶段根据输入图像的上下文信息分类图像, 第2阶段训练特有的着色网络进行彩色化.上述研究针对图像的局部块信息、一致性结构、上下文信息和可控性等方面进行改进, 提出相关的优化算法和网络框架, 提高使用神经网络进行自动图像着色的质量.
多尺度特征表示方法主要利用卷积操作融合不同深度和宽度的特征, 实现在不同尺度上的视觉任务.特征金字塔网络(Feature Pyramid Networks, FPN)[23]和PSPNet(Pyramid Scene Parsing Network)[24]在不同大小的特征图像上进行卷积, 并在网络末端对所有提取的信息进行融合并输出结果.Chen等[25]针对不同尺度的特征图像, 采用复杂度不同的卷积操作提取特征信息, 并通过特征融合分解的方式实现不同尺度信息之间交换.Meng等[26]设计动态调整策略, 使用决策网络对输入的视频帧的尺度进行自适应改变, 实现在不同尺度上的信息预测.
应用感知特征进行图像处理相关工作可提高模型的感知能力, 利用经过预训练的CNN提取图像的特征信息, 可在高级语义特征层面对图像进行整体感知.图像感知的方法可应用于图像超分辨率重建、图像去噪、图像分割等领域[27, 28, 29, 30].
基于神经网络的灰度图像着色方法需要进行学习训练, 在测试阶段对目标图像进行着色时, 受训练数据集上主要颜色的影响, 图像的彩色化结果单一, 与真实图像的颜色不一致, 着色图像的颜色丰富性较低, 对物体边界容易产生伪影和颜色溢出现象.针对上述问题, 本文设计多视野特征表示的灰度图像彩色化方法(Multi-field Features Representation Based Colorization of Grayscale Images, MFRC), 从多视野特征表示和视觉感知方面改进灰度图像彩色化方法, 本文方法主要包括优化、设计网络结构和目标损失函数.受FPN[23]的启发, 设计灰度图像彩色化框架, 使用多视野特征表示的端到端网络进行彩色化, 模拟人眼对图像的认知过程.从全局到局部、从大尺度物体到小尺寸物体进行渐进式观察, 提高对多种尺度目标物体的彩色化效果.在多个尺度上感知图像, 使用感知损失对比生成彩色图像和真实彩色图像, 提高图像的整体感知效果.在不同类别的6个数据集上的实验表明, 本文方法能有效提升彩色化图像质量, 产生颜色更丰富、色调更一致的彩色图像, 并在客观评价指标和主观感受上都较优.
目前利用深度神经网络对灰度图像进行彩色化, 可产生良好的着色效果, 但对不同尺度大小的目标物体进行着色时仍存在误着色和受训练数据主要类别颜色影响的问题, 造成图像彩色化质量降低和颜色溢出的现象.并且在进行图像着色时, 忽略图像的整体感知信息, 使彩色化图像在整体色调上不一致.GAN具有强大的图像生成能力, 在图像风格转换、超分辨率、图像着色等领域具有广泛的应用前景, 并衍生出一系列的网络模型[31, 32, 33].因此, 本文在U-Net基础上设计多视野特征表示的灰度图像彩色化方法, 利用感知损失对不同尺度特征进行感知, 提高彩色化效果.
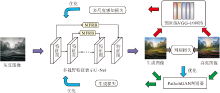
为了提取图像中丰富的特征信息, 本文设计多视野特征表示模块(Multi-field Feature Represented Block, MFRB), 并将其作为U-Net的跳跃连接, 融合不同层次的特征信息.因此, 本文方法由多视野特征表示U-Net和PatchGAN(Patch-Based GAN)[34]组成.U-Net充当彩色图像生成器, PatchGAN充当判别器.此外, 利用特征提取网络得到感知损失, 优化模型, 产生颜色更和谐的彩色图像.本文方法整体结构如图1所示.
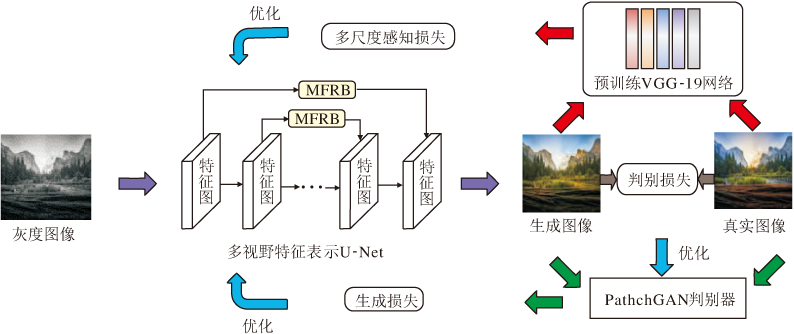 | 图1 本文方法结构图Fig.1 Structure of the proposed method |
输入待着色图像的亮度信息L, 生成器G提取其特征并输出预测色度信息a、b, 融合亮度信息和色度信息, 产生着色后的彩色图像.判别器D对来自真实数据和生成器的生成彩色图像进行判断, 计算生成图像和真实图像之间的概率分布相似性.通过生成器和判别器之间的相互博弈过程, 逐渐提高生成器和判别器的性能, 模型的损失函数定义为
L(G, D)=Ey[ln D(y)]+Ex[ln(1-D(G(x)))],
其中, x表示Lab颜色空间下待着色图像亮度信息, y表示Lab颜色空间下真实彩色图像, E表示期望值.通过最小化生成器损失和最大化判别器损失, 在生成器和判别器相互对抗学习中达到优化整体模型的目的.
灰度图像彩色化也可看作回归预测问题, 即使用优化模型预测每个像素的颜色通道值, 因此如何设计函数优化目标十分重要.在深度机器学习算法中, 通常使用平方差损失函数和绝对值损失函数计算真实数据与生成数据之间的差异值.然而在进行图像着色任务时, 仍会产生颜色溢出和边界模糊等问题.Isola等[34]设计PatchGAN, 在分块区域上判断真实图像和生成图像, 提高判别器网络的在局部分块特征上的感知效果, 达到提高生成图像质量的效果, 但忽略图像的全局特征信息, 导致图像整体彩色化质量不高.本文在此基础上增加感知损失, 从不同尺度特征上判断真实图像和生成图像, 对整个模型的优化目标为
L=arg
其中, G表示生成器网络, D表示判别器网络,
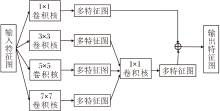
图像多尺度特征表示在计算机视觉任务中较普遍, 常见方式是设计不同的处理分支, 在不同尺度上获取图像特征信息, 然后通过不同的特征融合方式将所有分支提取的信息进行交叉传递.但这些方法的研究重点主要集中在如何设计特征融合方法和减小计算复杂度, 对于多尺度特征的提取, 通常使用下采样的方法获得.此方法会使输入图像分辨率以2的指数级降低, 获得的多尺度图像仅仅是分辨率上的不同, 不能表示多样的特征信息.因此, 本文从特征获取角度出发, 设计MFRB提取图像的特征信息, 并与改进的U-Net结合, 得到多视野特征表示U-Net.MFRB的网络结构如图2所示.
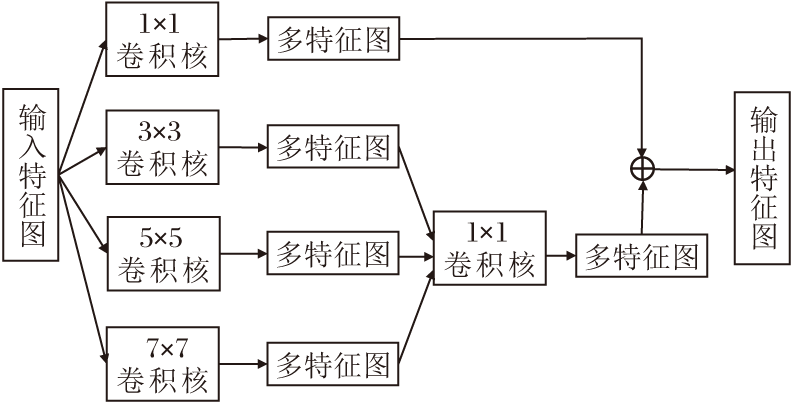 | 图2 MFRB结构图Fig.2 Structure of MFRB |
假设Xi表示输入灰度图像, 通过MFRB后的输出为Xi+1, 此过程可表示为
${{X}_{i+1}}=F\left( \frac{C}{\alpha}\sum\limits_{n=2}^{\alpha }{{{K}_{2n-1}}\left( {{X}_{i}} \right)} \right)$,
其中, C表示输入图像的特征通道数量, α 表示多尺度特征的级别,
在经过多次卷积后, 特征图像的大小逐渐减小, 并且随着卷积核的增大, 参数量呈指数级增长.在不超过特征图大小的情况下, 提取图像中的全局信息和局部信息, 将多视野感受级别设置为4(即α =4).从不同感受野上进行特征提取, 并使用卷积核大小为1的卷积操作融合不同尺度特征.使用一个大小为1的卷积保留原始特征信息, 最后将得到的所有特征进行融合输出.
U-Net在医学图像处理上性能较优, 在医疗图像分割、图像伪影去除等方面具有广泛应用[30, 35], 因此本文使用U-Net作为彩色化网络.传统U-Net直接融合下采样层和上采样层的特征信息, 使网络充分利用图像的浅层特征和深层特征.但是下采样提取的特征图属于低级语义信息, 而上采样层的特征图是由深层卷积得到的高级语义信息, 不能直接融合两者[36].因此, 本文将MFRB作为跳跃连接, 代替传统端到端特征直接相加的方法, 将低级特征通过MFRB后与高级特征结合, 提高多尺度特征提取能力.
Inception模块与MFRB较相似, 但仍存在如下不同: 1)功能不同.Inception是为了在增加网络深度和宽度时减少参数量, 而MFRB主要用于增加图像特征的感受野, 提取不同尺度的特征.2)结构不同.MFRB可自适应不同特征通道数, 对不同大小的尺度特征具有相同比重.整个模块卷积后得到的特征图像在数量上与输入特征数量保持一致.而在Inception模块前后输出特征图数量不同, 并且使用池化操作, 导致在图像彩色化过程中丢失部分特征信息, 不利于生成高质量彩色图像.3)位置不同.MFRB仅用于在对称的U-Net网络层之间, 而Inception作为网络的主体模块, 用于提取特征.
除了上述3点不同之处, 因为MFRB主要是提取图像中的多视野特征, 并且在MFRB输入前后的特征图大小和数量保持不变, 因此它与Inception结构类似, 不仅可作用于U-Net中的跳跃连接, 还可作为主体模块或辅助模块嵌入其它网络结构中.
MFRB使用深度可分离卷积代替传统卷积操作, 在达到提取图像多尺度特征信息的目的下, 减小网络的参数量.利用残差块和MFRB设计的多视野特征表示U-Net结构如图3所示.
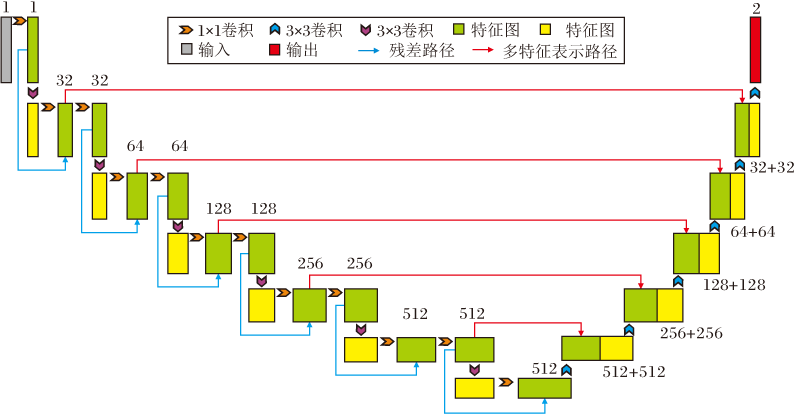 | 图3 多视野特征表示U-Net结构图Fig.3 Structure of multi-filed feature representation U-Net |
在下采样阶段, 为了充分提取灰度图像中的特征信息, 使用6个残差卷积模块进行特征提取.每次卷积后, 特征图像的大小缩至原来的1/2, 特征图像的数量变为原来的两倍.
在上采样阶段, 为了保持与端到端输出的特征图像大小一致, 使用卷积核大小为3、步长为2、填充像素为1的6个反卷积操作逐步重建彩色图像, 直至与输入图像相同大小.在每次反卷积后, 融合MFRB下采样特征与上采样特征并输出.具体网络参数如表1所示.
| 表1 多视野特征表示U-Net参数 Table 1 Parameters of multi-filed feature representation U-Net |
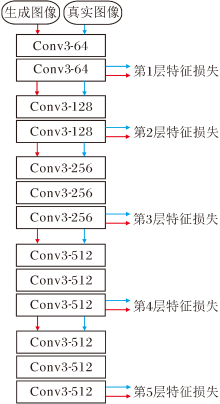
深度学习模型在产生彩色图像的前提下, 更应使生成图像的颜色在整体色调上保持和谐.为了使图像达到更优的着色效果, 使图像的整体色调一致, 本文使用感知损失函数, 在不同尺度上的语义信息上判断彩色化图像.本文的感知损失函数是一个在ImageNet数据集上经过预训练的VGG-19网络, 经过依次的卷积操作后, 得到通道数量为64、128、256、512、512的特征图像, 特征图像大小依次为256、128、64、32、16.向VGG-19网络输入彩色图像, 卷积后得到5个不同尺度的感知特征.多尺度感知网络结构如图4所示, 图中Conv x-y表示卷积核大小为x, 输出特征图数量为y.
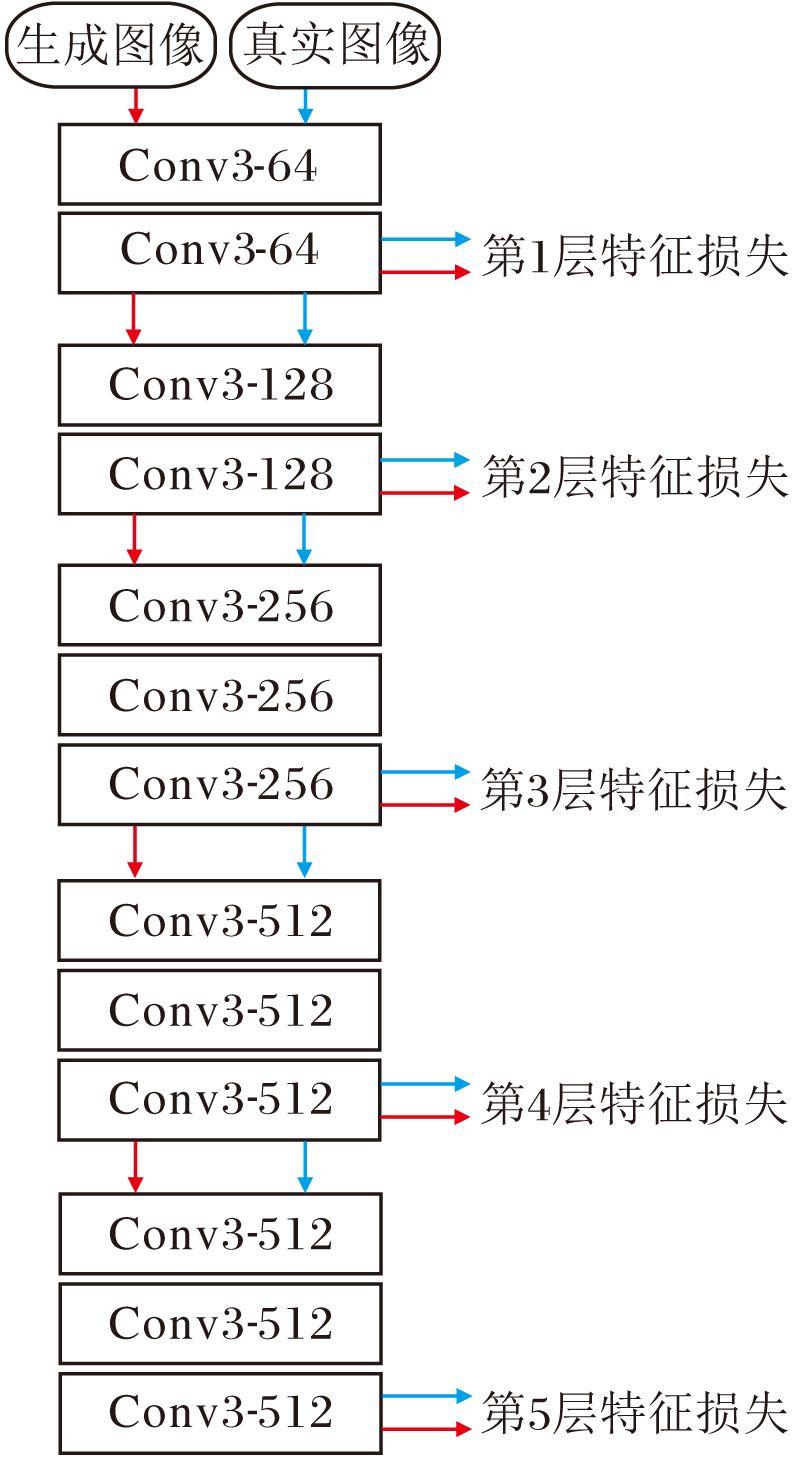 | 图4 多尺度感知网络结构图Fig.4 Structure of multi-scale perceptual network |
根据Gatys等[37, 38]提出的风格重建损失定义, 特征图像的格莱姆矩阵定义为
$G_{j}^{\phi }{{\left( x \right)}_{c, c'}}=\frac{1}{{{C}_{j}}{{H}_{j}}{{W}_{j}}}\sum\limits_{h=1}^{{{H}_{j}}}{\sum\limits_{w=1}^{{{W}_{j}}}{{{\phi }_{j}}{{\left( x \right)}_{h, w, c}}{{\phi }_{j}}{{\left( x \right)}_{h, w, c'}}}}$,
其中, x表示输入图像, C表示图像的通道数, H表示图像高度, W表示图像宽度, ϕ 表示VGG-19网络, ϕ j表示第j层网络.生成图像与真实图像之间的感知损失定义为它们的格拉姆矩阵差异值的Frobenius范数平方, 并且对于不同层次的损失设置权重都为1, 即5种特征损失具有相同的贡献程度.因此, 将5个不同层次的特征损失相加即可得到整体的感知损失:
${L_{p}}=\sum\limits_{j=1}^{5}{\left\| G_{j}^{\phi }\left( {\hat{y}} \right)-G_{j}^{\phi }\left( y \right) \right\|_{F}^{2}}$,
其中,
加入感知损失后, 本文方法得到进一步改进, 因此在下文中将融合感知损失的MRFC称作MFRC+.
为了验证融入MFRB结构的MFRC(即MFRC+)对复杂图像和小目标物体具有良好的彩色化效果, 本文在Natural Color Dataset(NCData)、OxFlower17、 SpongeBob、Monet、Horse、Summer数据集上分别进行实验.
NCData数据集是Anwar等[39]为了解决图像彩色化评价缺乏统一实验数据问题而建立的彩色图像数据集, 包括20个类别的721幅彩色RGB图像.OxFlower17、SpongeBob、SquarePants数据集上包含花卉图像和卡通动漫图像.Monet、Horse、Summer数据集均是从网络和ImageNet中选取的公开数据集, 涵盖动物和风景的自然图像和莫奈艺术图像[28].将所有数据集按照8∶ 2的比例随机划分为训练数据集和测试数据集.
所有实验均在同台计算机上完成, 使用64位Windows 10操作系统, 处理器为Intel(R) Core(TM) i9-10900X CPU @3.70 GHz, 显卡为NVIDIAGeForce RTX 2080 Ti, 科学计算库为PyTorch1.7.0, CUDA10.2, Python3.7.3.
在实验中, 对所有的数据集进行裁剪, 使所有图像的大小均为256× 256.由于所有图像均是在RGB颜色空间下的彩色图像, 而本文方法接收Lab颜色空间下的L亮度通道信息, 输出a、b色度通道信息.因此, 需将所有的图像进行颜色空间转换, 即从RGB颜色空间转换为Lab颜色空间.
实验分为训练和测试两部分, 在训练期间, 将经过预处理的L亮度信息输入生成器网络, 再将生成的a、b色度信息与输入亮度信息L进行融合, 得到彩色化图像.将生成的彩色图像和真实图像输入感知网络和判别器网络, 计算得到两者之间的差异值.实验设置迭代次数为100, 学习率为0.003, λ =100, γ =50.使用批量归一化对数据进行正则化, 经过100次对抗训练后得到最终的彩色化模型.本文采用经典算法和全自动彩色化算法[21, 32, 33]进行对照实验, 经过100次训练后得到最终的模型.
为了客观反映各彩色化模型在不同数据集上的性能, 使用峰值信噪比(Peak Signal to Noise Ratio, PSNR)、结构相似性(Structural Similarity, SSIM)和感知相似度(Learned Perceptual Image Patch Similarity, LPIPS)[40]对彩色化结果进行定量分析.PSNR是常见的评价图像压缩重建质量的测量方法.SSIM可从图像亮度、对比度和结构组成上评价图像质量好坏.LPIPS可从主观感受上评价图像质量, 数值越小, 表示两幅图像越相似.
2.3.1 主观评价分析
为了验证本文方法在不同尺度上都能得到较好的彩色化结果, 在6个数据集上选择不同复杂程度的图像进行实验.
本文选取如下对比方法:文献[19]方法、MemoPainter[21]、DCGAN(Deep Convolutional GAN)[32]、ChromaGAN[33]、pix2pix[34].
各方法在6幅图像上的彩色化结果如图5所示.由图可看出, 当图像复杂度较低时, 各方法都能进行良好的彩色化.但是当图像中的物体增加、颜色种类丰富时, DCGAN显然不再适用, 彩色化结果趋于黑白, 尤其在Summer、Horse数据集上.其它算法的彩色结果与真实图像都存在不同差异, 在前5幅图像上都能得到较好的彩色化结果.值得注意的是, 因为MFRC+可捕捉图像中不同尺度物体的细节信息, 得到的彩色化图像颜色更丰富, 更接近于真实图像.由于加入感知损失, 可从高级语义信息上对图像进行感知, 提高模型彩色化效果的一致性.因此得到的彩色化效果也更真实自然, 整体颜色更和谐, 未出现误着色和颜色溢出的情况.此外, 在第6幅图像上, MFRC+对图中的小人和湖面的彩色化效果更优, 进一步证实MFRC+在复杂图像和小目标物体上的优越性.
 | 图5 各方法的彩色化效果对比Fig.5 Colorization effect comparison of different methods |
2.3.2 定量指标分析
为了更客观公正地对比各方法的彩色化结果, 在6个数据集上进行实验, 并使用多种图像质量评价指标评价各方法生成的彩色化图像.各方法的PSNR值对比如表2所示, 表中黑体数字表示最优值.由表可看出, MFRC+得到的图像质量最优.
| 表2 各方法在6个数据集上的PSNR值对比 Table 2 PSNR value comparison of different methods on 6 datasets |
SSIM指标从图像结构上评价生成彩色图像和真实彩色图像, 各方法在6个数据集上的SSIM值如表3所示, 表中黑体数字表示最优值.由表可看出, MFRC+在各数据集上都取得最优值, 充分说明使用感知损失可提高彩色化模型的整体感知能力, 使生成彩色图像和真实彩色图像在结构上保持一致.
| 表3 各方法在6个数据集上的SSIM值对比 Table 3 SSIM value comparison of different methods on 6 datasets |
各方法在6个数据集上的LPIPS值如表4所示, 表中黑体数字表示最优值.由表可看出, MFRC+在所有数据集上得到最低值.因为LPIPS指标是利用在ImageNet数据集上训练后得到的固定网络对生成彩色图像和真实彩色图像进行相似性判断, 结果表示图像在高级语义信息上的相似度.因为MFRC+可处理不同尺度的图像特征, 产生的彩色化图像颜色种类更丰富、细节更清楚, 因此感知相似度较优.
| 表4 各方法在6个数据集上的LPIPS值对比 Table 4 LPIPS value comparison of different methods on 6 datasets |
2.4.1 多视野特征表示模块的性能
为了验证本文的MFRB模块可在不同视野上提取图像多尺度特征信息, 达到良好的彩色化效果, 在不添加感知损失的情况下进行实验, 各方法的图像彩色化结果如图6所示.
 | 图6 各方法生成的彩色化图像Fig.6 Colored images generated by different methods |
从图6可看出, 各方法对相同的灰度图像均可达到彩色化效果的目的, 但DCGAN对小尺度物体和图像细节进行彩色化时, 存在误着色和边界模糊等问题.(c)是使用pix2pix得到的彩色化结果, 图中花朵的紫色花瓣被正确地彩色化, 但花瓣边界产生颜色边界溢出现象, 将背景部分的绿色着色为蓝色, 与真实图像不一致.(d)为使用MFRC生成的彩色化图像, 由于采用MFRB在不同感受野上提取特征, 使网络可更好地对图像中不同尺度的物体进行彩色化, 对图中的花瓣颜色进行正确预测, 并且在花瓣边界未产生颜色溢出现象, 着色结果与真实图像保持一致, 表明MFRC可解决颜色溢出问题.
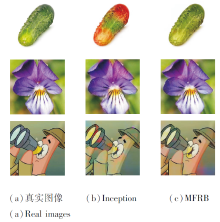
2.4.2 Inception与MFRB性能对比
Inception结构与本文的MFRB较相似, 为了表明MFRB和Inception不同, 将MFRB替换为Incep-tion结构, 在相同的实验条件下进行实验, 得到的彩色化图像如图7所示.由图可看出, 因为MFRB具有多视野特征提取的能力, 得到的彩色化结果明显优于Inception.
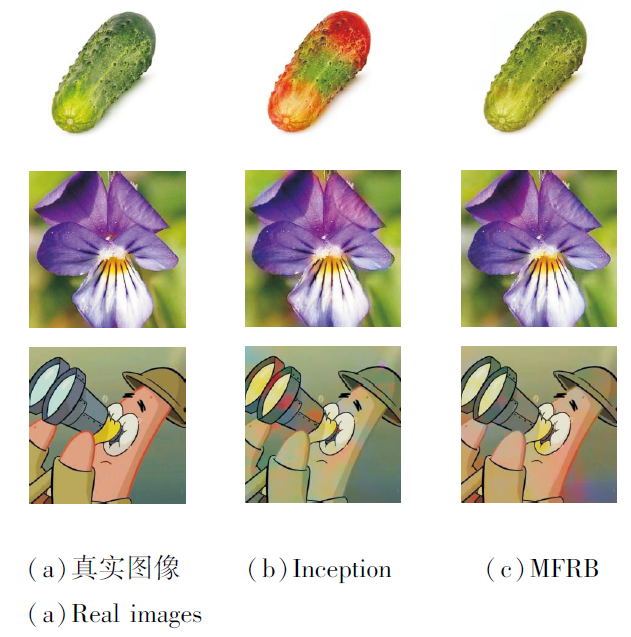 | 图7 Inception与MFRB生成的彩色化图像Fig.7 Colored images generated by Inception and MFRB |
本文还在数值上对比Inception和MFRB, 具体指标值如表5所示, 表中黑体数字表示最优值.由表可看出, MFRB性能更优.
| 表5 Inception与MFRB的指标值对比 Table 5 Index value comparison between Inception and MFRB |
2.4.3 有无感知损失对比
由于本文方法引入感知损失, 为了验证加入感知损失后可提升图像整体彩色化结果, 使用不带感知损失的MFRC和加入感知损失的MFRC+进行对比, 结果如图8所示.由图可看出, 虽然不加入感知损失时也能对灰度图像进行彩色化, 但是彩色化结果与真实图像存在一定差异.使用感知损失后, 彩色化图像的颜色鲜艳程度更高, 在图像整体上呈现一致性.例如, 图8中对绿色的西兰花进行着色时, 未添加感知损失时将第1个物体彩色化为黄色, 不符合图像的整体一致性.加入感知损失后, 所有的物体都被正确彩色化为绿色.因此, 使用感知损失可提高图像色彩一致性, 使得到的彩色化图像质量更高, 与真实图像更接近.
 | 图8 有无感知损失生成的彩色化图像对比Fig.8 Comparison of colored images with and without perceptual loss |
2.4.4 感知特征可视化
本文使用VGG-19网络作为感知网络, 并将其划分为5个尺度的感知层级, 对图像进行特征提取.将真实图像输入感知网络中, 并将其输出的5个层级特征图像进行可视化.因为每次特征提取都将特征图尺寸缩小为原来的1/2, 所以对小于图像原始尺寸的特征图使用双线性插值的方法进行上采样, 恢复其图像分辨率, 部分实验结果如图9所示.由图可看出, 随着感知深度增加, 提取的图像特征信息也更抽象.
 | 图9 感知特征的可视化结果Fig.9 Visualization results of perceptual features |
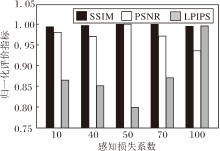
为了确定网络感知损失的系数, 对不同系数下网络模型的图像彩色化质量进行对比, 结果如图10所示.由图可看出, 使用不同感知损失系数对网络彩色化能力具有不同的影响.当感知损失系数为50时, 在3种指标上均达到最优值.这也说明加入感知损失可提高图像彩色化效果和图像整体一致性的有效性.
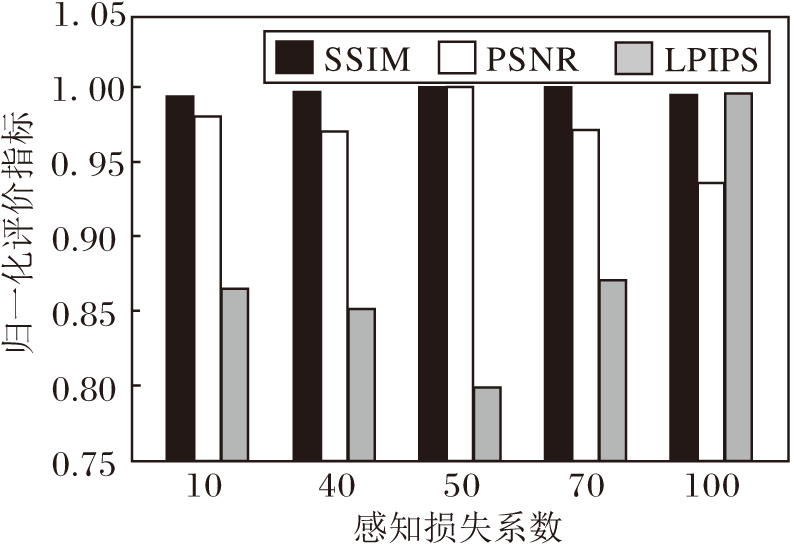 | 图10 感知损失系数对方法性能的影响Fig.10 Effect of different perceived loss coefficients on method performance |
本文从多视野特征表示和图像感知两方面分析图像彩色化问题, 提出多视野特征表示的灰度图像彩色化方法.使用多视野特征表示块(MFRB)的U-Net网络, 提取图像不同感受野下的特征信息, 提高方法对不同尺度目标的着色效果.使用感知网络在图像的高级语义信息上对彩色化图像进行相似度判断, 提高彩色化模型的感知能力, 使彩色化后的图像颜色在整体上保持一致.实验表明, 本文方法在自然图像和卡通动漫图像上具有良好的适应性.今后可考虑加强图像彩色化质量, 增强模型的迁移能力, 提高在更广泛生活应用场景中的实用性和可控制性.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [36] |
|
| [37] |
|
| [38] |
|
| [39] |
|
| [40] |
|