

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
稠密向量实体检索模型的二值化提速压缩
[王苑铮1, 2  , 范意兴
, 范意兴1, 2 , 陈薇1, 2 , 张儒清1, 2 , 郭嘉丰1, 2 ]
, 范意兴, 陈薇, 张儒清, 郭嘉丰]
|
|



作者简介:

王苑铮,博士研究生,主要研究方向为信息检索、自然语言处理.E-mail:wangyuanzheng19z@ict.ac.cn.

陈 薇,博士,研究员,主要研究方向为机器学习.E-mail:chenwei2022@ict.ac.cn.

张儒清,博士,助理研究员,主要研究方向为自然语言处理.E-mail:zhangruqing@ict.ac.cn.

郭嘉丰,博士,研究员,主要研究方向为数据挖掘、信息检索.E-mail:guojiafeng@ict.ac.cn.
在实体检索任务中,为了从大规模实体库中高效筛选与查询相关的候选实体,可使用稠密向量检索模型.然而在现有的稠密向量检索模型中,由于实体向量维度较高,导致实时计算效率较低、存储空间较大.文中通过实验发现这些实体向量存在大量的冗余信息:一方面,绝大多数实体向量分布在互不相同的象限里;另一方面,语义相近的实体所在的象限也更近.因此,文中提出二值化的实体检索方法,用于压缩实体向量,加速相似度计算.具体而言,方法利用符号函数(sign), 二值化压缩高维稠密的浮点向量,并通过汉明距离加快检索.从理论上分析文中方法保证检索性能的原因.通过定性、定量的分析实验验证理论的正确性,并给出基于随机升维旋转的二值检索性能改善方法.
About Author:
WANG Yuanzheng, Ph.D. candidate. His research interests include information retrieval and natural language processing.
CHEN Wei, Ph.D., professor. Her research interests include machine learning.
ZHANG Ruqing, Ph.D., assistant profe-ssor. Her research interests include natural language processing.
GUO Jiafeng, Ph.D., professor. His research interests include data mining and information retrieval.
In entity retrieval tasks, dense vector entity retrieval models are utilized to efficiently filter candidate entities related to a query from a large-scale entity base.However, the existing dense vector retrieval models engender low real-time computation efficiency and large required storage space due to the high dimension of entity vectors. In this paper,it is found that these entity vectors contain a large amount of redundant information through experiments. Most entity vectors are distributed in non-overlapping quadrants and quadrants containing entities with similar semantics are also closer to each other.Thus, a binary entity retrieval method is proposed to compress entity vectors and accelerate similarity calculations.Specifically, the sign function is employed to binary-compress high-dimensional dense floating-point vectors, and Hamming distance is exploited to speed up the retrieval.The reason that the proposed method can guarantee the retrieval performance is theoretically analyzed.The correctness of the theory is verified through qualitative and quantitative analysis experiments, and a method for improving binary retrieval performance based on random dimension increase and rotation is provided.
实体检索是为了从大规模的实体库中找到与查询相关的实体[1], 是很多自然语言处理任务的基础, 如文本数据分析[2]、事实抽取与验证[3]、问答系统[4, 5, 6, 7]、信息检索[8, 9, 10, 11]、推荐系统[12]等.不同于常规的文档检索任务, 实体检索任务的查询是一个带上下文的实体提及(Entity Mention), 而实体库除了可以是无结构的实体描述文档, 也可以是结构化、半结构化的知识图谱, 并且查询与实体间的“ 相关性” 通常是明确的, 即二者是否指代同一实体, 而不是模糊的语义相似性, 因此一个查询通常只有一个目标实体.当实体库规模很大时, 为了能正确、高效检索目标实体, 通常需要采用多阶段检索, 其中包含召回阶段和至少一个重排序阶段.召回阶段是从完整实体库中筛选少数候选实体, 要求高召回率和高效率.
近年来, 基于稠密向量表示的实体检索模型被广泛应用于召回阶段.在稠密向量检索模型中, 查询与实体首先被独立编码为稠密语义向量, 之后在稠密向量空间中通过简单的相似度函数(如点乘、余弦、L2), 利用K最近邻(K Nearest Neighbor, KNN)或近似近邻(Approximate Nearest Neighbor, ANN)召回与查询向量最接近的候选实体.稠密向量检索模型优点如下.1)稠密向量可有效建模查询与实体的语义相似性, 召回率高于传统精确匹配模型; 2)模型中的实体向量可离线计算好后再使用向量索引, 可提高在线检索的效率.
为了有效建模查询与文档的语义, 当前的稠密向量通常是高维的, 导致巨大的计算开销, 消耗大量存储空间.一方面, 稠密向量通常是高维的浮点数向量, 导致计算向量相似度时, 浮点运算开销很大, 往往需要昂贵的GPU等设备; 另一方面, 存储高维稠密的实体向量需要大量空间.例如:对于英文维基的500万实体, 如果使用1 024维32位浮点向量存储, 需要23 GB的空间, 难以部署在存储受限的小型设备上.因此, 压缩高维稠密向量、加快向量相似度计算, 是稠密向量检索亟需解决的问题.
为了解决压缩高维稠密向量、加快向量相似度计算的问题, 本文分析3个当前较优的稠密向量检索模型— — BLINK[13]、LUKE(Language Understanding with Knowledge-Based Embeddings)[14]、MGAD(Multi-granularity Alignments Based Distillation)[15]的实体向量, 发现高维空间中的实体向量分布具有“ 绝对稀疏、相对稠密” 的特点.绝对稀疏体现在每个象限几乎不超过一个实体, 说明高维向量存在信息冗余.相对稠密体现在相似实体分布在更近的象限里, 即向量各维度的正负号更相似, 说明象限正负号是一种精炼、可体现相似度的语义特征.
基于上述特点, 本文提出二值化的实体检索方法(简称二值检索), 实现压缩与加速.具体而言, 先利用符号函数(sign)提取向量各维度的正负号, 代替原本的高维浮点数向量, 实现二值化压缩.再使用汉明距离, 检索最近邻的二值化实体向量, 使用布尔运算代替浮点运算, 实现相似度计算的加速.
对二值检索的有效性进行理论分析和实验验证.在理论上, 当满足一定前提时, 二值检索等价于乘积量化(Product Quantization, PQ)检索[16], 此时相比浮点值模型, 召回的候选实体列表大概率保序, 可保证较优的检索性能.首先在实体检索的AIDA数据集[17]上进行实验, 以二值化后效果最优的MGAD为例, 发现召回率损失较少, 可大幅压缩实体向量的存储空间, 加速向量相似度计算.进一步, 对实体向量的定性、定量分析性实验验证方法和理论的正确性.此外, 若模型不满足理论前提导致检索性能损失较大, 可通过随机升维旋转改善性能.
为了平衡性能与效率, 实体检索通常分为召回和重排序两个阶段.在召回阶段, 传统方法是基于BM25[13]或实体别名表[18]的启发式检索方法.然而此类方法依赖于实体名与查询的精确匹配, 当无法精确匹配时, 召回率较低.近年来, 神经网络被应用于实体检索任务, 取得比启发式方法更优的检索性能.在召回阶段, 常用基于稠密向量的检索模型.此类模型将查询、实体独立编码为稠密向量, 再通过简单的向量相似度函数(如点积、L2), 使用精确K近邻或近似K近邻算法召回K个最相似的实体.
基于稠密向量的检索模型按实体向量的表示方式不同, 大致可分为3类:基于描述的方法、基于上下文的方法、混合式方法.基于描述的方法以BLINK为代表, 使用BERT(Bidirectional Encoder Representa-tions from Transformers)[19]将实体描述文本直接编码为向量.基于上下文的方法以LUKE为代表, 从海量上下文中利用实体与其它单词、实体的共现关系, 抽取实体的分布语义向量.混合式方法以MGAD为代表, 利用分布语义模型LUKE蒸馏实体描述编码器, 得到的实体向量同时具备描述和上下文的语义.
BLINK、LUKE、MGAD为当前性能较优的三个稠密向量实体检索方法, 分别适合在实体描述丰富、实体上下文丰富、实体描述和实体上下文都丰富的场景下训练实体向量.相比传统方法, 稠密向量模型的语义匹配能力更强, 召回率更高, 但缺点是时间复杂度和空间复杂度也更高.
二值检索是使用0、1或± 1的离散二值向量表示查询与实体, 然后使用汉明相似度检索的方法, 在图像检索和文本检索中都有应用.按照训练方式划分, 二值检索可分为两类:联合优化方法和后处理方法.在联合优化方法中, 二值化是与向量的学习过程一起训练的, 以文本检索任务的BPR(Binary Passage Retriever)[20]为代表.BPR在训练过程中, 使用可微的tanh函数近似sign函数, 训练接近二值向量的浮点值向量, 在推断时直接使用sign函数二值化.后处理方法直接使用其它模型训练好的浮点值向量, 对浮点向量进行一些简单变换后再二值化, 以图像检索任务的HE-WGC(Hamming Embedding and Weak Geometric Consistency)[21]和ITQ(Iterative Quantiza-tion)[22]为代表.在使用sign函数二值化前, HE-WGC对稠密向量进行随机旋转, ITQ通过迭代计算将稠密向量旋转至量化误差最小的方向上, 但是两者并未给出理论上的解释.在这两类二值检索方法中, 联合优化方法的检索效果更优, 但训练代价高昂.后处理方法的检索效果略差于联合优化方法, 但不需要重新训练模型, 可直接在训练好的模型上应用, 泛用性更好.
本节首先形式化介绍基于稠密向量的召回阶段实体检索, 再介绍针对稠密向量的二值化实体检索.在实体召回阶段, 给定一个带上下文的实体提及作为查询q, 目的是从一个大型实体库E={e1, e2, …, eN }中, 召回K个候选实体子集{e1, e2, …, eK }, K≪N.
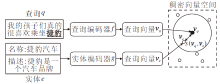
基于稠密向量的实体检索模型结构如图1所示, 首先使用两个独立的编码器将查询、实体分别编码为稠密向量, 再召回与查询向量最相似的K个候选实体.
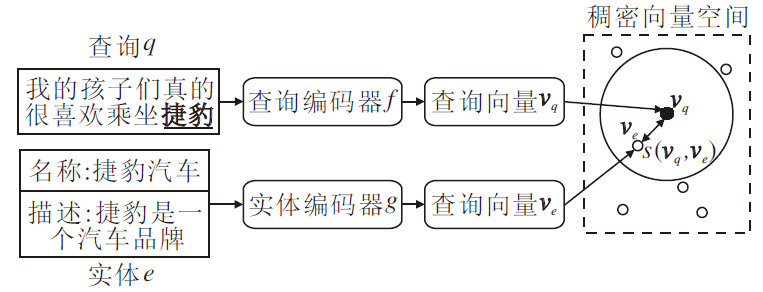 | 图1 基于稠密向量的实体检索模型结构图Fig.1 Structure of entity retrieval model based on dense vector |
对于查询q和实体e, 对应的稠密向量分别为:
vq=f(q), ve=g(e),
其中f、g表示两个互相独立的编码器.以BLINK为例, f、g都采用BERT, 将文本编码为向量.关于查询、实体编码器的更多细节, 请参考BLINK、LUKE、MGAD的相关文献[13, 14, 15].
召回过程是利用KNN召回与查询向量vq相似度最大或距离最小的K个候选实体.记s(· , · )为计算2个向量相似度的函数, KNN召回过程形式化表述为
KNN(vq)=arg
常用的相似度函数s(· , · )有点乘相似度、余弦相似度、L2相似度(L2距离取反)等.本文与BLINK、LUKE、MGAD一样, 采用点乘相似度.
稠密向量检索模型可利用神经网络建模vq、ve的语义相似性, 因此召回率超过传统的精确匹配模型.但是, 由于vq、ve通常都是高维浮点值向量, 且ve需要预先计算并存储, 当实体数量很多时, 大规模浮点向量的存储及相似度计算的开销很大.为了解决该问题, 本文提出二值化的实体检索方法.
二值化的实体检索方法(简称二值检索)简化使用浮点值的稠密向量实体检索(简称浮点值检索), 可压缩向量存储空间, 加快相似度计算.二值检索示意图如图2所示.
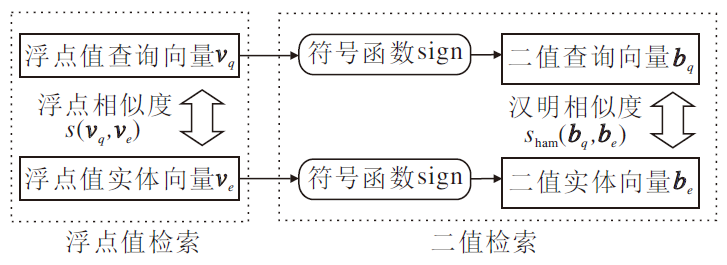 | 图2 二值检索示意图Fig.2 Sketch map of binary retrieval |
对于n维浮点值向量vq∈ Rn, ve∈ Rn, 首先利用符号函数
sign(x)=
获取每个浮点值的正负号, 得到n维二值向量
bq∈ {1, -1}n, be∈ {1, -1}n.
假设原本每个浮点值需要使用m bit表示(m通常为32或64), 而± 1使用1 bit即可表示, 因此存储n维浮点向量需要n× m bit, 而二值向量只需要n bit, 二值化可将存储压缩至1/m.
之后可利用汉明相似度sHam计算二值向量bq、be的相似度.定义汉明距离H(b1, b2)为b1∈ {1, -1}n, b2∈ {1, -1}n中不相同的bit的数量, 则二值向量的汉明相似度sHam、L2相似度sL2、点乘相似度sdot、余弦相似度scos四者都可从汉明距离H计算得到, 即
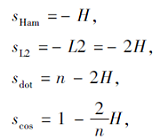 |
容易看出, 4个相似度是等价的, 因此实践中使用汉明相似度即可.对于现代CPU, 汉明距离H可仅用两条指令计算:
H(b1, b2)=POPCOUNT(XOR(b1, b2)),
其中, XOR为按位异或, POPCOUNT(· )为统计值为1的bit数量.这两条指令都是简单的布尔运算, 计算速度快于复杂的浮点运算.
本节从理论上分析使用二值检索代替浮点检索的可行性.首先, 当稠密向量满足前提条件“ 各维度是均值为0的对称分布” 时, 二值化检索等价于一种特殊的PQ检索[16].当满足此前提时, 汉明相似度与L2相似度大概率保序, 因此相比浮点值检索, 二值检索的性能损失不大.
首先介绍PQ检索的原理.PQ检索首先将高维向量空间划分为多个低维子空间, 对每个子空间上的实体向量集合通过K-means聚类生成k个聚类中心, 使用每个子空间上最近的聚类中心代替原本的实体向量(称为量化).之后分别在每个子空间上, 使用查询向量到实体聚类中心的距离, 最后组合这些子空间上的距离, 得到一个查询向量到实体向量的近似距离(称为量化距离), 其中最重要的是K-means聚类与量化距离的计算.
给定n维实体向量的集合{ve}⊆Rn, 先将ve 切分为多段独立的m维子向量的笛卡尔积:
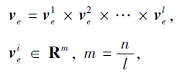
再在每个m维子空间上, 将子向量使用K-means聚为k个簇, 并使用最近的聚类中心代替原本的
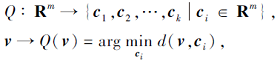
其中, d(· , · )为某种距离函数, 如L2距离, ci为使用K-means聚类后的第i个聚类中心.
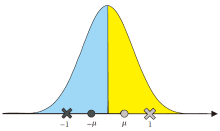
当各维度是均值为0的对称分布时, sign函数二值化等价于m=1, k=2的K-means聚类量化.这种K-means聚类的结果如图3所示.记左右两半的均值为± μ , 则{c1, c2}=± μ 就是K-means收敛时的聚类中心.若使用符号函数sign代替量化函数Q, 则等价于指定聚类中心{c1, c2}=± 1, 此时左右两簇的划分结果, 与以± μ 为聚类中心是相同的.
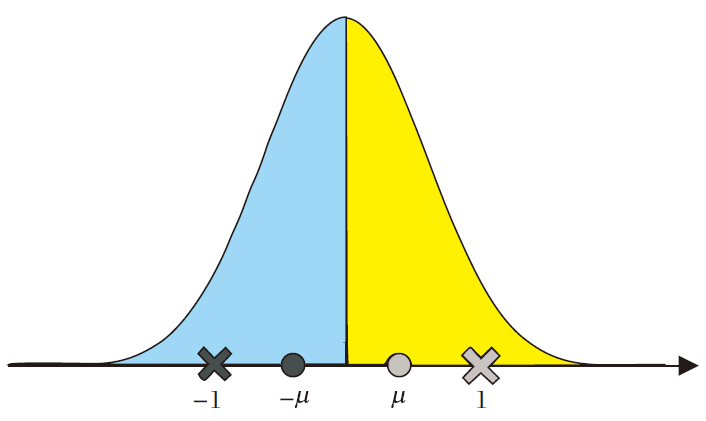 | 图3 m=1, k=2的K-means聚类结果Fig.3 Clustering result of K-means with m=1 and k=2 |
当满足可使用sign函数代替量化函数Q的条件时, 汉明距离与对称的量化距离等价.对称的量化距离dQ, 即对查询向量vq、实体向量ve都量化后计算的距离定义为
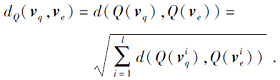
当Q(· )为sign函数, 距离d(· , · )为L2距离时, 由式(1)有dQ=2H, H为汉明距离, 因此dQ与汉明距离等价.
本节将从理论上分析汉明相似度与L2相似度在Rn上大概率是保序的, 所以二值检索与浮点值的检索性能相差不大.
首先定义相似度之间的保序性.保序性的含义为:在一种相似度s下更相似的两点, 在另一种相似度
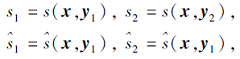
若满足
s1> s2⇒
则称从s到
P(
或
P(
则称从s到
l1=L2(x, y1), l2=L2(x, y2),
记汉明距离
h1=H(x, y1), h2=H(x, y2).
由于汉明距离等于汉明相似度取反(L2距离同理), 于是条件(2)等价于
P(l1≥ l2|h1< h2)→ 0. (3)
利用条件概率,
 |
说明条件(3)成立.
对于汉明距离, 给定x、 y1, 假设满足h1< h2的点y2存在, 则y2所在象限必须比y1的象限离x更远, 而这样的象限数量是有限、离散的, 因此P(h1< h2)是(0, 1)内的常数c.
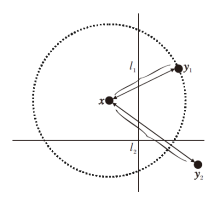
对于L2距离, 能满足条件l1≥ l2的点y2必须落在以x为球心、|x-y1|为半径的球里.以图4的二维空间为例, 相比无限的二维空间, 落在球内的概率趋近于0, 因此有
P(l1≥ l2)→ 0.
回到式(4), 由于左边
P(h1< h2)=c∈ (0, 1),
右边
P(h1< h2|l1≥ l2)< 1, P(l1≥ l2)→ 0,
于是必须有
P(l1≥ l2|h1< h2)→ 0,
式(4)得证, 因此汉明相似度到L2相似度大概率保序.
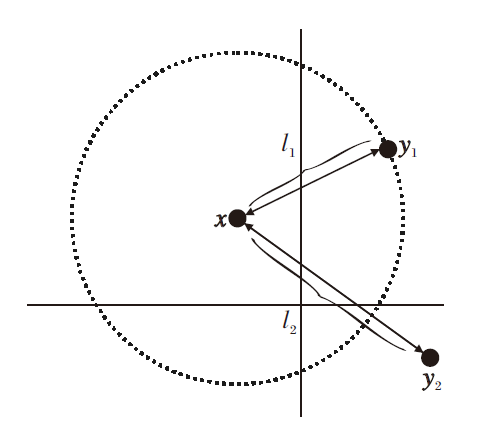 | 图4 P(l1≥ l2)→ 0示意图Fig.4 Sketch map of P(l1≥ l2)→ 0 |
本节通过实验验证sign函数+汉明距离的二值检索方案可在检索性能损失不大时, 压缩实体向量存储, 加快相似度计算.
在实体链接的基准数据集AIDA[17]上进行实验.除了BLINK、LUKE、MGAD, 还对比如下2个传统的启发式检索模型:1)Alias Table[18], 可预先通过维基百科锚文本收集; 2)BM25, 使用实体名称构建索引[13].
每个基于稠密向量的模型分为浮点值、二值化两种版本.浮点值模型是按官方超参数在AIDA-train数据集上微调的原版模型, 采用点乘相似度.二值化模型直接使用sign函数对浮点值模型的稠密向量二值化, 并使用汉明相似度检索, 该过程不需要训练.为公平起见, 所有模型的实体库统一限定为LUKE编码的约50万英文维基实体.
在AIDA-testB数据集上测试模型的检索性能、计算速度、存储空间.检索性能指标包括:MRR(Mean Reciprocal Rank)、Recall@K(K=1, 10, 30, 100), 后者简记为R@K.
实验平台的硬件配置如下:Intel(R) Xeon(R) Gold 5117 CPU @2.00 GHz, Tesla K80 GPU, 12 GB显存.
各模型检索性能如表1所示, 其中-b表示二值检索.由表可观察到, MGAD、BLINK、LUKE的浮点值模型效果优于Alias Table和BM25, 这显示稠密向量模型强大的语义匹配能力, 并且在3种稠密向量中, 使用上下文语义的MGAD和LUKE, 效果优于完全使用实体描述编码稠密向量的BLINK.由表还可发现, 二值化的BLINK和MGAD都可以保持较高的召回率, 其中MGAD在R@10上只损失0.8%, BLINK在R@30上只损失0.9%, 这两个模型二值化后依然性能优于启发式方法, 且二值化MGAD性能甚至优于浮点值BLINK.但是, 二值化的LUKE性能下降非常严重, 甚至差于启发式检索.总之, 对于部分神经检索模型, 二值化检索可保持较高的检索性能.
| 表1 各模型检索性能对比 Table 1 Retrieval performance comparison of different models % |
对于维度最高且二值检索性能最优的MGAD, 在AIDA数据集上测试其实体向量的存储空间及相似度计算速度, 结果如表2所示.对于32位浮点的实体向量, 二值化存储可减至1/32, 在CPU+内存的配置下, 相似度计算可加速约1.5倍, 甚至快于GPU+显存的浮点值模型.因此二值检索可大幅压缩存储、加快计算, 适合在低资源设备上部署.
| 表2 AIDA数据集上MGAD的效率 Table 2 Efficiency of MGAD on AIDA dataset |
4.2.1 定性分析
本节定性分析BLINK、LUKE、MGAD这3个稠密向量检索模型中实体向量的分布特点, 以及如何利用这些特点实现二值化检索.
分析三者预训练好的实体向量.三者的实体都来自英文维基, 但编码的实体数量不同, 最少的LUKE只编码最高频约10%实体, 最多的BLINK编码全部实体.此外3种实体向量的维度不同, BLINK为1 024维, MGAD为1 024维, LUKE为256维.本文发现如下2个特点, 并基于这2个特点提出二值检索方法.
特点1 实体向量分布在互不相同的象限里
使用sign函数提取浮点向量v每维的正负符号, 得到n维± 1向量b, 表示v在n维直角坐标系中所在的象限(n维空间有2n个象限).统计每个模型的实体向量分布在多少个象限里, 统计结果如表3所示, 表中all表示全量英文维基实体, top表示最高频的约10%实体.由表可发现:1)尽管3个模型编码实体向量的方法不同, 但对于高频实体, 每个实体向量都分布在不同象限里; 2)对于编码全部实体的BLINK, 只有很少的情况下多个实体会出现在同个象限里, 即每个象限里几乎最多只有一个实体.
| 表3 各模型的实体数量和向量象限数量 Table 3 Entity number and vector quadrant number of different models |
本文发现, 只有在实体描述过于相似的情况下, 才会出现一个象限中不止一个实体的现象.具体而言, 这种实体可细分为3类:1)维基消歧页; 2)只有名字没有描述; 3)使用一套描述模板批量编写的实体.这3类罕见情况属于实体库的噪声.此外, 实体向量确实都分布在互不相同的象限里, 且高维空间本身的象限数远多于实体数.例如:256维的LUKE共有2256≈ 1077个象限, 远多于全量英文维基实体数(约106), 而对于1 024维的BLINK和MGAD, 其
该特点说明使用浮点数的稠密向量存在大量信息冗余, 仅保留象限(通过sign函数得到的二值向量)就可代替原本的浮点向量, 从而压缩存储空间.
特点2 语义相似的实体向量所在象限也更近
进一步分析发现, 语义相近的实体会分布在更近的象限里(如象限(1, -1, 1)离(-1, -1, 1)更近, 离(-1, 1, 1)更远).下面通过一个可视化的例子加以说明.
本文选择两个实体:Java (programming language)和Switzerland, 并从MGAD的浮点实体向量中分别选择3个离它们距离最近的实体向量, 得到两组实体:
{Python(programming language), Java(software platform), Lua(programming language)}, {Switzerland football team, Swiss people, Switzerland in the Roman era}.
可看出, 每个实体都和自己组内的实体语义更相似, 和另一组实体的语义较远.
再将这两组实体向量二值化, 可视化效果如图5所示, 图中每行表示一个1 024维的二值化实体向量(深灰色为1, 浅灰色为-1), 每列的维度一一对应.± 1在各维度上的分布产生“ 条纹” , 2个二值向量的条纹越相似, 汉明距离也越小, 即象限离得越近.由图可看出, 组内语义较近的实体, 向量更相似(汉明相似度更大, 象限更近), 组间语义较远的实体, 向量更不相似(汉明相似度更小, 象限更远).
 | 图5 语义相似实体向量二值化的可视化效果Fig.5 Visualization for binarization of semantically similar entity vectors |
基于此特点, 可使用计算速度更快的汉明相似度, 衡量二值化后实体之间的语义相似度, 从而替换原本的浮点值相似度.
4.2.2 定量分析
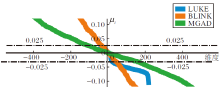
首先验证各模型是否满足二值化的理论前提, 即“ 各维度是均值为0的对称分布” , 发现对称分布基本成立(呈现为单峰对称分布), 但均值为0并不总成立.各模型各维度的均值(去除超过± 0.15的值)如图6所示.由图可发现, 只有部分维度的均值在0附近(图中± 0.025内), 这些维度与理论较符合.考虑到高维向量本身的冗余性, 及二值化的MGAD与BLINK召回性能并不差, 本文认为, 只要“ 均值接近0的维度足够多” , 就能抵消其余维度的负面影响.
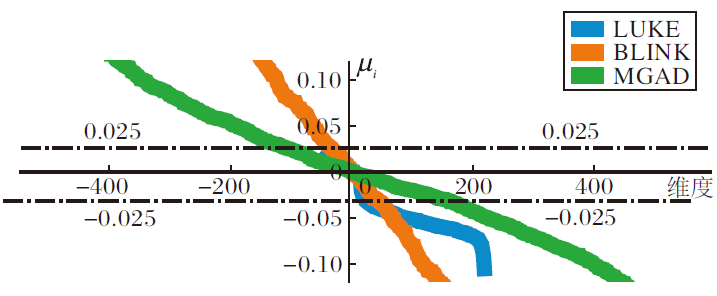 | 图6 各模型的各维度均值Fig.6 Mean of each dimension in different models |
再验证依据理论推导的结论, 即相似度的保序性.随机采样1 000个实体, 使用第1种相似度召回k近邻后, 计算有多少邻居在第2种相似度上保序.取k=3、10、100, 并测试汉明相似度(简记为Ham)、L2相似度(简记为L2)、余弦相似度(简记为cos)、点乘相似度(简记为dot), 保序性的实验结果如表4所示.由表可发现, 相似度保序的概率
MGAD > BLINK > LUKE,
platform), Lua( programming language)},
{Switzerland football team, Swiss people, Switzerland in
the Roman era}
| 表4 各模型相似度的保序概率 Table 4 Order-preserving probability of similarities for different models % |
该排序与图6中均值接近0的维度数量排序以及表5中二值化后的性能损失排序是一致的.此外以保序性最好的MGAD为例, 还可发现除了汉明相似度到L2相似度之外, 汉明相似度到余弦相似度、点乘相似度也是大概率保序的, 反之余弦相似度、点乘相似度到汉明相似度也大概率保序.
| 表5 各模型二值化后的性能损失 Table 5 Performance loss after binarization of different models % |
由此通过实验验证理论的正确性, 得到一个更宽松的结论:当各维度是对称分布时, 只要有足够多维度的均值接近0, 汉明相似度就大概率与L2相似度、余弦相似度、点乘相似度保序, 从而保证二值检索性能损失不大.进一步地, 均值接近0的维度越多, 保序性越优, 检索性能损失越小.
从4.1节和4.2节实验中发现, LUKE由于不能较好满足“ 有足够多的维度均值接近0” 的理论前提, 导致二值化后相似度保序性较差, 因此二值检索效果不佳.受HE-WGC在图像检索任务中应用随机旋转的启发, 发现对稠密向量随机升维旋转, 可以让更多维度均值接近0, 提高二值检索性能.
给定向量v∈ Rn, 随机升维旋转即对v右乘一个随机正交阵M∈ Rn× m, 其中m≥ n(当m=n时只旋转不升维).旋转可保证稠密向量的内积相似度、L2相似度、点乘相似度都不变, 而随机的升维可让各维度均值更接近0(作为对比, 虽然中心化也能令均值为0, 但这是一种平移变换, 无法保证点乘相似度、余弦相似度不变).具体而言, 设稠密向量集合的均值向量为μ , 随机升维旋转不改变μ 的模长, 且变换后的μ 均匀分布在半径为|μ |的m维球面上, 即
μ 2=
其中μ i为μ 的第i维分量, 也是变换后第i维的均值.由于各μ i同分布, 于是
Expect(
维度m越大, μ i的期望越接近0.
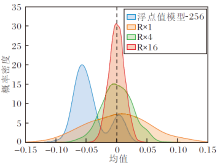
本节通过实验验证随机升维旋转确实可改善LUKE的二值化检索性能, 具体结果如表6所示, 表中b-R× n表示维度乘以n倍的随机升维旋转并二值化.除了浮点值模型以外, 其它行的数值是相对浮点值模型的性能损失.由表可发现:1)即使不升维, 只随机旋转(b-R× 1), 也可提高二值检索性能; 2)升维的倍数越大, 二值化检索效果越接近浮点值LUKE, 升维16倍时各项指标损失不到1%, 已非常接近浮点值模型(由于二值化可压缩至1/32, 即使升维16倍, 总存储空间依然能减半).
| 表6 对LUKE随机升维旋转后的二值检索效果 Table 6 Binary retrieval results of LUKE after random dimension increase and rotation % |
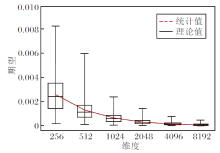
进一步绘制随机升维旋转后LUKE各维度的均值μ i分布图, 如图7所示.期望Expect(
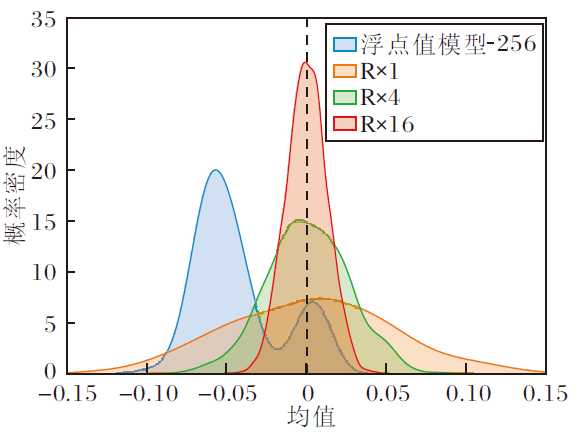 | 图7 LUKE随机升维旋转后均值分布Fig.7 Mean distribution of LUKE after random dimension increase and rotation |
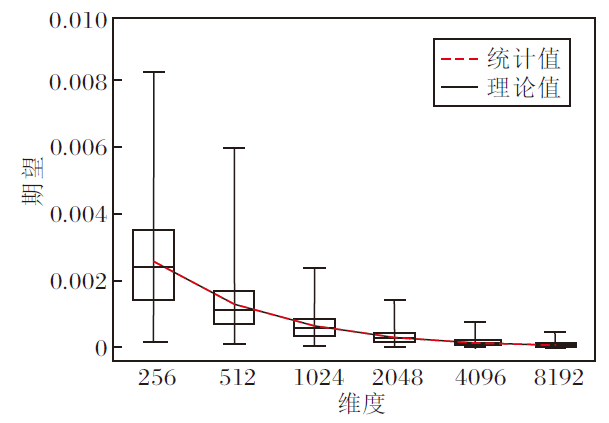 | 图8 期望Expect( |
对于基于稠密向量的实体检索模型, 它们的实体向量普遍具有2个特点:1)绝大多数象限中不超过一个向量; 2)语义相近实体向量分布在更接近的象限中.因此本文提出二值化的实体检索方法.使用sign函数+汉明相似度对实体向量进行二值检索.对于BLINK和MGAD, 该二值检索方法可保持较高召回率、压缩实体向量存储、加快相似度计算.从理论上分析二值检索方法在一定前提下的正确性.而对于二值检索效果不佳的LUKE, 可通过随机升维旋转使其更符合理论前提, 从而提高检索性能.今后将尝试建立更精细的二值检索理论, 此外会联合优化二值化与稠密向量学习过程, 得到更好的二值化表示.
本文责任编委 马少平
Recommended by Associate Editor MA Shaoping
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|