





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于差异双分支编码器的多阶段图像融合方法
[洪雨露1  , 吴小俊
, 吴小俊1 , 徐天阳1 ]
, 吴小俊, 徐天阳]
|
|



作者简介:

洪雨露,硕士研究生,主要研究方向为图像融合、深度学习.E-mail:yulu_hong@163.com.

徐天阳,博士,副教授,主要研究方向为人工智能、模式识别、计算机视觉.E-mail:tianyang_xu@163.com.
在现有的红外和可见光图像融合方法中,融合图像中的细节信息丢失严重,视觉效果不佳.针对上述问题,文中提出基于差异双分支编码器的多阶段图像融合方法.通过两支不同结构的编码器提取多模态图像的特征,增强特征的多样性.设计多阶段的融合策略,实现精细化图像融合.首先,在差异双分支编码器中,对两个编码分支提取的差异性特征进行初级融合.然后,在融合阶段,对多模态图像的显著性特征进行中级融合.最后,使用远程横向连接将差异双分支编码器的浅层特征传送给解码器,同时指导融合过程和图像重建.对比实验表明,文中算法可增强融合图像的细节信息,并在视觉效果和客观评价上都较优.
About Author:
HONG Yulu, master student. Her research interests include image fusion and deep lear-ning.
XU Tianyang, Ph.D., associate professor. His research interests include artificial intelligence,pattern recognition and computer vision.
In the existing infrared and visible image fusion methods, the details of the fused image are lost seriously and the visual effect is poor. Aiming at the problems, a multi-stage image fusion method based on differential dual-branch encoder is proposed. The features of multi-modal images are extracted by two encoders with different network structures to enhance the diversity of features. A multi-stage fusion strategy is designed to achieve refined image fusion. Firstly, primary fusion is performed on the differential features extracted by the two encoding branches in the differential dual-branch encoder. Then, mid-level fusion on the saliency features of the multi-modal images is conducted in the fusion stage. Finally, the long-range lateral connections are adopted to transmit shallow features of the differential dual-branch encoder implemented to the decoder and guide the fusion process and the image reconstruction simultaneously. Experimental results show the proposed method enhances the detailed information of the fused images and achieves better performance in both visual effect and objective evaluation.
本文责任编委 叶东毅
Recommended by Associate Editor YE Dongyi
图像融合是图像处理中的一个重要课题, 其目的是获得具有重要目标和丰富细节的融合图像.由于成像原理不同, 单个传感器能获取的图像信息相对有限.红外图像可获取图像的热辐射信息, 在视觉昏暗时也不受影响, 但是包括的纹理细节信息较有限, 影响人们对场景的理解.可见光图像可获得丰富的纹理信息和细节信息, 但在昏暗条件下获得的目标信息不明显.因此, 将红外图像和可见光图像进行融合可使融合图像中同时包含红外图像的显著性目标和可见光图像的背景细节信息, 融合后的图像更有利于人类的视觉感知, 也便于后续应用在其它计算机视觉任务中[1].融合技术可应用在检测[2, 3, 4]、目标跟踪[5, 6]、行为识别[7]等许多领域.
现有的图像融合方法一般可分为传统的图像融合方法和基于深度学习的图像融合方法.传统的图像融合方法主要包括基于多尺度变换的方法[8]和基于稀疏/低秩表示学习的方法[9, 10].基于多尺度变换的方法将源图像映射到不同尺度的特征空间, 然后选择合适的融合策略融合多尺度特征, 最后通过逆多尺度变换生成融合图像.基于稀疏/低秩表示学习的图像融合方法是从高质量的输入图像中学习一个过完备字典, 获得稀疏(低秩)的图像表示, 然后选择合适的融合策略, 获得融合的稀疏表示系数, 最后通过图像重构得到融合图像.虽然这些传统的图像融合方法可取得较好的融合质量, 但是学习一个过完备字典就占用融合算法的大部分运行时间, 而且融合质量非常依赖于手工设计的融合规则, 这些融合规则使融合算法越来越复杂.
近年来, 随着深度学习的兴起, 其强大的特征提取能力和重构能力被应用于图像融合中, 学者们提出许多基于深度学习的图像融合方法, 可分为非端到端的图像融合方法和端到端的图像融合方法.非端到端的图像融合方法[11, 12, 13]通常使用深度学习将源图像映射到特征空间, 并使用手工设计的融合规则融合深度特征.常用的融合规则包括取平均值、取最大值、加法等.Li等[12]提出DenseFuse(A Fusion Approach to Infrared and Visible Images), 在训练阶段, 仅通过自动编码器训练网络的重构性能, 不涉及融合策略.在测试阶段, 应用手动设计的融合策略获得多模态图像的融合图像.Li等[13]提出NestFuse(An Infrared and Visible Image Fusion Architecture Based on Nest Connection and Spatial/Channel Atten-tion Models), 为融合图像添加更多的纹理信息.虽然上述方法使用深度学习获得图像特征, 但仍需手动设计融合规则, 增加融合算法的复杂性.
为了避免手动设计融合规则, 让网络自适应地学习融合参数, 学者们提出许多端到端的图像融合方法[14, 15, 16, 17, 18, 19, 20, 21].Prabhakar等[14]提出DeepFuse(A Deep Unsupervised Approach for Exposure Fusion with Ex-treme Exposure Image Pairs), 使用无监督的方式训练多曝光融合网络, 网络包括编码器、融合层和解码器, 在融合层使用相加的方式进行特征融合.由于融合规则过于粗糙, 在复杂的融合任务上, 不具备优势.生成对抗网络(Generative Adversarial Networks, GAN)也被应用于端到端的红外和可见光图像融合中.Ma等[16]提出FusionGAN(A Generative Adver-sarial Network for Infrared and Visible Image Fusion), 使用GAN完成图像融合任务.生成器用于生成红外和可见光图像的融合图像, 判别器用于为融合图像添加纹理信息.但是, 由于损失函数只包括内容损失和对抗损失, 融合后的图像与红外图像接近, 丢失可见光图像的细节.随后, Ma等[17]改进文献[16], 在损失函数中添加细节损失和目标边缘损失, 在一定程度上提高融合质量.
虽然基于GAN的融合方法可实现融合目的, 但是由于GAN的训练不稳定, 网络训练非常困难, 并且融合图像依然丢失大量纹理信息.为了在训练简便的同时提升融合质量, Zhang等[18]提出IFCNN(A General Image Fusion Framework Based on Convolutional Neural Network), 使用两个卷积层作为特征提取模块, 选择简单的融合策略(最大值、平均值、求和)融合提取特征, 最后使用两个卷积层进行图像重建.这种方法虽然可应用于多种图像融合任务, 但网络结构过于简单, 无法提取全面的特征信息, 使融合图像丢失很多内容.此后, Zhang等[19]提出PMGI(A Fast Unified Image Fusion Network Based on Proportional Maintenance of Gradient and Intensity), 梯度分支负责提取纹理特征, 强度路径负责提取强度信息.该方法虽然实现图像融合的任务, 但是仅设计一个卷积核为1的卷积层用于图像重构, 过于简单的重构网络使融合图像较模糊.程春阳等[20]提出基于GhostNet的图像融合方法, 用Ghost模块替换卷积层, 并在损失函数中引入感知损失, 可自适应地学习网络参数, 融合图像中红外目标显著, 但可见光图像的背景信息保留有限, 边缘不清晰.Xu等[21]提出U2Fision(A Unified Unsupervised Image Fusion Net-work), 可解决多种图像融合任务, 但在某些具体的融合任务上表现一般, 缺乏针对性, 在红外和可见光图像数据集上融合图像的目标显著性较弱, 细节信息不足.
针对现有融合方法产生的融合图像细节信息丢失严重的问题, 本文提出基于差异双分支编码器的多阶段图像融合方法, 以端到端的方式训练网络, 避免手工设计融合策略, 降低融合算法的复杂性.本文方法设计编码器的两个分支, 使用不同的网络结构提取源图像的特征, 一个分支使用顺序连接的方式连接卷积层, 另一个分支使用密集连接的方式.差异双分支编码结构可将源图像映射到不同的特征空间, 每个分支能获取源图像的差异性特征信息, 增强特征提取能力.此外, 在现有的一些融合方法[12, 14, 18]中, 仅针对编码器提取的深层特征进行融合, 融合策略较粗糙, 导致融合结果的细节信息丢失严重.因此, 本文设计多阶段精细化融合策略, 不仅可在特征提取阶段对多源特征进行粗略融合, 还在深层特征空间和重构过程中应用融合操作, 使特征融合更充分, 有效增强融合图像的细节信息, 便于理解图像场景, 提升视觉感知效果.实验验证本文方法在视觉效果和客观指标上都较优.
本文提出基于差异双分支编码器的多阶段图像融合方法, 框架如图1所示.方法由三部分组成:差异双分支编码网络、融合层和重构网络.
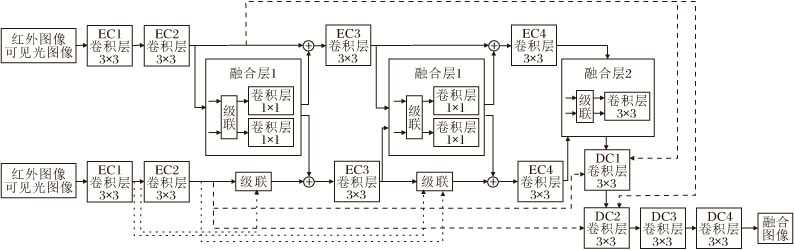 | 图1 本文方法框架图Fig.1 Framework of the proposed method |
如图1所示, 相比现有的图像融合网络, 本文设计差异双分支编码器提取源图像的特征.编码器的2个分支都使用4个卷积层, 分别是EC1、EC2、EC3、EC4.在第1个分支中, 将卷积层的连接方式设计为顺序连接.在第2个分支中, 将卷积层的连接方式设计为密集连接, 以此将源图像映射到不同的特征空间, 提取更丰富、全面的特征, 增强特征提取的多样性.网络输入是级联后的红外图像和可见光图像, 可表示为
$I_{input}=Concat(I_r, I_{vis}), $
其中Concat(·, ·)表示级联操作.这样的结构具有如下2个优点.1)使用两种不同的网络连接方式提取源图像特征的差异双分支编码器, 能学习更全面的信息.2)将不同模态的级联图像作为每个分支的输入, 可在特征提取阶段对多模态特征进行粗略融合.
本文设计精细化的多阶段融合策略, 融合操作分布在网络的三个阶段.在第一阶段, 如图1中的融合层1所示, 在特征提取阶段, 对编码器的两个分支提取的特征进行初步融合, 具体步骤是将前一层中两个编码分支产生的特征进行级联, 然后对级联后的特征分别进行1×1的卷积操作, 以适应两个分支的通道数目, 最后再将融合层1中生成的融合特征传送给编码器的两个分支.这种方式可增强两个分支之间的特征传输, 使多模态特征得到初级融合.在第二阶段, 如图1中的融合层2所示, 在深层特征空间中, 对编码器提取的特征进行融合, 将EC4的输出进行级联, 然后通过一次3×3的卷积融合两个分支的深度特征.在第三阶段, 通过远程横向连接将编码器的浅层特征融入图像重建的过程中, 指导图像重构.
多阶段的融合策略使融合操作分布在网络的多个阶段, 实现精细化特征融合, 获取质量更高的融合图像.
本文的图像重建网络简单有效, 包括4个卷积层(DC1、DC2、DC3、DC4).图像重构网络的DC4输出融合图像$I_f$.此外, 将EC2的输出连接到解码器的前两层(DC1, DC2), 增强图像重构能力.DC1和DC2的输出可表示为
$\begin{array}{l} \phi_{\mathrm{DC} 1}=\operatorname{Conv}\left(\phi_{f 2}+\sum_{j=1}^{n} \phi_{\mathrm{EC} 2}^{j}\right) \\ \phi_{\mathrm{DC} 2}=\operatorname{Conv}\left(\phi_{\mathrm{DC} 1}+\sum_{j=1}^{n} \phi_{\mathrm{EC} 2}^{j}\right) \end{array}$
其中, $ϕ_{DC1}$ 和$ϕ_{DC2}$ 分别表示DC1和DC2输出的特征图, Conv(·)表示卷积操作, $ϕ_{f2}$ 表示融合层2输出的特征图, $ϕ_{EC2}$ 表示EC2输出的特征图, n=2, 表示编码器的分支数量.
本文的目标是生成包含多模态图像信息的融合图像.因此, 融合图像中不仅要具有红外目标信息, 还应包含丰富的纹理细节信息.本文使用均方误差计算融合图像和输入图像之间的像素损失.但是, 只使用均方误差作为损失函数会使融合图像过于平滑, 丢失结构信息.
为了解决此问题, 引入结构相似度(Structural Similarity, SSIM)[22]损失, 指导融合图像中包含更多纹理信息.因此, 总的损失函数包括像素强度损失和结构相似度损失:
$L_{total}=L_{pixel}+λL_{ssim}, $(1)
其中, $L_{pixel}$ 表示像素强度损失, $L_{ssim}$ 表示图像的结构相似性损失, λ表示平衡参数.
图像的像素强度损失$L_{pixel}$ 主要是为了使融合后的图像看起来与输入图像相似, 像素损失可表示为
$\begin{array}{l} L_{\text {pixel }}=\frac{1}{C W H}\left\|I_{f}-I_{p}\right\|_{2}^{2}, \\ I_{p}=\frac{1}{2}\left(I_{r}+I_{\text {vis }}\right), \end{array}$
其中, C表示图像的通道数, W、H表示图像的宽、高, $\left\|·\right\|_2$ 表示2范数, $I_f$ 表示融合图像, $I_p$ 表示设置的图像, 为两个模态图像的平均值.
由于可见光图像包含更多的纹理信息, 通过计算可见光图像和融合图像之间的结构相似度损失, 将更多的纹理细节信息反映到融合图像中.结构相似性损失
$L_{ssim}=1-SSIM(I_f, I_{vis}), $
其中, SSIM(, ·, )表示结构相似度, 用于计算融合图像和可见光图像的结构相似度, $I_f$ 表示融合图像, $I_{vis}$ 表示可见光图像.
在训练阶段, 选择TNO数据集(https://figshare.com/articles/TN_Image_Fusion_Dataset/1008029)中的15对红外和可见光图像, 将这些图像裁剪为 64× 64的图像块, 随机选择8 000对作为训练集.批处理大小为4, 迭代次数为20.学习率为0.000 1.式(1)中的
通过融合图像的视觉效果及客观指标评价融合质量.质量较高的融合图像不仅要具有良好的视觉效果, 客观上还要包含充足的来自源图像的信息.因此, 本文选取如下6个客观评价指标:熵(Entropy, En)[24]、视觉信息保真度(Visual Information Fidelity, VIF)[25]、互信息(Mutual Information, MI)[26]、基于离散余弦变换互信息(Discrete Cosine Transform Based Fast-Feature MI, FMIdct)[27]、基于小波特征互信息(Wavelet Based Fast-Feature MI, FMIw)[27]、Qabf(Edge Preservation Value)[28].
本文选择如下对比方法:JSRSD(Infrared and Visible Image Fusion Method Based on Saliency Detec-tion in Sparse Domain)[9]、VggML(VGG-19 and The Multi-layer Fusion Strategy Based Method)[11]、Dense-Fuse[12]、NestFuse[13]、DeepFuse[14]、FusionGAN[16]、IFCNN[18]、PMGI[19]和U2Fusion[21], 对比方法的融合结果都是从原作者提供的代码中得到的.
为了证实多阶段融合策略的有效性, 进行消融实验, 包括:1)单阶段融合策略(简记为1-stage), 融合策略只包含融合层2, 无融合层1和DC1、DC2的横向连接.2)两阶段融合策略(简记为2-stage), 即融合策略包括融合层2和DC1、DC2的横向连接, 无融合层1.2)三阶段融合策略(简记为3-stage), 融合策略包括融合层1、融合层2和DC1、DC2的横向连接.不同网络获得的融合图像如图2所示.
 | 图2 使用不同融合策略获得的融合图像Fig.2 Fused images obtained by different fusion strategies |
由图2可知, 在使用单阶段融合策略获得的融合图像中, 红外目标信息突出, 但在光线昏暗时, 纹理细节信息丢失严重.相比使用单阶段融合策略获得的融合图像, 使用两阶段融合策略和三阶段融合策略得到的融合图像不仅拥有突出的红外目标信息, 还包含丰富的可见光图像的纹理信息, 具有良好的视觉效果.
为了更全面客观地验证多阶段融合策略的有效性, 本文使用TNO数据集上21对红外和可见光图像进行定量分析, 计算3种融合策略在21张融合图像上的指标平均值, 结果如表1所示, 表中黑体数字表示最优值.
| 表1 在TNO数据集上使用不同融合策略获得的指标平均值 Table 1 Average index values obtained by different fusion strategies on TNO dataset |
由表1可知, 随着融合阶段的增多, 得到的融合图像质量不断提高, 由此验证多阶段融合策略的有效性.
为了验证差异双分支编码器的有效性, 将编码器两个分支的连接方式设置为如下3种方式:都使用顺序连接(简记为seq-seq)、都使用密集连接(简记为dense-dense)、分别使用顺序连接和密集连接(简记为seq-dense).3种方式获得的融合图像如图3所示.
 | 图3 使用不同编码结构获得的融合图像Fig.3 Fused images obtained by different coding structures |
由图3可知, 都使用顺序连接结构获得的融合图像中红外信息明显, 都使用密集连接结构获得的融合图像更偏向可见光图像, 而分别使用两种连接的结构可更好地平衡红外图像和可见光图像的信息, 同时保留显著特征和丰富的细节信息.
再使用TNO数据集上21对红外和可见光图像进行定量分析, 结果如表2所示, 表中黑体数字表示最优值.
由表3可知, 通过本文的差异双分支编码结构得到的融合图像综合质量最高.
| 表2 在TNO数据集上使用不同编码结构获得的指标平均值 Table 2 Average index values obtained by different coding structures on TNO dataset |
| 表3 各方法在TNO数据集上的指标值 Table 3 Index values of different methods on TNO dataset |
在TNO数据集的21对红外和可见光图像上测试本文方法.各对比方法获得的融合图像如图4所示, 图中红色方框标注细节信息, 并对红色方框内的区域进行放大展示.
 | 图4 各方法在“ street” 图像上的融合图像Fig.4 Fused images obtained by different methods for “ street” images |
由图4可知, JSRSD获得的融合图像中包含噪声和伪影, 显著性特征不清晰.VggML、FusionGan和IFCNN获得的融合图像更偏向于红外图像, 字母信息模糊.由于背景信息在融合图像中非常重要, DeepFuse、DenseFuse、NestFuse、U2Fusion的融合结果中保留一定的纹理信息, 但仍较粗糙, 字母边缘不清晰.
本文方法获得的融合图像平衡红外图像和可见光图像的特征, 使融合图像既包含红外图像的显著目标, 又含有可见光图像的纹理, 字母也较清晰, 最终的融合效果更有利于人类的视觉感知.
各对比方法在测试集上获得的融合图像的指标值如表3所示, 在表中, 黑体数字表示最优值, 斜体数字表示次优值.
由表3可看出, 本文方法可在EN、MI、Qabf、FMIdct、FMIw指标上获得最优值.这表明在本文方法获得的融合图像中, 既包含丰富的细节信息量(EN、MI), 又拥有充足的特征信息和较高的图像质量(VIF、FMIdct和FMIw).在VIF指标上, 本文方法取得次佳值, 仅次于U2Fusion, 但两种方法的VIF值非常相近.相比U2Fusion, 本文方法的VIF值仅降低0.13%, 仍具有良好的视觉保真度.此实验验证本文方法的有效性.
为了验证本文方法的泛化性, 选择VOT2020-RGBT与TNO数据集上40对红外与可见光图像进行测试.各方法在其中一对图像上的融合效果如图5所示, 图中红色方框标记红外信息, 黄色方框标记可见光图像信息.
 | 图5 各方法在“ river” 图像上的融合图像Fig.5 Fused images of different methods for “ river” images |
由图5可知, DeepFuse、DenseFuse、PMGI、U2Fusion的融合图像中红外信息不显著, Nest-Fuse、IFCNN的融合图像中丢失大量可见光图像的纹理信息.本文方法获得的融合图像既有显著的红外特征, 又含有丰富的纹理信息.
各方法在40对图像上获得的融合图像的指标值如表4所示, 表中黑体数字表示最优值, 斜体数字表示次优值.
| 表4 各方法在VOT2020-RGBT与TNO数据集上的指标值 Table 4 Index values of different methods on VOT2020-RGBT and TNO datasets |
由表4可知, 本文方法在EN、MI、FMIdct、FMIw指标上获得最优值, 表明本文方法获得的融合图像质量更高, 也验证本文方法具有泛化性.
本文方法还可融合RGB图像与红外图像.首先将RGB图像转换到YCrCb空间, 仅将Y通道(亮度通道)和红外图像作为本文方法的输入, 获取融合后的亮度通道图.然后将融合的亮度通道与CrCb通道一起转换到RGB空间, 获得彩色融合图像.
RGB与红外图像的测试数据来自文献[4]和文献[29].选取本文方法部分融合结果, 如图6所示, 图中红色方框内表示红外显著特征.由图可知, 融合图像中不仅包含红外图像中的显著性目标, 还保留RGB图像的色彩和背景信息, 更有利于人类的视觉感知.
 | 图6 本文方法对RGB与红外图像的融合结果Fig.6 Fusion results of the proposed methods for RGB and infrared images |
本文提出基于差异双分支编码器的多阶段图像融合方法, 使用差异双分支编码器提取多模态图像的特征, 弥补特征提取多样性不足的问题.设计多阶段的图像融合策略, 在融合网络的不同阶段融合特征空间的特征, 使融合图像包含更全面的源图像的信息, 提升融合图像中的细节信息.实验表明, 本文方法可较好地保留红外图像的显著目标信息和可见光图像的背景信息, 同时在人类视觉感知和客观评价指标上都取得较优结果.性能较优的融合方法是应用于实际任务的关键之一, 还可应用在其它计算机视觉任务中, 如目标跟踪、检测等, 今后可开展进一步的研究.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|