


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
融合全局推理和MLP架构的甲状腺结节分割模型
[李彬榕1  , 谢珺
, 谢珺1 , 李钢2 , 续欣莹3 , 蓝子俊1 ]
, 谢珺, 李钢, 续欣莹, 蓝子俊]
|
|



作者简介:

李彬榕,硕士研究生,主要研究方向为计算机视觉、医学图像处理.E-mail:libinrong0384@link.tyut.edu.cn.

李 钢,博士,副教授,主要研究方向为人工智能、视觉信息处理.E-mail:ligang@tyut.edu.cn.

续欣莹,博士,教授,主要研究方向为计算机视觉、智能控制.E-mail:xuxinying@tyut.edu.cn.

蓝子俊,硕士研究生,主要研究方向为深度学习、医学图像处理.E-mail:1150435643@qq.com.
针对甲状腺结节分割中存在的超声图像噪声干扰较大、结节尺寸多变和现有模型计算复杂度较高的问题,文中构建融合全局推理和多层感知机(Multi-layer Perception, MLP)架构的甲状腺结节分割模型.模型以轴向移位MLP模块为基础架构,以更小的计算复杂度实现不同空间位置特征之间的交互.在编码部分,融合端到端的全局推理单元,基于图卷积对图像全局信息进行交互,缓解图像噪声干扰较大的影响.在解码部分,引入金字塔特征层,完成多尺度特征交互,应对结节尺寸多变的问题.在DDIT数据集上的实验表明,文中模型性能较优,此外,文中模型还适用于乳腺结节分割、视网膜血管分割等其它医学图像分割任务.
About Author:
LI Binrong, master student. Her research interests include computer vision and medical image processing.
LI Gang, Ph.D., associate professor. His research interests include artificial intelligence and visual information processing.
XU Xinying, Ph.D., professor. His research interests include computer vision and intelligent control.
LAN Zijun, master student. His research interests include deep learning and medical image processing.
To address the problems of large noise interference in ultrasound images and variable nodule size and high computational complexity of the existing thyroid nodule segmentation methods, a segmentation model combining global reasoning and multi-layer perception(MLP) architecture is proposed. The model is based on the axial shift MLP module, and hence the interaction between different spatial location features is realized with less computational complexity. The end-to-end global reasoning unit is integrated into the encoder and the global information interaction is conducted based on graph convolutional networks to alleviate the interference of image noise. The pyramid feature layer is introduced into the decoder and multi-scale feature interaction is performed to deal with the problem of variable nodule size. Experimental results on DDIT datasets show that the proposed model yields better performance, and it can be applied to other medical image segmentation task, such as breast nodule segmentation and retinal vessel segmentation.
本文责任编委 高 隽
Recommended by Associate Editor GAO Jun
甲状腺是一个蝴蝶形的内分泌腺, 位于颈部的前下方, 会分泌人体所需激素.甲状腺结节是指甲状腺细胞异常生长形成的肿块, 甲状腺结节的大小、形状、轮廓等特征是临床上甲状腺结节良/恶性诊断的重要依据.超声影像技术已成为临床上首选的甲状腺结节检测手段, 然而, 超声图像具有分辨率和对比度较低、固有斑点噪声较大、伪影较多等特性, 且甲状腺结节尺寸形态各异, 边缘轮廓粗糙, 导致临床检查时甲状腺结节区域不易精确判别[1].目前, 常使用卷积神经网络(Convolutional Neural Networks, CNN)实现对甲状腺结节的自动快速分割, 辅助临床检查, 如PSPNet(Pyramid Scene Parsing Net-work)[2]、DeepLabv3+[3]、U-Net类深度神经网络[4]等.
近期, 研究人员提出质疑:卷积层的存在是否必要, 不使用卷积层能否更好地实现机器视觉任务.因此, 能通过简单的线性操作实现参数学习的多层感知机(Multi-layer Perceptron, MLP)再次受到研究者的关注, 很多基于深度MLP的网络架构被提出.Tolstikhin等[5]提出MLP-Mixer, 未使用任何卷积层, 仅利用矩阵转置和MLP层实现空间特征信息的传输, 并在图像分类任务中取得较优结果.MLP-Mixer只能用于固定大小的输入图像, Chen等[6]提出CycleMLP, 可应对不同尺寸的输入图像.Cycle-MLP使用循环采样的空间连接方法, 在不增加计算复杂度的基础上扩大感受野范围, 在图像分类、目标检测、语义分割任务中都取得与CNN媲美的性能.
然而, MLP架构与CNN都只能捕获图像局部区域关系, 无法捕获任意形状的不相交区域和远距离区域关系[7].对于医学图像处理任务, 局部推理无法有效应对图像中斑点噪声较大和伪影较多的问题.全局推理模块致力于捕获图像全局依赖关系, 缓解噪声干扰.Wang等[8]提出Non-local块, 引入图像全局关系推理中, 计算图像中任何像素对当前像素的关系权值, 捕获图像远程像素点之间的依赖关系.Fu等[9]提出DANet(Dual Attention Network), 把Non-local操作视为空间维度的注意力机制, 并在此基础上引入通道注意力机制, 构建双注意力机制, 获取图像上下文依赖关系.
此外, 研究人员致力于探索效率和灵活性更高、性能提升更明显的全局推理方案, 如多头自注意力[10]、使用全连接图神经网络(Graph Neural Net-works, GNN)对上下文信息进行交互[11]、基于图卷积(Graph Convolutional Networks, GCN)[12]的全局推理、知识引导图推理[13]等方法.研究表明, 全局推理模块具有轻量化的优点, 能轻松插入模型中, 提升模型性能.
为了完成精确、高效的甲状腺结节分割, 本文提出融合全局推理和MLP架构的甲状腺结节分割模型, 融合基于图卷积的全局推理模块和金字塔特征层.模型以轴向移位MLP模块为基础架构, 以更小的计算复杂度实现不同空间位置特征之间的交互.在编码部分, 融合端到端的全局推理单元, 基于图卷积完成远距离像素依赖关系建模, 缓解图像噪声干扰较大的影响.在解码部分, 引入金字塔特征层, 完成多尺度特征交互, 应对结节尺寸多变的问题.在DDIT数据集上的实验表明, 本文模型性能较优, 此外, 本文模型还适用于乳腺结节分割、视网膜血管分割等其它医学图像分割任务.
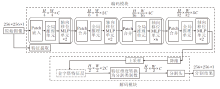
为了有效应对甲状腺结节分割中的难点, 本文提出融合全局推理和MLP架构的甲状腺结节分割模型, 结构如图1所示.模型采用编码-解码策略构建.编码模块由轴向移位MLP单元、全局推理单元和Patch操作组成.解码模块由主干网络进行上采样生成的金字塔特征层和分割头组成.首先对超声图像进行预处理, 统一为256× 256, 然后在输入网络中执行Patch嵌入操作, 将图像拆分成多个Patch Token, 这里将拆分尺寸设置为4, 即处理后的Patch Token大小为
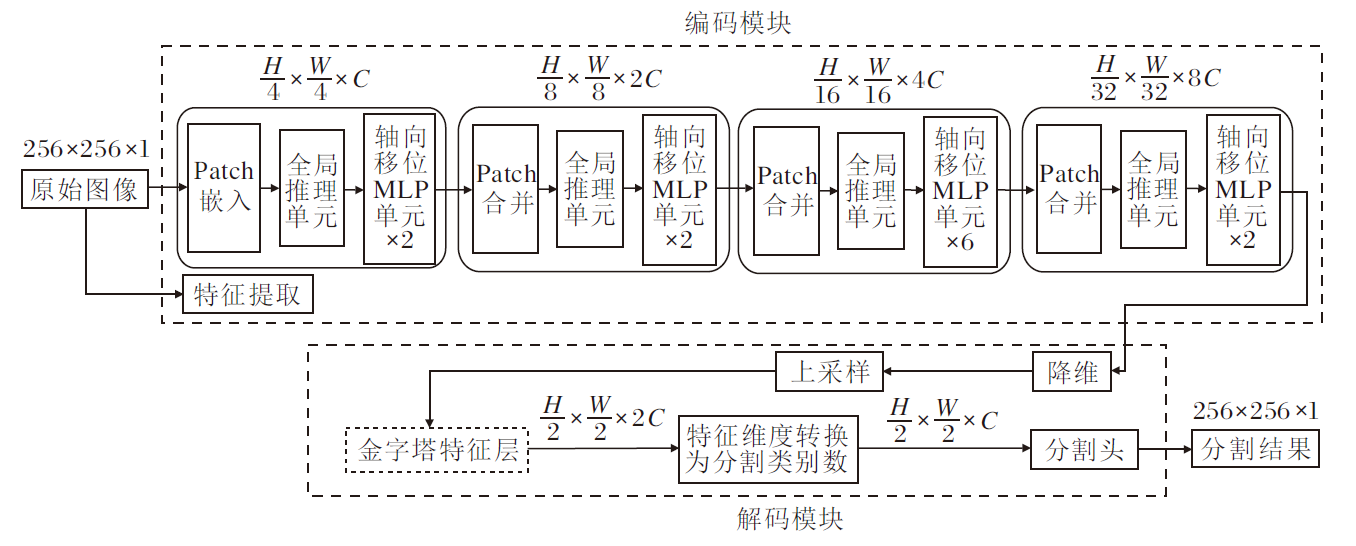 | 图1 本文模型结构图Fig.1 Structure of the proposed network |
为了完成甲状腺结节的精确分割, 需要对输入的图像特征进行充分的感知交互.为了以更小的计算复杂度实现不同空间位置特征之间的交互, 本文以轴向移位MLP单元[14]组成的模块为基础架构, 搭建甲状腺结节分割模型.
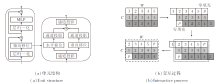
轴向移位MLP单元结构如图2(a)所示, 由层归一化(Layer Normalization, LN)操作、轴向移位操作、MLP和残差连接组成.轴向移位环节通过执行通道投影、水平移位和垂直移位以提取特征, 水平移位和垂直移位负责特征沿空间维度的运算, 通道投影将沿不同方向移位运算后的特征映射到一个线性层.
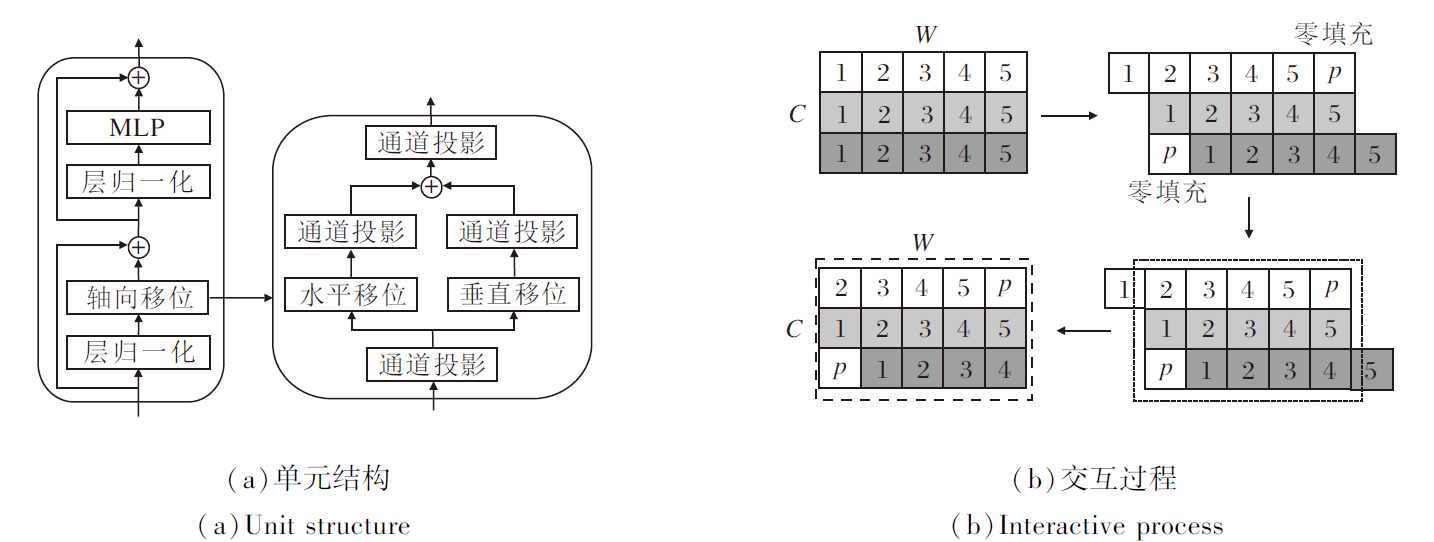 | 图2 轴向移位MLP单元Fig.2 Axial shift MLP unit |
图2(b)以水平移位为例展示轴向移位操作的交互过程.当输入特征尺寸为H× W× C时, H、W为特征张量的高、宽, C为特征张量维度, 假设W=5, C=3, 省略H, 当移位大小设置为3时, 输入特征会分成3部分, 每部分沿水平方向分别移位[-1, 0, 1]个单位并进行零填充((b)中白色块), 也可使用其它填充方法[15].提取(b)中虚线框中的特征作为新特征, 完成水平移位操作.垂直移位沿垂直方向执行同样的操作.
假设输入特征为X, 移位大小设置为s, 在轴向移位MLP单元输入特征沿水平方向和垂直方向都会划分成s个部分, 分别表示为Concat(X
YMLP=XhW
其中:W
Xh=Concat(
Xv=Concat(
分别表示特征的水平移位运算和垂直移位运算.由于特征在水平方向和垂直方向执行移位操作, 再将特征进行重新组合, 可组合来自不同空间位置的信息, 这样特征就可进行充分的感知和交互.
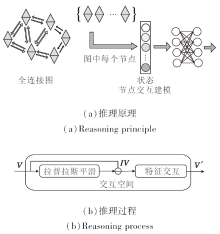
为了获取更全面的语义上下文信息, 同时更好地解决甲状腺超声图像噪声干扰较大的问题, 在MLP架构的基础上融合全局推理单元[16], 对图像特征的全局信息进行交互推理.全局推理单元的推理策略可分为3步:1)将特征投影到可有效计算推理关系的交互空间; 2)在交互空间应用图卷积进行推理操作; 3)将关系感知特征导回原始坐标空间.
全局推理单元结构如图3所示.输入特征X∈ RH× W× C, 其中H、W分别表示输入特征张量的高、宽, C表示输入特征张量的维度.通过学习投影函数f(· ), 将特征投影到交互空间, 即交互空间的输入特征V=f(X)∈ RN× C', N为交互空间中特征节点的个数, C'为特征节点维度.这里将投影函数表示为f(ϕ (X; Wϕ )), 投影函数的权重矩阵表示为B=θ (X; Wθ ), 其中ϕ (· )和θ (· )如图3所示, 由2个1× 1卷积层生成.
 | 图3 全局推理单元结构图Fig.3 Structure of global reasoning unit |
在交互空间中, 把捕获输入特征区域之间的关系简化为捕获相应节点之间的交互, 即构建一个全连接图, 如图4(a)所示, 图中每个节点将对应的特征存储为其状态, 这样关系推理简化为在较小的图上对节点之间的交互进行建模.
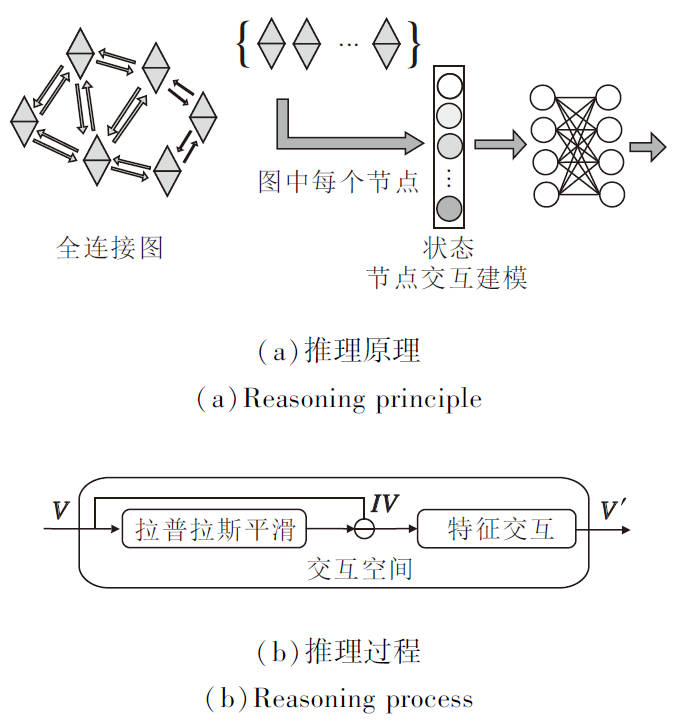 | 图4 交互空间推理过程Fig.4 Interactive space reasoning process |
本文应用图卷积建模和推理节点之间的上下文关系, 将全连接图表示为邻接矩阵Ag的形式.图卷积推理计算过程可分为2步, 如图4(b)所示.1)执行拉普拉斯平滑, 将全连接图中节点的新特征计算为该节点和其邻居节点的加权平均值, 从而使同个簇中的节点特征相似, 消除图像噪声干扰问题.2)在模型训练期间, 学习节点底层特征之间关系的权重矩阵Wg, 并进行特征交互, 学习特征之间的强联系, 为图像像素点的分类提供依据, 提升分割精度.
整个交互空间的输出特征为:
V'=((I-Ag)V)Wg,
其中, 邻接矩阵Ag和权重矩阵Wg都随机初始化并在模型训练期间通过梯度下降法迭代学习, I为单位矩阵, 用于加速算法优化.
再将关系推理后的输出特征反向投影回原始坐标空间, 以便整个单元的输出可被后面单元利用, 做出更好决策.通过学习投影函数g(· ), 将交互空间的输出特征V'∈ RN× C'反向投影, 得到
Y=g(V')∈ RH× W× C',
这里投影函数的权重矩阵D=BT, 使用权重矩阵B可减少计算成本.投影回原始坐标空间后, 再经过一个1× 1卷积层, 将维度扩展为输入维度, 并进行残差连接, 得到整个单元的输出Z∈ RH× W× C.
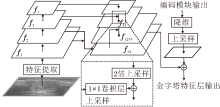
为了应对甲状腺结节尺寸多变的特点, 改善模型对甲状腺结节轮廓线细节的分割能力, 在解码模块使用金字塔特征层, 完成多尺度特征交互[17], 结构如图5所示.首先输入图像经过主干网络进行特征提取, 获取具有丰富语义的特征图.假设输入图像X0∈
Hi=
利用提取到的多尺度特征构建金字塔特征层, 构建方法是先对f4进行上采样, 得到特征图:
f34=upsample× 2(f4)+conv34(f3).
其中:conv34(· )表示1× 1卷积层, 实现f3到f4特征维度的补齐; upsample× 2(· )表示对特征图进行两倍的上采样, 这里使用双线性插值法, 也可使用其它上采样方法[18].得到的特征图f34为原始图像尺寸的1/8.再继续对特征图进行上采样:
f12=upsample× 2(f2)+conv12(f1),
f1234=upsample× 4(f34)+conv24(f12).
其中:conv12(· )、conv24(· )分别实现f1到f2和f2到f4特征维度的补齐; upsample× 4(· )表示对特征图进行四倍的上采样, 得到原始图像尺寸1/2的特征图f1234.然后, 将f1234与经过降维和上采样的特征进行合并, 得到金字塔特征层的输出.
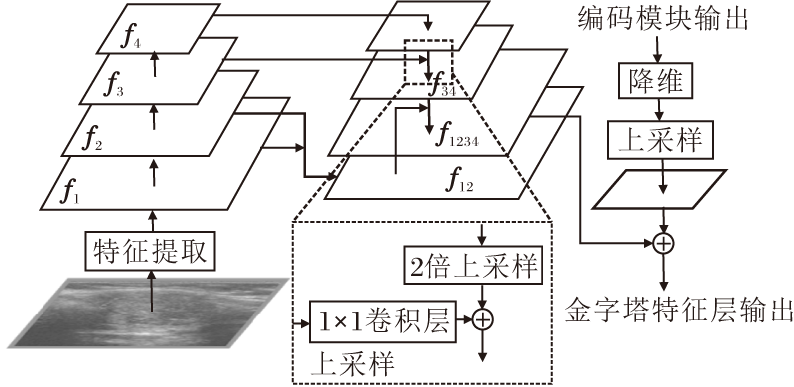 | 图5 金字塔特征层结构图Fig.5 Structure of pyramid feature layer |
研究表明, 这种自下而上提取多尺度特征的金字塔结构比原始自顶向下的特征金字塔表现更优[19], 可更好地保留顶层丰富的语义信息.如图1所示, 金字塔特征层的输出特征首先经过卷积层, 将特征维度转换为分割类别数, 再经过一个分割头, 得到最终的分割结果.而分割头是一个1× 1卷积层, 输出标签图中每个类别的置信度分数, 根据置信度分数确定最终的分割结果.
首先分析基于轴向移位MLP的模型相比CNN和Transformer架构的计算复杂度.卷积操作的计算复杂度与输出特征图的尺寸及卷积核的尺寸相关, 即单个卷积层的时间复杂度为O(M2K2CinCout), 其中, M表示卷积核输出特征图的尺寸, K表示卷积核的尺寸, Cin表示卷积层输入通道数, Cout表示卷积层输出通道数.而CNN的计算复杂度还要随卷积层的堆叠而不断累加, 导致CNN计算复杂度常出现冗余现象.基于Transformer的架构通常采用多头自注意力操作计算输入特征的注意力关系, 给定一个输入尺寸为H× W× C的特征图, 多头自注意力操作会经过4次全连接运算和2次矩阵乘法运算, 计算复杂度为
Ω (多头自注意力)=4HWC2+2(HW)2C.
轴向移位MLP单元只对输入特征进行移位操作, 不需要任何加法运算和乘法运算, 时间成本较低, 几乎与移位大小没有关系.对于H× W× C的输入特征图, 轴向移位操作实际上只有4个通道投影操作, 计算复杂度
Ω (轴向移位)=4HWC2,
其中, 卷积操作的计算复杂度为O(M2K2CinCout), 自注意力操作的计算复杂度为O(4HWC2+2(HW)2C), 轴向移位操作的计算复杂度为O(4HWC2).因此, 基于轴向移位MLP模型的计算复杂度要远低于CNN和Transformer架构的计算复杂度.
全局推理单元由3个1× 1卷积层和图卷积推理操作构成.1× 1卷积层的计算复杂度只与输入特征和输出特征的尺寸、维度有关, 图卷积推理中的拉普拉斯平滑和特征交互操作都只进行一次矩阵乘法.图3中全局推理单元的计算复杂度可计为O(3HWNCC'+N2C'+NC'2), 其中降维后的特征维度C'往往很小.因此, 相比其它复杂的推理方法(如多头自注意力方法), 本文使用的全局推理单元具有计算复杂度较小、灵活性较高的特点.由图1本文模型整体结构图可知, 模型由12个轴向移位MLP单元和4个全局推理单元堆叠而成, 因此模型整体计算复杂度约为
Ω (48HWC2+12HWNCC'+4N2C'+4NC'2).
实验选用DDIT(Digital Database Thyroid Image)小型开源数据集[20], 包含来自不同年龄、性别的637位患者病例的甲状腺超声图像, 部分图像中会有不相关区域.首先使用阈值法去除图像的不相关区域, 即对原始图像的像素值沿x轴和y轴求平均, 去除均值小于阈值的行和列, 经过实验确定阈值为5.将处理后的图像调整为256× 256, 作为网络输入.
本文使用交叉验证的方法评估模型性能, 在保证训练集和测试集中结节大小和类别分布相似的基础上执行五折交叉验证.输入图像为256× 256, 将结节规模按照结节所占像素数分为3个等级:1)小于1 722像素、2)小于5 666像素, 大于1 722像素、3)大于5 666像素.每个尺寸等级的图像都分成5部分, 如图6所示.将5部分依次作为测试集进行交叉验证.通过卡方独立性检验, 这个结节等级划分与甲状腺结节良/恶性分类有统计学意义.因此, 将数据集的637幅超声图像中的509幅图像作为训练集, 128幅图像作为测试集.
 | 图6 五折交叉验证Fig.6 Five-fold cross-validation |
实验使用Adam(Adaptive Moment Estimation)优化器训练网络, 优化器平滑参数β 1=0.7, β 2=0.999, 批尺寸设置为3.采用Warmup预热学习率策略和余弦退火衰减策略进行学习率调整, 初始学习率为1e-4, 学习率衰减率为0.011, 开始衰减的迭代次数为20, 每隔30次衰减一次.预热阶段的学习率为1e-12, 预热迭代次数为5.使用的损失函数为Soft Dice损失.
实验在具有NIVIDIA GeForce GTX-1080 Ti的单个GPU机器上进行, GPU专用内存为11 GB, 所有模型都使用Pytorch 1.5.0和Python 3.7完成实验.
使用Dice系数和交并比(Intersection over Union, IoU)值作为分割结果的评估指标.Dice系数主要用于评估两个不同样本间的相似程度, 即判断两个样本中重合部分占总元素的比例, 所占比例越高, 模型精度越高.IoU计算两个样本的交集和并集之比, 评估两个样本的相关性, 比值越高, 相关度越高, 模型性能越优.具体计算公式如下:
Dice=
IoU=
对于甲状腺结节分割任务, 上式中的X表示分割金标准图中的甲状腺结节区域, Y表示预测结果中的甲状腺结节区域, 真正例数(True Positive, TP)表示正确分割甲状腺结节的部分, 假正例数(False Positive, FP)表示将黑色背景预测为甲状腺结节的部分, 假反例数(False Negative, FN)表示将甲状腺结节预测为黑色背景的部分, 真反例数(True Nega-tive, TN)表示正确预测黑色背景的部分.
实验首先通过训练得到模型参数, 进而预测得到分割图, 最后使用预测分割图和分割金标准图计算Dice系数和IoU值.Dice系数和IoU值越接近1, 表明甲状腺结节分割效果越优.
使用准确性(Accuracy, AC), 敏感性(Sensibi-lity, SE), 特异性(Specificity, SP), 精准率(Preci-sion, PC)和ROC(Receiver Operating Characte-ristic)曲线下面积AUC(Area Under Curve)值评价分割结果.ROC曲线的横轴是假正例率(False Posi-tive Rate, FPR), 纵轴是真正例率(True Positive Rate, TPR), TPR越高, FPR越低, ROC曲线越陡, AUC值越大, 模型的性能越优.具体计算公式如下:
AC=
SP=
FPR=
为了探索模型中各组成模块的性能, 将MLP中的轴向移位操作、卷积操作、自注意力操作进行对比.实际上, 轴向移位可看作卷积操作的一个变体, 类似于空洞卷积[21], 可通过改变移位大小产生不同范围的感受野.此外, 轴向移位MLP还解决空洞卷积对小目标分割性能较差的问题.单个卷积核的参数量为O(K2CinCout), 其中, K表示卷积核的尺寸, Cin表示卷积层输入通道数, Cout表示卷积层输出通道数.自注意力操作需要沿着通道维度进行映射, 计算每个Patch块的查询向量、索引向量、内容向量, 因此参数量为O(3C2).轴向移位操作的参数量仅与特征维度有关, 可计为O(C2), 随着特征维度的增加, 本文模型将具有相当大的参数量, 使模型拥有更小的Patch Size和更多的特征维度数, 获得更精细和更多的特征信息.
为了探索MLP架构和全局推理单元的性能优势, 本文组合目前较通用的主流框架, 搭建不同模型, 进行消融实验, 结果如表1所示.在表中, 全局推理+多头自注意力的组合使用单阶段的编码方式, 其余全部为四阶段编码, 不同阶段特征维度不同.表1中的前4行对比ResNet、EfficientNet、多头自注意力和轴向移位MLP的性能差异, 从结果可看出, 使用轴向移位MLP使模型具有更快的训练时间和测试时间, 也使模型具有很大的参数量, 取得最优的分割结果.表1中第4行和第5行对比全局推理和多头自注意力的性能差别, 从结果可看出, 两者都会使模型产生很大的参数量, 但在效率和分割结果上, 使用全局推理的模型性能明显优于使用多头自注意力的模型.
| 表1 不同组合方式下模型性能对比 Table 1 Performance comparison of models with different combination |
为了进一步探索全局推理单元对模型整体分割性能的影响, 在模型编码部分的4个阶段分别使用或不使用全局推理, 消融实验结果如表2所示.由表可见, 在编码模块引入全局推理单元, 有助于提升模型性能, 添加的全局推理单元越多, 模型所需的训练时间越长、参数量越大、分割效果越优.在4个阶段全部使用全局推理单元, 取得最佳的分割结果.
| 表2 是否使用全局推理对模型性能的影响 Table 2 Model performance with and without global reasoning |
下面定量分析是否在解码部分加入金字塔特征层, 消融实验结果如表3所示.由表可看出, 使用金字塔特征层后, 虽然模型训练时间较多、参数量较大, 但分割结果值显著提升, 可见使用金字塔特征层能有效提升分割精度.
| 表3 是否加入金字塔特征层对模型性能的影响 Table 3 Model performance with and without pyramid feature layer |
由于实验测试集数量较少, 为了防止模型训练中过拟合现象的发生, 以及提高分割模型的泛化能力, 在模型训练阶段均使用测试时数据增强策略(Test-Time Augmentation, TTA)[22].给测试集上的每幅图像创建多个增强副本, 在包含增强副本的测试集上完成预测, 得到更可靠的评估结果, 并反馈到模型训练中.
下面使用本文模型进行消融实验, 定量分析TTA策略的好处, 实验结果如表4所示.由表可见, 使用TTA策略可取得更高值, 分割效果更优.
| 表4 是否使用TTA策略对模型性能的影响 Table 4 Model performance with and without TTA |
为了验证本文模型的性能, 实验选择医学图像分割经典模型进行量化对比.实验使用的经典模型全部来自基于Pytorch的图像分割神经网络库, 它们的特征提取网络均使用EfficientNet-D6.对比模型如下:PSPNet[2]、DeepLabv3+[3]、LinkNet[23]、PAN(Py-ramid Attention Network)[24]、U-Net[25]、UNet++[26].所有模型在同台机器的单个GPU上进行实验, 输入图像裁剪尺寸均采用256× 256, 总迭代次数均设置为184, 批尺寸设置为3, 学习率等其它超参数都保持一致, 所有模型均使用TTA策略完成训练.
各模型性能对比如表5所示.由表可看出, 本文模型单次迭代训练时间和测试时间都相对较少, 说明本文模型的计算复杂度较低, 能更快速地完成训练和预测.计算复杂度的降低并不意味着本文模型具有更少的参数量, 相反, 本文模型保留较高的参数量, 占用更多的存储空间, 这允许本文模型能以更小的计算复杂度获得通道维度更大、更精细、更多的特征信息.
| 表5 各模型的性能对比 Table 5 Performance comparison of different models |
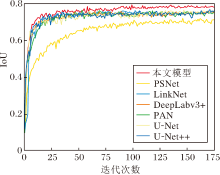
各模型训练过程中IoU值曲线变化情况如图7所示.由图可见, 本文模型的IoU值曲线提升更明显.
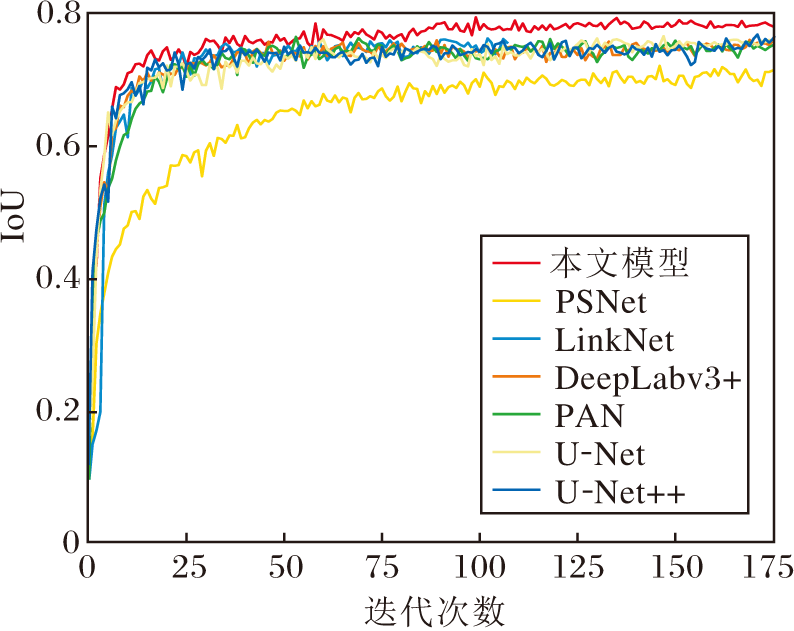 | 图7 各模型分割结果的IoU曲线Fig.7 IoU curve of segmentation results of different models |
各模型分割结果的指标值对比如表6所示, 表中黑体数字表示最优值.由表可看出, 本文模型分割结果最优, 取得更高的AC值、PC值、Dice系数和IoU值, 说明本文模型对甲状腺结节区域的判别精度更高, 即分割结果更准确.而本文模型的SE值和SP值不如U-Net和PAN, 这是因为U-Net在分割结果上出现较多的过分割现象, 即分割结果的面积总是较大一些, 而PAN在分割结果上出现较多的欠分割现象, 即分割结果的面积总是较小.
| 表6 各模型分割结果的指标值对比 Table 6 Comparison of evaluation values of segmentation results among different models |
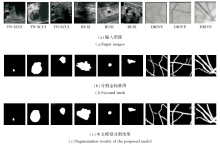
各模型的实际分割结果示例如图8所示, 其中, (a)为预处理之后的输入图像, (b)为专家标注的分割金标准图.由(c)、(d)可看出, PSPNet和LinkNet对大型结节和边缘轮廓线的分割结果粗糙.由(e)~(h)可看出, 多数模型对大型结节的分割效果较优, 而对小型结节和边缘不规则的结节会出现欠分割或过分割现象.由(i)可看出, 本文模型分割结果的边缘轮廓保持在专家标注图轮廓的附近, 除不规则结节以外, 其它结节分割结果纵横比和形状都未出现较大误差, 而这两种特征也是后续医疗诊断工作中至关重要的特征, 因此, 本文模型具有更好的分割效果.
 | 图8 各模型的分割结果对比Fig.8 Comparison of segmentation results of different models |
为了进一步验证本文模型在DDIT甲状腺结节分割数据集上的良好性能, 使用五折交叉验证方法对7个模型进行性能对比, 结果如表7所示.由表可见, 本文模型在每折上的IoU值都最高, 具有最好的分割性能.
| 表7 各模型的五折交叉验证IoU值对比 Table 7 IoU comparison of five-fold cross-validation of different models |
为了验证本文模型的通用性, 在TN-SCUI挑战赛甲状腺结节分割数据集[27]、乳腺结节分割BUSI数据集[28]、视网膜血管分割DRIVE数据集[29]上进行实验.TN-SCUI数据集为原始数据集经过增强处理后的版本, 包含7 288幅甲状腺超声图像, 其中3 282幅为良性结节、4 006幅为恶性结节.使用五折交叉验证方法, 选取5 830幅图像作为训练集, 1 458幅作为测试集, 经处理后的图像尺寸为256× 256, 总迭代次数为30.乳腺结节分割BUSI数据集共有647幅乳腺超声图像, 其中437幅图像为良性乳腺结节, 210幅图像为恶性乳腺肿瘤.在数据集上随机抽取516幅图像作为训练集, 131幅图像作为测试集, 图像尺寸为256× 256, 总迭代次数为90.对于视网膜血管分割DRIVE数据集, 首先运用取图像块的方法对训练图像进行数据增强, 增强后的数据集包含30 000幅图像块, 其中29 940幅图像块作为训练集, 60幅图像块作为测试集, 图像块尺寸为64× 64, 总迭代次数为120.
本文模型在3个数据集上的可视化分割结果如图9所示.由图可看出, 本文模型整体上的分割效果较完美, 说明模型中的全局推理单元能较好地应对超声图像中噪声干扰较大和伪影较多的问题, 而金字塔特征层的引入使模型能较准确地分割大小形态各异的结节和细微的视网膜血管分支.当然, 本文模型也存在一些不足之处, 如第1幅~第6幅中甲状腺和乳腺结节的边缘轮廓线分割差异较大, 分割表现有待提高.
 | 图9 本文模型在3个数据集上的分割结果Fig.9 Segmentation results of the proposed model on 3 datasets |
为了进一步表现本文模型的先进性, 在3个数据集上与多个模型进行对比, 实验结果如表8所示.实验中所有模型均在同台机器上使用相同的策略完成训练.由表可看出, 本文模型在3个数据集上都取得最高的指标值, 可见本文模型能充分捕获图像中的多尺度信息和细节信息, 更好地应对图像中的噪声干扰问题, 对乳腺结节分割和视网膜血管分割也能获得精度更高的分割结果.
| 表8 各模型在3个数据集上的指标值对比 Table 8 Index value comparison of different models on 3 dataset |
本文提出融合全局推理和MLP架构的甲状腺结节分割模型, 以轴向移位MLP为基础架构, 编码部分融合全局推理单元, 解码部分引入金字塔特征层, 实现甲状腺超声图像中结节区域的自动分割.实验验证和计算复杂度的分析表明, 本文模型能以更小的计算复杂度实现快速、精确的甲状腺结节分割, 更好地应对目前甲状腺结节分割存在的难点问题.另一方面, 对于其它医学图像分割任务, 如乳腺结节分割和视网膜血管分割, 本文模型也取得较优的分割效果.但是, 面对形状不规则的甲状腺结节, 本文模型分割结果仍存在不准确或轮廓线粗糙的现象.今后将考虑获取甲状腺超声图像显著性图, 往更精细化方向发展, 并结合深度学习技术, 实现甲状腺结节良/恶性分类.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|