{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于Transformer与异质图神经网络的新闻推荐模型
[张玉朋1 , 李香菊1  , 李超
, 李超2 , 赵中英1 ]
, 李超|
|


 李香菊,博士,讲师,主要研究方向为自然语言处理、情绪分析、推荐算法.E-mail:lixiangju100@163.com.
李香菊,博士,讲师,主要研究方向为自然语言处理、情绪分析、推荐算法.E-mail:lixiangju100@163.com.
作者简介: 张玉朋,硕士研究生,主要研究方向为机器学习、推荐系统.E-mail:13280314536@163.com.
张玉朋,硕士研究生,主要研究方向为机器学习、推荐系统.E-mail:13280314536@163.com.
 李超,博士,副教授,主要研究方向为网络表示学习、社交网络分析、推荐算法.E-mail:1008lichao@163.com.
李超,博士,副教授,主要研究方向为网络表示学习、社交网络分析、推荐算法.E-mail:1008lichao@163.com.
 赵中英,博士,副教授,主要研究方向为社交网络分析、数据挖掘、推荐系统.E-mail:zyzhao@sdust.edu.cn.
赵中英,博士,副教授,主要研究方向为社交网络分析、数据挖掘、推荐系统.E-mail:zyzhao@sdust.edu.cn.
新闻推荐方法大多假定用户浏览的新闻之间具有很强的时序依赖关系,但新闻具有更新的快速性及用户阅读的自由性等特点,使时序性建模中可能会引入噪音.为了解决此问题,文中提出基于Transformer与异质图神经网络的新闻推荐模型.采用Transformer从用户近期浏览的新闻中对用户的短期兴趣进行建模,通过异质图神经网络捕捉用户和新闻之间的高阶关系,建模用户长期兴趣和候选新闻的表示.同时,为了自适应调整短期兴趣和长期兴趣在用户建模时的重要性,设计用户长短期兴趣感知的点击预测机制.在真实数据集上的对比实验验证文中模型的有效性.
Author:ZHANG Yupeng, master student. His research interests include machine learning and recommendation system.
LI Chao, Ph.D., associate professor. His research interests include network representation learning, social network analysis and re-commendation algorithm.
ZHAO Zhongying, Ph.D., associate professor. Her research interests include social network analysis, data mining and recommendation system.
In most of the existing news recommendation models, it is assumed that there is strong temporal dependence among the news items browsed by users. However, noise may be introduced into temporal modeling due to the rapidity of news updates and the freedom for users to read. To solve the problem, a news recommendation model based on Transformer and heterogenous graph neural network is proposed. Different from the neural network model based on time series, Transformer is employed to model the users’ short-term interests from the recent reading history. Using heterogenous graph neural networks, users’ long-term interests and candidate news representations are modeled by capturing the high-order relationship information between users and news. Meanwhile, a long and short-term interests aware mechanism is designed to adaptively adjust the importance of users’ long-term and short-term interests in news recommendation. Experiments on a real-world dataset demonstrate the effectiveness of the proposed model.
随着互联网技术的快速发展, 信息过载严重, 用户无法快速选择感兴趣的新闻.新闻推荐旨在通过对用户和新闻建模, 帮助用户从海量新闻数据中筛选并推送其感兴趣的新闻, 有效缓解新闻信息的过载问题.目前, 新闻推荐已在改善用户阅读体验方面取得显著的效果, 引起学术界和工业界的广泛关注[1, 2].
现有的新闻推荐算法大体可分为基于协同过滤的推荐算法、基于内容的推荐算法、混合推荐算法[3].基于协同过滤的推荐算法假设行为相似的用户会对同个新闻具有相似的偏好.Xue等[4]提出DMF(Deep Matrix Factorization Models), 为一个深度矩阵分解模型, 使用非线性层处理用户与新闻的显示评级和隐式反馈.Wang等[5]提出图神经协同过滤框架, 将用户-项目交互构成一个二部图, 再在图上传播嵌入以学习用户-项目图结构.但协同过滤的推荐算法面临冷启动问题.为了解决这一问题, 研究者们提出基于内容的推荐算法和混合推荐算法.基于内容的推荐算法通过对新闻的内容或用户的属性建模, 获取用户的兴趣表示, 并向用户推荐相似的新闻.混合推荐算法结合不同的推荐算法, 获得更好的推荐结果.Bansal等[6]将主题模型、协同过滤和贝叶斯个性化排序整合到一个框架中.Cheng等[7]融合线性模型和前馈神经网络, 用于特征交互建模.Wu等[8]提出NRMS(Neural News Recommendation with Multi-head Self-Attention)、Fan等[9]提出GraphRec(Graph Neural Network Framework)、Qiu等[10]提出GREP(Graph Neural News Recommendation Model with User Existing and Potential Interest Modeling), 分别使用多头自注意力机制与其它算法结合, 用于新闻推荐.Wu等[11]提出NAML(Neural News Recommen-dation Approach with Attentive Multi-view Learning), 在建模新闻标题和内容时采用卷积神经网络(Convolutional Neural Network, CNN)与注意力机制结合的方法.
基于内容的推荐算法或混合推荐算法中的一个关键步骤是用户兴趣建模, 现有的用户兴趣建模方法大体分为3种:用户整体兴趣建模、用户时序兴趣建模和用户混合兴趣建模[12].用户整体兴趣建模在建模用户兴趣时, 将用户浏览的历史新闻看作一个没有顺序的集合, 不考虑用户浏览历史新闻的时间顺序信息.Wang等[2]提出DKN(Deep Knowledge-Aware Network), 通过注意力机制计算候选新闻向量与每条浏览新闻向量之间的权重, 使用该权重聚合用户的浏览历史, 计算用户的兴趣表示.Wu等[13]提出User-as-Graph, 将每位用户建模为一个个性化的异构图, 捕捉用户行为之间的相关性, 进行更准确的用户兴趣建模.Li等[14]提出MINER(Multi-interest Matching Network for News Recommendation), 使用多重注意力方法学习用户的多个兴趣向量表示, 在聚合用户的多个兴趣向量表示之后, 得到用户的最终表示.Wu等[15]提出CPRS(Click Preference and Reading Satisfaction), 从用户的点击新闻标题行为和对新闻内容的阅读行为两方面建模用户的整体偏好.这类模型在对用户兴趣建模时取得一定效果, 但忽略用户点击新闻的时间信息.
用户时序兴趣建模根据用户浏览新闻的时间排序, 注重考虑时序信息, 对用户兴趣进行建模.Okura等[16]采用门控神经网络(Gated Recurrent Unit, GRU)对用户浏览历史进行建模, 学习用户的兴趣表示, 计算用户兴趣表示与候选新闻表示之间的相关性, 从而实现新闻推荐.Khattar等[17]提出使用双向长短期记忆网络(Long Short-Term Memory, LSTM)的混合循环注意机, 使用双向LSTM构建用户历史组件.
用户混合兴趣建模在对用户兴趣建模时同时考虑用户浏览历史新闻的内容和用户浏览时序信息.Zhu等[18]提出DAN(Deep Attention Neural Network), 采用LSTM和候选新闻感知的注意力机制为用户建模, 分别生成用户浏览历史序列表示和用户兴趣表示.Hu等[19]提出GNewsRec(Graph Neural News Re-commendation Model), 考虑用户的长短期兴趣, 采用LSTM对用户最近浏览的新闻进行建模, 得到用户短期兴趣表示, 并采用图神经网络(Graph Neural Network, GNN)学习用户长期兴趣表示.An等[20]采用GRU学习用户短期兴趣嵌入, 并通过ID嵌入方式建模用户长期兴趣.
上述工作已取得一定的成果, 但已有的基于循环神经网络(Recurrent Neural Network, RNN)及其变体的工作在用户短期兴趣建模时, 通常假定用户浏览的新闻之间具有很强的时序依赖关系, 注重用户阅读新闻的顺序.但新闻推荐不同于序列推荐(如电子商务推荐)[21], 用户可能不会连续阅读类似的新闻.用户阅读新闻时通常会被新出现的新闻或重大事件吸引, 阅读的相邻新闻往往是多样化的而不是类似的.因此, 用户阅读新闻的顺序对用户兴趣的表示依赖性不大.当采用基于时序性的网络模型(如LSTM等)对用户阅读的新闻进行建模并获取用户兴趣时可能会引入噪音, 并且不同的历史新闻对用户近期兴趣建模也具有不同作用.此外, 现有工作往往假定长短期兴趣同等重要, 将得到的长期兴趣和短期兴趣表示进行拼接后再预测与候选新闻的匹配程度, 难以体现用户不同兴趣与候选新闻之间的匹配程度.
为了解决上述问题, 本文提出基于Transformer与异质图神经网络的新闻推荐模型(News Recom-mendation Model Based on Transformer and Heterogenous Graph Neural Network, NR-TrHGN).首先, 使用CNN得到新闻的表示.然后通过异质图神经网络捕捉用户和新闻之间的高阶关系, 建模用户长期兴趣和候选新闻的表示.用户阅读的近期新闻对其兴趣建模具有重要作用[19, 20], 但是由于用户短期阅读新闻数量相对较少, 对其构建异质图时, 会出现严重稀疏问题, 因此不同于长期兴趣采用图异质神经网络建模的方式, 本文采用Transformer从用户最近浏览的新闻中建模用户的短期兴趣表示.最后, 分别采用不同的评分规则计算候选新闻与用户长期兴趣和短期兴趣之间的匹配程度.在真实数据集上的对比实验验证本文模型的有效性.
文中的新闻推荐问题定义如下:给定新闻集I={d1, d2, …, dM}和用户集U={u1, u2, …, uS}, 其中, M表示新闻总数, S表示用户总数.用户u在新闻集I上的历史浏览记录为{du, 1, du, 2, …, du, n}, 其中du, j表示用户u浏览的第j个新闻.令
在本文中, 每条新闻包括标题、内容中的实体及实体类型.每个新闻标题T={w1, w2, …, wf}, 由一组单词序列组成, 其中, wi表示新闻标题T中第i个单词, f表示新闻标题中词语的个数.新闻内容由一组实体E={e1, e2, …, eg}和对应的实体类型C={c1, c2, …, cg}组成, 其中, ci表示实体ei的实体类型, g表示新闻内容中实体的个数.
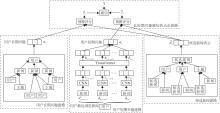
本文提出基于Transformer与异质图神经网络的新闻推荐模型(NR-TrHGN), 总体框架如图1所示.
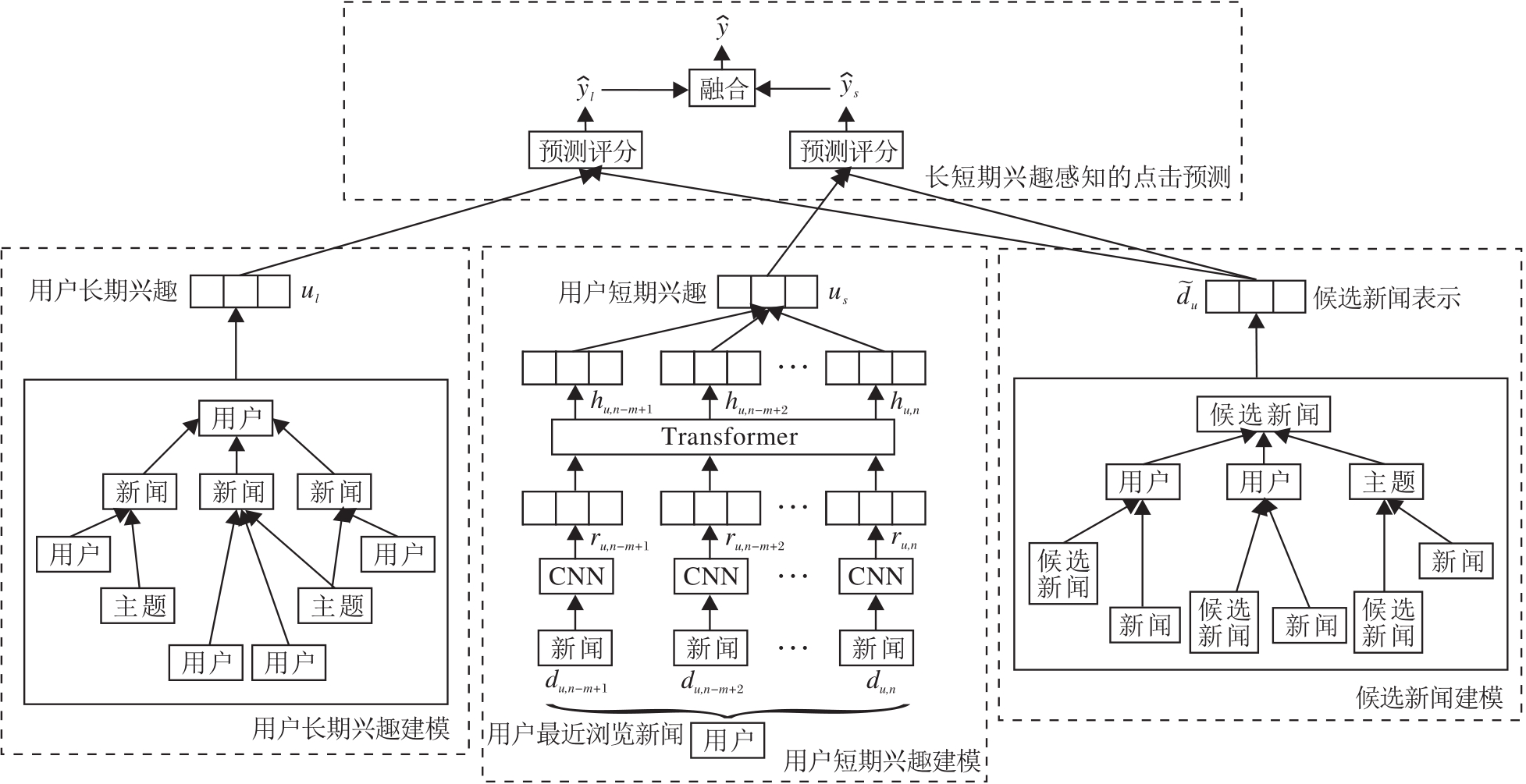 | 图1 NR-TrHGN总体框架图Fig.1 Framework of NR-TrHGN |
NR-TrHGN包括四个模块:用户长期兴趣建模、用户短期兴趣建模、候选新闻建模和长短期兴趣感知的点击预测.首先, 采用CNN提取新闻特征.然后, 为了能学习到用户、新闻和主题之间的高阶关系, 本文构建一个具有用户完整浏览历史的用户-新闻-主题异质图, 通过GNN的强大推理能力, 建模用户长期兴趣和候选新闻的表示.对用户最近浏览的新闻通过Transformer得到用户短期兴趣表示.最后, 分别使用两个评分表示候选新闻与用户长期兴趣和短期兴趣之间的匹配程度, 通过一个可学习的参数将两个评分线性组合, 得到一个统一评分, 用于最后预测.
在用户长期兴趣建模、用户短期兴趣建模、候选新闻建模这3个模块中均包含对新闻特征的提取.新闻特征提取部分主要包含两步.首先获取新闻标题、新闻内容中的实体、实体类型的嵌入表示.本文采用初始化词向量矩阵的形式, 根据词向量矩阵获取新闻标题的嵌入表示
其中, wi∈
及对应的实体类型嵌入
其中, ei∈
其中, f(c)=Wcc表示转换函数, Wc∈
新闻标题表示
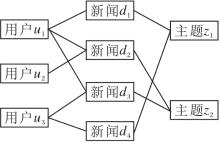
受异质图神经网络模型在推荐系统领域成功应用[22]的启发, 本文采用异质图神经网络捕捉用户和新闻之间的高阶关系.主题信息有助于更好地表示用户兴趣, 并减轻用户-新闻交互的稀疏性, 因此本部分首先采用LDA(Latent Dirichlet Allocation)[23]获取主题分布, 随后构建一个包含用户完整浏览历史的用户-新闻-主题异质图.使用图卷积网络学习用户和新闻的嵌入, 在图上传播嵌入, 对用户与新闻之间的高阶信息进行编码.
如图2所示, 异质图G=(V, R)包含节点集合V和边集合R.在本文中, 节点集合V={Vu, Vd, Vt}, 包括用户节点集合Vu、新闻节点集合Vd和主题节点集合Vt.本文的边集合通过如下方式连接:若用户ui浏览新闻dj(即xij=1), 则用户ui和新闻dj之间有边, 新闻dj与它的主题tk相连.
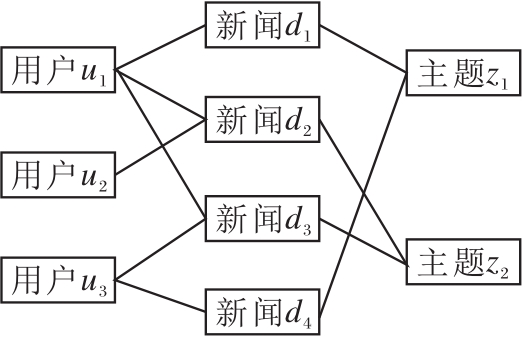 | 图2 用户-新闻-主题异质图Fig.2 User-news-topic heterogenous graph |
本文采用GNN捕获用户和新闻之间的高阶关系, 计算以用户为中心节点单层GNN的一般步骤如下.首先聚集用户的邻居节点, 将不同类型的邻居节点映射到同一空间, 通过GNN更新中心节点表示:
Eu=ReLU(W· (Mean(M· Ev))+b), (1)
其中, ReLU(· )表示ReLU激活函数, Mean(· )表示均值聚合函数, M表示将不同类型的节点转换到同一空间的可训练变换矩阵, W、b表示GNN层的权重矩阵和偏差, Ev表示中心节点Eu的邻居节点表示.同样地, 按照上述过程可得到新闻的特征表示En和主题的特征表示Et.
再计算与用户相邻新闻的线性平均组合:
EN=
其中, n表示与用户u相邻新闻的表示, 可随机初始化, Wn表示新闻可训练转换矩阵, 映射到用户嵌入空间, N(u)表示与用户直接相连的新闻集合.
然后通过邻居节点嵌入对用户长期兴趣嵌入进行更新:
ul=ReLU(Wl.EN+bl),
其中, ReLU(· )表示ReLU激活函数, Wl、bl分别表示第1层GNN的转换权重和偏差.
用户长期兴趣的最终嵌入表示只与用户直接相连的邻居相关, 即用户浏览过的新闻.为了捕获用户和新闻之间的高阶关系, 可将GNN从一层扩展到多层.如图1左侧用户长期兴趣模块所示, 二阶的用户嵌入先通过式(1)均值聚合用户表示和主题表示, 得到与用户直接相邻的新闻表示n, 再均值聚合新闻表示n, 得到用户的二阶特征表示ul.
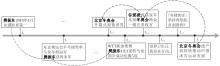
短期兴趣在用户兴趣建模中具有重要作用[19, 20].图3列举某用户在一段时间内阅读新闻的标题序列, 用户在时刻
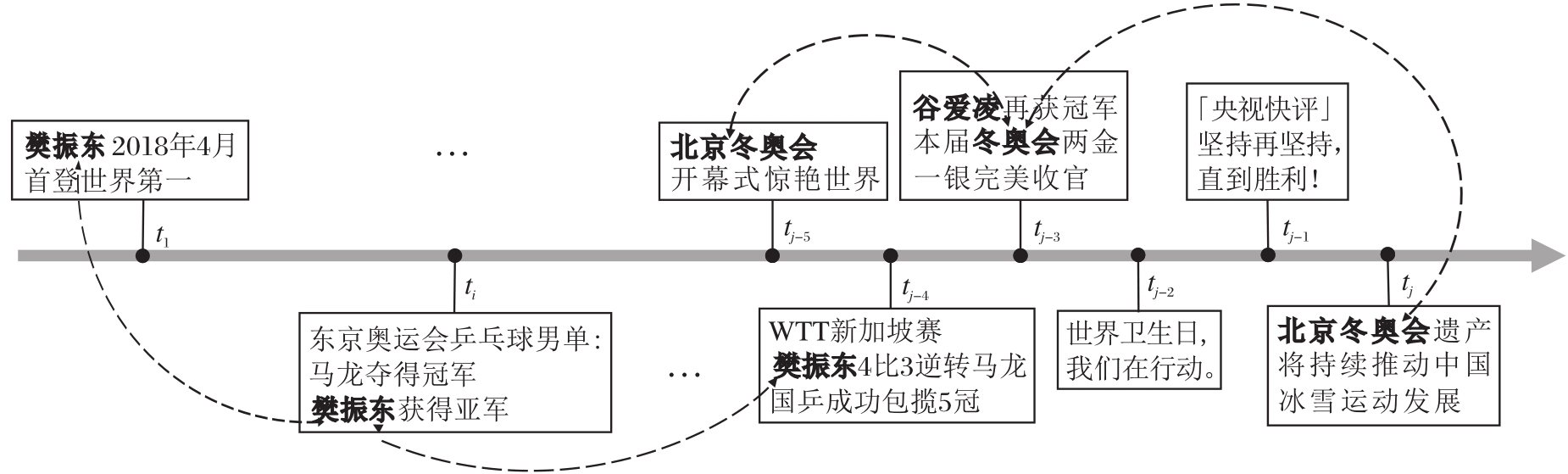 | 图3 用户阅读新闻的标题序列Fig.3 Title sequence of news read by user |
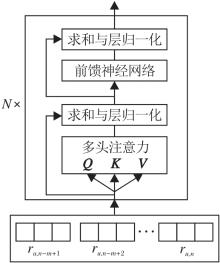
Transformer的编码器由多块串联组成, 其中每块由多头注意力机制和前向反馈神经网络组成[24].基于Transformer的用户短期兴趣编码结构如图4所示.
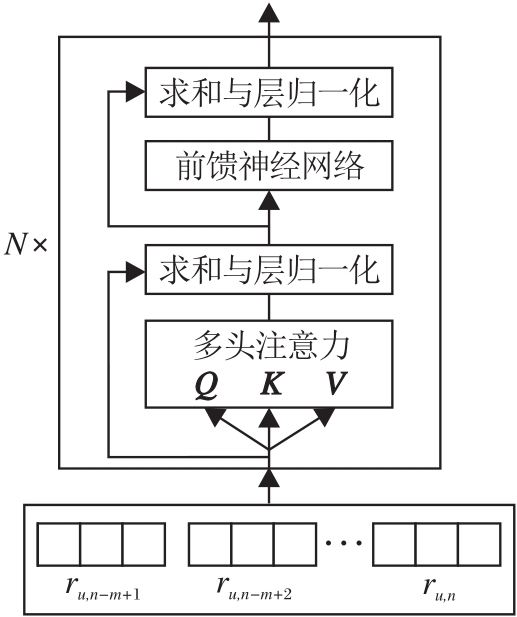 | 图4 基于Transformer的用户短期兴趣建模结构图Fig.4 Structure of user’ s short-term interest modeling based on Transformer |
以用户u最近浏览的新闻{du, n-m+1, du, n-m+2, …, du, n}的特征表示矩阵
为Transformer输入.Transformer每个模块的计算步骤如下.
Transformer中多头注意力机制通过3个矩阵实现, 即查询矩阵Q、键矩阵K和值矩阵V.首先将新闻的特征表示进行如下变换:
Qi=ReLU(
其中,
$\begin{array}{l} \boldsymbol{Z}_{\text {mul }}=\operatorname{Concat}\left(\boldsymbol{Z}_{i}\right) \cdot \boldsymbol{W}^{0}, i=1, 2, \cdots, \text { head, } \\ \boldsymbol{Z}_{i}=\operatorname{Softmax}\left(\frac{\boldsymbol{Q}_{i} \cdot \boldsymbol{K}_{i}^{\mathrm{T}}}{\sqrt{d_{k}}}\right) \boldsymbol{V}_{i}, \end{array}$
其中, head表示注意力头数, Zi表示第i个注意力头, Concat(· )表示拼接操作, WO表示附加的权重矩阵.接下来进行求和与层归一化:
o=Normalize(Zmul+
随后将o传递到前馈神经网络, 再次进行求和与层归一化操作.
Transformer包含N层这样的操作, 每层的输出作为下一层的输入.最终得到用户最近浏览新闻的隐藏表示:
H=[hn-m+1, hn-m+2, …, hn].
然后采用注意力网络进一步获取用户的短期兴趣表示us.
候选新闻建模与用户长期兴趣建模相似, 采用GNN捕捉用户和新闻之间的高阶关系, 不同的是本模块把候选新闻当作中心节点, 先通过式(1)均值聚合相邻的新闻嵌入, 得到与候选新闻直接相邻的用户嵌入u和主题嵌入t, 再聚合用户嵌入u和主题嵌入t, 得到候选新闻的二阶嵌入表示:
其中, Wu表示用户可训练转换矩阵, Wt表示主题可训练转换矩阵, 将它们从不同的空间映射到相同的候选新闻嵌入空间, U(z)、T(z)分别表示与候选新闻直接相连的用户集合和主题集合.
现有的基于长短期兴趣的新闻推荐模型往往将长期兴趣和短期兴趣进行拼接以表示用户兴趣, 但用户长期兴趣和短期兴趣在用户兴趣建模时重要程度不一定相同.因此, 本文提出长短期兴趣感知的点击预测方法, 更准确地预测用户新闻点击.首先通过候选新闻嵌入
然后通过
计算候选新闻
其中α 表示一个可学习的参数.
令
X=(u,
表示一个训练样本, 其中,
L=-{
其中, △ +表示正样本集, △ -表示负样本集.此外, 本文对使用注意力机制的权重参数进行L2正则化处理, 防止过拟合.
本文实验使用挪威新闻门户网站的真实数据集Adressa[25], 数据集情况如表1所示.Adressa数据集分为2个数据子集:Adressa-1week和Adressa-10weeks.Adressa-1week数据集包含一周(从2017年1月1日至2017年1月7日)内用户浏览新闻的数据, Adressa-10weeks数据集包含10周(从2017年1月1日至2017年3月31日)内用户浏览新闻的数据.Adressa是一个基于事件的数据集, 对于每个事件, 本文使用如下7个属性:会话开始、会话结束、用户ID、新闻ID、时间戳、标题和概要文件, 用于生成数据集.本文根据时间戳对新闻进行排序.
| 表1 实验数据集详细信息 Table 1 Description of experimental datasets |
对于Adressa-1week数据集, 本文把前5天的历史数据用于构造图, 前5天用户最后浏览的n条新闻用于用户短期兴趣建模, 第6天的数据用于生成< 用户, 新闻> 对, 建立用户和新闻之间的边, 最后一天的数据中20%用于验证, 80%用于测试.类似地, 对于Adressa-10weeks数据集, 本文使用前50天的数据用于构造图, 接下来的10天用于生成训练对, 剩下10天的20%数据用于验证, 80%数据用于测试.
同先前的新闻推荐相关工作[18, 19, 20]一致, 本文采用AUC(Area Under Curve)和F1作为评价指标.本文模型基于Tensorflow1.15实现.标题嵌入维度k1、实体嵌入维度k2和实体类型嵌入维度k3均设置为50, 新闻嵌入维度、用户嵌入维度和主题嵌入维度均设为128.并行CNN的参数配置和DAN[20]中一致, 用户最近浏览的新闻数m=10.Transformer中多头自注意力机制的头数设置为8.LDA中主题数设为20.在GNN中, 采样固定数量的相邻用户数Lu设置为10, 相邻新闻数Ld设置为30.本文采用均值为0、标准差为0.1的高斯分布进行随机初始化参数, 并采用Adam(Adaptive Moment Estimation)[26]对参数进行优化, 将学习率设置为0.000 3, 失活率设置为0.5.模型在训练过程中, 采用验证集进行验证.上述参数是根据模型在验证集上性能最优时确定的, 保留在验证集上最优的模型, 并在测试集上进行测试.
为了测试本文模型性能, 选择如下经典的基准算法与近期效果突出的新闻推荐方法进行对比实验.同先前的工作一样[19, 20], 所有的对比模型采用相同的参数设置.
1)Wide& Deep(Wide& Deep Learning for Recom-mender Systems)[7].经典推荐模型, 融合线性模型和前馈神经网络, 用于建模低阶和高阶的特征交互.线性模型用于提高模型的记忆能力, 但依赖于手动提取特征, 泛化能力较弱.前馈神经网络用于提高模型的泛化能力.
2)DeepFM(Factorization-Machine Based Neural Network)[27].经典的推荐模型, 主要包括线性模型和深度模型两个模块, 分别用于提取低阶信息的因子分解机和提取高阶交叉特征的神经网络.
3)DKN[2].基于深度知识感知的新闻推荐系统, 将单词和实体看作多个通道, 通过CNN合并语义和知识级的表示.
4)DAN[18].基于深度注意力神经网络, 用于新闻推荐, 采用基于注意力的并行CNN提取用户特征, 并使用基于注意力的RNN捕获用户浏览的顺序特征.
5)GNewsRec[19].结合用户长期兴趣和短期兴趣, 采用LSTM建模用户短期兴趣, 基于图神经网络建模用户长期兴趣, 拼接用户长期兴趣与短期兴趣, 用于用户最终表示.
6)AGNN(Attention-Based Graph Neural Network News Recommendation)[28].基于注意力的图神经网络新闻推荐模型, 采用多通道CNN生成新闻表示, 并利用改进的LSTM和图神经网络建模用户表示.
各模型在两个数据集上的指标值对比结果如表2所示, 表中黑体数字表示最优值.观察和分析表2, 可得出如下结论.
| 表2 各模型的性能对比 Table 2 Performance comparison of different models % |
1)新闻推荐模型优于其它推荐模型(如Wide& -Deep和DeepFM).这验证在新闻推荐任务上新闻推荐模型比一般的推荐模型更有效.表中所有新闻推荐模型在Adressa-10weeks数据集上的性能均低于Adressa-1week数据集上的性能, 可能是因为Adressa-10weeks数据集记录用户十周阅读的新闻, 由于用户新闻更新的快速性, 时间相对较久的新闻可能对用户兴趣建模产生干扰.Wide& Deep和DeepFM虽然在Adressa-10weeks数据集上的性能优于在Adressa-1week数据集上的性能, 但其性能均低于新闻推荐模型, 此外, 这两个模型在线性模型输入部分均依赖于人工提取特征, 泛化能力较弱.
2)分别提取用户长期兴趣和短期兴趣的模型比只考虑用户单一兴趣的模型效果更优.GNewsRec、AGNN、NR-TrHGN在两个评价指标上均高于其它模型, 这说明同时考虑用户长短期兴趣是有必要的.
3)相比其它同时考虑用户长短期兴趣的模型(GNewsRec和AGNN), NR-TrHGN的各项指标值均最高.这主要是由于NR-TrHGN借助Transformer强大的编码能力对用户近期兴趣进行建模, 过滤近期兴趣中不重要的信息.此外设计长短期兴趣感知的点击预测机制, 自适应地学习长短期兴趣在新闻推荐中的重要程度, 进一步提高模型性能.
本节对比模型的变体, 由此验证各模块的有效性, 定义如下4个子模型.
1)NR-TrHGN-t.表示从NR-TrHGN中去掉新闻主题信息, 即在GNN中不考虑新闻的主题信息.
2)NR-TrHGN-s.表示从NR-TrHGN中去掉用户短期兴趣, 即式(2)修改为
3)NR-TrHGN-a.表示从NR-TrHGN中去掉用户短期兴趣建模模块中的注意力机制, 由Transformer得到用户最近浏览新闻的表示
H=[hn-m+1, hn-m+2, …, hn],
通过均值聚合的方式得到用户的短期兴趣表示us.
4)NR-TrHGN-l.表示从NR-TrHGN中去掉用户长期兴趣, 即式(2)修改为
各模型在2个数据集上的指标值如表3所示, 表中黑体数字表示最优值.由表可看出, 当NR-TrHGN删除用户长期兴趣建模模块后, AUC和F1出现大幅下降, 这说明用户长期兴趣对用户兴趣表示影响程度更大.当NR-TrHGN删除用户短期兴趣建模模块后, AUC和F1下降超过2%, 这表明用户短期兴趣建模模块的有效性, 应同时考虑用户的长期兴趣和短期兴趣.当NR-TrHGN删除用户短期兴趣建模模块中的注意力机制后, 实验效果优于NR-TrHGN直接删除用户短期兴趣的效果, 这验证Transformer对NR-TrHGN的提升效果.相比没有新闻主题信息的模型, NR-TrHGN在两个指标上均有提升, 这是因为加入新闻主题信息可缓解数据稀疏性的问题.综上可见, 本文提出的各模块均是有效的.
| 表3 消融实验结果 Table 3 Results of ablation experiment % |
为了验证变量对实验结果的影响, 本节在Adressa-1week、Adressa-10weeks数据集上分析模型中GNN层数和Transformer层数对实验结果的影响, 并展示可学习参数α 的变化曲线.
不同GNN层数对实验结果的影响如表4和表5所示.表中黑体数字表示最优值; U-1 layer、U-2 layers分别表示在用户长期兴趣建模时, 以用户为中心节点的GNN层数分别设为1、2; N-1 layer、N-2 layers、N-3 layers分别表示在候选新闻建模时, 以候选新闻为中心节点的GNN层数分别设为1、2、3.当以用户为中心节点的GNN和以候选新闻为中心节点的GNN层数都为2时, 两个评价指标效果最优.当以新闻为中心节点的GNN层数从1层增至2层时, AUC值最高提升5.1%, F1值最高提升5%; 当以新闻为中心节点的GNN层数从2层增至3层时, AUC值最高下降3.7%, F1值最高下降4.6%, 以用户为中心节点的GNN层数变化表现出相同的趋势.这是因为一层的GNN不能捕获用户和新闻之间的高阶关系, 而三层的GNN可能会给模型带来更多的噪声, 影响模型性能.当推断节点间的相似性时, 更高的关系层数对实验结果意义不大[2].
| 表4 不同GNN层数的实验结果(Adressa-1week) Table 4 Experimental results of different GNN layers (Adressa-1week) % |
| 表5 不同GNN层数的实验结果(Adressa-10weeks) Table 5 Experimental results of different GNN layers (Adressa-10weeks) % |
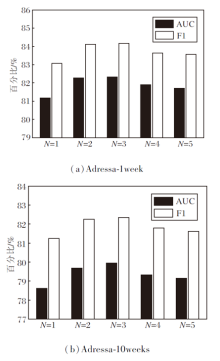
本文还考虑不同Transformer层数N对指标值的影响, 结果如图5所示.
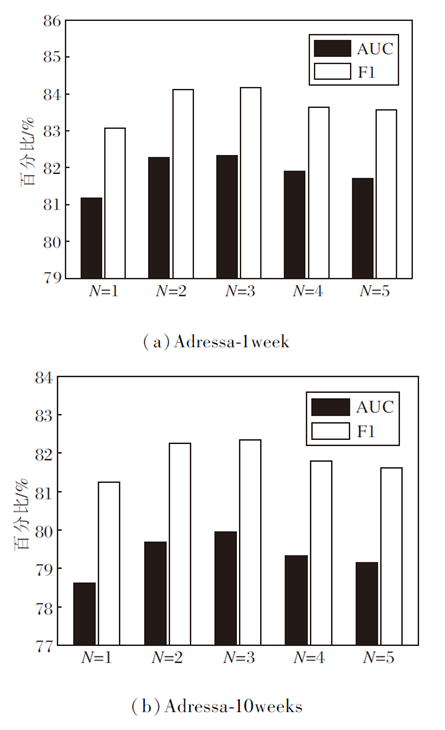 | 图5 不同Transformer层数的实验结果Fig.5 Experimental results of different Transformer layers |
由图5可看出, 当层数N=3时效果最优, 并且随着层数的增加模型效果逐渐下降.这是因为层数过多时, 可能引入噪声数据, 影响模型性能.因此本文将Transformer层数设为3.
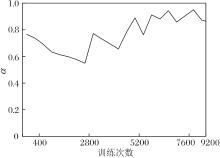
学习参数α 不同时的变化曲线如图6所示.随着训练次数的不断增加, α 逐渐趋于稳定, 稳定在[0.8, 0.95]区间, 当在验证集上效果最优时, α =0.85.这说明用户长期兴趣和短期兴趣在用户兴趣建模中具有重要作用, 其中用户长期兴趣对用户兴趣的影响较大, 占主要作用, 用户短期兴趣在用户兴趣中起到补充作用.
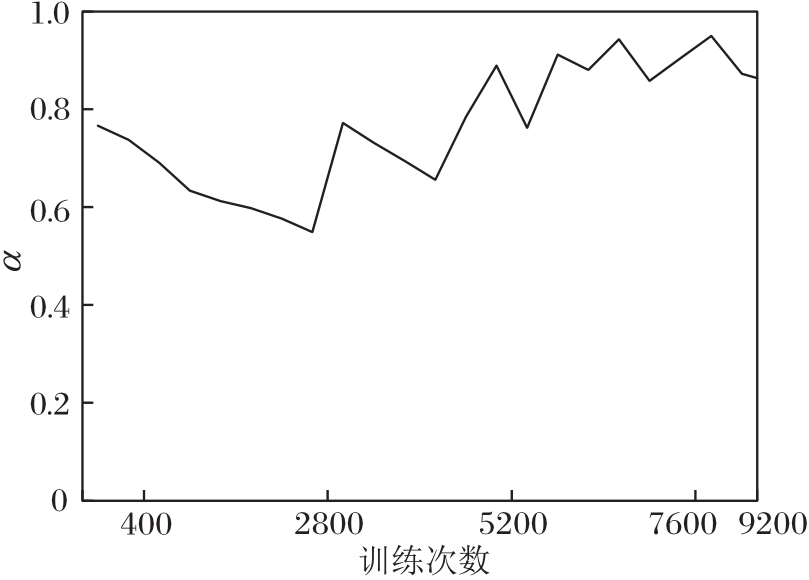 | 图6 可学习参数α 的变化曲线Fig.6 Variation curve of learnable parameter α |
本文提出基于Transformer与异质图神经网络的新闻推荐模型(NR-TrHGN).首先, 采用多通道卷积网络得到新闻的特征表示, 采用Transformer捕获用户近期阅读新闻之间的内在联系, 得到用户短期兴趣表示.然后, 建立用户、新闻、主题之间的异质图, 采用异质图神经网络得到用户、新闻和主题之间的高阶关系, 通过在图上传播嵌入学习用户和新闻表示.最后, 分别使用两个评分表示候选新闻与用户长期兴趣和短期兴趣之间的匹配程度, 通过一个可学习的参数将两个评分线性组合, 得到一个统一评分.在真实数据集上的对比实验显示, 本文模型在两个评价指标上均有提升, 表明本文模型的有效性.今后将考虑引入知识图谱, 加强对用户阅读新闻信息的理解, 获取更全面的新闻用户表示和用户兴趣表示, 提高新闻推荐的准确性.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|