

{kind=link}
{kind=link}
{kind=link}
基于MPNet预训练和多头注意力特征融合的引文意图分类方法
[祁瑞华1, 2  , 邵震
, 邵震1, 2 , 关菁华1 , 郭旭1 ]
, 邵震|
|


 祁瑞华,博士,教授,主要研究方向为自然语言处理、文本挖掘.E-mail:rhqi@dlufl.edu.cn.
祁瑞华,博士,教授,主要研究方向为自然语言处理、文本挖掘.E-mail:rhqi@dlufl.edu.cn.
作者简介:  邵震,硕士研究生,主要研究方向为自然语言处理.E-mail:jkl4131@126.com.
邵震,硕士研究生,主要研究方向为自然语言处理.E-mail:jkl4131@126.com.
 关菁华,博士,副教授,主要研究方向为自然语言处理.E-mail:guanjinghua@dlufl.edu.cn.
关菁华,博士,副教授,主要研究方向为自然语言处理.E-mail:guanjinghua@dlufl.edu.cn.
 郭旭,硕士,讲师,主要研究方向为自然语言处理.E-mail:guoxu@dlufl.edu.cn.
郭旭,硕士,讲师,主要研究方向为自然语言处理.E-mail:guoxu@dlufl.edu.cn.
引文意图自动分类是文献计量领域的重要问题,现有的引文意图分类模型存在对文本特征抽取能力有限、无法融合引文上下文特征和引文外部特征的问题.因此,文中提出基于MPNet预训练和多头注意力特征融合的引文意图分类方法.引入位置补偿结构,改善掩码语言模型与排列语言模型存在的缺陷.联合引文的语法词频特征与引文结构特征,提出适用于引文意图分类任务的特征抽取方法.再引入多头注意力机制进行特征融合,提升分类效果.在ACL-ARC数据集上的实验表明,文中方法在引文意图分类任务上性能较优,同时还具有在不平衡数据上的鲁棒性.
Author:SHAO Zhen, master student. His research interests include natural language proce-ssing.
GUAN Jinghua, Ph.D., associate professor. Her research interests include natural language processing.
GUO Xu, master, lecturer. His research interests include natural language proce-ssing.
Automatic citation intent classification is one of hot issues in the field of bibliometrics.The existing citation intention classification models engender the limitations in extracting textual features and fusing citation contextual features and citation external features. Therefore, a citation intent classification method based on MPNet pretraining and multi-head attention feature fusion is proposed. The position compensation structure is introduced to improve the masked language model and permuted Language model.The syntactic word-frequency features and structure features of citations are combined. A feature extraction method is proposed for citation intent classification task. The multi-head attention mechanism is introduced for feature fusion to improve the classification accuracy. The experimental results on ACL-ARC datasets demonstrate that the proposed method achieves better performance in citation intent classification task with robustness on the unbalanced data.
引用在科学成果论述中发挥着重要作用, 引用分析有助于学术文献的理解和研究人员的评价.学术文献中出现引用文献时, 引文意图不尽相同.引文意图分类的目标是分析学术文献中引证参考文献的引文意图.引文意图分类研究有助于更精准地完成引文重要性分析等后续文献计量研究任务, 因此成为文献计量研究领域的热点问题.
早期的引文意图研究主要采用人工定性分析方法[1].人工定性分析方法的主要问题是引文描述过于冗长, 无法自动处理大规模数据, 此外分析者的主观态度偏差容易导致错误的分类结果[2].为此, 亟需开展引文意图自动分类的研究.
引文意图的分类体系是引文意图分析研究的理论基础, 科学合理的引文意图分类体系有助于规范化分类标准并为数据集标注等工作提供良好的研究基础.Garfield[3]提出引文意图可分为“ 向研究先驱致敬” 、“ 提出相关研究者功绩” 、“ 指出方法论工具” 等15类.Moravcsik等[4]将引文的意图分类简化为5类, 包括“ 概念性与实操性” 、“ 结构化与非结构化” 、“ 发展与并行” 、“ 认同与否定” 和“ 无关的冗余引用” .Chang[5]研究自然科学与社会科学领域的期刊引用影响力, 并归纳“ 提供背景信息” 、“ 比较” 、“ 引用定义” 等11种引文意图.Pride等[6]提出ACT(Aca-demic Citation Typing), 将引文意图分为“ 研究背景” 、“ 使用方法论或工具” 、“ 对照对比” 、“ 研究动机来源” 、“ 拓展方法” 和“ 未来展望” 6类.
传统的引文意图自动分类主要分为基于特征工程的引文意图分类方法和基于语言模型的引文意图分类方法.基于特征工程的引文意图分类方法的主要思路是通过分析引文外部特征构建引文文本的特征表示, 再采用分类算法对这些外部特征表示进行引文意图分类[7].Teufel等[8, 9, 10]结合词性序列、位置和时态特征构建特征模型, 提出专用于引文分类的特征体系, 效果较优.Xu等[11]提出基于引文句子结构特征的特征表示方法.Nakagawa等[12]构建基于条件随机场的监督学习模型, 用于识别日文文献中的引文意图.Meyers等[13]将篇章转换成树形模型, 通过词性分析判断引文对比意图与证明意图之间的关联.Abdullatif等[14]利用语义标签表示引文文本, 提出基于规则的引文意图分类方法.Valenzuela等[15]扩展作者、摘要等引文意图相关特征, 采用支持向量机(Support Vector Machine, SVM)和随机森林(Ran-dom Forest)算法, 实现引文意图自动分类.Hassan等[16]进一步将文献[15]中提出的引文特征扩展到14种, 采用LSTM(Long Short-Term Memory)进行引文意图分类.Jurgens等[7]融合引文的模式特征、主题特征和语法特征等文本特征, 将文献意图分为背景、动机、使用、扩展、对比、展望6类, 利用随机森林算法进行分类.
基于语言模型的引文意图分类可分为基于词向量语言模型的方法[17]和基于预训练语言模型的方法[18].Yousif等[19]提出MTL(Multitask Learning Mo-del ), 采用词向量表示引文上下文, 通过多任务学习引文情感分类与引文意图分类两个子任务改善引文意图分类效果.Roman等[17]通过词向量表示引文文本, 聚类后再对各类簇进行引文意图标注.Cohan等[18]提出结合GloVe(Global Vector)与ELMo(Em-beddings from Language Models)的引文文本表示方法, 将引文意图分类作为主任务, 引文重要性标注任务和篇章子标题标注任务作为辅助任务, 通过损失函数共享的迁移学习方法完成引文意图分类任务.
近年来, 随着BERT(Bidirectional Encoder Representations from Transformer)[20]等预训练语言模型的出现, 引文意图分类研究取得一系列新的进展.Beltagy等[21]使用科技文献大数据训练得到用于科技文献文本表示的SciBERT(BERT of Scientific Text)语言模型.Zheng等[22]提出基于文献全文的掩码语言模型(Masked Language Model, MLM)预训练方法, 进行引文意图的分析.由于MLM掩码语言模型独立预测每个掩码, 存在预训练与微调不一致的特性, 可表示复杂的引文文本损失词之间的概率关联信息.Mercier等[23]提出基于XLNet(Extra Long Transformer Network)预训练模型的引文意图分类方法, 通过XLNet的优化排列语言模型(Permuted Language Model, PLM)[24]提升引文意图分类效果, 但由于PLM排列语言模型中每个符号(Token)的预测只能在排列后的序列中进行, 无法在自回归中获取完整句子的位置信息, 在处理引文文本时存在预训练与微调不一致的问题, 无法保留全部引文特征信息.
因此, 本文提出基于MPNet预训练和多头注意力特征融合的引文意图分类方法(Citation Intent Classification Method Based on MPNet Pretraining and Multi-head Attention Feature Fusion, MPMAF).通过语法知识特征表示和预训练语言模型改善对引文上下文语义信息的学习, 通过MPNet(Masked and Permuted Pre-training for Language Understanding)[25]的预测机制, 弥补现有预训练语言模型表示引文文本时的序列位置和词间关联损失, 通过多头注意力机制改善引文外部属性特征表示.
本文提出基于MPNet预训练和多头注意力特征融合的引文意图分类方法(MPMAF).先通过MP-Net预训练语言模型的预测机制弥补现有模型表示序列位置信息和词间概率关联上的不足.在此基础上, 通过多头注意力机制融合引文外部属性特征, 构建引文意图分类模型, 在学习过程中融合引文的文本表示与外部特征, 将引文的语法知识进行特征表示后作为外部特征, 分别对文本表示及外部特征两个向量空间进行模型训练后再融合, 改善引文外部属性特征表示.
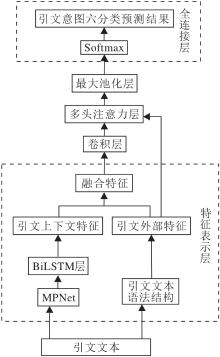
本文的基于MPNet预训练和多头注意力特征融合的引文意图分类方法(MPMAF)结构如图1所示.
 | 图1 MPMAF结构图Fig.1 Structure of MPMAF |
MPMAF的引文特征表示分为引文上下文特征与引文外部特征两个模块, 通过多头注意力机制融合这两部分的特征.其中, 通过MPNet预训练语言模型训练得到引文上下文特征, 由引文文本的语法结构获取引文外部特征.
在输入层完成引文文本的预处理和标注, 输入层处理的结果作为词嵌入层的输入.在特征表示层, 首先生成两部分特征:引文上下文特征和引文外部特征.引文上下文特征采用MPNet预训练模型生成的引文文本词嵌入向量表示, 并通过BiLSTM(Bi-di-rectional LSTM)提取引文上下文特征T'.
从输入层的引文文本抽取外部语法词频特征和引文结构特征构成本文的引文外部特征F.引文外部特征五元组表示如下:
$featureij={Onehotj(posj, pos_list), patternj, tfidfij, section_namej, offsetsj}, $(1)
其中, i表示句子标号, j表示句子中的单词编号.式(1)前三项为语法词频特征, 后两项为引文结构特征.
第1项Onehotj(posj, pos_list)是以One-hot形式表示的词性特征, pos_list为全部词性列表.
第2项patternj表示句子中是否包含如下6种句法结构的one-hot编码:
1)引文+动词[过去式/现在式/第三人称/过去分词].
2)动词[过去式/动名词/第三人称]+动词[动名词/过去分词].
3)动词[所有形式]+(副词[比较级/最高级])+动词[过去分词].
4)情态词+(副词[比较级/最高级])+动词+(副词[比较级/最高级])+过去分词.
5)(副词[比较级/最高级])+人称代词+(副词[比较级/最高级])+动词[所有形式].
6)动名词+(专有名词+并列连词+专有名词).
第3项tfidfij表示单词j在句子i中的Tf-idf值:
Wtf-idf=ln(1+ft, d)· ln(
其中, d表示每条样本, ft, d表示单词t在样本d中出现的频率, N表示所有样本数, nt表示出现单词t的样本数.
第4项section_namej表示引文在全文中的位置, 共有6种位置, 分别是experiments, method, related work, introduction, conclusion, others.
第5项引用偏移量offsetsj, 表示引用标识在整个引文上下文中起始的相对位置.
然后, 在特征表示层中拼接引文上下文特征和引文外部特征, 得到融合特征表示向量
C=Concat(F, T'),
并将C送入卷积层, 进一步从融合特征中提取引文意图分类的关键信息.
在多头注意力层, 为了计算引文文本特征之间的关联和权重信息, 采用多头注意力机制, 分别对引文融合特征C和引文外部特征F进行多头自注意力计算:
mht=MultiHeadAttention(num_heads=4, key_dim=2)(F, T').
在引文意图分类预测层, 将多头注意力层的输出结果mht输入最大池化层进行池化操作, 锐化特征并压缩输出维度.最后将池化层的输出结果输入全连接层, 通过激活函数计算得到引文意图六分类预测结果, 即预测为背景、对比、扩展、展望、动机或使用中的一类, 损失函数采用交叉熵损失函数.
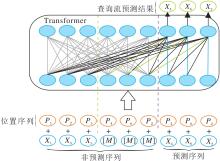
本文采用的MPNet预训练语言模型[25]是由Microsoft公司基于XLNet自回归模型结构增加位置补偿(Position Compensation)机制构建而成, 分别处理预测序列和非预测序列, 并为预测序列添加位置信息.MPNet预训练语言模型的结构如图2所示.
设当前输入序列为
X=(X1, X2, X3, X4, X5, X6),
MPNet预训练语言模型首先对序列进行随机排序, 得到随机排序的序列, 如
X=(X1, X3, X5, X4, X6, X2).
设非预测序列的长度为3, 则非预测序列和预测序列之间的分隔如图2所示.然后, 基于MLM的思路将预测序列进行掩码处理, 预测序列与非预测序列分别表示为
Xpredict=(X4, X6, X2), Xnon-predict=(X1, X3, X5, [M], [M], [M]),
其中[M]为掩码.MPNet预训练语言模型对所有的token加入位置信息, 构建位置序列
P=(P1, P3, P5, P4, P6, P2),
然后将合并后的位置序列和输入序列送入Transfor-mer结构中.
在图2的Transformer结构中, 左边的灰线表示非预测序列之间的双向自注意力掩码, 右边的蓝线表示双向注意力机制中的内容流注意力掩码, 绿线表示双向注意力机制中的查询流注意力掩码, 黑线表示这部分既要作为内容流注意力掩码, 又要作为查询流注意力掩码.MPNet预训练语言模型的位置补偿机制可保证每个token在预测时都可获取完整序列的信息, 最终的预测结果由查询流进行预测.
注意力机制能增强特征学习过程中底层单元的权重表示, 清晰阐明引文意图分类任务中每句话或每个单词在分类预测中的权重.在注意力机制中, 首先输入映射为Q、K、V的3个特征, Q表示单词查询向量, K表示接查询的关键信息, V表示每个单词的词嵌入表示内容向量.然后点乘Q和K生成attention map, 再将attention map与V点乘得到注意力加权特征:
Attention(Q, K, V)=softmax(
其中dk表示K的维度.
多头注意力机制是对多个单头注意力机制的集成计算, 在提高准确率的同时通过并行计算降低多特征学习任务的时间复杂度.多头注意力计算公式如下:
MultiHead(Q, K, V)=Concat(head1, head2)WO,
其中WO表示多个向量空间中单词的向量表示.本文根据引文上下文和引文外部特征融合任务的特点设定多头注意力的头数head=2, WO的维度为2dv× dmodel.
本文实验选用ACL-ARC数据集[6]作为实验数据集, 数据来源为ACL会议论文集ARC(ACL Antho-
logy Reference Corpus), 共包含186篇文献, 文献的研究领域为计算语言学, 总计1 941条引文实例.ACT数据集由论文写作者对其投稿中的引文意图进行标注, 标注结果具有权威性.ACL-ARC数据集标注6种引文意图, 数据集信息如表1所示.
| 表1 ACL-ARC数据集引文实例分布 Table 1 Citation instance distribution of ACL-ARC dataset |
实验中数据集的划分方案为Cohan等[18]在NAACL2019中提出的方法, 选取85%的数据作为训练数据, 剩余数据均分为验证集与测试集.由于Beltagy等[21]在SciBERT的研究中未提及ACL-ARC数据集的数据划分, 且上述文献都将ACL-ARC数据集来源及之前的SOTA结果指向Jurgens等[7]于ACL2018提出的工作, 所以本文将Cohan等公开的预处理数据集用于SciBERT的对照实验.由于数据规模有限, 参照文献[18]实验中划分85%训练集的划分方法.为了避免结果的偶然性, 进行20次重复实验, 取平均值作为最终结果[20].评价指标采用精度(Precision, P)、召回率(Recall, R)、F1值和F1值的标准差.
本文采用MPNet作为预训练语言模型表示引文文本上下文, 文本表示层的输出维度为768维.模型超参数搜索采用人工搜索的方式, 通过实验观察和调整具有较大影响力的超参数.在本文实验中, BiLSTM层输出神经元个数设置为128, 卷积层的输出神经元个数设置为128, 卷积核大小为1× 3, 为了尽可能地降低非必要特征带来的干扰, 卷积层填充模式采用保持卷积核和原矩阵最大重叠的方法.失活层比率选择0.2, 激活函数采用softmax函数, 损失函数采用稀疏类别交叉熵(Sparse Categorical Cross Entropy), 优化器采用Adam(Adaptive Moment Esti-mation), 学习率设置0.001, 实验的训练批次大小设置为32, 时期设为15.
对照实验方法选取近年相关文献在ACL-ARC数据集上的引文意图分类研究结果, 包括:Jurgens等[7]在ACL2018中提出的基于随机森林的分类方法(简记为Random Forest)、Cohan等[18]在NAACL2019提出的基于ELMo多任务辅助的分类方法(简记为Structural-Scaffolds)、Beltagy等[21]于EMNLP2019提出的SciBERT及其微调方法SciBERT Finetune、BERT、MPNet预训练模型的多个微调方法.
各方法的指标值对比如表2所示, 表中黑体数字表示最优值.由表可知, 相比利用Random Forest的机器学习方法, 使用预训练语言模型能大幅提升所有维度上的指标值, Random Forest作为更早的机器学习方法中的最佳结果, 说明深度学习在引文意图分类任务中效果优于传统的机器学习方法.同时, 对于MPNet的BiLSTM与MPMAF两种微调方法(MPNet-BiLSTM, MPNet-MPMAF), 相比单层BiL-STM, MPMAF能大幅提升F1值, 这也说明将引文属性特征融入分类模型之中是有效的, 如果仅依赖预训练语言模型进行特征表示, 会忽略这些引文属性特征.这也证实MPMAF能提升引文意图分类效果.训练结果的F1标准差也下降2.05%, 再次证实MPMAF稳定性强于BiLSTM.
| 表2 各方法的指标值对比 Table 2 Index comparison of different methods % |
分别对 BERT、SciBERT、MPNet三种语言训练模型进行微调, 在BERT与SciBERT的微调中, 通过观察F1标准差可看出, MPNet的训练导致的方差较大.基于MPNet的方法比现有SOTA结果的F1值提高1.82%, 这也验证MPNet能更准确地对引文文本进行特征表示, 提升引文意图分类的效果.由于SciBERT的官方微调方法未提供精度与召回率, 所以与Structural-Scaffolds进行精度与召回率的对比发现, MPMAF的精度下降1.48%, 召回率提升7.57%, 体现Structural-Scaffolds使用的迁移学习方法在判断精度上有一定优势, 但使用的ELMo预训练模型对特征的表示不足, 容易出现分类结果向数据量较大的分类偏移, 而引文意图分类数据具有不平衡的特点, 所以MPMAF更适用于引文意图分类任务.
各方法在ACL-ARC数据集各类别上的引文意图分类指标值对比如表3所示, 表中黑体数字表示最优值.由表可看出, 除了扩展、使用类别外, 本文方法在F1值上都达到最高值, 这可进一步证实本文方法对克服数据不平衡问题具有较好效果.并且从普遍性上看, 使用MPNet作为预训练模型时的召回率更高, 可避免将数量少的类别误判成数量多的类别, 这也能证实MPNet对特征的描述更丰富, 具有在不平衡数据上的鲁棒性.
| 表3 各方法在各类别上的指标值对比 Table 3 Index comparison of methods on different classes % |
MPMAF在MPNet和SciBERT预训练语言模型上微调之后, 产生的引文意图分类结果的混淆矩阵如图3所示.由图可知, SciBERT对背景类别的预测结果最多, 背景比例占到测试集的51%, 这也说明相比MPNet, 基于MLM的SciBERT更容易受到数据量大类别的影响.
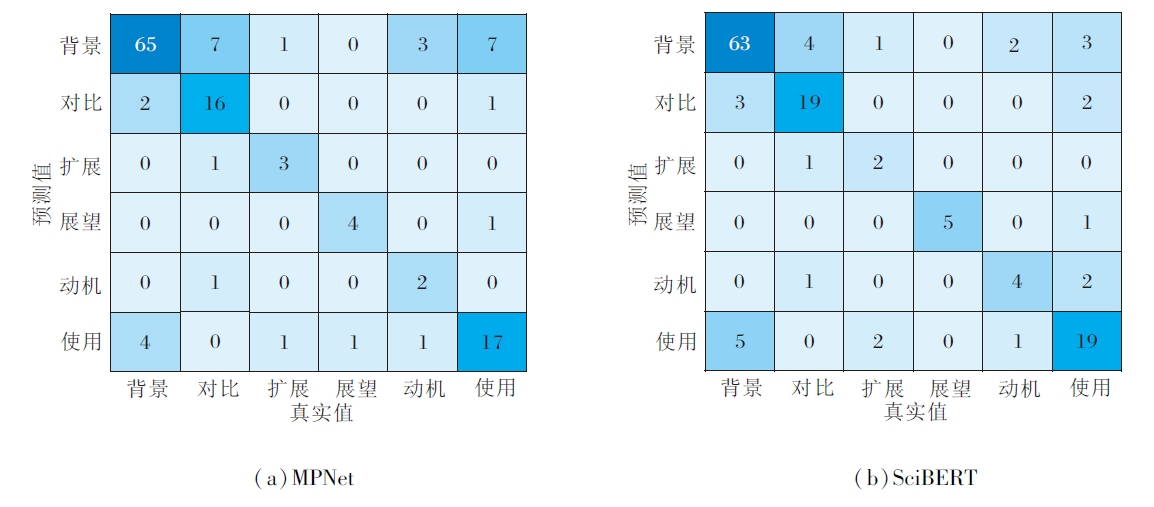 | 图3 不同模型微调后的引文意图分类结果混淆矩阵Fig.3 Confusion matrix of citation intent classification fine-tuned by different models |
本文认为这是由于MLM对特征的表示不够全面导致的, 有部分特征由于掩码的存在并未被发现, 从而导致将大量数据分为同一类别, 而MPNet预训练语言模型较好地解决这一问题.
在MPMAF中分别去除BiLSTM层、卷积层、多头注意力层后的指标值对比如表4所示, 表中黑体数字表示最优值.
| 表4 模型结构消融实验结果 Table 4 Results of ablation experiment of model structure % |
由表4可看出, 在缺少BiLSTM层或卷积层时精度出现上升, 召回率出现大幅下降.本文认为这是由于外部特征的融合带来一定的噪音, 在加入多头注意力机制后在精度、召回率上都有一定提升, 这也验证多头注意力在模型训练中的作用.
去除不同结构后本文方法在不同类别上的指标值对比如表5所示, 表中黑体数字表示最优值.去除BiLSTM层或卷积层后, 效果更优, 这进一步验证特征抽取预训练模型的输出的必要性.
| 表5 模型结构消融实验中各类别的指标值对比 Table 5 Index comparison of different classes in ablation experiment of model structure % |
本文认为当对于预训练模型的文本表示不进行进一步特征编码的情况下, 模型更容易受到样本较多的类的影响.
下面对比MPMAF使用引文结构特征和语法词频特征时的性能, 具体指标值如表6所示, 表中黑体数字表示最优值.
| 表6 MPMAF结合外部特征后的消融实验结果 Table 6 Results of ablation experiment of MPMAF with external features % |
由表6可看出, 当MPMAF结合语法词频特征和引文结构特征时, F1值和召回率最高, 精度也处于较高水平.当减少引文结构特征或语法词频特征时, 引文意图分类结果的所有指标值都有不同程度的下降, 表明这两类特征对引文意图分类任务的有效性.当两类特征完全被消融时, 引文意图分类结果的F1值和召回率降至最低, 呈现出高精度低召回率的特点, 说明此时的实验结果受到不平衡数据集中大样本类别的影响, 对于样本的特征捕捉能力较差.
MPMAF增减外部特征后的各类别消融实验结果如表7所示, 表中黑体数字表示最优值.由表可看出, 在背景、对比、展望、动机类别上, MPMAF结合2种外部特征后均取得最高的F1值, 综合性能最优.而在扩展、使用类别上去掉引文结构特征仅保留语法词频特征时, 综合性能最优, 原因是在引用文献的动机为使用方法论、工具或拓展方法时, 引文位置和偏移量并不具备显著的分布特征, 因此当实验中加入引文结构特征时引入噪音.
| 表7 MPMAF结合外部特征后各类别的指标值对比 Table 7 Index comparison of MPMAF combined with external features on different classes % |
本文提出基于MPNet预训练和多头注意力特征融合的引文意图分类方法, 将预训练模型合理地利用在引文意图分类任务中.相比其它预训练语言模型及其微调方法, 都获得效果上的提升.在ACL-ARC数据集上F1值比SOTA结果提升1.82%.在ACL-ARC数据集上的实验同时还证实本文方法在解决引文意图标注数据的不平衡问题上具有较好效果.今后将进一步详细探讨对不同引文动机类别的引文特征构成, 并在多领域引文数据集上进一步验证本文方法.此外, 还将引入更丰富的引文属性特征, 进一步改善引文特征表示效果.
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|